
基于数据挖掘的银行客户流失预测
2022-08-08 02:56谢宇许红
现代营销(创富信息版) 2022年7期
谢宇 许红
(成都信息工程大学 四川成都 610103)
一、引言及文献综述
在第三次工业革命的推动下,信息时代继往开来,重塑了各行各业,其中金融业也不例外。中国人民银行、工业和信息化部、公安部等十部委联合发布《关于促进互联网金融健康发展的指导意见》,落实了互联网支付、众筹融资和互联网消费金融等业态的监管责任,明确其业务边界。互联网公司的入局,一方面争夺传统金融业的市场份额,另一方面以客户至上为核心的理念在算法和流量加持下得到长足发展。归根结底,这是对客户的争夺。很多银行总是不停地获得新用户,而对于现有客户缺少关注。而现在,金融市场用户增长放缓,拉取新用户的成本远高于维护现有客户的成本,且现有客户也有着更高的价值。更严重的是,流失的客户会壮大竞争对手的客户队伍和规模,还会导致银行的声誉受损。
针对潜在流失客户进行积极联系和营销活动,可以极大挖掘这部分用户的价值。这也是在私域流量大热下,银行日常运营应当关注的重点工作,根据客户现有特征,预测客户流失意向,有的放矢地进行召回,是提升银行运营能力的关键一步。
对于客户流失的研究,一般集中于三个方面。
首先是关于客户流失因素的探究。国外学者提出服务缺失、定价问题、便利性缺失是商业银行客户流失的主要原因。国内学者在对流失因素进行多角度分析后,建立忠诚用户分类模型,专门针对商业银行客户流失因素进行相关性分析,并指出主动交易时间间隔最为重要。
其次是对于客户流失的预测研究。客户流失问题属于分类问题,国内外学者运用逻辑回归、决策树、随机森林及神经网络等方法进行相关研究。卢美琴结合某商业银行客户流失状况,运用决策树进行客户流失预测,再采用聚类方法进行用户分类,提出挽救措施。
最后是客户的挽回策略研究。国外学者Farquhar通过与英国银行业各级职员访谈,指出客户价值、品牌价值、产品质量和管理渠道等七个要素是挽留客户的关键要素。国内学者陈明亮根据客户的当前价值和未来潜在价值进行分类,根据每类客户的特征制定召回策略。李赛结合金融互联网背景下的外部压力,提出多渠道发挥优势,差异化提供产品,提升用户体验的对策。
二、理论准备
(一)相关算法介绍
本文涉及的建模问题为机器学习中的监督学习,属于分类问题中的二分类,有较多的经典模型可以使用。本文拟采用及时性和效果均得到认可的主流分类机器学习模型,如表1所示。

表1 主要分类器
(二)分类评价指标
本文需针对客户的信息,构建分类模型以预测客户流失情况。在实际的生产情况下,流失的用户所占比例较大幅度低于留存客户,所以该问题又属于样本不平衡的分类问题。对于此类问题,除了平时常用的基于ROC(Receiver Operating Characteristic)的曲线AUC(Area Under Curve),评价指标需要顾及多个方面,尤其是要关注召回率。本文结合混淆矩阵,对准确率、召回率指标进行简单介绍。
在监督学习中,通常将关注的类看作正类,一般标注为1,其余的类为负类(标注为0),根据分类器在测试集的预测结果,将以上实际情况和预测结果进行两两组合,可以得到四种情况的数量情况,分别是:Ture Positive(TP)——正类预测为正类数;False Negative(FN)——正类预测为负类数;False Positive(FP)——负类预测为正类数;True Negative(TN)——负类预测为负类数。基于此,部分常用指标如表2所示。
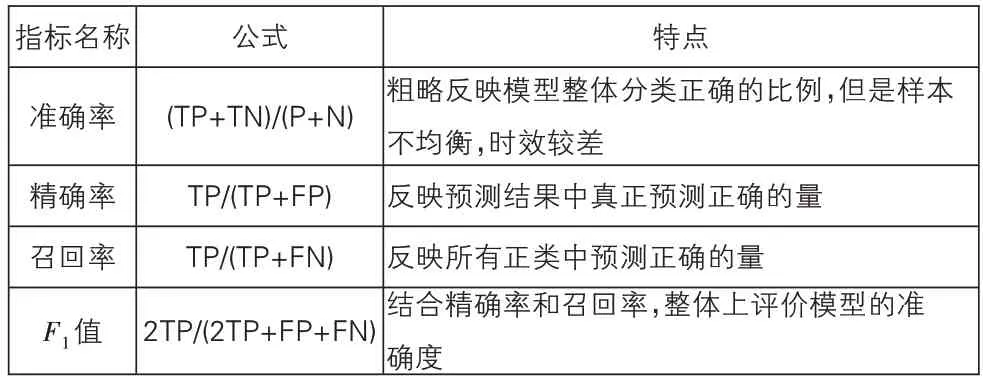
表2 常用评价指标
三、数据准备及清洗
(一)数据来源
本文所用数据来自kaggle——创建于2010年的数据科学竞赛平台。该平台通过众包的形式,由一方发布数据或者问题,平台用户提供解决方案。本文所用数据是一份银行客户流失数据,总共有10000个样本,含有年龄、地区、账户余额和购买产品数等14个特征。
(二)数据基本情况
从流失客户比例来看,在10000个样本数据中,流失客户占比为20.4%,属于一般不均衡问题。
再看部分分类特征,其柱状图如图1所示。从中可以看出,在地区上,法国人数最多,西班牙与德国人数相当。有趣的是,德国的流失客户反而最多,法国整体的运营情况良好。在性别上,男性人数高于女性,但其流失客户数略低于女性。这说明男性客户相对更为稳定,而女性用户则是需要特别维护。有信用卡用户的数量是无信用卡用户的两倍,但是流失比例在有无信用卡方面差距不大,这也是与常识略有不同的地方。活跃客户人数略高于非活跃客户,但是活跃客户流失比例低于非活跃客户。银行或考虑通过一些活动,促进非活跃客户转化为活跃客户。

图1 分类变量与流失客户柱状图
部分连续型变量与客户流失情况的箱线图如图2。从年龄来看,流失客户的年龄分布极端值较少,但是流失客户的年龄整体大于未流失客户。未流失客户的分布相较于流失客户较为集中,银行应当更加关注新获取的用户和高于平均留存年限的客户。令人担忧的是,流失客户的账户余额分布更为均匀,且数额更大,这或许是由于含有部分加入时间长的客户。而在用户的信用分数、工资或者产品数方面,客户流失与否没有太明显差异。整体来看,对流失客户的关注是有章可循的,并且会产生积极影响。

图2 连续变量与客户流失箱线图
四、模型建立
(一)特征工程
在传统的数据科学建模步骤中,特征工程是第一步,是在描述性统计的基础上对数据进行预处理,数据处理会根据变量类型采取不同方法。本次对连续变量,比如年龄、余额进行最大最小值编码,以实现不同量纲的数据去量纲化,剔除了不同特征在数值绝对值上的差异,同时提升模型在训练时的速度。而对于离散型变量,如性别、国籍等,借鉴于数字电路,运用二进制表示特征的取值。哑变量的引入使得属性数据得到很好的处理,而独热编码也会造成特征空间的膨胀,本次实践中,特征数量不多,可以直接使用,在数据维度更加丰富的情况下,可以结合主成分分析等降维手段,提升模型的拟合能力。
预处理过后的特征工程,是建模中的关键环节。在输入数据确定的情况下,通过特征工程,可以使模型的能力逼近真实情况,得到最接近实际情况的预测结果。常见的特征工程有结合业务背景的特征构造和基于数理变换的暴力构造。在数据科学的比赛中,选手为了提升精度会使用暴力构造,但该方法往往解释性弱,故在实际工作中会缺少指导意义,也就用得相对较少。
根据该问题的背景和数据,构造余额薪酬比、会籍年限年龄比和信用评分年龄比几个特征。余额薪酬比一定程度上反映客户的消费透支情况,并能反映客户的风险偏好和信用情况。会籍年限年龄比反映开通信用卡和年龄的相对关系,可以用于区分不同年龄段对卡的持有情况。信用评分年龄比,因为信用评分和客户流失没有描述性上的差异,这里创造性构造该指标,用于探究。
通过随机种子200进行抽样,以获得8∶2的训练集和测试集,以用于本地模型测试。
(二)参数调优
一般的超参数调优方法有网格搜索、随机搜索和贝叶斯优化,关于其原理此处不再赘述。本文采用应用最为广泛、性能稳定的网格搜索方法进行最优超参数的选择。具体调参结果如表3所示。

表3 主要超参数结果
从网格筛选的结果来看,树模型在训练集上的效果略优于其他模型,但是会出现过拟合的情况。因此,在求得最优参数的基础上,利用各种方法的最优模型进行测试集上的效果测试。
(三)实证结果分析
利用上一节中的结果,训练各个方法下的最优模型。各个模型在正类上的评价指标结果如表4所示。

表4 主要模型结果
由上表可知,树模型的整体表现较好。由于属于样本不均衡问题,准确率方面不会有太明显的差异。而极限提升决策树的召回率最高,实现了最大限度地预测流失客户,但是其精确率略低于支持向量机或者随机森林,这表明预测结果中有少量错误的预测。
为了纠正模型的偏差,发挥模型的优势,通过对模型结果进行软投票,以避免投票影响整体结果,最终样本量为2000的验证集精确率为0.80,召回率为0.37,F1值为0.51。模型精度尚可,有实际参考价值。
对于具体特征情况,可以参考图3的极限提升决策树特征重要性。这个特征重要性是根据特征在分类时所使用的次数得出的。从图中可以看出,账户余额和年龄是较为重要的原始特征。这两个变量在前面的描述性分析部分已体现出较为明显的差异。紧随其后的是余额薪酬比和信用评分年龄比两个构造特征,证明了根据业务背景进行特征工程的实用性。

图3 特征重要性树状图
树模型可以为我们提供特征的重要程度,即特征在分类时可以带来最大信息增益的次数,反映特征的有用性。但是,特征对于客户的流失情况起正向还是负向作用则需要借助回归模型,通过其系数的正负来判断对流失情况是积极还是消极影响。
在回归模型的系数中,信用分、账户余额薪酬比和账户余额是对客户流失有正向作用的特征。尤其是信用分高的优质客户,需要格外重视,而账户余额高的客户流失也不是好的现象,需要进一步了解主要的流失原因,采取针对措施。信用评分年龄比、是否为活跃用户和产品数量是抑制客户流失的特征,证明高信用低年龄是稳定的客户群体。活跃用户和购买产品更多的客户留存可能性更大,也是符合常识的。
五、结论与不足
综上所述,活跃用户及高信用低年龄的客户群体是银行的基本盘,需要重点监测,比如当活跃度降低,银行应当通过一些类似优惠券的活动对客户进行召回。而账户余额高的客户存在着高流失风险,这部分用户需要重点维护。客户本来有着较强的购买力,却没有挖掘出其价值,银行应当针对这部分用户进行有的放矢的营销。而对于信用分指标,高分值用户也有着较高的流失可能性,一方面需要进一步研究信用分打分体系是否符合实际情况,能否对业务进行指导,另一方面则是关注这部分用户流失的现实状况,进一步探究。
本文的目的是识别流失客户的概率并且提前采取运营措施以实现客户召回,所以对于模型的整体准确率不必过多关注。数据整体的流失概率为20%,只要精确率大于这一比率,随着该比例的增大,模型就越少浪费资源在错误的分类上。该模型已经较好地预测出流失客户并且没有过多浪费资源。
未来的工作可以收集更多数据维度,明确针对已有重点特征的召回或激活策略,并持续跟踪,持续优化。
猜你喜欢
小猕猴智力画刊(2022年9期)2022-11-04
数学小灵通(1-2年级)(2021年4期)2021-06-09
中国外汇(2019年9期)2019-07-13
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
中国设备工程(2017年5期)2017-05-11
中国设备工程(2017年7期)2017-04-10
小学生作文选刊·低年级版(2017年2期)2017-03-06
瞭望东方周刊(2016年45期)2016-12-07
