
基于大数据技术的非洲猪瘟传染病预测研究
2022-06-01 12:43:35高祥兰周楠蔡翔穆尚海
上海师范大学学报·自然科学版 2022年2期
高祥兰 周楠 蔡翔 穆尚海




摘 要: 对我国发生非洲猪瘟期间(2018年5月—2019年9月)的百度指数与该种疾病爆发的关联性进行研究,采用以省份为区域分组的二元Logistic回归模型,通过对17个地区数据的拟合,分别提前3周、提前2周、提前1周及当周预测了非洲猪瘟早期爆发的区域.研究结果表明:预测的准确率均高于91.2%,可作为对传统监测系统的有力补充.
关键词: 大数据; 百度指数; 预测; 非洲猪瘟
中图分类号: TP 274 文献标志码: A 文章编号: 1000-5137(2022)02-0232-05
GAO XianglanZHOU NanCAI XiangMU Shanghai
(1.School of Information, Shanghai Lida University, Shanghai 201609, China;2.School of Management, Shinawatra University, Pathum Thani 12160, Thailand;3.School of Business, Guilin University of Electronic Technology, Guilin 541004, Guangxi, China)
The relevance between Baidu Index during African Swine Fever occurred from May 2018 to September 2019 in China and the breakout of the disease was studied in this paper. By means of fitting the data of 17 districts, the area where African Swine Fever would outbreak was successfully predicted by the binary Logistic regression model 3, 2, 1 weeks in advance and in that week respectively. The results showed that the accuracy of the prediction was over 91.2% without exception, which could be a valuable supplement to the traditional monitoring system.
big data; Baidu index; prediction; African Swine Fever
0 引 言
2018年以來,世界多地陆续出现非洲猪瘟爆发的情况,非洲、欧洲和亚洲已有23个国家和地区受到非洲猪瘟的影响,截至2019年4月19日,我国31个省、直辖市及自治区都被波及.根据《2018年中国统计年鉴》数据,我国年人均猪肉消费达20.1 kg,非洲猪瘟的传播大量减少了市场上生猪的供给,直接推高了猪肉价格.
基于网络大数据的传染病监测预警研究最早出现在2009年,GINSBERG等利用谷歌搜索引擎搜索关键词成功预测了流感爆发,开启了网络搜索大数据在传染病预测中的研究热潮.同一时期及随后,HULTH等采用网络搜索关键词对流感的预测和监测进行研究,提出搜索关键词对流感预测具有明显的指向性.SANTILLANA等对组合网络搜索关键词和传统监测数据进行研究,提出网络大数据结合传统监测数据的预测方法,显著改善了传统监测数据的预测水平.其他与流感相关的大数据也被用于对流感预测的研究,例如非处方药销售数据、学生出勤数据及微博等社交平台数据等,且都具有一定的有效性.然而,以上研究大多误差率较高,且绝大多数只是针对流感、登革热、禽流感及埃博拉病毒,几乎没有动物传染病,例如非洲猪瘟的监测预警研究记录,存在明显的研究缺口.
本研究以27个搜索关键词组成的百度搜索指数为自变量,以非洲猪瘟发生可能性为二元因变量,采用二元Logistic回归模型进行预测拟合,以期能尽早预测非洲猪瘟的爆发.
1 数据来源和研究方法
通过中国农业部官网非洲猪瘟专题(http://www.moa.gov.cn/ztzl/fzzwfk/yqxx/index.htm),获取我国非洲猪瘟报告发生统计数据,包括省份、县市、发生日期、存栏数量、发病数量、死亡数量,以周为单位判断非洲猪瘟是否发生,作为模型的因变量.获取2018年5月7日—2019年9月15日(71周)期间27个搜索词的每日百度指数、全国每日资讯指数及全国每日媒体指数作为生成自变量的原始数据,数据来源网址为http://index.baidu.com/v2/main/index.html#/trend/.自变量定义如表1所示.
采用二元Logistic模型,计算跨越整个研究周期内按周统计的非洲猪瘟发生率与百度关键词搜索指数.非洲猪瘟发生率使用超前1阶、超前2阶、超前3阶得到了3个变化量.“超前”定义为将非洲猪瘟发生率移动到百度关键词搜索指数之前,“滞后”的意义相反.假设超前周预测第周发生非洲猪瘟的可能性为:
2 基于百度关键词搜索指数的预测方法
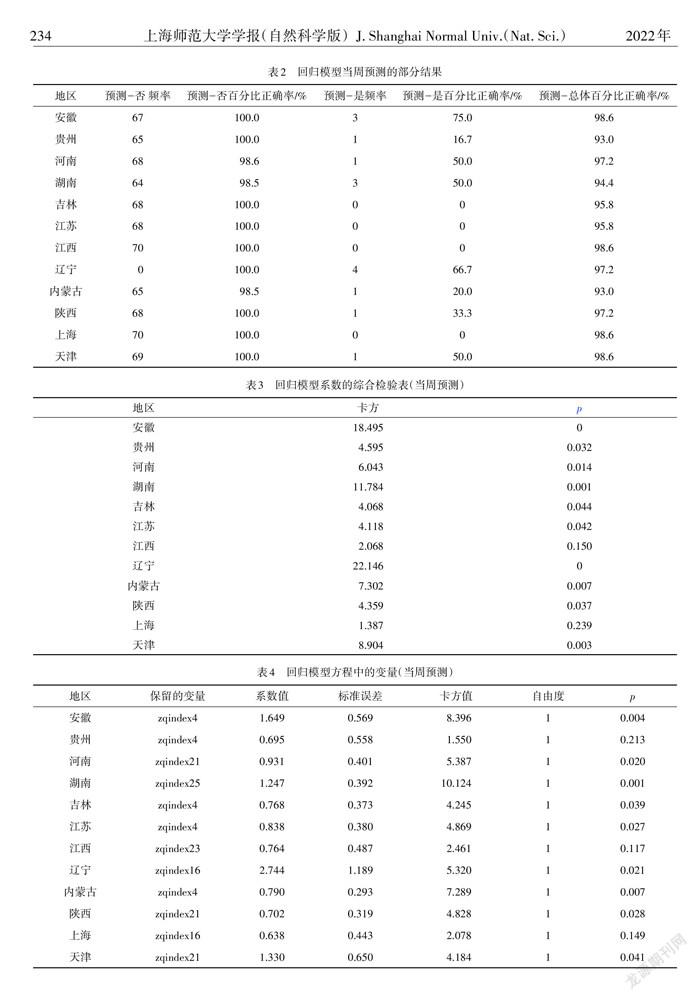
当周预测结果的回归分析
将z⁃score标准化值作为影响因子,当周非洲猪瘟发生率作为因变量,输入71周数据,建立回归模型,部分结果如表2~4所示.
表3为回归模型的似然比检验结果,<0.05表示检验结果不显著,将拟合的结果纳入模型变量中.由表3可见,回归模型在江西(=0.150)、上海(=0.239)不具有显著性,在其余地区具有显著性(<0.05).
表4表明自变量zqindex4对于安徽(=0.004)、吉林(=0.039)、江苏(=0.027)、内蒙古(=0.007)的预测具有显著性,对于河南(=0.298)、贵州(=0.213)的预测不具有显著性.表4中的其余变量的预测结果显著性存在差异,但有助于模型构建和提高预测结果,故将其保留.
提前周预测回归分析
将超前1周的因变量导入模型,结果表明:对于安徽、河南、湖南、吉林、江苏、辽宁、山西、陕西、天津、浙江的预测结果具有显著性,预测准确率分别为95.7%,98.6%,92.9%,94.3%,97.1%,91.4%,95.7%,97.1%,98.6%,98.6%;对于内蒙古(=0.087)和四川(=0.059)的预测不具备显著性,预测准确率均为92.9%.预测准确率最高的河南、天津和浙江(均为98.6%),70个样本中,共69个结果预测准确(68个成功预测未发生,1个成功预测发生),有1个结果预测错误(实际数据为发生,预测值为没有发生).预测准确率最低的是辽宁,70个样本中,共获得64个准确预测(62个成功预测没有发生,2个成功预测发生),预测中漏报发生4个,误报没有发生为发生2个.
提前1周预测回归分析中,自变量zqindex4,zqindex14,zqindex21,zqindex19,zqindex22保留在回归方程变量表中.
提前周预测回归分析
将超前2周的因变量导入模型,预测结果表明安徽、河南、湖南、吉林、江苏、辽宁、山西、四川、浙江具有显著性,预测准确率分别为98.6%,98.6%,94.2%,97.1%,98.6%,92.8%,95.7%,92.8%,100%.福建(=0.081)与青海(=0.53)的预测结果不具备显著性,预测准确率均为97.1%.预测准确率最高的是浙江省(100%),69个样本均被准确预测(67个成功预测没有发生,2个成功预测发生).预测准确率最低的是辽宁和四川,其中四川的69个样本中,共获得64个准确预测(63个成功预测没有发生,1个成功预测发生),预测结果中漏报5个发生.
提前2周预测回归分析中,自变量zqindex4,zqindex25,zqindex22,zqindex23,zqindex21,zqindex17,zqindex11保留在回归方程变量表中.
提前周预测回归分析
将超前3周的因变量导入模型,预测结果表明安徽、广东、贵州、河南、湖南、江苏、江西、辽宁、上海、四川、浙江具有显著性,预测准确率分别为95.6%,97.1%,92.6%,98.5%,92.6%,97.1%,100%,91.2%,98.5%,95.6%,98.5%.青海(=0.129)和重庆(=0.067)的预测结果不具有显著性.其中预测准确率最高的是江西,69个样本均被准确预测(68个成功预测没有发生,1个成功预测发生).预测准确率最低的是辽宁(91.2%),69个样本中,共获得62个准确预测(61个成功预测没有发生,1个成功预测发生),预测中漏报5个发生,误报1个.
提前3周预测回归分析中,自变量zqindex4,zqindex25,zqindex22,zqindex23,zqindex21,zqindex17,zqindex11保留在回归方程变量表中.
3 结论
本研究基于关键词的百度搜索指数网络大数据对非洲猪瘟的发生进行预测,对搜索指数进行预处理后,输入二元回归模型,实现了17个地区的有效预测,最低預测成功率为91.2%,其中对于非洲猪瘟没有发生的情况预测准确率达到98.0%以上,对于非洲猪瘟首次爆发的预测较为准确,对继发的预测存在不足.27个初选关键词中,9个关键词被保留在最终模型中,其中7个关键词在超前1~3周预测中具有普遍的指向性;另有2个关键词在当周预测中作用明显.研究结果证实了基于百度关键词的搜索指数可用作非洲猪瘟发生可能性的预测.
参考文献:
[1] GINSBERG J, MOHEBBI M H, PATEL R S, et al. Detecting influenza epidemics using search engine query data [J]. Nature,2009,457:1012-1014.
[2] HULTH A, RYDEVIK G, LINDE A. Web queries as a source for syndromic surveillance[J]. PLOS One,2009,4(2):e4378.
[3] SANTILLANA M, NGUYENA T, DREDZE M, et al.Combining search, social media, and traditional data sources to improve influenza surveillance [J]. PLOS Computation Biology,2015,11(10):e1004513.
[4] 谢立, 杨旭辉, 王婧, 等. 基于非处方药销售的流感样病例残差预警研究 [J]. 中国预防医学杂志,2014,15(8): 724-728.
[5] 李印东, 王全意, 李玉堂, 等. 学校因病缺课监测预警阈值的研究 [J]. 首都公共卫生,2008,2(3):112-115.
[6] JOHNSON H A, WAGNER M M, HOGAN W R, et al. Analysis of Web access logs for surveillance of influenza [J]. Study Health Technology Information,2004,107:1202-1206.
[7] ZOU Y Q, PENG Y S, LI Z, et al. Monitoring infectious diseases in the big data era [J]. Science Bulletin,2015,60(1): 144-145.
(責任编辑:包震宇,郁慧)
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
齐鲁周刊(2018年33期)2018-11-10 02:05:08
百科知识(2018年20期)2018-10-18 18:37:22
中国动物保健(2017年8期)2018-01-30 00:34:35
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
湖北畜牧兽医(2016年10期)2017-03-20 14:50:30
科技视界(2016年20期)2016-09-29 10:53:22
