
基于深度学习的垃圾识别分类系统研发
2022-07-03 14:33王科,林志华,刘丰俭
江苏工程职业技术学院学报 2022年2期
王 科 ,林 志 华 ,刘 丰 俭
(江苏工程职业技术学院,南通 226007)
随着人们生活水平的不断提高,日常生活垃圾数量激增。据世界银行报告,全球垃圾到2050 年将暴增70%,达到34 亿吨,[1]如何有效地进行垃圾处理成为难题。垃圾分类是科学地进行垃圾处理的前提,有助于可回收垃圾的再利用以及有害垃圾的无害化处理等。随着《生活垃圾分类制度实施方案》的实施以及若干城市的成功试点,垃圾分类逐渐成为人们日常生活的一部分。一方面,垃圾分类可以减少资源浪费;另一方面,垃圾分类可以减少环境污染,有利于生态文明建设。在目前的实施方案中,垃圾分类主要依赖居民的主动分类和监督员检查,对居民的素质有一定的要求且需要投入一定的人力,效果并不显著。近年来机器视觉技术的迅猛发展给解决这一问题提供了新思路,那就是借助于机器视觉技术进行垃圾分类。目前,基于深度学习的图像分类方法逐步多样化,为垃圾识别的研究提供了新方向。[2-4]本文提出一种基于预训练深度学习神经网络的垃圾分类系统,系统包含算法模块和Web 模块。算法模块包含数据增强、模型预训练、模型微调、模型推理等功能,并采用Dropout、Adam 和早停机制等关键技术。Web 模块提供用户交互功能。利用华为云人工智能大赛数据集进行训练,验证模型的准确性,并与VGG16 网络模型进行准确性比较,最后将系统部署在服务器上,完成垃圾分类系统的开发。
1 系统设计
1.1 卷积神经网络
深度卷积神经网络是一种前馈神经网络,网络结构深,由若干卷积层和激活函数、若干池化层、全连接层以及使用Softmax 激活函数的输出层组成,在图像识别领域应用广泛。[5]卷积层中的卷积核主要作用是提取图像特征,在本设计中,经过处理后的垃圾图片大小统一为224×224 像素,经过若干不同大小的卷积核进行相乘相加,然后将结果经过非线性激活函数的优化后输出;池化层夹在两个连续的卷积层间,主要用于压缩网络数据和参数的数量以减少过拟合;全连接层的作用是使各神经元进行相互全连接。整个卷积神经网络的传播过程如图1 所示,包含前向传播和反向传播过程。在前向传播过程中,通过对输入的垃圾图像数据进行多层卷积层的卷积和池化处理来提取特征向量,将特征向量传入全连接层,得出分类识别的结果。若识别结果与期望值不符,则进行反向传播。首先求出输出值与期望值之间的误差,再将误差链式返回,计算出每一层的误差,最后更新权值,使得下一次前向传播过程的垃圾分类结果值更新。

图1 卷积神经网络的训练过程
1.2 预训练网络
卷积神经网络学习和推测过程可以归纳为从带标签的数据中学习高维且抽象的特征,并泛化到同类型的未知数据。而对于图像识别这种视觉任务,则需要更深的网络提取更高维度的特征。但随着卷积神经网络层数的增加,网络中未知参数的数量会显著增加,这需要更大的训练集来优化模型参数,以防止过拟合。一种解决方法是使用预训练网络,使用卷积神经网络在大型数据集(例如ImageNet)上训练提取足够的一般特征,将其网络结构及浅层的网络参数复制到新的网络模型中,然后冻结一部分参数,训练其余参数和全连接层参数。这种方法直接利用从海量数据中学习到的成熟模型,然后进行微调,再用现有的数据集进行训练,准确率较高。垃圾识别分类的预训练步骤如下:①在预训练卷积基上添加自定义层,包含一个密集连接分类层、批标准化层、分类层;②冻结卷积基所有层;③利用垃圾分类数据集训练添加的自定义层;④解冻卷积基的一部分层,即微调模型中的高阶特征表示,以使它们与垃圾分类任务更相关;⑤利用垃圾分类数据集联合训练解冻的卷积层和添加的自定义层。
1.3 数据增强
神经网络的训练依靠数据集,但数据集的采集及标注工作耗时久、耗力多,很难得到十分充足的训练数据,在此过程中还可能会出现过拟合。数据增强是从现有的训练样本中生成更多的训练数据,其方法是利用多种能够生成可信图像的随机变换来增加样本,目标是模型在训练时不会两次查看完全相同的图像。这让模型能够观察到数据的更多内容,从而具有更好的泛化能力。为获得更多数据,可以对现有的数据集进行一系列的随机几何变换,以提升数据样本数量,缓解训练数据集的类别数量不均衡问题。常见的数据增强的方法有几何变换(平移、翻转、旋转)、随机调整亮度等。
以易拉罐为例,对易拉罐图像进行随机变换运算后可以产生多张不同的图像,图2 显示了变换后的4张图像。数据样本的扩增可以提升模型的泛化能力,有助于抑制模型过拟合现象的发生。

图2 易拉罐图像增强结果
1.4 垃圾识别分类算法设计
卷积神经网络中权重参数的求解依赖于前向传播和后向传播理论,根据链式求导法则得到式(1)。

式(1)中,J 是网络误差,ωji(k)是第k-1 层网络中第i 个神经元连接到第k 层第j 个神经元的连接权重,zj(k)是第k-1 层网络连接到第k 层第j 个神经元的输出值。若乘积部分大于1,当网络层数增多,最终求出的梯度更新将以指数形式增加,即发生梯度爆炸;若乘积部分小于1,当网络层数增多,求出的梯度更新信息将会以指数形式衰减,即发生了梯度消失,这会使深层网络的训练效果比浅层网络的差。使用ResNet 网络可以解决梯度消失或爆炸问题。ResNet 网络模型通过添加残差捷径,将输入和输出部分进行恒等映射,从而可以轻松扩展神经网络的层数,无损地传播梯度。
本文使用ResNet50 神经网络进行垃圾识别,ResNet50 网络分5 层,如表1 所示。其中第一层结构较为简单,即对输入进行卷积计算,可视其为对输入图像的预处理。后4 层由残差网络构成,分别用设计好的残差块依次叠加3、4、6、3 次,最后进行全连接,经过归一化形成各自类别的概率。每个恒等残差块中卷积核的顺序分别是 1×1,3×3,1×1,其中上一个 1×1 卷积层用于减少通道数,下一个 1×1 卷积层用于恢复通道数,这样就可使中间的3×3 卷积层的输入和输出的通道数都较小,既保持了精度又减少了计算量,因而效率更高。

表1 ResNet50 网络结构
基于TensorFlow(一个基于数据流编程的符号数学系统)的Keras(一个由Python 编写的开源人工神经网络库,可以作为Tensorflow 高阶应用程序接口)完成ResNet50 网络的搭建,使用数据增强技术扩充训练样本数量,使用ImageNet 数据集预训练ResNet50 网络,关键技术如下:① Dropout 算法。ResNet50 网络中参数数量约为25.6 M,即便使用数据增强提高样本数量,还是存在训练样本数不够大及训练样本噪声问题,易导致过拟合,故采用深度学习领域广泛采用的Dropout算法[5]提高网络的泛化能力。②自适应学习率Adam 算法。学习率对于卷积神经网络的性能具有显著影响,常见的学习率调整算法有 RMProp、Momentum、Adam 等。Adam 算法通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率,收敛速度快,学习效率高,适合处理大数据集。③早停机制。早停是一种用来避免训练迭代时出现过拟合现象的正则化方法。深度网络迭代训练时,尽管在训练集上表现越来越好,错误率越来越低,但实际上在某一刻,它在验证集的表现已经开始变差,这种现象在深度网络的训练中很常见。[6]为避免这种情况,可以设置保存使验证集误差最低的参数来获得更优的模型。如果在预设的耐心循环迭代次数内验证误差没有下降,则提前终止训练过程,这样能够使得算法始终存储训练过程中最优的深度网络模型,不仅节省了训练时间,而且可获得泛化能力更好的模型。
1.5 Web 界面设计
深度学习垃圾分类系统包含提供算法支持的算法模块和实现用户交互功能的Web 模块,系统功能模块如图3 所示。Web 模块利用Flask 框架搭建,Flask 是一个轻量级Web 应用框架,具有结构简单、部署轻快的特点。垃圾识别Web 界面采用Web Service 方式提供数据,用户通过post 方式将拍摄或现有的图像提交给后端,后端调用卷积神经网络进行预测,并把结果以json 的格式返回前端。
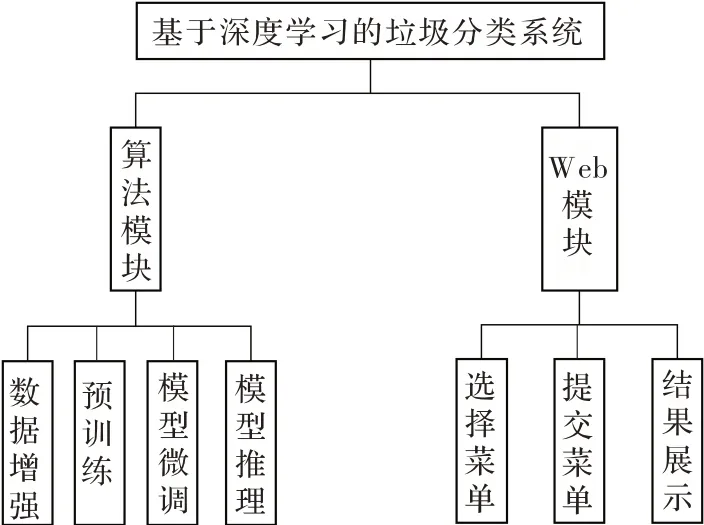
图3 深度学习垃圾分类系统模块图
2 试验与结果
2.1 数据集
本文训练数据集采用的是华为技术有限公司云人工智能大赛提供的垃圾图像数据集,该数据集涵盖了生活中常见的垃圾,并按照最新的垃圾分类标准将垃圾分成了可回收垃圾、厨余垃圾、有害垃圾和其他垃圾4 大类。该数据集总共包含14 082 张图片,其中数量最多的是可回收垃圾(8 611 张图像),数量最少的是有害垃圾(1 150 张图像),厨余垃圾 3 389 张,其他垃圾 1 652 张。
垃圾图像标签由两部分组成,包括4 个大类别和40 个小类别,其中4 个大类别中可回收垃圾类包含23 个小类别,有害垃圾类包含3 个,厨余垃圾类包含8 个,其他垃圾类包含6 个。各类别图像数量分布不均衡,厨余垃圾类的菜叶菜根图像数量最多,有736 张,最少的是其他垃圾类的牙签,有85 张。详见图4。

图4 垃圾数据集数据分类图
2.2 模型的训练与分析
对数据集进行数据增强及归一化处理后,将数据集按比例随机划分为8∶2,其中80%数据作为训练集,20%数据作为测试集。模型训练时,采用Adam 算法对神经网络进行迭代优化,设置初始学习率lr 为0.001,迭代过程中的样本批处理大小设置为32,学习衰减率为0.000 5,迭代训练的次数为100 次,早停容忍循环次数为10 次,选择交叉熵作为损失函数。选用的实验平台的计算机配置如下:Intel Xeon Silver 4210 CPU*2,128G RAM,Ubuntu16.04 操作系统,训练模型时计算并记录分类准确率和损失值的趋势。
ResNet50 网络训练后的正确率及损失值趋势如图5 所示,模型训练5 轮之后测试准确率趋于平稳,在26 轮训练结束后触发了早停机制,提前终止训练。最终训练准确率达到98.7%,测试准确率达90.8%。

图5 ResNet50 模型训练结果图
为了评估当前垃圾分类识别神经网络模型的性能,设计VGG16 网络开展对比试验,对比参数包括模型参数数量、准确率等指标。对比试验均使用微调模型的迁移学习方法,试验结果见表2。从表2 可以看出,ResNet50 的训练准确率达到98.7%,测试准确率达90.8%,结果优于VGG16 网络。

表2 不同网络模型训练结果
3 系统测试
在完成垃圾分类模型的训练后,将训练好的模型集成至Web 平台,并对模型进行分类功能测试。基于前述垃圾分类算法分析与设计,深度学习的垃圾分类Web 平台包括照片选取、手机拍照(移动端)、垃圾分类等主要功能。移动端运行效果如图6 所示。Web 界面包含选择菜单,点击选择菜单会提示照片图库、拍照和浏览3 个选项。选中照片图库将打开相册选择图片,拍照按钮会唤醒相机进行拍照。选中图片后,点击提交按钮,图片将会上传至服务器,系统进行模型推理识别并将识别结果返回前端,为用户处理垃圾提供指导。上传1 张网上的一次性餐盒图片,测试垃圾识别分类系统能否准确识别,图7 显示了识别标签为其他垃圾/一次性快餐盒,识别结果准确。进一步随机选取6 张不同类别的垃圾图片,分别是竹筷、易拉罐、电池、茶叶渣、毛绒玩具和烟蒂,图8 显示了垃圾图片识别出的标签,可以看出识别结果无误,识别效果良好。

图6 系统在移动端的运行效果图

图7 系统的运行结果示例图

图8 垃圾图片识别测试结果示例图
4 结论
本文基于深度学习构建垃圾识别分类系统,训练数据选用华为云人工智能大赛垃圾分类数据集,并对数据集进行数据增强,提出基于ResNet50 网络模型和迁移学习的图像分类方法,采用Dropout、Adam 和早停机制等关键技术。测试结果表明,系统能准确识别不同类型垃圾。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
科普童话·学霸日记(2021年2期)2021-09-05
当代陕西(2019年24期)2020-01-18
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
小太阳画报(2018年10期)2018-05-14
北京航空航天大学学报(2018年1期)2018-04-20
重型机械(2016年1期)2016-03-01
