
Collaborative image compression and classification with multi-task learning for visual Internet of Things
2022-04-27 08:28BingDUYipingDUANHngZHANGXiomingTAOYueWUConghongRU
Chinese Journal of Aeronautics 2022年5期
Bing DU, Yiping DUAN, Hng ZHANG, Xioming TAO, Yue WU,Conghong RU
a School of Computer and Communication Engineering, University of Science and Technology Beijing, Beijing 100083, China
b Department of Electronic Engineering, Tsinghua University, Beijing 100084, China
c School of Computer Science and Technology, Xidian University, Xian 710071, China
d Smart Network Computing Lab, Cross-strait Tsinghua Research Institution, Beijing 100084, China
KEYWORDS Deep learning;Generative Adversarial Network (GAN);Image classification;Image compression;Internet of Things
Abstract Widespread deployment of the Internet of Things (IoT) has changed the way that network services are developed, deployed, and operated. Most onboard advanced IoT devices are equipped with visual sensors that form the so-called visual IoT. Typically, the sender would compress images,and then through the communication network,the receiver would decode images,and then analyze the images for applications. However, image compression and semantic inference are generally conducted separately, and thus, current compression algorithms cannot be transplanted for the use of semantic inference directly. A collaborative image compression and classification framework for visual IoT applications is proposed,which combines image compression with semantic inference by using multi-task learning.In particular,the multi-task Generative Adversarial Networks (GANs) are described, which include encoder, quantizer, generator, discriminator, and classifier to conduct simultaneously image compression and classification.The key to the proposed framework is the quantized latent representation used for compression and classification. GANs with perceptual quality can achieve low bitrate compression and reduce the amount of data transmitted. In addition, the design in which two tasks share the same feature can greatly reduce computing resources, which is especially applicable for environments with extremely limited resources.Using extensive experiments,the collaborative compression and classification framework is effective and useful for visual IoT applications.
1. Introduction
Internet of Things (IoT) enables the physical things like home appliances or security systems to connect to the Internet for effortless utility, which uses data storage, analytics, and sensors to meet our daily needs better and more efficiently. Most advanced IoT devices are equipped with visual sensors;collectively these devices comprise the so-called Visual IoT (V-IoT).The V-IoT relies extensively on computer vision processing techniques to sense and process massive amounts of visual data. V-IoT devices have been broadly used in various fields,such as industrial production, video surveillance, intelligent transportation, precise farming, entertainment, and military and security applications.In these uses, the sensors include high-resolution (Red-Green-Blue) RGB cameras for surveillance and monitoring, normalized difference vegetation index cameras for precision farming, light imaging, detection, and ranging for simultaneous localization and mapping,and ultrasonic sensors for sense and obstacle-avoidance methods.These IoT sensors collect data (images) in real time, and the data are either processed on board if enough power is available or transmitted to a base station.
Users of the V-IoT focus on not only the perceptual quality(high-definition image/video) for human experience, but also the semantic inference (classification, detection, and recognition) of the images to enable intelligent surveillance, remotesensing, and virtual-reality scenarios.However, traditional‘‘Sender-Network-Receiver” information processing communication framework mainly focuses on the perceptual quality of the image without considering the semantic tasks. The two tasks are generally separated in the communication process. If semantic tasks are required, additional computing resources have to be consumed, which inadvertently increases the burden of airborne computing resources for V-IoT applications. Generally, the features used to preserve the perceptual quality are related to the features for the semantic inference,but the former are often not the most suitable features for the semantic inference. To use the limited onboard computing resources efficiently, the features being transmitted should be matched to the task. Therefore, for IoT scenarios with limited sensor computing resources,it is desirable to obtain perceptual quality and accurate semantic inference simultaneously in the communication system for onboard V-IoT applications.
1.1. Compression task
Researchers have developed compression standards, such as JPEG,JPEG 2000,and BPG.These compression standards are formulated by a rate-distortion function to optimize the bitrate and visual metrics, such as Peak Signal-to-Noise Ratio(PSNR) and Structural SIMilarity (SSIM). For instance,JPEG includes Discrete Cosine Transform(DCT)transformation, quantizer, and inverse DCT transformation, which are separated in the framework. In these traditional compression standards, image content is not considered, and thus, the performance of image compression is limited by treating image content equally.Afterwards,deep learning is used to compress the image with low bitrate. The encoder, quantizer, and decoder are jointly optimized by end-to-end learning.Mishra et al.proposed a wavelet-based deep auto encoder-decoder network for image compression, which took care of the various frequency components present in an image. Then, a goodquality decompressed image was achieved by adaptive representation learning.
1.2. Semantic inference
Because of booming deep learning, semantic inference tasks have made breakthrough progress.These tasks usually require a huge amount of training data,such as ImageNet,Psacal and Voc datasets, to learn the strong features for semantic tasks.For these datasets, researchers have performed a lot of work,for example, classification and semantic segmentation, and achieved remarkable results.
1.3. Separated compression and semantic inference
Some emerging V-IoT applications require images with high perceptual quality and accurate semantic inference simultaneously, such as video surveillance, and industrial production.For example, a variable-rate compression by reducing the channel redundancy under a Generative Adversarial Network(GAN) framework was proposed by Mishra et al. recently.They proposed a generative compression system at an extremely low bitrate. Then, the compressed images were used for semantic segmentation. Compression and semantic inference have been performed separately by two complex neural networks in this framework.
Inspired by the above,both the semantic inference(such as image classification) and image compression adopt the image features to complete the corresponding tasks. The image features are redundant for different tasks. Moreover, deep learning provides a promising way for multi-task collaboration.With the consideration, we propose a collaborative method to achieve the image classification and compression simultaneously in an end-to-end framework.By the collaborative framework, the compression can be achieved at the extremely low bitrate and the classification can be improved in terms of the accuracy. At the same time, the computing resource can be greatly saved.
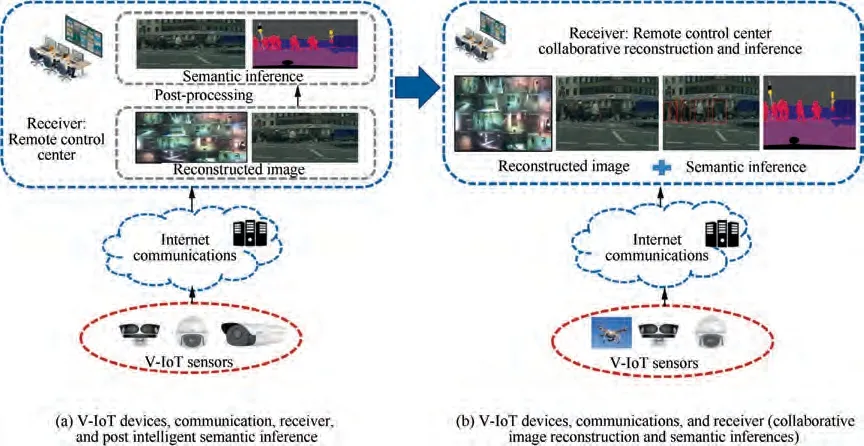
Fig. 1 Framework of V-IoT system.
In this paper, we propose a collaborative image compression and classification framework with multi-task learning for V-IoT applications. We call this framework collaborative image compression and semantic inference, as shown in Fig.1. The left framework is ‘‘V-IoT devices, communication,receiver, and post intelligent semantic inference”, and each step is a separate process; the right framework is ‘‘V-IoT devices, communications, and receiver (collaborative image reconstruction and semantic inferences)”, and the entire process can be implemented by end-to-end learning.In particular,we propose multi-task GANs including encoder, quantizer,generator, discriminator, and classifier to achieve the collaborative compression and classification.The key point of the proposed framework is the quantized latent representation used for compression and classification. GANs with perceptual quality can achieve low bitrate compression and reduce the amount of data transmitted. In addition, two tasks sharing the same features can greatly reduce the computing resources.The main contributions of the paper are summarized as follows:
(1) We propose a collaborative image compression and classification learning framework for V-IoT applications.The key point of the proposed framework is the quantized latent representation used for compression and classification.
(2) We design the multi-task GANs to conduct the compression and classification collaboratively. Two tasks share the same features, which can reduce considerable computing resources.
(3) We propose a novel optimization target:minimizing the combination of Mean Square Error(MSE)loss and perceptual loss, to preserve the fidelity at the pixel and semantic level.In this way,the collaborative framework can achieve low bitrate compression and reduce the amount of data transmitted.
The rest of this article is organized as follows. We briefly review the deep learning based approaches of image compression and intelligent semantic inferences in Sections 2 and 3,respectively. In Section 4, we propose the collaborative image compression and classification framework. Section 5 describes the multi-task GANs including the network structure and multi-task learning. The experimental results and conclusions are presented in Section 6.
2. Deep learning based image compression
Most advanced IoT devices are equipped with visual sensors that collect the multimedia data, such as image and videos.Videos and other applications continue to be in enormous demand,and there will be significant bandwidth demands with future application requirements. Therefore, the demand of image compression is urgent.Image compression is formulated by a rate-distortion optimization problem. Learning-based image compression can jointly optimize the encoder and decoder, which can be divided into two categories, Convolutional Neural Networks (CNNs) based compression and GANsbased compression.
2.1. CNNs-based compression
The CNN-based image compression consists of encoder,quantizer, entropy estimation, and decoder, each of which is modeled by a well-designed CNN. The loss function usually includes two parts:entropy estimation loss and distortion loss.The distortion loss mainly refers to visual metrics, such as PSNR and SSIM. Li et al.proposed a content-weighted encoder-decoder model, which involved an importance map subnet to produce the importance mask for locally adaptive bitrate allocation. By introducing the importance map based bit allocation and trimmed CNN based entropy estimation,Li et al. significantly enhanced the performance, which was compared favorably to traditional lossy image compression approaches.Lu et al.proposed an end-to-end deep video compression framework that combined the advantages of neural networks and traditional video compression.
2.2. GANs-based compression
The GANs-based image compression method consists of encoder, quantizer, entropy estimation, generator, and discriminator. The loss function usually includes three parts: entropy estimation loss, distortion loss, and adversarial loss. The discriminator is essentially a quality evaluation component from the data distribution level to force the distribution of the input image and the reconstructed image to be approximately equal.Therefore, the method can produce a better subjective visual experience with a notably low bitrate. Li et al.proposed a general-purpose compression framework for reducing the inference time and model size of the generator in GANs to preserve the visual quality. Agustsson et al.presented a learned image compression system, based on GANs, that operated at extremely low bitrates. By jointly training an encoder,decoder/generator, and a multi-scale discriminator, for low bitrates,our approach is preferred compared to the abovementioned state-of-the-art methods, even when those methods use more than double bitrates.
3. Deep learning based semantic inference
In V-IoT applications, it is challenging to efficiently analyze and search the objects from millions of objects captured every day. Typically, the compression and transmission constitute the basic infrastructure to support these applications. Then,the images are fed into the machine learning and pattern recognition algorithms to complete high-level analysis and retrieval tasks. This mode is called ‘‘compression then semantic inference”. The high-level semantic inference usually includes classification, detection and recognition, and semantic segmentation. The traditional methods usually extract welldesigned features,such as bag of words features,and then infer the semantics by the classifier, such as Support Vector Machine (SVM) and Linear Discriminant Analysis (LDA).Because of advances in deep learning,semantic inference tasks have made considerable progress recently.
3.1. Image classification
The image classification problem, widely used in V-IoT applications, is assignment of one label for each image. The network structure usually includes a well-designed feature extraction subnetwork and classification subnetwork. Feature extraction subnetworks are usually convolutional layers or residual blocks. The classification subnetwork is usually a number of fully connected layers.Then,the parameters of feature subnetwork and classification subnetwork are trained by end-to-end learning. Considerable progress has been made in image classification, primarily due to the availability of large-scale annotated datasets and deep CNNs. Russakovsky et al.proposed a large-scale benchmark dataset, the ImageNet dataset, that greatly advances the image classification and object recognition. Devi et al.presented a simple and efficient IoT-enabled disease detection system to detect and classify crops,which used image processing and IoT to process the images of the plants and extract their texture features. Xu et al.proposed a deep CNN for medical image classification.They used CNN transfer learning from non-medical to medical image domains for two different computer-aided diagnosis applications, thoraco-abdominal lymph node detection and interstitial lung disease classification.
3.2. Image detection and recognition
Like image classification, researchers are dedicated to extract key visual features in a compact form. In the Internet of the vehicles, various sensors collect the visual images or videos of the surroundings. Corresponding detection and recognition methods are used to support the active automotive safety systems.Wang et al.proposed CNNs and active contour models to extract and detect front vehicles for solving the problem of information perception against the front vehicle. Lou et al.proposed an IoT-driven vehicle detection method which combined the heterogeneous data feature of Ultra Wide Band(UWB) channel with magnetic signal features to improve the performance of the wireless vehicle detectors.
3.3. Image semantic segmentation.
Image semantic segmentation assigns one label for each pixel.Recent studies have greatly promoted the development of semantic segmentation by deep learning methods. Most state-of-the-art methods adopt fully convolutional networks to accomplish this task, in which the fully connected layer is replaced with the standard 2D convolution layer for dense prediction. In V-IoT applications, semantic segmentation has a crucial function.Shen et al.proposed an intermediate supervision deep neural networks,Deep Aurous Pyramid Intermediate Supervision, to promote the image analysis of ultra-sound IoT devices in smart health.Peng et al.proposed an effective algorithm for cross-domain face recognition by exploiting semantic information integrated with deep CNNs for video surveillance.
4. Collaborative image compression and semantic inference framework
Typically, the V-IoT would compress images in the sender,transmit through the communication system, decode images in the receiver and then analyze the images.V-IoT usually adopts the mode of ‘‘compression then semantic inferences”.A series of image compression standards (JPEG, JPEG 2000,and BPG) are developed to improve image compression performance. For example, PSNR is used to keep the original image and the compressed image as similar as possible at pixel level with a certain bitrate. Then, the compressed images are fed into the machine learning algorithms for semantic inference. With the continuous development of V-IoT technology,the amount of data is growing rapidly,which brings great challenges for image compression. To improve compression efficiency, some researchers extract the image semantics to transmit the compact representation. This approach is called‘‘semantic inferences then compression”. Deep learning based methods widely used for task-oriented compression extract the semantics to reduce the amount of data transferred. Feature similarity and semantic similarity are used to keep the features and semantics of the images as similar as possible with a certain bitrate.However,in either‘‘compression then semantic inference” or ‘‘semantic inference then compression” mode,image compression and semantic inference are performed separately.A benefit from the development of multi-task machine learning is the possibility to perform compression and semantic reference collaboratively by sharing the features and computing resources.
For a typical V-IoT scene, such as video surveillance or industrial Internet surveillance, high-definition images and image semantics are usually required.The traditional monitoring intends to obtain high-definition images, and process the images to obtain image semantics, such as classification, segmentation, detection, and recognition.Usually, these two tasks are conducted independently. Obtaining high-definition images is essentially a lossy image compression task.The input of this task is an image,and the output is the estimation of the image, which maps the image from pixel space to pixel space.By extracting key features from the encoder, the image is reconstructed by the decoder. The main task of this encoderdecoder is to ensure consistency of the reconstructed image with the original image in terms of pixels. For semantic inference tasks, the key point is to extract the discriminative features to distinguish different semantics, which maps the image from pixel space to label space.For example,image classification predicts one label for each image. What the above two tasks have in common is to extract high-level compact representation of the image,which can be shared with multiple VIoT applications. Deep learning is a promising way to achieve the image compression and semantic inference simultaneously,which shares the encoder to extract the image features.Collaborative compression and classification are realized by end-toend learning, and image classification can be realized with a smaller amount of data, which saves computing resources greatly. We can embed this collaborative compression and classification software in the airborne V-IoT device to improve the efficiency of communications and networks.
Thus, we propose a collaborative image compression and semantic inference approach. For an input image, both the reconstruction image and the classification label can be achieved by end-to-end learning.Fig.2 represents the collaborative image compression and semantic inference framework.It includes an encoder E, a quantizer Q, a discriminator D, a generator G, and a semantic inference module S. We assume the input image as X. The encoder E transforms the original image x into a feature space to obtain a feature map. The quantizer Q quantizes the feature map to obtain the quantized latent representation. Quantizer is a basic component of the image compression, which projects the feature map to several quantization levels.In this paper,we use 5 quantization levels:{-2,-1,0,1,2}.After passing through the encoder,the original image can output a feature map that is taken as the latent representation. Furthermore, this latent representation is quantized with the abovementioned quantization levels.Through this step,the transmitted data can be greatly reduced.The generator G generates images from the quantized latent representation. The objective function is the consistency between the original image and the generated image, such as MSE, and is called ‘‘reconstruction distortion”. The discriminator D distinguishes the generated image and the original image to improve the perceptual quality. The semantic inference module S uses the quantified latent representation to extract the image semantics.The objective function is the accuracy of semantic extraction, such as cross entropy error function. Then, the reconstruction distortion and semantic extraction accuracy are combined to obtain the overall objective function of the system. The system is further trained by a gradient descent algorithm. By the end-to-end learning, the encoder learns the compact representation for image reconstruction and classification at the same time, which greatly reduces the burden of calculation and storage. This method can be used in many V-IoT scenarios to improve the performance of IoT system. Fig. 2 shows that the generator and the semantic inference module share the encoder. Moreover,the quantized latent representation is used for semantic inference.
5. Multi-task generative adversarial networks
In this section, we describe multi-task GANs for this collaborative image compression and classification, including the network architecture, the multi-task learning and the corresponding experimental results.
5.1. Network architecture
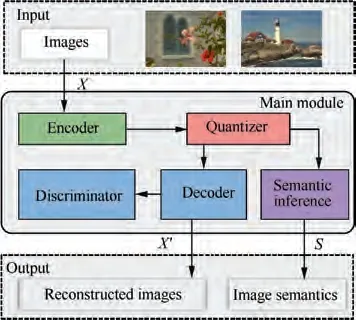
Fig. 2 Collaborative image compression and semantic inference framework, including encoder, quantizer, discriminator, generator, and semantic inference module.
GANs were first proposed to generate images from noise,and GANs have been used widely in many fields including image synthesis, image editing, semantic inpainting, and image compression. In particular, GAN-based image compression goes beyond typical image compression standards with a notably low bitrate. Santurkar et al.proposed the concept of generative compression. They pointed out that the compression of images using generative models is a direction worth pursuing to produce more accurate and visually pleasing reconstructions. Afterwards, researchers developed several variations of GANs to improve the compression performance. Inspired by previous work,we adopt GANs-based framework for this collaborative compression and classification. There are two reasons to do so. One is that GAN can compress image with a notably low bitrate and the other is that GAN can output a feature map which can be used for classification.In this framework,we use the GAN concept to realize a forward-backward multifunctional training task by integrating four loss functions of measuring classification, reconstruction, adversary and discriminator.
We define multi-task GANs as follows: x is the original input image. E is encoder, and z=E(x) is the output feature map. Q is the quantizer, and the output is q=Q(z). G is the generator, and x=G(q) is the reconstructed image. C is the classifier, and l=C(q) is the output label. Generally, both E and G are Fully Convolutional Networks(FCNs).The original image x has size of W×H×3. The encoder E produces a compressed representation (feature map) z with size of W/m×H/m×ch, where m is the sub-sampling factor, and ch is the channel number of z, which is related to the bitrate.For quantizer, we set five quantized centers {-2, -1,0,1,2}to reduce the transferred data. The representation of each model is summarized in Table 1.After the quantizer,the quantized latent representation has size of W/m×H/m×ch used for classification. By adjusting the bottleneck CH, different bitrates can be realized.Fig.3 represents the network architecture of multi-task GANs. The encoder subnetwork starts with a convolutional block with kernel size 7×7,stride 1 and channel size 32.Then,there are four convolutional blocks and each convolutional block has kernel size 3×3 and stride 2.The feature map channels of the four convolutional blocks are 64,128,256, and 512.
There are six residual blocks. Each residual block has kernel size 3 × 3, stride 1 and channel size 512. The structure of the generator G is an inverse process of the encoder. The discriminator starts with four convolutional blocks with the kernel size 3 × 3 and up-sampling stride 2. The feature map channels of the four convolutional blocks are 512, 256, 128,and 64. We adopt multi-scale discriminators to distinguish whether an image is from reality or the generative network.The classifier is composed of two fully connected layers with the size 2048.The five modules are well-designed to implement the collaborative compression and classification. To clearly show the network architecture, the parameters of each layer are shown in Table 2.
5.2. Collaborative multi-task learning
With the network architecture in Section 5.1,the collaborative multi-task learning mainly includes the forward process and backward process. In the forward process, we design different loss functions for different tasks. For image compression, we use GAN loss, generator loss and multi-scale discriminator loss to improve the perceptual quality at low bitrates. For image classification, we adopt the cross-entropy loss to ensure classification accuracy. For generator, the goal is to make the generated image and compressed image as identical as possible.We add up the two objective functions for joint optimization. The objective function is defined as follows:
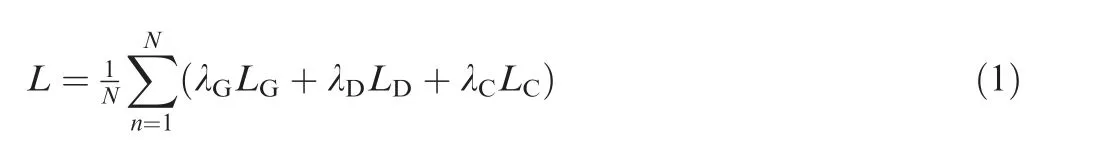
where L,L,and Lare the generator loss,discriminator loss and classification loss,respectively.The weights of the generator, discriminator, and classifier are λ, λ, and λ, respectively. λ, λ, and λ, are the hyperparameters defined before the training. Lloss includes the MSE loss, feature matching loss, and adversarial loss. Lincludes the multi-scale discriminator loss and adversarial loss. Lis the crossentropy loss.

Table 1 Models and their representation.
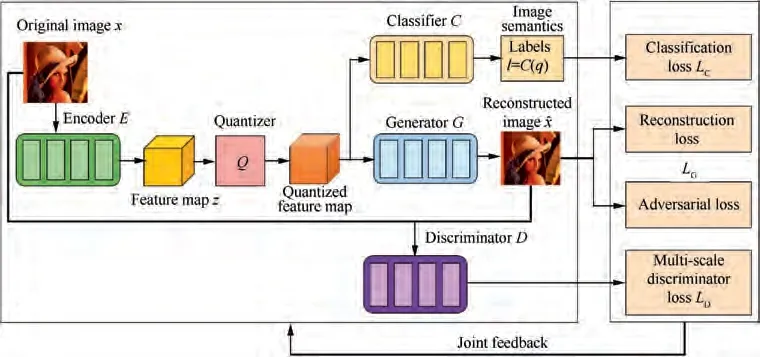
Fig. 3 Multi-task generative adversarial networks for collaborative image compression and classification.
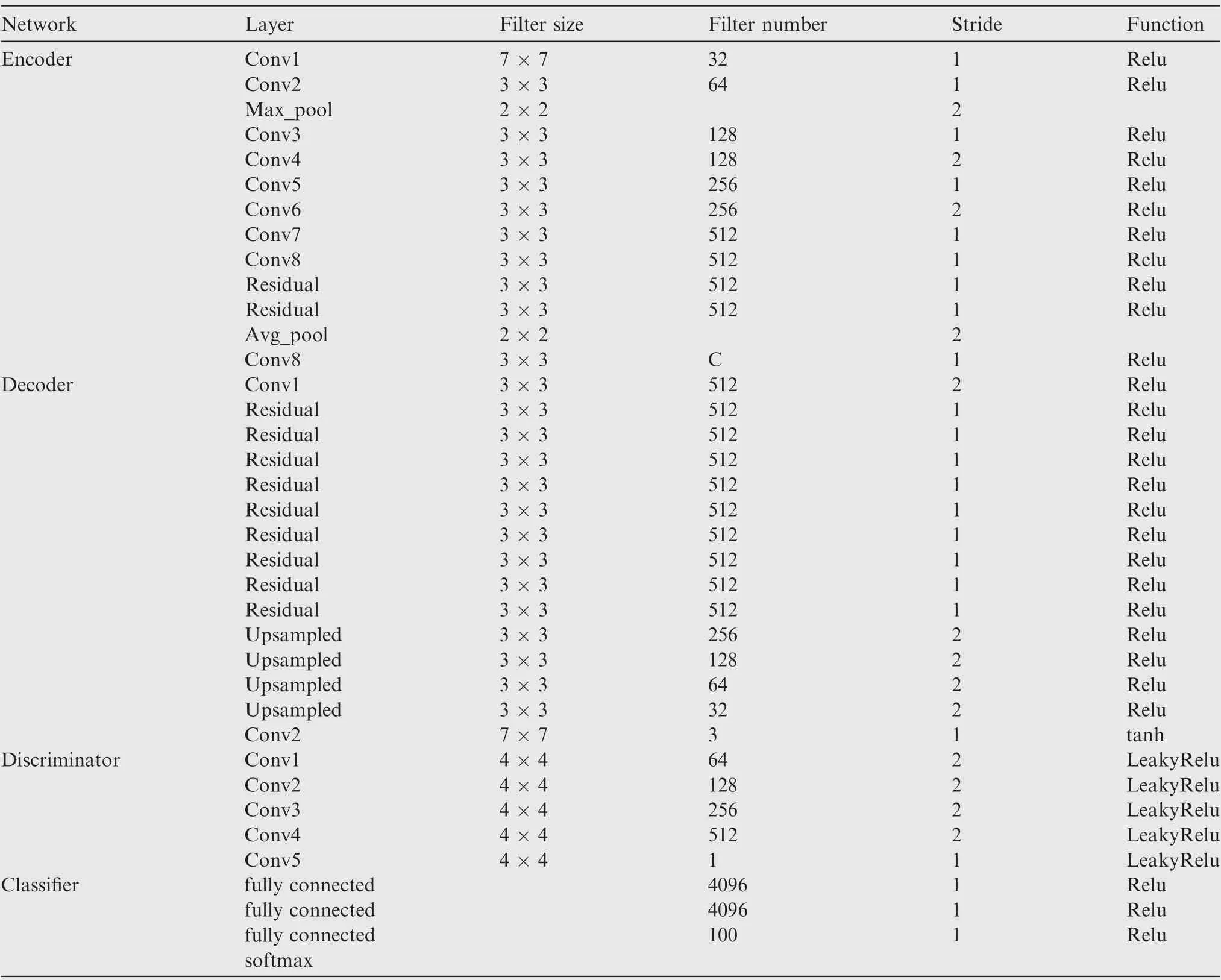
Table 2 Network parameters of different layers.
The objective function is defined as follows:


where yis the label of the input image x.
In the backward propagation process, we divide into three steps to train the network.The first step trains the generator by updating the parameters of the encoder and generator. The second step trains the classifier by updating the parameters of the encoder and classifier.Thus,the encoder is trained twice.The third step trains the multi-scale discriminator by updating the parameters of the discriminator. We train the entire network end to end until the objective function is less than 10. After the training is completed, an image is fed into the network and the reconstructed image and the classification labels are obtained simultaneously. Moreover, there are several hyperparameters in the proposed network, such as the weight coefficients λ, λ, λ, the bottleneck CH, and the node number of the fully connected layer in the classification subnetwork. The four weights are used to balance different tasks. The hyperparameter CH is used to control the bitrates.We also use dropout in the proposed network to prevent overfitting.

Table 3 Compression performance (PSNR and SSIM) and classification performance (accuracy) at various compression levels.

Table 4 Parameters of different tasks.

Fig. 4 Visual examples of compressed images on ImageNet dataset.
5.3. Simulation and experimental results
We tested our collaborative compression and classification on the ImageNet dataset. We randomly selected a subset of the ImageNet dataset with 100 classes with each class having 1300 images. We selected 90% of the images as the training set and the remainder as the test set. The input images were rescaled to 256 × 256. We trained the proposed network with 100 epochs with Adam optimization. Because all the subobjective functions are treated equally in our framework, the hyperparameters are defined as follows: λ=1, λ=1,λ=1. With many experiments, we set λ=12, λ=10.With different C, we obtained different bitrates. When C = 4, the bitrate was 0.0362. When C = 8, the bitrate was 0.0725. When C = 16, the bitrate was 0.145. We present the experimental results with these three bitrates.
We compared our proposed approach with image compression standards JPEG and JPEG 2000. First, we compressed the image to a fixed bitrate. Then, we used classical VGG(Visual Geometry Group) network for image classification.We verified the performance of the proposed algorithm from three aspects. Note that the discriminator is used to force the distribution of the input image and the reconstructed image similarly. PSNR may not be the most suitable for evaluating compression performance. Hence, we used SSIM to evaluate the compression performance.We used two metrics to evaluate the performance of the proposed approach,SSIM and classification accuracy, as shown in Table 1. First, GANs for image compression can achieve extreme low bitrate with visually acceptable reconstructions. Table 3 shows that, with 0.0362 bitrate, the compression performance was comparable to JPEG 2000.However,it is difficult to achieve this bitrate with JPEG. Second, with the notably low bitrate, the classification accuracy was tested on different bitrates and outperformed JPEG 2000. Especially with bitrate 0.0362, the classification accuracy of the proposed approach was three times that of JPEG 2000. Third, we represent the parameters of different tasks in Table 4. For separate compression and classification,the number of the parameters was 638.76 × 10. For collaborative compression and classification, the number of the parameters was 112.92×10.It demonstrates that the parameters were largely saved and the computing resources thereby saved. Thus, the collaborative compression and classification framework was effective and useful in V-IoT applications.
The visual results on ImageNet dataset are shown in Fig.4.The first and third columns are the original images, and the second and fourth columns are the compressed results by our proposed approach under 0.072 BPP. We can see that the textures of the images are recovered very well and the visual quality of the compressed images are satisfied. In other words, the visual quality of our proposed method is satisfactory at low bitrate.
6. Summary and conclusions
We have proposed a collaborative image compression and classification approach with multi-task learning for airborne V-IoT. Our contributions are summarized as follows:
(1) We develop a multi-task GAN including encoder,quantizer, generator, discriminator, and classifier to provide collaborative image compression and classification simultaneously. The key point behind this system is the quantized latent representation of multimedia.
(2) We use GANs for the compression under notably low bitrate, which reduces the amount of data transmitted.The compression and classification tasks o share the features save computing resources.
(3) The experimental results demonstrate that the collaborative compression and classification framework was effective and useful in extensive airborne V-IoT applications.
However, a multi-task learning model is difficult because multiple tasks are mutually restricted.An interesting direction for future work is to develop an effective learning algorithm for multi-task models. Moreover, the approach proposed by us is a macro framework in the V-IoT domain and we expect that this method will extend to other vision tasks such as target detection and target tracking to better serve V-IoT applications.
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
This work was supported by the National Key R&D Program of China (No.: 2019YFB1803400), the National Natural Science Foundation of China (Nos. NSFC 61925105,61801260 and U1633121), and the Fundamental Research Funds for the Central Universities, China (No. FRF-NP-20-03). This work was also supported by Tsinghua University-China Mobile Communications Group Co., Ltd. Joint Institute.
 Chinese Journal of Aeronautics2022年5期
Chinese Journal of Aeronautics2022年5期
- Chinese Journal of Aeronautics的其它文章
- Multiframe weak target track-before-detect based on pseudo-spectrum in mixed coordinates
- Mahalanobis distance-based fading cubature Kalman filter with augmented mechanism for hypersonic vehicle INS/CNS autonomous integration
- A new target tracking filter based on deep learning
- Structure-aware fusion network for 3D scene understanding
- A novel combination belief rule base model for mechanical equipment fault diagnosis
- De-combination of belief function based on optimization