
基于强化学习的网联车辆协同感知方法
2022-07-03 14:33陆阳阳
江苏工程职业技术学院学报 2022年2期
陆 阳 阳
(江苏工程职业技术学院,南通 226007)
0 引言
车辆协同感知是指相互连接的车辆通过V2V 通信[1](vehicle-to-vehicle communication,车辆间通信,简称V2V 通信)交换原始或处理过的传感器数据来增强安全性。无论是人工驾驶还是自动驾驶,传感器捕获的盲点数据均有助于避免车辆碰撞。本地车载传感器的感知范围和检测精度有限,当目标物体远离传感器或被道路物体遮挡时,可能无法准确检测并处理。虽然协同感知是增强互联车辆感知能力的有效方案,但它过于依赖V2V 通信,会产生大量数据,易导致网络拥塞。为保证通信可靠,每个连接的车辆都应智能选择传输数据,以节省网络资源。本文提出了基于强化学习的网联车辆协同感知方法,通过交换各自采集的传感器数据,每个连接的车辆使用本地车载传感器和通信获得的数据来了解周围环境,能有效避开盲区,提高行车安全系数。使用CIVS[2](Cooperative & Intelligent Vehicle Simulation,车辆智能协同仿真,简称CIVS)仿真平台来评估该方法,结果显示,该方法比传统单车环境感知方法检测范围更大、精度更高。
对协同感知方法的研究可以从传感器的数据处理、无线网络的应用等多方面展开。许多研究人员利用传感器融合来提高数据的可靠性和一致性,Rauch 等[3]提出了一种两步融合架构,Chen 等[4]设计了基于3D 点云的协同感知方法,以增强自动驾驶车辆的检测能力,但要求车载传感器必须是激光雷达传感器。也有文献阐述了协同感知网络方面的研究成果,Gunther 等[5]通过车载点对点网络研究了协同感知的可行性,还研究了标准分散式拥塞控制机制的可行性。强化学习[6]是一种流行的机器学习技术,被应用于车载通信中,Ye 等[7]利用强化学习对V2V 通信进行资源分配,每个V2V 链路都能找到最佳的传输功率。强化学习对于复杂的优化问题应用前景也很广阔。
1 网联车辆协同感知的准备工作
协同感知增强了车辆的感知能力,但车辆需要智能选择传输数据以节省网络资源。图1 给出了两个实例场景,车辆均配备车载传感器和V2X 通信(Vehicle to X,意为vehicle to everything,即车与物通信)接口。如图1a 所示,当所有车辆能相互看到时,不需要通过协同感知来共享数据。如图1b 所示,车辆B 看不到车辆C 时,来自周围车辆的协同感知数据有助于安全驾驶。同时,由于网络资源有限,周围参与协同感知的车辆需要智能选择有益的数据。

图1 车辆路况实例场景
强化学习能使智能体(Agent)在交互式环境中学习。强化学习包括3 个基本概念:状态(state,描述智能体的当前状态)、动作(action,表示智能体在每个状态下可以执行的操作)和奖励(reward,描述了智能体执行某种动作后引起的正面或负面的环境反馈)。强化学习的总体目标是通过学习使总回报最大化。本文的基于强化学习的网联车辆协同感知方法通过强化学习来确定每个连接的车辆要传输哪些本地车载传感器捕获到的周围环境信息。系统采用的强化学习技术为Q-Network[8]。首先在Q-learning 中创建并维护一个Q-table 作为智能体选择最佳策略的参考表。智能体可以查询Q-table,以确定与所有“状态—动作”对关联的奖励。在训练期间,通过式(1)不断计算和更新存储在Q-table 中的Q-value:

式(1)中 α 是学习因子,st是当前状态,at是时间 t 的动作,Q( )st,at是动作值函数估计值,rt是奖励,γ 是折扣因子,maxaQ(st+1,a)是下一个动作的预估奖励,Qnew(st,at)是新的动作值函数估计值。如式(2)所述,智能体选择最佳行动以获得最大化奖励,A 是动作集。

强化学习Q-learning 算法的完整描述如下:给定有限离散状态和行为空间马尔可夫决策过程的状态集S 和动作集A,其中折扣因子为γ,以表格形式存储动作值函数估计值Q(s,a)及动作选择策略π。强化学习Q-learning 算法步骤为:第一步,初始化动作值函数和学习因子α,初始化马尔可夫决策过程的状态,令时间t=0;第二步,循环,直到满足停止条件位置。循环算法为:①对当前状态st,根据动作选择策略π决定时间t的行为at,并观测下一时刻的状态st+1;②根据迭代公式(1)更新当前“状态—动作”对的动作值函数估计值Q(st,at);③ 更新学习因子,令t=t+1,返回①。
由于Q-table 可能会因大量的状态和动作而变得很大,因此采用卷积神经网络。在Q-Network 中输入是智能体的状态,输出是该状态所有可能操作的Q-value。
2 系统模型
图2 所示为系统模型的架构。在该模型中,每个连接的车辆通过V2X 通信并从相邻的车辆接收协同感知信息。此外,车辆还在本地融合来自多个车载传感器的信息,如摄像头、激光雷达和多普勒雷达。在处理这两类数据后,模型将通过V2X 通信网络将接收到的感知数据进行全局融合。由于有很多融合本地传感器和V2X 通信数据的策略[3],因此本模型不依赖于任何特定的融合算法,同时优先考虑局部感知的信息。为避免车辆通信中的信息泛滥,本模型只传输基于本地车载传感器的感知信息。在进行全局融合后将信息投影到基于网格的容器中,用于强化学习中的状态st。

图2 传感器融合模型
3 强化学习Q-learning 和网络模型
由于强化学习的目标是通过训练来实现长期回报最大化的,故本文将协同感知的状态、动作和奖励设计为:
1)状态。对状态st使用两个信息,即扇形投影和网络拥塞水平。首先,用扇形投影维护感知数据,如图3 所示,将车辆可视区域分割成5×3 的网格。如表1 所示,每个网格有13 个投影候选类别中的1 类。这13 个类别由4 个因素决定,即局部感知、BSM(Basic Safety Message,基本安全信息,简称BSM)传输、CPM(Cooperative Perception Message,协同感知信息,简称CPM)传输和CPM 中的对象。
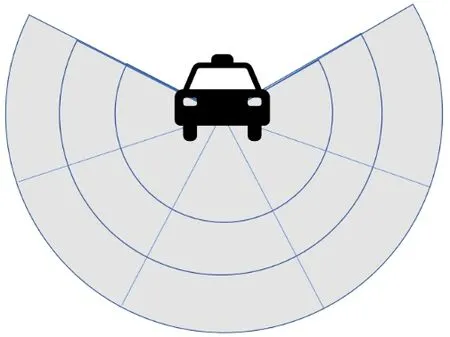
图3 扇形投影
如表1 所示,局部感知分为3 类,即空、占用及遮挡。网格中没有对象时标记为空。当本地传感器检测到某个网格中存在对象时,标记为占用。当某个网格被对象遮挡时,标记为遮挡。所有互联的车辆将BSM 作为安全标准进行传输。由于每个智能体根据其状态来控制CPM 的传输,因此智能体可能会从相邻连接的车辆中接收CPM。此外,本文使用网络负载φ 作为状态st的一部分,需要在网络拥塞时限制传输的感知数据量。网络负载φ 根据最近时间窗口内接收到的BSM 和CPM 的数据量计算得出。本文将网络负载φ 分为5 个等级。当周围没有车辆时,网络负载φ 为1 级;当车辆密度高时,如在拥挤的市区,网络负载φ 则为5 级。虽然智能体无法估计接收者的网络拥塞水平,但智能体和接收者都在V2X 通信的通信范围内,因此假设他们具有相似的网络条件。总之,时间窗口W 内的所有信息,包括扇形投影和网络拥塞级别都作为卷积神经网络的输入数据。

表1 扇形投影分类
2) 动作。系统的目标是减少车辆通信中的冗余信息,同时保持目标跟踪误差在较低水平。本文的模型中,定义了动作空间A={Transmit,Discard},其中当动作变为Transmit(传输)时智能体传输CPM,当动作变为Discard(丢弃)时智能体不传输CPM,动作由卷积神经网络输出的Q-value 值确定。
3) 奖励。本文设计了协同感知奖励,以提高感知能力的同时减少CPM 中的重复消息。在式(3)和式(4)中给出了奖励机制 rt,ω,m,n,其中有 1 个奖励和 3 个惩罚。rt,ω,m,n是在时间 t 内目标对象 ω 在发射器 m 和接收器n 的通信中获得的奖励。

式(3)、式(4)中,λ 表示奖励因子,t 表示时间,当接收器 n 未检测到共享对象 ω 时,值设为 1。ucpm、uℎist和unetconfig表示惩罚,是常量,值为负数。θ 表示在时间t 内包含对象ω 的CPM 的数量,通过该因子,模型可以在多个车辆共享相同的信息时给出更大的惩罚。φ 表示uℎist的惩罚因子。Tω是通过接收器n 的局部感知来监测对象ω 的最新时间戳。Ct,n是接收器n 在时间t 上的网络拥塞水平。
对于Q-learning,本文设计了3 个卷积层和2 个连接层组成的卷积神经网络。第一个卷积层有32 个8×8 的内核,步幅为 2;第二层有 64 个 4×4 的内核,步幅为 2;第三层有 64 个 3×3 的内核,步幅为 1;第四层是完全连接的512 个单元;第五层有1 个用于每个动作、传输(Transmit)和丢弃(Discard)的单元。
4 仿真平台测试评估
本文使用CIVS 车辆仿真平台进行模拟测试,并与单车感知方法、多源信息融合的环境感知方法[9]、动态传播的协同感知方法[8]在网络负载和目标检测可靠性方面进行比较。图4 为4 种不同车辆密度环境下CPM 共享数据的数量对比,可见基于强化学习的网联车辆协同感知方法减少了CPM 中共享的数据量,降低了网络负载。图5 为不同训练时间下不同方法的检测率对比,检测率越高,可靠性越高。在训练时间不足时,多源信息融合的环境感知方法调用了本地多个硬件,检测率最高;由于网络拥塞和数据丢包,基于强化学习的网联车辆协同感知方法在训练初期检测率提高不明显,但不断训练后,检测率逐步提高。图6 为不同训练时间下不同方法的数据包接收率对比,接收率越高表示车辆间通信质量越好。多源信息融合方法需要多个车载传感器传递感知数据,数据量较大,因此其接收率最低,动态传播的协同感知方法受网络状态影响较大,数据包接收率波动较大,基于强化学习的网联车辆协同感知方法随着训练时间的增加数据包接收率逐渐提高且优于其余3种方法。
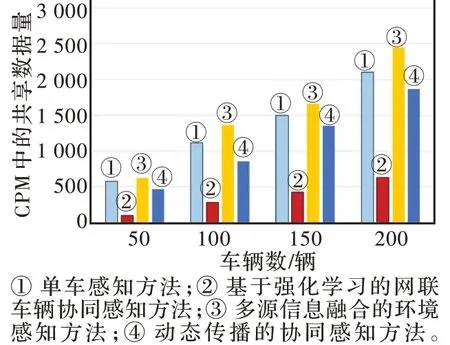
图4 不同车辆密度下CPM 中共享数据量的对比

图5 不同训练时间下不同方法的检测率对比

图6 不同训练时间下不同方法的数据包接收率对比
5 总结
本文提出了一种基于强化学习的网联车辆协同感知方法,互相连接的车辆智能地选择传输的数据来保持网络中较低的数据流量,通过减少网络负载降低数据包冲突的风险。仿真平台测试表明,该方法相比单车感知方法、多源信息融合的环境感知方法等提高了感知的准确性和可靠性,但该方法还存在局限性,后期研究还需考虑周围建筑物对车辆通信和感知的影响。
猜你喜欢
新班主任(2022年4期)2022-04-27
内燃机与配件(2022年2期)2022-01-17
数学物理学报(2021年1期)2021-03-29
家庭影院技术(2020年12期)2021-01-18
科学大众(2020年23期)2021-01-18
汽车观察(2019年2期)2019-03-15
电子制作(2018年18期)2018-11-14
金融经济(2017年9期)2017-09-13
中国公共安全(2017年9期)2017-02-06
家庭影院技术(2017年12期)2017-02-06
