
基于多标签分类的数字图书馆文本特征抽取方法研究
2022-07-21 02:57周黎源
自动化技术与应用 2022年6期
周黎源
(上海城建职业学院 图文信息中心,上海 201999)
1 引言
数字化图书馆是存储结构化信息的数字化资源库,传统图书馆、博物馆、档案馆、大学、政府部门、专业机构或个人都可以获得这些数字资源[1-2]。数字化图书馆的最终目标是使人们可以在任何时间和任何地点使用任何与因特网相连的数字设备,从而获得人类所需的知识[3-4]。数字化图书馆需要进行文本特征提取,作为一种有效的降维技术,特征提取在多标签文本分类中有着广泛的应用[5]。
赵勤鲁等人提出基于LSTM-Attention 神经网络的文本特征抽取方法,首先分别使用LSTM网络对文本的词语与词语和句子与句子的特征信息进行抽取,其次使用分层的注意力机制网络层分别对文本中重要的词语和句子进行选择,最后将网络逐层抽取到的文本特征向量使用softmax 分类器进行文本分类[6]。但是该方法在抽取文本特征时,文本特征不完整。李杰等人提出了基于深度学习的产品特征抽取方法,采用卷积神经网络进行短文本评论情感分类,以情感分类标签标注相应评论中提抽取的产品特征词,并利用词向量对产品特征词聚类,通过爬取的笔记本电脑和手机评论对方法进行训练和测试[7]。但是该方法的文本特征抽取准确率较低。
针对上述方法存在的问题,本文提出基于多标签分类的数字图书馆文本特征抽取方法。
2 基于多标签分类的文本特征研究
在多标签分类的基础上,对文本特征进行研究,以适应分类样本中存在多标签的情况,它在基因功能识别,音乐情感分类,图像语义标注等方面有着广泛的应用[8]。多个识别的具体步骤:
(1) 从引文功能标签集合L 中随机选取m 个k 子集,组成集合Lm。
(2) 对集合Lm中的任意元素Lk,将其所有集合都标记为L'k。结合单标签分类算法作为训练分类器hk;输入引文功能标签集合样本,输出集合标签的任意元素。
(3) 对集合中的任意元素按照步骤(2)训练,得到m 个分类器。
(4) 针对新的引文全局功能分类设计,应遵循步骤(3),从中可得到m个分类结果,由此组成集合Qm。
对每个L中的标签li进行如下操作:设定=0。将集合Qm中li的个数记为Sli。设定一个阈值t。标签集合L 中ti>t的标签组成的集合即为该样本的引文全局功能集合[9]。
图1是一个引文句功能合并示例。
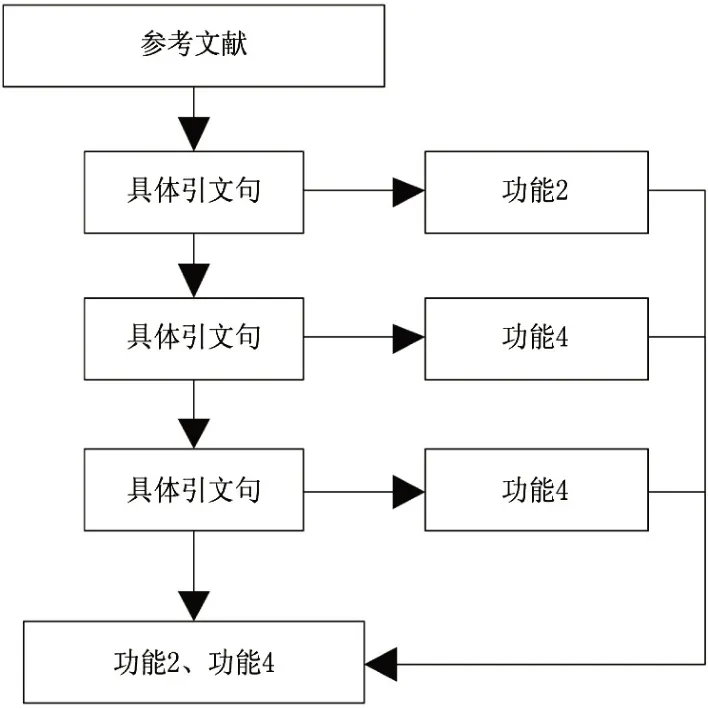
图1 引文句功能合并示例
(1) 词汇特征
词汇学特征一直是数字图书馆文本的核心特征,词汇表中的词语是否包含在引文中作为词汇的特点。另外,为了弥补有限的词汇覆盖范围,还选取了1-Gram作为词汇特征[10]。
(2) 句法特征
在被引的语境中,除了词汇本身能够反映被引功能外,某些特定的句型和语法结构也能反映被引功能。
(3) 物理特征
引文的物理性质决定了引文的分布和频率特点,不同地点的引文在功能上也可能有差异。所用分布特征包括:引文所在的章节、引文标记在引用句中的位置,以及能很好地识别“背景”功能性标记频谱特征。
(4) 整体特征
除引文主体的特点外,引文主体还具有某些特点,这些特点决定了引文的整体功能。
选定的参考级别特征包括:是否为自引,以及该参考在被引文献中被多次引用。
3 数字图书馆文本特征抽取
通过对基于多标签分类的文本特征的研究发现,文本分类的首要任务是在不影响分类效果的前提下,寻找降低矢量空间维数的方法。特征向量空间中剔除信息较少的词,使得向量空间的维数减少,即在文本分类中特征提取。图2显示了基于多标签分类的数字图书馆文本特征提取模型。
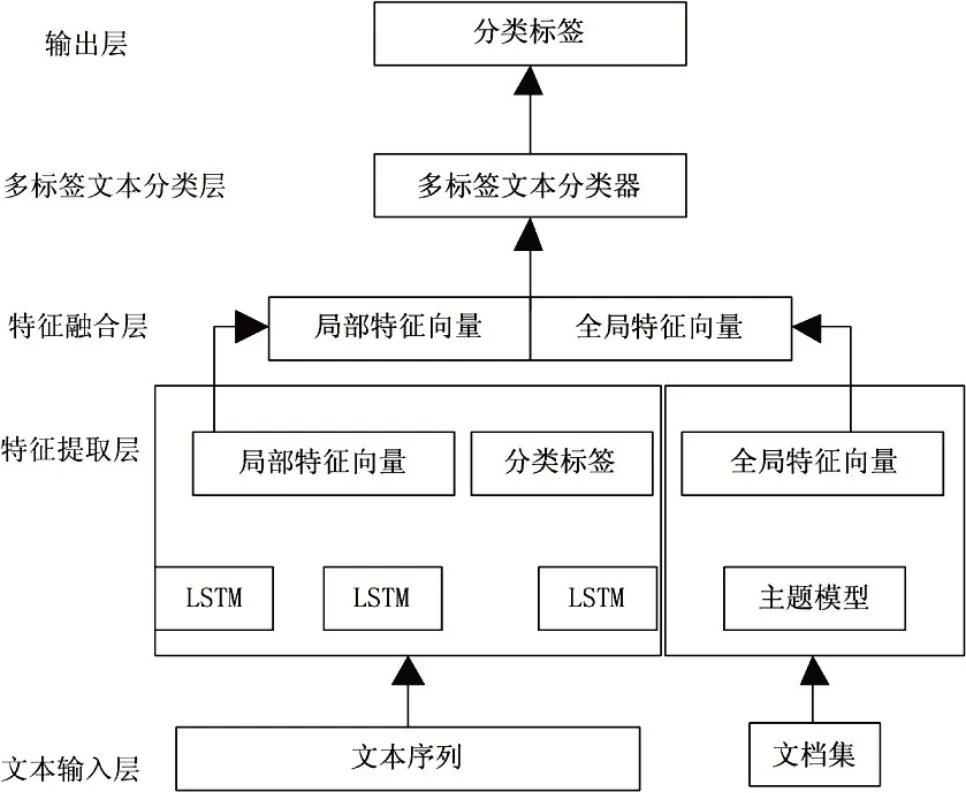
图2 基于多标签分类特征抽取模型
交互信息是用于测量两个随机变量之间的统计关系的信息论中的一个基本概念,基于互信息MI的特征选择,应从文本分类中随机选取一个常用的特征提取方式。结合最小二乘法,表示特征tk类Ci的相关性:
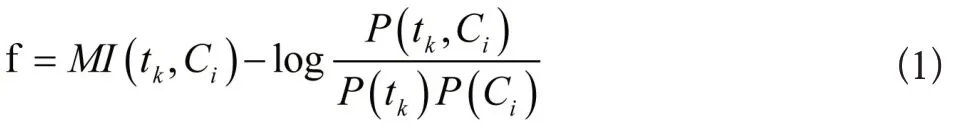
在上面公式中,P(tk,Ci)为类别Ci、特征tk同时出现的概率,P(tk)为特征tk出现的概率,P(Ci)为类别Ci出现的概率,P(tk|Ci)为特征tk在类别Ci中出现概率。
从上述公式中可看出,MI 算法是已给词和类别之间的独立关系,对每一个独立的词,将其在每一类中的出现概率与整个文本集合概率作对比,得到一类贡献量。根据公式(1)可知,如果计算出来的P(tk|Ci)的绝对值较大,那么可按照互信息算法排列顺序,此时可将P(tk|Ci)作为大负值的特征,并剔除tk,但是实际上,由此计算出来的结果只能说明具有tk特征。
如果tk特征不出现在类别Ci中,那么无法排除tk在其它类别中的重要性,结合MI算法计算方式,由此得到的特征tk容易被淘汰,因此,需要进一步改进,保留MI值大而为负的特征项。
MI 算法存在的另一个问题是,虽然用公式(1)计算出的特征词的概率不同,但其MI 值相同,该方法计算完毕后,在特征词的选取上容易出现问题。根据存在的问题,逐步对MI算法进行改进。以下是具体步骤:
(1) 在MI值为负的情况下,即使它很大,特征词也会被删除。这个计算步骤是:
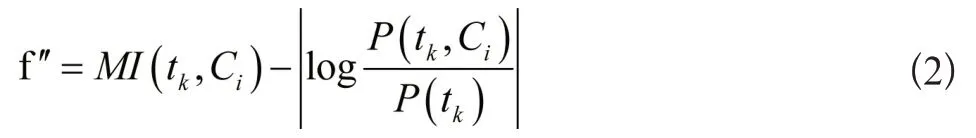
(2) 计算步骤如下,以防止不同概率的词在特定文档中使用相同的MI值:
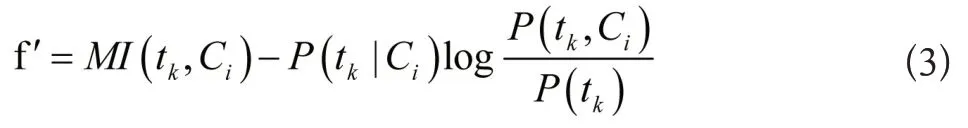
由此得到的新特征tk类别Ci的相关性为:
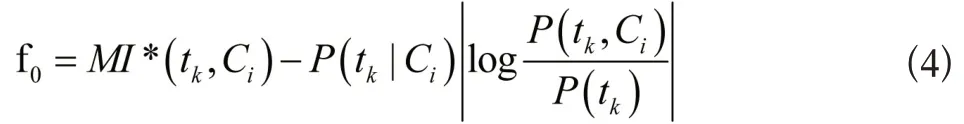
通过对上述内容的分析,提出了采用绝对值法和增加概率系数法的改进措施,避免了特征词的缺失,使特征在文档中的分类更加清晰。
4 实验
针对基于多标签分类的数字图书馆文本特征抽取方法研究进行实验验证分析。
4.1 实验平台设计
实验平台如软硬件环境如表1所示。
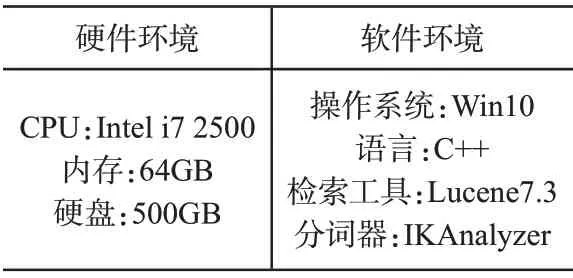
表1 实验平台如软硬件环境
4.2 实验步骤
首先选取了3190 篇与芒果遗传育种相关的论文,其中1190篇论文涉及芒果的遗传育种,其余4类主题文献为2000篇。将番茄遗传育种主题分为二级目标分类,其余4类为干扰分类。在课文集合中,每个选择1000 篇目标分类和干扰分类的文章作为训练集,剩下的1190 篇论文作为测试集,5个题目的比例为1:1,每题平均测试集文献近390篇。图3显示了特征提取和文本分类的实验过程。
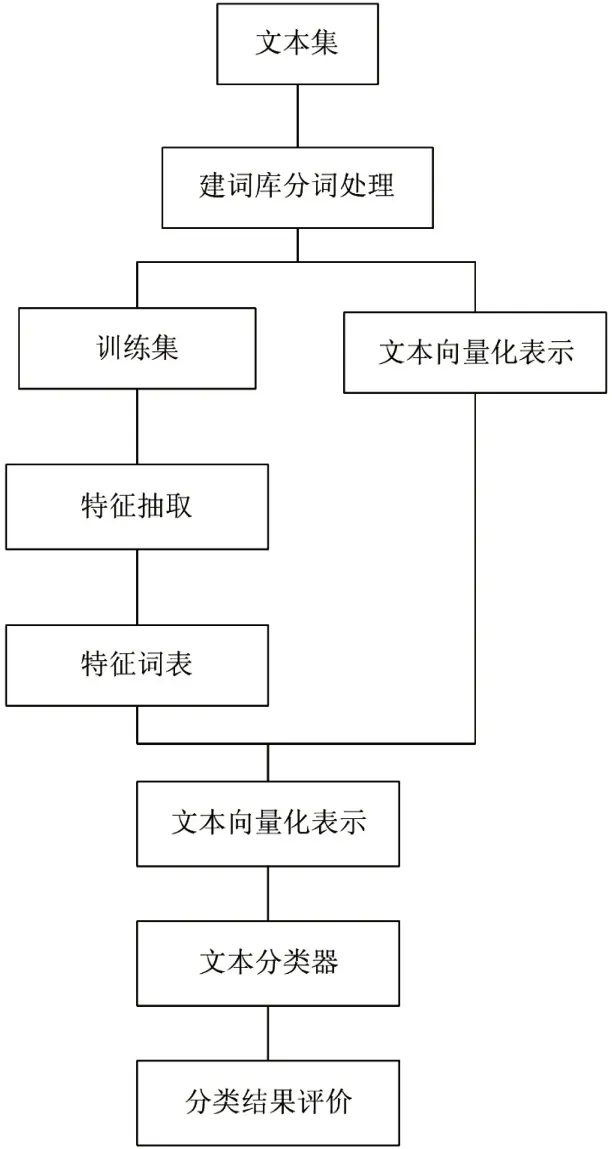
图3 特征抽取及文本分类实验流程
4.3 实验结果与分析
分别使用深度学习抽取方法、LSTM-Attention神经网络抽取方法、基于多标签分类抽取方法对抽取文本特征完整度、准确率展开分析,结果如下所示。
4.3.1 抽取文本特征完整度
针对抽取文本特征完整度研究,使用三种方法进行对比分析,结果如图4所示。
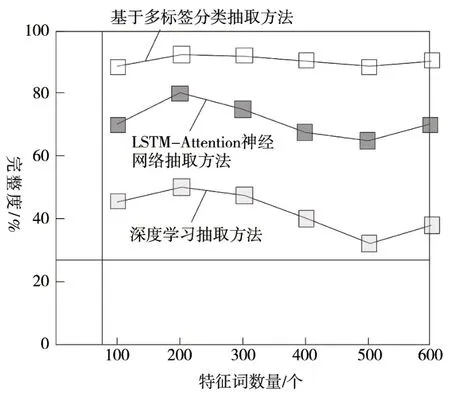
图4 三种方法抽取文本特征完整度对比分析
由图4 可知:使用深度学习抽取方法在特征词数量为500个时,特征完整度较低,为30%。当特征词数量为200个时,特征完整度较高,为52%;使用LSTM-Attention神经网络抽取方法在特征词数量为500 个时,特征完整度较低,为70%。当特征词数量为200 个时,特征完整度较高,为80%;使用基于多标签分类抽取方法在特征词数量为100个时,特征完整度较低,为90%。当特征词数量为200个时,特征完整度较高,为95%。因此,使用基于多标签分类抽取方法特征完整度较高。
4.3.2 抽取文本特征准确率
针对抽取文本特征准确率研究,使用三种方法进行对比分析,结果如图5所示。
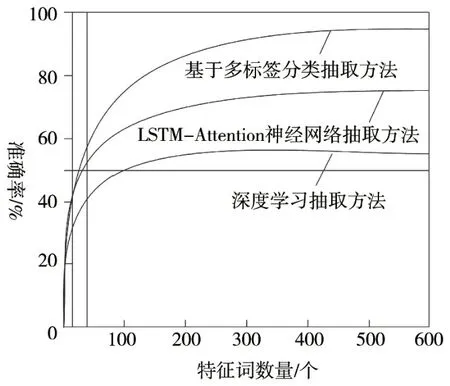
图5 三种方法抽取文本特征准确率对比分析
由图5 可知:使用深度学习抽取方法受到技术影响,导致部分特征不能完全抽取,准确率也降低,当特征词为300个时,准确率基本稳定在55%左右;使用LSTM-Attention神经网络抽取方法,在特征训练过程中易产生单一特征缺陷,导致部分特征不能完全抽取,准确率也降低,当特征词为400个时,准确率基本稳定在75%左右;使用基于多标签分类抽取方法最高抽取准确率可达到96%,因此,使用基于多标签分类抽取方法特征准确率较高。
5 结束语
利用多标签分类原理由主题模型得到文本的局部特征和整体特征;可在不同层次上提取文本特征,对文本功能的更全面探索。实验表明,与传统特征提取方法相比,在多标签特征提取模型中,基于不同数据集的分类性能有明显改善,其次,将所提出的多标签分类特征提取模型应用于序列模型,得到类别标签间的相关关系。
数字化图书馆是多学科融合的沃土,要想取得较好的效果,必须把各种信息处理和理解方法有机地结合起来。下一步工作方向是:
(1)日志挖掘技术在数字图书馆中的应用,通过对用户日志的分析,发现其规律与模式,完善信息组织结构,提高信息查询效率。
(2) 数字化图书馆的信息和过滤技术,通过信息结构化处理和用户建模,实现数字化图书馆个性化信息服务。
猜你喜欢
陶瓷学报(2021年4期)2021-10-14
计算机系统应用(2021年9期)2021-10-11
少儿画王(3-6岁)(2020年4期)2020-09-13
现代信息科技(2020年18期)2020-02-22
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
计算机技术与发展(2018年8期)2018-08-21
计算机应用与软件(2018年1期)2018-02-27
