
DFSMN-T:结合强语言模型Transformer的中文语音识别
2022-05-15 06:35胡章芳唐珊珊明子平姜博文
计算机工程与应用 2022年9期
胡章芳,蹇 芳,唐珊珊,明子平,姜博文
重庆邮电大学 光电工程学院,重庆400065
在语音识别发展领域,研究学者们致力于将语音信息尽量完整准确地转化成文本信息。语音识别的关键在于声学模型和语言模型两部分。在深度学习兴起应用到语音识别领域之前,声学模型已经有了非常成熟的模型体系,并且也有了被成功应用到实际系统中的案例。比如经典的高斯混合模型(Gaussian mixed model,GMM)和隐马尔可夫模型(hidden Markov model,HMM)[1]等。神经网络和深度学习兴起以后,循环神经网络(recurrent neural network,RNN)[2-3]、长短期记忆网络(long short-term memory,LSTM)[4]、注意力机制(attention)[5-6]等基于深度学习的声学模型和语言模型将此前各项基于传统声学模型和传统语言模型的识别案例错误率降低了一个级别。近年来,也有很多学者尝试建立端到端语音识别系统,比如百度提出了一种可以识别英语和普通话的端到端的深度学习方法[7],胡章芳等将残差网络与双向长短时期记忆网络相结合,构建端到端语音识别系统[8]。
在声学模型领域,Zhang等提出了新一代语音识别模型前馈序列记忆神经网络(feedforward sequential memory networks,FSMN)[9],紧凑前馈序列记忆神经网络(compact FSMN,CFSMN)[10]以及深度前馈序列记忆神经网络(deep FSMN,DFSMN)[11]。其中FSMN 是在标准的隐含层中使用类的内存块前馈神经网络,并在语言建模任务上的实验结果表明FSMN 可以有效地学习长期历史;CFSMN是在FSMN基础上增加了投影矩阵,在语音识别交换机任务中,所提出的CFSMN 结构可以使模型规模缩小60%,学习速度提高7 倍以上,而在基于框架级交叉熵准则的训练和基于mini 的序列训练方面,该模型仍能显著优于目前流行的双向LSTMs;而DFSMN在CFSMN的基础上增加了跳跃连接(skip connection),在中文语音识别任务上达到了85%的识别准确率。在语言模型领域中,Ashish等提出了基于注意力机制的新模型Transformer,并在英语数据集上进行了验证,结果显示比Attention 模型效果更好[12];Zhou 等研究了将音节和音素作为Transformer 模型的建模单元,在序列到序列语音识别系统上进行实验验证并得出基于音节的Transformer 模型优于基于ci 音素的对应模型,且与基于CTC-attention 的联合编解码网络的字符错误率不相上下[13]。
本文以DFSMN作为声学模型,引入Transformer作为语言模型建立语音识别系统。在该系统中,将采用CNN 来提取80 维的Fbank 特征,并将CTC loss[14]作为DFSMN 模型训练的损失函数,采用Adam(adaptive moment estimation)优化器进行优化。在语言模型模块,将以文献[15]中的Transformer 模型作为基础模型,研究Transformer 不同参数对其模型性能的影响,针对Transformer 计算量大的问题进行改进,训练出最优的Transformer模型与DFSMN模型相结合进行识别任务。
1 相关工作
语音识别系统包括声学模型和语言模型,在传统的语音识别系统中,通常采用DFSMN 作为声学模型,N-gram作为语言模型。
1.1 DFSMN模型
在CFSMN 结构中,因为每个CFSMN 层中包含了较多的子层,一个层中包含了4 个CFSMN 子层,2 个DNN 层的CFSMN 网络总共需要12 层结构。若通过直接增加CFSMN 层的方法来设计更深的CFSMN 网络,网络可能会出现梯度消失的问题。
基于上述问题,DFSMN 被提了出来。DFSMN 在CFSMN 的记忆模块之间添加了跳层连接,使低层的记忆可以直接流入高层的记忆模块中。在反向传播的过程当中,高层的梯度也会直接流入低层的记忆模块中。因此即使使用了更深的层数,也避免了梯度消失的情况。在特征提取上,DFSMN 结合低帧率LFR(low frame rate)[16],使得模型尺寸更小,延迟也更低。实验结果表明DFSMN 是用于声学模型的BLSTM[17]强有力替代方案。DFSMN的结构如图1所示。
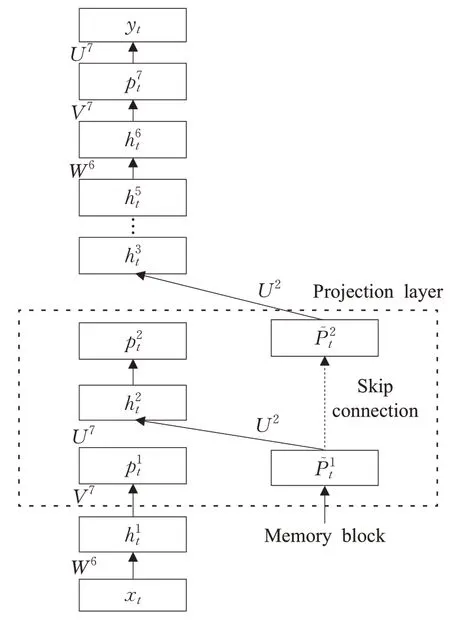
图1 DFSMN结构Fig.1 DFSMN structure
DFSMN的参数更新公式为:
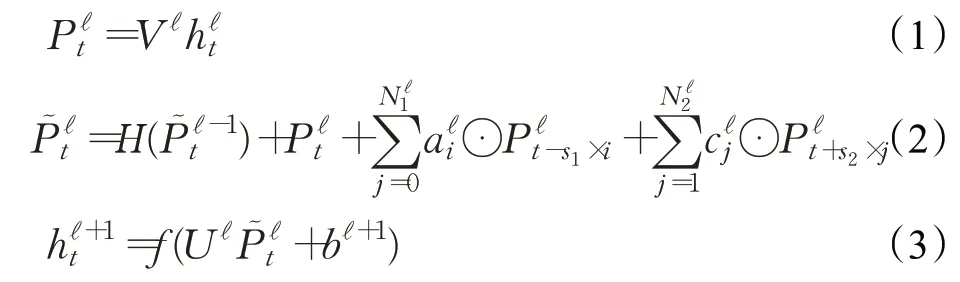
1.2 N-gram模型
N-gram 是传统语音识别中最常用到的语言模型[18-19]。N-gram指文本中连续出现的n个语词。n元语法模型是基于(n-1)阶马尔可夫链的一种概率语言模型,通过n个语词出现的概率来推断语句的结构。
当n=1时,一个一元模型(Unigram model)表示为:
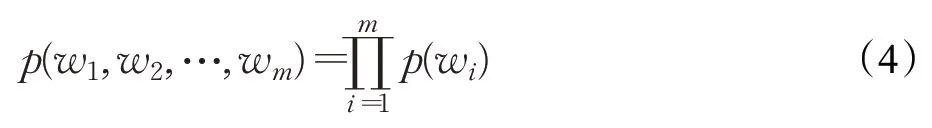
当n=2 时,一个二元模型(Bigram model)表示为:
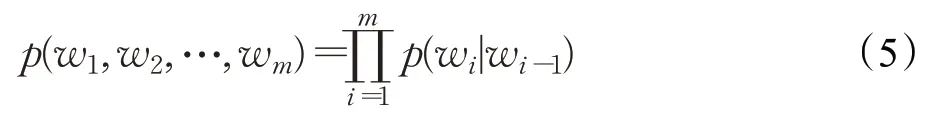
当n=3 时,一个三元模型(Trigram model)表示为:
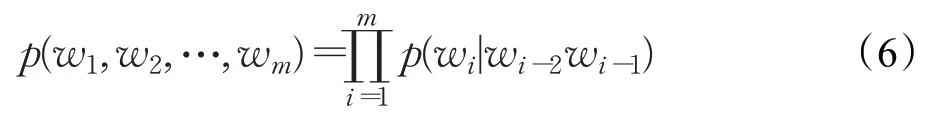
对于N-gram模型而言,可以表示为:
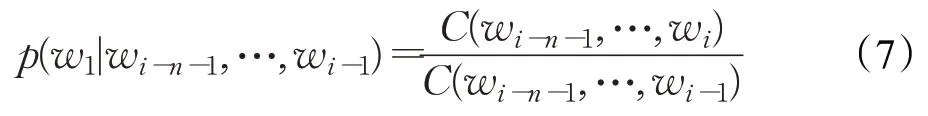
其中,C(w1,w2,…,wn)表示N-gram 中w1,w2,…,wn在训练语料中出现的次数,m是语料库的总字数。
2 引入Transformer的语音识别系统
已知一段语音信号,处理成声学特征向量后表示为X=[x1,x2,x3,…],其中xi表示一帧特征向量,可能的文本序列表示为W=[w1,w2,w3,…],其中wi表示一个词。语音识别的目的就在于求出。P(W|X)表示为:
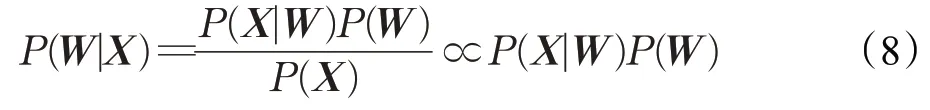
其中,P(X|W)称之为声学模型(acoustic model),P(W)称之为语言模型(language model),二者对语音语言现象刻画得越深刻,识别结果越准确。所以大多数研究都把语音识别分为声学模型和语言模型两部分,然而在传统语音识别系统中,往往将注意力集中在声学模型的改进上,忽略了语言模型N-gram存在词条语义相似性,参数n过大导致计算量太大等问题。因此本文引入强语言模型Transformer,结合DFSMN 构建中文语音识别系统,系统结构如图2所示。
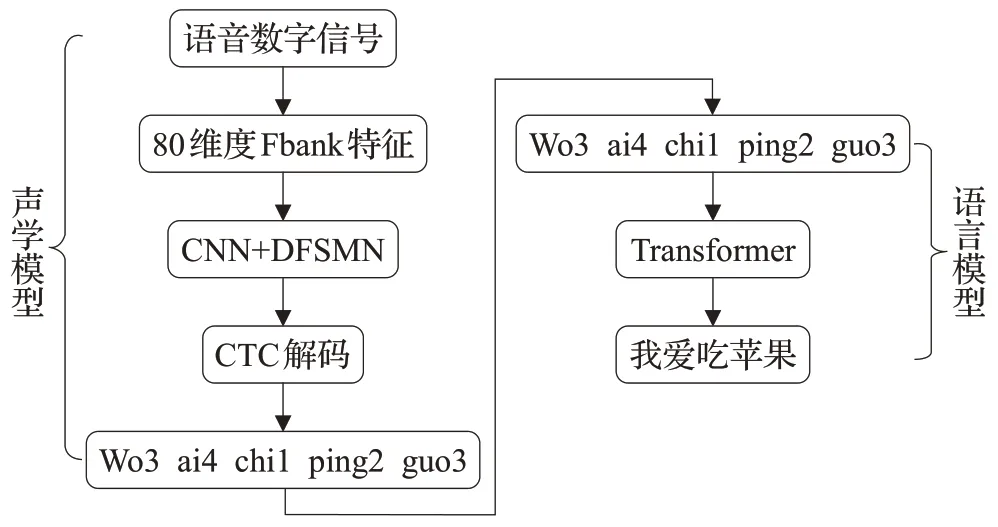
图2 引入Transformer的中文语音识别系统结构Fig.2 Chinese speech recognition system architecture with Transformer
Transformer 能学习到输入序列与输出序列之间的对应关系,其结构包括编码器和解码器两个主要模块,编码器编码时间序列,解码器结合编码器输出和上一时间步长的输出来生成下一时间步长的输出,直到生成结束符为止。Transformer模型结构如图3所示。
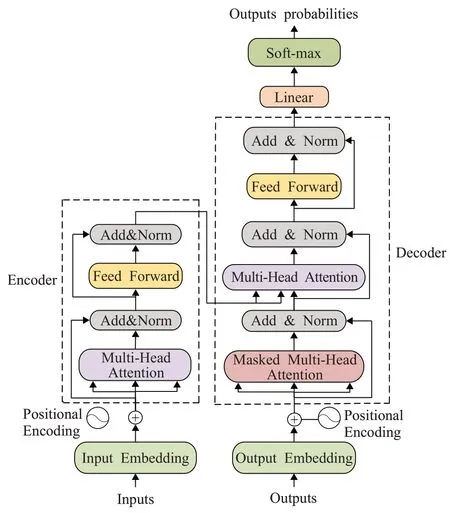
图3 Transformer模型结构Fig.3 Transformer model structure
2.1 编码器
在进入编码器之前,要先进行位置编码字符向量嵌入和字符位置向量嵌入,将两向量相加得到相同维度的向量作为输入,目的在于给输入添加字符顺序信息,让模型能够学习到字符顺序关系。编码器旨在对原始信息进行编码表示,编码表示能够较完全地体现出该字符序列的语义信息。编码器由N个编码单元组成,每个编码单元具有完全相同的结构。编码器包括多头自注意力层(multi-headed attention)、求和与归一化(add &normalization)、前馈神经网络(feed-forward)三个基本组件。其中,多头自注意层利用多个自注意力,从不同的信息维度上来提取字符的向量表示。
2.1.1 位置编码
由于Transformer 不包含递归和卷积,为了让模型利用序列的顺序,必须注入一些关于序列中记号的相对或绝对位置的信息。因此在编码器和解码器堆栈底部的输入嵌入中添加“位置编码”。位置编码与嵌入具有相同的模型维数,因此两者可以相加。位置编码采用不同频率的正弦和余弦函数,表示为:
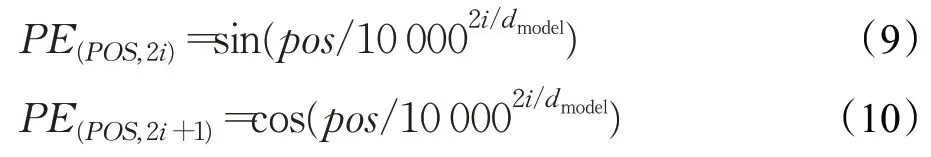
在上式中,pos是位置,i是维数。位置编码的每一维对应一个正弦信号。波长以几何级数的形式从2π增长到10 000·2π。
2.1.2 缩放点积注意力机制
在注意力函数的使用中,乘性函数和加性函数在理论上复杂度相同,然而实际应用中,乘性函数得益于高度优化的矩阵乘法代码的计算,使得乘性函数计算速度更快,更节省空间。缩放点积注意如图4所示。
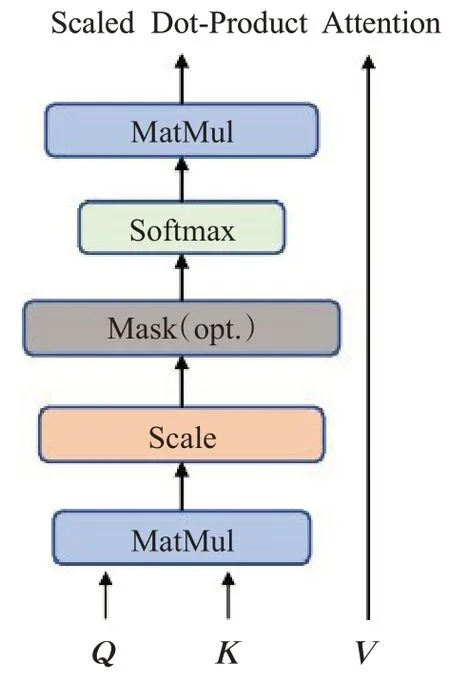
图4 缩放点积注意力机制Fig.4 Scaling dot product attention mechanism
输入由维度为dk的查询向量q和键向量k以及维度为dv的值v组成。接着计算查询与所有键的点积,再除以,并应用softmax 函数来获得这些值的权重。在实践中,将同时计算一组查询的注意力函数,这些查询被打包到一个矩阵Q中,键和值也被打包到矩阵K和V中。计算输出矩阵表示为:
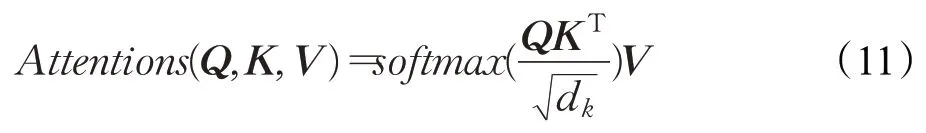
对于较大维度的值v,点积的大小也会变大,从而使softmax函数陷入具有极小梯度的区域。为了抵消这个影响,故在式(11)中需要除以。
2.1.3 多头注意力机制
多头注意力机制如图5所示。在该步骤中,将对每一个投射模块中的查询、键和值并行执行注意力函数,生成dv维的输出值。它们被连接起来并再次投射,从而得到最终的值。
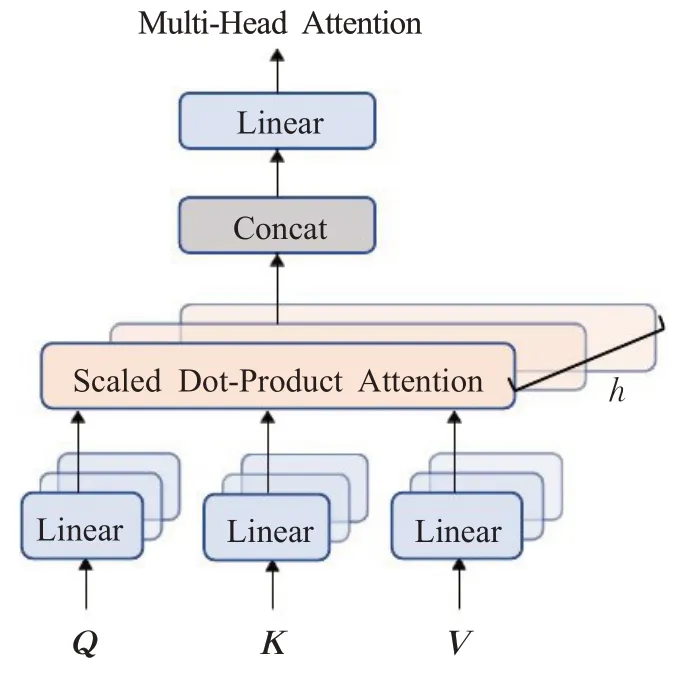
图5 多头注意力机制Fig.5 Multi-headed attention mechanism
多头注意力机制使模型能够在不同的表示子空间中,在不同的位置共同关注信息。如果只有一个注意力头,则会抑制这种情况。多头注意力机制表示为:
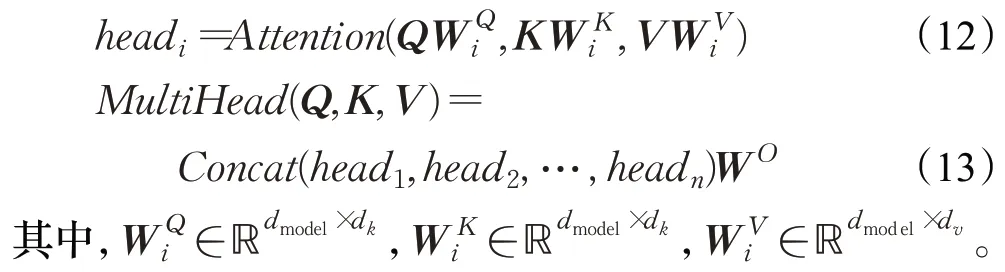
2.1.4 前馈神经网络
在编码器和解码器的子层中,还包括前馈神经网络层。该层包括矩阵线性变化Linear 层和Relu 非线性激活。该层网络可表示为:
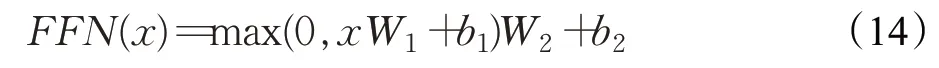
2.1.5 残差连接和归一化
每一个子层之后都会接一个残差连接和归一化层。其中,残差连接层避免了梯度消失的问题,而归一化层通常采用BN(batch normalization)。BN 的思路在于对每一层的每一小批数据上进行归一化,把输入转化为均值为0 方差为1 的数据,防止经过多层前向计算后数据偏差过大,造成梯度问题。
在多头自注意力层、求和与归一化层、前馈神经网络这三个不同层的结合下,最终得到编码器的输出。
2.2 解码器
解码器与编码器的结构类似,但是比编码器多了一个掩盖多头自注意力层。这个层包括了第一层掩盖多头自注意力层和第二层多头自注意力层。第一层使用掩盖多头自注意力层的原因是在预测句子的时候,当前时刻是无法获取到未来时刻信息的。在该层中,q是来自于上一位置Decoder 的输出,而k和v则来自于编码器。编码器可以并行计算,但是解码器类似于RNN 网络,需要一步一步去解码,最终输出对应位置的输出词的概率分布。
2.3 基于Hadamard矩阵滤波的注意力计算
针对Transformer计算复杂度高,且在训练过程中存在过拟合的问题,本文提出一种基于Hadamard 矩阵滤波的注意力权值计算方法。该方法应用于softmax 层,通过设置阈值对经过softmax归一化的注意力权值矩阵进行滤波,低于阈值的权值,由于对输出影响较弱,强制置为0,而高于阈值的分数则不予以改动。在多头注意力的计算过程中,该方法能够有效降低后续计算的参数量,从而减少模型的训练时间,增加解码速度,并且在训练不同的数据时,不同的参数丢弃后训练的模型会增加网络的泛化能力。Hadamard矩阵滤波位置如图6所示。
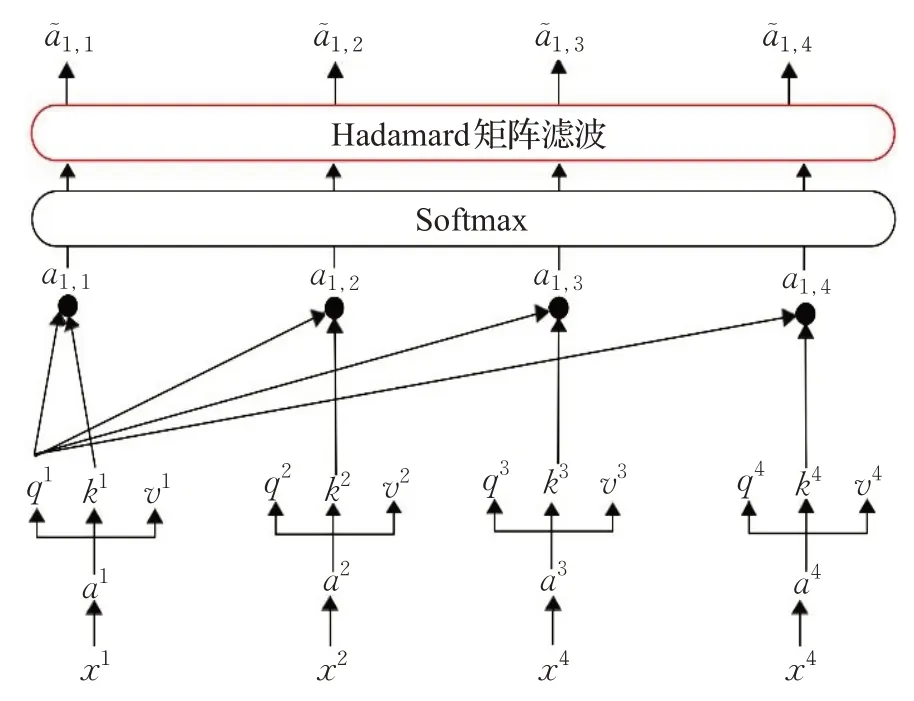
图6 Hadamard矩阵滤波位置Fig.6 Hadamard matrix filtering position
在图5中,每个单词创建三个向量,并通过词嵌入和每个向量对应的权重矩阵相乘所得。即:


得到q、k、v的值后,则要拿每个查询向量q去对每个键向量k做注意力,计算上下文对当前字符的注意力初始分数,即:

增加Hadamard矩阵滤波后,公式表示为:
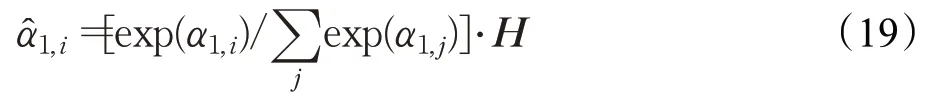
公式(11)更新为:
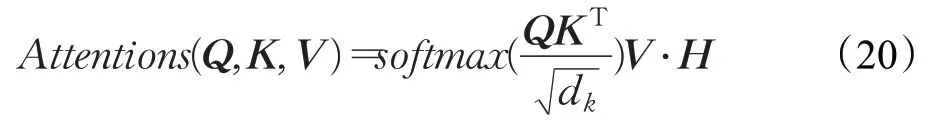
改进后自注意力计算流程如图7 所示,在该图中,矩阵H是由矩阵A经过阈值筛选后生成的Hadamard矩阵,矩阵A中值大于等于阈值T则矩阵H中相对应位置处的值为1,而A中值小于阈值T则H中相对应位置处的值为0。
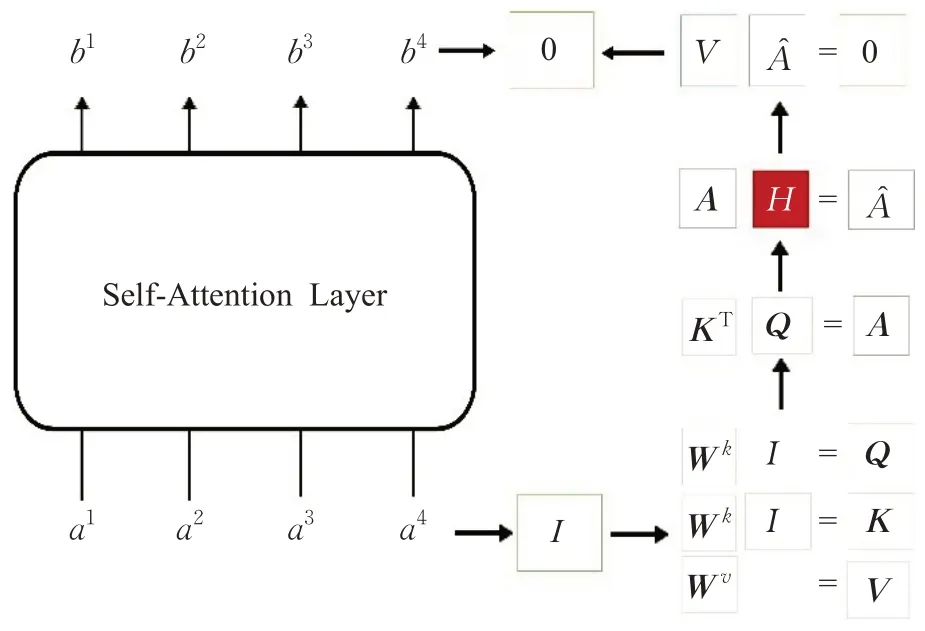
图7 改进后自注意力计算流程Fig.7 Improved self-attention calculation process
3 实验
3.1 前期准备
3.1.1 声学模型参数
声学模型使用的输入是具有16 kHz 采样率的单声道音频数据,结合低帧率LFR,通过一个固定的10 ms帧位移的25 ms汉明窗口进行分析,并利用80个mel滤波器组提取80 维的log mel fbank 特征。在卷积层中,根据输入的音频数据对其进行卷积操作,整个卷积包括1个卷积层和3个CNN层,以作为DFSMN层的输入。在DFSMN结构中,一共有6层网络,模型深度为512维,学习率为1E-4,dropout 为0.5。使用CTC 作为损失函数,对于一对输入输出(X,Y)来说,CTC的目标是将下式概率最大化:
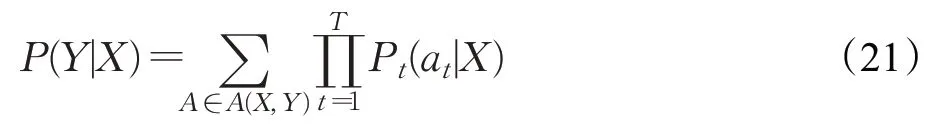
在对模型进行预测时,本文采用了Beam search 算法,并将宽度参数设置为10,即在每个时间t输出时,不同于贪婪算法只找概率最高的,而是找最高的10 个概率作为下一次的输入,依次迭代。对于优化器的选择,本文采用了Adam 优化器作为模型优化器,Adam 优化器本质上是带有动量项的RMSprop(root mean square prop)优化器,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。
3.1.2 语言模型参数
在Transformer 语言模型结构中,将以特征维度为256,批处理大小为40,多头注意力数为8,隐藏节点为512,学习率为1E-3,dropout 为0.3 作为初始参数设定。在进行训练时,采用标签平滑化处理(label smothing)以防止过拟合,表示为:

其中,y′为标签平滑操作后的样本标签,ε为平滑因子,u是人为引入的一个固定分布,并且由参数ε控制相对权重。
语言模型的损失函数则为预测结果与平滑值的交叉熵。表示为:
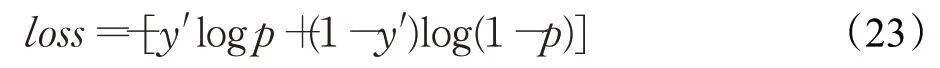
3.1.3 数据集
为了防止模型过拟合,提高模型的泛化能力,对于识别任务,本文采用的数据集包括Aishell-1[20]、Aidatatang、Magicdata、Thchs30[21]这四个中文数据集,总计1 163 h,包括995 452条语句,其中训练集863 845条,验证集50 694 条,测试集80 913 条,训练集与验证集及测试集的比例为86∶5∶9。
Aishell-1 数据集是北京希尔贝壳科技有限公司出版的中文语言公开语料库,由来自中国不同口音地区的400 人参加录音,总共178 h。Aidatatang 数据集是北京大唐科技有限公司提供的免费中文普通话语料库,该语料库包含200 h 的声学数据,由来自中国不同口音地区的600 人参加录制,数据库分为训练集、验证集和测试集,比例为7∶1∶2。Magicdata 数据集包含755 h 的语音数据,其中大多数是移动记录的数据,邀请来自中国不同口音地区的1 080 名演讲者参加录制,该数据库训练集、验证集和测试集的比例为51∶1∶2。Thchs30是清华大学语言技术中心(CSLT)发布的开放式中文语音数据库,总时长超过30 h。
3.2 实验结果
针对本文提出的DFSMN结合语言模型Transformer的语音识别系统,实验围绕Transformer的影响因素、改进后的Transformer模型及语音识别系统的验证三方面展开。在针对Transformer 的实验中,训练语料为相应开源语音的抄本及对应中文拼音,CER指的是拼音转汉字结果的字符错误率;在针对语音识别系统的实验中,CER指的是语音转写为中文的字符错误率。
3.2.1 Transformer的影响因素
对于Transformer 模型结构会受到哪些因素的影响,本文首先做了以下工作:以初始参数化的Transformer结构作为基础结构,分别以学习率lr、批处理大小batch_size、多头的数目num_heads以及num_block4 个参数作为变量进行实验测试,采用控制变量法对比不同参数取值对准确率和解码速度的影响。其中,学习率参数以L表示,批处理大小batch_size以B表示,多头的数目num_heads以H 表示,num_block以K 表示。不同参数取值的Transformer结构如表1所示。
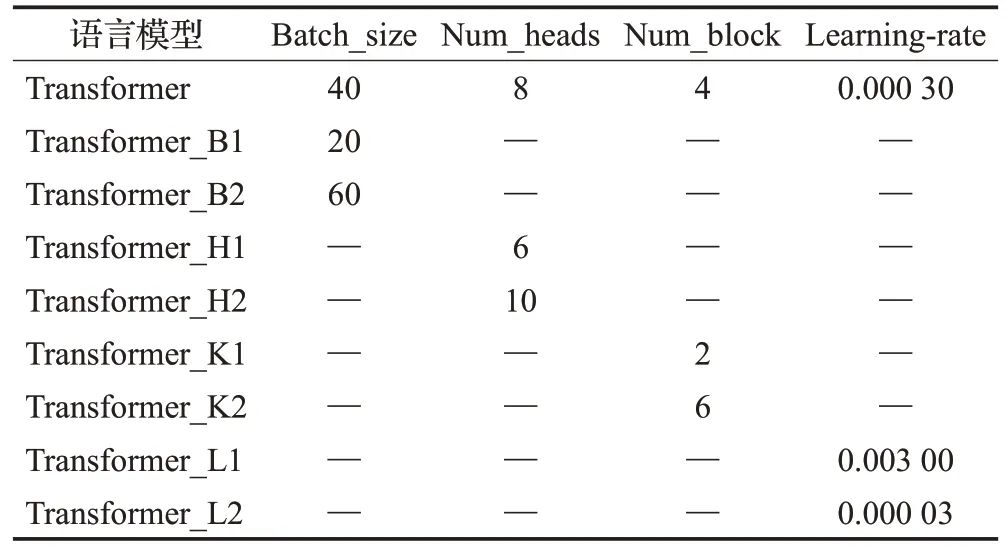
表1 不同参数取值下的Transformer结构Table 1 Transformer structure for different parameter values
在表1 中,Transformer 表示未经改动的初始参数模型,Transformer_B、Transformer_H、Transformer_K、Transformer_L 表示在初始参数模型基础上分别对批处理大小、多头的数目、num_block以及学习率进行了改变。对上述几个不同结构的Transformer进行训练,并在Aishell-1、Aidatatang、Magicdata、Thchs30 四个中文数据集上测试字符错误率及解码时间,实验结果如表2所示。
从表2可以看出,对比初始参数下的Transformer测试结果,可以得出以下结论:
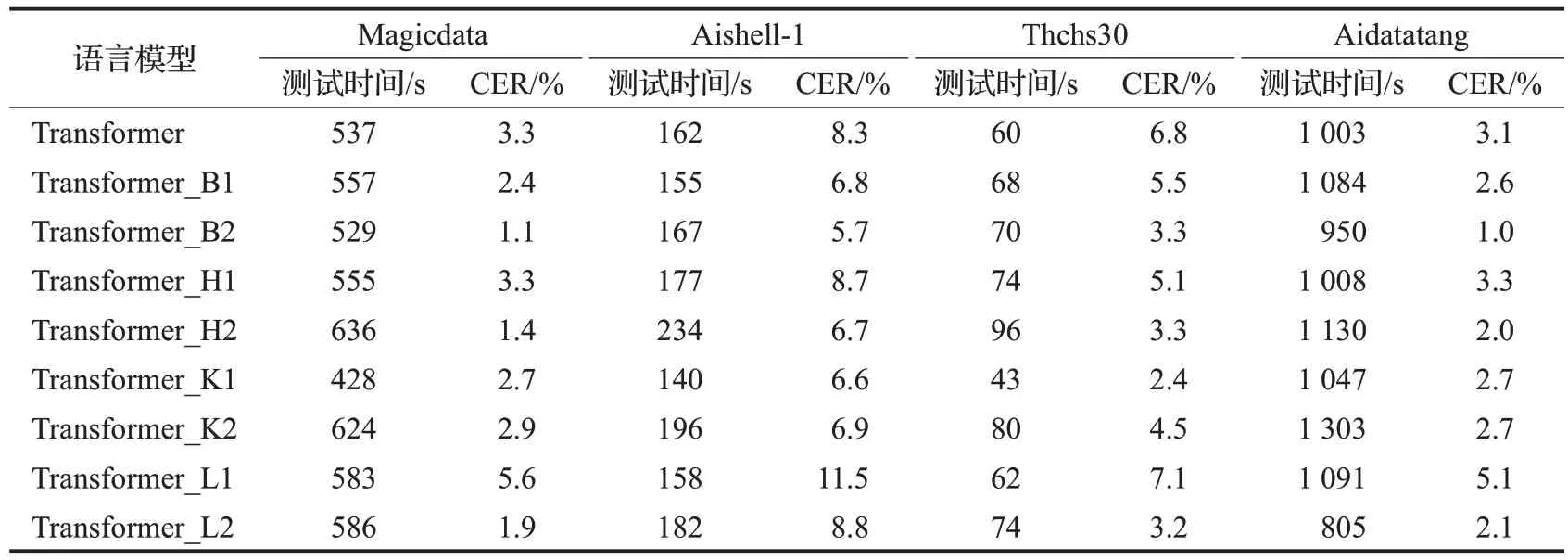
表2 不同结构下Transformer的测试时间及CERTable 2 Test time and CER for Transformer with different configurations
(1)减小batch_size会使得测试时间增长,解码速度变慢,但是字符错误率平均降低了1.1%;增加batch_size不仅使测试时间减少,解码速度变快,并且字符错误率也平均降低了2.6%。
(2)减少多头的数目会使测试时间增长,解码速度变慢,在字符错误率上并无明显变化;增加多头的数目会使测试时间增长,解码速度变慢,但是字符错误率平均降低了2%。
(3)减少num_block会使测试时间减少,解码速度变快,并且字符错误率平均降低了1.8%;增加num_block会使测试时间增长,解码速度变慢,但是字符错误率平均降低了1.1%。
(4)增加学习率会使测试时间增长,解码速度变慢,并且字符错误率平均提高了2.0%了;减少学习率会使测试时间增长,解码速度变慢,但是字符错误率平均降低了1.4%。
由上述实验可知,学习率lr、批处理大小batch_size、多头的数目num_heads以及num_block这4 个参数对Transformer模型的解码速度及识别准确率都有一定的影响。其中,在模型训练的过程中,特征维度通常取多头数目的立方。
3.2.2 改进后的Transformer
基于上述实验结果,选取学习率lr=0.000 03,批处理batch_size=60,多头数目num_heads=10,num_block=2作为改进前Transformer模型参数。为了与原始Transformer模型进行区分,将该模型记为Transformer_BHKL,表示在原始Transformer 模型上对四个参数都进行了变动。经过在4 个数据集上大量实验后,发现在阈值分别为T1=1E-7,T2=1E-6,T3=1E-5时实验效果最好。将阈值为T1、T2、T3时的Transformer模型分别记为Transformer_BHKLT1、Transformer_BHKLT2、Transformer_BHKLT3进行实验对比分析,实验结果如表3所示。
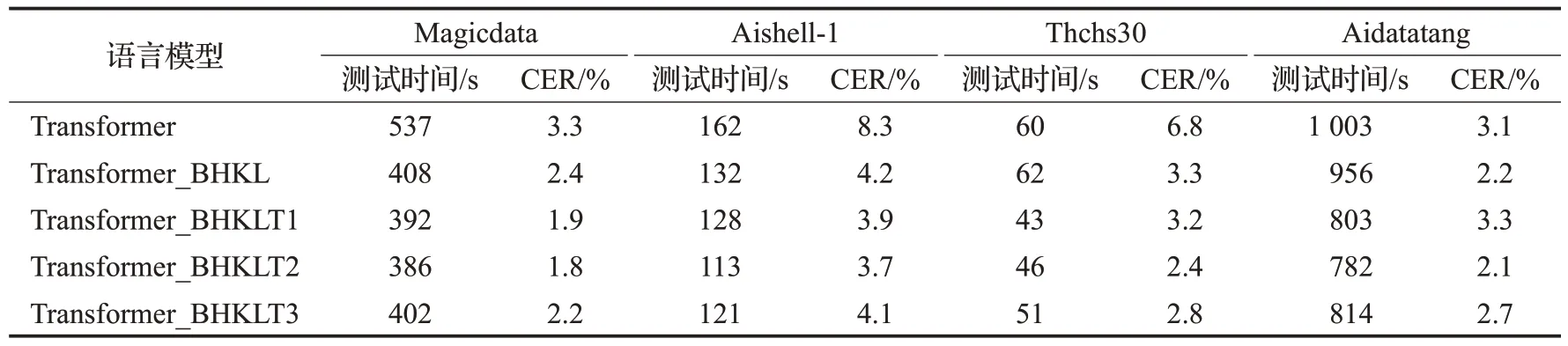
表3 改进后Transformer在数据集上的测试时间及CERTable 3 Test time and CER of improved Transformer on dataset
在表3中,Transformer_BHKL的实验结果验证了上述对Transformer模型的影响因素分析;对比Transformer_BHKL和增加阈值后的Transformer模型实验结果,当阈值为1E-6 时,改进后Transformer 模型在各个数据集上的识别错误率和识别速率都达到了最优,验证了对Transformer增加参数丢弃层后,模型的识别速率及识别错误率都有所降低。
3.2.3 语音识别系统的验证
为了验证改进Transformer 模型在语音识别系统中的性能,将4 个数据集分别在DFSMN 结合初始Transformer 模型,DFSMN 结合Transformer_BHKLT 模型上进行实验验证,测试结果如图8所示。
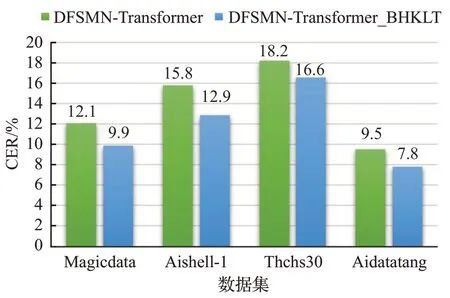
图8 4个数据集在模型改进前与改进后的结果Fig.8 Results for 4 datasets before and after model improvement
由图8 中4 种不同数据集的验证结果表明,本文构建的Transformer 结合DFSMN 语音识别系统在不同的数据集上都有良好的性能,在改进Transformer模型后,4种不同数据集上的字符错误率都有所降低,体现了该系统识别结果中字符错误率较低的同时也有较强的泛化能力。
为了验证声学模型DFSMN 结合改进语言模型Transformer 的语音识别系统的优越性,将该系统与BLSTM系统、ResNet-BLSTM-CTC系统、CFSMN-3gram系统、DFSMN-3gram 系统做对比,对比实验结果如表4所示。
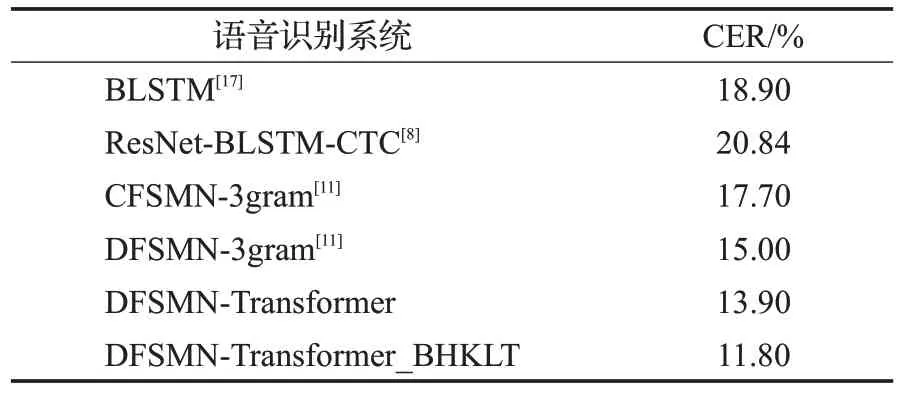
表4 不同语音识别系统的CERTable 4 CER of different speech recognition models
在表4中的数据表明,本文提出将声学模型DFSMN结合语言模型Transformer构建的语音识别系统相较于其他语音识别系统,在识别准确率上展现了一定的优越性,经过改进语言模型Transformer 后构建的语音识别系统较未改进前在识别准确率上也有所提高。
4 结束语
本文引入强语言模型Transformer,将其和强声学模型DFSMN相结合,建立了CNN-DFSMN-CTC-Transformer新型语音识别系统,并针对Transformer计算复杂度高,容易过拟合及泛化能力不足的问题提出了一种基于Hadamard 矩阵滤波的注意力计算方法。实验结果表明,新型语音识别系统总体性能优于某些现有语音识别系统,改进后的Transformer解码速度有明显提升。
猜你喜欢
汉字汉语研究(2020年2期)2020-08-13
家庭影院技术(2020年6期)2020-07-27
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
新课程·上旬(2019年1期)2019-03-18
家庭影院技术(2019年1期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年10期)2018-11-02
教师·中(2017年3期)2017-04-20
