
神经机器翻译面对句长敏感问题的研究
2022-05-15 06:35阿里木赛买提斯拉吉艾合麦提如则麦麦提麦合甫热提艾山吾买尔吾守尔斯拉木吐尔根依不拉音
计算机工程与应用 2022年9期
阿里木·赛买提,斯拉吉艾合麦提·如则麦麦提,麦合甫热提,艾山·吾买尔,吾守尔·斯拉木,吐尔根·依不拉音
新疆大学 信息科学与工程学院 多语种信息技术实验中心,乌鲁木齐830046
频繁的语言交流,对包括少数民族语言在内的翻译服务提出了大量多样化的需求。在传统翻译行业中,译员培养和译员提供服务的时间成本与经济成本均较高,逐渐走到瓶颈期。人工智能的不断发展,深度学习技术推动了机器翻译等自然语言处理技术取得重大进展,并且在大量训练数据的支撑下核心效果不断提升[1]。在机器翻译模型中Arthur 等人加入外部词汇从而解决翻译过程中的数据稀疏问题[2-3]。Bahdanau 和Wu 等人提出的基于注意力机制的神经机器翻译相比基于统计翻译方法,翻译性能及翻译效果取得了大幅改善,并且在个别场景中翻译效果逼近人类翻译水平[4-5]。2017 年这一技术稳定的局面被Transformer打破[6],并且成为了最受欢迎的神经机器翻译技术框架。
在同内容的表达方面,维吾尔语的内容序列长度要明显长于汉语的序列长度,并且在解码时文本序列越长对context信息的计算及译文的质量也会带来间接的影响,更难捕捉句子长距离的依赖。在机器翻译中模型融合是将多个神经机器翻译系统训练后的结果产物进行系统性的融合处理,以获取更好的译文结果的方法。模型融合的主要思路是在神经网络机器翻译中每个翻译模型都有自己的译文预测的优势部分,模型融合则可使各个翻译模型的优势能够巧妙地耦合以便获取一个更好的神经网络机器翻译模型,机器翻译模型融合现已被越来越多的研究爱好者们所接受,并且在众多可研论文及评测报告中表明,模型融合技术可高效地达到上述目的[7]。
神经网络机器翻译模型融合可以按照级别分为词汇级、句子级和短语级机器翻译模型融合。以句子长度为边界划分的机器翻译模型融合则需将候选结果先合并,再通过个性化的选取机制筛选出质量最好的翻译结果作为输出;短语级神经网络模型融合采用机器翻译译文和源端输入句子获取对齐后的短语翻译表(在此也可采用机器翻译模型过程译文产物),再次计算翻译预测概率,为获取新的译文句子采用短语解码器再次完成解码;词汇级神经网络机器翻译融合方法则是先将单词进行对齐(方法包括:GIZA++对齐方法、法医错误率(TER)和编辑距离对齐方法等),从而建立一致性网络并完成解码,获取新的译文句子。
本文为了充分利用维吾尔语与汉语有限的平行语料,考虑到维吾尔语汉语平行语料实验室自建数据集为更好地体现该方法的权威可信性及效果,加入了数据量较多的中英翻译任务采用了CWMT2018 中英数据集。本文根据句子长度信息,把原平行语料划分若干个模型,为每个模型训练一个子模型,提出了一种按句子长度融合策略的神经网络翻译方法,并使用两种不同的方法得到最终的译文。通过实验证明,在语料充足的情况下两种方法都能使机器翻译质量得到有效的提升,在三个不同测试集上均有所提升。
1 不同句长边界划分后的模型融合
机器翻译训练数据中理论上模型训练数据句长得均匀分布,但往往因为种种因素会有占比的失衡,而正是这样的一种失衡现象可能导致神经网络机器翻译模型在面对极端句长的情况中出现较差的一种表现[8]。为了充分利用海量平行语料并进一步提升机器翻译模型质量,提出了一种按句子长度划分策略的融合系统,并在维汉及英中任务中进行对比实验。
首先,将平行预料按句子长度划分几个模块;然后,使用每个语料对基线模型进行Fine-Tuning[5]训练。系统框架如图1所示。当模型训练完以后,最终本文使用两个方法来得到最终的译文。
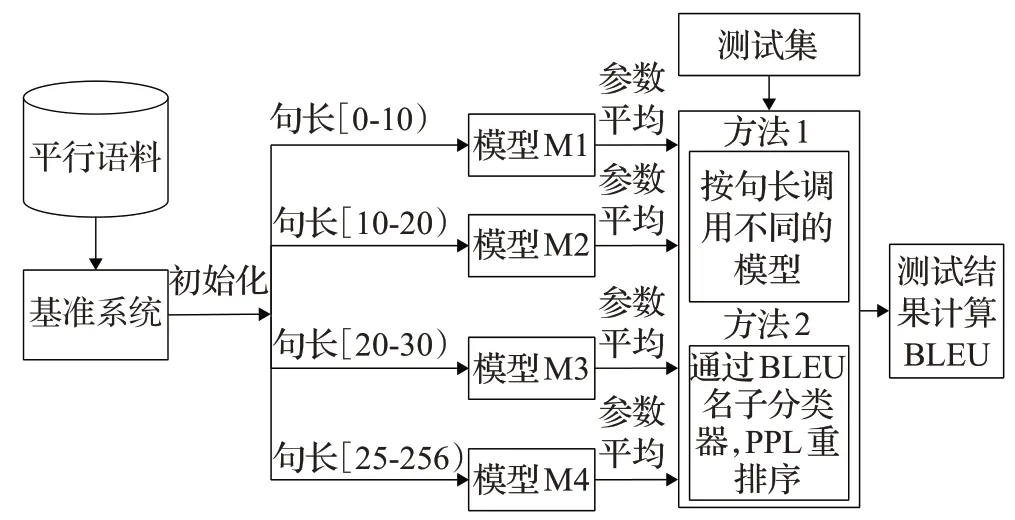
图1 不同句子长度模型的训练融合方法Fig.1 Training fusion method of different sentence length model
句长边界划分后模型的融合:根据测试集源语言句子长度调用相应的模型来得到译文。
三特征(困惑度、句长比与分类器)融合排序:
分别使用四个子模型进行翻译,将各个模型翻译结果按照句子比例、BERT[9]句子级困惑度(PPL)以及BERT 句子分类器的概率来重排序得到最终的翻译结果。下面分别介绍一下句子比例、困惑度以及本文的基于BERT的句子分类器。
句子比例计算:首先,分别对源语言和目标语言平行句对进行分词;然后,计算单词及标点数量,最终通过公式(1)获取句子比例。初步认为句子比例越接近1,说明这两条句子的平行度越好。

例如:
原文:I am student of Xinjiang University.(句长:7)
目标:我是新疆大学的学生。(句长:7)
通过公式计算句子长度比例P等于1,说明该句对里面的单词数量完全一样。
困惑度:在自然语言处理中,困惑度是用来评价语言模型好坏的指标。一般情况下,困惑度越低,说明语言模型对这句话的困惑程度越低,语言模型就越好。困惑度通常计算句子或文本的概率分布平均到每个词上的困惑度数值。困惑度的计算方式如式(2)所示。本文对于中文使用BERT(bidirectional encoder representation from transformers)预训练语言模型获取困惑度,并在融合系统中使用。
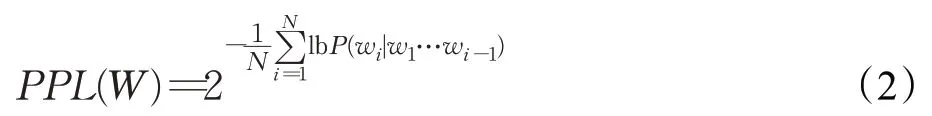
其中,N表示句子或文本的长度。
BERT 句子分类器:BERT 是截至2018 年10 月最新的state of the art模型,通过预训练和精调横扫了11项NLP 任务[9]。而且它的基本原理是Transformer,也就是相对比RNN 更加高效、能捕捉句子更长距离的依赖。本文提出的句子分类思路如下:
首先,将平行语料拼接起来作为正样本,将打乱的平行语料再进行拼接作为负样本创建训练数据;然后,将拼接后的句子作为BERT 的输入;最终,通过feed forward neural network(FFNN)和SoftMax 来训练句子分类器。
在此使用140 万条数据进行训练,其中正、负样本各70 万。模型的训练结果为:验证集上的正确率为94%,测试上的正确率为95%。在融合时将每个模型的翻译结果和原文进行拼接,作为句子分类器模型的输入,并得到对齐概率,最终将对齐概率、困惑度和句子长度按照比例进行打分,选出分数最高的作为最终翻译结果。
2 实验
2.1 实验数据与统计
本文实验中在维汉任务中使用100 万条已清洗的维汉平行句对,验证集为1 000条维汉平行句对,在中英任务中使用机器翻译评测(CWMT2018)的英-中平行语料进行实验,其中训练集为720 多万条英汉平行句对,验证集为1 000 条英中平行句对组成。在实验中,针对数据集进行了比较细致的预处理,包括编码转换、乱码过滤、分词、异常句子筛选以及BPE[10]切分等。其中:
(1)编码转换及去重:利用本课题小组研发的编码转换工具分别对维、汉、英语料进行全角半角转换、繁体简体转换、乱码过滤与去重操作。
(2)分词:利用开源的哈尔滨工业大学中文NLP 工具pyltp对中文语料进行分词处理;使用spacy开源工具对英语语料进分词。
(3)筛选:将对齐句子长度(单词数量)比例大于2.0或小于0.5 的句子去掉;对句子长度大于120 个单词的对齐句子去掉。
(4)BPE 切分:利用subword-nmt 开源工具对维-汉,汉-英等语料进行BPE切分处理;BPE迭代轮数均为50 000。
(5)句子长度区间划分:针对处理后的语料,按照句子长度划分四块数据集(0,10]、(10,20]、(20,30]、(25,xx],对每个数据集进行模型训练,并将对应数据集训练获得模型分别以model[0-10],model[10-20],model[20-30],model[25-xx]表示。
处理后的训练集和验证集统计结果如表1所示。

表1 训练集和验证集统计结果Table 1 Statistical results of training set and validation set
对LDC 语料进行同样的处理,分别为每个不同区间随机选取2 000条句对,共选取了三个测试集,每个测试共有8 000 条句对。具体测试集语料统计结果如表2所示。

表2 测试集语料统计结果Table 2 Statistical results of test set corpus
本实验以BLEU值作为主要的自动评价指标,采用基于字符(character-based)的评价方式计算BLEU 分数(值),对译文未做其他的后处理操作。
2.2 实验环境及设置
本实验使用Centos7.4操作系统,64 GB内存,双CPU Intel®Xeon®Gold 6140 CPU 处理器和2 块NVIDIA P40显卡。本文使用Google开源的Tensor2Tensor[11]工具进行模型训练并重写了模型的数据语料处理部分。为了实验结果的可比性,对所有的系统均使用transformer_base[6]参数,使用单个GPU训练,基准模型训练迭代次数均为20万步,其他子系统训练迭代次数10万步。在解码阶段采用Beam Search策略来进行预测,beam_size大小均为12,解码时长度惩罚因子alpha大小为0.6。当训练结束时,对最后30轮的训练模型参数求平均。
2.3 模型训练与损失分析
按照2.2 节的环境与参数训练了所有的模型,并对训练集和验证集的损失(Loss)及BLEU 值变化进行可视化。图2 是划分策略与基准系统的在训练集上损失变化。可以看出,基线系统随着模型的训练其损失虽然从6 降到了2 但是整体损失范围还是在大于2 的范围内,采用划分策略后的数据集(0,10],(10,20],(20,30],(25,xx]区间的子模型损失效果基本一致,其中[0,10]区间的子模型的训练损失最小。划分策略后的每一个子模型的训练损失小于基准系统,这说明各个子模型训练比基准系统更好。
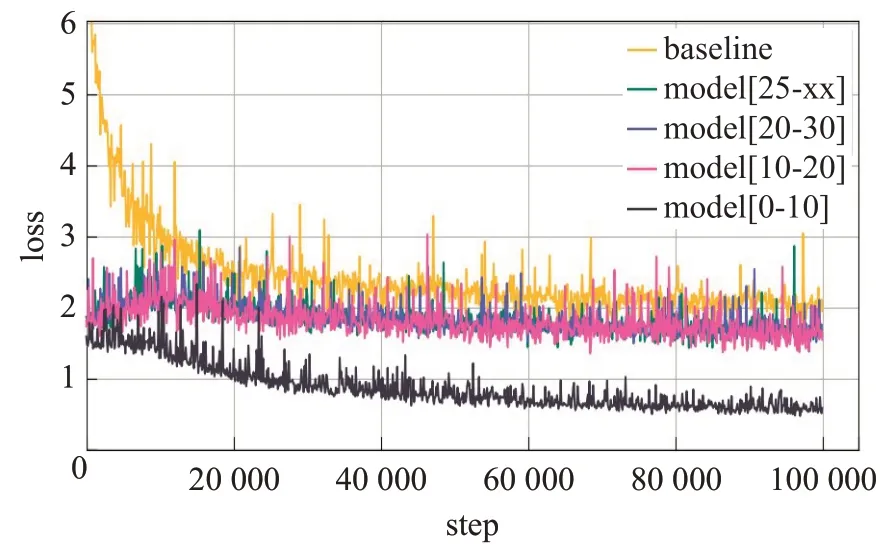
图2 训练集损失变化Fig.2 Change of loss in training set
图3 是各模型在验证集上的BLEU 值变化,图4 是各模型在验证集上的损失变化,根据图3 与图4 可发现,[0,10]区间的子模型的训练损失和BLEU 值出现了较大浮动的变化,因[0,10]区间的子模型普遍包含大量短句,而随着训练次数的增多,损失的大幅度上升,BLEU的大幅度衰减意味着[0,10]区间的子模型出现了过拟合问题。而[10,20]区间的子模型虽然没有[0,10]区间的子模型变化幅度大,但通过图3可观察到随着训练次数的增多同样出现了BLEU 值的衰减。而长句区间的两个子模型则呈现了较好的效果,其中[25,xx]区间的子模型,无论是在损失还是BLEU值效果均明显优于其他模型。
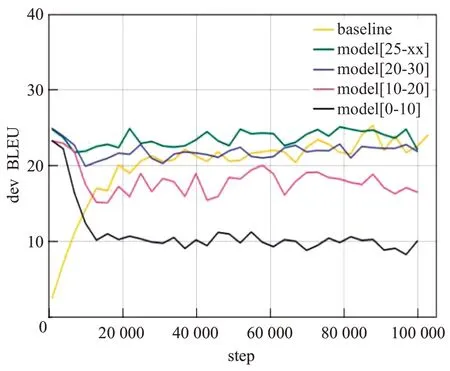
图3 验证集在训练时的BLEU变化Fig.3 BLEU change of validation set during training
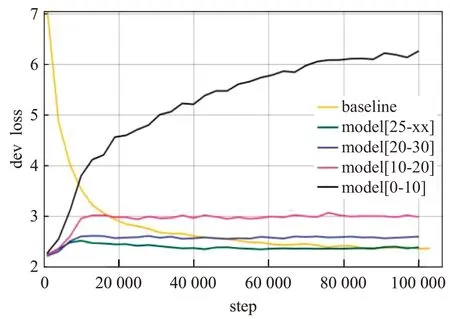
图4 验证集在训练时的loss变化Fig.4 Loss change of validation set during training
通过对图2~图4分析可知,句子长度确实对训练与测试有一定的影响,在训练集中包含大量短句的[0,10]区间子模型效果较为突出,而验证集中面对小规模数据,短句模型会因过多的训练次数出现过拟合,效果衰减严重,包含大量长句[25,xx]区间的子模型呈现了较好的翻译。本文方法用不同的句子长度实验不同的模型翻译,从而提升翻译效果。
2.4 实验结果与分析
2.4.1 三特征(困惑度、句长比与分类器)融合排序
为了验证句子长度比例、困惑度以及分类器概率对候选译文选取的影响,分别对每一项进行实验。
句子长度比例:首先,对各个子模型的译文的长度进行对比并减1;然后,找出最小的结果所对应的index;最后,把相应模型的译文作为翻译结果。
困惑度:首先,计算各个子模型译文的困惑度;然后,排序;最终,选取困惑度较小的对应模型的译文作为翻译结果。这样选取理论上不太可靠,因为短句子的困惑度一般比长句子的小,直接重排序困惑度往往选取的是短句子训练的模型译文。因此可加入句子比例,在先计算句子比例,然后选取同样的句子比例的候选译文,再按照困惑度重排序最终的译文。
分类器概率:对齐分类器概率与句子长度比例来选取译文。
通过尝试以这三个特征权重打分的方式进行融合重排序实验。首先,对所有候选译文计算句子长度;然后,找出对应区间并对应的模型翻译结果赋予40%的权重,计算句子长度比例获取绝对值后乘以20%的权重,按照困惑度排序结果不同级别的候选译文赋予0~20的权重,最终分类器概率乘20%的权重;最后,计算每一项候选译文的权重得分,选取得分最高的作为最终译文。具体的实验结果如表3 所示。可以看出该方法较Base line提升0.4~0.6 BLEU。
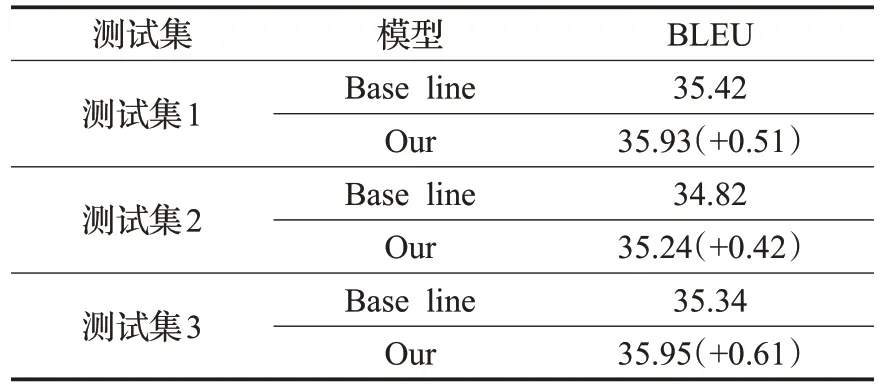
表3 按三特征融合重排序Table 3 Reordering by three special features fusion
2.4.2 句长边界划分后模型的融合
实验中,在不同测试集上分别对基准系统与按句子长度划分策略的翻译系统在Transformer模型上进行了对比实验,句长边界划分后模型的融合实验结果如表4所示。从实验结果中可以发现,该方法提出的系统翻译效果明显优越于基准模型。其中,在测试集1上跟基准模型翻译结果相比,提升了1.27 BLEU值;在测试集2上提升了1.21 BLEU值;在测试3上提升了1.27 BLEU值。可见,本文提出的集成策略的系统明显提高了翻译质量。
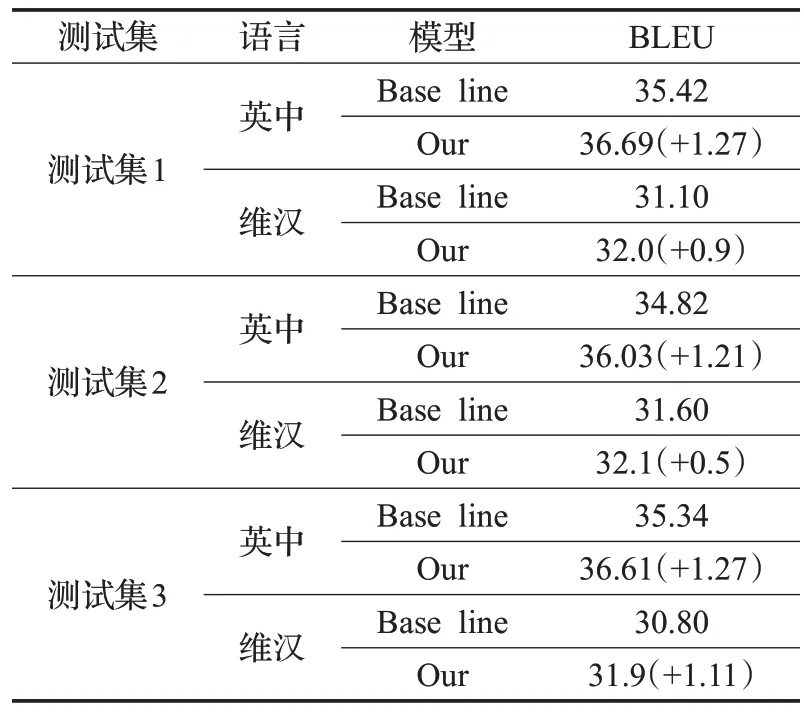
表4 Transformer模型翻译结果Table 4 Transformer model translation result
另外对基准模型,集成系统以及各个子系统分别在三个测试集上进行翻译测试。翻译实验结果如图5所示。
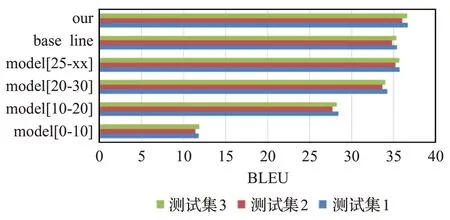
图5 不同句长区间模型在不同测试集的BLEU得分Fig.5 BLEU scores of interval models of different sentence lengths in different test set
3 结论与下一步工作
本文提出了一种按句子长度融合策略的神经机器翻译方法,并使用两种不同得方法得到最终译文。根据图5可发现:
(1)在Transformer 模型上,按句子长度划分的融合集成系统翻译结果在维吾尔语-汉语机器翻译任务中和中文-英文机器翻译任务中明显优于其他子系统以及基准模型的翻译结果。
(2)通过在100 万句对的维汉数据和700 多万句对的中英数据中可发现,句子长度划分后模型的融合方法在资源丰富的平行数据中效果更佳(因此在后续实验中只选用了英中任务进行验证介绍)。
(3)句子长度区间在[25,xx](大于25的)子模型翻译效果相比于基准模型翻译效果几乎持平(平均提高了0.34 BLEU 值)。这说明,长句子训练的模型各方面比其他子模型翻译效果好。
(4)数据集句子长度区间在(0,10]、(10,20]、(20,30]的子模型效果相比基准模型翻译效果明显不好,尤其是区间[0,10]的子模型翻译效果极差,发现该模型对长句子的翻译效果较差,平均译文长度跟训练集平均句长几乎相同,这说明在此短句子数据对机器翻译效果带来了严重影响,短句子训练的模型在短句子上翻译效果最佳。
在利用特征融合进行重排序[12],虽然增加了过程的复杂程度,但是翻译质量得到了提升。通过实验证明,在语料充足的情况下两种方法都能使机器翻译质量得到有效的提升。本文提出的方法与基准模型相比对硬件资源、GPU显存的要求较高,因此,今后将对模型的压缩[13]与改进方面继续探索研究[14]。
猜你喜欢
中国神经再生研究(英文版)(2022年2期)2022-08-08
通信技术(2021年12期)2022-01-25
计算机系统应用(2021年2期)2021-02-23
电子技术与软件工程(2019年18期)2019-11-18
计算机应用与软件(2018年9期)2018-09-26
小天使·二年级语数英综合(2017年12期)2017-12-05
电子技术与软件工程(2017年14期)2017-09-08
小天使·二年级语数英综合(2017年3期)2017-04-01
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
航天返回与遥感(2014年5期)2014-07-31
