
新冠肺炎疫情背景下聚集性传染风险智能监测模型
2022-08-12 02:29春雨童韩飞腾何明珂
计算机工程 2022年8期
春雨童,韩飞腾,何明珂
(1.首都经济贸易大学 管理工程学院,北京 100070;2.国能经济技术研究院有限责任公司,北京 102299;3.北京物资学院 物流学院,北京 101149)
0 概述
新冠肺炎一般指新型冠状病毒肺炎(Corona Virus Disease 2019,COVID-19)。2019 年末,新冠肺炎疫情爆发,全国各地报道多起聚集性传染病例。随着疫情防控进入常态化阶段,全国出现多点散发、局部聚集性疫情反弹的现象。2021 年7 月,南京禄口机场爆发聚集性传染疫情并扩散至全国多地,10 月至12 月,内蒙古、北京、浙江等多地出现散发聚集性传染疫情,疫情防控工作再次面临严峻考验。在人员密集的公共场所佩戴口罩并保持安全距离是有效防控聚集性传染的主要方式[1-2]。目前,人工监测是对公共场所人群聚集及口罩佩戴情况的主要监测手段。然而公共场所具有人流密集且流动性大的特点,人工监测不仅难以高效识别聚集人群的口罩佩戴情况,而且存在监测人员感染、监测人力不足等情况。因此,构建智能化的聚集性传染风险监测模型对现阶段的疫情防控具有重要意义和实践价值。
近年来,很多基于深度学习的高精度通用目标检测算法被提出,如Faster R-CNN[3]、R-FCN[4]、Cascade R-CNN[5]、YOLO[6]、SSD[7]、RetinaNet[8]、YOLOv3[9]等,并在很多场景下实现了落地应用[10-12]。在疫情防控背景下,研究者进行了一些口罩佩戴检测算法的研究。王艺皓等[13]针对复杂场景下存在的目标遮挡、密集人群、小尺度目标检测等问题,通过结合跨阶段局部网络、优化空间金字塔池化结构和使用CIoU 损失函数改进YOLOv3 算法,提出了新的口罩佩戴检测算法。曹城硕等[14]等同样针对口罩佩戴检测任务中被遮挡目标和小目标检测困难的问题,在特征提取网络中引入注意力机制,提出了YOLO-Mask 口罩佩戴目标检测算法。张修宝等[15]在ResNet50 网络的基础上加入空间和通道注意力学习机制,增强了口罩佩戴识别模型对口罩区域特征的学习。彭成等[16]基于YOLOv5 检测框架,通过将其中的部分特征提取模块替换为更轻量的GhostBottleNeck 和ShuffleConv 模块,实现了一种轻量级口罩佩戴 检测框架。WANG 等[17]提出了MFDD、RMFRD、SMFRD 3 种类型的蒙面人脸数据集以提高口罩检测识别精度。虽然口罩相关检测算法的研究取得了较大进展,但所涉及的功能及场景具有单一性,而单独一种功能无法有效地实现聚集性传染风险监测。此外,现有口罩检测算法的精度仍有待提升。
本文将聚集区域检测、行人检测和行人口罩佩戴情况检测相结合,提出多功能多场景的目标检测框算法Cascade-Attention R-CNN。针对任务中目标尺度变化过大的问题,选取高精度两阶段目标检算法Cascade R-CNN作为基础检测框架,通过在级联的候选区域分类-回归网络中加入空间注意力机制,达到突出候选区域重要特征和抑制噪声特征的目的,进而提升特征表达能力。在此基础上,根据检测结果评定疫情传染风险等级,实现对聚集性传染的无接触和智能化防控和监测。
1 聚集性传染风险监测模型
1.1 聚集性传染风险等级划分
口罩是预防呼吸道传染病的重要防线,能够大幅降低以新型冠状病毒为代表的呼吸道传染疾病感染风险[18]。由于商场、超市、火车站等公共场所具有人流密集且流动性大的特点,佩戴口罩更是成为预防聚集性传染的必要措施。根据《新型冠状病毒感染的肺炎防控方案(第六版)》中对聚集性病例的相关描述,本文将图像中两人及以上,可由人工判断为近距离相处的人群视为聚集人群(dense)。由于聚集人群中的人员密集程度和口罩佩戴情况是影响聚集性传染风险的重要因素,因此本文在判断聚集人群的基础上,将行人(person)及口罩佩戴(mask)两个要素作为变量,划定聚集性传染风险等级并以不同颜色标记进行区分,其中一级风险为最高等级。
设一张图像中dense 的集合为X=[x1,x2,…,xn],xi中person 的集合为Yi=[y1,y2,…,ym],mask 的集合为Zi=[z1,z2,…,zp],三者关系符合zi⊂yi⊂xi。设定xi中Yi数量的阈值为δ,则聚集性传染风险等级划分如表1 所示。

表1 聚集性传染风险等级Table 1 Level of aggregated infection risk
在实际监测中,阈值可根据实施监测的具体环境及情况进行调整,如密闭室内环境中可将δ降低,在开阔室外环境则可提高。
1.2 智能监测流程设计
目前,人工监测是对公共场所人群聚集及口罩佩戴情况的主要监测手段。然而由于公共场所人流密集,人工监测不仅难以高效识别聚集人群的口罩佩戴情况,且存在监测人员感染、监测人力不足等情况。虽然已有部分企业开发了口罩识别或行人识别模型以帮助疫情防控,但这些模型大多存在功能单一(只可识别口罩或行人)和场景单一(近距离和简单场景)的问题,难以在多场景下实现多类别的目标检测。
针对以上问题,本文提出聚集性传染风险监测模型,实现无接触和智能化的聚集性传染风险监测,模型架构如图1 所示(彩色效果见《计算机工程》官网HTML 版)。该模型可通过摄像头的监测画面识别特定场所的聚集人群、行人和口罩佩戴情况,并根据表1 判定风险等级。

图1 聚集性传染风险监测模型架构Fig.1 Framework of monitoring model for aggregated infection risk
本文模型包括数据获取、数据预处理、模型推理、检测结果、结果融合、风险等级6 个部分,具体过程如下:
1)数据获取:通过摄像头或其他图像采集设备获得视频影像。影像获取设备可根据具体场景监测需求调节距离和角度,以尽可能多地获取监测场景信息。由于摄像头拍摄的图像仅包含2 维信息,因此本文在判断聚集人群时不考虑3 维空间中的距离因素。
2)数据预处理:利用跨平台计算机视觉库OpenCV 将视频按帧切割成图片,并将图片作为目标检测模块的输入。OpenCV 是由Intel 公司开发的开源计算机视觉库,具有编写简洁而高效的特点,在图像处理领域被广泛应用[19-21]。由于将视频切分为帧图片属于成熟技术且不是本文讨论重点,因此对数据获取及数据预处理部分不做讨论。
3)模型推理:利用空间注意力机制优化Cascade R-CNN[5]算法,提出Cascade-Attention R-CNN 目标检测算法,并基于该算法建立基于视觉的多功能多场景目标检测模块,以数据预处理获得的帧图片作为输入,识别图片中人、口罩、聚集人群3个目标的位置及数量。具体内容详见1.3 节。
4)检测结果:多功能多场景目标检测模块的输出结果,用红色、蓝色和绿色的检测框分别标注聚集人群(dense)、人(person)及口罩(mask)的所在区域。
5)结果融合:利用结果融合模块判断目标检测结果中聚集人群(dense)、个人(person)和佩戴口罩(mask)三要素的隶属关系及数量,同时将目标检测模块结果与表1 中的聚集性传染风险等级相融合,判定图片的风险等级。具体内容详见1.4 节。
Steinhaus(1955年)、Lloyd(1957年)、Ball&Hall(1965年)和McQueen(1967年)分别从不同的学科研究领域提出了K-means聚类算法,同时,McQueen总结了 Cox〔1〕、Fisher〔2〕、Sebestyen〔3〕等的研究成果,给出了K-means算法的执行步骤,并利用数学方法进行了理论论证。
6)风险等级:将图片所对应的聚集性传染风险等级以不同边框颜色进行表示。颜色标签详见表1。
1.3 目标检测模块及算法设计
当前主流的通用目标检测算法大致分为两阶段目标检测算法和单阶段目标检测算法。相较于单阶段目标检测算法,两阶段目标检测算法由于在第一个阶段过滤掉了大部分不包含物体的候选区域,因此缓解了正负样本不平衡的问题,具有更高的检测精度。Faster R-CNN[3]作为最具代表性的两阶段目标检测算法,是之后很多优秀目标检测算法的基础,具有重要的里程碑意义。然而,目标尺度变化过大是本文任务中所存在的关键问题,而Faster R-CNN在处理这一问题上具有局限性[5]。在Faster R-CNN第一个阶段输出的候选区域中,绝大部分候选区域与真实目标的重叠面积较小,这在训练时会导致训练样本尺度不平衡,进而导致模型对于不同尺度的目标识别效果差别较大。为了缓解Faster R-CNN 对于尺度问题的局限性,本文基于Faster R-CNN,通过设计多个级联的候选框分类回归网络(RoI-Head),使得不同级别的RoI-Head 负责位置偏差不同的候选框的预测,提升了算法对于尺度变化的鲁棒性。然而,Cascade R-CNN 虽然设置了多个级联的RoIHead,但是每个RoI-Head 内部提取更高辨识度特征的能力仍然有提升空间,更高辨识度的特征更有利于区分不同尺度的物体。因此,本文基于Cascade R-CNN 提 出Cascade-Attention R-CNN 算法,通过结合空间注意力和卷积操作,设计一种特征提取能力更强的注意力候选框分类回归网络(Attention RoI-Head),进一步提升算法的检测效果。如图2 所示,算法输入为视频帧图片,通过级联3 种结构相同的Attention RoI-Head,输出行人(person)、聚集人群(dense)及口罩(mask)的检测类别分数及位置信息。其中,以score 代表每个类别的预测概率分数,bbox代表回归后的区域坐标。
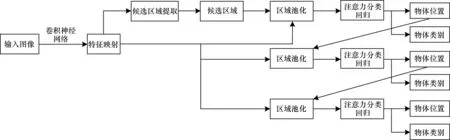
图2 Cascade-Attention R-CNN 算法流程Fig.2 Procedure of Cascade-Attention R-CNN algorithm
Cascade-Attention R-CNN 算法包含两个阶段:第一阶段为候选区域提取网络(Region Proposal Network,RPN),用于提取目标区域,以二分类的方式判断物体是否存在并对预先定义的anchor 区域位置进行微调,最终输出包含物体的候选区域(proposals),此阶段并不考虑具体的物体类别;第二阶段为基于空间注意力的候选框分类回归网络(Attention RoI-Head)。在R-CNN 系列的两阶段检测算法中,RoI-Head 往往先将候选框对应的特征输入到连续两个全连接层,然后再分别利用两个全连接输出最终候选框的类别概率分数和位置偏移。Cascade R-CNN 沿用了Faster R-CNN 中的RoI-Head,但并没有对其结构进行改进。本文提出的Cascade-Attention R-CNN 算法在使用Cascade R-CNN 级联结构的同时,对RoI-Head 的网络结构进行改进,通过在ROI Pooling Feature Map 上进行卷积和空间注意力的操作,提出Attention RoI-Head,实现了更强大的相关特征提取功能。
具体而言,本文将RoI-Head 中分类和回归共享的两个全连接层改变为3 个卷积层和1 个全连接层,且针对3 个卷积层分别使用空间注意力机制来提高特征表达能力。2 种RoI-Head 结构对比如图3 所示。

图3 RoI-Head 结构对比Fig.3 Structure comparison of RoI-Head
本文选择卷积层和空间注意力机制结合使用,是因为不同尺度目标物体的主要差异来源于空间层面的不同,对于其空间特征差异性的捕获更有助于实现对不同尺度目标物体的区分。相较于全连接层,卷积层能够更好地保持目标物体特征的空间特性,空间注意力则可对特征的空间层面进行显式加权,过滤噪声特征,增加更高辨识度空间特征的权重,进而实现对于不同尺度物体区分度更高的特征提取,最终提升算法对于任务中尺度变化过大情况的鲁棒性[22]。实验结果表明,改进后的Attention RoI-Head 具有更好的效果。关于空间注意力的具体形式,本文采用CBAM[22]中的空间注意力,如图4 所示。值得注意的是,其他形式的空间注意力或许具有更好的效果,但本文主要研究利用注意力机制与卷积结合去提升算法特征表达能力,进而缓解尺度变化过大的问题,而关于空间注意力的表达形式不是本文研究内容。

图4 空间注意力机制流程Fig.4 Procedure of spatial attention mechanism
损失函数属于多任务损失函数,包含第一阶段RPN 的损失和第二阶段Attention RoI-Head 的损失,且两部分损失均包含分类损失(cls loss)和回归损失(bounding box regression loss)。以RPN 阶段的损失函数为例,如式(1)所示:

其中:i表示候选框(anchors)索引;Ncls为总的anchors数量;Nreg为anchors 所在的中心位置个数;由于实际过程中Ncls和Nreg差距过大,因此用参数λ平衡两者差距,使网络可以均匀地考虑两种损失;pi表示预测候选框i为目标的概率表示选取候选框对应的样本所属标签,当候选框目标为正样本时取1,否则取0;ti表示预测的边界框(bounding box)的4 个坐标参数表示正确标注边界框的坐标;Lcls表示二分类器的分类损失,如式(2)所示;Lreg表示回归损失,如式(3)所示;R表示smoothL1函数,如式(4)所示。

为增强算法对于小目标检测的效果,本文引入特征金字塔网络(Feature Pyramid Network,FPN),通过采用一种自上而下(top-bottom)的方式,将顶层特征与底层特征进行融合,之后在融合后的每层特征上进行候选区域提取、相关类别预测和偏移量预测。
1.4 结果融合模块及算法设计
本文通过结果融合模块判断目标检测结果中聚集人群(dense)、个人(person)和佩戴口罩(mask)三要素的隶属关系及数量,并将目标检测模块结果与风险监测等级相结合。为了更准确地判断三要素关系及数量,结果融合模块对dense 和person、person 和mask 这2 种情况分别进行处理。

图5 图像坐标系示意图Fig.5 Schematic diagram of image coordinate system
设dense、person、mask的坐标分别为(x0,y0,h0,w0)、(x1,y1,h1,w1)、(x2,y2,h2,w2),其中:x和y分别代表检测结果中边界框左上角点在图中的横纵坐标;w和h分别代表边界框的宽和高。在判断dense 中person 个数阶段,设dense与person的交集坐标为(xi,yi,hi,wi),则有:

根据式(5)和式(6)可计算得出dense 和person边界框的面积交集Sσ以及person 边界框面积S1。当dense 与person 有交集且交集面积Sσ占S1的比例大于等于阈值α,即person 满足式(7)中所有条件时,判定该person 属于dense 且计数加1。

在判断person 是否正确佩戴mask 阶段,由于mask 的正确佩戴方式是在面部,因此默认mask 必须全部在person 边界框内。利用式(8)判断mask 是否得到正确佩戴:

其中:β代表mask 距person 边界框顶部的垂直距离占person 边界框高度h2比例的阈值。当mask 满足式(8)中所有条件时,判定mask 得到正确佩戴且计数加1。
1.5 评价指标
由于目标检测模块的检测效果直接影响聚集性传染风险监测模型的有效性,因此本文仅针对目标检测模块中的算法运行效果进行评价。为更好地综合反映精确率和召回率的情况,本文采用平均精度均值(mean Average Precision,mAP)作为对目标检测模块的评价指标,该指标兼顾了精确率和召回率。精确率PPrecision和召回率RRecall的计算公式如下:


其中:TP为正确识别的目标数量;FP为误识别的目标数量;FN为漏识别的目标数量。
通过选取召回率和精确率的值作为横坐标和纵坐标,得到的P-R 曲线下的面积即为平均精度(Average Precision,AP)。对所有类别求AP 并取均值即为mAP 指标。mAP 是目标检测问题中常用的评价指标,可以反映算法的整体性能[23-24]。
2 实验与分析
2.1 数据集构建
基于聚集性传染风险监测模型的定义,本文实验使用的数据集必须同时包含人群聚集和口罩佩戴两个特征,且包含不同场景和视角。为清晰表示不同场景及视角,本文以A1 和A2 分别代表平视及俯视两个视角,平视指镜头与被拍摄物体保持基本相同水平获得图片,俯视指镜头中人眼处于平常生活状态下的俯视镜头获得图片。以B1、B2、B3 分别代表近、中、远三种距离,C1 和C2 分别代表室内及室外两种场景,如图6 所示。由于缺少公开数据集,本文通过网络爬取及整合相关公开数据集的方式构建聚集性传染风险监测数据集。网络爬取部分选择百度及必应(bing)两个图片搜索引擎,分别以“口罩”“人群”“聚集”“疫情”“新型冠状病毒”等为关键词,利用爬虫下载搜索结果图片,并通过人工筛选得到1 049张有效图片。公开数据集部分选取大型商场(Mall Dataset)[25]、UCSD[26]、上海科技(Shanghaitech)[27]这3 个人群统计数据集,以及MAFA 面部口罩检测数据集[28]。经过对2 个渠道数据源的筛选和清洗,共得到1 542 张有效图片,按照5︰5 划分训练集和测试集。由于数据集中涉及部分人脸信息,出于肖像权保护及信息安全的考虑,对包含清晰面部信息的图片均采取去除眼部信息特征的处理。实验数据集的具体数据分布如表2 所示。最后,使用目标检测任务标注工具LabelImg将数据集标注为PASCAL VOC[23]格式。

图6 数据集示例图片Fig.6 Example images of dataset

表2 数据集数据分布Table 2 Dataset distribution of dataset
2.2 实验环境及参数设置
在多功能多场景目标检测模块的实验中,本文使用的仿真平台为Ubuntu 16.04,显卡采用GeForce GTX TITAN X 12 GB 独立显卡。此外,安装GPU 开发包CUDA10.1,深度学习框架为Pytorch 1.6.0,代码运行环境为Python 3.7.9。在训练阶段,采用ImageNet[29]上的预训练模型ResNet-50[30]作为特征提取网络。超参数设置如下:初始学习率为0.001,30 epoch 后调整为0.000 1,共训练32 epoch;优化器选择带Momentum 的SGD,其中Momentum 设置为0.9;batch size 为1。在训练和测试阶段,图片的输入尺寸统一为600×1 000 像素。
2.3 算法评价
表3展示了本文提出的Cascade-Attention R-CNN算法与其他主流目标检测算法的性能对比。通过表3 可知,两阶段目标检测算法Cascade R-CNN[5]mAP分别超过单阶段目标检测算法RetinaNet[8]和SSD512[7](输入图片的尺寸为512×512像素)5.8 和0.9 个百分点。本文提出的Cascade-Attention R-CNN 算法超过Cascade R-CNN 算法2.6 个百分点,结果表明本文提出的Attention RoI-Head 效果优于原始RoI-Head。此外,Cascade-Attention R-CNN算法关于行人(person)、口罩(mask)的AP 值均达到90% 以上,关于聚集人群(dense)的AP 值达到85%以上。
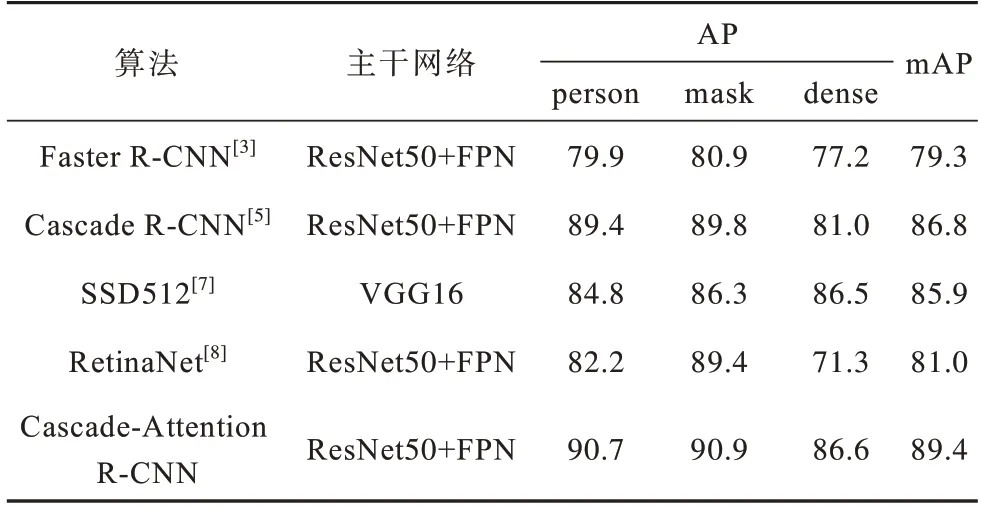
表3 不同算法的检测精度对比Table 3 Detection precision comparison of different algorithms %
2.4 实验结果及分析
本文聚集性传染风险监测模型的实验结果如图7 所示(彩色效果见《计算机工程》官网HTML版),其中体现了本文通过Cascade-Attention R-CNN算法构建的模型在不同场景和视角下对图片识别出的信息及相应的聚集性传染风险等级。其中:图片内边界框分别代表所识别的信息person(蓝色)、mask(绿色)及dense(红色);图片边框颜色代表聚集性传染风险等级;dense 中person 数量阈值δ设置为2;结果融合模块中的α和β阈值分别设置为2/3 和1.5。
通过对实验结果的分析可得到以下结论:
1)目标检测模块对于近、中、远距离的目标均具有良好的识别效果,如图7(a)、图7(e)、图7(k)所示。
2)目标检测模块可有效识别面部佩戴口罩情况,但存在特殊案例,如图7(f)中虽然识别口罩佩戴在面部,但未遮挡住鼻子,感染风险大幅提升。由于类似情况较少,此处不做特殊处理。
3)目标检测模块对于聚集人群(dense)具有良好的识别效果,但存在瑕疵。如图7(k)和图7(l)所示,当人群过于密集且视角过远时,dense区域存在漏人情况,但此类情况不影响风险监测模型的正确监测。
4)目标检测模块对于除口罩外的面部遮挡干扰具有较强的鲁棒性。如图7(b)和图7(c)所示,虽然用手和面巾遮住面部,但目标检测模块未将该类遮挡视为佩戴口罩。
5)结果融合模块具有良好的融合效果。对比表1 中定义的聚集性传风险等级可以看出,结果融合模块可以有效地将监测结果与风险等级相结合,得到正确的监测风险等级。
基于以上对实验结果的分析可知,多功能多场景目标检测模块可以识别不同视角(俯视、平视)、不同场景(室内、室外)及不同距离(远、近)的多类别(个人、聚集人群及口罩)图片信息,具有较高的准确率和鲁棒性,同时结果融合模块也可有效融合检测结果与风险等级,进而验证了本文模型的有效性。
3 结束语
近年来,新冠肺炎疫情严重威胁着人们的生命健康,而对于聚集性活动的监管,如聚集性人群以及口罩佩戴状态的监管,是控制疫情传播的重要手段。本文提出Cascade-Attention R-CNN 检测算法,缓解人工监管聚集性区域、行人和口罩佩戴耗费人力且增加传染风险的问题。为应对目标尺度变化过大的情况,选取Cascade R-CNN 作为基本检测框架,通过在候选区域分类-回归网络中加入空间注意力机制,实现更高辨识度的特征提取。在此基础上,通过融合Cascade-Attention R-CNN 的输出结果,构建聚集性传染风险监测模型,自动判定当前场景下的聚集性传染风险等级。实验结果表明,Cascade-Attention R-CNN 较Faster R-CNN、RetinaNet、SSD、Cascade R-CNN 等主流目标检测算法具有更高的检测精度,并且所构建的监测模型能够准确判定传染风险等级。本文采用原始的特征金字塔网络,针对固定尺度范围的目标仅使用单一的特征金字塔层。后续将利用不同层级的特征提取更高辨识度的特征,进一步提升检测效果。
猜你喜欢
初中生学习指导·中考版(2021年2期)2021-09-10
恋爱婚姻家庭(2020年27期)2020-10-09
意林(2020年9期)2020-06-01
海峡姐妹(2020年4期)2020-05-30
意林绘阅读(2019年12期)2019-12-30
作文大王·笑话大王(2019年3期)2019-04-22
百花洲(2018年1期)2018-02-07
瞭望东方周刊(2017年45期)2017-12-08
故事作文·低年级(2017年7期)2017-07-20
浙江人大(2014年6期)2014-03-20
