
面向教育大数据的知识追踪研究综述
2022-06-01 12:43魏廷江倪琴高荣郝煜佳白庆春
上海师范大学学报·自然科学版 2022年2期
关键词:个性化学习
魏廷江 倪琴 高荣 郝煜佳 白庆春








摘 要: 介绍了知识追踪(KT)的相关概念与任务,梳理其发展脉络,综述KT的原理、相关算法和数据集,分析了不同结构的KT模型的优缺点.在此基础上,对KT领域未来发展方向进行了深入探讨,提出了数据表征、认知建模、模型可解释性三个重要的发展方向,并作出了一定的展望.
关键词: 知识追踪(KT); 教育数据挖掘; 个性化学习; 学习者建模
中图分类号: TP 18 文献标志码: A 文章编号: 1000-5137(2022)02-0171-09
WEI TingjiangNI QinGAO RongHAO YujiaBAI Qingchun
(1.College of Information, Mechanical and Electrical Engineering, Shanghai Normal University, Shanghai 201418, China;2.Shanghai Engineering Research Center of Open Distance Education, Shanghai Open University, Shanghai 200433, China)
In this paper, firstly common models and datasets in the field of knowledge tracing (KT) were organized and the development and progress of them were collated. Secondly, the correlative theory as well as principles and datasets were overviewed. The advantages and disadvantages of KT models with different structures were analyzed. Moreover, the future development directions of the KT field were discussed, and three important directions of data representation, cognitive modeling, and model interpretability were proposed respectively, and the prospect for the future was predicted.
knowledge tracing (KT); educational data mining; adaptive learning; learner model
0 引言
在線教育使得学生能够随时随地学习不同来源的课程,也为个性化学习、因材施教带来新的机遇和挑战.对于学生而言,面对海量学习资源会遇到选择困难、碎片化学习、学习进度控制难等问题;教师对于学生的学习需求、学习效果难以进行准确评估.数据驱动下的知识追踪(KT)模型通过大数据分析学习过程和学习行为,能够精准识别学习者的个性特征,动态监控学习过程,实时预测学习趋势,有效评价学习结果,给予学习者个性化的干预和自适应的指导.
KT算法将学生的知识掌握程度随着时间的推移建模预测,从而能够准确地预测学生在未来互动中的表现,据此有针对性地为学生订制不同的学习路线,提升学习效率.学生通过在线学习平台进行学习交互,形成答题行为时间序列,KT算法通过对学习者和序列联合建模,预测其对于新知识的认知概率分布,进一步推理出学习者的技能和认知水平.
根据学生答题记录评估学生的知识状态是当前KT建模领域重要的研究内容.其核心思想是根据学生学习轨迹来自动追踪学生的知识水平随着时间变化的过程.早期KT技术主要依赖于概率模型,将知识的掌握程度预测看作“掌握/未掌握”的概率分布推理问题,如隐马尔可夫模型(HMM)、贝叶斯KT(BKT)模型.HMM可以根据学习者历史知识状态预测隐变量的概率分布,并刻画状态之间的转移情况.KT领域采用的深度学习方法最早出现在2015年,PIECH等提出了经典的深度KT模型(DKT),其核心思想是基于学习者练习数据是典型的序列数据的特性,利用循环神经网络(RNN)可以相对有效地捕捉到时间序列前后的关联性.随着相关研究的进展,在KT领域,注意力机制的方法也逐渐被引入神经网络中,并在性能和可解释性方面取得了突破.
本文作者主要综述了采用传统方法和深度学习方法对KT建模方面的研究成果,通过讨论上述模型的优劣,对KT领域的研究作出了展望.具体来说:1) 对KT领域目前主要的问题进行了梳理,全面总结了KT领域当前的研究进展;2) 深入剖析了目前主流KT模型,从问题表征、因素关系表示、认知和遗忘机制方面阐述KT的过程;3) 通过分析和对比主流KT模型,在数据表征、认知遗忘、可解释性方面展望了未来研究方向.
1 KT问题
2 传统KT方法
传统KT方法主要基于概率模型,追踪的过程可以划分为基于BKT模型的方法和基于因素模型的方法.基于BKT模型的方法主要关注于学习者交互序列预测,而因素分析模型更加偏重于解释KT过程中所涉及的各种学习因素.
基于模型的方法
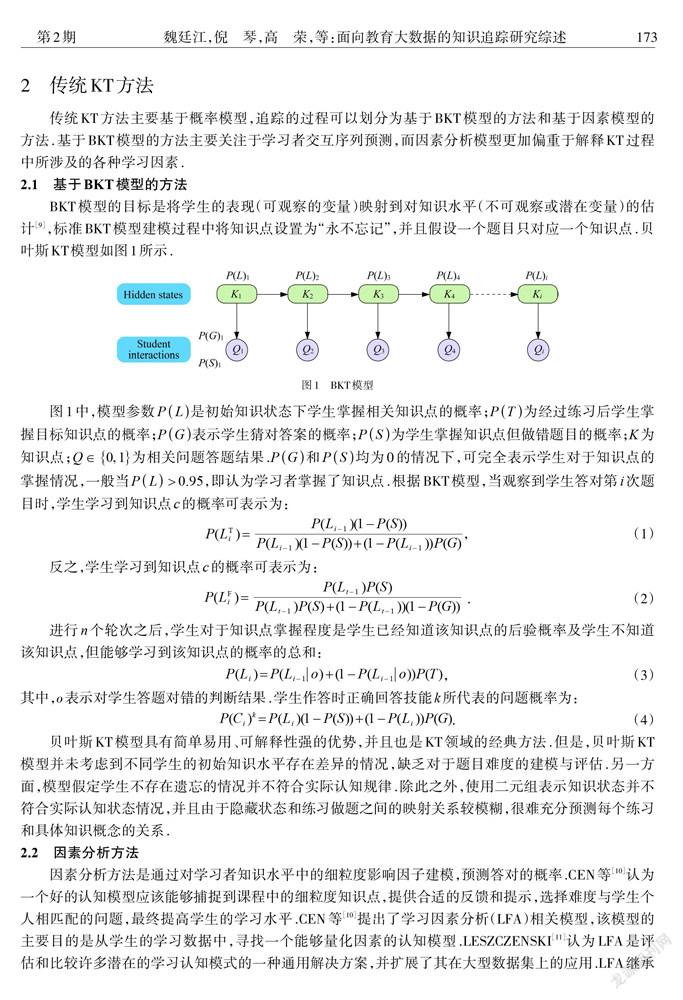
BKT模型的目标是将学生的表现(可观察的变量)映射到对知识水平(不可观察或潜在变量)的估计,标准BKT模型建模过程中将知识点设置为“永不忘记”,并且假设一个题目只对应一个知识点.贝叶斯KT模型如图1所示.
贝叶斯KT模型具有简单易用、可解释性强的优势,并且也是KT领域的经典方法.但是,贝叶斯KT模型并未考虑到不同学生的初始知识水平存在差异的情况,缺乏对于题目难度的建模与评估.另一方面,模型假定学生不存在遗忘的情况并不符合实际认知规律.除此之外,使用二元组表示知识状态并不符合实际认知状态情况,并且由于隐藏状态和练习做题之间的映射关系较模糊,很难充分预测每个练习和具体知识概念的关系.
因素分析方法
因素分析方法是通过对学习者知识水平中的细粒度影响因子建模,预测答对的概率.CEN等认为一个好的认知模型应该能够捕捉到课程中的细粒度知识点,提供合适的反馈和提示,选择难度与学生个人相匹配的问题,最终提高学生的学习水平.CEN等提出了学习因素分析(LFA)相关模型,该模型的主要目的是从学生的学习数据中,寻找一个能够量化因素的认知模型.LESZCZENSKI认为LFA是评估和比较许多潜在的学习认知模式的一种通用解决方案,并扩展了其在大型数据集上的应用.LFA继承和发展了心理测量学中用于评估认知的矩阵,并扩展了学习曲线分析理论.LFA模型通过对认知模型空间进行启发式搜索,使研究者可以评估一套知识点的不同认知表征方式,即同一组知识点会在不同学生身上表现出不同的因素依赖.传统上基于逻辑回归的LFA模型可以表示为:
为了探寻学习者数据中的时间序列特征,CEN等进一步提出了加性因素模型(AFM)模型,AFM模型可以应对KT过程中出现多个知识点的情况,可以连续渐进式地追踪学习者的学习情况,能够设计适合学习者的知识点难度系数和学习速率.PAVLIK等对AFM模型进行进一步的扩展,提出了绩效因素分析(PFA)模型,PFA模型将学习者学习过程中的交互过程分为积极和消极两个方面,AFM模型可被看作是PFA模型的一种特例.
因素分析方法在KT领域表现出了极强的可解释性,能够处理多种学习者特征.但大规模在线教育数据中数据维度太多,特征编码和额外信息来源较为复杂,模型拟合难度也较高,相较于深度模型来说,潜力有限,无法做到真正的大规模、自适应且动态地追踪.
3 KT过程分析
问题表征
3.1.1 知识关系
领域知识模型对应用领域的组成元素及其结构进行描述,表示内部各组成元素及其之间的相互关系,其组成主要包括语义网络、层次结构、领域本體、知识图谱等技术.知识图谱是由Google在2012年为改善搜索引擎而提出的一个新的概念,可以将其简单理解为多关系图.在领域表示学习方面,目前的绝大多数研究都基于关联主义学习理论,把精力聚焦于对通用知识图谱的构建上.
知识点具有天然的图关系属性,近年来利用深度学习处理图结构数据的图神经网络,受到了广泛关注.NAKAGAWA等提出无预先知识图结构的情况下,构建知识图谱并进行KT的方法,并且该方法基于图结构,提高了模型预测的可解释性.TONG等引入了问题模式的概念,构造了一个分层的练习图,可以对学习依赖关系进行建模,并采用两种注意机制突出学习者的重要历史状态.SCHLICHTKRULL等提出了基于关系图卷积神经网络(CNN)的知识图谱构建方法.LI等在R-GCN的基础上,利用学生互动过程,构建了“学生—互动—问题”网络,提出了R2GCN模型,适用于异构情况下的网络学习.YANG等提出了一种端到端的DKT框架,能够利用“高阶问题—技能”关系,缓解数据稀疏性和多知识点问题.
从认知维度出发构建认知图谱,更能理解学习者学习过程,从而在认知层面对学习者进行建模.但是通过分析研究发现,以上大多数研究都集中在对表层学习概念和关系链接的表征上,缺乏关于实体重要性、隐性知识链接、隐性知识与显性知识相互作用对学习能力的影响等方面的研究,并且对于自动构建认知图谱缺乏相关的研究,还无法真正实现对学习者认知状态的识别.
3.1.2 因素关系处理
深度学习技术逐步应用到了KT领域,IRT模型也被重新改造,以适应深度学习方式,通过融入学生能力状态,提升网络性能.典型的实例有Deep-IRT,它是IRT模型与DKVMN模型的结合.HUANG等提出知识熟练度追踪(KPT)模型和练习关联的知识熟练度(EKPT)模型,应用于知识估计、分数预测和诊断结果可视化三个重要任务.VIE等综合IRT,AFM,PFA等模型,提出了知识追踪机(KTMs)框架,KTMs利用所有特征的稀疏权值集,对学习者答题结果的概率进行建模.
IRT模型特别是其衍生出的MIRT模型,存在的较大问题是模型有效训练难度高,所以在实际中并不常用.从IRT到AFM以及PFA模型的演化过程,实质上是在逐步将学习者数据中的各种特征纳入分析的过程,但是以因素分析为基础的特征分析模型对于动态数据建模能力相对较弱,无法跟踪学生的认知状态,对于大规模自适应学习缺乏足够的技术支持.
3.1.3 学习者认知机制和遗忘机制
目前KT领域绝大多数模型都会关注到学习者的认知过程和知识遗忘过程,对这两个维度高效建模是进行有效认知诊断的关键.WANG等提出了一种通用的神经认知诊断框架,摒弃人工特征,将神经网络集成到复杂的非线性交互模型中,解决认知诊断问题,并且结合CNN,提出了Neural CDM+模型,通过自动提取系统中的知识点信息,补充知识点相关度矩阵,避免了主观性甚至错误.
关于记忆研究方面,最为经典的是艾宾浩斯遗忘曲线,心理学家赫尔曼·艾宾浩斯通过一系列的测量实验总结了遗忘规律,近似表示为指数函数,但艾宾浩斯曲线是建立在经验之上的,并且测量的范围相对宽泛.MURRE等通过数学证明了如果学习率的分布遵循伽玛分布、均匀分布或半正态函数,幂函数为指数函数的平均结果,即在大规模的知识点学习过程中,学习过程的整体遗忘性规律可以被认为遵循幂函数分布.
DKT模型使用RNN一定程度上实现了对记忆过程模拟,但是仍然没有真正意义上模拟人类思维习惯.LI等提出的学习与遗忘追踪(LFKT)模型,在RNN的基础上成功模拟了一定程度的思维遗忘机制;DKVMN模型通过类似于计算机内存管理的方式,建立知识记忆遗忘矩阵,在模型可解释性上取得了很大的进步;GHOSH等提出的模型不仅在问题细分方面取得了进步,还在基于Transformer的模型框架上引入了注意力衰减机制,模拟全局遗忘行为,从而取得了较好的模型效果.总的来说,KT问题不能简单地对学习者数据进行拟合,人的认知及遗忘过程是研究学习者知识掌握过程的关键因素.
3.2.1 基于RNN的KT
RNN是一种用来分析时间序列模型的网络,其最大优势在于可以记忆前期输入的相关信息,并利用其对当前问题进行判断和输出.DKT是一种利用RNN的KT方法.虽然BKT方法可以追踪知识掌握程度,并且PFA等模型的性能表现更加优秀,但DKT可自动提取练习标签之间的关系并且追踪学习过程中的时间信息,其性能和实验结果明显优于之前的方法.
基于RNN的模型中,从学生划分方面,MINN等提出了一种新的KT模型——基于动态学生分类的DKT(DKT-DSC),通过在每个时间间隔内将学生分组,预测学生的学习效果;YEUNG等在2017 ASSISTments Data Mining竞赛中采用DKT进行知识状态预测,证明了DKT模型在实际工作中的有效性.在习题方面,SU等通过追踪学生的练习记录和相应练习的文本内容,提出了一个通用的练习增强循环神经网络(EERNN)框架,根据其知识水平预测成绩.整体来讲,基于RNN结构的追踪模型在性能和可用性方面大幅度超越了传统模型,但是在解释性上略显不足.
3.2.2 基于注意力机制的DKT
关于注意力机制的研究一直在进行.PANDEY等认为学习者完成当前练习的过程中,必然伴随着对过去相关练习交互的回忆,通过注意力机制,可以在过去的交互序列中寻找到与当前问题相关的重点信息,从而做出更为准确的预测,并且证明了基于Transformer的模型比基于RNN的模型在运算速度上快了一个数量级.
基于Transformer的KT模型主要难点在于构造合适的Query,Key和Value值,以及選择适合的注意力实现方法.CHOI 等将练习序列和回答序列分别进行编码,从而寻找到了更为合适的Query,Key和Value值.SHIN等将经过时间、滞后时间两个特征编码与学生答题响应的编码进行结合,从而增强了模型的预测精度.
3.2.3 基于Hawkes过程的DKT
大多数关于DKT的研究主要集中在时间特征和全局遗忘衰减上,对于不同知识点的时间交叉效应研究相对较少.MEI等在2017年提出可以利用Hawkes过程对长短期记忆(LSTM)节点的时间效应(遗忘效应)进行衰减处理.KT领域的学习者交互过程可以被看作是一系列的连续事件流,但是泊松过程假定事件相互独立,并不符合多知识点状态下学习者交互的逻辑.Hawkes过程则假设过去事件会在一定程度上提高未来事件发生的概率,并且这种影响会随着时间指数衰减,这种思想比较符合认知遗忘规律下的学习者能力.WANG等在DKT領域引入Hawkes Process的模型,深入研究了不同知识点之间的时间交叉效应,并且提高了深度模型的可解释性,从而使得基于KT模型反馈教学成为可能.HawkesKT的强度便于可视化,可为教育专家提供参考和完善意见.另外,由于模型本身无复杂的网络结构,在训练效率和参数解释方面能体现显著的优势.
DKT技术有效推动大规模在线动态追踪学习者能力的研究进展,并且由于深度模型本身具有高度的拟合能力,使得深度模型在大规模数据集上表现出了比传统模型更好的性能和准确度,大幅度提升了KT模型的可用性.但目前KT领域的研究不仅仅追求模型精确度,对于模型的可解释性、泛化能力也提出了更高的要求.DKT技术虽然对比早期技术有明显的进步,但是缺乏对于学习者记忆能力、学习风格、认知能力等的进一步探索,并且未全面考量学习者认知状态在复杂在线教育环境中对于KT的影响.
3.2.4 主要深度模型对比
从传统基于隐马尔可夫过程的KT到DKT,KT领域的研究经历了巨大的变革,本节将对KT领域有代表性的深度模型进行对比分析.
从模型输入方面来看,基于RNN的DKT模型普遍使用学习者编号![]() 、习题号
、习题号![]() 和知识点
和知识点![]() 编号作为模型的输入.以Transformer结构为基础的模型则偏向于向输入中添加知识点内容、学习者交互序列等内容.大多数基于注意力机制的模型通过寻找学习者与问题交互过程、知识点关系等的内在注意力关联提升模型性能.而基于Hawkes Process的KT模型在输入方面更关注时间序列和交互序列,通过研究时间交叉效应,在记忆模拟方面取得进展.
编号作为模型的输入.以Transformer结构为基础的模型则偏向于向输入中添加知识点内容、学习者交互序列等内容.大多数基于注意力机制的模型通过寻找学习者与问题交互过程、知识点关系等的内在注意力关联提升模型性能.而基于Hawkes Process的KT模型在输入方面更关注时间序列和交互序列,通过研究时间交叉效应,在记忆模拟方面取得进展.
模型输出方面,目前KT模型不仅要求模型输出成绩预测,还对模型可解释性输出提出了更高的要求,DKT模型并未做出突破性进展.DKVMN模型作为对DKT模型的扩展,在可解释性方面做出了突破,可以观察到练习题所需要的技能标签.以Transformer结构为基础的KT模型得益于注意力机制,可以通过可视化注意力表示出结构性的反馈意见,从而为学习者提供有效的帮助.而HawkesKT的核心出发点参数是高度可解释的,通过对模型参数的可视化,还可以在大量技能之间找到关联,适用于在线和传统教育场景.记忆衰减处理方式是KT的核心问题之一.基于LSTM模型的KT模型主要依赖于网络结构,保持和遗忘所提取的输入数据部分特征,拟合学生学习过程,从而做出预测,但是通过门控方式实现的记忆留存并不符合学习者实际记忆过程.DKVMN以记忆增强网络为基础,通过结构化模型模拟逻辑流控制,以类似计算机内存管理技术的方式实现记忆留存,但是这种模式过于机械化,并且对于不同学习者的学习速率无法进行很好的量化.基于注意力机制的模型逐步关注记忆力衰减机制在KT任务中的作用,但是绝大多数模型的工作都集中在整体记忆衰减方面,缺乏对知识点尺度甚至问题尺度上记忆过程的探索.HawkesKT方法在知识点尺度上的交叉效应方面取得了突破,但是其对记忆衰减的模拟上依然以指数分布曲线为主.
4 分析与展望
本文作者对比讨论了目前主流的KT模型,分析了主流模型的优缺点.目前的研究主要针对知识点与题目间的关系进行建模,很少有研究从模型效果评价指标、学习潜力预测、深度记忆过程模拟等方面进行知识状态追踪和预测,同时也较少有对多知识点关系建模方法进行知识状态追踪的研究.通过分析KT领域目前主流的模型,梳理出KT领域未来的发展方向,从数据表征、认知建模、建模方法、解释及反馈方面对KT领域进行展望.
1) 数据处理及数据表征.KT模型在运用输入数据方面越来越需要预处理、预训练操作.预训练模型在序列任务上表现出了良好的性能,采用可解释性较强的算法预处理输入数据变得越来越重要.比如使用Rasch编码预处理输入数据后,再进行注意力运算和模型预测,在模型性能和可解释性方面都取得了很好的效果.在数据特征方面,引入学习者生物特征、更加丰富的习题特征都是未来重要的突破方向,KT模型应该向更高维度、更普适、更泛化的方向发展,如何对学习者的非结构性学习数据进行追踪也是重要的发展方向.
2) 认知建模.认知诊断和KT分别应用于学习者静态数据分析和动态数据分析,但KT模型内不应缺乏对学习者认知能力的建模.对于问题维度、知识点维度的建模不足以拟合学习者的知识状态变化,应在此基础上进一步对认知维度进行建模,从而在更高的维度上追踪学习者的状态变化情况.
3) 模型方法及可解释性.自从DKT被提出以来,KT领域内的模型基本以深度模型为主,但越来越多的工作表明DKT无法做到真正的动态自适应KT.基于RNN的模型在数据拟合能力上逐步被以注意力机制为核心的Transformer类模型超越,未来KT领域建模方法应该在注意力方向、图谱方向进一步发展.人脑记忆的形成过程中,人自身的注意力是重要的一环,这也是基于注意力机制模型结合遗忘建模取得不错效果的关键原因.知识图谱作为非结构化知识表征的重要手段,在KT领域有更进一步的潜力,并且对于认知能力研究也可以加入图谱技术,从而在可解释性KT方向取得突破.
5 总结
自新冠疫情爆发以来,在线教育行业需求愈发旺盛,对海量教育数据的学习者数据分析变得愈发重要,从数据中追踪学习者认知能力、知识水平、学习状态、心理变化等是自适应式、动态反馈式学习环境构建的基础性任务.
KT技术通过分析海量学习者的学习数据,能为学习者开发个性化学习方式,提供准确学习行为评估.本文作者梳理了KT领域的经典模型,分别从传统KT理论到DKT模型两个大方面进行剖析,并以数据处理、学习者内在因素、模型可解释性及可反馈性方面进行详细梳理和分析,对KT未来方向进行了探究.
参考文献:
[1] HUO Y, WONG D F, NI L M, et al. Knowledge modeling via contextualized representations for LSTM⁃based personalized exercise recommendation [J]. Information Sciences,2020,523:266-278.
[2] JIANG Q, ZHAO W, LI S, et al. Research on the mining of precise personalized learning path in age of big data: analysis of group learning behaviors based on AprioriAll [J]. e⁃Education Research,2018,39(2):45-52.
[3] PIECH C, SPENCER J, HUANG J, et al. Deep knowledge tracing [J]. Computer Science,2015,3(3):19-23.
[4] YE Y W, LI F M, LIU Q Q, et al. Incorporating the variables of forgetting and data volume into knowledge tracing model: how does it impact prediction accuracy? [J]. Distance Education in China,2019(8):20-26.
[5] ZHAO J, BHATT S, THILLE C, et al. Interpretable personalized knowledge tracing and next learning activity recommendation [C/OL]// Proceedings of the Seventh ACM Conference on Learning@Scale. New York: Association for Computing Machinery,2020:325-328[2022-01-15]. https://doi.org/10.1145/3386527.3406739.
[6] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates,2017:6000-6010.
[7] KONG W L, HANG S Y, ZHAO S L. Construction of adaptive learning path supported by artificial intelligence [J]. Modern Distance Education Research,2020,32(3):94-103
[8] CHOI Y, LEE Y, SHIN D, et al. Ednet: a large?scale hierarchical dataset in education [J/OL]. [2022-01-08]. http://arxiv.org/abs/1912.03072.
[9] MANRIQUE R F, CAMILO E L G, LEON E. Student modeling via Bayesian knowledge tracing: a case study [C]//Computing Congress (CCC), 2014 9th Colombian. [S.l.:s.n.],2014:1-6.
[10] CEN H, KOEDINGER K, JUNKER B. Learning factors analysis⁃a general method for cognitive model evaluation and improvement [C]// International Conference on Intelligent Tutoring Systems. Taiwan: Springer,2006:164-175.
[11] LESZCZENSKI J M. Learning factors analysis learns to read [D]. Pittsburgh: Carnegie Mellon University,2007.
[12] PAVLIK P I, CEN H, KOEDINGER K. Performance factors analysis: a new alternative to knowledge tracing [C]//Proceedings of the 2009 conference on Artificial Intelligence in Education. Amsterdam: ACM,2009:531-538.
[13] MA X C, ZHONG S C, XU D. Research on support model and implementation mechanism of personalized adaptive learning system from the perspective of big data [J]. China Educational Technology,2017(363):97-102.
[14] GORI M, MONFARDINI G, SCARSELLI F. A new model for learning in graph domains [C]// 2005 IEEE International Joint Conference on Neural Networks. Montreal: IEEE,2005:729-734.
[15] NAKAGAWA H, IWASAWA Y, MATSUO Y. Graph?based knowledge tracing: modeling student proficiency using graph neural network [C]// IEEE/WIC/ACM International Conference on Web Intelligence. Thessaloniki: IEEE,2019: 156-163.
[16] TONG H, WANG Z, LIU Q, et al. HGKT: introducing hierarchical exercise graph for knowledge tracing [J/OL]. [2022-01-10].https:∥arxiv.org/abs/2006.16915.
[17] SCHLICHTKRULL M, KIPF T N, BLOEM P, et al. Modeling relational data with graph convolutional networks [C]//GANGEMI A, NAVIGLI R, VIDAL M E, et al. The Semantic Web. Cham: Springer International Publishing,2018: 593-607.
[18] LI H, WEI H, WANG Y, et al. Peer⁃inspired student performance prediction in interactive online question pools with graph neural network [C/OL]// CIKM’20: Proceedings of the 29th ACM International Conference on Information & Knowledge Management. New York: Association for Computing Machinery,2020:2589-2596[2022-01-15]. https://doi.org/10.1145/3340531.3412733.
[19] YANG Y, SHEN J, QU Y, et al. Gikt: a graph⁃based interaction model for knowledge tracing [C]// HUTTER F, KERSTING K, LIJFFIJT J, et al. Machine learning and knowledge discovery in databases. Cham: Springer International Publishing,2021:299-315.
[20] GHOSH A, HEFFERNAN N, LAN A S. Context-aware attentive knowledge tracing [C/OL]// Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: Association for Computing Machinery,2020:2330-2339[2022-01-15]. https://doi.org/10.1145/3394486.3403282.
[21] HARVEY R J, HAMMER A L. Item response theory [J]. Counseling Psychologist,1999,27(3):353-383.
[22] HOLSTER T A, LAKE J. Guessing and the Rasch model [J/OL]. Language Assessment Quarterly,2016,13(2):124-141[2022-01-15].https://doi.org/10.1080/15434303.2016.1160096.
[23] YEUNG C K. Deep⁃IRT: make deep learning based knowledge tracing explainable using item response theory [J/OL]. [2022-01-15]. https:∥arxiv.org/abs/190411738.
[24] ZHANG J, SHI X, KING I, et al. Dynamic key?value memory networks for knowledge tracing [C]// International Conference on World Wide Web. Geneva: Association for Computing Machinery,2017:765-774.
[25] HUANG Z, LIU Q, CHEN Y, et al. Learning or forgetting?A dynamic approach for tracking the knowledge proficiency of students [J]. ACM Transactions on Information Systems (TOIS),2020,38(2):1-33.
[26] VIE J J, KASHIMA H. Knowledge tracing machines: factorization machines for knowledge tracing [J/OL]. Proceedings of the AAAI Conference on Artificial Intelligence,2019,33(1):750-757[2022-01-15]. https://ojs.aaai.org/index.php/AAAI/article/view/3853.DOI:10.1609/aaai.v33i01.3301750.
[27] WANG F, LIU Q, CHEN E, et al. Neural cognitive diagnosis for intelligent education systems [J/OL]. Proceedings of the AAAI Conference on Artificial Intelligence,2020,34(4):6153-6161[2022-01-15]. https://ojs.aaai.org/index.php/AAAI/article/view/6080.DOI:10.1609/aaai.v34i04.6080.
[28] MURRE J, CHESSA A G. Power laws from individual differences in learning and forgetting: mathematical analyses [J]. Psy⁃chonomic Bulletin and Review,2011,18(3):592-597.
[29] LINDSEY R V, SHROYER J D, PASHLER H, et al. Improving students’ long⁃term knowledge retention through personalized review [J/OL]. Psychological Science,2014,25(3):639-647[2022-01-15]. https://doi.org/10.1177/0956797613504302.
[30] LI Z, ZHOU D D, WANG Y. Research of educational knowledge graph from the perspective of “Artificial Intelligence+”: connotation, technical framework and application [J]. Journal of Distance Education,2019,37(4): 42-53.
[31] MINN S, YU Y, DESMARAIS M C, et al. Deep knowledge tracing and dynamic student classification for knowledge tracing [C/OL]// 2018 IEEE International Conference on Data Mining (ICDM). 2018:1182-1187.DOI:10.1109/ICDM.2018.00156.
[32] YEUNG C, LIN Z Z, YANG K, et al. Incorporating features learned by an enhanced deep knowledge tracing model for stem/non-stem job prediction [J]. International Journal of Artificial Intelligence in Education,2019,29(3):317-341.
[33] SU Y, LIU Q, LIU Q, et al. Exercise⁃enhanced sequential modeling for student performance prediction [J/OL]. Proceedings of the AAAI Conference on Artificial Intelligence,2018,32(1):2435-2443[2022-01-15]. https://ojs.aaai.org/index.php/AAAI/article/view/11864.
[34] PANDEY S, KARYPIS G. A self⁃attentive model for knowledge tracing [C]// International Conference on Education Data Mining. Montreal: Word Press,2019:1-6.
[35] CHOI Y, LEE Y, CHO J, et al. Towards an appropriate query, key, and value computation for knowledge tracing [C]//Proceedings of the Seventh ACM Conference on Learning@Scale. New York: Association for Computing Machinery, 2020:341-344.
[36] SHIN D, SHIM Y, YU H, et al. Saint+: integrating temporal features for EdNet correctness prediction [C/OL]// 11th International Learning Analytics and Knowledge Conference. New York: Association for Computing Machinery,2021:490-496[2022-01-15]. https://doi.org/10.1145/3448139.3448188.
[37] MEI H, EISNER J. The neural Hawkes process: a neurally self?modulating multivariate point process [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates,2017:6757-6767.
[38] WANG C, MA W, ZHANG M, et al. Temporal cross⁃effects in knowledge tracing [C/OL]// Proceedings of the 14th ACM International Conference on Web Search and Data Mining. New York: Association for Computing Machinery, 2021:517-525[2022-01-15]. https://doi.org/10.1145/3437963.3441802.
(责任编辑:包震宇,郁慧)
猜你喜欢
考试周刊(2017年1期)2017-01-20
内蒙古教育·职教版(2016年11期)2017-01-05
课程教育研究·中(2016年11期)2017-01-04
电脑知识与技术(2016年28期)2016-12-21
教育教学论坛(2016年46期)2016-12-19
中国信息技术教育(2016年21期)2016-12-05
电脑知识与技术(2016年24期)2016-11-14
科教导刊·电子版(2016年21期)2016-08-23
科技视界(2016年6期)2016-07-12
考试周刊(2016年52期)2016-07-09
