
精确增量式ε型孪生支持向量回归机
2022-07-29 10:24顾斌杰熊伟丽
控制理论与应用 2022年6期
曹 杰,顾斌杰,潘 丰,熊伟丽
(江南大学轻工过程先进控制教育部重点实验室,江苏无锡 214122)
1 引言
支持向量机(support vector machine,SVM)[1]是一种经典的分类算法,被广泛运用于文本分类[2]、图像分类[3]、自动程序验证[4]等领域.之后,SVM的思想被用于解决回归问题,即支持向量回归机(support vector regression,SVR)[5].SVR通过将样本的输出值向上和向下平移并作为特征值,再分别设置正负标签,形成两类样本,然后构造将两类样本分开的超平面,获得原始样本的回归平面,即将回归问题转化为分类问题来解决.
近年来,由SVM发展而来的一种分类算法,孪生支持向量机(twin support vector machine,TSVM)[6]兴起.与SVM不同,TSVM通过求解两个小规模的二次规划问题,构造两个非平行的超平面,把训练时间减小到SVM的四分之一,并且具有更好的泛化性能.之后,Peng基于TSVM的思想提出了孪生支持向量回归机(twin support vector regression,TSVR)[7].实验结果表明,TSVR在训练速度和泛化性能上均优于传统SVR.因此,TSVR迅速成为支持向量机领域的研究热点.例如,约简TSVR[8]通过减小核矩阵的规模,加快了训练速度;ε型TSVR(ε-twin support vector regression,ETSVR)[9]改进了目标函数并运用逐次超松弛技术加快了训练速度;ν型TSVR[10]通过引入νε项,优化ε的值,提高了模型的泛化性能;基于快速聚类的加权TSVR[11]通过入协方差矩阵和加权对角矩阵,提高了算法的抗干扰能力.
以上研究致力于目标函数或者相关离线训练算法的研究.在实际应用场景中,样本一般是在线增量提供的,如果使用离线算法训练模型,那么每次更新都需要重新训练,无法满足系统实时性的要求.而增量学习算法利用已有的训练结果,快速更新模型,能够提高系统的实时性.目前为止,在增量式SVM与SVR的研究上,学者们取得了很多研究成果.2000年,Cauwenberghs等人创新性地提出了增量式与减量式SVM[12],基于已有模型通过有限次数迭代使得新增样本满足Karush–Kuhn–Tucker(KKT)条件.之后,该方法又被扩展到解决精确增量式SVR(accurate online support vector regression,AOSVR)[13]、多增量式与减量式SVM[14]、精确增量式ν型SVR[15]等问题.并且该类算法的可行性和有限收敛性在理论上也得到了严格的证明[16].
然而,对于增量式TSVM和增量式TSVR,目前的研究还较少,主要是针对最小二乘型问题或者是使用梯度下降法进行优化.例如,改进增量式最小二乘TSVM[17]改善了低维数据情况下模型的训练速度;增量式最小二乘TSVR[18]简化了矩阵求逆运算的复杂度,提高了算法运行的效率;增量式和减量式模糊有界TSVM[19]利用具有收缩策略的对偶坐标下降法求解对偶问题,提高了模型更新的速度.
对于ETSVR模型,目前还没相应的增量学习算法,本文尝试把AOSVR的思想用于解决ETSVR的增量学习问题,提出一种精确增量式ε型孪生支持向量回归机(accurate incrementalε-twin support vector regression,AIETSVR).首先,通过提前调整拉格朗日乘子,判断可行域内异常拉格朗日乘子的目标值并在计算调整步长时进行修正,解决如下两个问题:1)目标函数中的二次损失项使得新增样本后模型的对偶问题产生较大的变化,可能出现大量原有样本的拉格朗日乘子不符合KKT条件的情况,无法获得有效的初始状态;2)可能出现异常样本的拉格朗日乘子在边界内或者在边界外的情况,当在边界内时,往两边调整都有可能无法确定方向,当在边界外时,需要判断移入各个集合步长的有效性.接着,从理论上分析了AIETSVR的可行性和有限收敛性.最后,为了验证AIETSVR算法的可行性和有限收敛性以及解的精确性和在缩短训练时间上的优势,在基准测试数据集上进行实验.
为了便于理解,下面列出本文算法描述中用到的符号表示的含义:∅表示空集;∆表示在调整过程中的变化量;det(·)表示对应方阵的行列式;0和e为相应维数元素全为0和1的列向量;I为相应维数的单位矩阵.Gij表示矩阵G的第i行第j列的元素;Gij表示删除了矩阵G第i行元素和第j列元素后的矩阵;G∗j表示矩阵G的第j列向量;Gi∗表示矩阵G的第i行向量;GS1∗表示由向量Gi∗,i ∈S1组成的矩阵;GS1S1表示由Gij,i,j ∈S1组成的矩阵.αi表示向量α的第i个元素;αS1表示由αi,i ∈S1组成的向量;αi表示删除向量α的第i个元素后的向量.S1(i)表示S1集合中第i个样本在训练集中的索引,表示更新后的M.以此类推.
2 ε型孪生支持向量回归机
对于一个给定的训练集数据T=其中:xi ∈Rm为输入,yi ∈R为输出,n为训练集样本的个数,m为每个样本的特征数,则样本矩阵和输出矩阵可以分别表示为A=[x1x2···xn]T∈Rn×m和Y=[y1y2··· yn]T∈Rn.
不同于传统支持向量回归机,ε型孪生支持向量回归机减小了二次规划问题的规模,通过寻找下界回归函数和上界回归函数+b2,其中w1,w2∈Rm为权重向量,b1,b2∈R为偏置,构造两个非平行的超平面.其原始问题可以表示为如下约束最优化问题[9]:
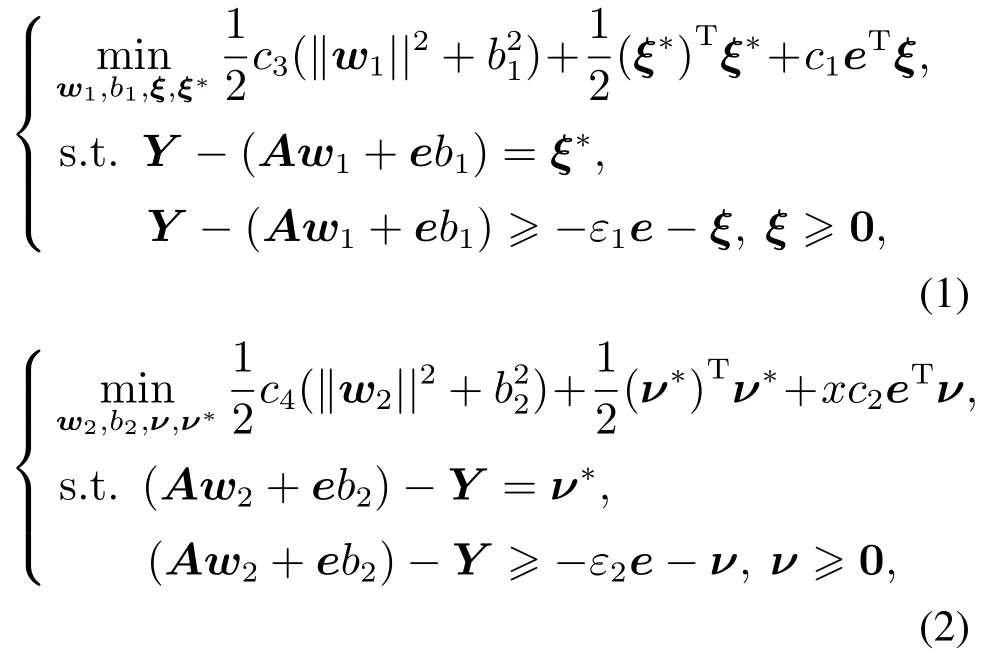
其中:c1,c2>0为惩罚参数,c3,c4>0为正则化参数,ε1,ε2>0为不敏感因子,ξ,ξ∗,ν,ν∗∈Rn为松弛向量.
令G=[e A],则可得式(1)和式(2)的对偶问题如下:
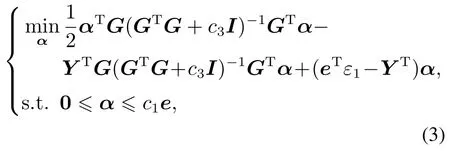
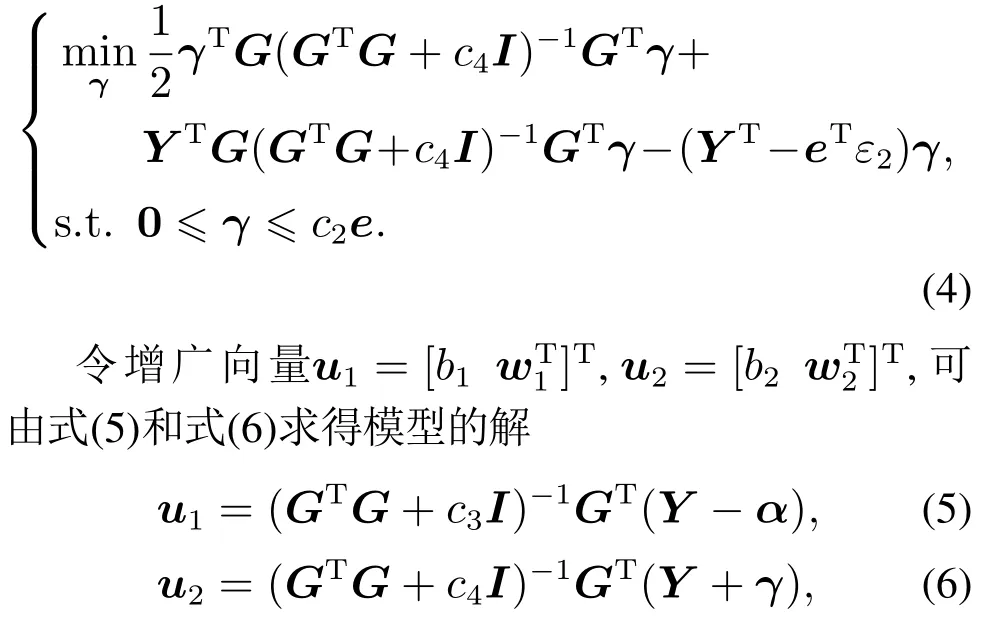
其中拉格朗日乘子α和γ通过求解式(3)和式(4)可得.
对于某一测试输入x,其对应输出为f(x)=(f1(x)+f2(x))/2.
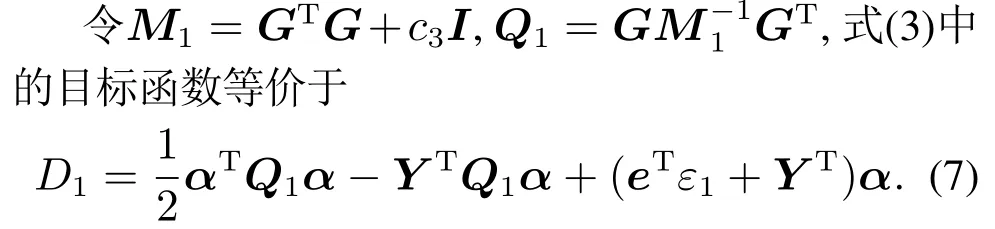
基于KKT定理,由D1的一阶导数可得式(3)的KKT条件如下:
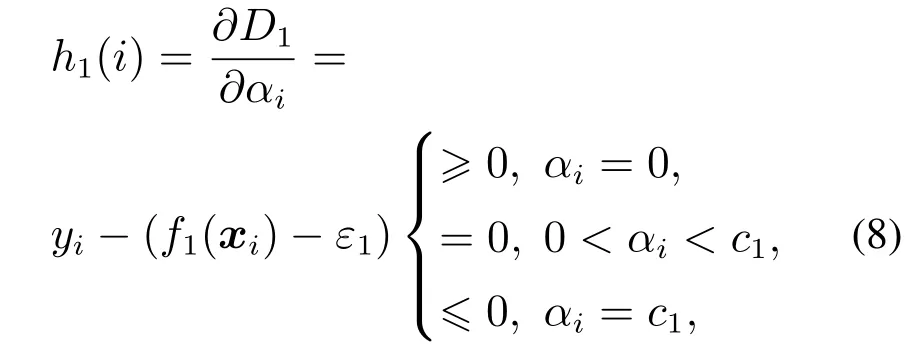
其中h1(i)为边界距离函数.
由式(8)可知,训练样本可以分为3个独立的子集,由上到下分别为保留支持向量集R1,边界支持向量集S1和错误支持向量集E1.同理可得,式(4)的KKT条件.
3 增量算法
由于ETSVR中含有(ξ∗)Tξ∗和(ν∗)Tν∗项,导致即使新增样本的拉格朗日乘子为0,也会使f1(x)和f2(x)产生很大变化,可能出现大量原有样本的拉格朗日乘子不满足KKT条件的情况,使得逐步迭代调整的效率不高,这也是AOSVR的方法不能直接用于解决ETSVR的增量学习问题的重要原因.
为此本文提出了一种精确增量式ε型孪生支持向量回归机.该算法包含3个部分:1)高效更新逆矩阵和,这是由ETSVR模型包含一个二次损失的特点决定的,每新增一个样本对偶问题就会发生较大改变;2)提前调整,主要用于减少更新后不满足KKT条件的原有样本的个数;3)检查每个样本的KKT条件,通过增量关系式,对异常样本的拉格朗日乘子进行逐步调整.
当新增样本(xn+1,yn+1)时,本文算法基于已有训练信息更新f1(x)和f2(x)的增广向量u1和u2.由于u2与u1的更新相似,接下来以更新u1为例详细阐述本文的增量学习算法.令
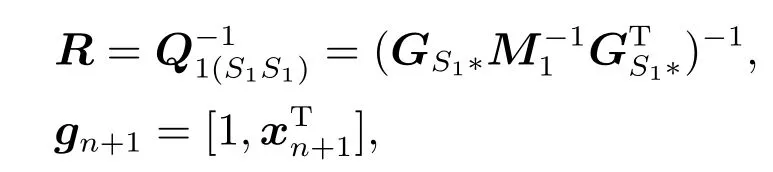
αn+1为新增样本的拉格朗日乘子.
3.1 高效更新逆矩阵和R
当新增样本(xn+1,yn+1)加入训练集后,首先需要对逆矩阵和R进行更新.
引理1设A∈Rn×n正定,u,v∈Rn是任意向量,若1+vTA−1u0,则有[20]
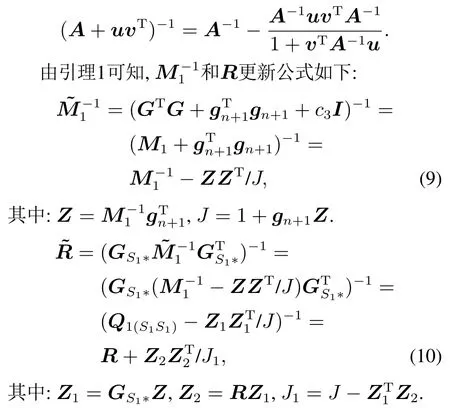
3.2 提前调整
由于式(1)的目标函数中二次损失项(ξ∗)Tξ∗的存在,由式(9)更新将导致和Q1发生较大的改变,影响原有样本的边界距离.为了尽可能减少影响保证原有样本边界距离不变,使得大部分原有样本的拉格朗日乘子符合KKT条件,获得一个有效的初始状态,通过以下两个步骤提前计算αn+1并调整αS1.


3.3 筛选异常样本

3.4 增量关系推导


3.5 计算最大步长ηmax
每迭代过程中,需要在以下4种情况中搜索最大步长ηmax:
情况1在F1集合中,样本(xi,yi)移入S1,R1和E1集合的步长对应如下:


情况2在S1集合中,样本(xi,yi)移入R1或E1集合的步长如下:
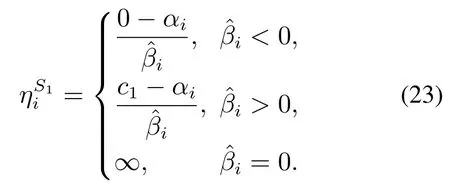
情况3在R1集合中,样本(xi,yi)移入S1集合的步长如下:
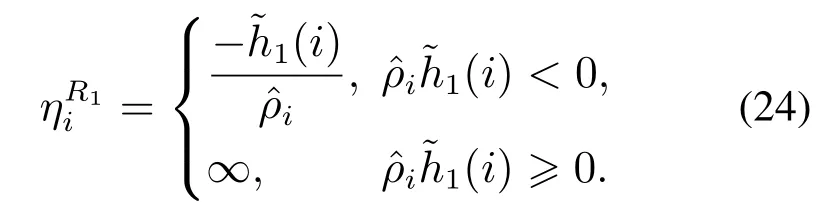
情况4在E1集合中,样本(xi,yi)移到S1集合的步长如下:
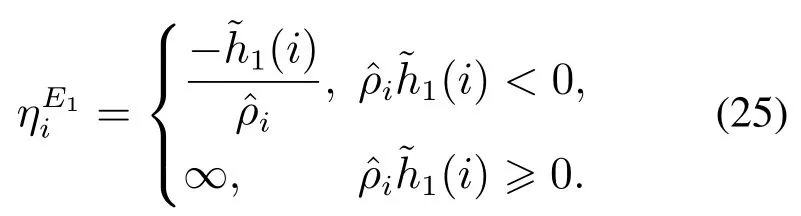
最终,ηmax由式(26)确定

3.6 高效更新逆矩阵
在筛选异常样本以及迭代调整的过程中,当S1集合发生改变时,需要对进行更新.

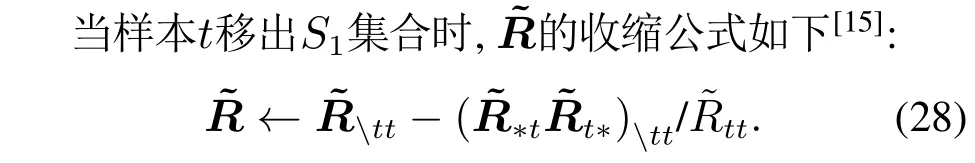
3.7 算法步骤
AIETSVR算法的整体步骤如下:

同理,可得到新增样本后上界回归函数的增广向量u2.
4 算法复杂度分析与对比
4.1 AIETSVR算法复杂度分析
为了说明本文算法在处理增量问题时,训练时间上的优势,以更新增广向量u1为例,对第3.7节中步骤1到步骤5分别分析其时间复杂度,由于乘法的复杂度远高于加法,因此以下分析中只考虑乘法运算的次数.假设当前已更新完n个m维样本,S1和F1集合中的样本个数分别为和.

但是,本文算法需要在计算过程中保存逆矩阵和R,大小分别为m2和.由于m不会改变且一般情况下m ≪n,支持向量具有稀疏性,不会很大,因此这两个逆矩阵不会占用很大的内存空间.除此以外,训练样本矩阵和3个集合的划分情况(以向量形式)需要保存,大小分别为n×m和n×1.
4.2 不同算法的时间复杂度对比
本节选取算法思想相近的AOSVR,以及ETSVR的两种常用求解算法:逐次超松弛法(ETSVRSOR)和内点法(ETSVRQP),分析时间复杂度,体现AIETSVR在训练时间上的优势.令AOSVR算法的支持向量个数为lS.
对于小规模数据集,m ≈lS ≈lS1≈n,各个算法的时间复杂度如下:AOSVR迭代前O(n2),每次迭代O(n2)+O(n);ETSVRSOR迭代前O(n3),每次迭代O(n2)+O(n);ETSVRQP 迭代前O(n3),每次迭代O(n3);AIETSVR 迭代前O(n2)+O(n),每次迭代O(n2)+O(n).综上可以看出,在小规模数据集上,ETSVRQP的时间复杂度较高,而AOSVR,ETSVRSOR和AIETSVR时间复杂度相当.
对于大规模数据集,m ≪n,各个算法的时间复杂度如下:AOSVR迭代前O(n),每次迭代O(lS)+O()+O(n);ETSVRSOR迭代前O(n)+O(n2),每次迭代O(n2)+O(n);ETSVRQP 迭代前O(n)+O(n2),每次迭代O(n3).
综上可以看出,ETSVRSOR时间复杂度的数量级为O(n2)要小于ETSVRQP的数量级O(n3).AOSVR时间复杂度的数量级为O(n)+O(),由于在大规模数据集上支持向量个数lS远小于样本数n,因此时间复杂度小于ETSVRQP和ETSVRSOR.
而AIETSVR的数量级为O()+O(n),由于ETSVR单个目标函数仅有一个不等约束是SVR的一半,即/2.因此AIETSVR的时间复杂度小于AOSVR,延续了ETSVR相对于SVR在训练时间上的优势,并且时间复杂度远小于ETSVRSOR和ETSVRQP这两种离线算法,适合于大规模数据集的在线增量训练.
5 可行性和有限收敛性分析
通过可行性分析,证明AIETSVR算法中逆矩阵更新的可行性以及拉格朗日乘子调整的可靠性.其中,定理1是对文献[16]中定理2的进一步延伸,定理2和定理3由文献[16]中的证明推广而来.通过有限收敛性分析,证明AIETSVR算法经过有限次数调整收敛到最优解.其中,定理4和定理5的证明分别参照文献[16]和文献[15].令(xc,yc)为F1集合中的一个候选样本.
5.1 可行性分析
本文把算法的可行性证明,分为以下2个问题:
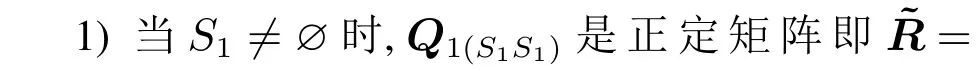



5.2 有限收敛性分析
有限收敛性分析将确保本文算法在有限次数调整后收敛到问题的最优解.首先,证明在迭代过程中,当αF1在[0,c1]区间内调整时,目标函数D1单调递减(定理4).然后,以此为基础,证明经过有限步迭代后,AIETSVR算法将收敛到最优解(定理5).


6 数值实验与分析
6.1 实验设计和参数设置
为了验证本文算法的可行性和有效性,从以下两个角度出发设计实验:1)将目前常用的ETSVR的求解算法与AIETSVR在训练速度和精度上进行对比;2)AIETSVR是否能够延续ETSVR相对于SVR的优势,比AOSVR的训练速度更快.
选取AOSVR[13],ETSVRQP[9],ETSVRSOR[9]和本文算法AIETSVR,在基准测试数据集上进行仿真实验.其中,ETSVRQP使用MATLAB二次规划工具箱中的内点法求解ETSVR的对偶问题,能够获得精确解,且不需要前一时刻的模型信息,属于离线批处理训练算法,但是时间复杂度较高;ETSVRSOR使用逐次超松弛法求解ETSVR的对偶问题,时间复杂度较低,且不需要前一时刻的模型信息,也属于离线批处理训练算法,但是只能求得近似解,代码可以从http://www.optimal-group.org/Resources/Code/ETSVR.html下载;AOSVR使用文献[13]中提出的在线增量算法求得精确解,时间复杂度低,需要保存前一时刻的模型信息,代码可以从https://github.com/fp2556/onlinesvr下载.所有实验在Intel i5-8300H(@2.3 GHz)处理器,8 G内存的计算机,MATLAB2018a软件平台上完成.
实验中使用的UCI基准测试数据集如表1所示.
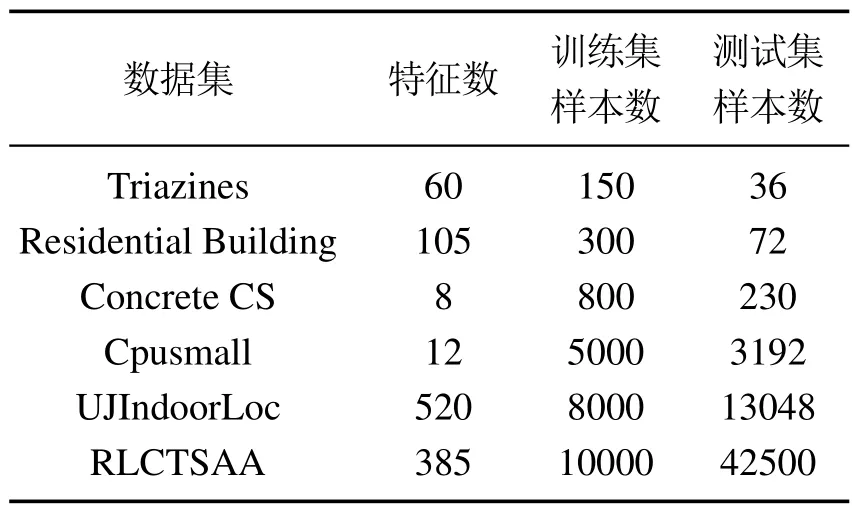
表1 实验中使用的基准测试数据集Table 1 The benchmark datasets used in our experiments
首先把每组数据集的特征归一化为[0,1],然后划分训练集和测试集,由于训练集中含有重复样本会导致多个样本同时到达边界,不符合每次仅有一个样本到达或离开边界的假设[16],因此重复样本不选入训练集中.在训练集上,采用5次五折交叉验证的方式,共25次实验的平均值进行网格参数寻优.在参数寻优时,SVR使用LibSVM提供的离线算法进行训练,ETVSR使用ETSVRQP进行离线训练.最终以训练集上的最优模型在测试集上的表现来评估该模型的好坏.采用如下性能评价指标:
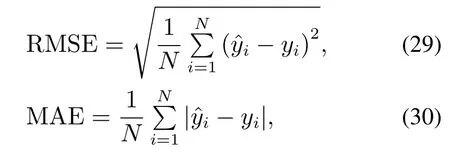
此外,平均新增一个样本所需的训练时间也作为性能评价指标.并且列出增量算法需要调整的拉格朗日乘子的平均数量τ,表明本文算法通过第3.2节提前调整后获得了有效的初始状态.对于AOSVR,由文献[13]可知τ始终为1;对于本文算法,τ=;由于离线算法ETSVRSOR和ETSVRQP每一次迭代都是对拉格朗日乘子的整体调整,并不区分拉格朗日乘子是否异常,因此τ无意义.
AOSVR的参数设置为ε=0.01,C=2i,在i∈[−8,8]的范围内寻找最优值,ETSVRQP,ETSVRSOR和AIETSVR共有的参数c1=c2=2i,c3=c4=2i,在i∈[−8,8]的范围内寻找最优值,考虑到不敏感因子ε1,ε2对算法的影响较小[23–25],并为了对比公平起见,取ε1=ε2=0.01.由文献[9]可知,ETSVRSOR需要设置参数t=0.9和停止迭代的阈值为0.001.
6.2 实验结果与分析
表2列出了4种不同的回归算法在基准数据集上的实验结果,“−”表示该处指标无意义,粗体表示最优指标.从表2可以看出,与AOSVR相比,其他3种算法的泛化性能更好,即ETSVR模型在泛化性能上要优于SVR模型,这与文献[9]中的结论相同.由于ETSVRQP使用MATLAB的二次规划工具箱进行训练,因此可以把ETSVRQP的解作为ETSVR模型的精确解.对于ETSVR的3种训练算法ETSVRQP,ETSVRSOR和AIETSVR,AIETSVR与ETSVRQP在RMSE和MAE指标上的结果完全相同,但是ETSVRSOR却有差异.因此本文算法能够获得ETSVR模型的精确解,而ETSVRSOR由于收敛性差且梯度信息不准确最终得到的只是近似解.
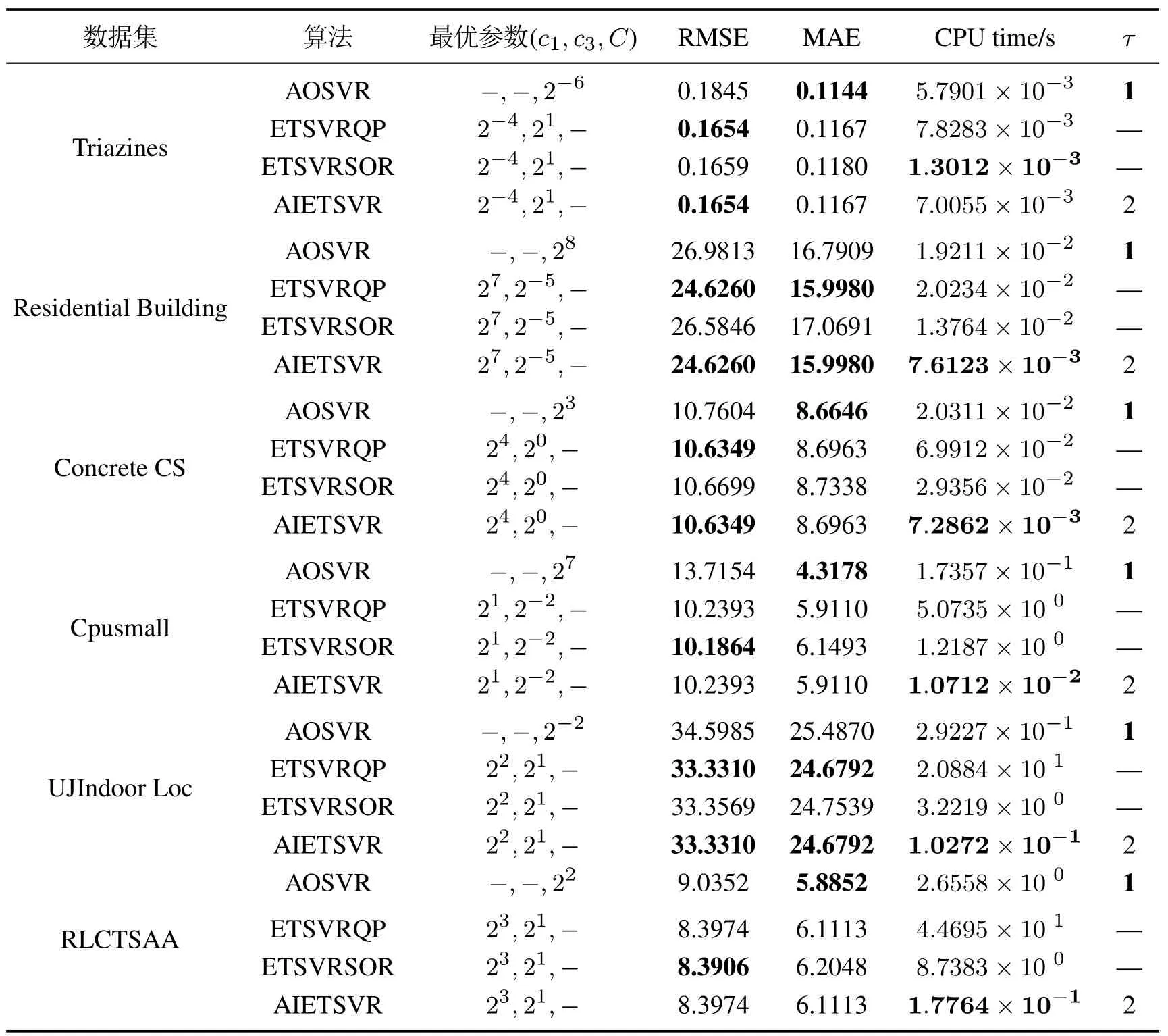
表2 4种不同回归算法在基准数据集上的实验结果Table 2 The experimental results of four different algorithms on benchmark datasets
对于平均单个样本的增量时间,AIETSVR除了在第1个规模最小的数据集上不是最优外,在其余数据集上均表现出很大的优势.结合第4.2节中的分析可知:在小规模数据集上,ETSVRQP的时间复杂度较高,其他3种算法的时间复杂度相当;在大规模数据集上,ETSVRQP的时间复杂度最高,ETSVRSOR次之,这两种算法是离线训练算法,并不适合处理大规模数据集的在线增量学习问题,而AOSVR和AIETSVR这两种在线增量算法的时间复杂度远低于离线算法,且AIETSVR比AOSVR训练效率更高,适合于大规模数据集的在线增量训练.主要原因是:与AOSVR相比,ETSVR模型中的每个目标函数都只有一个不等约束,相当于把SVR模型的S集合分为了S1集合与S2集合,因此AIETSVR算法迭代时需要更新的2个逆矩阵的大小为AOSVR算法对应逆矩阵的1/4左右,使得AIETSVR训练时间远小于AOSVR.与离线训练算法ETSVRQP和ETSVRSOR相比,AIETSVR基于已有模型信息进行增量,训练时间大为减少,并且在每个数据集上都能得到与ETSVRQP相同的RMSE和MAE指标,即该算法能够获得精确解.
从τ指标上可以看出,第3.2节的提前调整有效地减少了异常样本并获得有效的初始状态.由第3节可知,本文算法时间复杂度随着τ的增加,成倍增长,而通过提前调整,避免了新增样本后大量异常拉格朗日乘子的产生,使得算法的时间复杂度不会急剧恶化.
图1为随着训练样本个数增加,4种算法的RMSE性能指标的变化过程.从图1中可以看出,AIETSVR和ETSVRQP的RMSE变化曲线完全相同,而ETSVRSOR和ETSVRQP的RMSE变化曲线只是趋势相同,结果相近.这就意味着AIETSVR通过增量关系,在逐步调整过程中,保证非异常样本的拉格朗日乘子始终满足KKT条件,并获得一个十分精确的解.而ETSVRSOR由于收敛性差且梯度信息不准确,只能获得一个近似解.与SVR相比,ETSVR的RMSE在6个数据集上均取得了更好的结果,说明ETSVR在RMSE上具有更好的泛化性能,原因是ETSVR目标函数中包含了二次损失项,相当于对RMSE指标进行了优化.
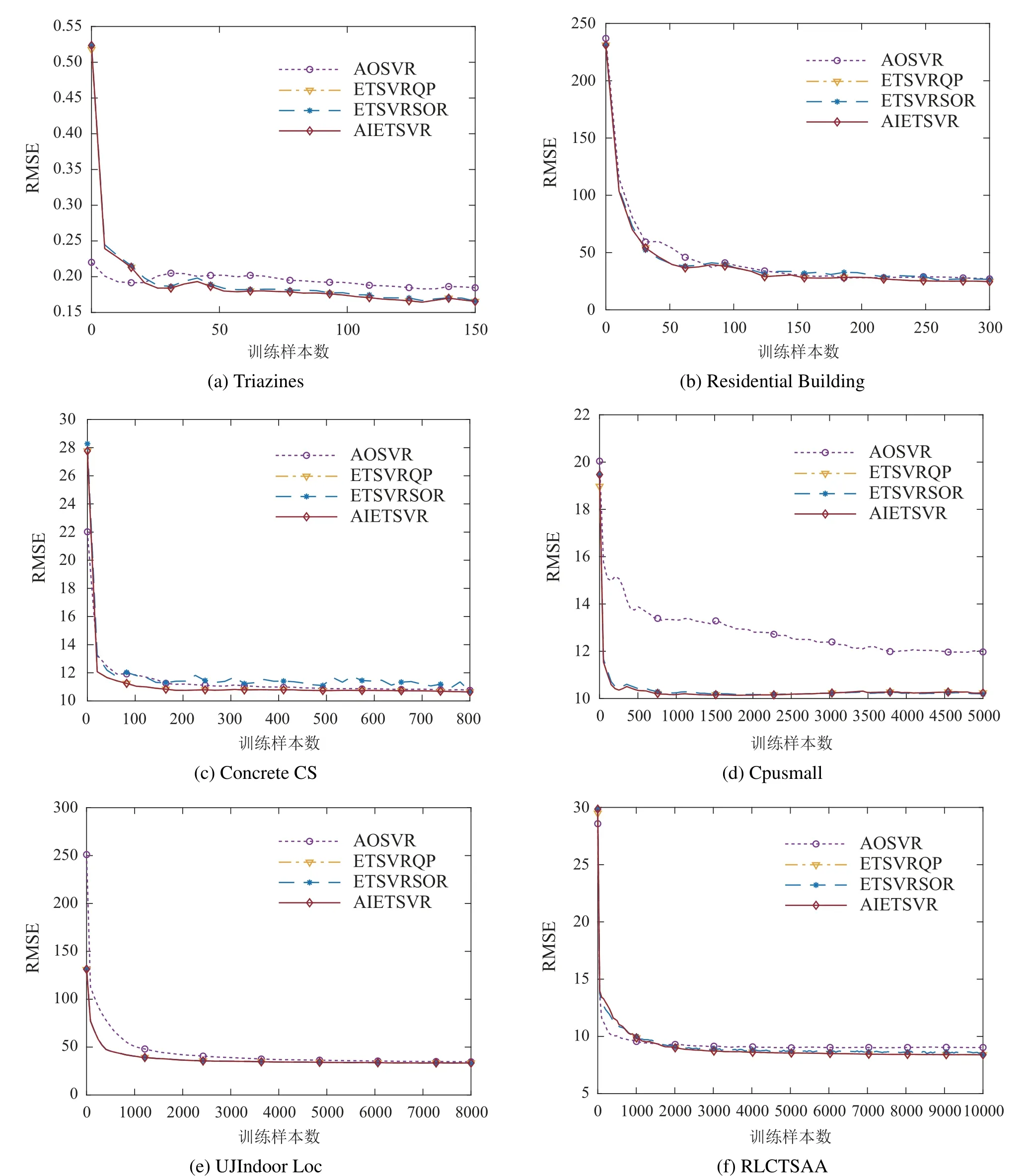
图1 RMSE随训练样本增加的变化过程Fig.1 The changing process of RMSE versus the number of training samples
图2为随着训练样本个数增加,4种算法的MAE性能指标的变化过程.从图2中可以看出,AIETSVR和ETSVRQP的MAE变化曲线同样完全相同,而ETSVRSOR和ETSVRQP的MAE变化曲线只是趋势相同,结果相近.这进一步证实了本文算法能够获得精确解.但是,与SVR 相比,ETSVR 在MAE 上略差.原因是SVR中的ε不敏感损失与MAE类似,相当于对MAE的直接优化,而ETSVR中包含的为单边ε不敏感损失,相比而言约束较弱.
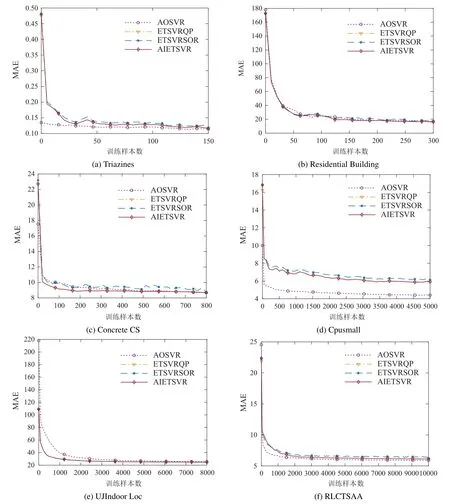
图2 MAE随训练样本增加的变化过程Fig.2 The changing process of MAE versus the number of training samples
图3为随着训练样本个数增加,每种算法新增一个样本所需训练时间的变化过程.从图3中可以看出,除第一个规模最小的数据集外,与其余3种算法相比,AIETSVR在训练时间上具有一定的优势,且随着样本量增加,新增一个样本模型所需的训练时间增长缓慢.
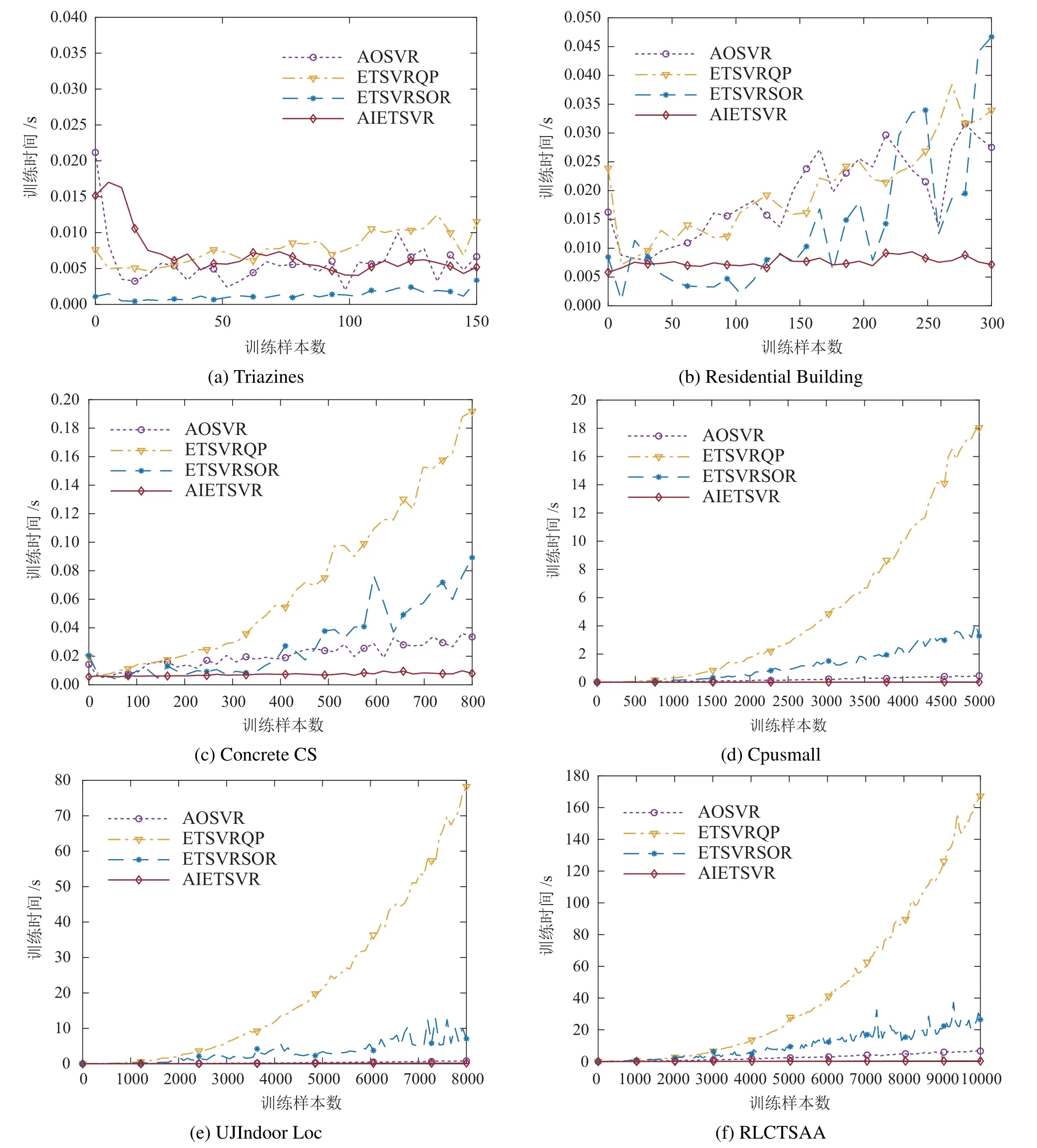
图3 新增一个样本所需训练时间的变化过程Fig.3 The changing process of the training time elapsed when adding a new sample
由第4.2节可知,在小规模数据集上,ETSVRQP的算法复杂度较高,其他3种算法复杂度相当,但是由于实际的影响因素较多,因此出现了图4(a)和(b)上训练时间增长很不稳定的现象.
结合第4.1节和第4.2节可知,在大规模数据集上,m ≪n,除n外,AIETSVR算法的时间复杂度主要取决于.本文通过提前增量调整使得τ=,避免了由于τ增加使得时间复杂度急剧恶化.又由于ETSVR模型本身的优势,每个目标函数都只有单个边界,支持向量都有很好的稀疏性,即和较小,迭代过程中需要更新的逆矩阵R规模较小,故每次迭代消耗的时间较少.而对于小规模数据集,由于其余算法所求逆矩阵规模均很小,体现不出本文算法在迭代过程中所需更新的逆矩阵R规模小的优势.故AIETSVR更加适合于处理大规模数据集上增量学习问题.
7 总结
本文设计了一种精确增量式ε型孪生支持向量回归机算法,解决了增量环境下无法高效更新线性ε型孪生支持向量回归机模型的问题.该算法通过计算新增样本的拉格朗乘子以及调整支持向量集的拉格朗日乘子获得迭代调整前的有效初始状态,然后基于AOSVR的方法,调整异常拉格朗日乘子,并且从理论上分析了算法的可行性和有限收敛性.实验结果表明,在有限步迭代过程中,本文算法仅需更新两个较小规模的逆矩阵,极大地减少了大规模数据集下模型更新的时间,而且能获得精确解.
猜你喜欢
北京大学学报(自然科学版)(2022年4期)2022-08-18
社会科学战线(2022年2期)2022-03-16
计算机研究与发展(2022年1期)2022-01-19
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
杂文选刊(2019年12期)2019-12-06
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
意林·少年版(2018年22期)2018-12-05
新青年(2018年8期)2018-08-18
幸福·婚姻版(2018年12期)2018-02-22
文苑(2015年9期)2015-09-10
