
动态环境下融合轻量级YOLOv5s 的视觉SLAM
2022-08-12 02:30伍子嘉
计算机工程 2022年8期
伍子嘉,陈 航,彭 勇,宋 威
(1.江南大学 物联网工程学院,江苏 无锡 214122;2.江南大学 人工智能与计算机学院,江苏 无锡 214122)
0 概述
同步定位与地图构建(Simutaneous Localization and Mapping,SLAM)是指机器人在未知环境中通过自身携带的传感器进行环境感知和周围环境的三维重建。机器人搭载的传感器常见的有相机、激光传感器、惯性传感器,由于相机采集的图像具有更丰富的色彩纹理信息,且相机价格低廉、体积小、功耗较低,所以应用较广泛。由相机作为主要传感器的系统被称为视觉SLAM 系统[1]。
现有的视觉SLAM 系统主要分为依靠特征点进行匹配并构建稀疏地图的特征点法,及利用最小化光度误差构建稠密地图的直接法。CAMPOS 等[2]在ARTAL 等[3]的基础上发布了基于特征点法的ORBSLAM3 方法,这是特征点法的代表。文献[4]中的DTAM 系统使用直接法实现实时稠密三维重建,文献[5]中的LSD-SLAM 系统利用图像灰度实现定位和半稠密点云地图构建。直接法的实现是基于同一像素点的灰度值在各个图像中固定不变这一假设,但由于光照变化、相机自动曝光等因素的影响,这一假设很难实现,因此基于直接法的SLAM 系统稳定性较差。
将视觉SLAM 系统与深度学习技术相结合可以有效利用图像中的语义信息,提高系统的定位建图精度。文献[6]的SLAM++系统可以将硬件采集到的点云信息与事先构建好的高质量3D 模型数据库进行对比,将匹配成功的物体模型插入地图中,但该系统的缺点是只能构建数据库中存在的物体模型。文献[7]提出将目标检测网络与传统的单目SLAM相结合,令目标检测框结合先验知识选出场景中的动态物体,并将边界框内的特征点全部剔除。但由于目标检测框框选出的范围大于动态物体的范围,因此会造成动态目标周围的静态特征点也被误剔除,导致系统精度下降。DynaSLAM 系统[8]将语义分割网络MASK-RCNN[9]与多视图几何相结合,实现对动态目标的检测和剔除。文献[10]提出DS-SLAM系统,在ORB-SLAM2 的基础上结合了SegNet 语义分割网络[11],去除了环境中运动的人的影响,同时可以构建语义八叉树地图,但是语义分割比较耗时,无法达到实时性的效果。
针对现有视觉SLAM 系统在动态环境下普遍存在精度较低或实时性较差的问题,本文提出一种面向动态环境下的视觉SLAM 系统,通过融合轻量级YOLOv5s 网络,减小模型的大小。此外,将目标检测网络与光流法相结合,剔除SLAM 系统前端的动态特征点,提高系统在动态环境下的定位精度。
1 系统框架
1.1 ORB-SLAM 系统
ORB-SLAM 系统的推出代表着主流特征点法SLAM的高峰,包括ORB-SLAM2与ORB-SLAM3系统。
1.1.1 ORB-SLAM3 系统
相比ORB-SLAM2 系统,ORB-SLAM3 系统融合了IMU 传感器,提升了整个SLAM 系统的定位及建图精度。如图1 所示,ORB-SLAM3 系统具有跟踪、局部建图、闭环检测3 个并行线程。跟踪线程负责ORB 特征点的提取和匹配,通过最小化重投影误差来估计2 帧间的相对位姿[2]。局部建图线程负责对得到的关键帧进行管理,通过集束调整(Bundle Adjustment,BA)来优化局部地图中所有帧的位姿。闭环检测线程通过关键帧检测整个地图是否发生闭合的回环,并通过位姿图优化不断矫正累积的漂移误差。当通过词袋模型检测到闭环后,会开启第4线程进行全局优化。

图1 ORB-SLAM3 系统线程与结构Fig.1 Threads and structure of ORB-SLAM3 system
1.1.2 改进的ORB-SLAM 系统
为提升ORB-SLAM 系统在动态环境下的精度与鲁棒性,本文在该系统原有的3 个并行线程的基础上增加了目标检测模块与光流模块作为第4 个线程。
在传统的跟踪线程中如果提取的ORB 特征点一直处于运动状态,那么这些点在特征点匹配计算位姿的过程中将会不断给系统带来积累误差,最终导致定位失败。如图2 所示,在跟踪线程中加入目标检测与光流线程,检测并剔除动态目标上的动态ORB 特征点,使其不参与相机位姿计算,仅留下静态特征点参与位姿计算。

图2 传统的跟踪线程与改进的跟踪线程Fig.2 Traditional trace threads and improved trace threads
1.2 目标检测网络Mobilenetv3-YOLOv5s
在结合深度学习的SLAM 方法中,实时性尤为重要。本文首先考虑将基于像素的语义分割方法与SLAM 系统相结合,但实验发现基于像素的语义分割方法难以实时运行。因此,本文引入基于深度学习的目标检测网络来检测环境中潜在的运动对象,通过融合轻量级网络进一步改进,该方法以较高的运行速度满足了SLAM 系统的实时性要求。但单独的目标检测网络的方形目标检测框通常会框选出不属于动态目标上的特征点,本文通过引入光流法可以有效解决该问题。
1.2.1 目标检测网络YOLOv5s
YOLO 是一种基于回归的目标检测算法,是目前应用最广泛的目标检测算法之一。它将目标检测作为回归问题求解,直接从一张输入图片获得预测物体的边界框位置及其分类,在保证准确率的同时兼顾了实时性,在速度与精度上达到了良好平衡。YOLOv5 目前仍在迭代更新,包含YOLOv5s、YOLOv5m、YOLOv5l、YOLO5x 共4 个版本。不同版本之间的主要区别在于深度及特征图的宽度不同,可以很方便地在其配置文件中通过调整depth_multiple 与width_multiple 两个参数的大小进行配置。
YOLOv5s 网络是YOLOv5 系列中深度、特征图宽度最小的网络。其模型参数量约为7.5M,在V100GPU 上,每张图片推理速度仅为0.002 s,即帧率为500 frame/s,完全满足实时检测的需求。
与先前的目标检测网络相比,YOLOv5 对整个网络的各个部分均作出了改进,包括在输入端采用Mosaic 数据增强、自适应锚框计算、自适应图片缩放,在Backbone 中引入Focus 结构与CSP 结 构,在Neck 中使用FPN+PAN 的结构,在输出端中采用GIOU_Loss 作为目标检测框的损失函数,同时引入了NMS 非极大值抑制机制。
1.2.2 轻量级网络MobileNet-V3
传统的卷积神经网络对内存需求大、运算量大,导致其无法在移动设备上实时运行。如VGG16 网络的权重为490M,Resnet-152 层网络的权重有644M。MobileNet 网络[13]是专注于移动端设备的轻量级CNN 网络,相比于传统的卷积神经网络,在准确率小幅降低的前提下大幅减少了模型参数与运算量。在Imagenet 数据集上相比VGG16 网络的准确率减少了0.9%,但模型参数只有VGG16 网络的1/32。其参数量大幅减小的原因主要是其引入了深度(Depthwise,DW)卷积、逐点(Pointwise,PW)卷积。如图3 所示,DW 卷积与PW 卷积相结合构成了深度可分离卷积(Depthwise Separable Convolution,DSC)。图3 中,DF表示输入特征矩阵的高和宽;M表示输入特征矩阵的深度;DK表示卷积核的大小;N为输出特征矩阵的深度;默认卷积步距为1。MobileNet 网络中卷积核大小一般为3×3,所以理论上普通卷积计算量是深度可分离卷积的8~9 倍。

图3 深度可分离卷积Fig.3 Deep separable convolution
普通卷积的计算量与深度可分离卷积的计算量之比如式(1)所示:

MobileNet-V1 被推出 后,Google 公司先 后推出了MobileNet-V2[14]和MobileNet-V3。图4 所示的MobileNet-V3 网络相比前代最大的特点首先是使用了神经网络架构搜索(Neural Architecture Search,NAS)技术,其次是更新了Block,使用了h-swish 激活函数,在深层网络中,这可以减小计算量,提高网络精度。同时,引入基于压缩奖惩网络(Squeeze and Excitation,SE)模块,注意力机制能够在训练过程中在特征图上自行分配权重,使网络从全局信息出发选择性地放大有价值的特征通道,并能抑制无用的特征通道用以提高网络的性能。最后,MobileNet-V3 还减少了第1 个卷积层的卷积核个数,精简了Last Stage。

图4 MobileNet-V3 网络的结构Fig.4 Structure of MobileNet-V3 network
1.2.3 轻量级目标检测网络MobileNetV3-YOLOv5s
为实现YOLOv5s 网络的轻量化,本文采用MobileNetV3-Small 取 代YOLOv5s 的Backbone 特 征提取网络,MobileNetV3-Small 网络结构如表1所示。
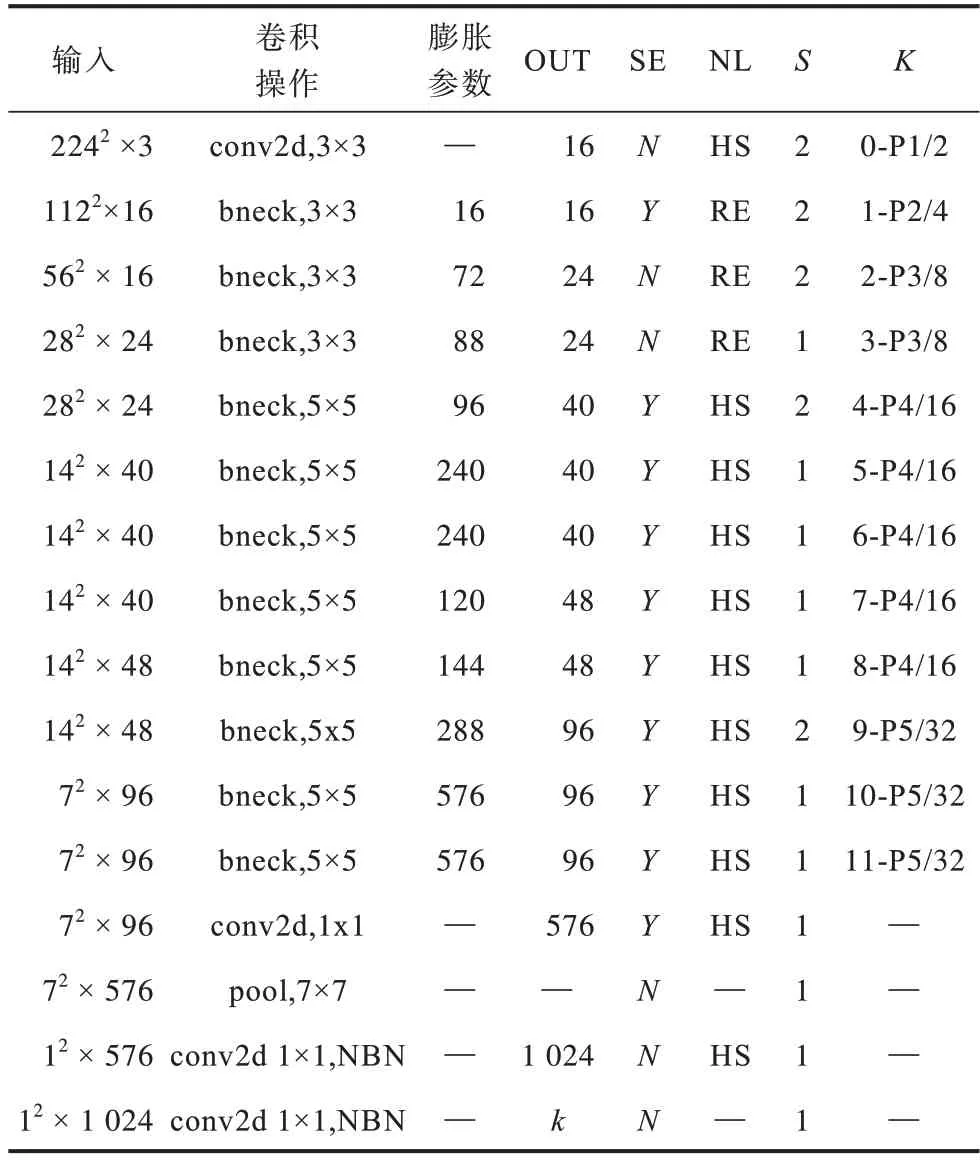
表1 MobileNetV3-Small 网络结构Table 1 MobileNetV3-Small network structure
如表1 所示,MobileNetV3-Small 的网络结构中有多个含有卷积层的块。其中:conv2d 表示正常的卷积层;bneck 即MobileBlock,表示卷积层,BN 层和激活函数的组合;NBN 表示不使用BN 层;SE 表示是否使用注意力模块;NL 表示非线性激活函数的类型;HS 表示h-swish 激活函数;RE 表示ReLU 激活函数;S表示步长;K参数表示这一层是模型中的第几个Block,相对输入的缩放是多少,“—”表示该层并没有被使用到,所以并无参数。
将MobileNetV3-Small 取 代YOLOv5s 的Backbone特征提取网络,并将各层所需特征图调整对齐,YOLOv5s 的Neck 所需的3 种不同尺度的特征图分别从3-P3/8、8-P4/16、11-P5/32 处引出,如 图5所示。

图5 改进的YOLOv5s BackboneFig.5 Backbone of improved YOLOv5s
1.3 ORB 特征点与光流法
1.3.1 ORB 特征点提取
常见的特征点有SIFT[15]、SURF[16]、ORB[17]等,这些特征点有的很精确,有的在光照变化下仍具有相似的表达,但实用的SLAM 系统主要考虑实时性问题。在同一幅图像中同时提取1 000 个特征点,SIFT 约花费5 228.7ms,SURF 约花费217.3 ms,ORB约花费15.3 ms[18]。由此可以看出,ORB 特征点在速度方面提升明显,对于实时性要求很高的SLAM 系统来说是一个很好的选择。
ORB-SLAM 系统在提取特征点时,建立了一个8 层的图像金字塔来实现尺度不变性,每层之间的比例为1.2 倍,在金字塔的每一层上检测特征点,将每一层的ORB 特征点均检测完毕后,会将所有特征点按比例投影至最底层。
1.3.2 光流法
光流法是一种描述像素在不同图像帧之间运动状态的方法。在动态目标上,同一个像素会在图像中运动,通过光流法可以追踪固定像素的运动过程。其中,描述整幅图像中部分像素运动状态的称为稀疏光流,描述所有像素运动状态的称为稠密光流。稠密光流以Hom-Schunck 光流为代表。稀疏光流以Lucas-Kanade[19]光流为主,也称为LK 光流。本文为减少计算量,只计算SLAM 系统的视觉里程计提取到的ORB 特征点的光流场,所以采用了LK 光流。
LK 光流的成立基于3 种假设:图像中的像素亮度(灰度)在连续帧间不会发生变化;帧间的时间间隔相对较短;相邻像素具有相似的运动。如图6 所示,图像的灰度可以视为时间的函数:在t时刻,位于图像中(x,y)处的ORB 特征点的灰度可以写为I(x,y,t)。

图6 LK 光流Fig.6 LK optical flow
根据光流法的灰度不变假设:同一个特征点的灰度值在各个图像中是固定不变的。对于t时刻位于(x,y)处的特征点,在t+dt时刻将移动至(x+dx,y+dy)处。
根据灰度不变假设可得:

对式(2)等号左侧进行泰勒展开,保留一阶项,得到式(3):

根据灰度不变假设,特征点在t与t+dt时刻的灰度值相等,可得:

两边同时除以dt可得:

式(5)中dx/dt为特征点在X轴上的运动速度,而dy/dt为在Y轴上的速度,分别记为u、v。∂I/∂x为图像在该点处X轴方向的梯度,∂I/∂y则是在Y轴方向的梯度,分别记为Ix、Iy。把特征点灰度对时间的变化量记为It,将其写成矩阵形式,如式(6)所示:

仅凭式(6)无法计算出特征点的速度u、v,必须引入额外的约束。在LK 光流中,以特征点为中心假设一个6×6 的窗口,内部36 个像素具有相同的运动。此方程是1 个超定方程,常用最小二乘法求解,如果一次迭代效果不佳,可以多迭代几次即可求解u、v。

将图像金字塔中所有的特征点向下迭代进行光流计算,每个特征点的光流信息(u,v)将会被记录到ORB-SLAM 系统内部记录特征点信息的结构体中,并用于下一步动态ORB 特征点的剔除。
1.4 运动目标检测与动态ORB 特征点的剔除
之所以要将目标检测网络与光流法相结合,一方面是因为仅从目标检测的结果来看,只能基于先验知识间接判断物体是否运动。对于静止的汽车、贴在墙上的人像画等此类目标,上面的特征点均会被识别成动态特征点。另一方面是因为目标检测网络检测出来的区域是一个规则的方形区域,而实际生活中的动态目标常常是一个边界不规则物体。如果粗暴地直接将目标检测框中圈出的目标区域内特征点全部去除的话,会删除一部分静态特征点,导致SLAM 系统匹配出的特征点数量大幅减少,影响定位精度。当动态目标占据较大画幅时甚至会导致初始化失败或者跟踪失败。
MobileNetV3-YOLOv5s目标检测网络对图像进行推理后生成的预测框由位置参数x、y、w、h以及置信度和分类结果6 个参数组成。x、y分别为预测框的中心与原图像的相对值,w和h表示预测框的长和宽与原图像的相对值。置信度代表该预测框内包含某物体的可信度以及预测框位置的准确度。分类结果则根据训练时使用的数据集所包含的物体类别决定。
如图7 所示,以预测框A为例,本文首先将其位置参数x、y、w、h转换为预测框左上方和右下方顶点在原图像下的坐标,分别设为(XA1,YA1),(XA2,YA2)(在原图像中,左上方顶点为坐标原点,向右设为X轴正方向,向下设为Y轴正方向)。

图7 特征点分布示意图Fig.7 Distribution schematic diagram of feature points
将目标检测网络输出的参数转换为目标检测框在原图像下坐标的公式,如式(8)所示:

其中:l为原图像的宽;d为原图像的高。
预测框内所包含的ORB 特征点均是基于先验知识判断的待定动态特征点,预测框之外均为静态特征点。首先假设所有的特征点集合为P={p1,p2,…,pn},待定动态特征点集合R={r1,r2,…,rn},静态特征点集合为O={o1,o2,…,on},P=R∪O。集合R内所有特征点都将参与动态特征点的筛选,每个特征点的坐标信息(x,y)由ORB-SLAM 系统前端计算所得,在X与Y轴方向上的速度信息(u,v)由光流法计算所得。由于在实际应用场景中,不仅图像中的动态目标运动会产生光流信息,画面的背景(静态特征点)也会随着相机本身的运动产生光流信息,所以需要先依照式(9)计算集合O内所有静态特征点的平均运动速度,即背景运动速度。
其中:U和V分别为在X与Y轴方向上的平均运动速度。
利用背景运动速度可以对集合R内所有待定动态特征点进行筛选,如式(10)所示。

其中:l为判断集合内特征点是否为动态特征点的自适应阈值,如果大于该阈值则判定为动态特征点,否则判定为静态特征点。动态特征点在计算位姿时将会全部被删除,不参与重投影计算位姿。
2 实验与结果分析
本文采用慕尼黑工业大学提供的RGB-D数据集系列中5个数据集进行测试,分别为sitting_xyz、walking_static、walking_xyz、walking_halfsphere、walking_rpy。该系列分为高动态场景和低动态场景。在高动态场景中,人在场景中会持续行走;在低动态场景中,人坐在椅子上,没有明显的动作。数据集名称中的static、xyz、halfsphere、rpy分别代表4种不同的相机运动方式:相机基本静止;相机沿X、Y、Z轴移动;相机在直径为1 m 的半球表面移动以及相机在翻滚、俯仰和偏航轴上旋转。
数据集中的真实轨迹由一个运动捕捉系统获得,该系统包括多台高速摄像机与惯性测量系统,能够实时获取相机位置与姿态的数据。因此该数据集被大多数视觉SLAM 研究人员采用,作为评估视觉SLAM 系统的标准数据集之一。
为加快深度学习模型的收敛速度,在本实验中,目标检测网络的训练在一台服务器上运行,其CPU为AMD Ryzen 9 3900X,内存为128 GB,GPU 为RTX3090,显存为24 GB。其他所有实验均运行在1台PC 上,CPU 为AMD Ryzen 7 5800H,内存为16 GB,GPU 为RTX 3060 Laptop,显存为6 GB。系统环境为Ubuntu 18.04,采用CUDA 11.1,深度学习框架PyTorch 1.9.0 装载在Anaconda 的虚拟环境中。目标检测实验运行软件为Pycharm。目标检测网络采用Python3.6 编写,SLAM 部分采用C++编写。
2.1 光流法实验
由图8(a)可知,因为相机本身的运动导致背景画面的运动,使传统的光流法在并没有运动目标的情况下也追踪到了大量的光流信息。由图8(b)、图8(c)可知,背景运动与人物运动的光流方向不一致,利用该特性,可以有效提取出运动目标的特征点。图8(d)为经过算法筛选后的预期效果,可以观察到全部光流信息均来自于运动的人。

图8 光流法检测动态特征点示例Fig.8 Examples of dynamic feature point detection by optical flow method
2.2 动态目标检测实验
目标检测网络采用VOC-2007 数据集训练,该数据集包含人、公交车、汽车、自行车、椅子在内的20 种不同物体,本次训练中训练集包含7 867 张图片,将MobileNetV3-YOLOv5s 网络训练了1 000 个epoch,batch_size 设置为128,学习率为0.003 2,余弦退火超参数为0.12,学习率动量为0.843,权重衰减系数为0.000 36。训练过程中利用可视化工具Tensorboard 得到的损失函数变化如图9 所示,可以观察到预测框、类别、置信度的损失均在稳步下降,为了达到较好的训练效果,随后又将batch size 减小并进行了训练,直至模型收敛。

图9 训练过程中损失函数可视化Fig.9 Visualization of loss function during training
利用MobileNetV3-YOLOv5s 网络对图片进行检测,检测效果示例如图10 所示。预设动态场景中运动物体均为人,所以将目标检测网络设置为只检测人,检测效果如图11 所示,可以观察到在图11(b)中人物仅露出双腿的情况下,目标检测网络也能将其准确框选出来。

图10 MobileNetV3-YOLOv5s 检测效果示例Fig.10 Detection effect examples of MobileNetv3-YOLOv5s

图11 运动中的人的检测效果示例Fig.11 Detection effect examples of people in motion
对walking_rpy 数据集中的910 张图片进行检测推理,不同目标检测网络在GPU 与CPU 上的模型参数量、算力要求、推理时间、帧率表现如表2 与表3 所示,所有测试均进行5 次,最终结果取平均值。可以观察到,利用MobileNetv3-Small 网络取代YOLOv5s的Backbone 特征提取网络使模型参数量减少了51.88%,算力要求减少了63.42%,在CPU 上推理速度提升了53.06%。

表2 在GPU 上的实验结果Table 2 Experiment results on GPU

表3 在CPU 上的实验结果Table 3 Experiment results on CPU
2.3 位姿估计误差分析实验
位姿估计误差分析实验采用evo工具将ORB-SLAM系统所估计的相机位姿CameraTrajectory.txt 与数据集所给的真实位姿groundtruth.txt 进行测试对比。测试指标为绝对轨迹误差(Absolute Trajectory Error,ATE),ATE 指标直接计算相机位姿的真实值与估计值之差,可以非常直观地反映算法精度和轨迹的全局一致性。
实验中计算了均方根误差(Root Mean Squared Error,RMSE)和标准偏差(Standard Deviation,STD)。其中均方根误差用于描述观测值与真实值的偏差,易受到较大或偶发错误的影响,所以能更好地反应系统的鲁棒性。标准差评价估计轨迹相较于真实轨迹的离散程度,能够反映系统的稳定性。
实验将ORB-SLAM3 系统与本文系统在高动态场景中的4 个数据集以及sitting_xyz 数据集上进行定量比较,计算时在旋转、平移与尺度缩放这3 个尺度上对齐,结果如表4 所示,表中每组实验均进行了2 次,最终结果取平均值。

表4 ORB-SLAM3 与本文系统的绝对轨迹误差对比Table 4 Comparison of absolute trajectory error between ORB-SLAM3 and system in this paper
令ORB-SLAM3 的误差为m,本文系统的误差为n,则相对提升率R的计算公式为:

由表4 可知,与ORB-SLAM3 系统相比,本文系统在5 个数据集下RMSE 的平均提升率达80.16%。对于在walking_static 与walking_rpy 这2 个数据集下的提升效果不如其他3 个数据集这一问题,通过观察目标检测网络处理后的图片与系统运行时的实际状态发现,在walking_static 数据集中,有相当一部分图像帧中人物占据画幅面积太大,导致检测到的静态特征点较少。而在walking_rpy 数据集中由于图像大幅旋转且画面模糊,部分人像未能被目标检测网络框选出来,最终导致了估计精度下降。
图12、图13 所示分别为ORB-SLAM3 系统与本文系统在walking_halfsphere、walking_xyz 两个数据集下的估计轨迹与误差分布图(彩色效果见《计算机工程》官网HTML 版)。

图12 ORB-SLAM3 系统估计的轨迹与误差分布Fig.12 Trajectory and error distribution estimated by ORB-SLAM3 system

图13 本文系统估计的轨迹与误差分布Fig.13 Trajectory and error distribution estimated by improved system
图12 和图13 每组图像中的子图(a)、图(c)分别为在walking_halfsphere 数据集下的计算结果,每组图像中的子图(b)、图(d)分别为在walking_xyz 数据集下的计算结果,从图中可以较明显地观察到本文系统所估算出的位姿和真实轨迹十分接近,相比ORB-SLAM3系统,各类误差值均有一个数量级的减小。
将本文所设计的视觉SLAM 系统与其他动态场景下的SLAM 系统进行对比,包括基于语义分割网络的DynaSLAM 和DS-SLAM 系统、通过优化关键帧之间的位姿图计算最小化光度和深度误差来获得约束条件的DVO-SLAM[20]、基于光流法的动态SLAM 方 法OFD-SLAM[21]以及MR-SLAM[22],对 比结果如表5 所示,其中“—”表示原论文中并未对这一数据集进行测试,加粗部分代表最佳结果,次佳结果下方用下划线示意,从表中可以发现最佳与次佳结果主要来自于DynaSLAM与本文系统。Mask-RCNN 在Nvidia Tesla M40 GPU 上处理每张图片需要195 ms,相比使用MASK-RCNN 的Dyna SLAM 系统,本文系统实时性更高,且ATE 指标相差非常小,可以认为性能相当。

表5 不同系统的绝对轨迹误差对比Table 5 Comparison of absolute trajectory error between different system
3 结束语
本文提出一种面向动态环境的视觉SLAM 系统,使用轻量级网络MobileNetV3 作为目标检测网络YOLOv5s 的主干网络,以减少模型参数量和算力需求,提升在CPU 上的推理速度。通过将目标检测网络与光流法相结合用于ORB-SLAM 系统的前端,剔除动态特征点。在TUM 数据集上的实验结果表明,相比ORB-SLAM3 系统,本文系统位姿估计精度提升了80.16%,相比DS-SLAM、DVOSLAM、DynaSLAM 等典型的动态SLAM 系统,本文系统在实时性与精度上均有部分提升。下一步将对网络模型进行剪枝蒸馏,将网络移植到性能更差的移动端设备上,同时加强对模型的训练,有效利用目标检测提取出的语义信息进行稀疏语义地图的构建,从而优化系统,使其能适用于更高层次的机器人定位工作。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
导航定位与授时(2022年4期)2022-08-05
小型微型计算机系统(2021年12期)2021-12-08
北京航空航天大学学报(2021年9期)2021-11-02
中国惯性技术学报(2020年4期)2020-12-14
导航定位与授时(2020年4期)2020-07-29
浙江海洋大学学报(自然科学版)(2020年5期)2020-06-19
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
电子技术与软件工程(2019年6期)2019-04-26
