
流数据概念漂移检测研究进展
2022-07-06 06:35聂秀山林熙明
山东建筑大学学报 2022年3期
聂秀山,林熙明
(山东建筑大学计算机科学与技术学院,山东济南 250101)
0 引言
流数据(Data Stream)是大量快速连续传输的顺序数据序列,是一个随时间延续而无限增长的动态数据集,且数据类型和数据的分布是不确定的。 在现今的大数据时代,网络监控、气象、工业流程、交通、金融等领域都会产生大量的流数据。 在日常生活中,随着社交网络及短视频平台的普及,网络聊天、网上购物、视频评论等[1]也产生了大量的流数据。 政府机构和企业单位通常需要依据流数据做出各种预测和决策[2],因此对流数据的挖掘和分析就显得非常重要。 但是,流数据的统计关系会随着时间的变化而随机改变,且很难预测,这种变化称为概念漂移。 其会以改变类分布、出现新特征等多种方式影响流数据的属性[3],降低各种基于流数据的管理和决策系统的效率和准确度。
概念漂移通常发生在数据预测和决策模型中,离线(Offline)训练好的模型在面对在线(Online)流数据时,因在线流数据的不确定变换,导致预测目标变量的统计特性会随时间发生不可预测的变化,进而导致原有模型性能的急剧下降,此时需要训练新的模型重新适应目标新的统计特性。 在不断变化的大数据环境中,如何检测到概念漂移,并采取相应的措施成为了一个关键问题。
1 概念漂移概述
1.1 概念漂移定义及来源
概念漂移是指输出目标的统计特性随时间以任意方式随机变化的现象[4],指的是输入数据和输出目标之间的关系随时间变化的在线监督学习场景。1986 年,SCHLIMMER 等[5]首次提出概念漂移后,国内外的数据挖掘研究人员对概念漂移展开了深入研究。 如今概念漂移已经成为数据挖掘领域的研究热点,当预测模型遭遇概念漂移时,需要预测模型能够动态调整,以便对概念漂移做出适当的反应[6]。

1.2 概念漂移的分类
概念漂移常见的一个分类标准是概念变换的速度。 当概念之间的变化是突然或迅速时,称之为突变;当从一个概念到另一个概念的转变在多个实例中发生时,称之为渐变[10]。 根据概念变换的速度,概念漂移分类如图1 所示,可以分为突发式漂移、渐进式漂移、增量式漂移和复发式漂移。 由图1 可知,突发式漂移是指在短时间内突然发生概念间的变化;渐进式漂移是指旧概念在一段时间内,间隔随机的时间逐步转变为新概念;增量式漂移是指旧概念持续转变为新概念;复发式漂移是指旧概念转变为新概念后,间隔一段时间又重新变为旧概念。 其中,突发式漂移和增量式漂移属于突变,而渐进式漂移属于渐变。

图1 概念漂移分类图
对于突发式、渐进式和增量式3 类概念漂移研究的重点是如何在概念漂移过程中使模型预测精度下降最少,并实现较高的恢复率,即检测出是何种类型的漂移后,尽快训练出新的模型以适应具有新的数据分布或属性的流数据。 相比之下,对复发式漂移的研究强调历史概念的使用,即如何在最短的时间内找到与之匹配的历史概念,由于复发式的漂移可能呈现周期性现象,因此检测出是此类漂移后,仅需在原有模型的基础上增加具有周期性的漂移模型即可继续使用。
2 概念漂移检测算法
当出现了概念漂移现象时,如何检测出概念漂移是一个重要的问题。 传统的机器学习系统主要由模型训练和模型预测2 个部分组成,但在概念漂移现象下,系统新增了3 个组成模块,即漂移检测(是否发生漂移)、漂移理解(何时、何地、如何发生漂移)和漂移适应(对漂移存在的反应),如图2 所示。其中,漂移检测是最为重要的环节。

图2 概念漂移下机器学习模型示意图
2.1 漂移检测基本框架
概念漂移检测是指通过识别变化点或变化时间间隔,来表征和量化概念漂移的技术和机制。 漂移检测一般包含数据获取、数据建模、统计值计算和假设检验4 个阶段[2],其框架如图3 所示。

图3 概念漂移检测基本框架图
数据获取阶段旨在从数据流中获取到数据块。因为单个数据实例不足以携带足够的信息来判断总体分布,所以将多个数据单例组织成数据块在分析数据流数据分布中非常重要。
数据建模阶段旨在提取数据特征,特别是提取数据漂移时对系统影响最大的特征进行数据建模。这一阶段是可省略的,因为其主要涉及数据降维或减少样本量,以满足存储和在线学习速度的需求。
统计值计算阶段是相异性度量或距离估计。 其量化了漂移的严重性,并形成了假设检验阶段的检验统计数据。
假设检验阶段使用特定的假设检验评估阶段三观察到的变化的统计显著性。 通过证明第三阶段提出的检验统计量的统计界限确定漂移检测的准确性。
2.2 漂移检测算法
根据在第三阶段中所使用的检验统计量可将漂移检测分为基于错误率检测概念漂移、基于数据分布检测概念漂移以及多假设检验检测概念漂移3 类。
2.2.1 基于错误率的漂移检测
流数据的概念漂移可通过模型随时间变化而产生的精度性能变化来监测。 如果存在一个时间节点t,模型在时间t 后的预测错误率明显增加,这就说明数据流的性质可能已经发生了改变,即可能存在概念漂移。 如果出现这种情况,则需要根据发生变化后的数据重新训练模型。 这种根据模型预测错误率的变化来检测是否发生概念漂移的方法是概念漂移检测最常见策略[11]。 这类方法关注在线错误率的变化,一旦错误率的增加或减少被验证是具有统计意义的,将触发漂移警报。
这类算法中最具代表性的算法是漂移检测算法(Drift Detection Method,DDM)[12],这是第一个为概念漂移检测定义警告级别和漂移级别的算法。 在该算法中,根据二项式分布,针对漂移程度定义警告级别和漂移级别。 该算法使用时间窗口采集新的数据实例,当新的数据可用于检测时,DDM 会计算时间窗口内的数据样本的错误率。 如果观察到的错误率变化的置信水平达到警告级别,DDM 开始构建新的模型,同时使用旧的模型进行预测。 如果变化达到漂移级别,旧的模型将被新的模型替换,以进行后续的在线预测。 DDM 算法认为,如果数据实例的分布保持平稳,错误率应该随着示例数量的增加而降低;如果错误率增加,DDM 则认为数据分布发生了变化,当前使用的学习器已经过时。 DDM 采用的时间窗口[2]如图4 所示,DDM 在原有的历史数据窗口中添加下一时刻的实例,从而构成新数据块。

图4 DDM 时间窗口策略图
DDM 在突变式的概念漂移上表现效果较好,但对渐变式概念漂移效果不佳,且会增加内存的开销,后续的很多算法改进了 DDM。 如漂移检测方法(Early Drift Detection Method, EDDM)[13]和基 于Heoffding 不等式的漂移检测方法(Drift Detection Method based on the Hoeffding's inequality,HDDM)[14]。 EDDM 与 DDM 类似,但其统计的是两个连续分类错误之间的距离,即两个分类错误之间的实例个数,而不是如DDM 一样统计错误率。 因此,当概念稳定时,错误之间距离增大,当其减小时,会触发警告级别和漂移级别。 EDDM 比DDM 更适合检测渐进的概念漂移。 HDDM 则同DDM 一样,也使用错误率作为检验统计量,HDDM 在假设检验阶段采用Hoeffding 不等式判断概率差异来检测漂移,同时需要对渐变式概念漂移和突进式概念漂移分别设置不同阈值,增加了额外的开销。
与DDM 等方法相比,NISHIDA 等[15]提出了等比例检测的统计测试方法(Statistical Test of Equal Proportions,STEPD),该方法通过比较最近的时间窗口和整个时间窗口来检测错误率变化,对于每个时间戳,系统中有历史数据窗口和新数据窗口,新数据窗口的大小必须由用户定义,其检验统计量符合标准正态分布,因此可以很容易计算出警告阈值与漂移阈值。 基于STEPD 方法,研究者提出了Fisher 比例漂移检测器(Fisher Proportions Drift Detector,FPDD)[10],这是在样本较小时使用Fisher 精确检验的STEPD 的一种变体。 同样是使用等比例检验。Fisher 平方漂移检测器 FSDD(Fisher Square Drift Detector, FSDD)与 FPDD 类似,但其检验统计量使用卡方统计检验来代替等比例检验。 此外,Fisher检验漂移检测器(Fisher Test Drift Detector,FTDD)则使用了Fisher 精确测试来检测漂移。
与STEPD 需要用户自定义新数据窗口大小不同,BIFET 等[16]提出了一种基于两个时间窗口的漂移检测算法, 称为自适应窗口方法(Adaptive Windowing,ADWIN),其采用的窗口策略如图5 所示。 在ADWIN 中,可以自动调整比较窗口的大小。ADWIN 不要求用户预先定义窗口大小,而只需指定窗口的总大小。 然后,其会检查所有可能的窗口切割,并根据新旧两个子窗口之间的变化率计算出各个子窗口的最佳大小。 当这些子窗口的均值差大于给定阈值时,会检测到漂移,但这种方法过于灵敏,在噪声较多的数据流中会导致检测的错误率较高。此外,在概念漂移检测方法中,由于ADWIN 能够动态适应概念漂移,但其新数据窗口存在吞吐量瓶颈,因此 GRULICH 等[17]提出了并行自适应窗口(Parallel Adaptive Windowing)技术,为每秒数百万元组的高速数据流提供可伸缩的概念检测。

图5 ADWIN 自适应时间窗口策略图
在基于HDDM 的方法中,研究人员融合了统计方法与窗口,提出了使用滑动窗口和Hoeffding 不等式进行漂移检测的方法(Fast Hoeffding Drift Detection Method,FHDDM)[18],该方法在漂移检测中能有效的提高数据流分类的正确率,但仍存在漂移检测的延迟问题。 为此,徐清妍等[19]在FHDDM算法的基础上,提出了基于交叠滑动双窗口和Hoeffding 不等式的漂移检测方法(New Fast Hoeffding Drift Detection Method, NFHDDM )。FHDDM 为基于滑动窗口的检测方法,通过在预测结果上设置滑动窗口,在滑动窗口中根据预测结果正确与否填入“1”或“0”实现,NFHDDM 在此基础上通过在滑动窗口上使用四分位距来提取当前数据流段的特征,并改进了FHDDM 算法中Hoeffding 不等式阈值定义。 NFHDDM 不仅能够获得更高的漂移点检测正确率,还能有效减小概念漂移检测的延迟,从而提高流数据分类的正确率。 HUGGARD等[11]则提出了一种新的概念漂移检测方法,称为校准漂移检测方法(Calibrated Drift Detection Method,CDDM)。 现有的概念漂移检测方法监控模型预测的准确度,并在准确度度下降时预测漂移。 然而,准确度可能是一个粗糙的指标。 CDDM 通过检测基础学习器校准的变化而不是准确性的变化来实现这一点,将基础学习器所预测的标签以及人工打上的真实标签输入漂移检测器,若二者标签一致,则表明没有发生漂移;若二者出现差异,则以人工打上的真实标签为准,对学习器进行重新训练,并报告发生了漂移。 CDDM 利用校准来区分真实漂移和虚拟漂移,对任何虚拟漂移常见的领域都是有效的,但其在计算效率上有时是比较滞后。
以上涉及的算法主要聚焦于在线学习场景。 近年来,也有部分算法关注离线场景,如郑灿彬等[20]主要研究概念漂移的离线场景问题,提出一种3 阶段的概念漂移检测方法(Tsinghua Progress Concept Drift Detection,TPCDD)。 该方法将事件日志通过活动关系抽取转变成一个活动关系矩阵;通过活动关系的频繁度分析随时间的变化情况检测出每个活动关系的变更点,将其列为候选变更点;再通过聚类合并候选变更点得到漂移点。 其采用分治策略检测出变更点后再整合,使得检测准确率高、误差小,但是该方法没有考虑到相邻的两个模型可能会存在时间上重叠的情况。
2.2.2 基于数据分布的漂移检测
第二类漂移检测算法是基于数据分布的漂移检测。 这类算法使用距离函数或距离度量来量化历史数据和新数据分布之间的差异。 如果差异被证明在统计上存在显著差异,系统将触发学习模型更新过程。 这些算法通常要求用户预定义历史时间窗口和新数据窗口。 常用的策略是两个滑动窗口,固定历史时间窗口,同时滑动新数据窗口[2],如图6 所示。KIFER 等[21]首先提出了这一思路,如果分布有自身的 概 率 密 度 函 数, 则 距 离 DL1=历史时间窗口和新数据窗口中数据分布的概率密度函数。

图6 基于数据分布的漂移检测双时间窗口策略图
储光等[1]考虑文本数据流隐含的语义信息,提出一种新的概念漂移检测算法。 通过引入潜在狄利克雷分布( Latent Dirichlet Allocation,LDA)模型计算语义相似度,并基于相邻数据块共有词比例和相似主题比例,在频繁漂移情况下实现有效的概念漂移检测。
在基于滑动窗口的方法研究中,杨帆等[22]在准确率的基础之上,充分考虑了数据块间概率分布的差异性,提出了一种基于相对熵的概念漂移检测算法,将分类器的分类准确率与相对熵的值作为漂移判别基准。
姜振东等[23]则提出了一种基于 Kolmogorov-Smirnov 检验的概念漂移检测方法。 根据Kolmogorov-Smirnov 检验,计算当前样本和参考集的累积分布函数之间的差异。 如果分布 Pi≠ Pi+1,时间i 处被称为概念漂移点。 该方法使用滑动窗口,在每次滑动时都检验基窗口以及新窗口中的样本差异是否大于阈值来判断是否发生了概念漂移。
郭虎升等[24]提出一种基于时序窗口的概念漂移类别检测(Concept Drift Class Detection based on Time Window, CD-TW)方法,既可检测漂移的节点,又可检测漂移的类别。 该方法借助时序窗口机制对流数据进行分块学习。 通过对参考窗口进行训练,得到训练的准确率作为检测基准,然后对滑动窗口进行测试,得到滑动窗口的准确率。 比较滑动窗口与训练窗口的准确率的比值,若低于阈值则输出为漂移节点。 CD-TW 可以较为准确地检测漂移节点,并且对不同类别的概念漂移有较强识别能力,对数据流挖掘提供了重要的帮助。
此外,章恒等[25]则以传统网络数据流为研究对象,提出了基于历史数据分布的双交叉窗口概念漂移检测算法。 该方法使用滑动窗口接受数据流,交叉部分为窗口大小的一半。 通过计算历史数据与窗口中数据的每个元素的距离来判断是否发生了概念漂移。 若窗口中的所有元素与历史数据的距离小于警告级别,则不存在漂移;若存在些许元素的距离高于警告级别,而所有元素距离小于漂移级别则只发出警告信号;若存在元素的距离高于漂移级别,则直接判断发生了漂移。 因此该方法有较高的精度以及一定的抗噪能力。
除了基于滑动窗口的检测方法以外,还有基于图的检测方法。 PAUDEL 等[26]提出了一种新的基于图流的无监督概念漂移检测方法,称为基于鉴别子图的漂移检测器(Discriminative Subgraph-based Drift Detector,DSDD),该方法的基本过程是:(1) 为流中的每个图发现有区别的子图;(2) 根据判别子图相对于图的分布来计算窗口的熵,使用直接密度比估计,在滑动窗口向前移动时得到的熵值序列中检测概念漂移。 在连续的窗口中,通过熵的变化鉴别出子图分布的变化程度,若此变化是明显的,则可判断为概念漂移。 DSDD 具有较低的漂移检测延迟以及较低的漂移错误率。
LIU 等[27]则提出了一个基于等强度k 均值聚类空间分割直方图的方法 ( EqualIntensity kMeans,EI-kMeans),EI-kMeans 重点关注的如何有效地将多变量样本转换为多项式分布,再使用现有的假设检验检测漂移。 此方法能够在保持高抗噪能力的同时有着更高的检测灵敏度。
总体来说,已有的方法尚未能很好地应对类别分布不平衡的多类数据流,为此,KORYCKI 等[3]提出了一种新的基于受限玻尔兹曼机(Restricted Boltzmann Machine for Multi-Class Imbalanced Data Streams, RBM-IM)的可训练概念漂移检测器。 该算法能够同时监测多个类,并利用重构误差,独立检测每个类的变化。 RBM-IM 使用了一个不平衡的损失函数,允许其处理多个不平衡的分布。 由于其可训练性,能够跟踪流中的变化和不断演化的类角色,以及能够处理发生在少数类中的局部概念漂移。 这是一种新颖且可训练的概念漂移检测器,具有对偏移不敏感的损失函数,能够监测具有动态不平衡比率的多类不平衡数据流,是一种对偏移不敏感的生成型神经网络。 RBM-IM 存储训练数据分布的压缩特征,通过使用旧数据和新传入数据的属性间的相似性度量,便可评估数据分布是否有变化,以此来检测概念漂移。 其对多个类别不平衡的数据分布具有稳定性。
此外,还有针对区域或局部数据分布的漂移检测方法。 LIU 等[28]提出了一个区域密度不等式度量,称为局部漂移度(Local Drift Degree, LDD)测量方法,通过量化两个不同样本间的区域密度的差异,从而识别密度增减或稳定的区域,以衡量在每个可疑区域的区域漂移的可能性。 LIU 等[29]提出了一种基于区域密度估计的概念漂移检测方法,称为基于最近邻的密度变化识别方法(Nearest Neighborbased Density Variation Identification,NN-DVI)。 其由3 个部分组成。 第一部分是基于k 最近邻的空间划分模式,通过检索关键信息来将不可测量的离散数据实例转换为一组共享子空间,用于密度估计;第二部分是一个距离函数,其累积了这些子区域中的密度变化,以量化数据集之间的总体差异;第三部分是针对距离的统计显著性检验,通过该检验可以确定概念漂移的置信区间。 NN-DVI 中应用的距离对区域漂移非常敏感,并已被证明遵循正态分布。 因此,NN-DVI 的准确性和误报率在统计上得到了保证。 NN-DVI 对区域密度变化引起的概念漂移敏感度高,同时也对噪声具有稳定性。 CHEN 等[30]基于观测值,提出了一种基于局部感知分布的概念漂移检测方法,可对突发性的概念漂移进行检测。 该方法对潜在的概念集进行维护,若新传入的数据实例被错误地分类,则难以区分其是一个新的概念数据实例还是一个噪声数据实例;然而,如果在短时间内有相对大量的数据实例被错误地分类,且同时都处在同一个密集的区域中,则可以合理假设此时出现了新的概念,若在潜在概念集中发现有足够多的相邻点与错误分类的实例具有相同的标签属性,则可以推断出发生了突发式概念漂移。
此外,部分方法利用已有的漂移检测方案,将其融合训练出新的漂移检测结构。 张永等[31]提出了一种基于多层次验证的多标签数据流概念漂移检测算法,此方法的基本过程是:(1) 利用滑动窗口的思想,将多标签数据流视为一个大小相同的连续数据块;(2) 将检测概念漂移分为两层进行验证:第一层为检验层,主要计算数据分布的变化情况,使用相应标签数据质心与区间夹角的对比来测量数据块的差异,如果高于区间上限则直接判断为发生了概念漂移,低于区间下限则为未发生漂移,若在区间内发出漂移预警信息,则传入第二层校验层。 在校验层中,使用相应标签混淆矩阵之间的欧氏距离来测量差异程度,若距离大于阈值则判断为发生了概念漂移。该方法通过两层判断是否发生概念漂移,并监控数据流分布的变化。 此方法显著降低了误报率。ZHANG 等[9]则采用分层结构,提出了一种多变量监督数据流的分层缩减空间检测框架(Hierarchycal Reduced Space Detection Framework for Multivariates Supervised Data Streams,HRDS),用于准确有效地检测多维数据流的真实漂移和虚拟漂移。 其关键思想是利用监督信息中的知识来发现现有检测方法可能无法检测到的变化。 实现这一目标的基本过程为:(1) 识别一个低维空间,该空间包含与给定分类任务的最相关的信息,即识别由训练样本跨越的特征子空间,以便将输入的多元数据样本投影到该空间;(2) 不再监视原始输入样本,而是在这个缩减的特征空间中为特定的分类任务执行检测,不仅监控数据流的边缘分布,还监控每个类的条件分布;(3) 提出了一种在每次检测后重新配置信息量更大的再训练数据集的新方法,可以检测出真实漂移和虚拟漂移,同时在高维数据流上具有较高的准确性和低误报率,并且有较低的漂移检测延迟。
除了通过检测特征分布来比较数据分布的方法以外,LU 等[4]提出了一种基于案例推理(Casebased Reasoning, CBR)系统的检测概念漂移方法,引入了一个新的胜任力模型,通过测量胜任力而非特征分布来比较数据分布,胜任力是指当前能够成功解决的问题的比例,基于胜任力的概念检测方法不需要案例分布的先验知识,而是通过胜任力模型估计概率分布并检测变化,并提供检测到的变化的可靠性的统计保证。 除了确定是否存在概念漂移,该方法还可以根据胜任力模型量化和描述检测到的变化。
此外,TANHA 等[32]提出了一种数据流半监督分类的共形预测漂移检测框架(Conformal Prediction for Semi-Supervised Classification on Data Streams,CPSSDS), 使用归纳共形预测方法(Inductive Conformal Prediction, ICP)识别信息量最大的数据点,以提高增量基础学习器在每个输入数据块上的分类精度。 该框架使用增量分类器作为基础学习器,并使用自训练框架来处理标记样本的稀缺性。该方法利用一种形式的共形预测器发现一组信息丰富的未标记数据实例,并在每个训练过程中添加到原始训练集中。 在此框架下,通过比较两个连续数据块的共形预测输出的分布,采用 Kolmogorov-Smirnov 检验来检测概念漂移,而不必考虑分类过程的计算困难性。 此方法提高了半监督分类性能,且能够检测突进式与渐进式漂移,此外该方法可以改进用以高度不平衡的数据流。
2.2.3 多假设检验的漂移检测
多假设检验漂移检测算法使用多个假设检验以不同的方式检测概念漂移[2]。 YU 等[33]提出了分层线性四速率(Hierarchical Linear Four Rates, HLFR)框架,该框架通过在在线环境中利用一组分层假设检验来检测不同数据流分布(包括不平衡数据)的概念漂移,该方法还提出了一个用于概念漂移检测的两层分层假设测试框架。 此方法可以检测概念漂移的所有可能的变体并且可以显著减小误报率,甚至在存在不平衡类标签的情况下也能做到这一点。
孙子健等[34]则提出一种面向工业过程难测参数建模的双窗口概念漂移检测方法。 步骤为:(1) 建立离群样本检测窗口及分布检测窗口双窗口,在离群样本检测窗口采用支持向量回归获得实时过程数据中包含的离群样本,在分布检测窗口计算离群与历史样本间的欧氏距离;(2) 使用F 检验、t 检验及Q 检验方法,计算出样本的漂移度指标,若低于阈值则报告该离群样本发生概念漂移。 该方法提升了检测的准确度,但较依赖于模型预测精度,降低了检测效率。
2.2.4 复合漂移检测
近年来,部分研究者将上述几类方法组合起来,提出了复合漂移检测算法。 张宝菊等[35]基于错误率和漂移度,提出概念漂移的并行检测机制。(1) 使用学习算法训练模型获得每个数据块的分类错误率;(2) 比较预测错误率,如果超出置信区间;(3) 计算基于欧氏距离的概念漂移程度,若漂移程度上升,表明数据分布很可能发生变化,则报告发生概念漂移。
由于目前的漂移检测方法大多数集中于漂移位置的检测,关于漂移类型识别的研究很少。 在漂移类别识别的研究中,GUO 等[36]提出了一种基于多滑动窗口的概念漂移类型识别方法,能够在快速检测漂移位置的过程中有效识别概念漂移类型,准确分析在线学习过程中的关键信息,提高流数据分析和挖掘的效率和泛化性能。 该方法基于错误率及数据分布,在检测过程中,漂移位置由单个基本滑动窗口和单个基本静态窗口检测。 在增长过程中,使用多个滑动窗口来识别漂移类别,其中填充了少量漂移位置后的新数据。 在跟踪过程中,使用复合滑动窗口和复合静态窗口获得识别漂移子类别的重要信息。 漂移类型识别过程中通过检测漂移长度识别漂移类别。 而基于漂移类别,根据流数据中不同数据块的分布之间的关系来识别漂移的子类别。 但该方法仅适用于监督学习中,且无法准确检测增量式漂移。
2.2.5 漂移检测方法总结
综上所述,基于错误率的漂移检测方法在数据获取阶段时,基本采用固定初始窗口大小并随时间滑动以增大窗口,或自适应划分历史数据及新数据窗口,在统计值选择上以计算时间窗口之间数据实例的分类错误率为主,能够快速地检测突进式漂移或渐进式漂移。 此外,基于错误率的漂移检测方法主要预测模型随时间推移的性能,因此只在分类精度下降后才会检测变化,进而发出警报信号,而且这类漂移检测方法通常需要全面地访问真实标签,但在一些真实的场景中,概念标签并不是很容易获得,这样就降低了此类方法的实用性。
基于数据分布的漂移检测方法在数据获取阶段,其历史数据窗口与新数据窗口相互独立,该类方法主要聚焦于使用距离函数以判断双窗口中的数据实例分布的相似性差异,具有较高的检测灵敏度与稳定性,甚至能够识别概念漂移类型。 但是,此类方法虽然能够检测到输入空间内的漂移,但仍无法准确地判断漂移出现的原因是数据分布的变化还是标签标记的错误。
多假设检验的漂移检测方法在数据获取阶段以及所采用的统计值与前两者相似,但在假设检验阶段使用了多个不同的假设检验来检测漂移,能够提升检测的准确率,但损失了检测的效率。
复合漂移检测方法则是将上述多种方法组合起来,能够在提升漂移检测的精确度以及速度的同时,识别出漂移的类型。
2.3 概念漂移检测常用的公开数据集
常用的公开真实数据集,包括带有混合漂移的真实数据集,总结如下:
(1) Electricity[37]数据集 每30 min 从澳大利亚新南威尔士电力市场获取的随时间变化的电价样本,样本总数为45 312 个,每个样本包含8 个特征和2 个类。 数据集上的每个样本都有5 个字段,即星期几、时间戳、新南威尔士州电力需求、维多利亚州电力需求、各州之间的计划电力传输和类别标签。此数据集可用于短期的概念漂移检测。
(2) CoverType[38]数据集 植被覆盖类型数据集,其样本总数为581 012 个,每个样本拥有54 个特征,共有7 个类,其中54 个特征中除了前10 个为浮点数,其余均为One-hot 变量。
(3) Poker-Hand[38]数据集 扑克手数据集,可用于检测类别不平衡的概念漂移,其中包含1 025 010个样本,每个样本包含10 个特征和10 个类。
(4) KDD-Cup99[38]数据集 网络入侵检测数据集,可用于检测未知类别的概念漂移,有494 021个样本,每个样本有41 个特征和23 个类。
(5) Spam[39]数据集 垃圾邮件数据集,主要用于渐进式漂移检测,有9 324 个样本,包含了499 个特征和2 个类。
(6) NOAA Weather[40]数据集 NOAA 气象站点数据集,有18 159 个样本,每个样本有8 个特征和2 个类。
数据集设置情况见表1。
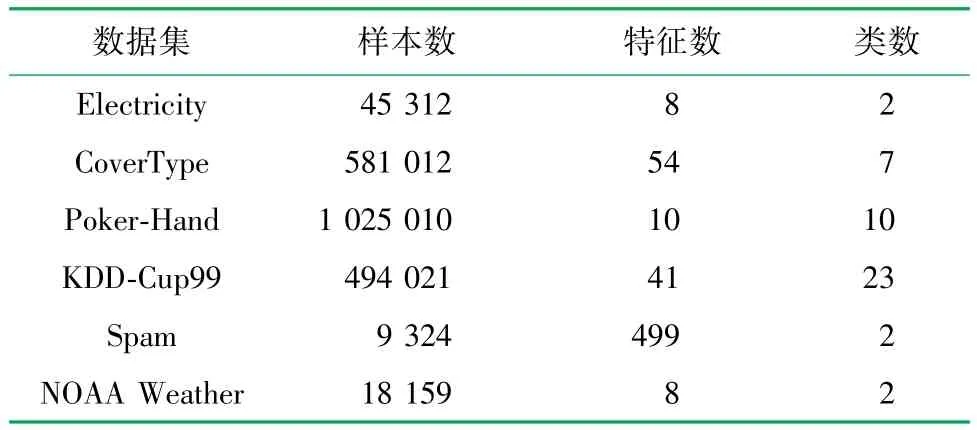
表1 真实数据集 单位:个
此外,还列出了漂移检测使用频率较高的人工合成数据集。 由于数据实例是由预先定义的规则和特定参数生成的,所以合成数据集是评估不同概念漂移场景下学习算法性能的一个很好的选择。 包括
(1) STAGGER[41]数据集 每个样本有3 个特征和2 个类。 其来源为真实漂移,可检测突发式概念漂移。
(2) Hyperplane[42-43]数据集 每个样本有10个特征和2 个类。 其来源为真实漂移,可检测渐进式与增量式概念漂移。
(3) SEA[44]数据集 每个样本有3 个特征和2个类。 其来源为真实漂移,可检测突发式概念漂移。
(4) Circle[12]数据集 每个样本有2 个特征和2 个类。 其来源为混合漂移,可检测渐进式概念漂移。
(5) Sine[12]数据集 每个样本有2 个特征和2个类。 其来源为真实漂移,可检测突发式概念漂移。
(6) LED[38]数据集 每个样本有24 个特征和10 个类。 其来源为真实漂移,可用于检测突发式概念漂移。
(7) RandomRBF[45]数据集 样本总数、特征数、类的个数均可随机生成。 其来源为混合漂移,可用于检测突发式、渐进式以及增量式概念漂移。
数据集设置情况见表2。

表2 人工合成数据集
3 展望
文章介绍了概念漂移检测的定义、形式、分类以及现有研究工作,描述了现有概念漂移检测算法重点,分析了各类方法的优缺点,并介绍了对概念漂移检测常用数据集。
现有的漂移检测算法虽然能够判断是否发生了概念漂移,但仍不能准确识别概念漂移的类型,因此该领域还需要加强对漂移类型识别的研究。 此外,漂移检测算法还面临着冷启动问题,现有的漂移检测算法需要初始窗口来收集假设检验的基本统计属性,但在初始窗口中无法实现检测策略,如果初始窗口中就存在概念漂移,这就影响了检测的效果,因此,如何解决冷启动问题是概念漂移检测的重要研究方向。
在数据集的获取方面,由于在实际应用中获得数据真实标签的成本较高,因此无监督或半监督的概念漂移检测方法也是重要的研究方向。
猜你喜欢
航空学报(2022年7期)2022-09-05
汽车维修与保养(2020年10期)2021-01-22
汽车维修与保养(2020年11期)2020-06-09
网络空间安全(2019年10期)2019-03-20
新课程·上旬(2019年1期)2019-03-18
教师·中(2017年3期)2017-04-20
科技资讯(2016年18期)2016-11-15
试题与研究·教学论坛(2016年27期)2016-08-11
学生之友·最作文(2014年5期)2014-07-09
教学研究与管理(2014年4期)2014-05-16
