
一种多尺度光流预测与融合的实时视频插帧方法
2021-12-08 07:05:04马境远王川铭
小型微型计算机系统 2021年12期
马境远,王川铭
1(北邮感知技术研究院(江苏)有限公司,江苏 无锡 214115) 2(北京邮电大学 智能通信软件与多媒体北京市实验室,北京100876) E-mail:2219063829@qq.com
1 引 言
随着生活水平的提升,人们对于视频的观看质量要求越来越高.普通摄像设备拍摄的视频帧速率有限,从而影响观众的特殊观感体验.因此,在视频拍摄后对其进行适当的后处理,也成了视频制作中十分重要的一环,视频插帧就是其中关键技术.视频插帧[1-9]目标是通过两个连续的输入视频帧数据,用以合成其中间帧的数据.视频插帧能够有效地提高视频播放的帧率,保证视频中目标运动的连续性,减少用户观看时的卡顿感,提升用户的观看体验,因此被广泛应用于影视作品、体育比赛视频精彩片段的慢动作回放[1]等方面.视频插帧对帧率的改变也使得其能够被用于视频压缩传输等任务中.此外,具有产生新图像的特性也使得它能够在视频内容编辑、多视角视频合成等方面发挥作用.
如图1所示,传统的基于光流的视频插帧方法[2,9]主要由以下两个步骤组成:光流估计和中间帧合成.光流估计是指对两个连续视频帧图像(I0、I1),分别估计它们与待生成中间帧的光流信息(Ft→0、Ft→1).中间帧合成指的是通过估计得到的光流信息,对视频帧图像对进行映射变换,得到最后的中间帧(It).其中,光流估计的效果对插帧结果有着关键的影响.但是,视频插帧任务中光流估计十分具有挑战性,与一般的光流估计任务存在本质上的不同.一般的光流估计方法能够获得需要估计光流的两张图像,但是在视频插帧任务中,需要被估计光流的图像数据是不完整的,即其中一张图像是要生成的目标图像,因此只能利用可获得的连续两幅视频帧图像.
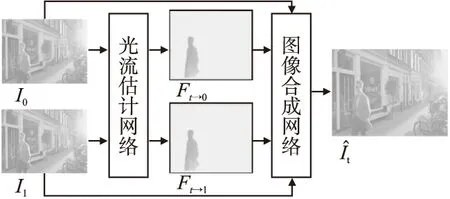
图1 基于光流的视频插帧方法Fig.1 Optical flow-based video interpolation method
为解决视频插帧任务中光流估计难的问题,人们提出了一系列方法.这些方法围绕着如何更准确地预测光流信息和如何更充分利用光流信息两方面进行研究,但是它们往往需要两次光流估计,严重降低了深度神经网络模型的运行效率,使得这些插帧方法很难应用于实时视频分析任务中.
针对如何利用光流信息进行实时视频插帧的难点问题,本文遵循当前的视频插帧框架,提出一种基于多尺度光流预测与融合的实时视频插帧方法.本文的方法由光流预测和中间帧合成两部分组成,首先采用不损失信息的下采样方法对图像进行多规模的下采样,获得不同尺度的图像数据;之后通过带有注意力机制的特征提取网络来提取视频帧对的特征,并根据该特征得到预测光流信息.因为输入图像是多尺度的,所以获得的光流信息也具有不同的尺度信息,本文采用了一个光流融合网络将这些多尺度的光流信息进行融合得到最后的结果用于图像合成.
在大规模视频插帧基准数据集上,对所提方法进行了训练和测试,实验结果表明本文的方法能够实时地生成高质量的视频插帧效果.同时将所提方法与当前的经典方法进行了实验对比,比较结果展示本文方法的优越性.
2 相关工作
视频插帧任务,由于其广泛的应用性,一直是计算机视觉与多媒体技术领域研究的热点问题.传统的视频插帧方法往往都伴随着视频编码策略的设计,目的也是为了优化传输的效率.而近年来,随着深度学习的日益发展,深度神经网络因其强大的特征提取能力,在诸多视觉任务上取得了很大突破.因此,现阶段有一系列的方法期望通过深度学习技术来完成视频插帧任务.
Liu[1]等受到自编码器的启发,设计了一种基于神经网络编码器-解码器的模型去学习体素流,从而合成插帧图像.但是对不同尺度的体素间关系的忽略导致了其不能较好处理不同体素移动速度不一致的问题.Jiang[2]等提出了一种双向光流估计方法,通过神经网络梯度输入图像对之间的光流,再结合这种双向光流,得到输入图像与待合成图像的光流信息.但是,这种迭代估计的方法导致了光流估计的速度较慢,使得无法应用于实时视频任务中.Bao[3]等除了光流信息,还设计了一个深度估计网络来促进光流估计的结果.这种多信息融合的特性使得其估计得到的光流结果更加精确,从而合成更加高质量的中间帧.但是,引入了深度估计模型同样导致了该方法计算量的增加,从而降低了方法的运行速度.除了深度信息,Bao[4]等还提出了一个利用运动估计信息的视频插帧方法,通过设计的运动估计和运动补偿神经网络,生成更具有鲁棒性的视频插帧结果,但是同样降低了方法的运行速度.
还有一部分方法探究如何更好地进行图像合成操作.Niklaus[5]等通过预训练后的光流估计模型得到光流估计,并将光流信息与图像的深度特征进行结合,一同送入到一个合成网络中,得到最后的结果.
除了基于光流的方法,还有一些方法使用深度神经网络直接生成中间帧的结果.SepConv[6]和AdapConv[7]是属于此类的两个典型方法,它们通过使用自适应卷积学习图像对之间的移动变换和融合策略.但是没有准确的移动指导信息,生成的结果缺乏了鲁棒性.CAIN[8]利用通道注意力来增强网络学习能力,实现端到端的视频插帧.
3 多尺度光流预测与融合方法
光流估计的效果对于视频插帧的质量有着重大的影响,为了提升视频插帧的性能,本文提出了一种多尺度光流预测与融合方法.整体框架如图2所示,包括图像下采样、卷积操作、特征拼接、光流预测、光流融合等模块.对于输入的一对连续视频帧,首先进行下采样.不同阶段的下采样的尺度是不同的,图像中使用Sk来进行表示.在下采样之后,通过一个简单的卷积模块独立地提取两张图像特征,再将两组特征沿通道维度进行拼接.拼接得到的结果送入光流预测网络中,得到当前尺度图像的光流估计结果.对于该结果,一方面被用于将图像进行映射变换,从而送入下一阶段的模型,另一方面,与下一阶段预测的光流进行融合,得到更细化的光流结果.本节详细介绍下采样方法、提取与光流预测方法和多尺度光流融合.
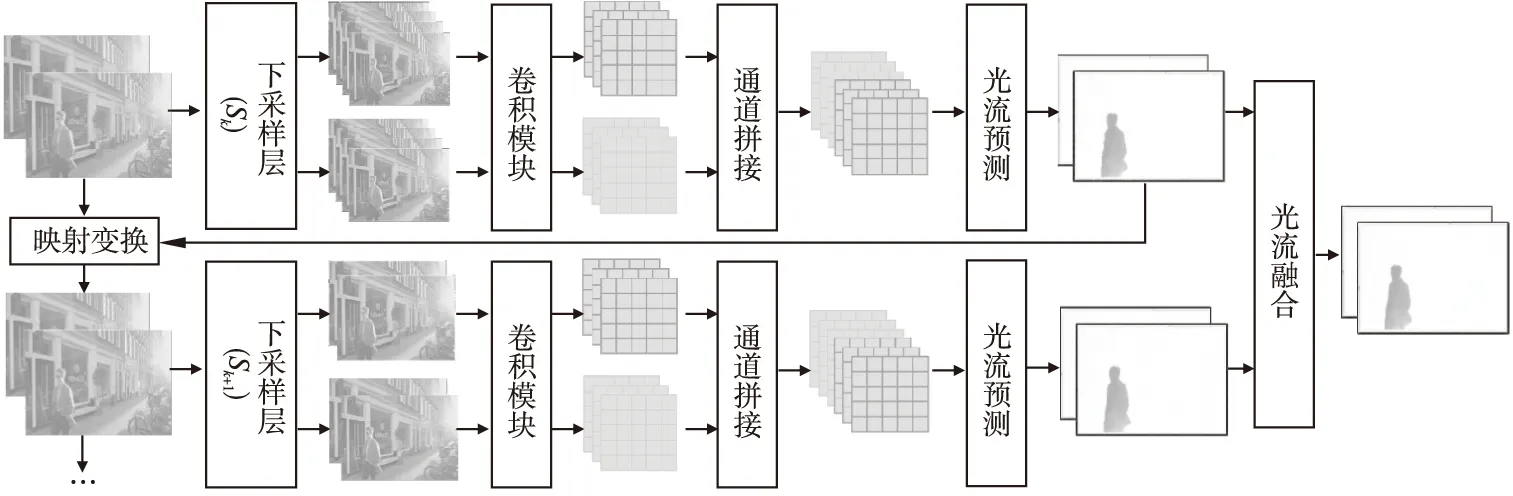
图2 多尺度光流预测与融合框架Fig.2 Framework of multi-scale optical flow prediction and fusion
3.1 信息无损的下采样方法
运动距离小的像素在小尺度的图像中更易被忽略,而运动距离大的像素在小尺度的图像中仍能被观察到.基于这样一种观察,多尺度学习常被应用于视频插帧任务中.图像常被下采样为不同的尺度,从而学习不同尺度下的光流信息.但是现阶段方法,对于图像的多尺度变化,通常采用的是图像插值,导致了信息上的丢失.因此本文设计一种信息无损的多尺度下采样方法.
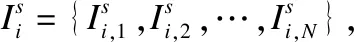
图3分别展示了基于插值的下采样方法和本文使用的下采样方法.对于基于插值的方法,下采样只能产生一张图像,而本文的方法会产生多张图像,这些图像是原始图像的一种互补的分割表示,包含了原始图像的全部信息.

图3 不同下采样方法的比较Fig.3 Comparison of different down-sampling methods
基于插值的下采样方法势必会导致部分信息的丢失.而本文采用的下采样方法是将空间信息压缩到通道维度上,因此没有信息的损失,同时,这些子图在细节上的不同也使得网络能够学习更加鲁棒的光流信息.
3.2 基于注意力的特征提取与光流预测
对于3.2节中得到的输入数据,本文先通过一个简单的卷积神经网络,对两张图像分别提取特征.该卷积神经网络由两层组成,每层都包含一个卷积层和PReLU[10]层.之后将两个图像对应的特征沿通道维度进行拼接,得到光流预测模块的输入.
如图4所示,光流预测网络由多个残差模块和一个转置卷积组成.其中残差模块由顺序排列的卷积模块和注意力模块组成.卷积模块与之前图像特征提取网络相同,都是由卷积核是3的卷积与PReLU层组成.而注意力模块是由卷积核是1的卷积操作和通道注意力结合而成,其数学表达式为:
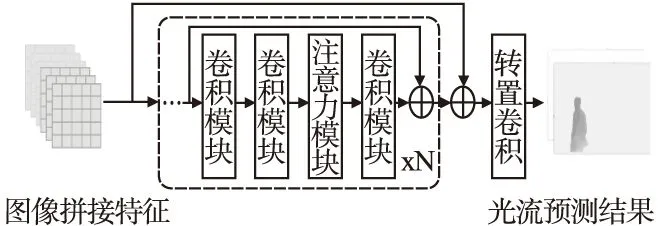
图4 光流预测网络结构Fig.4 Network of optical flow prediction
X′=C(X*π(F(θ(F(X)))))
(1)
其中X为特征,C是卷积核大小为1的卷积,θ是ReLU[11]函数,π是Sigmoid函数,F是线性层,*表示按元素相乘.与SENet[12]保持一致,本文也在FC中使用了缩减系数a来降低维度数.在具体实现中,每个阶段的卷积通道数目、缩减系数都有所不同,在实验部分将详细介绍这些参数.最后,本文使用了一个卷积核为4,间隔为2的转置卷积输出预测的光流信息.因此,特征提取与光流预测的整体结构参数如表1所示.
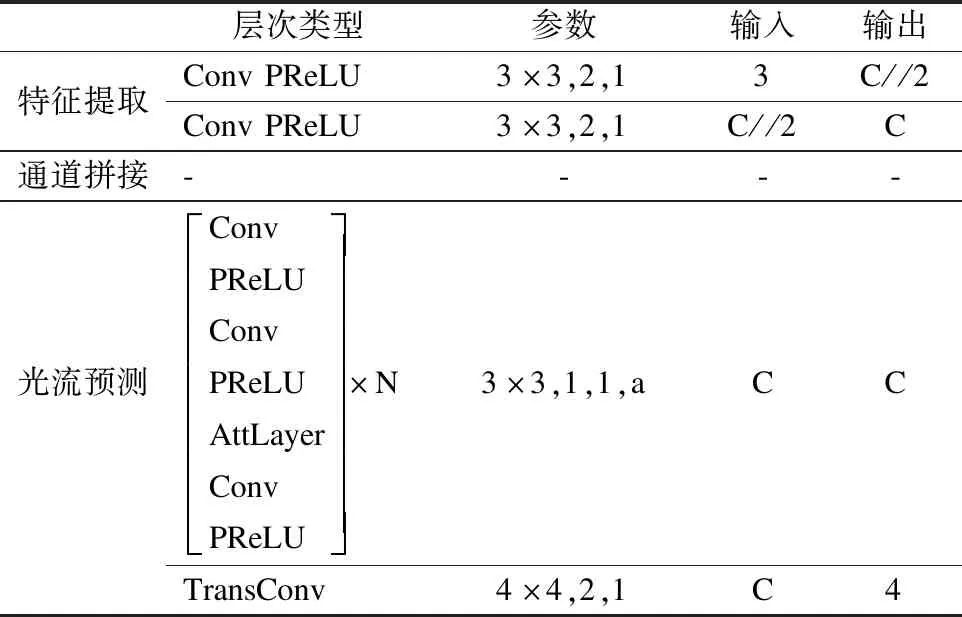
表1 光流预测网络结构Table 1 Network of optical prediction
3.3 多尺度光流的融合网络
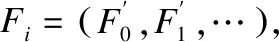
Fi=D(∏j,U(F′j))
(2)
其中,U表示上采样操作,将所有光流上采样到固定的尺度.∏表示沿通道维度将上采样后的光流进行拼接.D表示可变形卷积操作,其卷积核为3,间隔为1,填充为1.与传统卷积相比,可变形卷积对每个通道都自适应地学习一个偏移量,通过该偏移量,可以捕获不同尺度光流中更加相关性的部分,从而生成更加鲁棒性的输出信息.同时,可以看出,阶段i的光流输出,是对之前所有阶段输出光流的一个融合.
4 实 验
4.1 实验环境设置
4.1.1 训练数据
本文在Vimeo90K-Triplet[14]数据集上进行模型的训练和测试.Vimeo90K-Triplet是专为视频插帧任务构建的数据集,包含73,171个3帧连续序列的数据集,所有图像分辨率都是448×256.
本文采用3帧中的第1和第3帧作为模型的输入,而第2帧作为模型的真值.在训练阶段,随机从原图中裁剪224×224大小的图像作为输入,同时带用了随机水平翻转、随机垂直翻转、随机通道打乱、随机时序翻转等数据增强方法.而在测试阶段,保持图像的原始大小,不做数据增强.
此外,为了训练模型对光流信息的预测的准确性,本文采用ListFlowNet[15]预先在数据集上生成所有的光流信息,作为模型训练时的监督信息.
如图5所示,一个训练样本数据包含了3张连续的图像I0,It,I1,以及光流图Ft->0,Ft->1.为了更好地展示视频帧之间的区别,本文将I0,I1结合,可以看到其差异性.

图5 训练数据可视化展示Fig.5 Visualization of training data
4.1.2 模型参数
对于光流估计模型,本文将阶段数目设置为3,每个阶段的光流预测网络中残差模块数目为2,通道数分别是240,128和96.此外,下采样层的尺度分别是4,2和1.对于注意力模块,本文统一将下采样系数设置为16.本文主要是提出了一种光流预测模型,因此,直接采用RIFE[9]方法中提出的上下文内容提取与融合网络作为图像合成模型.此外,图2中的映射变换,本文采用了在视频插帧领域广泛采用的“后向映射”方法,该方法具体细节可以参考RIFE[9].
4.1.3 训练策略
在损失函数方面,对于光流预测结果,本文使用了在视频插帧领域广泛采用的L1范式损失作为优化函数:
(3)
其中fgt为光流真值,fpred为光流预测值.该损失将所有预测的光流都与光流真值计算损失并求和.此外,还使用了恢复损失函数:
(4)
和统计损失函数[16]对预测图像进行损失计算.最终将三者相加作为最终优化损失.
本文采用AdamW[17]作为优化器,将其衰减设置为1e-4,总共训练300轮.每一批次数据的大小是48,学习率使用余弦函数进行调节,从同一个1e-4逐渐降低到0.在测试方面,本文度量了峰值信噪比(PSNR,peak signal-to-noise ratio)和结构相似性(SSIM,structural similarity)两个被广泛使用的图像质量评价指标.在硬件配置方面,采用了TITAN XP (Pascal)GPU作为训练和测试硬件.
4.2 方法比较
本文与当前视频插帧方法进行了比较,比较的方法有:DVF[1]、Slomo[2]、DAIN[3]、MEMC[4]、SepConv[6]、CAIN[8]、RIFE[9].其中,重新实现了RIFE,以达到公平比较的目的.表2展示了比较的结果,可以看出,本文的方法在PSNR和SSIM两个方面都能取得很好的效果.
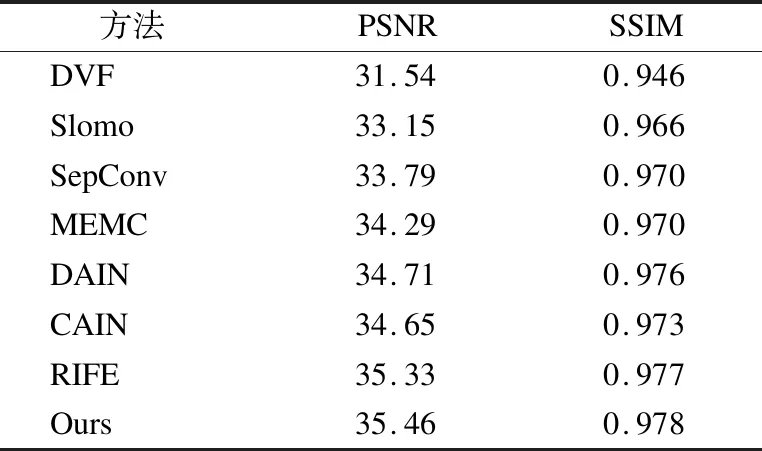
表2 不同方法的比较Table 2 Comparison with different methods
在图6中,本文可视化了光流预测和插帧的结果.共有3组图片,每一组图片上面两张分别是光流预测的结果和光流真值的可视化,而每组下面两张图像是视频插帧的结果和真值图像.可以看出,本文的方法较好地预测了光流信息,同时得到了鲁棒的插帧结果图像.
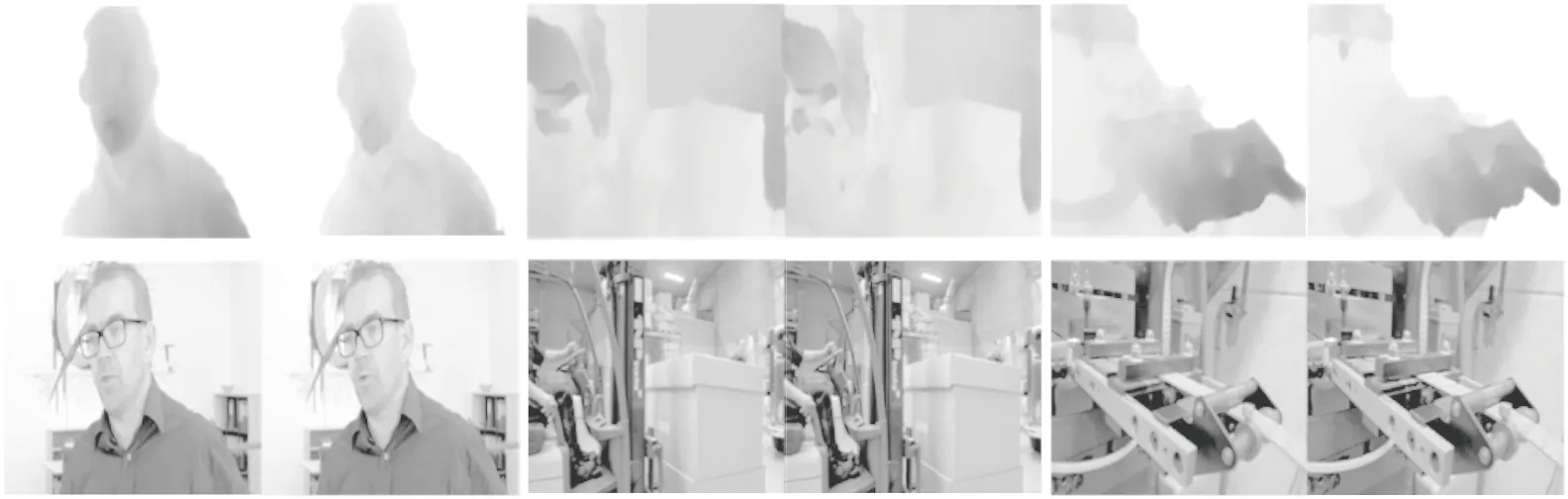
图6 光流预测结果、真值与视频插帧结果、真值的可视化Fig.6 Visualization of the prediction and ground truth for optical and video interpolation
4.3 消融实验
为了证明方法中不同模块的有效性,本文对其进行了消融实验.实验数据是基于640p的视频帧计算得到的.本文将一个带有6层卷积模块的残差网络作为BaseNet,然后依次添加下采样模块(DS,Down-Sampling),注意力模块(AM,Attention Module)和光流融合模块(FM,Fusion Module).实验结果如表3所示,可以看出,所提模块能够有效地提升模型插帧结果的性能,同时在时间开销上的增加较少,能够良好地满足算法实时性的要求.
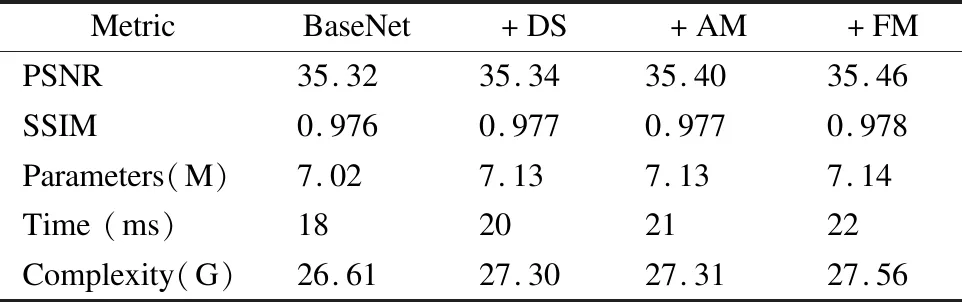
表3 不同模块对模型的影响Table 3 Effect of different components
5 结束语
视频插帧因其广泛应用性,很多学者进行了研究.但是现阶段的方法运行效率较低,实时性难以保证.本文提出了一个多尺度光流预测和融合模型,利用轻量级神经网络,充分学习视频中光流的变化,得到了较好的视频插针效果.具体地,本文采用了信息无损的下采样策略,基于注意力的特征提取和多尺度光流融合方法,达到了较好实时性和可靠性的平衡.在大规模视频插帧基准数据集上的实验也表明了方法的有效性.通过本文提出方法,视频后处理可以更好地解决视频慢动作回放问题,人们可以更清晰、生动地观看到影视作品、体育比赛精彩视频片段慢动作回放,并对其中细节进行分析利用.
猜你喜欢
导航定位学报(2022年5期)2022-10-13 08:35:28
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
电子制作(2019年11期)2019-07-04 00:34:38
电光与控制(2018年10期)2018-10-13 08:19:00
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
太空探索(2016年5期)2016-07-12 15:17:55
时代英语·高三(2014年5期)2014-08-26 17:01:17
中国铁道科学(2014年6期)2014-06-21 06:35:32
电视技术(2014年19期)2014-03-11 15:38:20
