
低光照环境下基于面部特征点的疲劳驾驶检测技术
2022-07-17 07:42谢忠志李曙生
汽车安全与节能学报 2022年2期
朱 艳,谢忠志,于 雯,李曙生,张 逊
(泰州职业技术学院 机电技术学院,泰州225300,中国)
造成交通事故的主要因素有酒后驾驶、超速驾驶、违章驾驶和疲劳驾驶等4 个方面。疲劳驾驶造成的交通事故占交通事故总数的比例超过20%,在特大交通事故中的占比超过45%。夜间开车比白天更容易疲劳,凌晨1 点到3 点是交通事故高发时间段,大多数特大交通事故发生在该时间段。因此如何有效地在低光照环境下监控和预防疲劳驾驶一直是研究重点[1],对于减少交通事故具有重要的意义。
从特征源来分,对于驾驶员疲劳状态的检测主要有:基于驾驶员生理参数的识别方法、基于车辆状态信息的识别方法和基于驾驶员行为特征的识别方法。
基于生理参数的识别方法属于接触式测量,通过穿戴在身上的各类传感器获取驾驶员脑电、心电和肌电信号,从中提取出反映疲劳状态的特征指标[2-4]。N. S.Disa 等人[2]通过传感器采集驾驶员肌电信号和呼吸信号,采用近似熵方法对信号处理后,通过阈值判断来检测疲劳状态。李江天等人[3]采用多信息融合的方式,将采集到的脑电、心电、肌电和血氧饱和度 4 种信号作为分析数据源,采用神经网络算法对驾驶员疲劳状态进行识别,实现了较好的检测效果。此类方法具有较高的识别精度和可靠性,但是由于需要将各类传感器穿戴在身上,从而造成驾驶人员行动不便,因此很难大规模推广。
基于车辆状态信息的识别方法是通过角度、速度等传感器采集车辆行驶状况参数,并从中提取出特征指标来进行疲劳状态识别[5-8]。F. Friedrichs 等人[5]将采集到的方向盘转角、车辆横摆角、方向盘修正频率等信息作为数据源,采用神经网络算法识别疲劳状态,识别精度达到了84%。刘军[6]将采集到的方向盘转角信息作为疲劳状态检测的数据源,提取出反映车辆运行状态的两种有效指标,从而进行疲劳状态识别。由于车辆的运行状态受道路状况和驾驶习惯等外界因素影响较大,因此该方法识别精度较低,适应性较差。
基于驾驶员行为特征的识别方法,主要通过图像传感器实时采集驾驶员面部表情、眼睛活动、头部运动和身体坐姿等行为特征来实现疲劳状态识别[9-19]。W. Kim 等人[13]将采集到的嘴巴、头部和眼睛特征数据输入卷积神经网络模型来识别疲劳状态。胡习之[14]从图像中提取眼睛和面部特征点坐标,并通过机器学习算法进行疲劳识别。由于三原色(red-green-blue,RGB)图像传感器受光线影响较大,并且疲劳特征提取和机器学习算法耗时较长,因此该方法实时性和适应性较差。为适应各种光照环境,LIU Weiwei 等人[19]基于虹膜对红外光线反射率较高这一特性,通过红外(infra-red, IR)摄像头与窄带滤光片定位虹膜,并提取眼部特征用于疲劳判断取得了不错的效果,然而,窄带滤光片几乎滤除了所有的自然光线,无法提取其他面部疲劳特征,由于疲劳特征比较单一,因此识别精度相对较低。
本文选用深度视觉传感器Kinect V2 作为图像采集设备,首先提取面部特征点和头部转角数据,通过坐标转换将数据进行标准化处理,然后对眼睛和嘴巴开合度进行归一化计算,并在此基础上提取疲劳特征数据。最后采用基于数据统计序列的卷积神经网络算法建立检测模型对疲劳状态进行识别,并通过Visual Studio 和MATLAB 混合编程的方式完成实验平台的搭建,对本文方法进行验证。
1 特征点数据采集及标准化处理
1.1 人脸跟踪及面部特征点数据提取
微软提供了专门用于Kinect 传感器的人脸跟踪功能模块(Face Tracking SDK),首先将改进的人脸特征向量输入Adaboost 分类器进行人脸检测,之后采用AAM 算法对人脸进行实时跟踪并对121 个面部特征点进行提取,其工作流程如图1 所示。
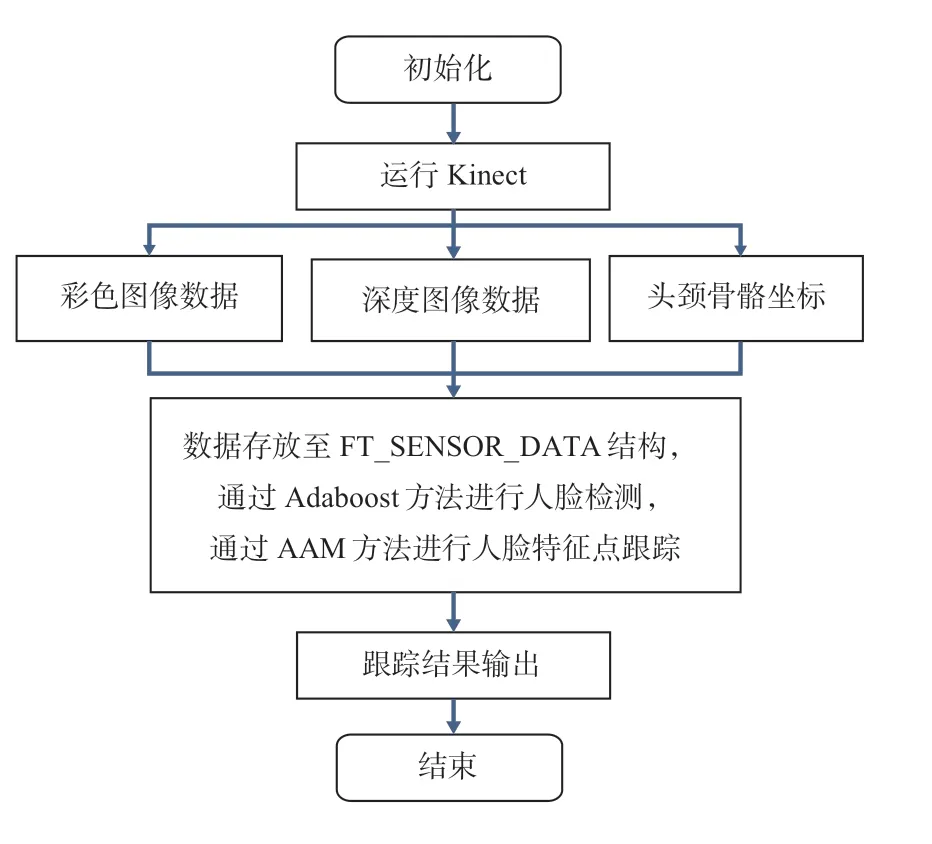
图1 Face Tracking 人脸跟踪流程图
FT_SENSOR_DATA 结构用于存放人脸追踪所需的输入数据,包括彩色图像数据、深度图像数据和头颈骨骼坐标数据三部分,其中的头颈骨骼坐标也是通过深度图像数据计算得到。由此可知,该算法在人脸实时跟踪中,深度图像数据起到了至关重要的作用。相对于仅使用RGB 彩色图像数据的人脸跟踪算法,该算法跟踪效果更好,跟踪速度更快(一般可以保证在50 ms 之内),且受光线影响较小,非常适用于低光照环境下的人脸实时跟踪。
图2为Face Tracking SDK 提供的人脸跟踪算法在低光照环境下的实时跟踪效果。由图2a 可见:低光照环境下的RGB 图像清晰度非常低,基于该图像的人脸跟踪算法很难进行实时跟踪,面部特征点数据提取困难。图2b 图为基于深度图像的人脸实时跟踪。由于深度信息由红外传感器提供,受光线影响较小,所以采用深度图像,可以在低光照环境下较好地实现人脸实时跟踪,并精确地提取面部121 个特征点数据。

图2 低可见度下RGB 图像和深度图像人脸跟踪效果
疲劳识别所用到的面部特征点分布如图3 所示。

图3 疲劳识别所用面部特征点分布
由于驾驶员在疲劳状态下眼部和嘴部特征点数据变化比较明显,因此,本文选取眼部和嘴部的32 个特征点数据作为疲劳状态识别的分析数据源,选取94 号特征点(鼻骨中下缘)作为坐标转换参考基准点,用于对特征数据标准化处理。
1.2 面部转角数据提取
获取人脸跟踪结果后,除了可以得到面部特征点数据,还可以通过Get3DPose 函数直接获取面部转角数据,通过该数据对采集到的面部特征数据进行标准处理。图4 是面部转角数据的定义:θP为低头和抬头角度,其角度识别范围为-45°~ 45°,θR为左右偏头角度,其角度识别范围为-90°~ 90°,θS为左右摇头角度,其角度识别范围为-45°~ 45°。

图4 Kinect V2 头部转角识别示意图
1.3 面部特征点数据标准化处理
在人脸跟踪和面部特征点提取时,由于采用的是Kinect 自身的坐标系统来输出三维跟踪结果(x, y, z),坐标原点(x= 0,y= 0,z= 0)位于kinect的红外相机中心,X轴方向为顺着kinect 照射方向的左方向,Y轴方向为顺着kinect 照射方向的上方向,Z轴方向为顺着kinect的照射方向,如图5 所示。

图5 面部特征点数据坐标系统
由于Kinect 的拍摄角度和距离会随着脸部的移动不断发生变化,因此实时提取到的面部特征数据也会变化,特别是在脸部转角较大的情况下,坐标数据差异更大。如果直接采用该坐标系下的面部特征点数据进行疲劳状态分析,则会因为数据没有标准化而造成识别精度严重下降。
通过坐标变换,将采集到的面部特征数据转换至Z轴和面部垂直且坐标原点与面部等高的新坐标系统中,完成特征数据的标准化处理,这样可以最大程度的降低由于拍摄角度和拍摄距离不同而造成的数据偏差,从而大大提高识别精度。坐标变换过程如图6所示。

图6 面部特征坐标变换过程
坐标变换的步骤如下。
步骤1 选取94 号特征点(鼻骨中下缘)A(xA,yA,zA)作为坐标转换参考基准点,以点A为旋转中心,以线段OA为母线,旋转角度为θS,将Kinect 坐标原点O(0, 0, 0)移动至O1(x1, 0,z1),移动过程中Y方向坐标保持不变。

A(xA,yA,zA)和O(0, 0, 0)的Euclid 距离为O1(x1, 0,z1)和O(0, 0, 0)之间的Euclid 距离d0可由式(2)得:
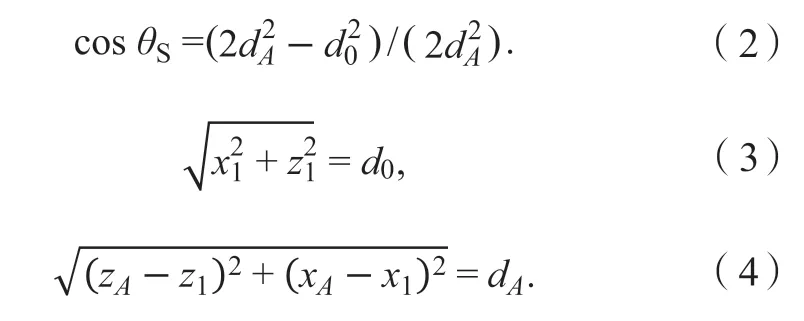
式(3)和(4)联立,得x1和z1。
步骤2 将O1(x1, 0,z1)沿着竖直方向移动到O2(x1,yA,z1),移动距离为yA。移动过程中保持X轴和Z轴坐标不变。至此,O2(x1,yA,z1)被移动到面部的正前方向且与面部中心(94 号特征点)等高的位置。将O2(x1,yA,z1)作为新坐标系的原点。
步骤3 绕O2X轴旋转θP角度,旋转矩阵为

步骤4 绕O2Y轴旋转θS角度的旋转矩阵为
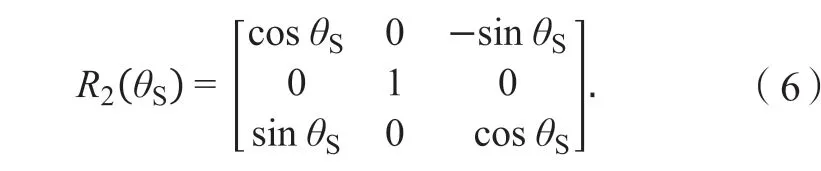
步骤5 绕O2Z轴旋转θR角度,其相对应的旋转矩阵为

步骤6 至此,生成新的坐标系O2-X2Y2Z2,面部特征点数据在该坐标系下的坐标可由式(8)转换得到,R0=R1(θP)R2(θS)R3(θR)。
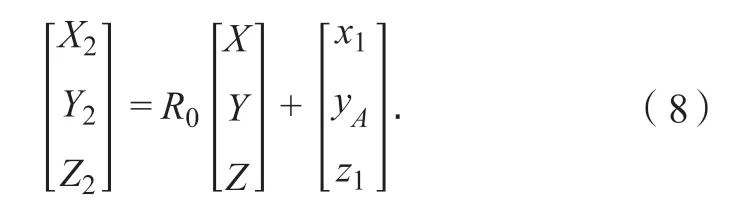
2 疲劳特征数据提取
2.1 眼睛和嘴巴轮廓曲线拟合
右眼轮廓曲线以53 号和56 号节点为界,可分成上下2 部分,左眼轮廓曲线以20 号和23 号节点为界可分成上下2 部分,嘴巴轮廓曲线以88 号和89 号节点为界可分成上下2 部分。上半部分轮廓曲线可由式 (9)中的F1(x)所示,下半部分轮廓曲线由式(9)中的F2(x)所示。

分别将左眼、右眼和嘴巴的上下2 部分节点数据带入F1(x)和F2(x),计算其误差平方和,找到使误差平方和最小的函数作为轮廓拟合曲线。图7 中曲线1 为眼睛在闭合和睁开状态下的轮廓拟合曲线,图8 中曲线1为嘴巴在闭合和张开状态下的轮廓拟合曲线。
2.2 眼睛和嘴巴开合度归一化计算
驾驶员的疲劳状态很容易通过眼睛和嘴巴的形态变化反映出来,因此如何对眼睛和嘴巴的开度大小进行标定至关重要。对于不同的驾驶员,眼睛和嘴巴的开合状态差异较大,所以需要一种归一化的指标对眼睛和嘴巴开度大小进行标定,以提高检测的准确性和鲁棒性。
由式(10)计算眼睛和嘴巴开合程度,并将其作为开度大小标定的归一化指标。A1为眼睛和嘴巴轮廓拟合曲线所围成的面积,A2为其外接圆的面积大小。如图7中曲线2 为眼睛在闭合和睁开状态下各特征点的外接圆。图8 中曲线2 为嘴巴在闭合和张开状态下的外接圆。

图7 眼睛轮廓拟合曲线和外接圆

图8 嘴巴轮廓拟合曲线和外接圆
眼睛开合度归一化指标ηNAE如图9 所示。嘴巴开合度归一化指标ηNAM如图10 所示。

图9 眼睛开合度归一化指标ηNAE 曲线图
由图9 可知:眼睛在睁开状态和闭合状态下的ηNAE值差别明显,眼睛在睁开状态下ηNAE的值大于0.25,而在完全闭合状态下ηNAE的值小于0.2。
由图10 可知:嘴巴在张开状态和闭合状态下的ηNAM值差别比较大,闭合状态下的ηNAM值在0.3上下波动,而完全张开状态下的ηNAM值均大于0.55。因此,选取ηNAE和ηNAM作为眼睛和嘴巴开度大小标定的归一化指标,具有较高的识别精度和较好的鲁棒性。

图10 嘴巴开合度归一化指标ηNAM 曲线图

2.3 疲劳特征数据提取
1)眨眼频率fb。根据数据统计发现,正常精神状态下人的眨眼频率为12~15 次/min,而在疲劳状态下人的眨眼频率会大大降低,在严重疲劳状态下眨眼频率会小于6 次/min。选取ηNAE= 0.25 作为眨眼识别阈值,由于Kinect 传感器的帧率大约为30 帧/s,非疲劳状态下,一次完整眨眼过程中ηNAE≤ 0.25 的持续帧数为5~8 帧,因此,如果连续5 帧以上的图像ηNAE≤0.25,则判定完成了一次眨眼过程。将30 s 作为一个统计时长Δt,计算眨眼频率fb。
2)眨眼平均时长tb。根据统计发现,正常精神状况下人的眼睛从全部睁开到全部闭合完成一次眨眼过程的时间为0.25 ~0.35 s。但是在疲劳状态下,完成一次眨眼的时长要比正常精神状态下的眨眼时长大的多。眨眼平均时长tb由式(11)计算,其中:ns为一个统计时长内眨眼过程持续图像帧数,nf为一个统计时长内的图像帧数,N表示一个统计时长Δt 内眨眼的次数。

3)眼睛闭合总时长tc。在正常精神状态下,除了眨眼过程外人的眼睛都处于最大张开状态,而在疲劳状态下人的眼睛会较长时间处于完全闭合或半闭合状态。选取ηNAE= 0.2 作为眼睛闭合状态识别阈值,计算一个统计时长Δt内所有ηNAE≤0.2 的图像总帧数,从而得到眼睛闭合总时长tc。
4)打哈欠频率fy。但在说话或吃东西时,嘴巴也会表现出和打呵欠类似的特征,因此需要将它们区分开来。研究发现,打哈欠时人的嘴巴打开的程度比较大,并且持续的时间相对较长。选取ηNAM= 0.45 作为打呵欠状态识别阈值,如果连续20 帧以上的图像ηNAM≥0.45,则判定完成一次打哈欠过程,计算出打哈欠的频率fy。
5)打哈欠总时长ty。在疲劳状态下,打哈欠时嘴巴会张开到最大状态,其总时长要远远大于其他状态。选取ηNAM= 0.5 作为嘴巴最大张开状态阈值。计算一个统计时长Δt内所有ηNAM≥0.5 的图像总帧数,从而计算得到嘴巴打哈欠总时长ty。
6)低抬头频率fh。驾驶员在疲劳状态下,会出现频繁低抬头或长时间低头现象[20]。通过Kinect 人脸跟踪功能模块(Face Tracking SDK)获取的面部转角参数中的θP来确定低头角度。实验研究发现θP≤30°时,即可判定驾驶员处于低头状态,计算一个统计时长Δt内的低头频率fh,如果低头频率大于8 min-1,则判定驾驶员已经处于疲劳状态。
本文将疲劳状态划分为不疲劳、轻度疲劳、中度疲劳和严重疲劳4 个等级,疲劳等级和识别特征数据之间的关系如表1 所示。

表1 疲劳等级划分和识别特征数据之间的关系
3 疲劳状态识别算法
3.1 卷积神经网络疲劳识别模型的建立
由表1可知,对眨眼频率、眨眼平均时长、眼睛闭合总时长、打哈欠频率、打哈欠总时长和低抬头频率6个疲劳识别特征数据进行阈值分析可以对驾驶员疲劳状态进行识别,由于阈值分析算法简单,因此识别速度快,对设备性能要求不高,系统实时性较好,但是由于不具备非线性处理和自学习能力,因此识别精度不高,鲁棒性差。本文采用基于数据统计序列的卷积神经网络算法构建驾驶员疲劳状态识别模型,算法内部采用多权值的加权运算,具有更好的鲁棒性和适应性[21-22]。选取统计时长 Δt= 30 s,计算6 个识别特征数据的大小,将连续6 Δt(3 min)作为一个周期,构建66 样本数据如式(12)所示,将其作为卷积神经网络识别模型的输入。

由于样本数据维度较小,因此构建的卷积神经网络疲劳识别模型采用2 层结构,如图11 所示。

图11 卷积神经网络疲劳识别模型结构
第1 个卷积层大小为3×3×4,用于对疲劳特征进行初步提取。第2 个卷积层大小为3×3×8,用于对疲劳特征进行精确提取。中间经过2 个2×2×1 的池化层
连接,可以有效降低特征维度,提高运算效率。采用1×1×4 的全连接层将权重矩阵与输入向量相乘再加上偏执,得到分类的得分,并将“分布式特征表示”映射到样本标记空间。最后采用Softmax 输出层将4 个疲劳状态的得分归一化为(0,1)的概率,将概率最大的确定为当前疲劳等级。
3.2 疲劳状态识别系统的实现
安装微软的Kinect for Windows SDK 和Kinect for Windows Developer Toolkit,配置软件Visual Studio 中的include 和lib 的路径即可实现对Kinect V2 深度视觉传感器的开发。卷积神经网络算法通过MATLAB软件完成,基于其数据处理能力和复杂模型求解能力,可以完成疲劳状态识别模型的构建。
图12为由MATLAB 程序实现的卷积神经网络疲劳识别模型训练结果。
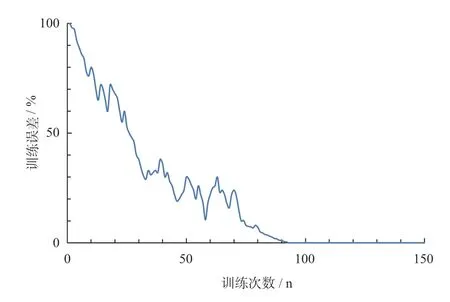
图12 卷积神经网络疲劳识别模型训练过程
由图12 可知:当训练次数在90 次左右时,各隐含层参数基本收敛,训练准确率达到100%。这表明了该卷积神经网络模型具有良好的学习能力。
采用Visual Studio 和MATLAB 混合编程的方式实现疲劳识别系统实验平台。Visual Studio 软件安装windows 10 SDK,对Visual Studio 和MATLAB 进行路径和属性配置,即可实现2 个软件之间的交互编程。
4 实验结果和分析
参加实验的人员在驾驶模拟器中进行3~6 h 的连续驾驶,由视频记录下在不疲劳、轻度疲劳、中度疲劳和严重疲劳4 个状态下驾驶人的行为。选取20 个不同性别、身高、外貌、肤色的驾驶员作为实验对象,在不同光照条件下分别采集2 h 驾驶视频,实验光照环境如图13 所示。实验对象的年龄分布、男女比例以及不同疲劳状态下的模拟视频时长如表2 所示。

表2 实验对象年龄、性别、不同疲劳状态下的模拟时长

图13 疲劳驾驶实验所处的光照环境图
将其中10 人的驾驶视频构建得到的200 个样本作为训练样本,输入到卷积神经网络疲劳识别模型(convolutional neural network,CNN)进行学习。将另外10 人的驾驶视频构建得到的200 个样本作为测试样本,输入到卷积神经网络进行疲劳识别。并将相同的实验数据输入阈值分析(threshold value analysis,TVA)、支持向量机(support vector machine,SVM)、强分离器(Ada-Boost)、决策树(decision tree,DT)和K 近邻(k-nearest neighbor,KNN)算法模型进行识别[23-25]。实验结果如表3 所示。

表3 正常光照和低光照环境下各算法模型识别结果
可以发现,阈值分析方法具有最快的识别速度,但其识别精度比较低,仅有65%左右。本文设计的卷积神经网络识别算法(CNN)在正常光照和低光照环境下的识别精度都超过了90%,并且识别时间仅130 ms左右,无论识别精度还是识别速度均优于其它几种机器学习识别模型。
5 结 语
本文采用深度视觉传感器Kinect V2 作为图像获取设备,采用基于数据统计序列的卷积神经网络算法建立识别模型,并构建疲劳状态检测实验平台,最后在正常光照和低光照环境下进行了实验。结论如下:
1) 采用深度视觉传感器Kinect V2 进行人脸跟踪和面部特征数据提取,不论在正常光照还是低光照环境下,都可以实现实时精确地跟踪,相比于RGB 视觉传感器,具有更好的适应性。
2) 基于最小二乘法对眼睛和嘴巴轮廓进行曲线拟合,并将拟合曲线和外接圆的面积比作为眼睛和嘴巴开合度归一化指标,实验发现,相对于其它特征指标,具有更好的鲁棒性。
3) 采用基于数据统计序列的卷积神经网络算法建立识别模型,相对于其它识别算法,具有更高的识别精度和更快的识别速度。
4) 采用Visual Studio 和MATLAB 混合编程的方式实现驾驶员疲劳状态检测实验平台构建,系统开发方便灵活,运行可靠。
如何将系统更加小型化将是今后研究的重点。
猜你喜欢
中国动物保健(2022年10期)2022-11-04
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
学生天地(2020年11期)2020-08-25
小学生作文(低年级适用)(2019年12期)2020-01-18
小资CHIC!ELEGANCE(2019年40期)2019-12-10
文苑(2018年22期)2018-11-19
动漫星空(2018年9期)2018-10-26
水禽世界(2015年6期)2016-03-04
水禽世界(2014年4期)2014-09-21
