
基于XGBoost的采煤机健康状态评估方法研究
2022-05-13 11:41:54曹现刚陈瑞昊李彦川伍宇泽
煤炭工程 2022年5期
曹现刚,陈瑞昊,李彦川,伍宇泽,岳 东
(1.西安科技大学 机械工程学院,陕西 西安 710054;2.陕西省矿山机电装备智能监测重点实验室,陕西 西安 710054;3.陕西陕煤铜川矿业有限公司,陕西 铜川 727000)
采煤机作为多部件复杂系统,在运行过程中由于截割煤岩时受到变工况、环境噪声等各种复杂因素影响,采集到的振动、电流等监测信号往往难以提取关键信息[1]。复杂设备的健康状态评估方法根据不同的评估原理,大致可以分为以下三类:基于经验的健康状态评估[2]、基于模型的健康状态评估[3]和基于人工智能的健康状态评估[4]。其中,基于经验的评估方法包括:灰色理论法、模糊综合评判法[5]、云模型理论[6]、层次分析法、D-S证据理论;基于模型的评估方法主要包括失效物理模型、故障树等[7,8];基于人工智能的评估方法主要有:支持向量机[9]、马尔科夫理论、贝叶斯网络、神经网络[10-12]等。
目前国内外设备健康状态评估研究多集中于电力[13,14]、导弹[15]、航空航天[16,17]等领域,针对煤矿设备的状态评估研究并不多见;在评估对象上主要集中于对单一或者简单部件系统进行状态评估,对于多部件复杂系统[18]的健康状态评估研究成果较少。采煤机健康状态评估工作是一个多层次、多属性评估过程,基于模型的评估方法建模困难求解异常复杂,而基于经验的评估方法受主观因素影响较大,各部件、指标权重难以确定。基于传统神经网络的评估方法可解释性较差,易陷入局部极小值。此外,大多数健康状态评估方法无法针对冗余性、突变性、不平衡数据集,导致评估效率较低。针对以上问题,本文提出了XGBooost的采煤机健康状态评估方法研究,首先筛选出相关性较低的参数数据,构建采煤机健康状态评估指标体系;采用XGBoost算法对采煤机健康状态进行评估,调优模型确定关键参数,通过实验验证,得到XGBoost算法的评估结果和混淆矩阵为采煤机健康状态评估工作提供依据,对采煤机健康管理具有一定意义。
1 采煤机健康状态评估指标构建及运行状态划分
1.1 采煤机状态量选取
本文主要研究电牵引双滚筒式采煤机,双滚筒采煤机可分为牵引部、截割部、电气系统和辅助装置。双滚筒电牵引采煤机各部位名称如图1所示。
根据采煤机结构组成和工作方式,同时考虑采煤机实际可安装部位,分析得到采煤机主要运行状态监测数据。采煤机的各个关键部件或部位均安装对应的传感器对其进行实时监测,保证采煤机的健康状态。采煤机需要监测的部分状态参数见表1。

1—截割滚筒;2—摇臂;3—截割电机;4—牵引电机;5—油泵电机;6—液压单元;7—电气控制箱;8—变频箱;9—电磁阀柜;10—变压器箱;11—牵引减速箱;12—调高调斜装置;13—破碎机构;14—破碎电机图1 电牵引采煤机基本结构

表1 采煤机的部分状态监测参数
1.2 采煤机状态参数相关性分析
采煤机运行过程中各部件监测的状态参数间存在复杂的关联关系,因此需要找出这些关联数据,去除数据的冗余性和相关性,为采煤机健康状态评估工作做准备。单一的相关系数并不能客观地表征数据变量间密切的相关关系,因此本文选择综合相关系数,即将Spearman相关系数、Person相关系数进行综合用于表征采煤机状态数据变量间的相关关系。
Spearman相关系数计算公式如下:
式中,ρ1为两变量间的Spearman相关系数;N为样本容量;di为变量间秩次差值。
Person相关系数ρ2的计算公式如下:
式中,cov(X,Y)为X和Y的协方差;σX、σY为X和Y的标准差;μX、μY为变量X和Y的平均值。Person相关系数一般在-1到1之间取值,当前提条件一定的情况下,一般使用绝对值表示两参数变量间的相关性。
状态参量间的综合相关系数用rxy表示,则rxy为:
通过计算状态参数间的综合相关系数rxy,筛选出状态评估指标,构建出采煤机健康状态评估体系。采用rxy表示状态监测参数x和y之间的综合相关系数,两状态参数间的相关系数rxy的值与对应的两个变量之间的相关性描述见表2。

表2 综合相关系数rxy的绝对值与对应的两个变量间关系
本文以采煤机牵引部各监测参数为例,完成监测参数间相关性分析,进而完成采煤机状态评估指标筛选。为了分析采煤机状态监测参数和指标间的相关性,选取正常工况下的采煤机牵引部8项状态参数序列数据,包括牵引电机温度、牵引电机转速、牵引电机振动、牵引电机电流、冷却水压、牵引电机转矩、油缸内油压、牵引减速箱温度等八项参数,分别计算这八项参数之间的综合相关系数,将相关度高于阈值0.6的几个参数用同一指标参数替代,减少监测参数间的冗余属性,通过相关性分析得到的相关性热力图结果如图2所示。

图2 牵引部状态参数间综合相关系数热力图
由图2可知,C1牵引电机温度与C2牵引电机转矩密切相关,因此可以用C1即牵引电机温度代替这两个指标,以此类推,筛选出状态参数间相关性都低于0.6的四项基本监测参数,依次为:牵引电机振动、牵引电机温度、牵引电机电流、牵引电机转速。同理,得到其他部件的状态参数相关性分析结果,筛选出相关性低的状态参数作为采煤机健康状态评估指标,剔除掉相关性较强的数据。
由于采煤机集机械,电力和液压系统于一体,因此影响采煤机的状态监测参数众多,但若将其全部用作采煤机状态评估指标,会增加不必要的工作量和影响评估工作效率。因此,本文在煤矿调研的基础上,结合采煤机结构、易发故障部位置和采煤机监测参数相关性分析,筛选出影响采煤机健康状态的最重要的多维指标,在此基础上确定采煤机健康状态评估指标体系的组成,分别从指标层、部件层到整机层进行分层划分,如图3所示。

图3 采煤机健康状态评估指标体系
1.3 采煤机健康状态等级划分
采煤机作为一个复杂设备,它的健康状态等级变化是一个渐变过程,从健康状态到劣化再到故障,因此为了便于量化计算和结合专家经验,本实验将其分为四个健康状态等级,分别是健康、良好、劣化、故障,采煤机健康状态对应的采煤机各等级描述见表3。
2 XGBoost原理
极端梯度提升算法(extreme gradient boosting,XGBoost)采用多线程加速树的构建,使用树模型作为基础分类器来形成强大的分类器,并通过将多个基础分类器集成在一起,这在分类任务中具有高效、准确和解释性好的优点[19]。XGBoost算法的基本概念和理论如下:

表3 数据集基本信息
1)基学习器。极限梯度提升树由回归树和分类树这两个基本部分构成,XGBoost是以分类和回归树(classification and regression tree,CART)作为基础学习器,采用XGBoost对评估模型进行训练,特征的属性被转移到每个叶子节点,对应于每个叶子的分数。
2)树的复杂度。每一棵回归树,可拆分为结构部分和叶子节点权重部分,则第t个树模型:
ft(x)=wq(x),w∈RT
(4)
式中,w为叶子节点分值;q(x)为样本x对应的叶子节点号;T为叶子数,RT是T维实数,表示叶子权重的集合。复杂度包含了一棵树里面节点的个数以及每个数叶子节点上面输出分数的模平方,因此,树的复杂度为:
式中,Ω为复杂度;γ是叶子节点数的惩罚系数;λ是正则项系数;wj是叶子节点j对应的分值。
3)目标函数为:

式中,I={i|q(xi)=j},Gj=∑i∈Ijgi,Hj=∑i∈Ijhi。

5)增益。在创建树模型时,可采用贪心算法,每次对已有的叶子加入分割。对于一个决提的分割方案,其获得的增益为:
式中,第一项为左子树分数,GL为树分类后左子树gi之和,HL为树分类后左子树hi之和;第二项为右子树分数,GR为树分类后左子树gi之和,HR为树分类后左子树hi之和;第三项为不分割下的分数,表示新叶子节点带来的复杂度代价。由以上原理可知XGBoost将多个弱学习器结合,因而可以获得更好的性能。
将采煤机状态数据作为特征量输入,采煤机的四种健康状态作为分类输出结果,通过模型训练,通过各项模型参数调优,得到最佳参数值。
3 XGBoost集成学习模型训练
3.1 模型建立步骤
本节采用XGBoost集成学习建立采煤机健康状态评估模型,通过划分采煤机健康状态等级,建立训练样本,并对XGBoost模型内部关键参数优化,最后对采煤机健康状态进行评估,得出结论。应用XGBoost对采煤机健康状态进行评估的主要过程如下:
第一步是将相关分析、特征选择后的指标数据作为XGBoost的输入特征,将采煤机不同的健康状态等级作为评估算法的类别标签。
第二步是将采煤机状态数据集进行划分。通过状态量的选取和指标体系的构建,将采煤机状态数据集分为训练集和测试集,按照一定的比例对其进行划分。
第三步是对XGBoost分类模型的主要参数进行初始设置。模型建立后对采煤机状态评估模型的各项参数进行设置,如树的最大深度、模型的学习率、最小叶子权重和等。
第四步是用训练集数据对采煤机XGBoost状态评估模型进行训练,用采煤机数据测试集对模型进行测试。通过构建一棵CART决策树,然后依次增加状态分类节点,分别对前一次的评估结果进行拟合,训练过程中的目标是损失函数最小,通过求取损失函数最小的特征作为分叉树的特征,在此基础上求出每一个叶子节点即状态的预测分数,将每棵树的每种评估结果的预测分值作为概率值,根据概率值最大完成状态分类和评估。
最后一步是不断调整XGBoost模型参数。通过改变各项参数值查看评估模型分类效果,以综合评估效果最优的XGBoost各项参数作为最终的评估模型参数。具体的评估流程如图4所示。
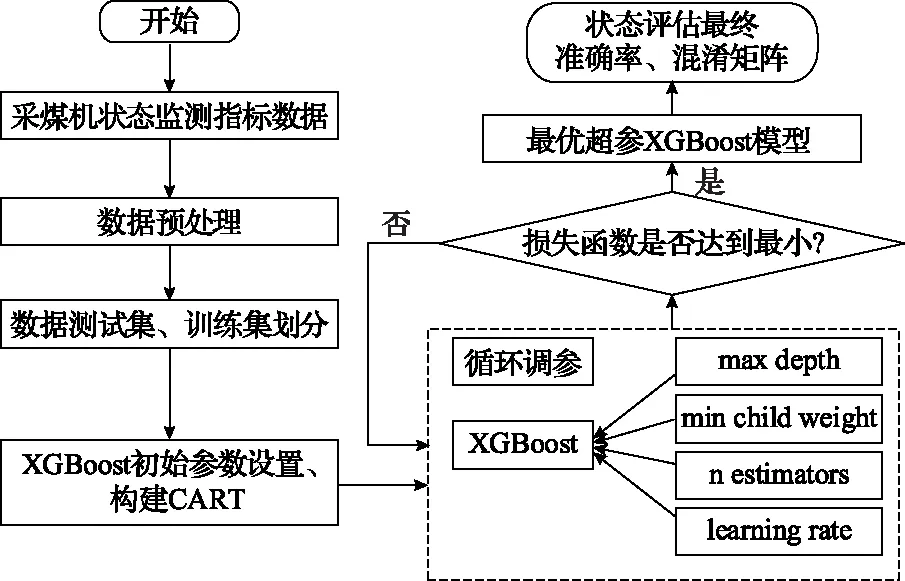
图4 XGBoost模型评估流程
3.2 XGBoost状态评估模型参数
为保证评估结果的准确性,本节通过选取采煤机状态指标数据1000条作为实验数据,将采煤机指标参数如牵引电动机温度等归一化后的15维数据导入XGBoost评估模型中,数据集中80%作为训练集,20%作为测试集。通过交叉验证[20]的方法对XGBoost评估模型的参数进行调优,将训练集和测试集分类错误率作为模型的评估指标,多次调参得到采煤机状态评估模型的最优参数。
在对XGBoost的采煤机评估模型参数优化前,首先需要对影响XGBoost模型评估效率的关键参数进行分析。第一类参数是调节过拟合的参数即树的最大深度max_depth、最小叶子节点权重和min_child_weight等。一般来说max_depth越深,说明评估模型可以学习到更细微具体的数据样本信息,但当树的深度的过深时,就可能发生过拟合现象。此时测试集数据分类错误率较高、训练集分类错误率较低;min_child_weight的值越大时,越能全面学习到样本的各项特征,但当min_child_weight值过大时,模型学习到较多无用信息,因而发生过拟合现象。因此,本章主要对这两个关键参数进行优化。
最小叶子节点权重和“min_child_weight”的取值一般在4~10之间,本章取“min_child_weight”取值为4、6、8、10时,得到XGBoost模型的训练集和测试集的分类错误率如图5所示。由图5可知,当设置树的高度为2、4时,训练集合测试集的分类错误率相差不大且能控制在相对较小的范围内且树高度为4时平均分类错误率更小;当设置树的高度为6、8时,错误率虽较小,但是训练集和测试集差距过大,不适合作为最佳参数。因此,综合以上因素,选择树高度为4时最为合理。

图5 不同树高度时XGBoost模型分类错误率对比
不同min_child_weight时XGBoost模型分类错误率对比如图6所示,可知,当设置min_child_weight为4、6时,训练集合测试集的分类错误率相差不大且能控制在相对较小的范围内,min_child_weight值为6时分类错误率更小;当设置min_child_weight值为8、10时,错误率虽不大,但是训练集和测试集差距过大,训练集误差率过高,因此不适合作为最佳参数。因此,综合以上因素,选择最小叶子节点权重为6时最为合理。

图6 不同最小叶子节点权重和时分类错误率对比
接下来要调整的参数为最小损失函数下降值gamma与随机采样比例subsample、随机列数比例colsample_bytree。gamma表示每个节点划分时对应的损失函数的下降值,若算法越保守gamma的数值越大。本章中,gamma的大小依据经验在0~0.5之间进行调整,每次相隔0.1,通过实验得出当gamma的值为0.1时最佳,准确率为0.985。随机列数比例colsample_bytree表示决策树的生成时间,而随机采样比例subsample表示采样的样本占整个样本的比例。通过不断调整参数,求得colsample_bytree和subsample的最佳组合参数为前者的值为1,后者的值为0.8时模型的效果最佳主要模型参数见表4。

表4 模型参数
3.3 评估过程
参数调优后,将数据集导入XGBoost评估模型,因为XGBoost采用集成树模型,因此将模型可视化,可以看到评估过程树的结构,因为树的数量较多,以第一个类别(即健康状态1)的第一棵树为例,可得到树结构如图7所示。

图7 树结构
由图7可知,每一棵树划分的状态指标参数和对应的划分阈值,其和采煤机状态数据集的第一组数据对应,将每组数据4种状态的相对应的叶子节点分值相加,即得到该组状态数据所对应的4种健康状态的分值[X1,X2,X3,X4],以此类推可计算出该组数据对应的每个健康状态的概率[P1,P1,P1,P1],依据概率最大即可得到采煤机对应的健康状态等级。
4 实例分析
本文选取陕北煤矿某型采煤机监测数据筛选出采煤机状态指标数据1000组作为实验数据,每种状态数据包括15维状态指标数据和对应的健康状态等级标签。其中“健康”状态数据400组、“良好”状态数据300组、“劣化”状态数据200组、“故障”状态数据100组,采煤机各个健康状态等级对应的状态等级描述见表3。
在设置各项参数最优值的基础上,将采煤机状态数据集导入进行训练和测试,模型训练步骤如图4所示。模型训练完毕后,将200组测试数据导入XGBoost状态评估模型,分别计算评估准确率、每种健康状态的召回率、以及综合评估参数F1的值来评判模型。评估准确率是表示评估模型总体好坏的指标,然而采煤机健康状态评估样本存在不平衡问题,即健康样本数量远多于不健康的样本,仅凭单一的准确率指标无法定性模型的评估效果,因此用每一类样本中被正确分类的数量占该类健康状态样本中的比例即来评价模型对样本不平衡问题的适用程度。同时为避免单一准确率和召回率评价指标的弊端,采用两者的综合评价指标F1值来综合反映评估模型的效果,F1值越接近于1,评估模型的分类效果越好。通过程序运行,评估过程中测试集的多分类错误率merror如图8所示,得到模型的具体评估结果用混淆矩阵表示如图9所示。
由图9可以看出,在200组数据中,有197组状态数据被正确分类,即197组状态数据可以被准确得到对应的健康状态,有1组数据属于“健康”状态而被分类为“良好”状态,有2组数据属于“劣化”状态而被分类为故障状态,但状态预测结果与实际只相差一个等级,对结果影响不是特别大。模型总体评估效果较好,总体准确率高达98.50%,“健康”状态等级准确率为98.66%,“良好”状态等级准确率为100%,“劣化”状态等级准确率为94.87%,“故障”状态等级评估准确率为100%,4种健康状态等级的平均召回率为98.38%,F1平均值为97.61%,平均召回率和FI值较高,说明模型对采煤机数据集每种状态和总体的评估效果都较好。
5 结 语
本文针对采煤机变工况、工作环境恶劣等特点,将XGBoost集成学习方法引入采煤机健康状态评估工作中,根据综合相关系数,对采煤机状态指标进行筛选。实验表明,经过调参以后的模型评估效率和准确性较高,更适用于采煤机不平衡数据集。
猜你喜欢
中国卫生统计(2023年5期)2023-11-30 01:40:14
防爆电机(2022年1期)2022-02-16 01:14:06
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
教师·中(2017年3期)2017-04-20 21:49:49
试题与研究·教学论坛(2016年27期)2016-08-11 14:57:08
教学研究与管理(2014年4期)2014-05-16 22:44:12
河南科技(2014年18期)2014-02-27 14:14:58
