
一种基于联邦学习与区块链的传染病预警模型*
2022-06-09 05:45李道兴李元诚刘海青
自动化技术与应用 2022年5期
李道兴,李元诚,刘海青
(华北电力大学 控制与计算机工程学院,北京 102206)
1 引言
传染病是由病原体引起的能在人与人或人与动物之间相互传播并广泛流行的疾病。传染病传播的速度很快,并且一旦爆发将给个人,社会,国家带来巨大的损失[1]。如果能提早预警传染病的爆发,就可以通过防疫措施将疫情控制在局部地区,从而尽可能减少疫情所带来的负面影响。因此传染病预警模型在传染病预防的过程中起到了重要的作用[2]。
根据传染病预警模型使用的技术种类,可以将传染病预警分为两类:基于统计学的传染病预警模型和基于大数据技术的传染病预警模型。基于统计学的传染病预警模型按照传染病流行的三间可以分为时间模型,空间模型,时空模型这三类[3]。时间模型利用传染病确诊的时间和人数信息,通过回归法[4],时间序列法[5],统计过程图法[6]等方法对传染病是否爆发进行预警。空间模型[7-11]利用患者地理位置的相关信息,监测传染病患者是否出现了空间上的聚集性,从而发出预警信息。时空模型[12-15]借助于时间和空间聚集性探测方法,来判断固定区域内的病例数、空间聚集热点区域是否达到预警阈值,如果达到,系统则发出预警信号。传统的传染病预警模型最大的问题在于其必须依赖医院确诊,上报传染病病例,从而对传染病的爆发进行预警,因此对于已知类型的传染病效果较好。但是对于突发的未知新型传染病,相关部门很难在短时间内统一诊断标准,从而降低了预警的时效性。基于大数据技术的传染病预警系统使用诸如网站搜索量等网络信息,不用依赖医院确诊传染病病例来对传染病的爆发进行预测,从而提高了传染病预警系统的实时性。2009年,Ginsberg 等人[16]利用谷歌网站上对于流感的搜索数据,比当地疾控中心提前一周预测了流感爆发的到来。近年来,随着深度学习技术的成熟,使用社交媒体信息进行传染病预警的研究也越来越多。Aramaki 等人通过将自然语言处理技术与支持向量机相结合,分类出和流感相关的twitter[17]。Serban 等人设计的传染病系统SENTINEL,通过结合临床数据与twitter 数据对传染病是否爆发,以及爆发的严重性进行预警[18]。虽然基于大数据技术的传染病预警系统在预警实时性上表现优异,但是社交媒体上的存在大量错误和虚假信息,可能误导预警系统。而如果采用医院中电子病历中的信息来进行传染病预警则无法保护患者的隐私。
本文建立了一种新型的传染病预警模型,采用电子病历作为预警数据源,在保证患者数据隐私的前提下,通过联邦学习的方法训练symptomBERT 模型提取电子病历中关于症状和疾病的相关信息并输出传染病症状向量,最后利用C2&C3算法检测传染病症状向量的各个维度构成的时间序列,一旦出现异常峰值则会立刻预警。在训练symptom-BERT 模型的过程中采用了信誉区块链来选取可靠的计算节点来保证symptomBERT模型的训练效果。
2 模型设计
2.1 传染病预警模型结构
我们设计的传染病预警模型如图1所示,其中最重要的是两个部分,一个是负责从电子病历文本信息中提取得到传染病症状向量的SymptomBERT模型,其次是C2&C3预警算法。
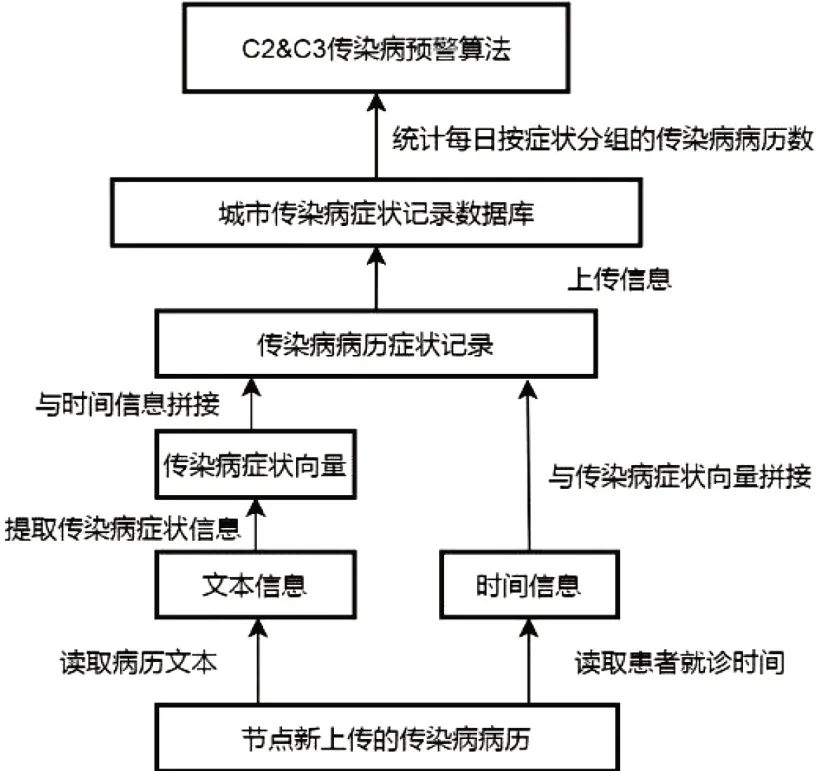
图1 传染病预警模型结构
由于电子病历生成会先于传染病卡(疑似病例在未确诊前不会填写传染病卡),因此从电子病历文本信息中提取传染病症状向量进行预测保证了我们的预警模型具有较高的实时性。同时为了保证信息提取的准确性,我们采用了最新的自然语言处理模型BioBERT[19]并对其进行了部分改进。我们的新模型命名为SymptomBERT。SymptomBERT 模型以BERT模型[20]作为基础,其结构如图2所示,其中采用了多层双向Transformer[21]作为编码器和解码器。不同于传统的循环神经网络,Transformer以自注意力模块为基础进行构建,因而能够更好的构建句子中相隔较远的词之间的依赖关系,对于文本类的任务具有较好的表现。此外,为了输出传染病症状向量,我们在原始BERT模型的基础上还在最后一层添加了一个全联接层来调整输出的维度。Symptom-BERT 由24 个Transformer 模块构成,每个Transformer 模块的隐藏层数目为1024,注意力机制数为16,总共含有近3亿4千万参数。因为SymptomBERT模型规模较大,我们首先需要对其进行预训练,让其首先能够提取出医学文本的表征,然后再通过微调训练的方式让其输出传染病症状向量。预训练采用MaskLM 方法,首先随机将病历中15%词掩盖掉,SymptomBERT模型的任务是读取整个句子来预测被掩盖的词的真实值是什么从而完成预训练。在预训练结束后,我们再通过微调训练的方式让SymptomBERT适应提取传染病症状向量的任务。
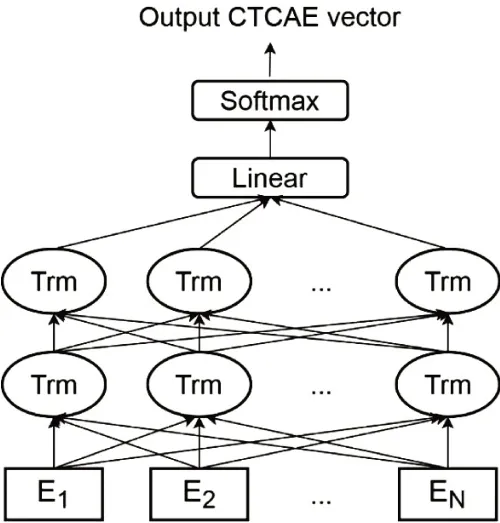
图2 SymptomBERT模型结构
为了保护电子病历数据中的患者隐私信息,我们采用联邦学习的方式来对模型进行微调训练。联邦学习是一种新型的分布式保护隐私的机器学习技术,它使分布式的节点能够协作地训练一个全局的机器学习模型,而不需要将私有的本地数据上传到中央服务器。每个节点从中央服务器中获得一个初始参数为θ 的全局机器学习模型(在本文中为SymptomBERT模型)ΦBERT(θ),并用本地的电子病历数据对其进行训练。当节点用本地数据完成训练后将把模型的参数或梯度上传到中央服务器的从而对全局模型的参数进行更新。假设节点n有用于训练的数据集sn,则总共N个节点所含的全部数据集为sn=s。在上述条件假设下,联邦学习的目标函数可以写为以下形式
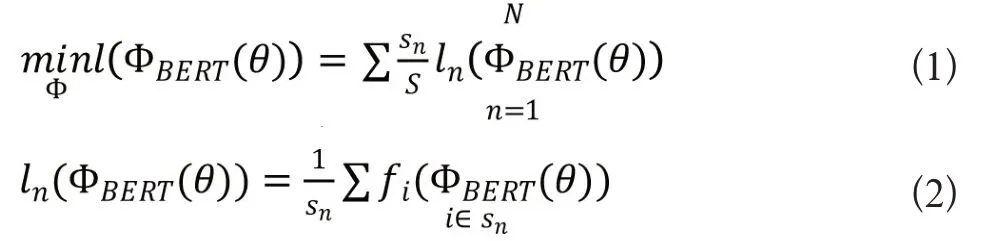
其中fi是在节点n中样本i产生的损失函数值。
在全局模型训练的第t个迭代,每个节点将会上传其使用本地数据集训练参数为θ(t)全局模型ΦBERT(θ(t))得到的梯度,假设每个节点使用随机梯度法对模型进行训练,更新步率为αn,则本地的模型在t+1 时刻的参数为:。之后在模型聚合阶段,全局模型将聚合所有本地节点模型的参数,从而完成对于SymptomBERT模型的微调训练。
当出现新的传染病病历时,训练后的SymptomBERT模型会自动提取病历中的传染病症状信息,生成传染病症状记录,并将其上传至数据库。数据库会统计该地区每日按症状分组的传染病病历数,再由C2&C3 算法来判断是否发出预警,C2&C3算法是由美国疾控中心研发的EARS系统[22]的核心算法之一,适合传染病综合症状信息的预警监测,其具体算法如下所示。假设一共监测J种传染病症状,那么传染病症状记录数据库第i日上传的含有第j种症状的病例数为,C2&C3算法首先计算7天内该症状病例数时间序列的中位数Medianj。
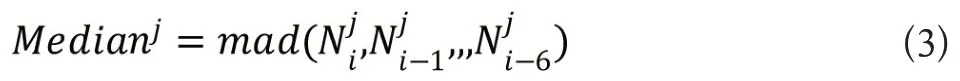
其中mad()代表求中位数运算,之后计算中位数标准差MAD。
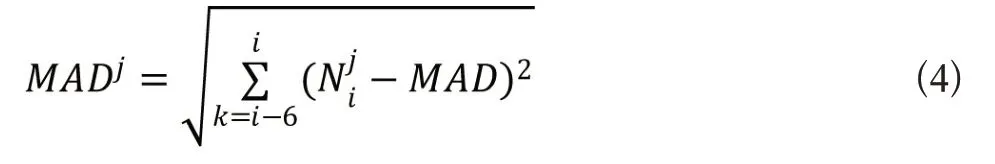
C2 预警是针对某个症状的预警,假设症状为j,则该症状触发C2预警的条件为:
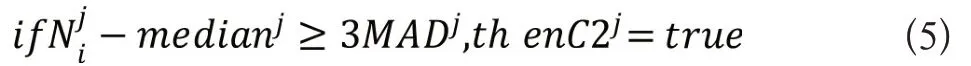
当触发3 个或3 个以上的C2 预警时则会触发级别更高的C3预警,用公式的形式可以表示为:
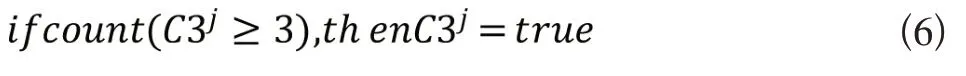
C2&C3 传染病预警模型的准确度主要依赖于SymptomBERT 模型的信息提取的准确度,因此我们采用一种基于区块链的联邦学习框架来选取可靠的训练节点,从而保证SymptomBERT模型的训练效果。
2.2 基于区块链的传染病预警模型联邦学习训练框架
为了使用含有大量患者隐私数据的电子病历数据来训练SypmtomBERT 模型,我们参考文献[23]中的模型,设计了一个基于联盟区块链的联邦学习框架来训练Symptom-BERT模型。这个联邦学习框架包括两层,应用层与区块链层,详情如图3所示。
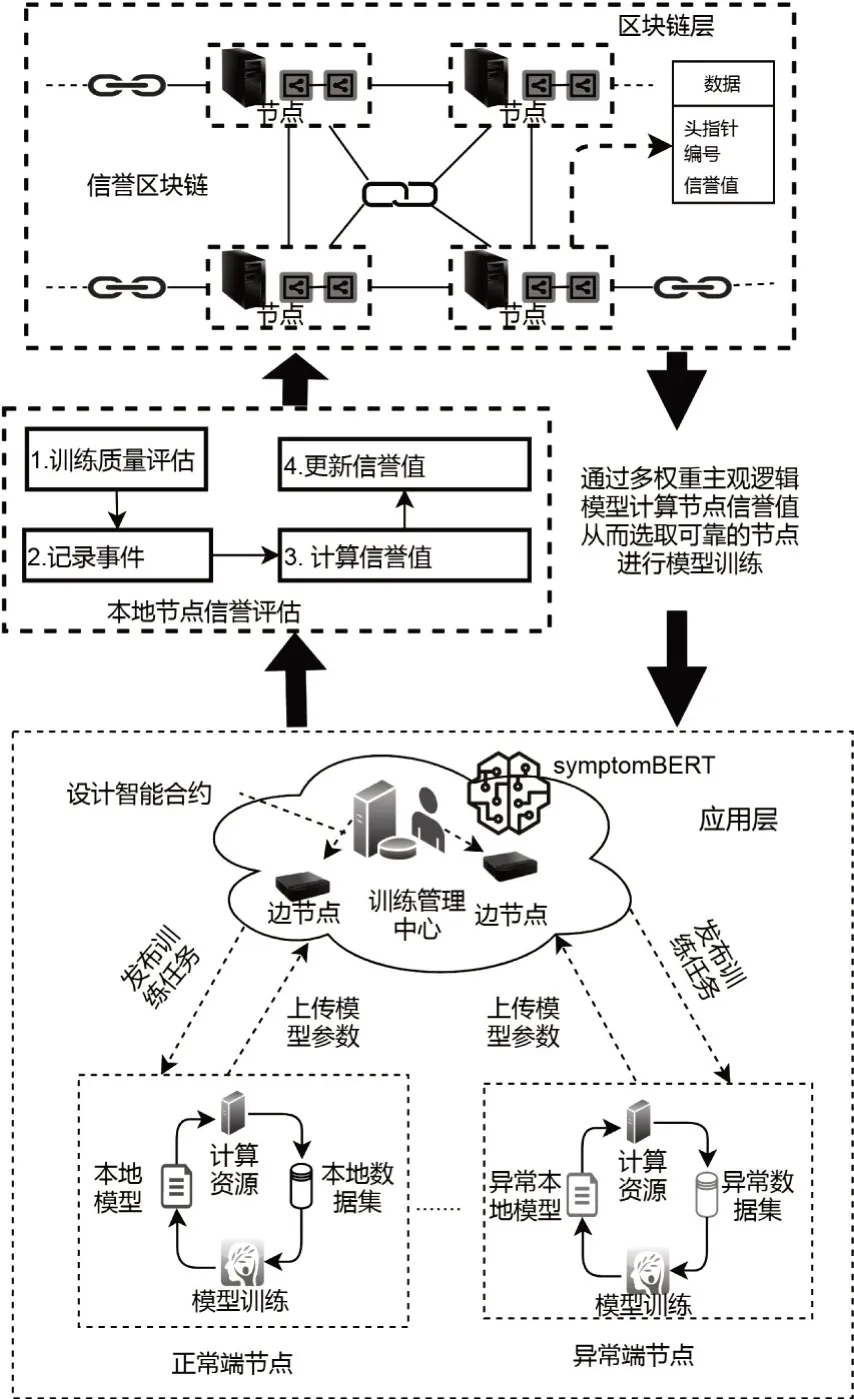
图3 传染病预警模型联邦学习训练框架
在应用层,我们考虑使用以太网网作为底层结构,整个网络采用环状与星状混合的拓扑结构,网络的端节点是部署在医院的深度学习服务器,并将广泛部署的交换设备作为网络的边节点。端节点不仅具有先进的算力,同时也储存着大量包含患者隐私数据的电子病历。联邦学习的特点在于:当训练管理中心发布训练SymptomBERT 的任务后,端节点会直接利用本地的数据进行模型训练,而不会将本地的数据上传至中心的服务器,从而保证了患者数据的隐私性。由于部分端节点设备可能不在线或者临时被其他深度学习模型训练任务所征用,因此训练管理中心会首先设计一个智能合约来选取可靠的端节点作为训练节点来进行Symptom-BERT 模型的训练。每个训练节点使用本地的数据来训练SymptomBERT 模型得到新的SymptomBERT 模型参数。训练节点完成训练后会将本地的模型参数上传至训练管理中心中来更新全局的SymptomBERT模型。训练管理中心会将本地模型的参数进行聚合,并更新到全局的Symptom-BERT 模型上。以上的步骤将会一直重复直到全局的SymptomBERT 模型的准确率达到预先设定的值。广泛分布的边节点使端节点能够及时与训练管理中心进行通信。训练管理中心将根据训练节点模型更新和训练的情况来生成该端节点的信誉。信誉的管理由区块链层的联盟区块链来进行,我们称该区块链为信誉区块链。
在区块链层,由于边节点同时连接着端节点与训练管理中心,因此我们利用边节点来选取符合条件的端节点作为训练节点。我们使用基于信誉的方法训练节点。当完成端节点的信誉被所有端节点一致验证后,该节点的信誉值将会被存储到信誉区块链的数据块中。由于区块链的分布式与不可篡改的特点,即使在发生争议和破坏的情况下,数据区块中存储的信誉值仍是永久而公开的证据。在计算信誉时,我们不仅考虑使用来自本次训练SymptomBERT模型时模型训练中心提供的信誉值,还将结合该端节点之前训练深度学习模型的的表现作为间接信誉值来综合考虑端节点的信誉值。信誉值是选择训练节点的最重要的指标。
3 模型可行性评估
我们的实验主要分为两个部分:第一部分是通过联邦学习的方法训练SymptomBERT 模型提取电子病历中的症状向量,第二部分是利用训练好的SymptomBERT 模型提取症状向量并利用C2&C3算法对传染病进行监测预警。我们实验在云平台上的虚拟机上进行,虚拟机配置了一块NIVIDIA 2080Ti GPU,内存为16g,采用Ubuntu 16.04LTS操作系统。
在第一部分实验中,我们基于PyTorch内核的联邦学习框架PySyft来实现SymptomBERT模型。由于电子病历数据涉及病人的隐私较难获取,我们仅从中国临床案例成果数据库中获取到了529 份与传染病相关的文本型电子病历数据,因此我们采用了迁移学习的方法来对github 上的chinese-clinical-NER 开源项目中使用的BERT 模型进行微调,从而获得用于提取症状向量的symptomBERT模型。我们首先对529份文本型电子病历数据进行人工标注,并将分为训练集和测试集两部分,训练集包含400 份电子病历样本,储存在4 个联邦学习数据节点中,每个节点100 份,这些数据节点中的电子病历样本在训练时不会被上传到中心节点,从而保护了患者的隐私;测试集包含129 份电子病历样本。在微调过程中,我们只对SymptomBERT 模型中Linear 层和Softmax 层的参数进行反向传播,保持其他层参数不变。训练过程中损失值的变化如图4所示。
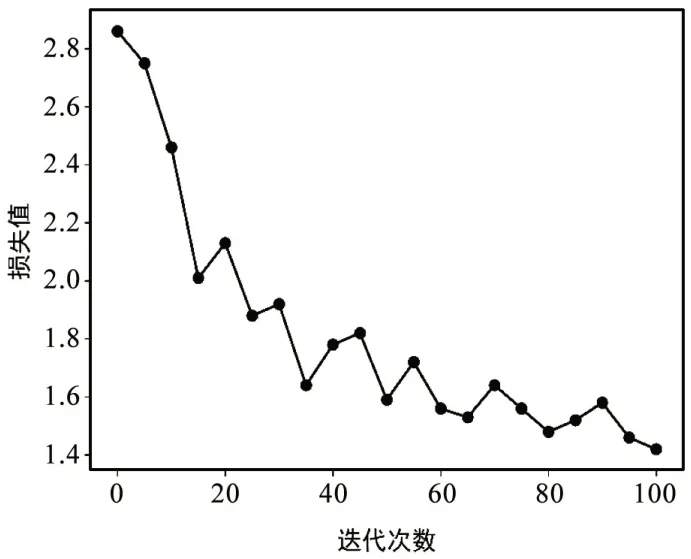
图4 SymptomBERT模型训练过程中损失函数值的变化
从图4中我们可以看到随着迭代次数的增加,损失值逐渐下降,并最终在1.5 附近波动,证明symptomBERT 模型在电子病历训练集上收敛。我们在电子病历测试集上对训练后的symptomBERT模型进行了测试,symptomBERT模型在电子病历测试集上的准确率为0.80,回归率为0.83。
在第二部分试验中,我们采用某私立医院提供的2015年到2017年传染病相关的3191 条电子病历数据,其中2956条是结构化数据,其中的症状信息记录在表格中可以直接提取;235 条为非结构化文本数据,需要使用SymptomBERT模型对其中的症状信息进行提取,我们提取了三种症状信息:咳嗽(Cough)、发热(Fever)、咳痰(Expectoration),并用C2&C3算法对其进行监测预警。症状信息的时间分布如图5所示。
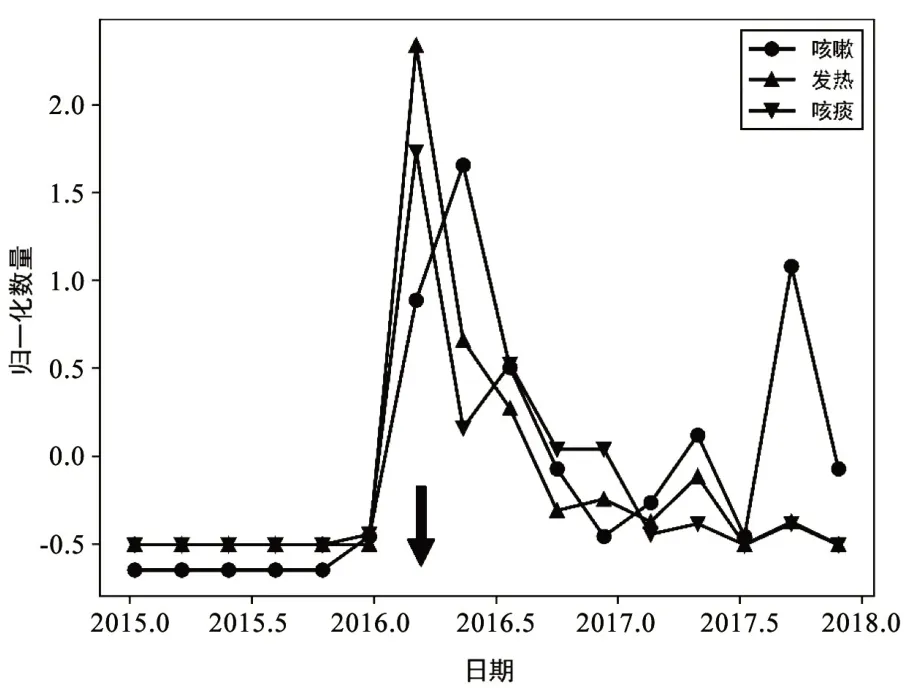
图5 症状信息的时间分布图
从图5中我们可以看到C2&C3算法在2016年2月15日产生了咳嗽、发热、咳痰三种症状的C2预警信号(图5中黑色箭头),并产生了C3 预警信号。而在在2016年2月16日,咳嗽、发热、咳痰三种症状的数量达到最大值。这表明C2&C3算法能够对传染病的相关症状信息进行有效的监测预警。
4 结束语
本文基于联邦学习和区块链技术提出了一种新型的传染病预警模型,利用分布在各医院的端节点存储的电子病历数据训练SymptomBERT 提取症状向量对传染病发病情况进行检测,并用C2&C3 算法判断传染病是否爆发从而进行预警。该模型通过监测电子病历中描述的症状来对传染病进行预警,不需要精确确诊是哪种传染病,因此该模型更加适用于突发新型传染病疫情的预警。本模型的主要创新点在于使用了联邦学习的方法训练SymptomBERT模型从而保护了病历数据中患者的隐私,并采用信誉区块链来选取可靠的端节点进行训练从而保证了模型训练的抗干扰性。实验证明基于联邦学习和区块链的传染病预警模型可以在保证患者隐私的前提下,有效提取症状向量进行传染病预警。在未来的工作中,计划进一步提升该模型的预警效果和性能。
猜你喜欢
传染病信息(2022年3期)2022-07-15
肝博士(2022年3期)2022-06-30
包装工程(2022年1期)2022-01-26
趣味(语文)(2021年9期)2022-01-18
今日农业(2021年8期)2021-07-28
数学小灵通·3-4年级(2020年9期)2020-10-27
作文评点报·低幼版(2020年25期)2020-07-23
今日农业(2019年12期)2019-08-13
中国社区医师(2016年8期)2016-12-20
小说月刊(2014年11期)2014-04-18
