
基于改进U-Net的零件缺陷分割标注
2022-06-01 16:31:48金文倩朱媛媛王笑梅
上海师范大学学报·自然科学版 2022年2期
金文倩 朱媛媛 王笑梅


摘 要: 提出一种以U-Net为基础,依据零件缺陷的特点对网络进行一系列改进的模型,以提升网络对零件缺陷的分割精度.首先在U-Net结构中的编码阶段,使用改进的残差网络Res2Net提高该阶段的特征提取能力;然后在网络编码器与解码器的中间部位增加空洞卷积,在不改变特征图尺寸的情况下增加感受野,降低误检率与漏检率;最后在U-Net的输出阶段与Mini U-Net进行结合,对原本的输出结果进行二次补丁,提高对微小缺陷的检测精度.实验结果表明,对MVTec数据集进行分割的F1-Score分数达到87.21%,时间为0.017 s,达到了良好的检测效果.
关键词: 图像分割; 缺陷检测; U-Net; Res2Net; 空洞卷积
中图分类号: TP 391 文献标志码: A 文章编号: 1000-5137(2022)02-0129-06
Part defect segmentation and annotation based on improved U-Net
JIN Wenqian, ZHU Yuanyuan*, WANG Xiaomei
(College of Information, Mechanical and Electrical Engineering, Shanghai Normal University, Shanghai 201418, China)
Abstract:A model based on U-Net network and a series of improvements to it according to the characteristics of part defects were proposed to improve the segmentation accuracy of part defects. Firstly, the improved residual network Res2Net was used in the coding stage of U-Net network structure to improve the feature extraction ability during this stage. Secondly, the hole convolution was added in the middle of the network encoder and decoder, and the receptive field was increased without changing the size of the characteristic image, so as to reduce the false detection rate and omission detection rate. Finally, in the output stage of U-Net, Mini U-Net was combined with to patch the original output results, so as to improve the detection accuracy of small defects. The experimental results showed that the F1-Score of MVtec dataset segmentation reached 87.21% and the time was 0.017 s, with which outstanding detection effect could be achieved.
Key words:image segmentation; defect detection; U-Net; Res2Net; void convolution
0 引言
将深度学习和缺陷检测问题相结合是当下十分热门的研究领域.CHEN等[1]结合single shot multibox detector(SSD)网络及you only look once(YOLO)算法构建了一个由粗到细的级联检测网络,对高铁线路紧固件进行缺陷检测;CHA等[2]通过faster region convolutional neural networks(FasterRCNN)检测混凝土裂缝,中、高两级钢腐蚀,螺栓腐蚀和钢筋分层5种损伤类型;YU等[3]提出一种基于YOLOv4的空心杯电枢表面空洞缺陷检测的方法,解决空心杯电枢表面微小缺陷检测过程中检测精度低、速度慢以及不能实时检测等问题.上述检测算法对于缺陷仅能进行笼统的方框标注,无法精确到图像的具体像素.本文作者将图像分割应用到目标缺陷检测领域,将图像中的像素分割出来,对应到不同类别中.首先在U-Net结构的[4]编码阶段使用改进的残差网络Res2Net[5]提高特征提取能力,使用更细粒度进行特征提取.在网络编码器与解码器的中间部位增加空洞卷积[6],通过改变扩张率来扩大感受野,在不改变特征图尺寸的情况下获取不同尺度的特征信息,可以避免下采样所造成的细节信息丢失等问题,降低误检率与漏检率.最后在U-Net的輸出阶段,将之与Mini U-Net[7]进行结合,对原本的输出结果进行二次补丁,提高对微小缺陷的检测精度.98883410-D20E-490F-9F06-C3584C2EAFBE
1 改進的U-Net模型
1.1模型结构
对U-Net模型编码器-解码器的基本结构进行改进(图1).
在模型的编码器阶段,将原先的普通卷积结构替换为Res2Net模型[8],使用更细的粒度获取多尺度特征,扩大图像感受野,增加图像分割的精度.
编码器与解码器之间连接空洞卷积结构,进一步扩大感受野,获得不同尺度的特征图像.如图1所示,先串联空洞率分别为1,2,4的3个空洞卷积,每层的感受野分别为3,7,15[9].U-Net的编码器部分有4个下采样层,在最后一个特征图上融合了第一个特征图上的特征信息,并以此覆盖第一个特征图上的特征信息.
Mini U-Net是由U-Net的中间部分组成的.最后将U-Net的输出部分连接一个Mini U-Net对U-Net的输出结果作二次补丁,避免零件因存在微小缺陷而导致的模糊和细节丢失等情况.
1.2Res2Net
Res2Net结构图如图2所示.
由此可以得到不同数量以及不同感受野大小的输出,再经过一个1×1的卷积,将输出进行融合.这种先拆分再融合的策略能够提高特征处理的效率.
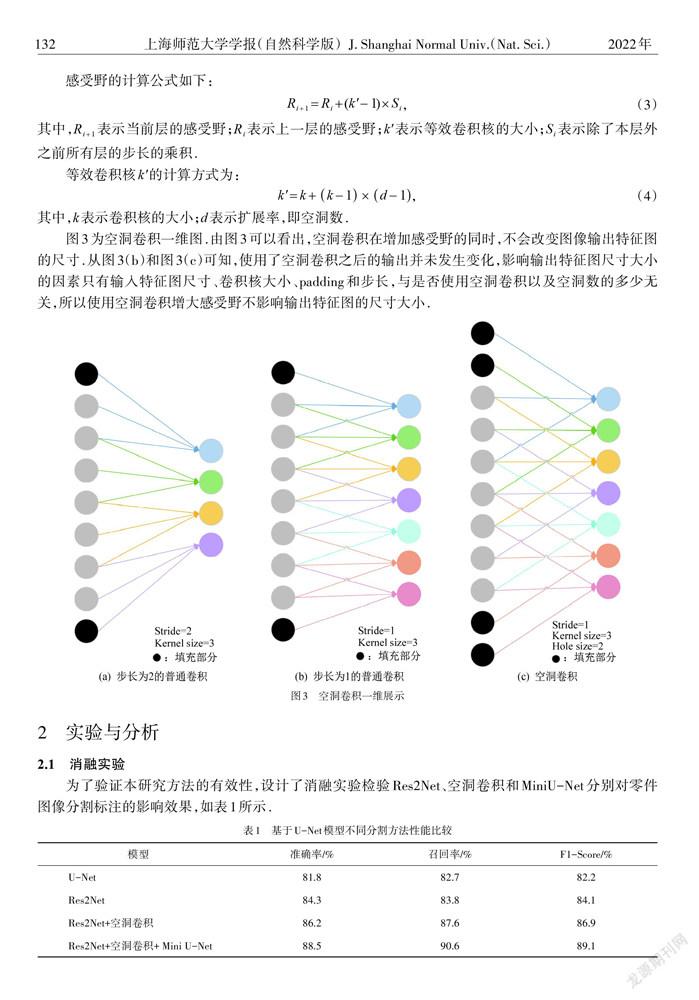
1.3空洞卷积
增加网络特征点的感受野就意味着要增加接触到的图像范围,这样能获得更多语义层次及更好的特征,感受野越大,包含的特征更加趋于全局;反之,包含的特征会趋于局部.由Visual Geometry Group(VGG)网络可知,1个7×7卷积层的正则化等效于3个3×3卷积层的叠加,通过多个小的卷积层的叠加不仅可以大幅度地减少运算参数,还能具备同样的正则化效果,减少了过拟合的可能性,更好地缓解了U-Net在缩小放大过程所产生的特征图细节丢失和精度下降的问题.
2 实验与分析
2.1消融实验
为了验证本研究方法的有效性,设计了消融实验检验Res2Net、空洞卷积和MiniU-Net分别对零件图像分割标注的影响效果,如表1所示.
由表1可知:原始的U-Net模型在零件数据集上进行分割标注实验的分割效果尚佳,但准确率较低;将原先的卷积结构改进为Res2Net之后,各项性能都有了一定程度的提升,但是召回率的提升幅度较小;在此基础上继续增加空洞卷积提高感受野,模型的性能得到进一步的提高;再加入MiniU-Net进行第二次补丁训练,3个指标都有明显的提升.从原始U-Net模型到最终的模型,每增加一个改进模块,模型的性能都有不同程度的提升,体现了模型改进的有效性.
2.2基于MVTec螺丝数据集异常区域分割
图4为使用改进的U-Net模型对MVTec螺丝数据集[10]进行异常区域分割的结果.数据集共有mainpulated_front螺丝前端、scratch_head顶部划痕、scratch_neck颈部划痕、thread_side螺纹侧面4个部位的缺陷.图4展示了数据集中的ground_truth标签图,可以看出改进的U-Net模型可以将数据集中的异常区域分割出来,准确率较高,对于thread_side螺纹侧面缺陷存在一定的漏检现象.
表2为对螺丝数据集的检测结果.从表2中可以看出,本研究的模型对于各缺陷检测的平均精度均值(mAP)均在80%以上,有良好的分割效果.其中,对于scratch_head顶部划痕的分割效果最好,达到91.19%,对于thread_side螺纹侧面的分割效果最差.
3 结论
通过在U-Net的编码器阶段添加改进的ResNet结构,增加检测粒度;在编码器与解码器中间部位连接空洞卷积,在不改变特征图尺寸大小的情况下,增加模型感受野;在U-Net解码器的输出部分连接MiniU-Net,对网络进行二次补丁,提高微小缺陷的检测精度.实验结果表明,改进后的U-Net具有良好的检测效果,检测速度较快,检测精度较高.
参考文献:
[1] CHEN J W, LIU Z G, WANG H R, et al. Automatic defect detection of fasteners on the catenary support device using deep convolutional neural network [J]. IEEE Transactions on Instrumentation and Measurement,2018,67(2):257-269.
[2] CHA Y, CHOI W, SUH G, et al. Autonomous structural visual inspection using region:based deep learning for detecting multiple damage types [J]. Computer‐Aided Civil and Infrastructure Engineering,2018,33(9):731-747.
[3] YU C H, HUANG H S, ZENG F, et al. Real-time detection of surface defects of hollow cup armature base on YOLO_v4 [J]. Modular Machine Tool & Manufacturing Technique,2021(6):59-62,66.98883410-D20E-490F-9F06-C3584C2EAFBE
[4] RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation [C]// International Conference on Medical Image Computing and Computer-Assisted Intervention. Strasbourg: Springer,2015:234-241.
[5] GAO S H,CHENG M M,ZHAO K, et al. Res2Net: a new multi?scale backbone architecture[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2019, 43(2):652-662.
[6] YU F, KOLTUN V. Multi?scale context aggregation by dilated convolutions [C]// International Conference on Learning Representations. ICLR: San Juan,2016:arXiv:1511.07122.
[7] CAI Q H, LIU Y H, ZHANG R F.Two-stage retinal vessel segmentation based on improved U-Net [J]. Laser & Optoelectronics Progress,2021,58(16):480-490.
[8] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE,2016:770-778.
[9] QU Z, CHEN W.Concrete pavement crack detection based on dilated convolution and multi-features fusion [J/OL].Computer Science[2021-12-23]. http:// kns.cnki.net/kcms/detail/50.1075.TP.20211011.1608.004.html.
[10] BERGMANN P, BATZNER K, FAUSER M, et al. The MVTec anomaly detection dataset: a comprehensive real?world dataset for unsupervised anomaly detection [J]. International Journal of Computer Vision,2021,129(1):1038-1059.
(责任编辑:包震宇,顾浩然)98883410-D20E-490F-9F06-C3584C2EAFBE
猜你喜欢
中国高新技术企业(2016年34期)2017-02-10 16:40:20
计算技术与自动化(2016年4期)2017-01-11 14:19:49
科技视界(2016年26期)2016-12-17 16:25:03
农业与技术(2016年20期)2016-12-08 19:30:58
电脑知识与技术(2016年24期)2016-11-14 02:04:38
电脑知识与技术(2016年24期)2016-11-14 01:48:33
科技视界(2016年3期)2016-02-26 11:42:37
