
Spark技术在自然资源数据管理中的应用研究
2022-07-21 02:57蒋凤钗
自动化技术与应用 2022年6期
蒋凤钗
(广东省国土资源技术中心,广东 广州 510075)
1 引言
在智能化和大数据背景下,如何加强自然资源机构信息化建设,推动国土资源数据管理的深入推进,是当前思考和研究的重点。而在“十三五”提出的《国家信息化规划》(以下简称《规划》)方案中,更是强调要以大数据作为基础,结合国土资源数据实际,建立纵向联动和横向协同结合的国土资源共享服务平台,并重点解决国土资源数据集成管理难、计算效率等和数据服务能力差的问题,高度实现我国国土资源空间数据治理能力的现代化。而近几年来,广东省国土资源部门严格按照《规划》要求,大力推动国土资源信息化管理,如构建一体化的数据资源管理中,建设国土资源信息管理与服务平台等,从而为自然资源业务管理提供了重要技术支撑,实现了跨部门、跨业务和跨层级的多业务应用。在取得以上成果的背景下,部分业务还有待进一步提升,如国土资源数据管理、大数据的国土资源数据分类等方面。而针对国土资源数据的管理,目前主流解决方案是采用Hadoop,依托该框架中的HDFS 文件管理系统实现国土资源数据的分布式存储[1-3];在数据分类方面,通常采用K-means[4-6]、SVM[7-9]等。但实践认为,Hadoop框架的高吞吐和低响应的特点已经不能满足实时大数据的应用需求[10]。因此本研究尝试结合国土遥感图像数据和Spark技术的特点,构建一个基于Spark的高效国土资源数据分类架构,并对该架构的进行试验验证,从而为国土资源数据的自动管理提供借鉴。
2 相关技术
2.1 Spark技术
目前主流的并行架构包含两类:一类是基于Hadoop的MapReduce 并行架构;一类是基于内存式计算的Spark,其中可兼容各种计算模式,且相对于Hadoop 讲,具有更高的性能。Spark的核心在于弹性分布式数据集,通过该数据集可将中间计算的部分或全部数据缓存在内存中,从而在并行计算中反复使用,且该数据提供了丰富的操作函数。Spark的执行流程如图1所示。
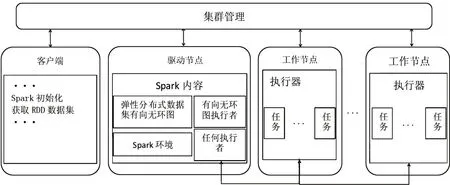
图1 Spark作业执行图
在上述的Spark 执行过程中,最为关键的包含三个阶段:一是驱动器节点生成RDD,这是Spark 计算的核心,通过将数据转换为RDD,从而执行不同的算子和函数;二是切分,目的是实现调度;三是生成任务,即将每阶段的转换到工作节点上执行。
2.2 SVM支持向量机
SVM 作为机器学习的一种,主要通过结构化风险最小的方式来提高自身的学习泛化能力,进而实现在样本较少的情况下,获取良好的统计规律。SVM 的基本思想是找到一个最优分类面,使正负类数据的分类间隔最大。具体数学描述为[11]:
设训练样本(xi,yi),xRn,y(-1,1),i=(1,2,…,l),l 表示样本数,n为维数。当线性可分的时候,则存在最优分类超平面,具体为:

对优化目标取极值,从而得到:
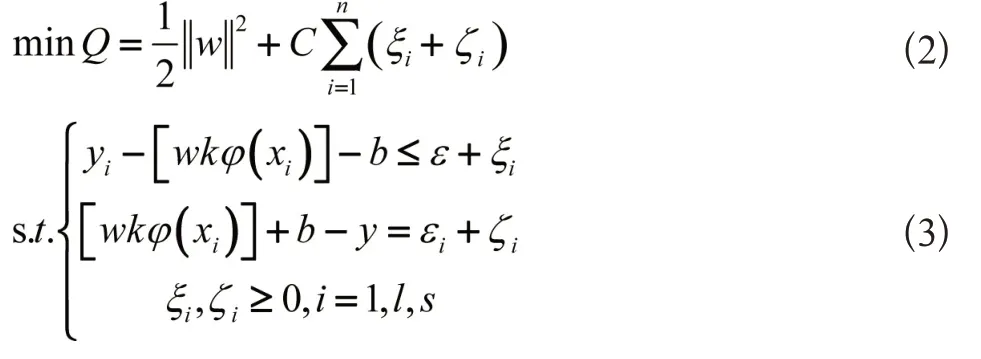
式(2)中,C为惩罚参数,ξi、ζi为松弛因子,ε表示损失函数。
引入Lagrange 乘子求解上述优化问题,从而得到最优决策函数为:
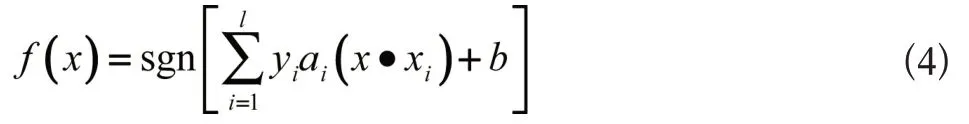
式(3)中,ai、bi为Lagrange系数,且根据K-T条件,上式的解必须满足:

而对于非线性分类时,SVM 只需通过核函数即可将样本映射到高维空间H中,进而经非线性问题转换为线性问题,最终在高维空间中实现分类。
3 基于Spark的SVM并行化分类
3.1 Spark并行化框架改进
传统的算法效率提高改进主要包含两类:一是采用Hadoop 框架中的MapReduce 并行框架对SVM 算法进行并行化处理,如刘倩(2018)通过MapReduce将数据集进行分块训练,然后再将训练后的数据集进行合并训练,以此大大提高了传统SVM算法运行的效率;二是对SVM算法和数据进行优化处理,如宫文峰(2020)通过对svm 的参数进行优化,并借助CNN神经网络对特征集进行筛选,以提高SVM算法自身数据分类的效率;刘金燕(2020)则在优化前,提出对分类数据进行处理,剔除其中的无效数据,以提高分类的效率和准确率。以上基于SVM 的改进主要是通过MapReduce 并行化,或者是对SVM算法本身进行改进,以此来提高算法分类效率和准确率。但MapReduce在处理数据是需要与其他节点保持高度并行,而Spark 对特定的数据集进行高效迭代。因此,基于以上的考虑,本文引入Spark 框架进行并行化处理,以提高SVM分类算法处理效率。与此同时,传统的遥感图像分类主要是依赖于MPI 多进程,即借助MPI 整体并行控制能力,将海量数据的计算转为分布式计算,从而将大任务分解为多个小任务。但单一的MPI也存在局限,即不同实现不同集群节点信息的共享,且计算能力受到限制。CUDA 具有强大的单机计算能力。综上本研究尝试在Spark 环境下,在MPI 多进程中嵌入CUDA 并行框架。在发挥CUDA 的单机计算能力同时,又利用MPI 的整体并行控制能力和问题分解能力,具体改进框架如图2所示。
根据图2的并行处理框架,首先在每台集群节点服务器上安装HDFS、Spark、MPI等,在安装完成后,将数据上传到HDFS文件储存系统中,然后执行Spark程序,进而实现MPI将数据分发给子进程,而CUDA发挥单机计算优势,实现高效率的并行计算。
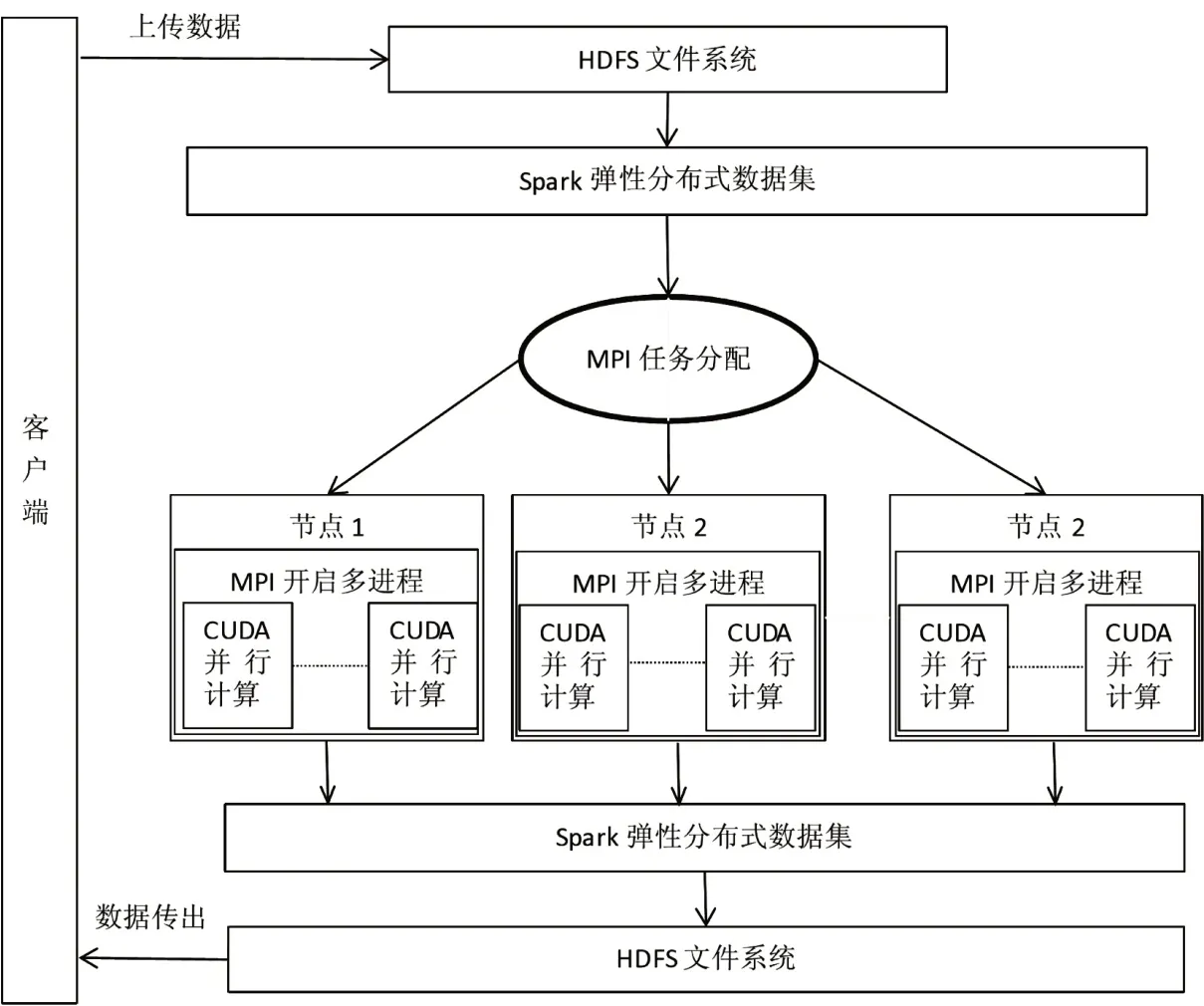
图2 基于Spark的MPI-CUDA 处理框架流程
3.2 SVM支持向量机并行化分类框架设计
结合图2的改进方案,将基于Spark的SVM并行化分类方案设计为如图3所示。该方案的具体步骤为:在运行SVM算法前,首先将数据上传到HDFS中,从而为后续的并行化分类提供参考。在该架构中主要分为两部分:一是训练模型,即通过训练样本对SVM模型进行训练,从而达到最优SVM模型。具体来讲,Spark首先从HDFS文件中读取数据,将得到的RDD分布式数据集分发到各个集群节点。当各个节点对数据进行训练后,将RDD数据集转换为SVM要求的格式,然后通过MPI接口程序对样本进行训练,并同时调用CUDA进行并行计算。最后将训练得到的最优参数构建SVM分类模型。二是测试训练。在完成最优SVM 模型的参数寻优后,将最优的参数分发到各个节点,并通过该最优参数构建的SVM对数据进行分类,并最终合并各个节点的分类结果,得到整体的RDD数据集。
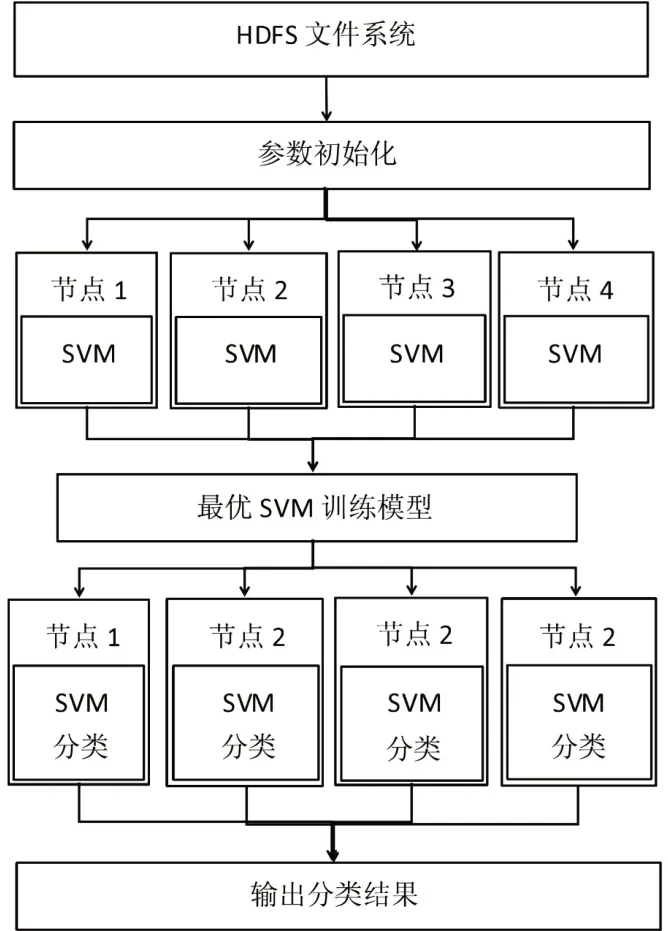
图3 SVM 算法的高性能并行计算处理整体框架图
4 SVM并行化分类实现
4.1 节点样本数据的SVM训练实现
节点模型的训练如图4所示。在该训练过程中,首先通过MPI主进程将数据分发给各个次进程,换句话说就是将数据分发给各个子节点,各个子节点进行SVM训练。SVM参数的初始化,包括迭代次数、惩罚因子C 和Gamma 系数(系数用k 表示);然后通过迭代得到局部最优的Gamma 系数,且每次迭代后,都剔除非边界样本点;合并局部支持向量,并将合并得到的局部向量作为下层的层叠输入;最后合并所有的局部支持向量,得到最优的SVM训练模型。
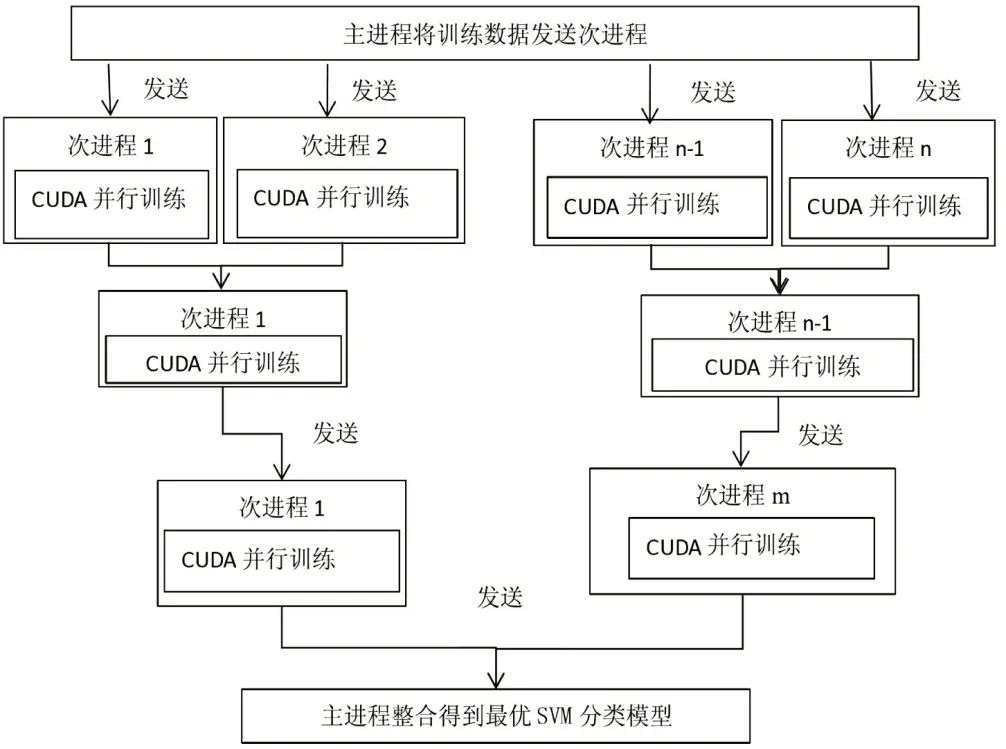
图4 节点训练实现过程
4.2 节点测试数据的SVM分类实现
测试数据的SVM分类流程如图5所示。首先各个节点会通过MPI 开启多进程,然后调用CUDA 并行处理方式实现对数据的计算与分类。在完成分类后,次进程将结果发送给主进程,再通过repartition函数对得到的结果进行合并,得到RDD数据集;最后通过Geo Py Spark将分类结果写成图。

图5 测试数据分类实现流程
5 实验验证
5.1 实验方案设计
为验证上述并行化方案的可行性与科学性,通过对比实验的方式对上述设计方案进行验证。具体设计为四个试验,具体试验方案见表1所示。
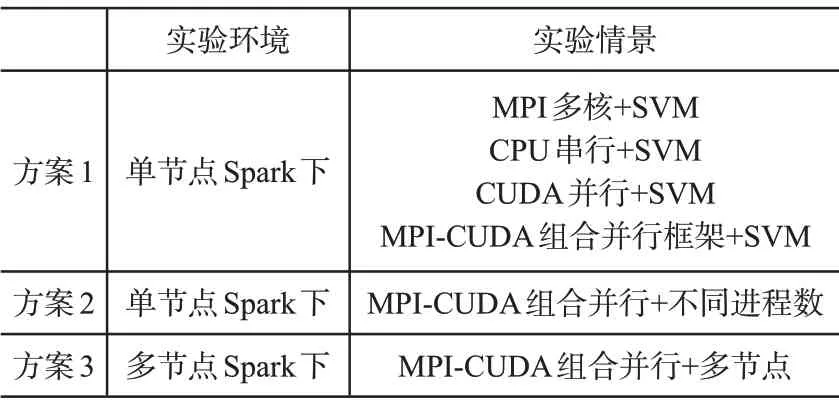
表1 试验方案
5.2 数据来源与环境搭建
5.2.1 数据来源
本试验数据选择Landsat8的影像数据,成像时间为2019年8月5日,数据范围为广东东部及沿海等大部分地区。通过影像分析,将样本分为五个类型:建设用地、农业用地、水体、湿地植被、滩涂。然后利用Clip工具对影像图像进行裁剪,进而作为样本数据,以整幅影像图作为测试数据。将上述的样本数据和测试数据上传到HDFS 系统中,为后续的SVM分类奠定基础。
5.2.2 环境搭建
本试验环境搭建主要分为两部分:一是对单节点环境搭建,二是对集群节点环境进行搭建。其中单机Hadoop选择hadoop-2.7.4 版本,Spark 选择Spark-2.1.0,JDK 选择1.80,操作系统选择CentOS7。在实验测试情景方面,分别按CPU 串行、MPI 多核、CUDA 并行、MPI-CUDA 四个测试情景进行搭建,且MPI开启进程为5个次进程。集群搭建环境见表2,总共设计6个集群节点,1个为主节点,其余五个为子节点。
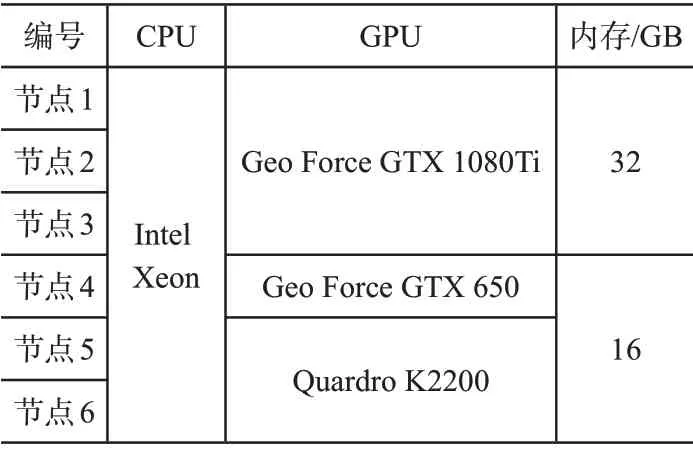
表2 集群服务节点搭建
5.3 参数设置
通过对数据集的训练试验,设定C=1.0,Gamma=0.1。
5.4 试验结果
(1) 方案一测试结果
方案一的试验测试结果见图6所示。
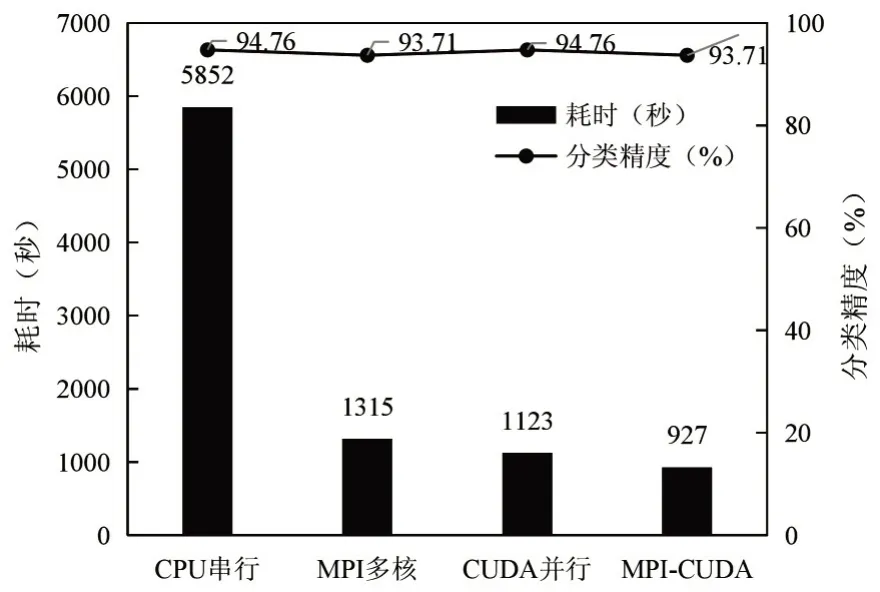
图6 单节点下不同情境的测试时间和分类精度
根据试验结果看出,CPU串行下的SVM训练与分类耗时最高,达到5852s,而MPI-CUDA并行下的SVM分类训练与分类耗时最少,为927s,比传统CPU 串行分类效率高6.3倍,说明采用MPI-CUDA并行分类效率要明显高于传统的并行或串行SVM 分类。然而在分类精度方面,本研究得到的分类结果要低于CPU 和CUDA,主要原因是因为MPICUDA是通过整合各子进程分类结果的方式得到最终SVM模型,从而导致最终得到的模型不一定为最优的分类模型,因此得到的分类精度要低,但两者之间的分类精度相差较小,在试验可接受范围内。
(2) 方案二测试结果
研究认为不同的进程数会影响样本训练和分类的效率。因此构建单机节点下不同进程数,以对比分析MPI-CUDA的SVM并行分类效率与精度。试验结果如图7所示。
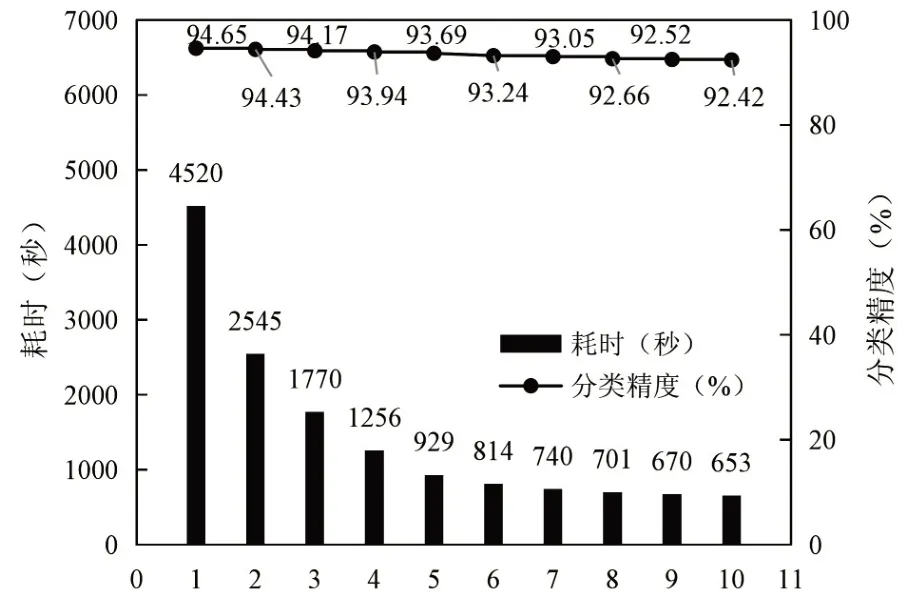
图7 不同进程数下的SVM分类时间与分类精度
根据上述的试验结果看出,随着次进程数的不断增加,SVM并行算法的分类精度不断降低,精度从94.64%降低到92.42%。同时当进程数在8的时候,分类的速度开始逐步趋于平稳。但是随着进程数的增加,分类的效率却明显提高,从进程数为1 的时候下的4513s,下降到653s。根据以上结果可以看出,并行分类有助于提高分类效率,但进程数并不是越多越好。
(3) 方案三测试结果
在多个节点下,运行基于MPI-CUDA 的SVM 并行化程序,每节点进程数统一设置为5,评价指标以并行环境与单机环境下分类处理时间之比(加速比)作为评价依据。
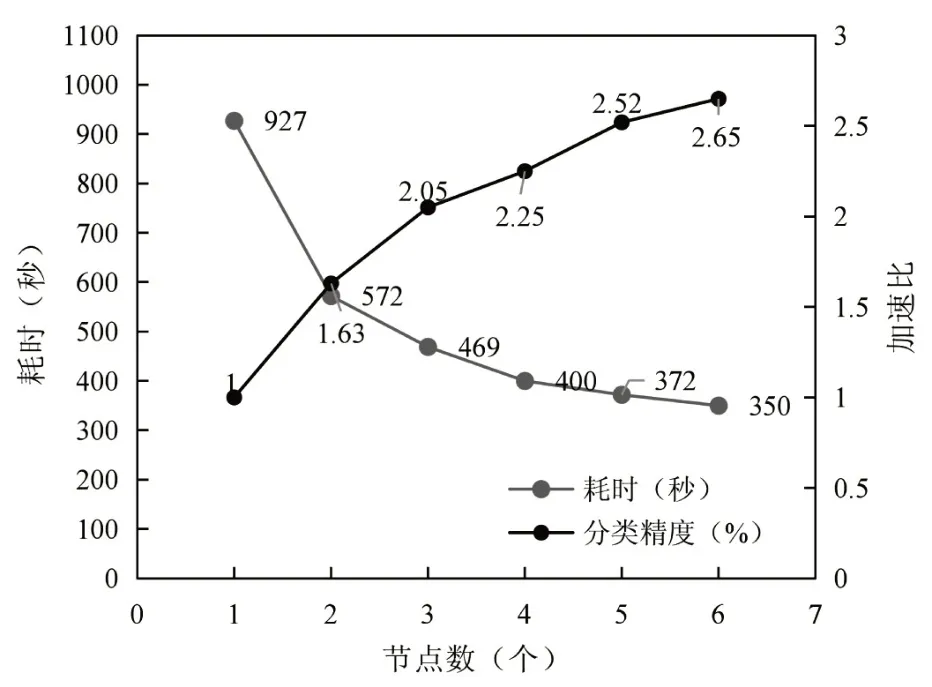
图8 不同节点下SVM的耗时情况和加速比
根据上述三个实验方案的测试结果看出,随着节点数量的增加,SVM并行分类的效率也在不断提高,但变化服务在逐步趋缓。而从加速比来看,当节点数增加的同时,加速比也在不断增加,表明节点数的增加,分类的效率也越来越高。
6 结束语
通过以上的研究看出,本研究构建的MPI-CUDA 的SVM并行方案可靠,可实现SVM分类的高性能分类。但以上研究也存在缺陷,那就是并行化处理后的SVM 分类精度有所降低,但降低幅度在试验可接受的范围内,但通过本改进,确实可大幅度提高传统串行SVM分类的效率,降低分类时间。因此,在下一步的研究中,本研究应重点就如何整合不同节点训练模型下的最优SVM模型进行研究。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
昆明理工大学学报(自然科学版)(2022年4期)2022-09-07
数学小灵通(1-2年级)(2021年4期)2021-06-09
中国外汇(2019年20期)2019-11-25
中国外汇(2019年8期)2019-07-13
长江丛刊(2017年34期)2017-11-15
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
少儿科学周刊·少年版(2015年3期)2015-07-07
散文百家·下旬刊(2014年8期)2014-10-11
