
基于改进Cycle-GAN的光流无监督估计方法
2022-08-05 02:27:28刘晓晨
导航定位与授时 2022年4期
刘晓晨,张 涛
(1. 东南大学仪器科学与工程学院,南京 210096;2.东南大学微惯性仪表与先进导航技术教育部重点实验室,南京 210096)
0 引言
光流作为一种描述物体运动的方法,受启发于自然界。蜜蜂等昆虫的导航与着陆等行为均依赖于其复眼中的光流。光流估计是计算机视觉研究中一项基础且重要的任务,用于获得连续两帧图像中对应物体的像素级别的移动。光流分为稠密光流和稀疏光流。稀疏光流只对每个感兴趣点周围小窗口内的局部信息进行光流求解,得到的光流数量远小于图像尺寸。而稠密光流则对图像上每一个像素点进行一次光流解算,得到的光流数量等于图像尺寸。因此,稠密光流包含了更多的信息,相较于稀疏光流有更好的适用性。目前,光流在导航、运动检测和目标跟踪等任务中拥有广泛的应用场景。经典的光流估计方法大多通过最小化以亮度恒定和空间平滑假设为代表的能量函数来求解目标光流,如1981年B.Horn和B.G.Schunck提出的HS光流算法和B.D.Lucas和T.Kanade提出的LK光流算法。随着这两种光流算法的出现,同时面向无人机和无人车等设备的自主导航需求,越来越多的学者开始利用光流求解导航参数。唐大全等利用ORB(Oriented FAST and Rotated BRIEF)优化LK光流算法,提升了无人机速度估计的精度。Yang J.等通过最小化一个包含分段常数模型假设和光流场连续性约束假设的全新能量函数,获得了在复杂运动背景下的物体光流信息。闫宝龙等利用模糊核均值算法对金字塔LK算法得到的稀疏光流进行聚类,减少由于光照变化等不利条件对光流野值造成的影响,提升了载体速度的估计精度。虽然在很长的一段时间内,以HS和LK光流算法为代表的经典变分方法成为求解光流的主流方法,但其针对大位移、运动遮挡与光照变化等条件下的光流解算精度还需进一步提高;同时,由于存在大量的迭代计算,导致变分模型法实时性较差,进而限制了该方法的应用。
随着高性能图像处理单元(Graphics Proces-sing Unit,GPU)的快速发展,为基于深度学习的光流估计方法提供了硬件基础。Flownet开创了利用有监督卷积神经网络(Convolutional Neural Networks,CNN)估计光流的先河,启发了越来越多的研究者开展基于深度学习光流估计方法的研究。作为里程碑式的工作,Flownet2.0针对Flownet光流估计精度不高等问题,利用网络堆叠实现了更加复杂的结构,将基于深度学习法的光流估计精度提升到了和经典变分法一致的水准,但也导致网络的实时性较差。A.Ranjan等将空间金字塔模型和深度学习模型相结合,提出了一个名为Spynet的精简化网络,实现了光流由粗到精的估计。Zhai M.等利用空间金字塔中的两种注意力模块,自适应地对网络中的通道和空间特征进行加权,提高了光流的估计精度。虽然目前利用有监督学习估计的光流精度已超过变分方法,实时性也较变分方法有所提高,但大多数基于深度学习的光流估计方法都需要对应的逐像素的光流真值参与模型的训练,而光流真值的获取工作异常繁琐,因此合成数据集成为训练网络所需样本的主要来源。由于合成数据集与真实应用环境存在差异,利用合成数据集训练出来的网络在真实环境中的表现并不太理想。因此,无监督学习的方法成为了光流估计领域的热点。
基于无监督学习的光流估计方法大多采用新的损失函数来指导网络实现无监督训练。J.J.Yu等受经典变分理论的启发,在损失函数中引入亮度恒定和运动平滑项,使光流估计网络实现了无监督的训练。Yang B.等基于前后向一致性检验和鲁棒Census变换,设计了一个全新的损失函数,实现了光流的无监督估计。Liu P.等基于知识蒸馏技术,提出了一种无监督方案,利用教师网络指导学生网络学习光流估计。虽然无监督学习方案无需光流真值参加网络的训练,且在某些特定场景中的性能可以超过有监督学习(如简单运动场景),但在稍微复杂环境或运动中无监督方法的精度仍然不足。同时,仅仅利用改进的损失函数对网络进行指导,对光流估计精度的提升是有限的,因此,一些研究人员将重点放在了生成对抗网络(Ge-nerative Adversarial Networks,GAN)上。
在零和博弈思想的启发下,GAN最初由I.Good-fellow于2014年提出,由生成器和判别器之间的对抗性训练来实现。GAN在图像生成、风格转化和超分辨率生成等计算机视觉领域有着巨大的潜力。为了进一步提高光流估计的精度,一些工作从GAN中借鉴对抗机制以取代无监督方法中的损失函数,取得了具有竞争意义的成果。R.K.Thakur等提出了一种基于条件生成对抗网络的场景光流估计方案,该方案可以从立体图像中获取场景光流。为了降低无监督方法中亮度恒定和空间平滑性先验的局限性,文献[18]采用对抗损失和GAN结构代替先验假设估计光流。在此基础上,Che T.等在GAN中嵌入一个倒置网络,用于获得对称光流,进而提升光流估计的准确性。尽管其中一些方法是半监督方法,但这些方法同样需要光流真值来更新判别器,这依旧依赖于带有真值的光流数据集。同时GAN的训练不稳定,容易陷入模式崩塌(Mode Collapse),导致训练失败。
为充分发挥GAN在光流估计中的优点,并克服上述不足,本文提出了一种基于循环生成对抗网络(Cycle-GAN)的无监督光流估计方法。首先,利用循环对抗机制,在网络训练阶段摆脱对光流真值的依赖,实现无监督训练。其次,为提升光流估计精度,提出了一种双判别器机制(Dual Discrimina-tor Mechanism,DDM),对生成器生成的光流在底层和高层特征中分别进行鉴别,迫使生成器生成更加符合光流原始分布的数据。然后,为降低Cycle-GAN陷入模式崩塌的风险,本文将Spynet作为教师网络,在Cycle-GAN训练的前期,指引其训练方向,提升训练效率。最后,改进Cycle-GAN损失函数,利用光流一致性损失来进一步提高光流估计的精度,通过轮廓一致性损失来细化前景物体轮廓的光流信息。
1 用于光流估计的改进循环生成对抗网络
1.1 改进循环生成对抗网络结构设计
GAN是一种借鉴零和博弈思想而产生的深度学习网络。GAN中最核心的两部分是生成器和判别器。生成器负责按照要求生成数据样本,以期利用生成的样本欺骗判别器。判别器则竭尽所能将生成器生成的样本和真实样本区分开。生成器和判别器以此种方式进行对抗训练,当判别器无法准确区分数据来源时,即达到纳什平衡,完成训练。
为降低网络在训练阶段对光流真值的依赖,本文利用改进Cycle-GAN进行运动物体的光流场的无监督获取。经典的Cycle-GAN在GAN的基础上,引入了额外一条对称的镜像分支,两条分支对同一任务进行循环求解,进而实现对网络的无监督训练。本文提出的改进Cycle-GAN的整体框架如图1所示。为方便网络训练,本文将两张待求解光流的RGB图片和在通道维度拼接后生成的6维张量直接作为生成器的输入。如图1所示,在Cycle-GAN中,Real_A与Real_B是无对应关系的两类图片,在本文中,Real_A为两帧共6维待求解光流图片,其包含了光流信息;Real_B为任意真实光流可视化图,主要负责为网络指明训练的方向。循环生成对抗网络由两条完全对称的分支组成,为简化说明,只对Real_A到Rec_A进行解释。首先,Real_A经过生成器生成一个二维的光流矩阵,而后经过光流可视化操作,将二维光流矩阵转化为三维图像,即Fake_B,也就是说,生成器负责由原始图向光流矩阵进行转换。而后将得到的Fake_B与Real_B同时输入到双判别器中,双判别器同时对图像来源进行判断。若来自生成器,则尽可能将其标记为0,若来自Real_B,则尽可能将其标记为1。此后,将Fake_B接着输入到生成器中,反向生成类似于Real_A的图片Rec_A,即生成器负责将图片由光流图向原始图转换。同理,在另一条支路中,Real_B也经历了两个生成器的循环转换,在此不再赘述。循环生成对抗网络的这种循环生成机制,使其具有了无监督学习的能力,不需要一一对应的样本真值,大大降低了训练样本的获取难度。
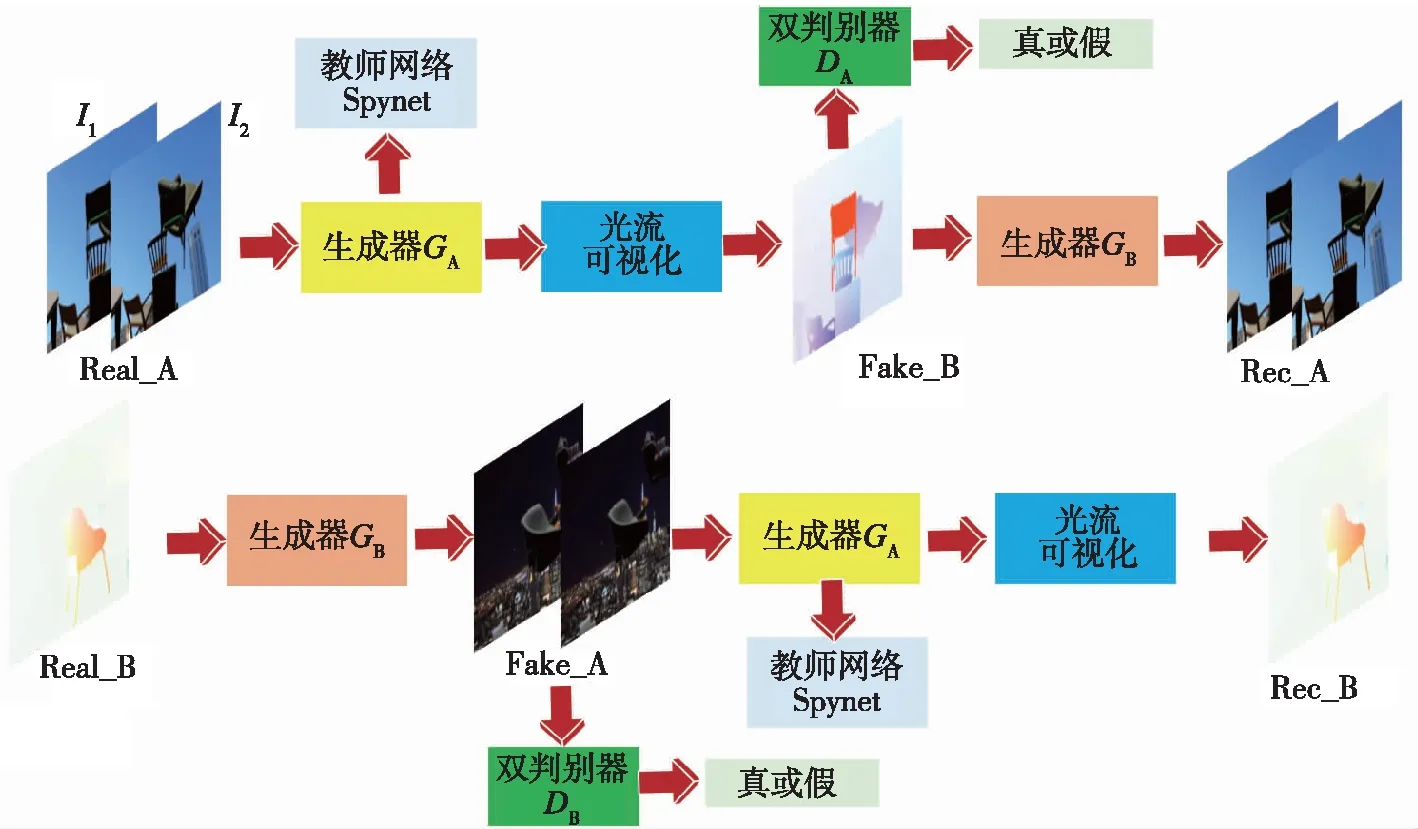
图1 本文提出的用于光流估计的改进Cycle-GANFig.1 The improved Cycle-GAN for optical flow estimation
在GAN的训练过程中,生成器极易产生单个或者有限个模式的图片,使得不同的样本输入生成器得到的输出是大致相同的,即产生了模式崩塌。为降低模式崩塌的风险,本文在Cycle-GAN的训练过程中,引入事先训练好的Spynet光流网络作为教师网络,在训练初期指引生成器快速、高效地逼近目标域,在节省训练时间的基础上,增加模型的鲁棒性,降低陷入模式崩塌的风险。具体细节将在后续介绍。
1.2 双判别器结构设计
为提升生成器生成的光流精度,本文提出了双判别器机制来迫使生成器生成更高质量的光流信息。双判别器结构如图2所示。判别器与判别器网络结构大不相同,经过3层3×3卷积后,特征被提取到256维,而后利用1层3×3卷积对图片的来源进行判断,True代表图像来源于Real_B,False则代表图像来源于生成器生成的样本Fake_B。判别器结构较为简单,所提取的特征维度较低,只能感受到底层特征,因此被用来针对图片的轮廓、线条以及颜色等底层特征进行图像判别。相反,在判别器中,经过4层卷积后,特征被提取到了512维,而后经过6层残差连接模块进行特征的进一步提取与抽象,最后经过1层3×3卷积输出一个判别结果。判别器结构较为复杂,能提取图像中的高层特征,因此被用来针对图像的语义特征进行鉴别。综上,在网络的训练过程中,将生成器经图像可视化得到的Fake_B和Real_B输入给双判别器,双判别器中的和分别从底层特征和高层特征对图像来源进行鉴别,如图像来源于Real_B,则需要和同时输出为True,否则为False。
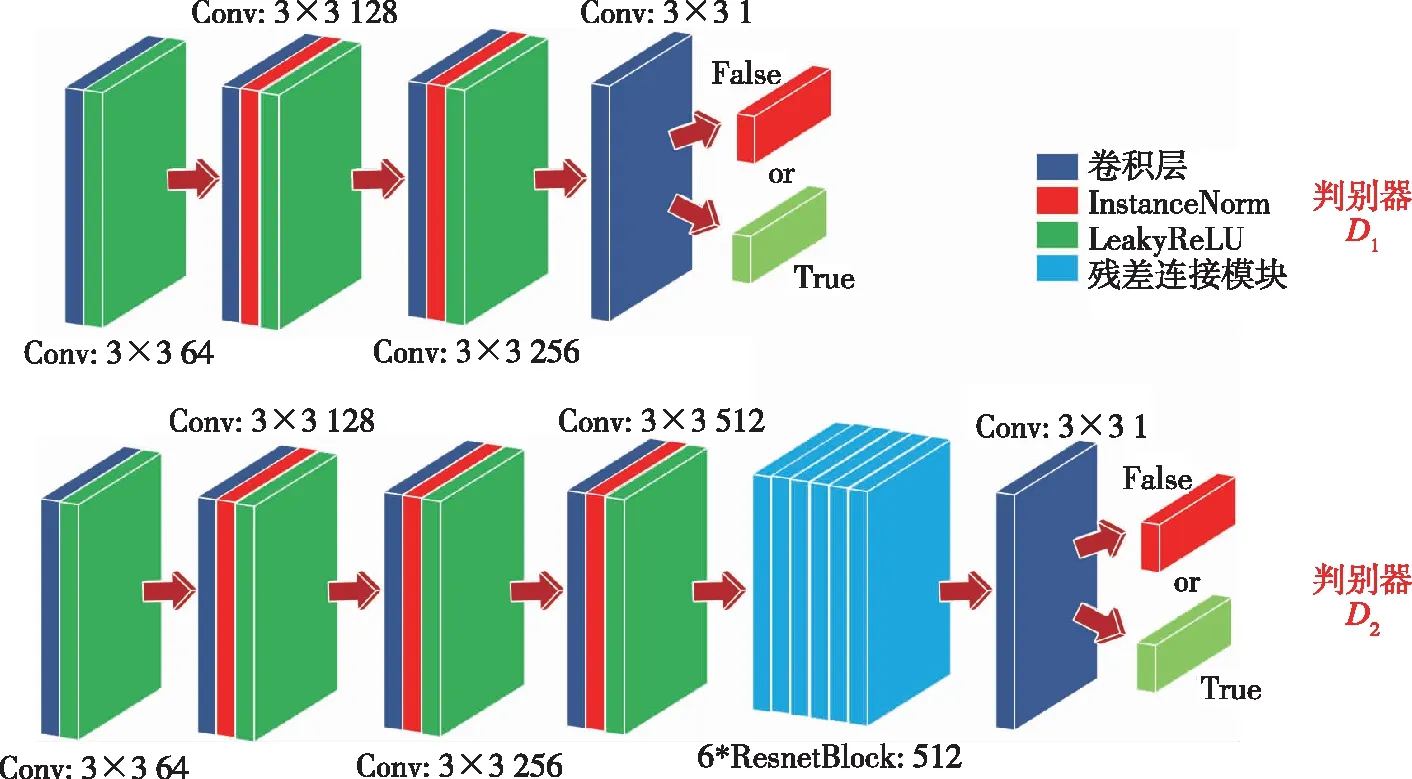
图2 本文提出的双判别器机制Fig.2 The proposed dual discriminator mechanism
为提升双判别器中对高层语义特征的判别能力,本文设计了一个残差连接模块,如图3所示。输入-1被分为2路,分支1为跳跃连接;分支2经过3×3卷积、归一化和ReLU激活函数激活后,输入到1个3×3卷积与归一化层组成的模块中,而后与分支1中的原始输入-1相加,作为最终的输出。采用残差模块的作用在于可以增加网络深度的同时,使得网络参数可以有效地进行传播,进而减少梯度消失的风险。
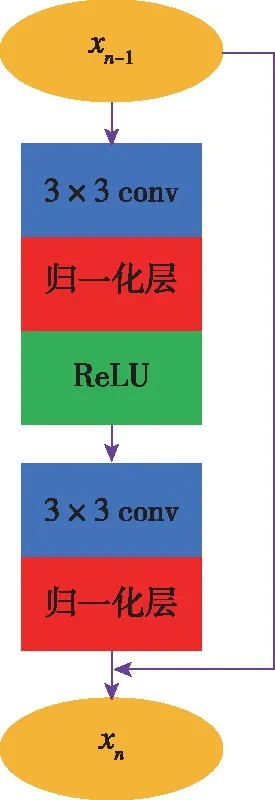
图3 残差连接模块Fig.3 The structure of Resnet-Block
2 损失函数
如前所述,Rec_A是由Real_A经生成器和生成的,而Fake_B为所需光流图,为保证Fake_B在语义上的正确性,需保证Rec_A与Real_A尽可能地相似,以和表示Real_A和Real_B,则有循环一致性损失如下

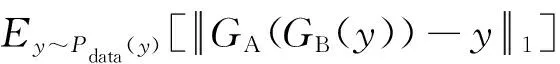
(1)
其中,代表数据的期望值,本文提出的双判别器机制中,包含两组4个判别器(,和,),以,为例,循环生成对抗网络对抗损失函数如下
(,,,,)=~()[log()+
log()]+~()[log(1-(()))+
log(1-(()))]
(2)
从对抗损失中可以看出,双判别器致力于最大化该损失,即将生成器生成的虚假图像与真实图像尽可能地分辨出来。而生成器则通过最小化对抗损失函数,以达到蒙骗判别器的目的。
图4所示为用于表示光流大小与方向的色轮图。该色轮基于HIS(Hue-Intensity-Saturation)颜色空间,沿切向旋转时,代表了光流不同的方向;从色轮圆心沿径向向外饱和度增加,则代表了光流的大小逐渐增加。因此,可以根据色轮一一确定光流图中的运动方向与大小。光流的可视化转换是以为基础,将中物体的运动利用HIS颜色空间展现出来。基于此,本文结合光流的定义,引入光流一致性损失,具体定义如下
=((+,+)-(,))
(3)
其中,和代表网络计算出的水平和垂直方向光流;和代表待求解光流的两幅原始图像;和分别为对应图片中的坐标;()=(+0001)为Charbonnier惩罚函数,本文取05。光流的定义即为到中对应像素的移动,因此,可通过光流一致性损失来优化光流的求取精度。

图4 光流色轮图Fig.4 The color wheel for optical flow estimation
其次,光流图中的物体轮廓信息是基于中运动物体的位置生成的,因此,引入轮廓一致性损失函数来优化生成的光流图中的物体相较于中对应物体的轮廓细节。具体如下
=((()))-()
(4)
其中,代表对整幅图进行二值轮廓提取操作;代表对光流进行可视化操作。
然后,本文引入Spynet作为教师网络,对生成器生成的光流进行指导。由于本文中的教师网络只负责对Cycle-GAN前期的训练指明方向,后续通过对抗机制不断优化自身精度,因此无需追求高精度网络作为教师网络。Spynet作为一种简单的光流估计网络,参数量少,可以降低对设备的计算需求,比较适合作为本文提出的网络的教师网络。深度学习的训练需要大量样本数据,大量训练数据的引入也导致了网络训练的速度变慢,教师网络的引入可以降低循环生成对抗网络对训练样本的依赖,提升训练速度,同时也可减少网络陷入模式崩塌的风险。本文采用端点误差(Endpoint Error,EPE)损失作为教师网络的损失。
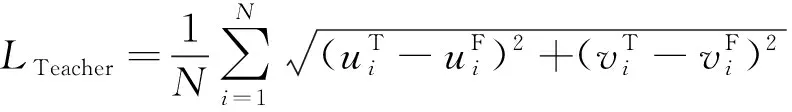
(5)
最终,本文提出的优化之后的Cycle-GAN损失函数如下。
=
++++
(6)
其中,~表示权重系数。
3 实验验证
Flyingchairs作为一款合成数据集,拥有22872组光流原始图片和其对应的真值数据,是基于深度学习估计光流的重要数据集。为减轻新样本采集压力,本文采用该数据集对提出的改进Cycle-GAN进行训练。同时,本文选取随机的22000组光流原始图像和随机的10000组光流真值作为训练样本,以此种方式打乱光流原始图像和真值的对应关系,从而验证网络的无监督训练方式。特别地,详细的训练设备及参数信息如下:在训练设备方面,本文采用的服务器CPU为2块英特尔至强E5-2698 V4,GPU为2块Nvidia RTX3090,显存为24GB*2,整机内存为128GB,存储为1TB SSD+4TB HDD;在训练参数方面,共训练1000个epoch,其中,前500个epoch为学习率固定,且大小为0.0002,后500个epoch学习率从0.0002不断衰减,直到第1000个epoch时学习率衰减为0。损失函数中的权重为=4。同时,教师网络Spynet在前200个epoch起作用,且=2,在后800个epoch中=0,在上述配置中训练1个epoch时间大约为610s,batch size设为4,采用的深度学习框架为Pytorch。
3.1 光流算法比较实验
在上述参数下完成训练后,为验证所提光流网络的精度,本节引入额外五种SOTA(state-of-the-art)光流算法作为对比,其详细信息如表1所示。利用Flyingchairs数据集、Sintel数据集以及KITTI-2012数据集进行测试。其中,Flyingch-airs数据集将椅子模型和真实场景进行结合,利用仿射变换得到椅子之间的光流真值,该数据集包含22232个用于训练的图片对和640个用于测试的图片对。MPI Sintel数据集分为Clean和Final两个版本,来源于一个全部开源的3D动画电影,分别提供1041对训练图像和552对测试图像。Clean版本包含的是只有光照变换的图像,而Final版本则在Clean的基础上添加了运动模糊和噪声,因此,相对于Clean版本,Final版本更能验证模型的鲁棒性,这也是本文选择Final版本作为测试集的主要原因。不同于前面2个合成数据集,KITTI-2012来源于真实世界,通过车载激光雷达获取真实环境下的光流真值。该数据集的光流真值并不是逐像素的,而是通过采样得到的半稠密光流。同时,该数据集体量也较小,只包含194对光流帧。在不同数据集下得到的光流可视化结果如图5~图7所示。

表1 用于对比的光流算法

图5 Flyingchairs数据集下的光流可视化对比图Fig.5 Comparison of optical flow visualization on Flyingchairs dataset

图6 Sintel-Final数据集下的光流可视化对比图Fig.6 Comparison of optical flow visualization on Sintel-Final dataset

图7 KITTI-2012数据集下的光流可视化对比图Fig.7 Comparison of optical flow visualization on KITTI-2012 dataset
从图5可以看出,DDFlow作为一种无监督光流估计方法,其精度是弱于有监督方法的,具体表现在椅子靠背处的光流细节信息明显产生了丢失现象。Spynet虽然在椅子靠背处细节信息有所保留,但图片中间有一部分光流估计错误,导致可视化图中的颜色与真值中相差较大。PWCnet和LiteFlownet3虽然精度弱于Flownet2.0,但其网络参数明显少于Flownet2.0,因此其精度也具有一定的竞争性。本文提出的方法由于引入了对抗机制和双判别器机制,使得光流估计较为准确,同时由于损失函数的改进,使得细节信息保留得较为完好,与GT真值的差异最小。
从图6所示的Sintel-Final数据集上的光流可视化对比结果中可以看到,相较于其他方法,本文的网络有着更好的细节表现,具体可从人物的头发纹理和左上角的木板细节中体现,这要归功于双判别器机制与改进的损失函数带来的增益。在与教师网络Spynet的对比中可以看出,所提出的网络的结果已大幅优于教师网络,这说明生成器与判别器的对抗机制为光流估计精度的提升提供了前提。同样的结论也可从KITTI-2012数据集中得出,如图7所示,本文方法得到的前景光流更为突出,细节较为平滑,且光流方向与大小的精度也较高。为量化对比结果,本文利用EPE作为量化指标(EPE数值越小,算法精度越高),对以上几种算法进行量化对比。与式(5)类似,EPE计算方法如下。
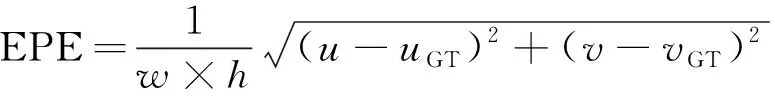
(7)
其中,和分别代表图像的长和高;和分别代表求解出的水平和垂直方向上的光流;和则分别代表水平和垂直方向上的光流真值。所得几种对比算法的EPE如表2所示。

表2 几种算法在不同数据集上的EPE
3.2 消融实验
为验证本文提出的光流估计方法改进之处的有效性,本节开展了消融实验。实验内容分为以下四部分,原始Cycle-GAN(Original Cycle-GAN,OCG)、添加教师网络的Cycle-GAN(Cycle-GAN with Teacher network,CG-T)、添加教师网络和改进损失函数的Cycle-GAN(Cycle-GAN with Teacher network and improved Loss function,CG-T-L),以及在CG-T-L基础上添加双判别器机制的本文算法(Ours)。需要特别说明的是,由于教师网络仅用于在初期为本文的Cycle-GAN光流估计网络提供大致的训练方向,因此对其精度要求不高,本文使用的Spynet未针对任何特定数据集进行微调与优化,使用权重为在通用数据集上训练完成的原始权重。消融实验结果如图8所示。

图8 消融对比实验结果Fig.8 Ablation comparison experiment results
从图8可以看出,由于光流估计的复杂性,原始Cycle-GAN没有很好地找到合适的映射关系,产生了模式崩塌现象,即无论每次输入的图片是否一样,均产生图6中类似马赛克一样的结果,无法分辨前景和背景光流信息,导致光流解算失败。当引入教师网络Spynet之后,在训练初期对原始Cycle-GAN进行引导,此时虽然光流解算误差较大,但已能大致区分前景和背景信息,说明教师网络的引入有利于降低原始Cycle-GAN陷入模式崩塌的风险。然而,由于原始Cycle-GAN未对光流估计任务进行任何优化与改进,使得光流求解精度较低,误差较大。当在CG-T的基础上引入本文所提的改进损失函数之后,光流估计精度进一步提升,在图8中具体表现为,前景物体光流估计轮廓较为清晰,方向和大小较为准确,背景光流估计精度与CG-T相比也有一定的提升,说明损失函数的介入使得网络更好地拟合了输入图片与输出光流之间的映射关系。但由于没有对网络结构进行优化,光流估计精度的提升有限,因此,CG-T-L的精度最终低于教师网络Spynet的精度。当在CG-T-L的基础上引入双判别器机制后,光流估计精度进一步提升。在可视化图中可以清晰地看出,所提出的方法精度已超过教师网络,这是由于双判别器机制在底层和高层水平特征上对生成器生成的数据进行鉴别,并迫使生成器提升自身的拟合精度。同时,由于对抗机制的引入,也使得生成器与双判别器在不断迭代更新中逐渐变强,最终实现优于教师网络的光流估计精度。同样地,为量化消融实验对比结果,表3给出了几种对比算法的EPE。

表3 消融实验EPE
4 结论
本文基于循环生成对抗网络,提出了一种以无监督方式训练的光流估计网络。该方法在充分利用Cycle-GAN对抗机制的同时,对判别器与损失函数进行改进,使得光流估计精度大幅提升。同时,通过引入Spynet作为教师网络,降低了模型陷入模式崩塌的风险。但本文提出的方法还有继续优化的空间,例如,降低网络参数以实现更高的实时性能,以及利用优化之后的生成器以期实现更高的光流估计精度,都是未来工作面临的技术挑战与研究方向。
猜你喜欢
导航定位学报(2022年5期)2022-10-13 08:35:28
江西教育·职教版(2022年9期)2022-04-29 00:44:03
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
今日农业(2019年15期)2019-01-03 12:11:33
电光与控制(2018年10期)2018-10-13 08:19:00
电子制作(2017年1期)2017-05-17 03:54:35
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
智能系统学报(2015年5期)2015-12-03 05:18:20
浙江大学学报(工学版)(2015年2期)2015-05-30 07:05:04
中国铁道科学(2014年6期)2014-06-21 06:35:32
