
基于层次语义多项式DS融合的铁路扣件状态分布学习
2022-07-12 04:08黄翰鹏罗建桥李柏林
铁道标准设计 2022年7期
黄翰鹏,罗建桥,李柏林
(西南交通大学机械工程学院,成都 610031)
引言
铁路运维工作中重要环节之一是检查用于固定钢轨的铁路扣件工作状态,一般包括正常、断裂、丢失、遮挡4种,如图1所示。由于户外光照变化、局部道砟遮挡的广泛存在,正常扣件容易被误判为失效状态,造成大量误检。目前,扣件视觉检测方法主要通过设计判别性的特征,来确保及时发现失效扣件[1-4]。这些方法有效降低了失效扣件的漏检率,却未针对性地解决正常扣件误检问题。虽然卷积神经网络(Convolutional Neural Networks,CNN)能够自动学习图像特征,但依然无法克服扣件误检问题。这是因为包含大量参数的CNN往往快速且充分地拟合到训练数据上,导致了CNN过拟合问题,削弱了网络泛化能力。即使正常扣件图像发生细微变化,例如少量道砟,过拟合的网络也会将扣件误判为失效。采用单一图像标签训练网络是造成过拟合的重要原因,标签平滑被证明可有效缓解过拟合问题[5-6]。因此,针对扣件状态设计合理的标签平滑方式是解决误检问题的关键。

图1 铁路扣件示意
标签分布学习(label distribution learning,LDL)是一种标签平滑手段,通过为每个训练样本赋予一个标签分布向量对单标签进行平滑,解决了传统单标签学习中存在的标签歧义问题,同时,相比单标签学习,标签分布学习能够缓解单标签学习的过拟合问题,提高模型适应性[7]。标签分布向量取代了传统单标签,向量内元素代表对每种分类状态的描述程度,常应用于面部年龄估计、头部姿态估计等领域[8-14]。一般的,LDL基于高斯分布,图2(a)显示了年龄估计任务中常用的标签分布,年龄估计任务中之所以能够直接使用高斯分布,是因为面部特征的时序性及相近年龄的特征相似性,高斯分布能够准确且合理表达样本标签。但并不是所有任务都能够直接使用高斯分布等现有分布,扣件状态就无法像年龄分布一样将真实年龄平滑至附近年龄,故针对不同问题,合理的分布构建方法是LDL的主要限制。
针对扣件误检问题,结合DS理论(Dempster Shafer,DS)融合多个层次的语义多项式(Semantic Multinomial,SMN)形成扣件状态分布,提出基于层次语义多项式DS融合的扣件状态分布学习方法(SMN-DS)。首先,根据图像子块卷积特征构造图像语义多项式SMN,表达扣件状态分布;然后,提取多层卷积特征分别建立SMN,对层次化SMN进行DS融合形成最终的状态分布。状态分布用于模型训练,测试阶段以概率最大的状态作为检测结果。算法流程如图3所示。
与关注特征的现有方法不同,所提算法改进样本的标签表达,目的是建立状态分布表达图像语义内容。如图2(b)所示,状态分布不仅表达了正常状态,而且反映了扣件被道砟遮挡。将正常状态上的标签值平滑到遮挡状态,是为了提高模型适应性,防止含有少量道砟的正常扣件被误检。

图2 状态分布及图像

图3 SMN-DS算法流程
1 基于SMN-DS的状态分布
将LDL迁移到扣件检测任务需要构造扣件状态分布来表达图像语义内容。为此,提出基于SMN-DS的扣件状态分布构造方法。
1.1 扣件语义多项式
SMN是一种基于子块的弱监督学习方法,根据每个子块的类别概率计算图像的语义分布。采用这种弱监督的语义表达可提高模型适应性[15-19]。构造SMN步骤如下。
首先,将任意类别c=1~C建模成关于子块的概率分布。类别c可表示成混合高斯模型
(1)

(2)
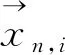

(3)
然后,进行归一化
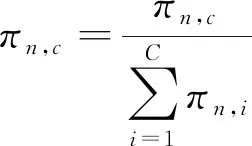
(4)
由于仅指定了图像类别,未给出子块类别,因此,SMN是关于子块的弱监督学习。图像语义分布由所有子块信息共同决定。如图2(b)所示,道砟区域的子块表达了遮挡状态,扣件弹条和螺母区域的子块则反映了正常扣件状态。对应的图像状态分布同时表达了多种状态。
1.2 层次SMN的DS融合
不同层次的卷积特征具有互补的表达能力。基于中低层特征的SMN,根据灰度、方向等底层信息表达图像语义分布,基于高层特征的SMN,则从更加抽象的角度反映扣件状态分布。因此,融合不同层次的SMN,可提高表达图像内容的能力。


m1⊕m2⊕…⊕mn(A)=
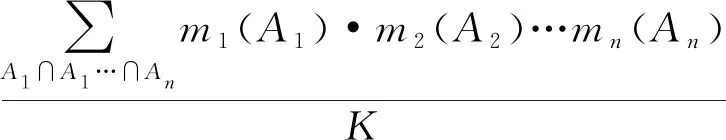
(5)
式中,mn(A)为第n个SMN对状态A的基本概率;K为归一化系数,计算方式如下
(6)
证据合成即为层次SMN融合方式,可得

(7)



(8)

2 实验分析
从状态分布可视化、学习曲线分析、分类性能对比3个方面进行算法验证。
2.1 实验设置
数据集来自沪昆线云南至大理路段扣件图像,正常/断裂/丢失/遮挡样本数量分别为8 375,723,420,824。数据集随机划分为训练集、验证集、测试集。训练、验证集中各类样本数量分别为200,100。测试集包含“正常”2 000张,“断裂”200张,“丢失”50张,“遮挡”200张。实验测试集“正常”数量远大于其他状态数量的原因在于,“正常”扣件被误检为其他状态,是影响扣件分类准确率的最主要因素,同时也是扣件分类问题的重难点,故设置较多“正常”扣件测试集。
算法参数方面,为防止高斯混合模型在训练中停留在局部最小值的问题,SMN中的高斯分量K应大于扣件类别4,但不应过大,从而加大计算量且对上述问题也无明显改善。故将高斯分量K设置为5,初始模型选用ImageNet上的预训练VGG-16模型。采用SGD训练模型100个epoch,学习率、动量、权重衰减、批量分别为0.001,0.95,0.000 5和8,算法实现基于Python和Pytorch。
2.2 状态分布可视化
为分析所提算法表达图像内容的能力,图4展示了20个扣件样本构造的状态分布及其部分对应的图像,左侧为扣件图像,黑色直线连接了该张扣件图片对应的状态分布,状态分布内各元素大小如右侧映射表所示。如图4所示,红色虚线框内为两张“正常”扣件图像,区别为下方扣件存在少量道砟。通过这两张“正常”扣件的状态分布可知,SMN能够保证对扣件真实标签状态描述的准确性,“正常”元素为状态分布内最大元素。同时,从第2张扣件图像的状态分布看出,因存在少量道砟,引起了“遮挡”元素标签值的变化,该张图像“遮挡”元素的标签值明显大于无道砟“正常”扣件的“遮挡”元素标签值。第10张样本为“断裂”扣件,从“断裂”扣件构建的状态分布可以看出,“断裂”标签值大于其他非真实状态标签值,但由于“断裂”图像与“正常”图像整体相似,仅在局部弹条区域存在差异,故部分“断裂”样本的状态分布中,“正常”状态的标签值相较于其他非真实标签值可能较大。第14张为“丢失”扣件,由于“丢失”样本与其他三类有明显区别,故标签纸集中在“丢失”状态。对于“遮挡”样本,扣件标签值主要集中在“遮挡”状态上,但由于道砟遮挡程度的不一致,导致裸露出的扣件弹条面积不同,造成“正常”标签值会出现较大变化。例如:第18张“遮挡”样本,由于图像上有部分区域能够明显看出扣件弹条的外观轮廓,故“正常”标签值达到了0.2。因此,基于SMN-DS的扣件状态分布,能够自适应地描述图像内容,实现标签平滑。

图4 部分状态分布可视化
2.3 学习曲线分析
为分析状态分布在缓解训练过拟合方面的效果,图5画出了网络学习阶段训练集和验证集上的精度曲线。精度=分类正确样本数量/总样本数量。采用单标签训练的VGG-16时,精度收敛迅速,在15Epoch就接近收敛,训练精度接近饱和(接近100%),但验证精度在较低水平停止变化,约为95%。饱和的训练精度和较低的验证精度说明单标签引起了过拟合问题,模型适应性差。对比而言,SMN-DS的训练精度缓慢收敛到较低水平,约98%,但验证精度明显超过VGG-16。因此,SMN-DS缩小了训练精度和验证精度的差异,表明过拟合问题得到缓解,网络适应新样本的泛化能力提高。

图5 学习曲线对比
2.4 分类性能对比
为分析SMN-DS的扣件状态分类性能,表1列出了近年来不同方法的分类结果。其中,正常扣件被预测为其他状态称为误检,误检率=误检图像数量/正常扣件总数×100%;扣件若断裂、丢失、遮挡被预测为正常称为漏检,漏检率=漏检图像数量/失效扣件总数×100%。

表1 扣件状态分类性能对比
表1中序号1将方向梯度直方图作为其算法底层特征,并用其训练高斯混合部件模型;序号2通过固有频率的频谱特征训练SVM判断扣件状态;序号3通过K-means算法提取视觉单词,然后描述为LDA主题模型,最后使用SVM训练LDA主题分布判断扣件;序号4直接使用初始模型VGG-16;序号5为改进YOLOv3算法;序号6~8采用单一卷积特征构造状态分布;序号9为本文所提算法。表1数据为测试集分类结果,为5次随机数据划分实验的平均值。
从表1可知,所有方法漏检率均较低,说明扣件的失效种类容易判别,扣件分类的难点在于降低误检率。序号1~2皆是对扣件进行正负二类判断,分类类别少,误检率较高;基于特征工程的序号3分类性能较高,但扣件局部特征编码导致了较大的计算量;序号4~5是基于深度学习的分类方法,二者在训练过程中都出现了过拟合现象,导致测试集分类性能不佳;采用状态分布的方法序号6~8,误检率皆低于使用单一标签的VGG-16及YOLOv3,说明SMN能够起到标签平滑的作用,缓和了过拟合问题。而对比方法6~8实验结果,高层SMN模型的分类性能弱于低层SMN模型和中层SMN模型,这是因为高层卷积特征的感受野宽,容易丢失局部图像特征,造成状态分布仅反映与单标签相同的全局信息。从实验结果上判断,SMN-DS的性能最佳,说明基于状态分布训练的模型适应性强,大幅降低了误检。
3 结论
针对扣件状态检测中误检率高的问题,提出基于SMN-DS的状态分布构造算法,根据图像子块卷积特征构造样本SMN,然后融合不同层次卷积特征生成的SMN。所提算法与现有关注特征工程及改进深度学习网络的方法不同,从平滑标签的角度出发,缓和了传统深度卷积网络训练过程中过拟合的现象,从而提高了模型分类性能。结论如下。
(1)融合后的SMN能够自适应表达图像内容,实现了标签平滑。
(2)构造的状态分布可缓解训练过拟合问题,提高了模型适应性。
(3)相比单标签,SMN-DS减少降低了扣件误检。
SMN-DS的不足之处是需对状态分布进行人工校正。下阶段计划改进SMN中的弱监督学习方法,使求解的类别模型能够保证状态分布中样本真实状态具有最高概率。
猜你喜欢
智能计算机与应用(2022年10期)2022-11-05
铁道建筑(2022年4期)2022-05-10
铁道勘察(2022年2期)2022-04-19
铁道学报(2021年8期)2021-09-09
现代计算机(2021年36期)2021-03-14
南京理工大学学报(2020年4期)2020-09-21
铁道建筑技术(2020年11期)2020-05-22
计算机应用(2018年12期)2019-01-07
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
