
基于图像增强的鳕鱼识别*
2022-07-26 07:10:26王德雨张元良
江苏海洋大学学报(自然科学版) 2022年2期
石 伟,王德雨,张元良
(江苏海洋大学 海洋工程学院,江苏 连云港 222005 )
中国海域面积约300万km2,海洋生物资源极其丰富,但中国海洋资源的开发利用程度与发达国家相比仍然较低,海洋经济发展总体水平不高。鱼类资源作为海洋生物资源中最重要的种类,不仅是人类重要的食物来源,也是沿海城市渔业发展的经济基础[1]。鳕鱼在中国主要分布于黄海和渤海,其营养价值丰富且肉质鲜美,是海洋鱼类资源中重要的食用经济鱼类。本文选取鳕鱼为图像识别的研究对象。目前,水下目标识别已经成为视觉行业的研究热点。由于光在水体中传播会被吸收和散射,导致水下获取的图像相较实物原图质量退化严重,存在色偏、对比度低以及模糊等问题,因此,直接对原始图像进行图像识别效果不够理想,目标识别准确率低,特征提取困难,所以需要对图像进行增强和颜色恢复。水下图像增强技术可分为深度学习类和非深度学习类。对于非深度学习类的增强方法,Ancuti等[2]基于融合原理,提出了一种色彩补偿与白平衡的多尺度融合方法,该方法增强后的图像和视频降低了噪声水平,更好地暴露了黑暗区域,提高了全局对比度;刘柯等[3]针对水下低光环境以及色偏等问题,提出了一种低光水下环境中的图像复原及增强办法。对于深度学习类的水下图像增强,Fu等[4]通过结合深度学习和传统图像增强方法,提出采用两分支网络分别补偿颜色和降低对比度的方法;Islam等[5]提出了一种名为FUnIE-GAN的生成对抗网络,通过配对和非配对训练来学习提高水下图像质量。
对于鱼类识别技术,Li等[6]针对LifeCLEF数据集中的部分鱼类目标提出了一种轻量型R-CNN算法,获得了较高的鱼类识别准确率;顾郑平等[7]基于卷积神经网络采用迁移学习、支持向量机相融合的方法进行鱼类识别研究;Yusup等[8]使用YOLO深度学习算法进行自动识别,并根据YOLO更快的物体检测优势,通过珊瑚鱼水下视频对算法进行了分析;Lin等[9]采用带有全景摄像机的水下无人机,进行了基于深度学习的鱼类自动识别。
传统的水下图像增强方法无法完全去除图像色偏,且图像质量也会有所下降,对此,本文提出了一种基于图像增强的鳕鱼识别方法,首先利用UWGAN通过其自身的数据集生成逼真的水下图像,然后利用Deep WaveNet框架中的增强框架进行颜色恢复和细节复原,再利用RGHS对图像的亮度和对比度进行调整,并采用深度学习和非深度学习方法相结合的手段来进一步提高图片质量,最后利用改进的YOLOv5进行鳕鱼识别。本文所提出的方法可为水下鱼类探索以及智能化捕捞研究提供一定的参考。
1 基于图像增强的鳕鱼识别算法
1.1 算法流程
本文所提出的算法流程如图1所示。首先,通过UWGAN框架中的生成对抗网络,根据纽约大学NYU数据集中的空中图像(airimage)和图像的深度信息(airdepth),以及自建鳕鱼数据集中的水下图像,生成逼真的水下图像(fakeimage),然后利用airimage和fakeimage构成的图像对Deep WaveNet框架中的图像增强模块进行颜色恢复及细节复原,最后利用相对全局直方图拉伸(RGHS)进行对比度以及亮度调整,至此图像增强模块已经完成,随后用改进YOLOv5对增强后的鳕鱼图像进行检测识别。
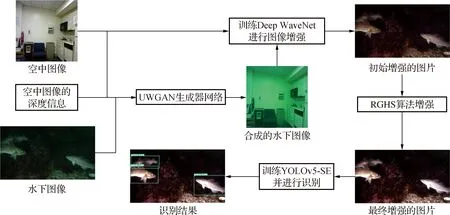
图1 算法流程
1.2 UWGAN以及Deep WaveNet
UnderWater GAN(UWGAN)基于水下成像模型生成水下图像,并通过生成对抗式网络估计其各项参数。此外,从水下成像模型来看,水下图像可看成由两部分组成,一种是直接衰减图像,另一种是后向散射图像。将不同水类型的真实水下图像输入到模型中,可以得到相应类型的合成水下图像,最后利用UNet作为水下图像的恢复网络对这些图像进行增强。
本文主要利用UWGAN生成逼真的水下图像。水下光学成像过程可以用水下成像模型进行数学描述,如式(1)所示。此模型广泛应用于近年来的水下图像增强方法。
I(x)=D(x)+B(x)。
(1)
式中:I(x)为每个像素的光照强度x,D(x)和B(x)分别表示直接衰减图像和后向散射图像中每个像素的强度x。在此模型的基础上,训练一个包括生成器G和鉴别器D的标准生成对抗网络,以此得到最后的输出I(x)。通过UWGAN生成对抗网络,可以得到airimage和fakeimage的图像对[10]。
Deep WaveNet网络可以同时增强和提高退化水下图像的空间分辨率,为此,其接受域采用了衰减制导局部和全局一致性的颜色通道。此外,接收域越大,就越能够更好地学习图像中的全局特征。一般来说,水下图像的全局特征主要以蓝色为主,而海洋生物则与绿色紧密相连,因此,蓝色通道被分配了一个较大的接收域,而绿色通道则被分配了一个较小的接收域,同时进一步减小红色通道接收域。此外,此方法还采用了以阻断注意力为基础的方法,自适应调节网络中信道的特定信息流。
在本文中,分别用D,E来表示退化图像和增强的图像,D表示fakeimage中的图像,E表示airimage中的图像,整个Deep WaveNet分为四个阶段,如图2所示。第一阶段的目标是生成具有波长驱动的上下文信息特征。第二阶段的第一层类似于第一阶段,其由一堆具有不同接收域的卷积层组成,实际上,阶段二的目的是从阶段一的上下文信息特征中生成颜色特定的失真残差。第三阶段以上下文注意力残差作为输入,输出全局颜色校正残差。第四阶段作为图像重构模块,由一个反卷积层、一个注意力残差块和另一个反卷积层组成,其以全局颜色校正残差作为输入,最后输出增强后的水下图像[11]。
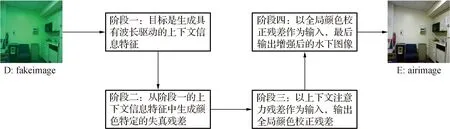
图2 Deep WaveNet工作流程
1.3 相对全局直方图拉伸(RGHS)
RGHS是在RGB和CIE-Lab颜色模型中提出的,它基于灰度世界理论来处理图像。
RGHS首先根据灰度世界假设理论修正G和B通道,而不考虑R通道,因为水中的红光很难通过简单的颜色均衡进行补偿,当然,这样也可能带来红色过饱和的问题。
其次是进行相对全局直方图拉伸。全局直方图拉伸公式见式(2),输入和输出像素强度值分别表示为pi和po,a,b分别表示输入图像的最小强度和最大强度;c,d分别表示目标输出图像的最小强度和最大强度。与全局直方图拉伸公式不同,相对全局直方图拉伸公式见式(3)[3],其中pin和pout分别为输入和输出像素,Omax,Omin,Imax和Imin分别为拉伸前后图像的自适应参数。
(2)
(3)
在经过RGB颜色模型的对比度校正后,对图像进行颜色校正处理。在此过程中,将水下图像转换为CIE-Lab颜色模型,以提高颜色性能。在此颜色模型中,用L分量表示图像的亮度,当a=b=0时,颜色通道将呈现中性灰色值。因此,对输出的a和b分量进行修改,以获得准确的颜色校正,同时使用L分量调整整个图像的亮度。CIE-Lab颜色模型中的L,a和b分量经过自适应拉伸过程后,将通道组合并转换回RGB颜色模型,可以生成对比度增强和颜色校正的输出图像[12]。
1.4 加入SE注意力机制的YOLOv5目标识别
YOLOv5算法是一种单阶段目标检测算法,它能够使目标定位与目标分类任务均在一个阶段完成,不仅简化了目标检测的整个过程,同时大大减少了目标检测所需的时间,在检测速度上更加满足实际需求。YOLOv5检测网络共有4个版本,分别为YOLOv5x,YOLOv5l, YOLOv5m,YOLOv5s。其中,YOLOv5s是深度和特征图宽度均最小的网络,相对于其他网络,它的优点是模型尺寸比较小且检测速度快。YOLOv5s包括4个部分:输入端、基准网络、Neck网络和Head输出端[13]。
本文选用的检测权重即为YOLOv5s,并在YOLOv5网络中引入了SE(squeeze-and-excitation networks)注意力机制。SE注意力增强模型对网络进行优化增强的方法分为两步[14](见图3)。首先是压缩过程,就是对输入特征图W×H×C进行通道信息的全局平均池化,目的是将特征图变为1×1×C向量;随后是激励过程,激励模块中含有两个全连接层。为了减少通道个数进而降低计算量,在网络中设置了缩放参数SERatio。在第一个含有C×SERatio个神经元的全连接层中,其输入向量为1×1×C,通过全连接层后输出的向量为1×1×C×SERadio。随后通过第二个含有C个神经元全连接层,这样的输出向量为1×1×C。之后进行的是Scale操作,其目的是将原特征图对应通道的矩阵和SE模块计算出来的各通道权重值分别相乘,得到输出结果W×H×C。
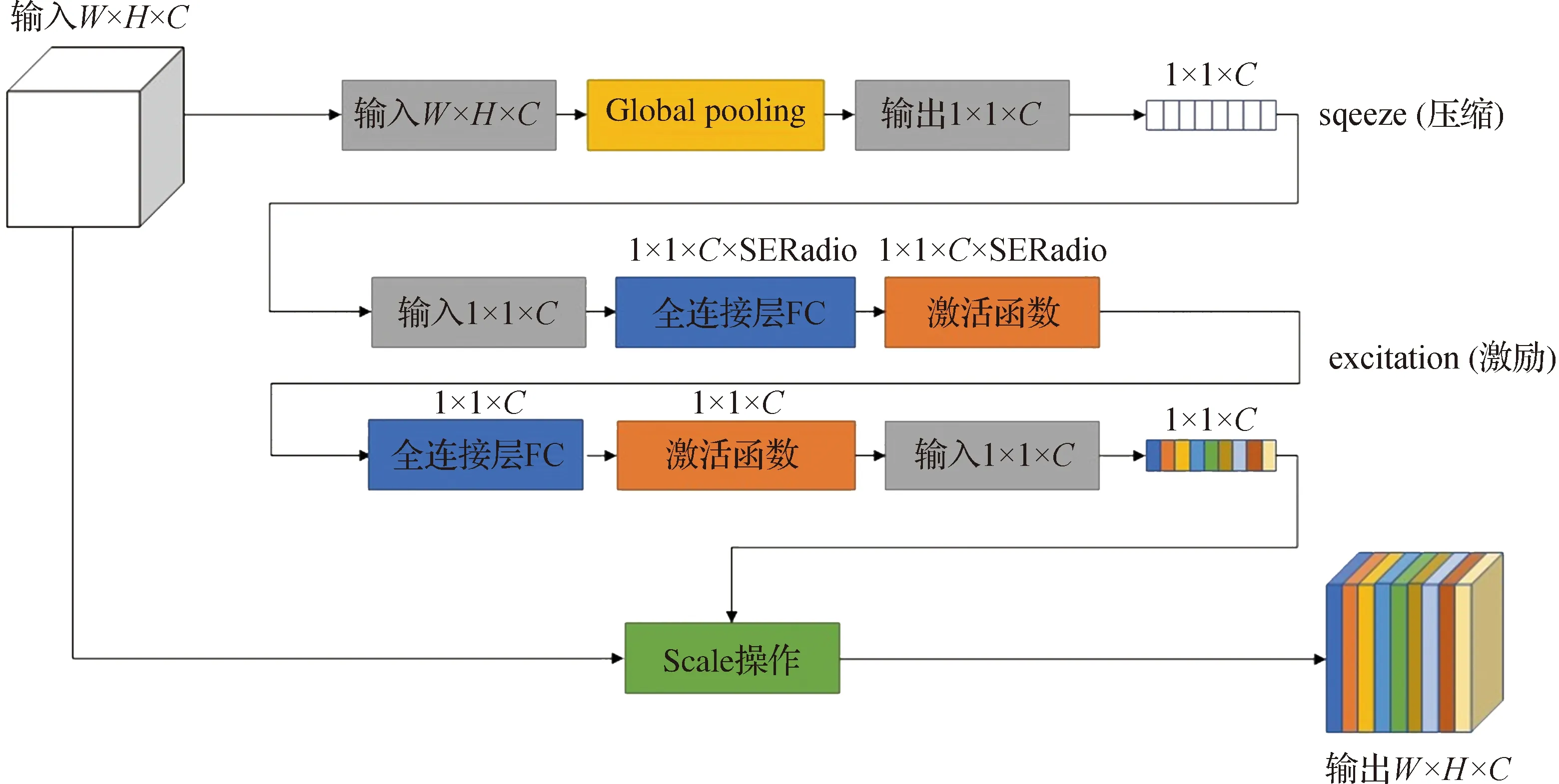
图3 SE注意力机制模块
2 图像增强实验结果分析
2.1 数据集的获取及建立
鳕鱼视频文件来自Nature Footage网站。本文将鳕鱼视频文件分割成1 400张图片文件,运用于YOLOv5识别的训练集和测试集,比例为8∶2,其中鳕鱼标注为gadus;运用于UWGAN中的图像数量为416张水下带有绿色色偏的鳕鱼图像。此外,还使用了纽约大学数据集中的420张空气图片和420个深度数据。
2.2 实验结果分析
不同算法的实验结果如图4所示,图片从上到下依次为测试图1~6。引用水下彩色图像质量评估(UCIQE)[15]和水下图像质量评价指标(UIQM)[16]两种指标来评价并比较本文算法与其他算法的差异。本文算法先通过深度学习算法进行颜色校正并改善图片质量,再用非深度学习的方法调整对比度及亮度。不同算法的增强效果如表1和表2所示,表中黑体数值表示最优结果。

a 原图

表1 相关增强方法UCIQE值
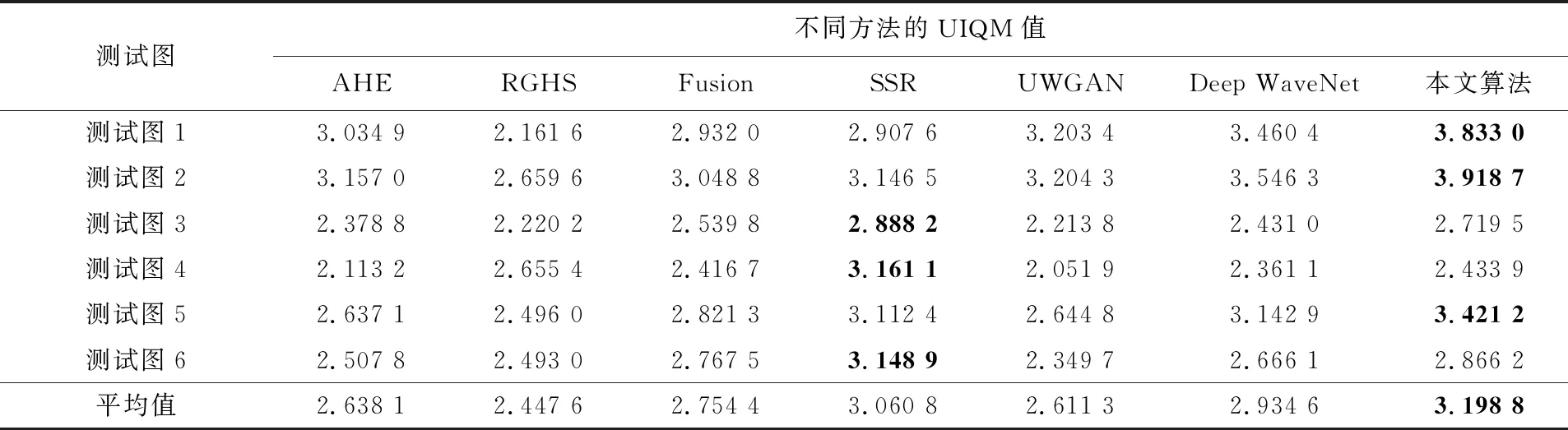
表2 相关增强方法UIQM值
从原图来看,鳕鱼图片存在明显的绿色色偏,这对鳕鱼识别增加了一定的难度。根据实验结果,AHE和Fusion两种算法都使图像得到了一定程度的色彩增强和对比度增强,但图像细节在增强之后丢失;RGHS增强使图片亮度和对比度都得到了提高,细节处理也较好,但其存在明显的绿色色偏;SSR增强之后所形成的色偏更加严重,部分图像增强后对比度过高,色彩过分调节,图片细节丢失严重;UWGAN很好地解决了图像的色偏问题,细节恢复也比较好,但是部分图像存在对比度较高的问题;Deep WaveNet增强之后细节恢复较好,也去除了绿色色偏,但存在亮度过低的问题。运用本文所提出的算法,经过深度学习及非深度学习处理之后,所得的视觉效果好于其他方法,较好地去除了绿色色偏,图片细节和亮度效果等表现均较好。
从客观评价指标来看,本文算法的UCIQE值在6幅图片处理结果上的平均值为0.573 6,均优于其他算法;从UIQM值来看,本文算法的平均值为3.198 8,同样也高于其他几种算法。综合主观和客观评价结果,本文方法在图像对比度、亮度以及增强后的图像细节等方面均表现出较高的处理能力,总体上略微优于其他几种方法,因此选择本算法作为图像预处理的方法。
3 目标检测结果对比
为了体现出本文方法的有效性,共进行了三种算法进行目标识别的实验。第一种为原图片作为数据集直接进行检测识别,项目命名为YOLOv5-before;第二种是用本文算法增强后的图片进行鳕鱼识别,项目命名为YOLOv5-after;第三种就是在第二种算法的基础上添加SE注意力机制从而进行识别,项目命名为YOLOv5-SE,并在训练时保留最好权重。本文算法均是基于NVIDA RTX3070 8G,学习率设置为0.01,学习阈值设置为0.2,三种算法的各项数据如图5和表3所示。
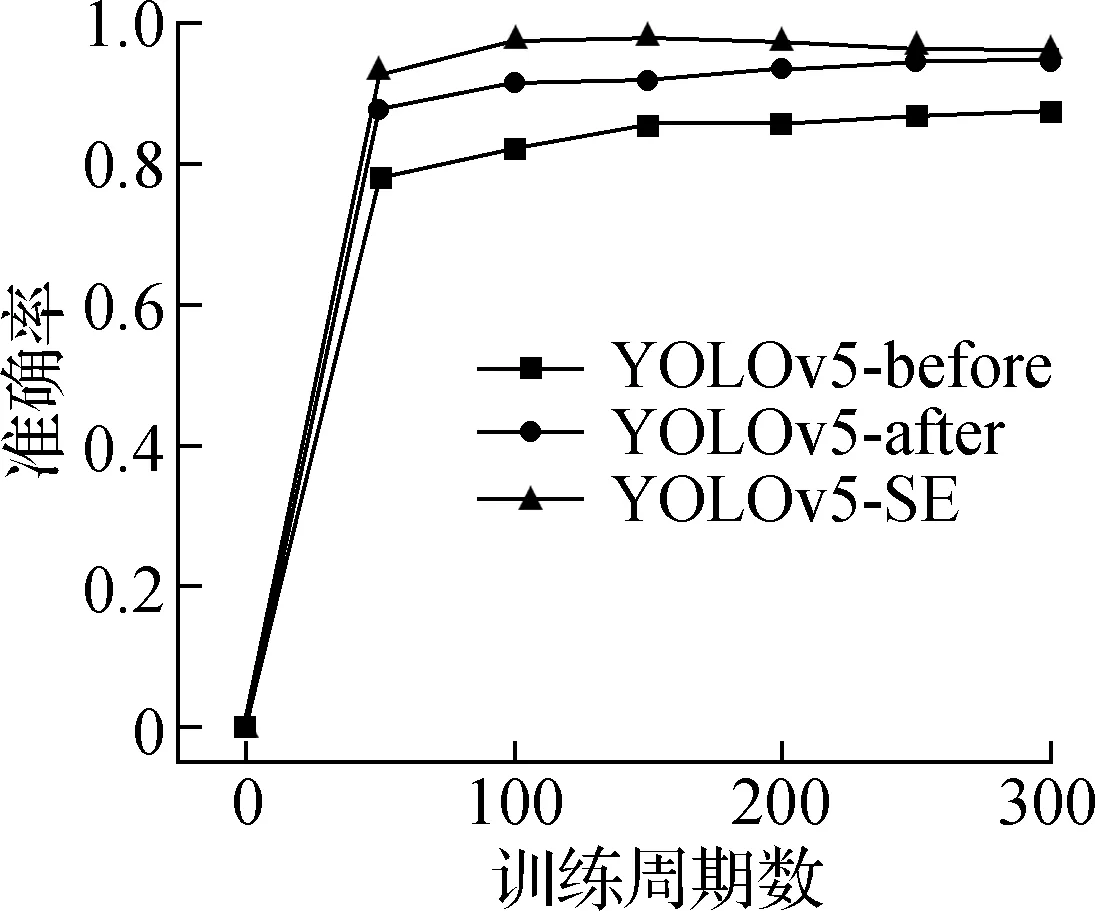
a 准确率
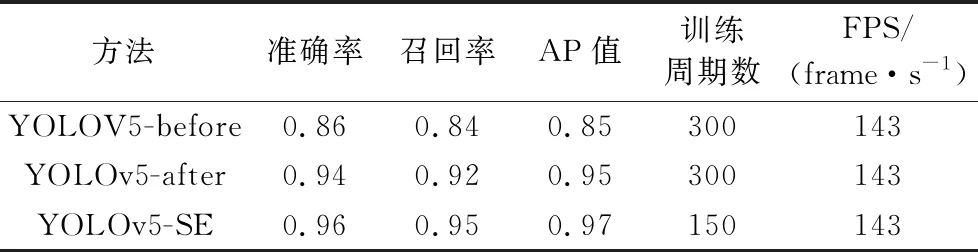
表3 三种算法各项数据的比较
从图5可以看出,使用图像增强后的数据集相比直接用原始数据集进行识别训练,不管是准确率(precision)、召回率(recall),还是AP(average precison)值,都得到了提高。而添加了SE注意力机制的网络的各项参数相比YOLOv5-after也得到了提高,但此网络在150周期训练之后各项数据都呈现出下降趋势,出现过拟合现象,因此之后又将此网络训练至150周期,而非原来的300周期。
从表3中的数据可以看出,YOLOv5-before和YOLOv5-after的训练周期数均为300,处理图片的速度都是143 frame/s,而YOLOv5-SE仅仅训练了150个周期,不管是准确率还是召回率和平均准确率都得到提高,即客观上整体得到提高。
图6是三种算法的部分实际测试结果。从图中可以看出,相比未添加注意力机制的YOLOv5-after算法,YOLOv5-SE有了一些提升,主要体现在识别的置信度上,而采用原图数据集直接进行训练识别的结果则比较差,也存在部分鳕鱼识别不出来的现象,且置信度很低。综合以上来看,最后改进得到的YOLOv5-SE网络相较于YOLOv5-before在各项指标上都有大幅提高,其中AP值从0.85提升至0.97,提升了14%,改进后得到的YOLOv5-SE算法在识别精确率上相比用原图作为数据集的方法得到了提升。此外,增加SE注意力机制后,训练周期数相比之前也减少了50%。

图6 三种算法的识别结果对比
4 结论
为了有效且较精准地检测出视频中的鳕鱼目标,本文先利用UWGAN生成对抗网络以及鳕鱼数据集生成fakeimage,其次利用Deep WaveNet进行颜色以及细节矫正,最后使用相对全局直方图拉伸算法进行亮度以及对比度调整。相比其他算法,本文使用了深度学习算法与非深度学习算法相结合的方法,客观上在UCIQE和UIQM指标上均优于其他算法,在主观上也相对优于其他算法。对于本文中改进的YOLOv5算法,其引入了SE注意力机制,不仅训练周期数相比之前减少了50%,准确率也得到了提高。
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:07:12
数学物理学报(2022年2期)2022-04-26 14:08:04
燃气涡轮试验与研究(2021年6期)2021-08-01 03:09:10
海洋信息技术与应用(2020年4期)2021-01-18 06:21:36
自我保健(2020年4期)2020-06-19 02:10:48
小哥白尼(野生动物)(2019年4期)2019-09-10 07:46:12
中国生物医学工程学报(2019年5期)2019-07-16 07:56:50
金桥(2018年4期)2018-09-26 02:24:54
北京航空航天大学学报(2017年3期)2017-11-23 05:14:58
红领巾·萌芽(2015年10期)2015-09-10 07:22:44
