
基于双判别器生成对抗网络的PET和MRI图像融合*
2022-07-26 07:14:52贺天福康家银武凌霄姬云翔
江苏海洋大学学报(自然科学版) 2022年2期
贺天福,康家银,武凌霄,姬云翔
(江苏海洋大学 电子工程学院,江苏 连云港 222005)
近些年来,现代医学影像技术更新迅速,新技术和新设备在医学诊断与治疗中发挥了重要作用。经各类医学成像设备采集到的医学图像,在一定程度上能够呈现人体的不同信息,从而有助于医生更加直观、精确地掌握患者的身体状况。磁共振成像(magnetic resonance image,MRI)是一种结构型成像,能够提供反映人体软组织与神经血管等解剖结构的高空间分辨率信息[1];正电子发射断层扫描(positron emission tomography,PET)图像是一种功能型成像,它能够提供反映人体细胞代谢活动的信息,从而有助于发现异常状况[2]。这两类医学成像设备的成像方式存在差异,使得单一模态的医学影像仅能够在某一层面反映人体的部分信息而无法相对完整地反映人体的真实状况。影像融合技术可将MRI与PET这两种不同模态的医学影像进行整合,实现各自信息的优势互补,从而使融合得到的图像既能够保留MRI图像中丰富的空间结构信息,又能够保留PET图像中所呈现的人体功能信息,进而有助于临床医生进行疾病的有效诊断。
针对多模态医学影像的融合问题,研究人员已经提出了许多不同的策略与算法。第一类备受关注的方法是基于多尺度变换的方法,该类方法的实现包含3个部分:图像变换,按照一定的融合规则进行融合,以及图像逆变换。截至目前,研究人员已提出了多种基于多尺度变换的图像融合方法,如基于小波的方法[3]、基于非下采样轮廓波变换(non-subsampled contourlet transformation,NSCT)[4]和非下采样剪切波变换(non-subsampled shearlettransformation,NSST)[5]等,这些方法都在多模态医学图像的融合中展现了良好的效果。基于多尺度变换的医学图像融合方法能够根据对应的变换域空间特点灵活地设计相应的融合规则,但此类方法往往会在源医学图像变换至对应变换域后产生一定程度的图像失真问题。第二类常用于医学图像融合的方法是基于稀疏表示(sparse representation,SR)[6]的方法。此类方法后续发展为采用联合稀疏表示(joint sparse representation,JSR)[7]、组稀疏表示(group sparse representation,GSR)[8]等进行多模态医学图像的融合。该类方法的重点在于稀疏表示字典的构建以及目标函数优化方法的选择。采用稀疏表示能够以线性组合的方式较好地表示源医学图像,与此同时能够节省存储空间,但却会在融合图像中产生块效应,导致融合图像对源医学图像的细节保持不完整。第三类用于图像融合的方法是基于边缘保持滤波的方法。该类方法因其良好的性能被相关学者关注,文献[9]提出了一种用于图像融合的引导滤波算法。文献[10]将局部拉普拉斯金字塔滤波引入到解剖和功能图像的融合中。这种分解策略不仅保留了边缘,而且增强了细节,同时还较好地保留了能够反映图像功能信息的伪彩色信息。
近年来,深度学习在自然语言处理与图像处理等各个领域都有巨大的发展,国内外研究者也将其应用于图像融合领域。采用深度学习的图像融合方法,在一定程度上能够避免传统的图像融合方法的缺陷。基于深度学习的医学图像融合方法中常用方法之一是基于卷积神经网络(convolutional neural network,CNN)的方法。该类方法利用网络中卷积层优秀的图像特征提取能力对源图像进行特征提取,然后结合特征图或其他方法将提取到的特征进行融合。文献[11]提出了一种用于医学图像融合的多尺度残差金字塔注意力网络(记为MSRPAN),该网络由一个特征提取器、融合器和重构器组成,其中在特征提取器部分采用3个MSRPAN块来提取医学图像的多尺度特征。另一种常见的利用深度学习策略进行图像融合的方法是基于生成对抗网络(generative adversarial network,GAN)的方法。文献[12]首先将生成对抗网络应用到图像融合领域,提出了FusionGAN模型,通过网络生成器与判别器的对抗保留红外图像与可见光图像的信息,但采用单一判别器使得生成器随着对抗训练的深入而偏向于可见光图像。文献[13]提出了DDcGAN网络,该方法通过在生成器中使用反卷积,并采用双判别器,使得生成器生成图像时能够对不同分辨率的源图像进行融合从而得到较高分辨率的融合图像,但生成器所采用的编码—解码器网络使得图像浅层特征的利用率较低;此外,在融合PET与MRI图像时,模型的损失函数不能较好地平衡不同模态的医学图像信息。文献[14]提出了DSAGAN模型,该模型通过采用双支路机制分别提取两种源图像的信息,并与注意力机制相结合更好地对特征进行提取和选择,以达到较好的融合效果,但由于其采用双支路结构,使得模型在特征提取过程中能够同时利用两种源图像特征的融合层数目较少,从而缺乏对图像浅层特征直接应用。这些方法展现了优异的性能,但也存在一些不足,如融合得到的图像往往较为模糊,且对细节部分的保留不够充分。文献[15]则通过在特征提取网络中插入原始可见光图像,一定程度上增强了融合图像中的结构性信息。
基于以上分析,本文提出了一种基于双判别器生成对抗网络的PET和MRI图像融合模型。该模型的主体由一个生成器网络和两个判别器网络组成,其中生成器部分通过采用密集连接来保证图像信息的高效利用,同时在生成器网络中用于特征提取的中间层级额外引入MRI图像以提高生成图像的密集结构信息。具体过程为:首先通过图像的彩色空间变换将PET图像由RGB空间变换到YCbCr空间;再将PET图像的Y分量与MRI图像联结后输入到生成器网络;然后将通过生成器所生成的图像和真实图像分别输入到两个判别器中,通过进行循环对抗来不断提升生成器与双判别器的能力,最终达到平衡,从而使得生成器能够生成一幅既包含原始MRI图像的空间结构信息又包含原始PET图像的功能信息的融合图像。
1 相关工作
1.1 生成对抗网络
生成对抗网络[16]于2014年由Goodfellow提出,该网络通常由两部分构成,即生成器网络和判别器网络,其中,生成器网络根据对应的输入生成类似于真实目标的高维分布的假数据,而判别器网络则要尽可能地分辨出通过生成器网络所生成假数据和真实数据。生成器和判别器网络通过二者之间的互相对抗与博弈来提升各自的能力,最终达到一个动态平衡,即判别器网络已经无法判断输入的数据是来自于生成器所生成的数据还是来自于真实数据,此时的生成器网络已经学习得到了真实目标的高维数据分布[17]。具体而言,生成对抗网络通过以下的目标函数进行优化:

(1)
其中:V(D,G)为目标函数,G表示网络的生成器,D表示网络的判别器;x表示真实数据,z表示输入的随机噪声;Pdata(x)表示真实数据分布,Pz(z)表示希望得到的生成分布。
1.2 YCbCr彩色空间
MRI图像为灰度图像,它能够呈现人体的结构信息,包括纹理细节和密集结构信息。而对于PET图像而言,它通过放射性示踪剂的摄取情况反映人体重要的功能信息,通常表现为伪彩色的RGB图像。为了便于实现MRI(灰度图像)和PET(伪彩色图像)的融合,需要对PET图像进行颜色空间的变换。本文将PET图像由RGB彩色空间变换为YCbCr彩色空间。变换后的PET图像包含3个分量,分别为Y,Cb和Cr,其中Y分量主要包含能够反映PET图像整体结构与亮度变化的亮度信息,而Cb与Cr分量则分别反映了原图像的蓝色与红色的浓度偏移量成份。由RGB至YCbCr的变换过程如下:
(2)
2 本文算法
2.1 融合的总体框架
基于前述生成对抗网络、YCbCr变换等方法,本文提出了基于双判别器生成对抗网络的PET与MRI图像融合框架,如图1所示。
图1中,IM,IP分别为MRI和PET图像;IP-Y,IP-Cb和IP-Cr分别为PET图像经过YCbCr变换得到的3个分量;Generator为生成器,Discriminator-M和Discriminator-P为两个判别器,分别对应MRI图像与PET图像经YCbCr变换得到的IP-Y分量;IF-Y为经过生成器生成的图像,IF为最终的融合图像。
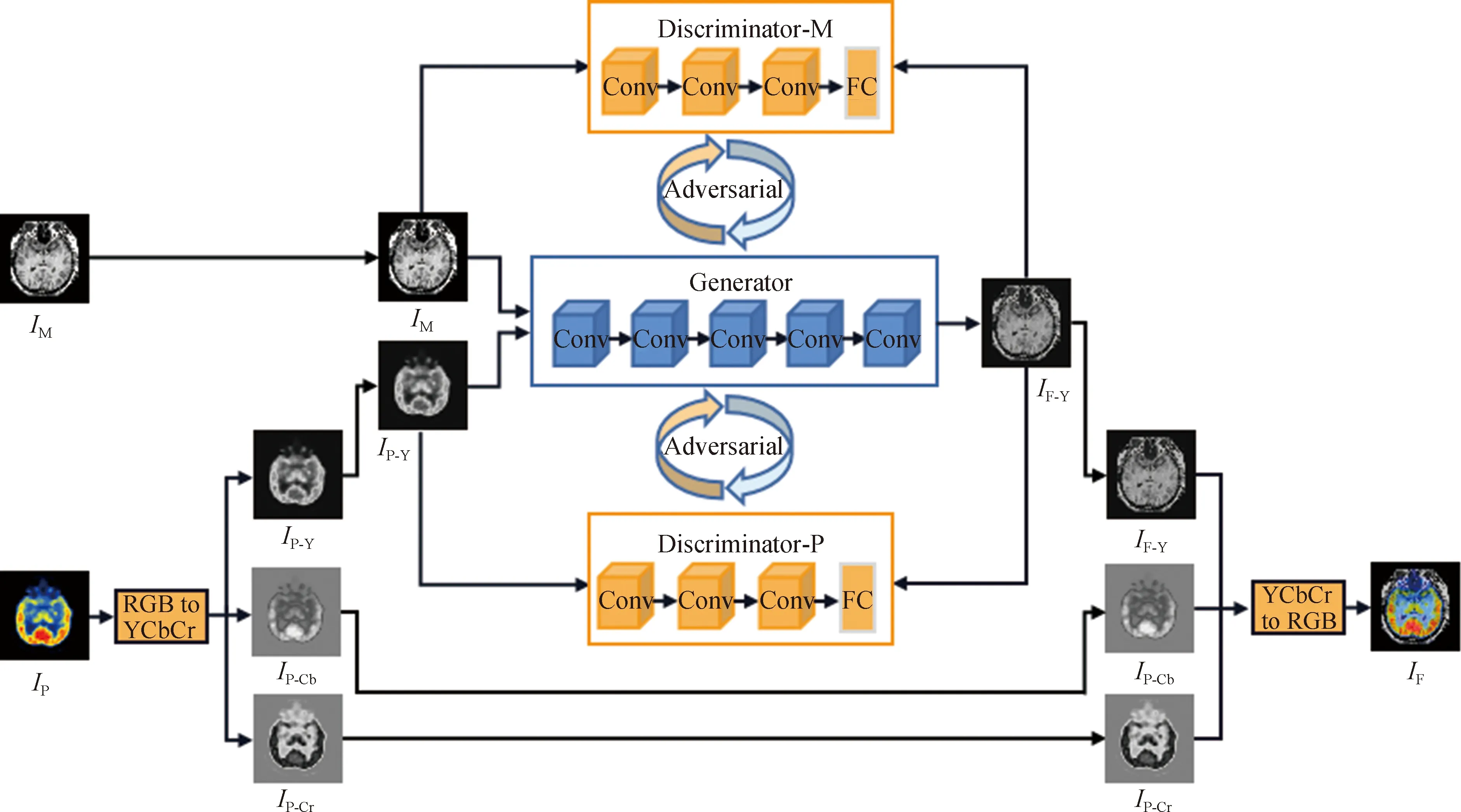
图1 总体融合框架
如图1所示,整个融合框架包含一个生成器和两个判别器,具体融合步骤如下。
(1) 将IP进行YCbCr变换分别得到IP的Y,Cb,Cr 3个通道的分量图像IP-Y,IP-Cb和IP-Cr。
(2) 将IM与IP-Y输入到生成器中,生成器提取输入图像的特征信息并进行特征选择,然后融合生成IF-Y。需要指出的是,此步骤需要事先完成生成器网络的训练过程。生成器网络的训练过程为:首先将IM与IP-Y图像输入到生成器网络;然后将生成器网络所生成的IF-Y分别与IM,IP-Y输入到对应的判别器Discriminator-M和Discriminator-P中进行鉴别;接下来,依据生成器与判别器的输出结果对生成器和判别器的网络进行对抗训练和交替更新,直至达到网络平衡。此时训练得到的生成器网络就是所需的用于PET和MRI图像融合的生成器。
(3) 将生成器网络生成的IF-Y分量图像与对应的PET图像的IP-Cb,IP-Cr两个分量图像进行YCbCr的反变换,从而得到最终的融合图像IF。
2.2 损失函数
2.2.1 生成器损失函数 为了避免生成器生成的图像趋向于平滑而丢失源图像中丰富的细节信息,本文在设计生成器的损失函数时采用混合损失,从表层信息以及深层语义信息两方面对网络整体进行约束。生成器的损失函数定义为
LG-total=Ladv+αLssim+βLgrad+γLper。
(3)
其中:LG-total为总损失,Ladv为对抗损失,Lssim为结构相似性损失,Lgrad为梯度损失,Lper为感知损失;α,β,γ分别为调整不同损失间的比例参数。每一种损失将在后续内容中分别详述。
(1) 对抗损失。对抗损失项由两部分构成,通过在训练过程中的平衡使得生成器能够同时保留两幅源图像的信息,具体定义为
Ladv=log(1-DM(IF-Y))+log(1-DP-Y(IF-Y)),
(4)
IF-Y=G(IM,IP-Y)。
(5)
其中:IF-Y为生成器所生成的图像,IM为原始MRI图像,IP-Y为原始PET图像经过YCbCr变换得到的Y分量;G为网络的生成器,DM为鉴别生成器所生成的图像与原始MRI图像的判别器,DP-Y为鉴别生成器所生成的图像与原始PET图像经过YCbCr变换的Y分量的判别器。
(2) 结构相似性损失。结构相似性损失项通过亮度、对比度、结构方面对生成器进行约束,使得输入的融合图像与源图像之间拥有一定的相似结构,具体定义为
Lssim=(1-SSIM(IF-Y,IM))+(1-SSIM(IF-Y,IP-Y))。
(6)
其中,SSIM(·)表示对输入的两幅图像进行结构相似性计算,输出一个小于等于1的标量,值越大表明两幅图像的结构越相似。
(3) 梯度损失。梯度损失主要衡量融合得到的图像分别与源MRI和PET的YCbCr的Y分量间的结构纹理等信息的差异,从而约束融合图像尽可能多地包含源图像的细节和纹理信息,具体定义为
Lgrad=η||IF-Y-IM||TV+ρ||IF-Y-IP-Y||TV。
(7)
其中:||·||TV为TV范数;η,ρ分别为调整不同损失间的比例系数。
(4) 感知损失。感知损失主要用来衡量图像特征信息的保留情况,以此对生成器进行深层次约束。具体过程为:将生成器所生成的融合图像与源图像分别输入到预训练好的VGG19网络中;通过VGG19网络对图像进行特征信息提取,得到源图像在深层语义上的表现;通过计算融合图像与源图像在深层语义表示上的区别来考量图像特征信息的保留情况。本文选择了VGG19网络中的第3,8,17和26共4层作为图像的感知特征层,并且选择从像素内容上进行深层约束,从梯度方面进行生成器融合图像与MRI图像的相似性约束。感知损失具体定义为
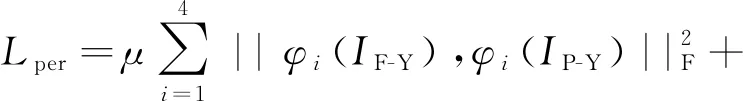
(8)
2.2.2 判别器损失 对于判别器损失,本文选择两个网络结构相同的判别器并采用相同的损失函数,来区分生成器生成的图像与原始输入的图像,并通过判别器来促使生成器产生符合原始图像纹理与强度的融合图像。判别器的损失函数为
LD=LDM+LDP-Y,
(9)
LDM=E(-log(DM(IM)))+E(-log(1-DM(IF-Y))),
(10)
LDP-Y=E(-log(DP-Y(IP-Y)))+E(-log(1-DP-Y(IF-Y)))。
(11)
其中:LDM为对MRI与融合图像进行判别的损失,LDP-Y为对PET的Y分量和融合图像进行判别的损失;E(·)表示取平均值操作。
2.3 网络结构
2.3.1 生成器网络结构 本文生成器的网络结构如图2所示。生成器网络由5层卷积组成,采用密集连接策略以增强图像信息在网络中的传递,此外通过将密集连接后的特征再与原始的MRI图像联结,作为后续网络的输入以增强生成图像中的密集结构信息,从而更好地表现图像的细节信息。第一层至第四层均选择3×3的卷积核,激活函数选择为LeakyRelu函数,最后一层则通过使用1×1卷积核滤波器进行信道降维,选择非线性函数Tanh进行激活;n为卷积输出通道数,分别为256,128,64,32,1;所有卷积层的步长均为1。
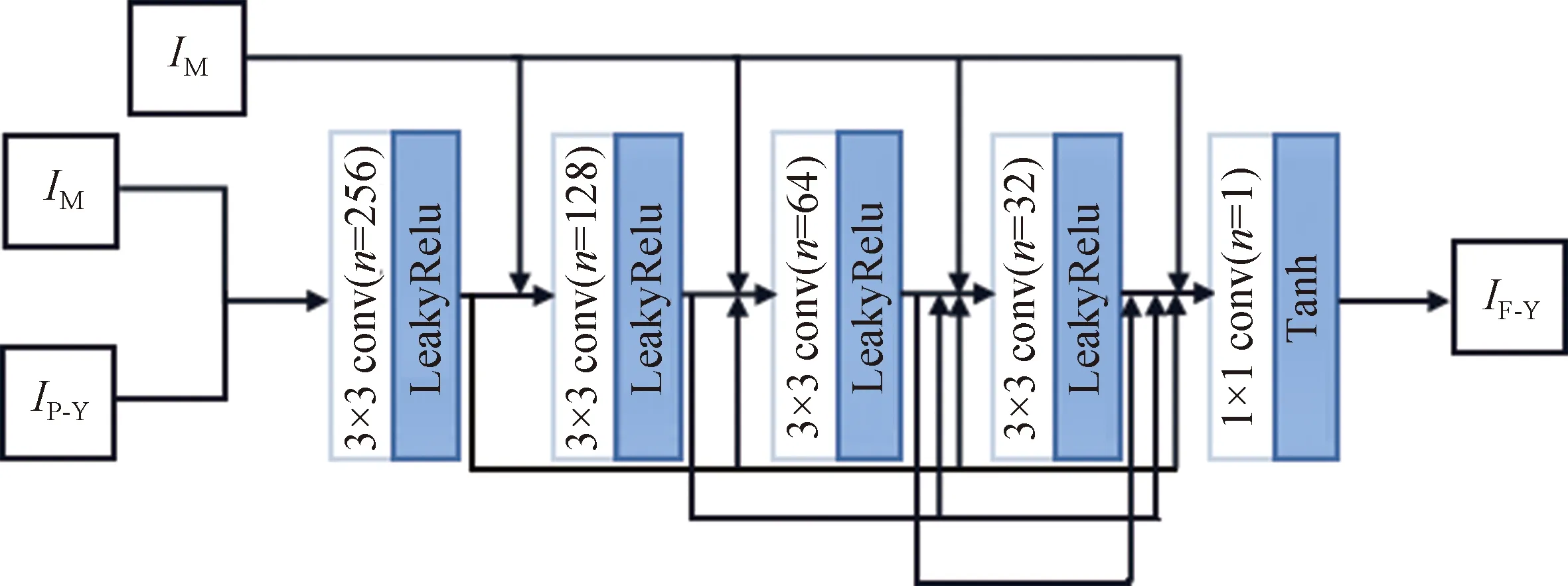
图2 生成器网络结构图
2.3.2 判别器网络结构 本文采用的判断MRI与融合图像的判别器的结构如图3所示,其中第一层至第三层选择卷积层进行特征提取,最后一层利用全连接层(fully connected,FC)汇集信息并作出决策。第一层选择3×3的卷积核,激活函数选择为Relu函数;第二层与第三层也采用3×3的卷积,并使用BN(batch normalization)层进行归一化操作,激活函数选择为LeakyRelu函数;三层卷积层的步长均为2;最后一层FC层,选择非线性函数Tanh进行最终决策,生成一个0到1间的标量值从而对输入图像进行判断。对于用于判断PET图像的Y分量与融合图像的判别器而言,由于其功能与判断MRI和融合图像的判别器功能类似,因此本文采用与判断MRI和融合图像的判别器相同的网络结构。
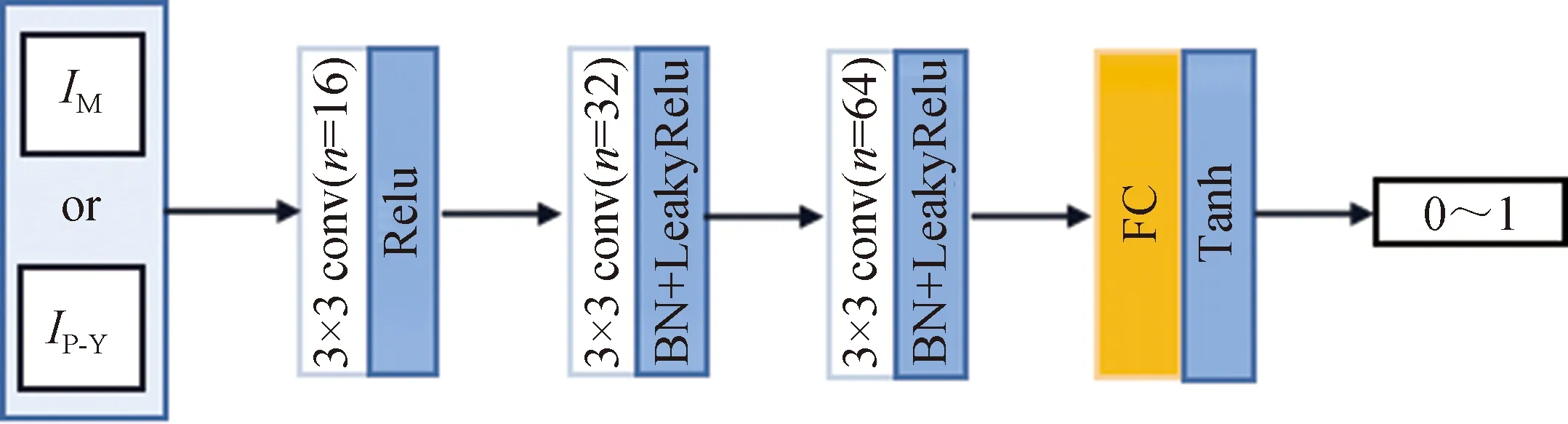
图3 判别器网络结构图
2.4 训练过程
(1) 初始化生成器与两个判别器的网络参数,将MRI和PET图像的Y分量图输入到对应的判别器中,根据输出结果对判别器的参数进行更新。
(2) 将MRI和PET图像的Y分量图联结后输入到生成器网络中,得到生成器生成的融合图像,结合对应的生成器损失对生成器网络参数进行更新。当生成器总损失LG-total大于LG-max时重复此过程至多20次。
(3) 将MRI和PET图像的Y分量图与生成器生成的图像分别输入到对应的判别器中,根据输出结果对判别器的参数进行更新。当判别器损失LD小于LD-min或大于LD-max时重复此过程至多5次。
(4) 重复过程(2)和(3)直至网络达到平衡状态。
上述训练过程中,LG-max为第一批源图像输入到生成器所得到的生成器损失的0.7倍;LD-min设置为1.2,LD-max设置为1.8。此做法的目的主要是调节两个判别器损失间的平衡,从而加速网络训练过程。上述训练过程的运行环境为Pytorch框架、Python3.6.13平台;硬件环境为GeRorce RTX-2080Ti GPU 和 Intel(R)Core(TM) i5-8265U CPU。
3 实验结果及分析
3.1 实验设置
3.1.1 数据介绍 本文中用于实验的PET和MRI图像均取自于哈佛大学医学院的“全脑”(The Whole Brain)数据集(http: //www.med.harvard.edu /aanlib/),图像原始大小均为256×256。本文从“全脑”数据集中随机选择51对图像作为网络的训练数据。在对图像边缘进行尺寸为4的零值填充后,通过将步幅设为18将成对的图像进行裁剪,使PET与MRI图像块的大小为84×84像素,如此操作后共得到5 100对PET和MRI图像块。在测试阶段,从“全脑”数据集中随机挑选20组图像来测试训练所得的模型的性能。
3.1.2 参数设置 本实验中,用于调节生成器总损失项LG-total的参数α,β,γ分别设为10.0,5.0,0.2;调节生成器梯度损失项Lgrad的参数η,ρ分别为1.1,1.0;调节生成器感知损失项Lper的参数μ,ν分别为0.1,10;网络的参数优化器选择为RMSprop优化器;学习率设为2×10-3,平滑常数设为0.9,每个批尺寸的大小设为24,总的迭代次数设为3。
3.1.3 评价指标 为了对不同算法的融合结果进行客观评价和分析,本文选择了以下8种常用的图像融合评价指标:结构相似性(structural similarity,SSIM)[18],从亮度、对比度、结构三方面度量源图像与融合图像的相似性,其值越大表示融合图像越接近原始图像;基于梯度的融合性能指标Qab/f[19],衡量融合图像与源图像间的相似边缘,其值越大表示融合图像拥有更多原始图像的边缘细节信息;信息熵(entropy,EN)[20],衡量融合图像所包含信息量的多少,其值越大代表融合图像中含有越多的信息量;基于噪声评估的融合性能指标Nab/f[21],评价图像融合过程中引入的噪声信息的多少,其值越小代表融合后的图像引入了更少的噪声;相关系数(correlation coefficient,CC)[20],度量融合图像与原始图像间的线性相关度,其值越大代表融合越贴近原始图像;边缘强度(edge intensity,EI)[20],评价融合图像的边缘锐化程度,其值越大代表融合图像质量越好;空间频率(spatial frequency,SF)[22],通过图像在空域的梯度分布来度量融合图像细节信息的丰富程度,其值越大表示融合图像拥有更多的细节信息;人类视觉敏感度指标Qcb[23],通过取全局质量平均图来测算图像质量,其值越大表示融合图像质量越好。
3.1.4 对比算法 本文选择了3种基于生成对抗网络的图像融合方法,在20组测试图像上从主观与客观两方面对融合结果进行分析与评价。3种用于对比的方法分别来自于文献[12](记为DDcGAN)、文献[13](记为FusionGAN) 和文献[14](记为DSAGAN) 。
3.2 实验结果
3.2.1 主观评价 对融合结果的主观评价主要通过肉眼观察进行,即通过目视判读图像的融合效果,如图像的颜色、亮度以及真实度等。换言之,对融合结果的主观评价主要为判断融合图像能否在视觉上较为完整地展现源图像的信息。图4和图5分别展示了两组PET和MRI图像通过4种不同方法得到的融合结果。为了便于比较,本文用矩形框标注出图像中差异较大的部分。
图4所示的第一组融合结果中,采用FusionGAN方法得到的融合结果虽然对源PET图像的功能信息保留较为完整,但严重丢失了源MRI图像中较为显著的结构信息;采用DDcGAN方法得到的融合图像存在诸如源PET图像部分功能信息丢失、源MRI图像中结构信息保留不明显等问题;采用DSAGAN方法得到的融合结果能较丰富地保留源PET图像信息,但从源MRI图像中保留的结构信息存在一定的伪影;而本文方法在保留源PET图像功能信息与源MRI图像显著结构信息间取得一定平衡,从而将源MRI图像中存在的较为显著的结构在融合图像中完整地表现出来,得到的融合结果比较迎合人眼的视觉效果。
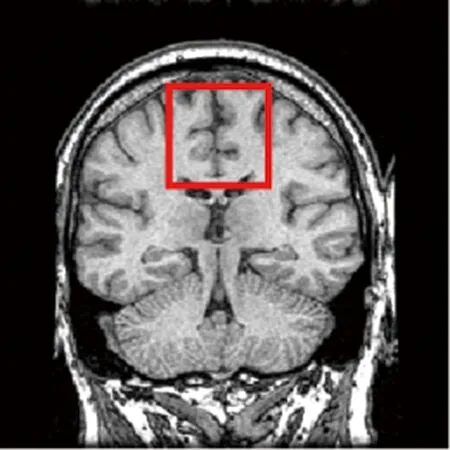
a MRI
图5所示的第二组融合结果中,采用FusionGAN方法得到的融合结果对源MRI图像中的结构性信息保留不充分,边缘轮廓不够明显;而采用DDcGAN和DSAGAN方法得到的融合图像能够一定程度地保留源MRI图像中的小尺寸结构信息,但图像中小尺寸结构的边缘效果较为模糊;相对地,本文方法对源MRI图像信息的融合更充分,得到的融合结果中小结构信息丰富清晰,整体主观视觉效果更好。
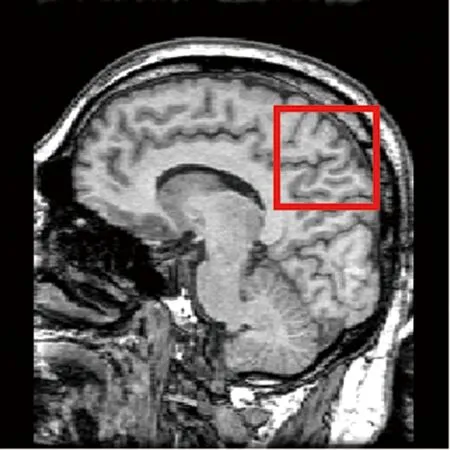
a MRI
3.2.2 客观评价 为了进一步评价所提方法的融合效果,本文利用“3.1.3”中引入的量化指标对不同算法所得的融合结果进行客观、定量的评价,评价结果具体如表1所示,其中粗体表示效果最佳者。
由表1可知,本文所提方法在SSIM,Nab/f,Qab/f,CC,SF,EI与Qcb等7个客观评价指标上都得到最佳值。本文方法所采用的生成器网络在使用密集连接的同时引入了结构信息丰富的源MRI图像,并且,相较于其他几种方法,本文方法在生成器网络的损失函数中对梯度等结构信息给予了更多的关注,因此在SSIM,Qab/f,SF和EI等更关注图像边缘结构和纹理等信息的指标上取得了最佳值。本文方法中生成器网络的整体深度较浅,并且在网络层中未采用BN层以降低对数据的依赖,从而能够更好地保留网络所提取的浅层特征,随之减少了因特征丢失而引入的额外噪声,因此在Nab/f与CC指标上达到最佳值。在Qcb指标上取得优异性能,表明本文所提方法所生成的融合图像在对比度方面表现良好,更为符合人类视觉系统。在EN指标上本文方法表现欠佳,主要原因在于为了提升融合图像的结构信息,本文方法在融合的过程中比较关注结构信息丰富的源MRI图像,却不可避免地导致源PET图像的信息有所损失。综上所述,本文所提方法就定量指标而言,总体优于对比的其他几种方法,取得了更好的融合结果。

表1 不同方法在融合20组MRI与PET图像时的融合结果
为了更直观地展示不同方法在融合PET和MRI图像时的客观效果,图6显示了4种方法在融合20组成对MRI与PET图像时各个量化指标的情况。
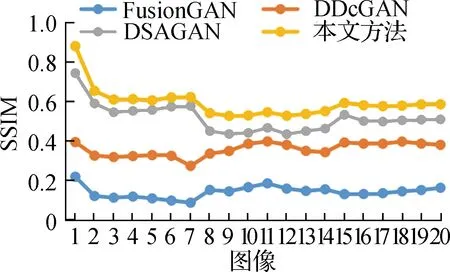
a SSIM
此外,为了比较不同算法在融合PET和MRI图像时的效率,本文测试了不同算法在融合20组测试图像时的平均运行时间,如表2所示。

表2 不同融合方法的平均运行时间
如表2所示,本文所提方法的运行时间略逊于DSAGAN方法而高于其他两种方法,由此可知本文所提方法在保证图像融合效果的情况下有较高的运行效率。
4 结论
本文提出了一种基于双判别器生成对抗网络的PET和MRI图像融合方法。所提方法是一种端到端的网络模型,在图像的融合过程中无需设计复杂的融合策略。本文方法总体上由一个生成器和两个判别器构成,其中生成器在采用密集连接的同时还在部分层级引入源MRI图像,以便更好地在网络中传递图像特征,从而提升融合图像的细节纹理等信息;同时,通过两个结构相同的判别器不断提升生成器的性能。损失函数方面,采用混合损失,即通过结构相似性、梯度、感知与对抗等损失对生成器同时进行表层及深层约束。在公开的数据集上进行的实验结果表明,本文方法在主观视觉效果与客观定量评价方面均取得了较优的结果。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17 08:08:06
江西教育·职教版(2022年9期)2022-04-29 00:44:03
今日农业(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:38
作文小学中年级(2020年6期)2020-07-24 08:33:10
现代出版(2020年3期)2020-06-20 07:10:34
今日农业(2019年15期)2019-01-03 12:11:33
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
