
基于Bi-LSTM-Attention 的英文文本情感分类方法
2022-09-02 06:24朱亚辉
电子设计工程 2022年16期
朱亚辉
(长沙师范学院外国语学院,湖南长沙 410100)
情感分类是自然语言处理中的一种底层技术,对于问答系统、推荐系统等任务都有较大的帮助[1]。当前,随着社交媒体的广泛普及,网络上的很多关于商品、服务的评论留言对改善商家服务以及了解人们的情感倾向很有帮助[2]。而情感分类任务就是能够根据评论文本中的情感色彩倾向性进行分类,得到积极和消极情感两个类别[3]。该文将重点讨论句子级别的情感分类任务,即对给定的语句进行情感二分类。
1 相关工作
最近十几年里,基于深度学习的理论在图像和文本处理领域均取得了飞跃式的成果与发展[4-5],情感分类任务自然也引入了基于深度学习的方法[6-8]。当前,尽管情感分类领域中有不少的研究工作都已达到了良好的成效,但一方面情感模型无法有效地捕捉两个方向的句子上下文依赖[9],另一方面又无法对情感特征内部的相互依赖性进行建模。
为了解决上述问题,该文同时采用双向长短期记忆(Bidirectional Long Short-term Memory)网络Bi-LSTM 与自注意力机制,提出了一种采用Bi-LSTM 与Attention 的英文文本情感分类算法模型。
2 相关技术
2.1 长短期记忆网络LSTM
图1为一个基本的LSTM的结构图。
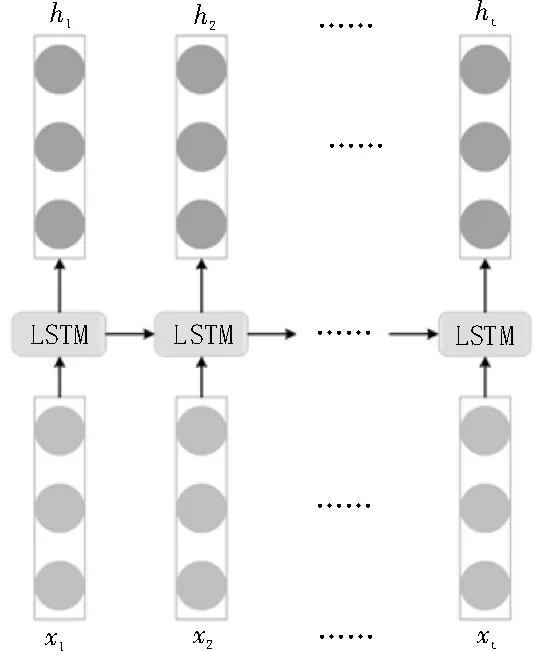
图1 标准的LSTM结构
LSTM 网络[10]是基于门控机制构建而成的,每个LSTM 单元中主要包含了输入门i、遗忘门f和输出门o。首先,遗忘门根据当前输入与上一个隐藏状态ht-1来选择遗忘上一个状态ht-1中的哪些信息。其次,输入门对单元的状态进行更新,决定了输入xt和上一个隐藏状态ht-1的信息通过量。最后,输出门控制从当前单元状态到隐藏状态的信息流。在第t个时间步单个LSTM 单元状态的运算流程如下:
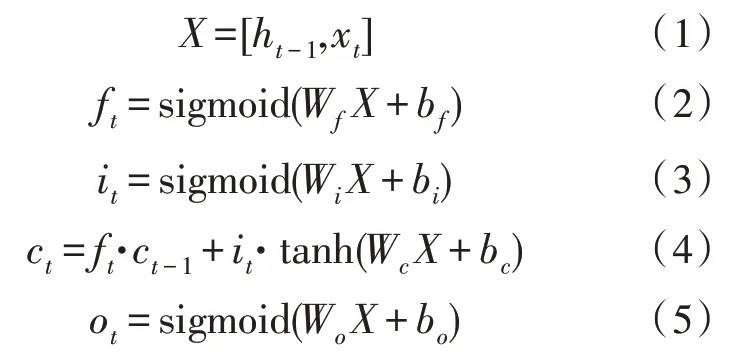
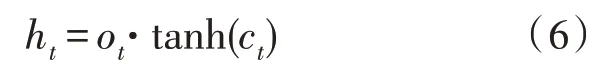
其中,xt∈Rn是输入向量,而W∈Rm·n是各个门的参数,b∈Rm是偏置向量;上标n与m分别是输入向量的维度与数据集中单词的总数;而[·]表示拼接操作。
2.2 双向长短期记忆网络
Bi-LSTM 网络[11]同时考虑了从前往后和从后往前两个方向的上下文信息,这样就可以获取到单个句子中相邻词语间的依赖关系。如图2 所示是一个标准的Bi-LSTM 的基本结构。给定输入xt和上一个时间步的隐藏状态ht-1,前向和后向的LSTM 的隐藏状态的计算公式如下:
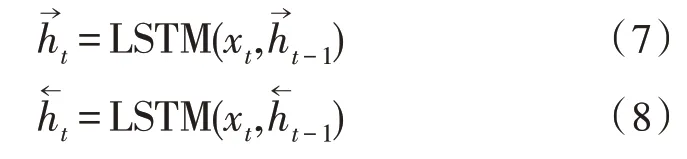
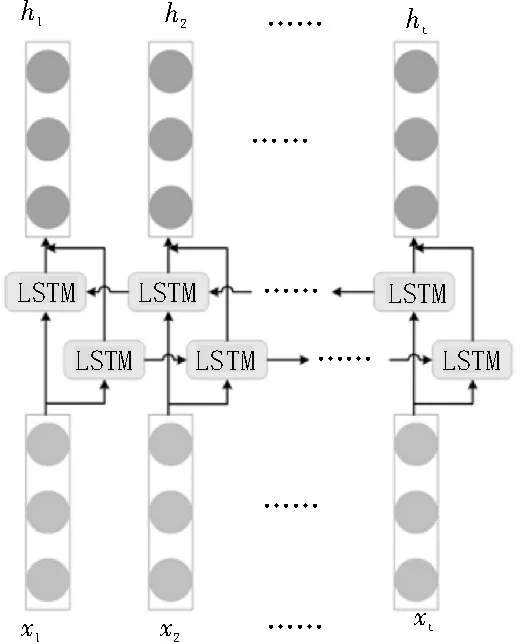
图2 标准的Bi-LSTM结构
最终,Bi-LSTM 的输出是拼接前后两个方向的隐藏状态得出的,即。
3 基于Bi-LSTM-Attention的情感分类模型
如图3 所示为该文所提模型的整体网络架构图。该模型主要包含了以下几个必不可少的组成部分,分别是输入句子序列层、词嵌入层、Bi-LSTM 层、自注意力层和一个Softmax 分类器。
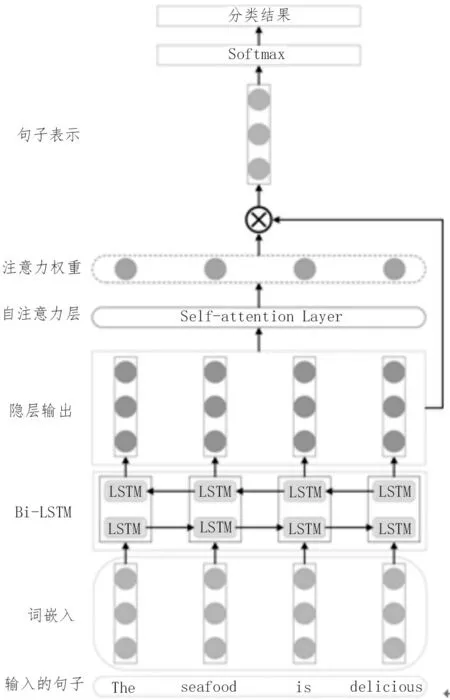
图3 Bi-LSTM-Attention模型的整体架构图
3.1 输入句子序列层
输入的第i句子si可以表示为:
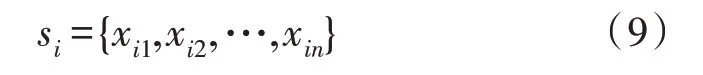
其中,xik是句子序列中的第k个单词,n是句子序列的最大长度。
3.2 词嵌入层
词嵌入层主要用于将输入句子序列中的单词表示为一个个维度为n的实值向量。该文使用了300维的GloVe 向量作为词嵌入预训练模型。
3.3 Bi-LSTM层
Bi-LSTM 利用前后两个方向的上下文特征信息,有效解决了上下文信息的提取和利用问题。Bi-LSTM 层的输出为:
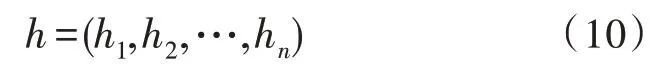
3.4 自注意力层
在情感分类任务中,自注意力机制可以实现对当前输入进行权重调整,突出了对分类结果有重大影响的词语的作用,而非同等对待所有的上下文信息。给定Bi-LSTM 层的隐层输出h,注意力权重的计算过程如下:
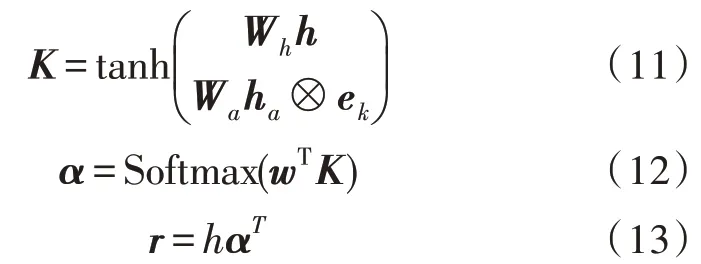
其中,K∈,α∈RT,r∈Rd,Wh∈Rd×d,Wa∈以及w∈都是参数矩阵。α是注意力权重矩阵,而r是输入句子的权重表示。ha⊗ek表示向量h重复地拼接了k次,而ek是大小为k的列向量。
最终,用于分类的句子表示为:

3.5 Softmax分类器
该文通过Softmax 层来计算条件概率分布,即预测输入句子对应的标签。条件概率的计算公式为:
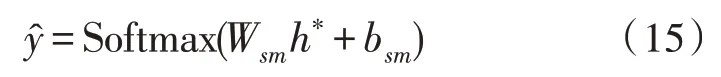
其中,Wsm和bsm分别是Softmax 层的权重参数与偏置参数。
3.6 损失函数
该文在训练的过程中主要使用交叉熵损失函数:
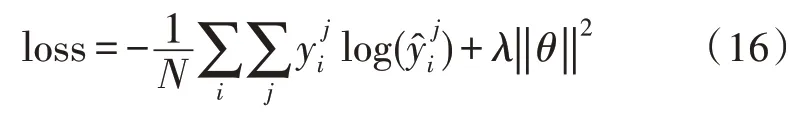
其中,i和j分别是句子的索引与类别索引,yi是预测的标签。λ是L2正则化项,θ代表模型的可优化参数集合,即{Wf,bf,Wi,bi,Wc,bc,Wo,bo,Wsm,bsm}。同样地,词嵌入向量也是模型的参数。
4 实验结果与分析
4.1 实验设置
在训练模型之前,该文通过GloVe 词向量来建立所有的词向量,模型中的词向量及其隐藏层向量均为300 维,Bi-LSTM 层的节点数为16 个。注意力权重的长度与句子的最大宽度是相同的,设为25。批次大小设置为32,学习率初始值设置为0.001,衰减因子为0.01,选择Adam 作为优化器,L2正则化项λ=0.1。为了防止模型过拟合,该文使用了随机失活的方法随机丢弃掉Bi-LSTM 层中的一些网络单元,随机失活率设为0.3,训练总轮数为50。
4.2 数据集和评价指标
该文主要使用两个常用的公开数据集来进行实验,分别是MR 数据集和SST-2 数据集。表1 中给出了各个数据集的详细统计信息。

表1 数据集的详细信息
该文主要采用准确率(Accuracy)作为指标来评估所提出的模型的性能和有效性。上述指标的计算公式如下:
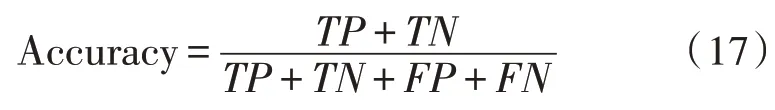
其中,TP为被准确地区分为正例的总数,FP为被误分为正例的总数,FN为被误分为负例的总数,TN是被准确地区分为负例的总数。
4.3 对比的基准模型
为了充分地验证所提算法模型的效果,该节将所提出的模型与其他8 种基准模型进行了实验对比,即SVM[12]、RNTN[13]、RAE[14]、MV-RNN[15]、CNNmultichannel[16]、CNN-non-static[16]、LSTM与Bi-LSTM。为了确保公平合理,所有的对比模型都是基于同一训练集从零开始训练的。
4.4 实验结果
表2 中提供了上述各个对比模型在MR 与SST-2数据集中的测试结果。对比表2 中的各个模型的准确率可以发现,采用深度学习的分类模型的性能远胜于常规的采用机器学习方法(即SVM)的分类模型。实验对比结果表明,该文所提出的模型在两个数据集上的性能是最优的。具体而言,原始的LSTM 模型在两个数据集上的性能明显低于CNN 模型的性能,而使用了Bi-LSTM 模型之后性能稍微有所提升,因为Bi-LSTM 同时考虑了前后两个方向的上下文信息,但其整体性能依旧低于CNN 模型的。然而,所提出的Bi-LSTM-Attention 模型结合了自注意力机制之后,其性能一举超越了CNN 模型,这充分表明结合了自注意力机制的Bi-LSTM 模型能够更好地探索语义特征间的内部依赖关系,并自适应地提升句子中的情感词的语义特征的权重,从而提升情感分类的性能。
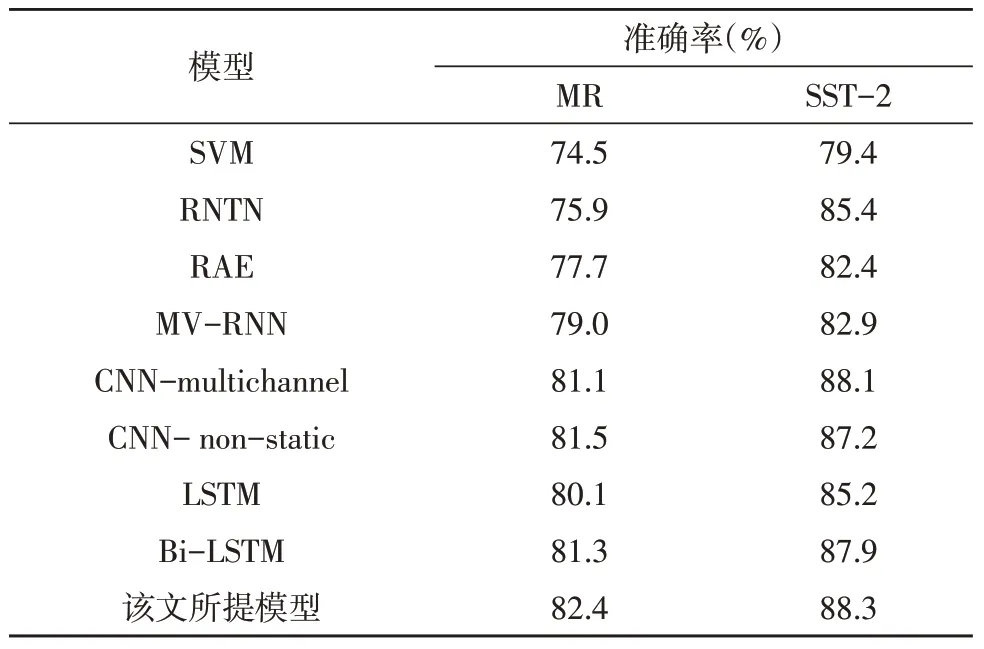
表2 在MR和SST-2数据集上的准确率
5 结论
针对英文文本的情感分类任务,该文主要提出了一种Bi-LSTM-Attention 分类模型。实验结果表明,该文提出的Bi-LSTM-Attention 模型在MR 和SST-2数据集上的性能显著胜于其他对比模型,能够利用注意力机制提升评论文本中的重要情感词语的权重,从而提升情感分类的性能。此外,该文提出的模型同时利用了前后两个方向的LSTM 来捕获双向的上下文信息,大大提升了模型的特征捕获与表达能力。
猜你喜欢
心理学报(2022年5期)2022-05-16
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
当代陕西(2020年17期)2020-10-28
甘肃教育(2020年22期)2020-04-13
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
