
基于平均位置学习的改进粒子群算法研究
2022-05-18 01:41:38杨妹兰刘衍民舒小丽
重庆工商大学学报(自然科学版) 2022年3期
杨妹兰, 刘衍民, 张 倩, 舒小丽
(1.贵州大学 数学与统计学院,贵阳 550025;2.遵义师范学院 数学学院, 贵州 遵义 563006;3.贵州民族大学 数据科学与信息工程学院, 贵阳 550025)
0 引 言
粒子群算法(Particle Swarm Optimization,PSO)[1]是1995年由 Eberhart 和 Kennedy提出的一种基于模拟鸟类觅食行为过程的随机智能优化算法。在PSO中,种群的每个粒子表示所研究问题的候选解,每个粒子通过向个体历史最优位置和种群历史最优位置学习来更新当前速度和位置。PSO由于具有结构简单、寻优能力强、容易实现和收敛速度快等优点,近几年被广泛应用于各个领域,如煤炭[2]、工业生产[3]和水电调度[4]等。但是,PSO仍然存在一些问题,比如容易出现早熟问题、维数灾难问题和易陷入局部最优解等。
为了提高PSO的综合性能,许多研究者对PSO存在的问题进行相了关的改进研究,主要的改进分为:
(1) 邻居拓扑结构的改进。研究者们已经设计了许多不同类型的拓扑结构,从而以很多不同方式来改进粒子的学习策略。如Kennedy等[5-6]提出了几类基本的领域拓扑结构,如环形结构、星型结构和齿形结构等,还分析了几种拓扑结构对优化问题结果的作用。文献[7]利用全局版本和局部版本拓扑结构相结合,从而改进了粒子的学习策略,有效提高算法的寻最优解能力和收敛性能。
(2) 优化粒子速度的更新过程。粒子的速度更新公式由学习样本的选择进行决定,如文献[8]利用个体间的欧式距离大小来选择每个个体的学习样本,有效增强了种群的多样性;文献[9]在粒子速度更新公式中引入全局最优位置和综合最优位置作为学习对象,提高了粒子的搜索能力;文献[10]引入免疫算法的粒子群优化方法,既增强了每个粒子的搜索能力,还提高了算法的收敛性能;文献[11]提出一种基于贝叶斯迭代法的综合学习粒子群算法,增强了算法的局部最优规避能力。这些改进方法对提高算法的运行效率,跳出局部最优解具有一定作用。但是,在遇到复杂的多维多峰问题时,收敛效果不理想、全局搜索能力和局部开发能力不协调等问题依然存在。
因此,本文针PSO的特性和不足,提出了一种结合适应度距离比值和平均位置的改进粒子群算法MLFDR。通过与4个不同算法进行实验对比与分析,证明MLFDR能够更好地平衡局部开发和全局搜索,同时算法在求解精度和收敛性能上得到了显著提高。
1 基本粒子群算法
标准粒子群算法(PSO)是一种生物进化算法,它是受到鸟类觅食行为的启发。在研究PSO时,把种群中每个粒子看作D维搜索空间中的一个搜索个体,个体的当前位置视为优化问题的一个可能解,即粒子的飞行过程可视为对应个体的搜索过程。种群中粒子通过向个体历史最优位置和种群历史最优位置学习来更新当前速度和位置。
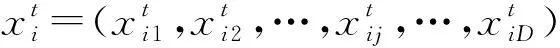
(1)
(2)
2 改进的粒子群算法
2.1 贪心策略
贪心策略总是在当前条件下为最优的选择,换句话说,该策略不是从整体上进行选择,而它的选择只是在某种意义下的局部最优解,因此,很多问题自身的特点就决定着该问题采用贪心策略就能获得最优解或者较优解。
定义1 贪心策略是指从问题的初始状态出发,通过若干次的贪心选择而得出最优值(或较优解)的一种解决问题方法。
本文改进的PSO应用贪心策略,粒子群在每次更新位置后,对局部搜索的结果个体历史最优位置(pbest)采用贪心策略选择,即
(4)
2.2 MLFDR算法
PSO具有参数比较少、易实现以及操作方便等优点,但算法也具有寻优精度较低、前期收敛速度偏慢以及容易陷入局部最优解等问题,种群中的每个粒子仅由它的个体历史最优位置和种群历史最优位置决定。针对PSO的上述情况,本文引入比粒子自身适应值更好的邻近粒子和平均位置[12]作为学习对象。在学习策略中引入比粒子自身适应值更好的邻近粒子,使种群避免陷入局部最优解,还增强粒子的搜索能力。
在选择过程中,考虑最简单和最稳定的变化来选择一个适应值之差与一维位置距离的比值最大对应粒子nbest,用粒子nbest来更新当前粒子速度的每个分量,可提高算法的寻优能力和收敛能力。选择最大比值公式为
(5)
在学习策略中引入平均位置作为学习对象,可提升种群的多样性和改善算法的学习策略,同时还能提高算法的运行效率。该算法分为两个阶段更新粒子[13],具体改进策略如下。
2.2.1 前期引入种群的平均位置的改进
阶段一是指算法前期更新至第2×ps次的部分(ps表示种群规模),改进之处是在速度更新公式中引入种群的平均位置作为学习对象,该平均位置综合了种群所有粒子的飞行行为,使算法在搜索过程具有一定的普遍性,可以保证算法的收敛性,同时提升了种群的多样性,还提高了每个粒子飞行过程的稳定性,还能更好地平衡局部开发能力和全局搜索能力,从而有效增强了算法的寻优能力。在每一次更新前,先计算出当前所有粒子位置的平均位置,具体平均位置公式如下:
(6)
(7)
其中,mp(1,j)表示第j维的平均位置;h参数是一个社会影响因素;d表示维数变量(d≤D),取β=0.01。
一般情况下,种群的收敛要求每个粒子位置向量的每个维度收敛,所以算法的收敛难度与搜索维数成正比。在搜索维数的基础上建立社会影响因素h,有利于收敛性与多样性之间有良好的平衡状态。根据观察,参数h与优化问题维数d成正比,可以控制种群平均位置的影响;如果该参数的值取得很大,可能会出现过早收敛到平均位置的情况,从而不能到达最佳行为。
在阶段一采用贪心策略,每次在当前粒子的速度和位置更新后,将更新后的个体历史最优位置适应值(pbestval)与种群历史最优适应值(gbestval)比较,若更新后的个体历史最优适应值(pbestval)更优,则将对应的个体历史最优位置(pbest)储存起来,还将个体历史最优位置和适应值分别赋值给种群历史最优位置和适应值;反之就不用储存且种群历史最优位置和适应值保留原值。具体公式如下:
(8)
(9)
其中,sgn表示符号函数;pbest(k)表示算法储存的第k个个体历史最优位置。
2.2.2 后期引入最佳位置的平均位置改进
阶段二是指算法从第2×ps次评价之后的部分,粒子个体的收敛速度较快,但容易出现局部最优停滞的现象。为了使算法效果更好,在算法后期引入更新后储存的所有个体历史最优位置的平均位置,去替换阶段一的平均位置,既可以使算法跳出停滞现象,还提升了局部搜索精度,而且阶段一的优点依然保持,还能够很好地协调算法的局部开发能力与全局搜索能力。在本阶段更新后继续使用贪心策略,若与种群历史最优位置比较后得个体历史最优适应值更优,则储存对应个体历史最优位置。在阶段一结束后,开始计算储存中所有个体历史最优位置的平均位置,具体平均公式如下:
(10)
其中,u表示储存个体历史最优位置的个数;pbest(k)j表示储存中被标记的第k个粒子第j维的个体历史最优位置;mp表示平均位置。
MLFDR的学习对象除了个体历史最优位置和种群历史最优位置外,还添加了两个学习对象,即比粒子自身适应值更好的邻近粒子(nbest)和平均位置(mp),可保证算法改进的优点,还能使整个算法达到更佳的效果。粒子的迭代更新速度公式如下:
(11)
其中,nbestij表示最佳适应度距离比值对应的粒子位置;mp表示平均位置,阶段一用式(6)计算平均位置,阶段二用式(10)计算平均位置;h表示社会影响因素,控制种群平均位置的影响,还可以更好地平衡种群多样性与收敛性之间的状态。
2.3 改进粒子群算法的基本步骤
(1) 种群初始化。种群初始化的粒子是以随机方式来生成初始位置和速度。
(2) 计算适应值。计算每个粒子的适应度值,然后,确定当前的个体历史最优位置和种群历史最优位置,将个体最优的适应度值存储在pbestval中,将种群最优的适应度值存储在gbestval中。
(3) 按照式(5)计算最大值比,求得nbest;用式(7)计算h;在前ps次更新时,需按照式(6)计算种群所有粒子位置的平均位置mp。
(4) 更新粒子位置。按照式(11)和式(2)来更新当前粒子的速度和位置。
(5) 更新个体最优。将粒子更新后的适应度值与其未更新前的适应度进行比较,取适应值较好的粒子作为当前迭代后的粒子。
(6) 更新种群最优。通过比较个体历史最优适应值和种群历史最优适应值,若个体历史最优适应值较好,将对应的个体历史最优位置储存起来,且将个体历史最优适应值赋值给种群历史最优适应值的方式更新种群历史最优位置。
(7) 判断算法是否评价至第2×ps次,若是则按照式(10)计算mp后,将mp赋值给步骤(3)的mp。
(8) 算法终止。如果满足最大迭代数结束条件,算法搜索停止;否则返回到步骤(3)继续搜索。
MLFDR流程如图1所示。
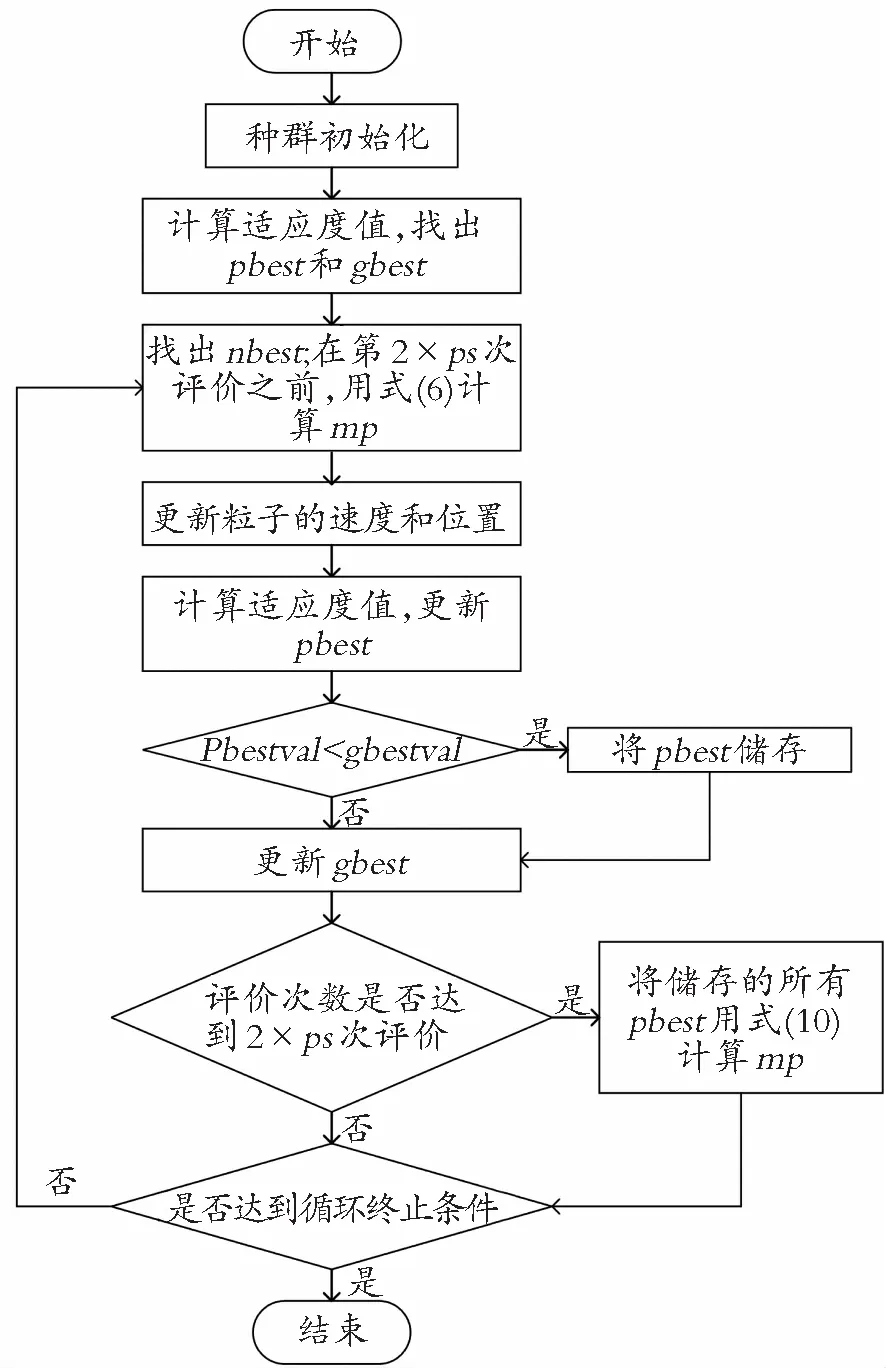
图1 MLFDR算法流程
3 MLFDR算法性能测试与分析
3.1 检测函数选取
为了测试MLFDR的收敛速度和全局搜索能力,利用CEC2017测试函数中的单峰和多峰共8个测试函数进行函数优化的对比实验。其中,f4和f5为单峰函数,f1、f2、f3、f6、f7和f8为多峰函数,它们分别用于检验不同算法的搜索速度、寻优能力和全局搜索能力。具体测试函数见表1。

表1 本文选用的8个测试函数
为了增加这些检测函数的优化难度,将部分函数都进行旋转,用“*”表示对应测试函数进行旋转 。选择4个不同算法与本文提出的MLFDR相比较,4个不同算法分别是:PSO[1]、FDR[8]、wFIPS[14]和UPSO[7]算法。
3.2 算法参数设置
选取FDR、PSO、wFIPS和UPSO算法进行对比,为了体现不同算法之间的可比性,实验中所有算法都取参数保持一致,种群规模是10,每个测试函数单独运行了50次,对于非旋转的测试函数则每次运行进行3×104函数评价,旋转的测试函数则每次运行进行2×104函数评价,其他参数设置见表2。

表2 对比5个算法的具体参数设置
3.3 实验结果和分析
3.3.1 收敛特性仿真实验
为了检测不同算法的收敛特性,给出在确定的函数评价次数下不同算法的运行特性。不同算法以3×104和2×104函数评估后的收敛曲线图分别有图2和图3。
从图2可以看出,采用非旋转测试函数检测算法的情况,对于Rastrigin’s 、Rosenbrock’s、Non-con tinuous Rotated Rostrigin’s 、Ackley’s、Happy Cat和HGBat函数检测时,MLFDR算法取得了最好的运行效果,且表现出更加明显的优势。而FDR和wFIPS算法在多峰问题上也表现出求解能力,主要是它们的学习策略不同于PSO和UPSO算法,可以有效地避免早熟收敛。从图3可以看出,采用旋转测试函数,对于Rastrigin’s、Non-continuous Rotated Rostrigin’s、High Conditioned Elliptic、Rosenbrock’s、Discus 、Ackley’s、Happy Cat和HGBat 函数检测时,MLFDR表现出较好的收敛性,主要是引入平均位置来构建广泛学习策略,于是提高了种群的多样性,增强了种群跳出局部最优解的能力。
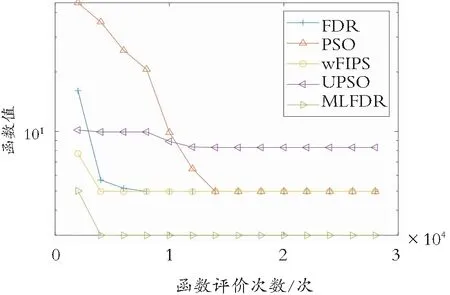
(a) Rastrigin’s 函数
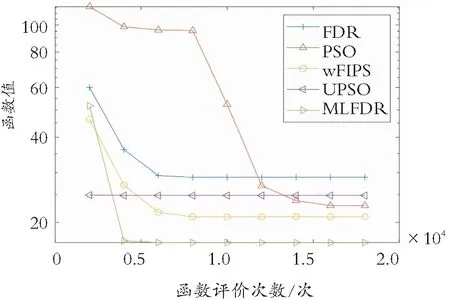
(a) Rastrigin’s函数
3.3.2 鲁棒性分析
为了检测5个不同算法在相同测试函数的不同环境(函数旋转和不旋转)下算法运行是否具有稳定性,选择了3个Benchmark函数(Ackley、Happy Cat和HGBat),通过实验研究算法在这些测试函数的稳定性。鲁棒性分析结果在表3中给出,本文“鲁棒性”是在50次单独运行过程中算法成功取到指定阈值的比例,FEs为取到阈值时的函数评价次数,S为取到指导阈值的比例(单位是%)。其中3个函数的阈值分别是0.4、0.3和0.5。
在表3可以看出,PSO、wFIPS、FDR和MLFDR算法在Ackley’s函数非旋转情况下100%取到了指定阈值,但在旋转情况下只有MLFDR成功取得阈值。Happy Cat函数在非旋转和旋转情况下都只有MLFDR算法成功取得阈值,但FDR在旋转和非旋转的情况下表现较为稳定,wFIPS在旋转情况下也表现较为稳定。HGBat函数在非旋转和旋转情况下都仅有PSO、FDR和MLFDR算法成功取到了阈值,但MLFDR算法比PSO和FDR算法都用了较少的函数评价。
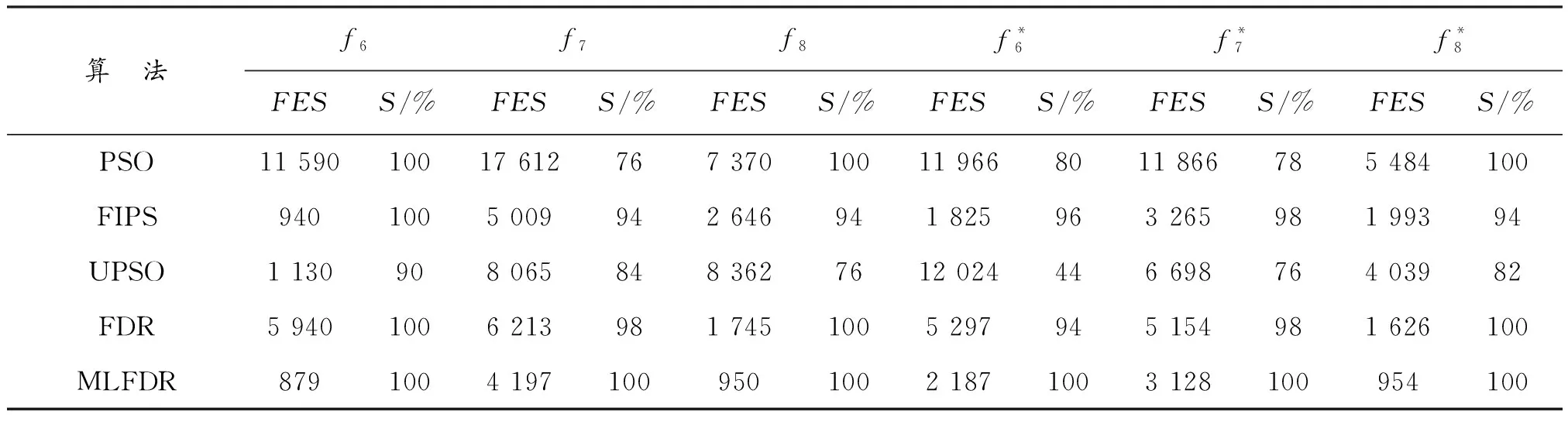
表3 5个算法的鲁棒性分析
3.3.3 测试函数寻优结果分析
为了排除偶然性引起的误差,分别对6个非旋转和8个旋转测试函数进行50次独立实验。在多个标准测试函数上,对5个不同算法进行50次独立运行后所得实验结果如下。
实验结果如表4和表5可知,实验在相同约束条件下,MLFDR分别在非旋转测试函数和旋转测试函数的统计结果中明显优于另4个对比算法。对于测试函数f6,几种算法寻优效果差别不大,MLFDR寻优结果略大于其他4个算法;对于f1、f2、f3、f7、f8和旋转的所有测试函数,MLFDR寻优效果都优于其他4个算法。不论是非旋转测试函数还是旋转测试函数,MLFDR寻优结果优于其他4个算法,平均值和标准差都比其他4个算法小,说明MLFDR的稳定性和鲁棒性优于其他4个算法,证明改进后的粒子群算法具有一定优势。
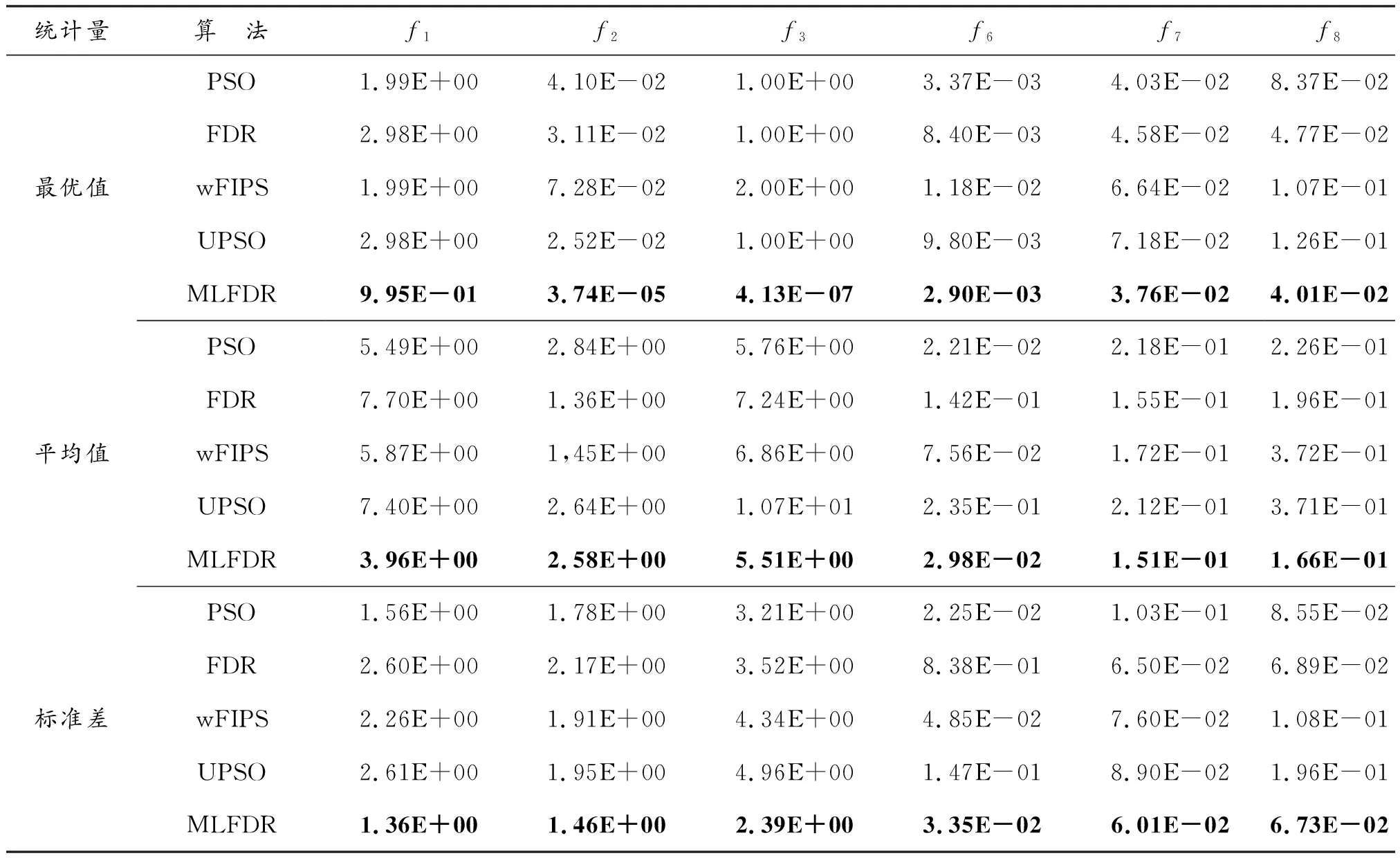
表4 非旋转测试函数寻优结果

表5 旋转测试函数寻优结果
3.3.4 Wilcoxon秩和检验
由表6可知,为了进一步评估MLFDR的性能,在a=5%显著性水平下,对30次独立运行下的MLFDR于其他4个算法的最佳结果进行Wilconxon秩和检验。以验证MLFDR所得结果与其他4个算法中最好结果的差别是否有统计意义。表6显示检验结果所示,小于等于0.05表示结果有差(符号“1”),大于0.05表示结果没有差异(符号“0”),在8个基准测试函数中,MLFDR的性能在8个测试函数上与PSO、FDR、wFIPS和UPSO算法有差异,而且MLFDR的p值基本都小于等于0.05,表明MLFDR的差异性在统计上显著的。

表6 Wilcoxon秩与检验p值
4 结 论
本文为解决PSO存在寻优精度不高、易陷入局部最优解等不足,提出了一种基于平均位置学习的改进粒子群算法MLFDR。该算法通过引入比粒子自身适应值更好的邻近粒子和平均位置作为学习对象,改善了算法的早熟收敛问题,提高了收敛速度。其主要研究粒子群算法在优化问题时综合所有粒子平均位置的有益信息,提高了算法对函数的优化,特别是多峰函数优化中的性能。通过用8个测试函数进行实验,与其他4个算法的比较得出MLFDR综合性能更好。
猜你喜欢
今日农业(2022年15期)2022-09-20 06:54:16
测控技术(2018年10期)2018-11-25 09:35:54
红土地(2018年7期)2018-09-26 03:07:38
浙江工业大学学报(2017年5期)2018-01-22 02:03:46
物联网技术(2017年5期)2017-06-03 10:16:31
上海理工大学学报(2016年2期)2016-06-02 09:22:25
陕西理工大学学报(自然科学版)(2015年6期)2016-01-25 11:00:22
江苏高职教育(2014年2期)2014-07-16 07:10:04
物理与工程(2014年4期)2014-02-27 11:23:08
当代畜禽养殖业(2014年10期)2014-02-27 07:59:49
