
基于改进的卷积神经网络邮件分类算法研究
2022-05-18 01:38戴旭凡
重庆工商大学学报(自然科学版) 2022年3期
宋 丹, 陆 奎,戴旭凡
(1.安徽理工大学 计算机科学与工程学院, 安徽 淮南 232001;2.安徽理工大学 电气与信息工程学院, 安徽 淮南 232001)
0 引 言
随着网络媒体的发展和电子邮件的普及,社交媒体中的广告越来越多地充斥在生活中,给人们带来了很多困扰。垃圾邮件不仅占据空间内存,还侵犯收件人隐私,所以邮件的快速分类就成了现在的热门课题。邮件分类的研究是自然语言处理的一个分支方向,对此,国内外已有很多学者进行了深入研究,主要有传统的机器学习方法,如朴素贝叶斯、k近邻算法、支持向量机等,深度学习方法,如卷积神经网络、循环神经网络等。
文献[1]在基于词典的基础上,增加了5部词典,结合分析文本之间的语义规则,实现文本情感分析;文献[2]在Skip-Gram模型中将词向量映射到一个低维度,结合CNN提取特征,再加一层Highway网络对整体特征优化,提高了模型准确率;文献[3]提出基于KNN的方法和一般基于图的分类方法来区分中国评论网站中的串通垃圾邮件发送者,两种方法的分类效果明显优于纯指标分类器;文献[4]用CNN进行了一系列分类任务的实验,对该体系结构简单修改,同时使用特定于任务的向量和静态向量,在多个基准上都取得了很好的结果,证明了一个简单的CNN与很少的超参数调整和静态向量在多个基准上能取得很好结果;文献[5]提出了一种全局最大池化模型,通过提取多个卷积层和GMP层得到更深层的语义特征,在点积层产生情感得分,提高了模型效率;文献[6]在传统卷积神经网络模型基础上去掉了池化层,加上了门阀循环单元GRU层,提出来一种串并行卷积门阀循环网络新模型,提高了分类准确率。
传统分类模型结构简单,改进模型或者结合一些其他模型会提高分类的准确率。因此,本文通过对inception V1模型特征优化,将稀疏矩阵聚类为密集矩阵,最终到soft分类器中分类。实验通过对数据样本多次迭代操作,结果显示:精准率逐渐升高且趋于稳定,通过几种分类模型的对比试验可以得出,i-CNN模型相对其他机器学习模型有着较好的分类效果。
1 相关工作
1.1 卷积神经网络与文本分类
卷积神经网络是一种深层神经网络模型,本质上就是多层卷积运算,将上一层神经元的输出作为下一层的输入,通过多层卷积计算,对每一层的卷积运算结果进行非线性转换[10]。卷积神经网络相较于传统神经网络具有参数共享、局部连接两大优势,使网络需要训练的参数大大减少,却没有降低准确率。
参数共享也可理解为“平移不变性”,是指一组神经元对应一个权重,而不是每个神经元对应一个权重,这样就减少了很多参数。局部连接是指和上一层神经元中的局部相连,而不是和上层所有神经元相连接,这样又减少了很多参数,减少了后续的计算量。
用传统的机器学习方法做文本分类任务时,通常输入文档的tf-idf向量作模型的特征,这样的输入会使tf-idf表示丢失文本序列中的顺序。而卷积神经网络对文本数据建模时,输入词向量,然后通过滑动窗口将长短不一的词向量转化为固定长度的向量,这样可以保留原文本中的一些局部特征和顺序上的信息。由于远距离两个词之间的依赖关系很难被捕捉到,所以基于CNN的文本分类更适合短文本。
1.2 文本分词
不同于英文文本词与词之间有分隔符,不用进行分词处理,中文文本字词之间没有分隔符,而且单个汉字不能完整的表达意思,所以中文文本要进行分词处理。中文分词会存在很多问题,最主要的就是会出现歧义,对句子进行不同的分词会出现不同的意思。对于这一问题,可以在卷积时使用多种不同的卷积核进行卷积。其次是分词词典要全面、及时更新,中文分词选用Word2vec分词器,它是一个基于gensim库的中文数据处理工具包,在词典中,每一个词都有唯一的向量对应,文本就可以转化为向量表示。
1.3 停用词处理
停用词就是文本中出现频率很高而且没有实际意义的词,比如“的”、“啊”“了”等,也包括标点符号和网络表情包,它们没有表达任何感情倾向,对文本情感划分没有影响。邮件一般都是比较短的文本,停用词的存在对结果的影响更大。
去停用词常用的方法是选择一个比较全面的词表,过滤去重,将文本中的停用词逐一去掉。去重后的文本不仅降低了特征向量的维度,降低了后续计算的复杂度,在一定程度上还提高了分类的准确率。
1.4 Word Embedding模型
图像在计算机处理时输入的是二维矩阵,因此处理中文邮件时也要先把文本转变为矩阵形式,通过开源工具word2vec将文本中的词转化为词向量。CBOW和Skip-Gram是word2vec的两个模型,CBOW更适合数据样本比较少的数据库,而Skip-Gram在大型语料中分类准确率更高,所以实验选用Skip-Gram模型构造Word Embedding模型[11]。
Skip-Gram模型通过输入词wt预测上下文Swt=(wt-k,…,wt-1,wt+1,…,wt+k),其中k为wt卷积窗口大小,即上下文中预测词向量的个数,CBOW模型则是根据上下文Swt去预测某个词向量wt。Skip-Gram模型和CBOW模型训练目标优化函数分别如式(1)和式(2)所示:
(1)
(2)
其中,C为数据样本中所有的词向量,k为wt上下文卷积窗口大小。Word2vec为得到训练后网络中隐藏层的参数,这些参数就是Word2vec学习的词向量。
2 i-CNN模型
虽然传统的CNN模型已经在卷积、池化层通过部分连接,下采样的方式减少了参数,但是随着样本数据的增加,会出现数据稀疏现象,造成空间的浪费,同时也会带来维数过高的问题,使得计算复杂度增高。为了解决这两个问题,将Inception V1模型与CNN模型结合,提出来i-CNN模型,在卷积层后加入1×1卷积核,通过降低特征向量的通道维数来减少参数,提高计算效率及分类精准率。
i-CNN模型的框架流程如图1所示:将处理好的词向量输入模型,使用过滤器获取特征向量,改变窗口大小,得到多个特征向量,池化层筛选最强的特征向量,最终到soft分类器输出类别的概率,通过比较分类结果和数据集标签计算损失函数,再通过梯度下降算法反向传播,调节模型参数降低损失至网络收敛,训练过程完成。
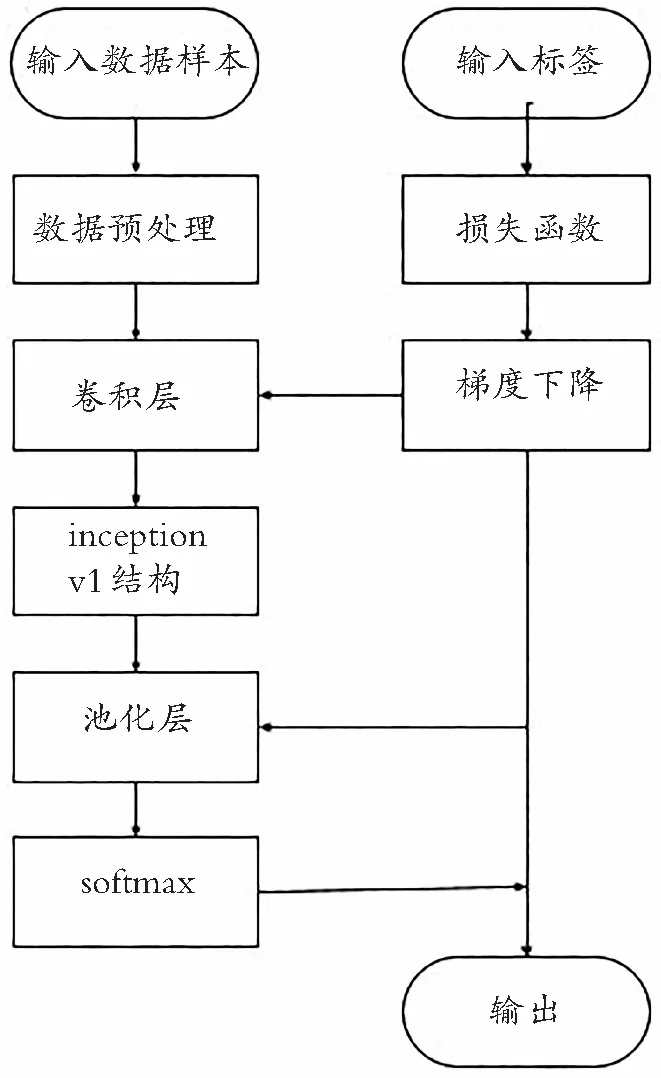
图1 网络框架流程图
2.1 输入层
输入层将中文邮件处理为词向量,一般是n×k的矩阵,其中n为文本单词总数,样本数据的词向量维度要保持一致,若长度不够,用padding补零,超出则舍弃。用开源工具包word2vec将每个词转化k维向量,k维向量作为未知参数由训练得到。
如例句:本公司有部分普通发票、商品销售发票、增值税发票及其他服务行业发票。处理之后变成{本公司,有,部分,普通发票,商品,销售,发票,增值税,发票,及,其他,服务,行业,发票}。
2.2 卷积层的优化
2.2.1 卷积层
在卷积层对样本数据进行特征提取,这是建立模型最重要的一步。在输入的n×k的矩阵上,卷积操作定义如式(3)所示:
ci=f(w·xi:i+h-1+b)
(3)
其中,xi:i+h-1代表输入矩阵的第i行到第i+h-1行所组成的大小为h×k的滑动矩阵窗口,w和xi:i+h-1的维度一样,也是h×k,b为偏置参数,f为非线性激活函数,Ci为标量。
卷积核在做卷积操作时,假设卷积窗口大小为2,在2×k的滑动窗口上卷积,就可得到(n-1)个结果,然后拼接组成(n-1)维的特征向量,如式(4):
c=(c1,c2,c3,…,cn-1)
(4)
卷积层中可以设定不同的卷积窗口h,提取不同的特征,单一的卷积操作可能会造成对句子意思理解的偏差,设置不同尺寸的卷积核,从每一个卷积核的卷积操作中提取一个特征,就可以提取出不同的特征,减少因语义产生的分类误差。
2.2.2 Inception V1模型
Inception V1模型主要改进网络中的卷积层,针对网络参数过多,容易过拟合,以及深层网络梯度下降停滞等问题,1×1卷积核可以降低特征向量通道维度。在卷积层采用不同尺寸的窗口做特征提取,max pooling本身也是一种特征提取,也可以作为一个分支,这就是inception V1模型。模型结构如图2所示,在3×3,5×5前,max pooling后加上1×1卷积核,降低特征向量厚度。
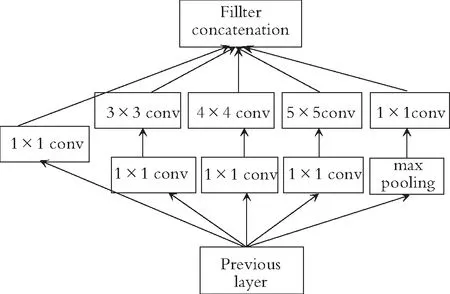
图2 Inception V1模型结构图
根据图2做对比计算,假设上层输入特征向量的维度为256,输出特征向量维度也是256,直接用3×3×256维的卷积核输出256维特征向量,参数为256×3×3×256=589 824个。如果先经过1×1×64的卷积核,再经过一个3×3×64的卷积核,最后再经过一个1×1×256的卷积核,参数为256×1×1×64+64×3×3×64+64×1×1×256=69 632个,这样就减少了大部分的参数。
2.3 池化层
池化层对上层特征向量压缩,提取主要的特征,减少网络参数和后续计算复杂度。池化方法有很多种,主要采用max池化,即把上一层中的每个卷积核产生的最大特征向量作为特征值,如式(5):
(5)
2.4 全连接层
全连接层对前面高度抽象化的特征整合,进行维度转换,再加上激活函数的非线性映射,通过Softmax函数对分类情况输出,Softmax表达式如(6)所示:
(6)
i表示n维向量的第i个值,对于输入的n维向量,向量的每个值都表示输入对于每个类的概率。
3 实例分析与应用
3.1 实验数据
实验数据是从网络上获取并整理的中文邮件,根据语义将邮件分为正常邮件和垃圾邮件,正常邮件是需要的,垃圾邮件是一些广告、推文等。根据语义将邮件整理放在两个文件夹中, 5 000条正常邮件为正向评论,放在Positive-examples文件夹中,5 000条垃圾邮件为负向评论,放在Negative- examples文件夹中。在两个不同数据集上进行实验,对本文所提出模型进行评估。对于每个数据集,随机抽取80%作为训练集,20%作为测试集,并进行多次迭代实验,直到损失函数收敛。
3.2 实验环境
实验采用Intel Core i5处理器、8G内存、Windows系统、开发语言是Anaconda集成环境中的Python3.7编写实验代码,开发工具为PyCharm Community Edition。主要的几种环境配置如表1所示。

表1 实验环境及配置
3.3 实验设计
本实验利用gensim库中的Word2vec中文工具包进行分词和词性标注,并将邮件中的词转化为词向量,进而对词向量训练。实验参数主要有词向量维度、卷积窗口大小、池化方法等。其中词向量维度设置为128,卷积窗口大小在(3,4,5)中取值,卷积核数量设置为128,比率为0.5,批量尺寸为64,评估间隔为100,采用max-pooling方法进行池化。本文网络模型参数设置如表2所示。
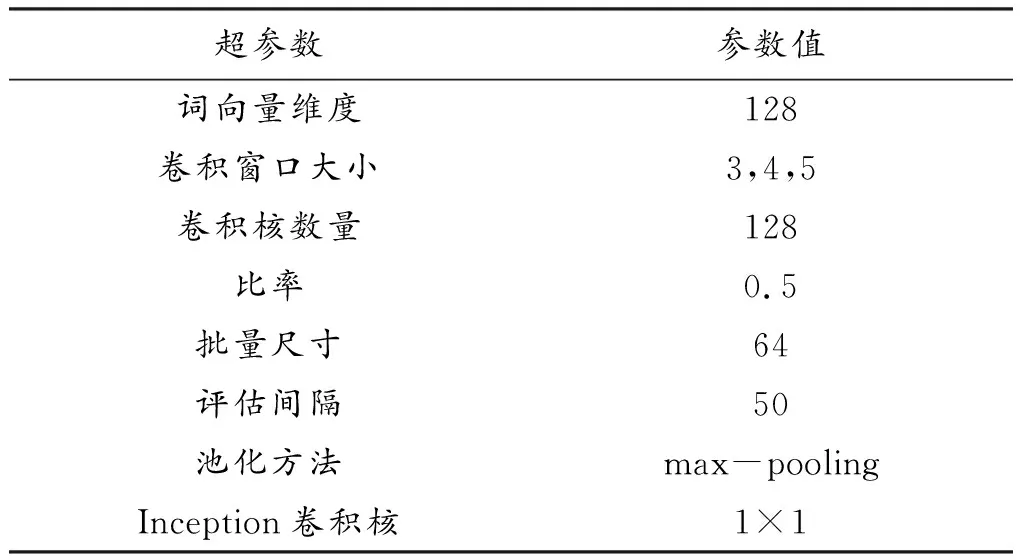
表2 网络模型参数
实验用整理好的中文邮件去验证i-CNN模型的分类效果,具体做了以下3种实验:
(1) 对训练集数据进行预处理,分词、去停用词、词向量转化输入网络模型,进行训练,每50次做一次评估检测保留accuracy值,用accuracy衡量模型性能。
(2) 为了比较i-CNN模型在中文邮件分类中与其他分类方法性能的优劣,用支持向量机(SVM)、朴素贝叶斯(NB)、k邻近算法(KN)3种传统的分类模型做对比试验,使用同一组数据集,正向评论和负向评论各5 000条。
(3) 为了比较inception V1模型对传统CNN模型的优化效果,在同一组数据集训练,各种参数保持一致。
3.4 实验结果分析
数据集在模型中的训练结果如图3所示,经过600次迭代训练,精准率稳定上升达到90%以上,最高达到93.7%,验证了i-CNN模型对垃圾邮件有较好的分类效果。
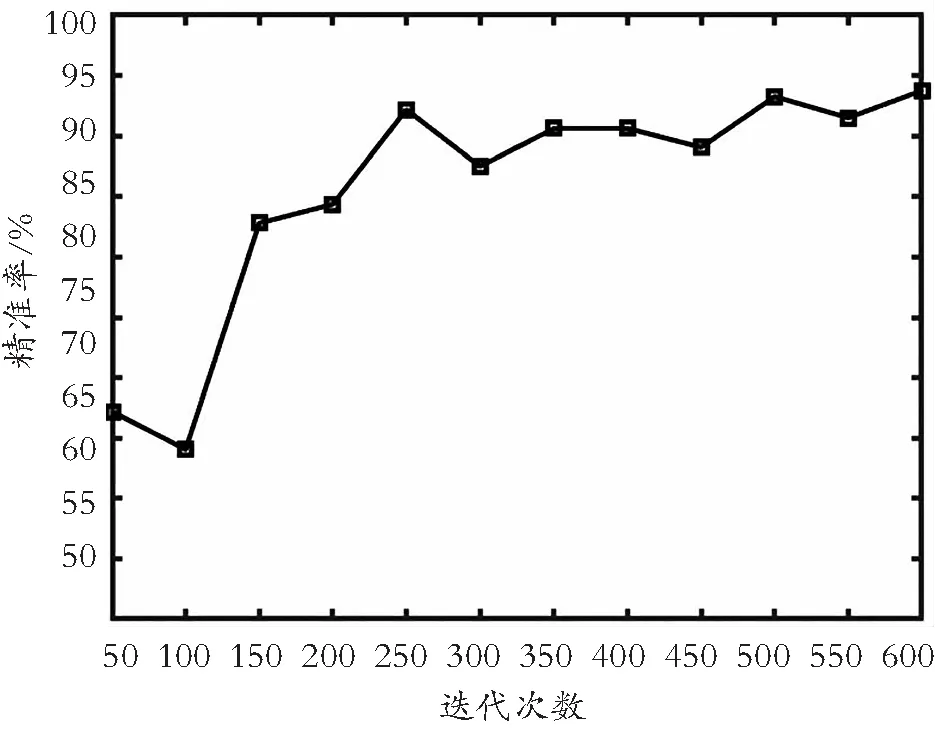
图3 训练数据精准率
由表3可以看出,i-CNN模型的分类精准率达到了92.18%,除了与支持向量机的分类效果比较接近,其分类性能远高于朴素贝叶斯和k近邻算法两种传统的机器学习模型,说明i-CNN模型具有较好的分类性能。

表3 数据分类精准率
由表4可以看出:相同的数据样本中,在CNN模型中加入inception模型,精准率提高了1.45%,效果不是很好,主要是网络的深度不够,inception V1模型对深层的网络优化效果更好。

表4 有无inception结构的结果对比
4 结 论
通过对邮件的分类试验,可以看出i-CNN模型在文本分类方面有较好的效果,inception V1模型确实能优化网络,提高分类效果,但从结果来看,还有很多的提升空间。对本实验来说,数据样本还不够大,种类还不够全面,网络深度不够,目前的网络模型缺乏通用性、灵活性,在提高分类效果方面还需要更多探索,可尝试与其他模型结合或者改进卷积神经网络模型来做进一步研究。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
承德医学院学报(2022年2期)2022-05-23
计算技术与自动化(2022年1期)2022-04-15
保定学院学报(2022年2期)2022-04-07
中学生理科应试(2021年11期)2021-12-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
疯狂英语·新阅版(2020年11期)2020-12-21
数学学习与研究(2018年15期)2018-11-12
电脑爱好者(2012年22期)2012-11-19
