
基于ERNIE-RCNN梅花研究信息文本分类方法
2022-07-06 01:04付红萍陈恺之陈志泊
东北农业大学学报 2022年5期
付红萍 ,陈恺之 ,陈志泊 *
(1.北京林业大学信息学院,北京 100083;2.国家林业草原林业智能信息处理工程技术研究中心,北京 100083)
梅花(Prunus mume)作为中国传统十大名花之首,是我国第一个获准国际登录权的植物品种[1],在国际也具有一定影响力。当前梅花主要研究方向有基因[2]、育种[3]、非生物胁迫[4]等,开发基于以上研究方向下梅花研究信息的语义检索[5]、智能问答[6]等应用,有助于研究人员使用粗粒度查询语句搜索研究信息,提高查询效率。此类应用还可根据研究人员输入的查询语句,按研究方法、研究结果、研究品种等专业知识结构呈现现有梅花研究信息,便于后续研究工作。
开发实现基于梅花研究信息的智能检索、智能问答等应用,需按不同研究方向构建梅花研究信息相关知识图谱[7]。而梅花研究信息的分类结果,将直接决定不同梅花知识图谱研究信息与研究方向符合程度,影响相关智能检索、智能问答应用中研究信息查询结果的专业度和匹配度。
目前,梅花研究信息分类的传统方法主要依靠人工,且要求人员具有较高的专业素养,存在效率较低、周期长且易出错等问题。
使用针对梅花研究信息的文本分类方法替代人工方法可有效解决上述问题[8-10]。该方法可在用户输入语料后,自动学习并按照不同语料特征进行识别并分类[11-12],无需人工干预,有效提高梅花研究信息分类效率和分类正确性。
早期文本分类方法是先手动构建文档特征后,再将文档特征输入分类器中进行预测。如朴素贝叶斯[13](Naive bayesian)、支持向量机[14-15](Sup⁃port vector machine)、隐马尔科夫模型[16](Hidden markov model)、随机森林[17](Random forestres)等。这类方法需手工构建特征而难以对文本数据特征进行全面抽取,降低模型对文本信息的泛化能力,分类效果较差。
随着深度学习不断发展,利用深度学习方法构建模型成为研究主流。单纯将词向量表示文本的深度学习模型,如Zhang等用于中文短文本分类的TextCNN模型[18],Tiun等在功能性和非功能性需求进行文本分类的FastText 模型[19],分类效果较传统机器学习方法有所提升,但模型解释性弱,难以调整模型特征。基于上下文机制的深度学习文本分类模型,如Lin等用于序列标记任务的RNN模型[20],Girshick等提出的RCNN模型[21],均可较好捕捉词语间的依赖,从而增强对本文特征的学习能力,但仅适用于短文本数据,难以处理序列长文本信息,且因顺序处理文本易产生计算瓶颈。基于注意力机制的模型,如You等提出的HAN(Hier⁃archical attention network)模型[22],可提升模型分类精度,解决长序列分类问题,但无法消除歧义,词语表示能力受限。基于预训练语言模型的深度学习模型,如Devlin等提出的在外文多源语料进行预训练的BERT[23](Bidirectional encoder representa⁃tions from transformers)模型、Sun等提出的在中文多源语料进行预训练的ERNIE[24](Enhanced lan⁃guage representation with informative entities)模型,均在大规模语料上进行训练,学习语料上下文语义后,再应用到具体分类任务中此类方法较好地解决了歧义问题,语言表征能力增强,分类效果好。
本文提出基于改进ERNIE-RCNN 的梅花研究信息文本分类方法。针对现有文本分类方法对梅花研究信息进行分类时,因缺乏训练数据导致分类精度不佳的问题,本文在搜集中文梅花文本信息并进行初步处理基础上,定义梅花研究信息类别,并对文本标注,最终构建梅花研究信息文本数据集;针对传统模型在梅花研究信息编码时难以体现文本逻辑性和语义精确性还原较差等问题,本文在改进ERNIE 模型,提升其语料预训练效果后,应用ERNIE 模型进行编码。此外,为提高分类结果准确性,本文引入TextRCNN[25]模型作为分类模型,并改进TextRCNN 模型提高其卷积层泛化能力,进一步提升模型文本特征及词序提取能力。即将ERNIE模型输出向量作为TextRCNN模型输入向量进一步提取特征,最终输出分类结果。
1 材料与方法
1.1 文本分类方法流程
本文文本分类方法总体流程如下:
第一步:搜集待研究领域或对象的相关文本语料。
第二步:完成语料预处理、语料标注等工作,构建文本数据集。
第三步:使用模型对数据集数据编码。
第四步:将编码后数据送入深度学习模型进行训练。
第五步:分类器输出最终分类结果。
文本分类方法总体流程如图1所示。
本文提出的梅花研究信息文本分类方法主要围绕文本数据集构建、文本数据编码和模型学习这3个步骤开展研究。
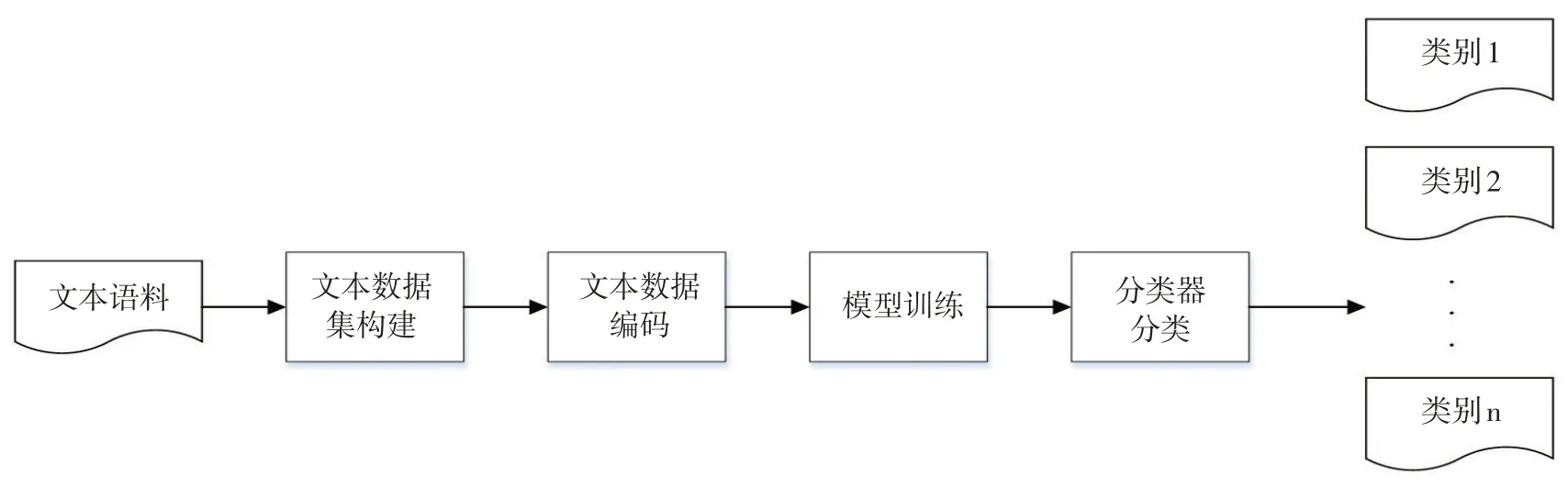
图1 文本分类总体流程Fig.1 General process of text classification
1.2 梅花研究信息文本数据集构建
1.2.1 数据预处理
首先,依托知网、谷歌学术等平台对梅花研究相关论文、新闻和百科信息中包含的梅花研究信息进行爬取,并进行整合。其次,剔除整合数据中无用词、多余词,纠正错误信息,最终完成数据预处理过程。
1.2.2 数据标注
为保证梅花研究信息分类专业性,结合论文调研及专家权威意见,归纳得到梅花主流研究方向(基因、育种、非生物胁迫等)。据此,将梅花研究信息按研究方向分为基因、育种、非生物胁迫、引种栽培、梅花特征信息、化学成分与应用信息等6个类别。
将收集的文本数据按不同研究方向进行类别标签标注。结合论文和专家意见对不同研究方向文本特点进行总结与归纳,根据文本特点,手工标注数据后人工检验,以保证标注准确性。数据集共包含梅花6个类别的10 763条标注数据。
数据集中研究方向及其对应数据条数如表1所示。梅花研究信息数据样例如表2所示。
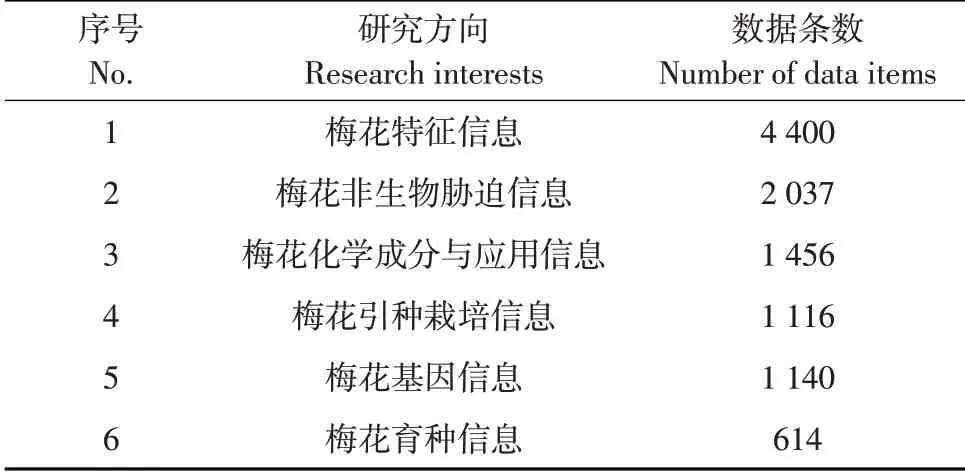
表1 数据集信息Table 1 Information of dataset
1.3 改进ERNIE模型
早期文本分类方法对梅花研究信息编码时存在以下问题:①梅花研究信息文本逻辑性强,对上下文语义依赖性较高,模型难以提取上下文信息特征,导致编码后向量对原文本逻辑还原不足。②中文词句语义丰富,存在一词多义等问题,模型编码后向量对语义还原不准确。使用预训练语言模型编码可有效解决上述问题。目前主流的预训练语言模型为BERT模型,该模型编码结构使用嵌入层、Transformer[26]双向编码、引入注意力机制等方式,解决了传统模型编码时对文本语料上下文语义提取不充分、中文文本的一词多义问题。但该模型对梅花研究信息语料仍存在中文语义概念识别不清,中文表示能力不强的问题。
ERNIE模型在BERT模型上进行改进,在预训练时引入大量中文语料,以词作为语义知识单位进行训练及建模,增强模型对中文语义表示能力,拥有更好的上下文推理能力,使模型可对不同来源、不同特征中文语料精确编码。解决了BERT模型对中文语义概念识别不清、中文表示能力弱的问题。本文选择ERNIE 模型作为语料编码模型。ERNIE模型整体结构如图2所示。

表2 梅花研究信息样例Table 2 Sample of Prunus mume's research information
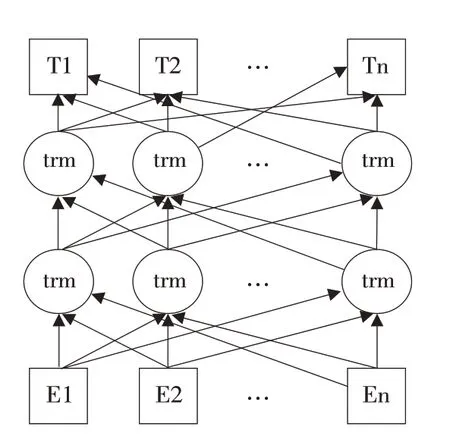
图2 ERNIE 模型结构Fig.2 Structure of ERNIE model
其中,trm 表示Transformer 编码器,其作用是对输入层向量使用自注意力机制[27],定量表示向量中每个字符对其他字的关注程度,用于解决上下文歧义问题。[E1,E2,…,En]是文本经ERNIE模型嵌入操作后的向量表示。嵌入操作由3个嵌入过程组成:①字符向量嵌入(Token embedding),标记序列中每个字符,并分割不同分句。②分段标识嵌 入 (Segment embedding) , 区 别 字符向量序列中分句,并在句子级别表示向量序列。③序列位置嵌入(Position embedding),表示向量序列中每个字符在序列中位置。嵌入操作流程如图3所示。
自注意力机制运行过程如下:编码器为每一个输入向量额外创建三类向量:Value向量、Query向量和Key向量,三类向量分别由输入向量与编码器内已训练的3 个内置矩阵Wv、Wq、Wk相乘得到,然后这三类向量组成矩阵,依据公式(1)计算输出向量,完成自注意力机制。输出向量计算公式为:
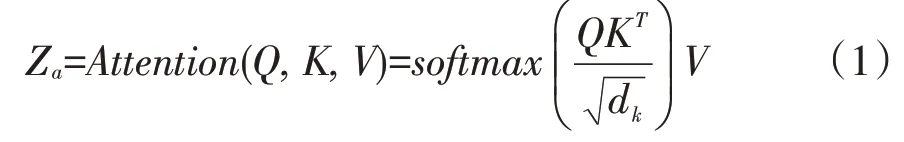
式中,Za-编码层输出向量;Q-Query 向量组成矩阵;K-Key 向量组成矩阵;V-Value 向量组成矩阵;dk-Query向量维度。

图3 嵌入操作流程Fig.3 Process of the embedding operation
ERNIE 模型利用多个Transformer 编码器在隐藏层内实现多头注意力机制[28]。在多头注意力机制中,每个注意力头(Header)可看作是单个Trans⁃former 编码器,分别拥有相应Query、Key、Value权重矩阵。在计算不同注意力头的关注程度向量Z1,Z2,Z3,…,Zn后,模型将向量拼接,乘上编码层内置的附加权重矩阵W0后,得到最终的自注意力矩阵。计算公式如下:
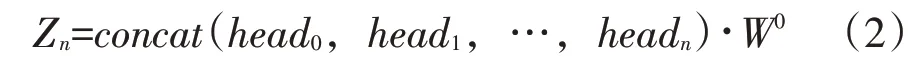
其中,headi=Attention(Qi,Ki,Vi);
式中,Zn-编码层输出的自注意力矩阵。
多头自注意力机制与输出的编码向量共同作用,提升句子词语间关注程度,相比仅使用单个Transformer模型的自注意力机制方法,可更好解决一词多义问题。
在ERNIE 模型编码前,需在大规模语料上完成预训练过程。预训练目的是训练隐藏层的相关参数,得到文本通用表示,提升编码准确性。在训练相关参数同时,模型也依据预先设置的丢弃率,对隐藏层进行Dropout 操作,以防止隐藏层中相关参数过于依赖某些特征导致过拟合,影响编码结果。
本文从两方面改进ERNIE模型编码结构,以提升ERNIE模型预训练效果,提高其编码准确性。一方面,增加ERNIE 模型每个隐藏层中多头注意力机制中的注意力头数目,将12个注意力头提升至16个注意力头,以增强对文本特征信息、位置信息和权重信息的精确编码能力。另一方面,将隐藏层丢弃率(Dropout 值)由0.1 提升至0.15,提高模型泛化能力,使模型对不同结构、内容的文本有更强的泛化性。改进ERNIE模型编码结构如图4所示。

图4 改进ERNIE编码结构Fig.4 Architecture of improved ERNIE encoder
预训练结束后,将改进的ERNIE 模型应用于梅花语料中,最终完成编码过程。[T1,T2,…,Tn]为ERNIE 模型编码后向量输出,输出向量将被输入TextRCNN模型进行文本分类。
1.4 改进TextRCNN模型
TextRCNN模型借鉴RNN和CNN结构,在分类过程中保留文本词序,考虑文本上下文信息,同时也可提取文本重要特征,取得较两类模型更好的分类正确性。本文采用TextRCNN 模型作为分类模型,其结构如图5所示。
TextRCNN模型分类过程如下:①输入层对输入向量进一步编码。②卷积层获得输入层编码后向量,通过循环神经网络模型对向量进行前向和后向扫描,获取文本更多上下文信息,并结合上下文特征向量作为输出。③拼接层将输入层输出向量与卷积层输出向量进行拼接形成新向量,使用tanh 函数进行激活。④拼接层输出向量被送入池化层,池化层进一步提取其特征值,以获取文本中重要句子成分。⑤全连接层对池化层输出结果进一步整合与提取后,通过softmax函数获取分类结果的概率分布。⑥最后在输出层输出分类结果。
本文对TextRCNN卷积层中(BiLSTM[29]层)Drop⁃out值进行改进,将Dropout值从0.1提升至0.2,使卷积层对不同文本输入有更好的泛化性,提高上下文信息获得精确度,为拼接层提供特征信息更为全面的输出向量,最终提高TextRCNN模型分类效果。

图5 TextRCNN模型结构Fig.5 Structure of TextRCNN model
1.5 改进的ERNIE-RCNN模型
改进的ERNIE-RCNN 模型为1.3 中改进的ER⁃NIE 模型与1.4 中改进的TextRCNN 模型的组合模型。该模型建立步骤如下:
第一步:使用含中文维基百科、百度百科、百度新闻、百度贴吧等的多源预训练数据集对改进的ERNIE模型进行训练,完成预训练过程。
第二步:将梅花研究信息文本数据集划分为训练集、验证集和测试集,使用字向量表示梅花研究信息文本数据,并将字向量读入到改进的ERNIE模型。
第三步:改进ERNIE 模型将初始字向量转为编码后向量,并将编码后向量作为改进TextRCNN模型输入向量。
第四步:通过ERNIE 模型编码后向量对Tex⁃tRCNN模型训练,并输出分类结果。
模型建立步骤如图6所示。

图6 模型建立步骤Fig.6 Step of constructing model
2 试验与分析
2.1 试验环境
模型训练环境配置为:处理器为i7-9750,CPU 频率为2.60 GHz,内存16.00 GB GPU 为RTX 2060。模型编写和训练在Windows 环境下使用PyTorch框架完成,编程语言为Python3。
2.2 试验数据
将数据集中已标注的基因、育种、非生物胁迫、引种栽培、梅花特征信息、化学成分与应用信息等6 个类别共10 763 条标注数据作为试验数据。为保证研究科学性,从试验数据中随机选取80%作为训练集,10%作为验证集,10%作为测试集。
2.3 模型评价指标
评估文本分类效果常用的4 个指标为精准率P、召回率R、F1值[30]以及正确率ACC。
精准率公式如下:

式中,TP-模型预测样本为此特定类且实际也为此特定类样本数;FP-模型预测样本为此特定类但实际不为此特定类样本数。
召回率公式如下:

式中,FN-样本实际为此特定类别,但模型预测为其他类别样本数。
F1值公式如下:


正确率公式如下所示:式中,TN-模型预测到其他类别且归类正确的样本数;N总-总样本数。
2.4 试验及方法验证
为验证改进ERNIE-RCNN模型性能,本文开展分类效果验证、参数选择两类试验,试验设计如下:
试验1:改进ERNIE-RCNN模型分类效果验证。对比改进ERNIE-RCNN模型、仅改进ERNIE的ER⁃NIE-RCNN 模型、原始ERNIE-RCNN 模型、ERNIE模型、BERT模型、TextRCNN模型,分别测试其在梅花研究信息文本数据集的精准率、召回率、F1 值和正确率。
试验2:改进ERNIE-RCNN 模型关键参数研究。观察改进ERNIE-RCNN 模型关键参数与文本分类正确率变化关系,分析改进ERNIE-RCNN 模型关键参数选取依据。
2.4.1 改进ERNIE-RCNN模型分类效果验证
分类效果验证模型及其对应关键参数见表3。
所有模型均设置初始学习率为5×10-5,训练轮数设置为50,使用Adam 算法对模型进行训练[31]。采用相同试验数据进行训练,评估试验结果。
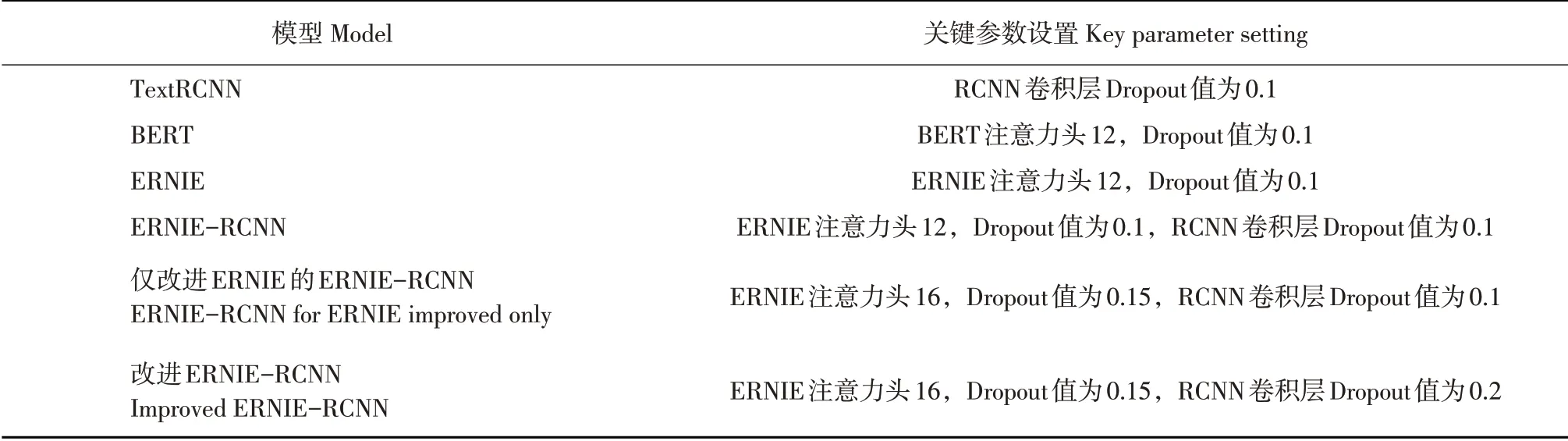
表3 模型及关键参数Table 3 Model and key parameters
不同模型对梅花研究信息分类精准率见表4,改进ERNIE-RCNN模型对于梅花所有研究信息的分类精准率最高。其中,对于育种信息的分类精准率最高,为98.36%;对于化学成分的分类精准率最低,为91.53%。
不同模型对梅花研究信息召回率见表5。由表5可知,改进ERNIE-RCNN模型对于梅花所有的研究信息分类召回率最高。其中,对于梅花的特征信息分类召回率最高,为98.35%;而对于育种信息的召回率为最低,为90.27%。
不同模型对梅花特征信息分类F1值见表6。由表6可知,改进ERNIE-RCNN模型在梅花所有研究信息上F1值最高。其中,在特征信息的F1值最高,为97.56%。而在基因信息的F1值为最低,为92.35%。
不同模型正确率见表7。由表7可知,改进ER⁃NIE-RCNN模型在测试集上正确率最高,为95.35%。
探究6种模型F1值和正确率,发现其余5种模型对于不同研究信息的分类效果总体高于TextRCNN模型,说明预训练语言模型对上下文关系和位置信息进行学习和编码后,可综合提升模型精准率、召回率及分类正确率。在加入TextRCNN 模型后,ERNIE-RCNN 模型F1 值和正确率高于原ER⁃NIE 模型,表明TextRCNN 模型对语义特征优化和提取效果较好。
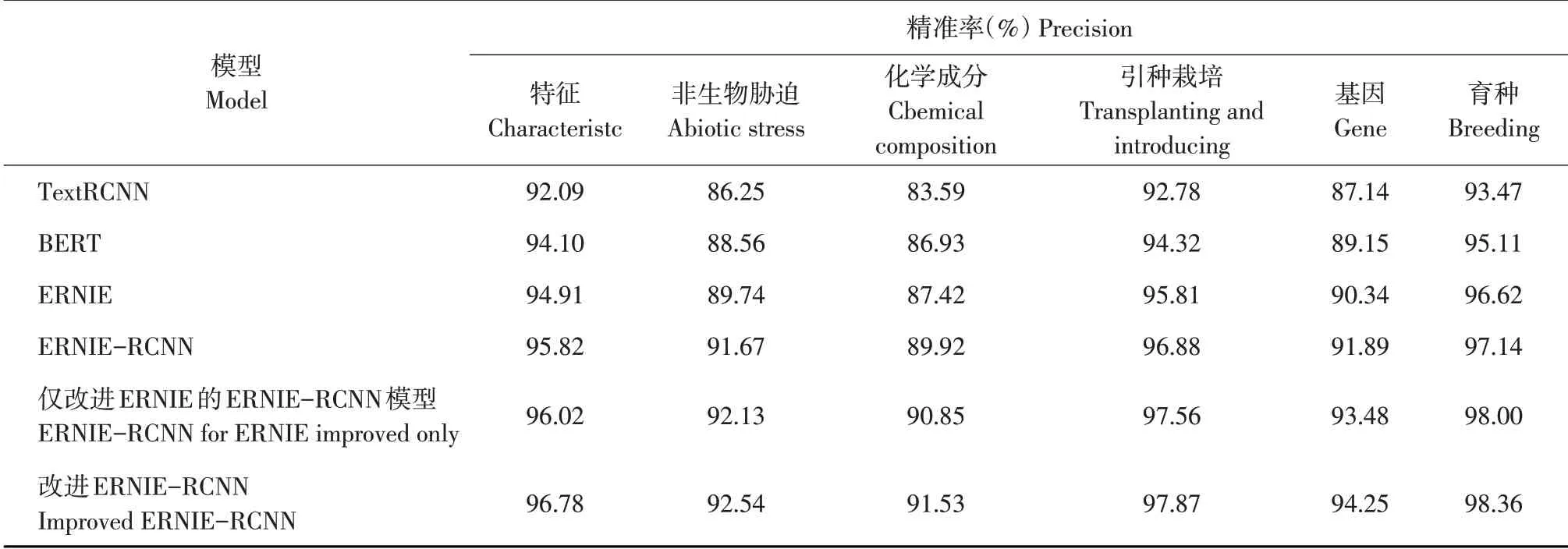
表4 梅花研究信息精准率比较Table 4 Comparison of research information's precision rate with different classification model

表5 梅花研究信息召回率比较Table 5 Comparison of research information's recall rate with different classification model
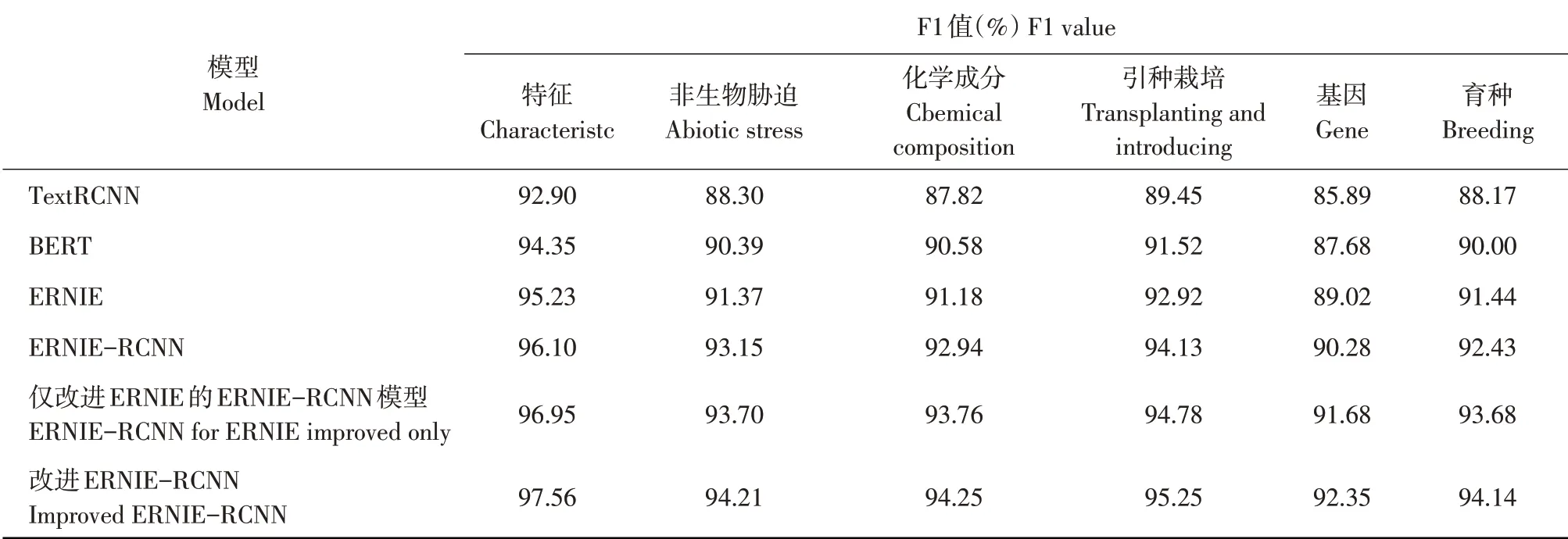
表6 梅花研究信息F1值比较Table 6 Comparison of research information's F1 value with different classification model

表7 不同模型正确率比较Table 7 Comparison of accuracy with different classification model
对比仅改进ERNIE 的ERNIE-RCNN 模型与改进ERNIE-RCNN 模型的正确率可发现,在ER⁃NIE 模型保持相同关键参数的前提下,仅对Tex⁃tRCNN模型进行改进可提升分类正确性,但提升幅度低。对比仅改进ERNIE模型的ERNIE-RCNN模型与ERNIE-RCNN模型的正确率可发现,仅改进ER⁃NIE 模型的ERNIE-RCNN 模型相对于ERNIE-RCNN模型的分类正确性提升幅度较高。综上可说明ER⁃NIE-RCNN模型分类正确性更依赖于ERNIE模型的编码效果。
对改进ERNIE-RCNN 模型在不同研究信息的分类指标进一步探究,发现其在化学成分类别的精准率较低。原因为此类别下语料文本特征不鲜明,包含的干扰信息相对较多。可通过进一步完善化学成分信息的描述方式,精简化学成分信息的文本描述篇幅,使模型可以更好提取其文本特征。
分析不同类别召回率发现,改进ERNIERCNN模型在育种信息类别的召回率较低。原因为该类别数较少,模型尚未完全掌握该类别文本特征。可通过扩充相关研究信息数据集解决该问题。
改进ERNIE-RCNN 模型在所有梅花研究信息上获得相对于其他模型的最好识别效果,证明此模型在语料较少、语义混淆等语料不完善情况下具有较好鲁棒性和分类能力。
2.4.2 改进ERNIE-RCNN模型关键参数研究
本文使用控制变量法,对改进ERNIE-RCNN模型关键变量开展研究试验。
①注意力头数目对分类效果的影响
保持改进TextRCNN 模型参数不变,在ERNIE模型预训练过程中设置不同注意力头数目,观察模型正确率随注意力头数目变化规律,结果见图7。
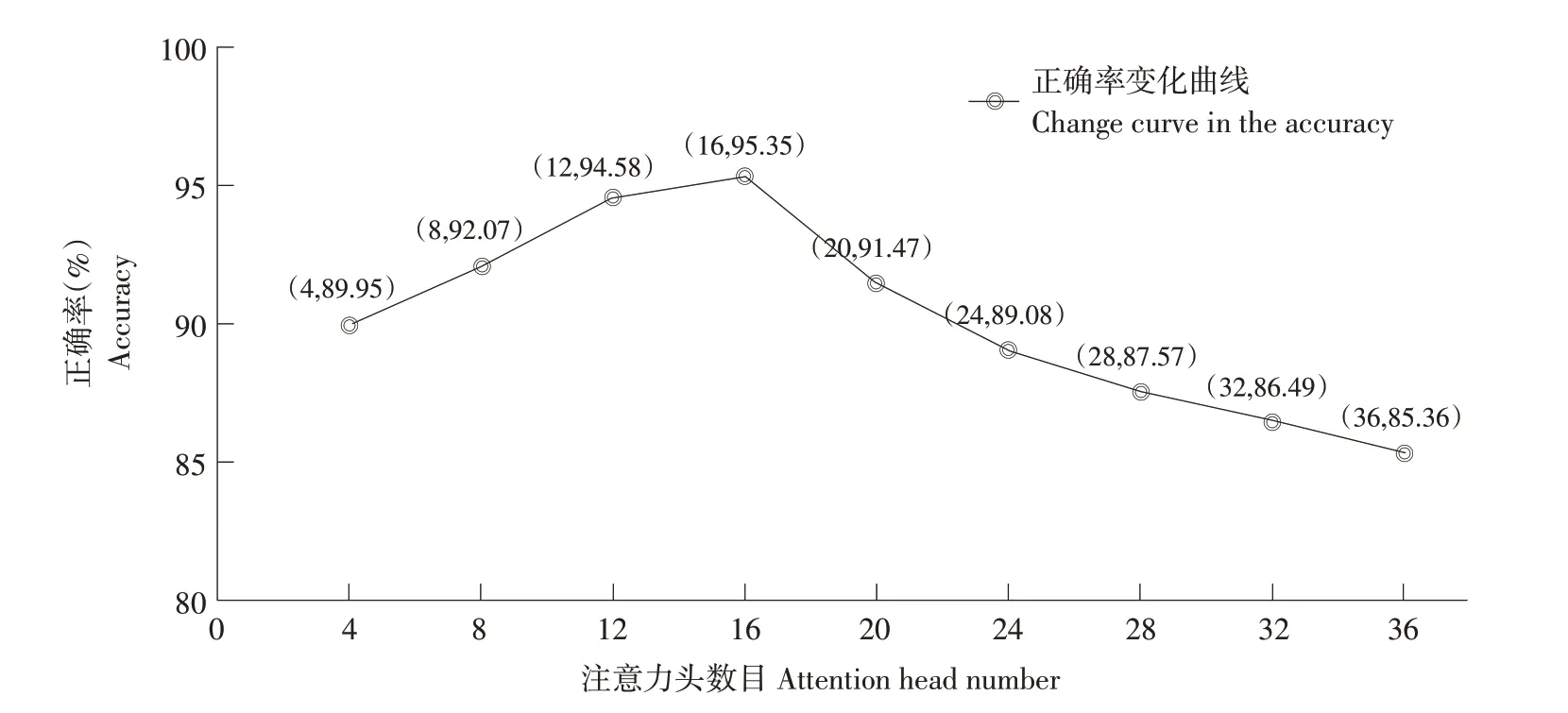
图7 注意力头数目与正确率关系Fig.7 Relationship between attention head number and accuracy
由图7 可知,注意力头数目为16 时模型正确率最高,为95.35%。注意力头数目<16时,注意力头数目越高,模型正确率越高。注意力头数目>16时,模型正确率持续下降。原因为注意力头数目<16时,随注意力头数目增多,模型对语料位置、上下文信息提取能力逐步提升,正确率呈升高趋势,而注意力头>16时,不同注意力头所提取的上下文和语料位置信息产生混淆,模型文本分类正确率下降。由此可知,适度增加注意力头数目,可有助于提升预训练语言模型编码能力,提升模型识别效果。但注意力头数目过多会形成干扰,减弱模型编码作用,最终降低模型分类正确率。②ERNIE模型中Dropout值对分类效果的影响保持改进TextRCNN 模型参数不变,在ERNIE模型预训练过程中Dropout 值分别为0.05、0.1、0.15、0.2、0.25、0.3、0.35、0.4、0.45、0.5。观察模型采用不同Dropout 值时对应的正确率变化规律,结果如图8所示。
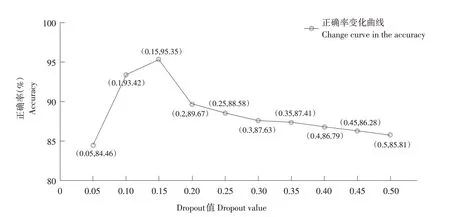
图8 ERNIE模型Dropout值与正确率关系Fig.8 Relationship between Dropout value in ERNIE model and accuracy
由图8 可知,Dropout 值在0.15 时正确率最高,为95.35%。Dropout值小于0.15时,Dropout值越大,正确率越高;Dropout 值大于0.15 时,随Dropout 值增加,模型正确率持续下降。原因为Dropout 值过大时,ERNIE 模型在预训练过程中被随机丢弃的特征也较多,使ERNIE 模型无法全面学习语料特征,编码不精确,最终ERNIE-RCNN模型分类正确率下降。而当Dropout 值较小时,ERNIE 模型编码过分依赖局部特征,导致ERNIERCNN模型泛化性下降,最终正确率降低。由此可知,Dropout 值偏大或偏小均对ERNIE-RCNN 模型正确率造成损失。
③TextRCNN 模型中Dropout 值对分类效果影响
保持改进ERNIE 模型参数不变,在TextRCNN卷积层中Dropout 值分别为0.05、0.10、0.15、0.2、0.25、0.30、0.35、0.40、0.45、0.50。观察TextRCNN模型采用不同Dropout值时正确率变化规律,结果如图9所示。
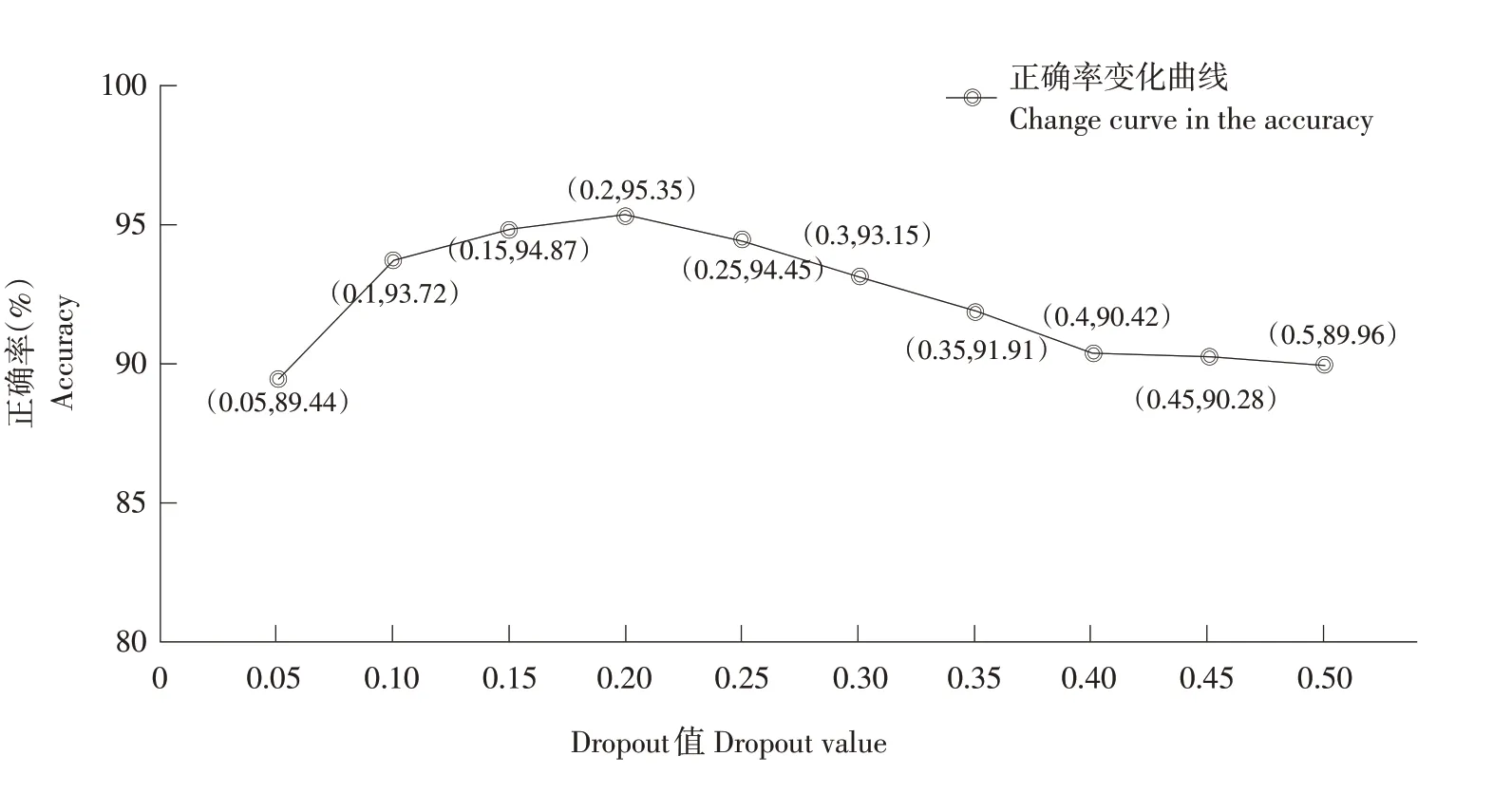
图9 TextRCNN模型Dropout值与正确率关系Fig.9 Relationship between Dropout value in TextRCNN model and accuracy
由图9 可知,Dropout 值在0.2 时正确率最高,为95.35%。Dropout 值小于0.2 时,Dropout 值越大,正确率越高;Dropout 值大于0.2 时,随Drop⁃out值增加,模型正确率持续下降。因为当Dropout值过大时,TextRCNN中卷积层在训练时被随机丢弃的特征也较多,使TextRCNN 模型对语料上下文特征提取较少,在传递到拼接层时语料特征不全面,导致ERNIE-RCNN 模型分类正确率下降。而当Dropout 值较小时,TextRCNN 卷积层中前后向扫描时上下文语料特征丢弃较少,使得输入至拼接层时拼接层过于依赖部分语料特征,导致ER⁃NIE-RCNN模型在分类时泛化能力下降,正确率也随之下降。由此可知,Dropout 值偏大或偏小均对卷积层输出向量特征提取产生干扰,最终对ER⁃NIE-RCNN模型正确率造成损失。
3 结 论
对梅花研究信息开展高效准确分类,既是构建梅花研究信息知识图谱的重要预处理工作,也可为基于梅花研究信息进行相关语义检索、智能问答提供良好基础。因此,本文提出基于改进ER⁃NIE-RCNN模型的梅花研究信息文本分类方法,并验证其分类效果。
通过对比试验发现,改进ERNIE-RCNN 模型相对于仅改进ERNIE 的ERNIE-RCNN 模型、原始ERNIE-RCNN 模 型、ERNIE 模 型、BERT 模 型 和TextRCNN 模型分类效果均有提升,表明改进方法的有效性、深度学习应用于梅花研究信息分类的可行性,可为梅花或其他植物研究信息的文本分类问题提供新思路和参考。
当前模型在部分研究信息类别上分类效果不理想,下一步将通过研究新方法并引入更多语料进一步优化当前模型和提高分类效果。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
医学食疗与健康(2022年3期)2022-04-23
中国典型病例大全(2022年7期)2022-04-22
现代计算机(2021年33期)2022-01-21
小学生学习指导(中年级)(2021年12期)2021-12-30
健康体检与管理(2021年6期)2021-11-17
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
家教世界·创新阅读(2016年11期)2016-12-27
故事会(2016年15期)2016-08-23
