
Structure-aware fusion network for 3D scene understanding
2022-04-27 08:22:44HiinYANYtingLVVeniceErinLIONG
Chinese Journal of Aeronautics 2022年5期
Hiin YAN, Yting LV, Venice Erin LIONG
a School of Automation, Beijing University of Posts and Telecommunications, Beijing 100876, China
b Interdisciplinary Graduate School, Nanyang Technological University, Singapore 639798, Singapore
KEYWORDS 3D point clouds;Data fusion;Structure-aware;3D scene understanding;Deep metric learning
Abstract In this paper, we propose a Structure-Aware Fusion Network (SAFNet) for 3D scene understanding. As 2D images present more detailed information while 3D point clouds convey more geometric information, fusing the two complementary data can improve the discriminative ability of the model.Fusion is a very challenging task since 2D and 3D data are essentially different and show different formats. The existing methods first extract 2D multi-view image features and then aggregate them into sparse 3D point clouds and achieve superior performance. However,the existing methods ignore the structural relations between pixels and point clouds and directly fuse the two modals of data without adaptation.To address this,we propose a structural deep metric learning method on pixels and points to explore the relations and further utilize them to adaptively map the images and point clouds into a common canonical space for prediction. Extensive experiments on the widely used ScanNetV2 and S3DIS datasets verify the performance of the proposed SAFNet.
1. Introduction
Visual perception is the key to numerous artificial intelligence applications.Among them,3D perception is absolutely one of the most significant techniques which has already achieved rapid and comprehensive developments in recent years.Beyond all questions, 3D perception has a lot of applications in terms of human-computer interaction, autonomous driving and robotics.In most cases,3D data from these fields exists in the form of 3D point clouds together with 2D images,of which 2D images usually present more detailed information about the scene while 3D point clouds convey more geometric information.Under such circumstance, how to naturally and effectively fuse these two data forms and simultaneously take the structural relations between the point clouds into consideration becomes a pivotal problem.Firstly,2D data and 3D data vary with each other to a large extent with no direct transformation approach between them. For example, the resolution of 2D images is much higher than 3D point clouds and 3D point clouds are always non-uniform because of the discrete grid structure.Besides,even if 2D images could be transformed so as to fuse with 3D point clouds, some constraints on the point clouds should be applied in order to adaptively take control of the structural relations for better 3D space representation.
Recently, a series of neural networks taking point cloud data as input have made much impression on 3D tasks such as 3D classification and 3D semantic segmentation. However,simply using point clouds with relatively lower resolution could not achieve powerful results all the time. The reason is that 3D point clouds only provide geometric information about each scene, but the detailed information like color and illumination is vague, which definitely has negative influence on subsequent tasks. Different from 3D point clouds, 2D images are generally of high resolution taken by RGB cameras, in which color information could be easily distinguished.Based on these considerations, we wish to make full use of original 2D images to improve the discriminative ability of the 3D model. That is to say, extracting features from 2D images and then lifting the features to 3D form tend to combine abundant information for the fusion with 3D point clouds.
In order to address the challenges mentioned above, we propose a Structure-Aware Fusion Network (SAFNet),where we first choose various RGB images from video streams in the original datasets, which are of high resolution,and then extract the corresponding feature maps using a convolutional encoder-decoder neural network. After that, the lifting and concatenation operations are utilized on the 2D features to form a new dense point cloud. Nevertheless, for the subsequent fusion process, we have to transform the dense point cloud into a sparse point cloud by aggregation.Importantly, instead of directly fusing two forms of data without adaptation, we further employ a metric learning method to restrict the inner structure of the sparse point cloud, where points with the same label are pulled close while points of different classes are relatively pushed away.Our metric learning loss is adapted from the cross-entropy loss and involves the similarity computation between positive and negative point pairs. In the end, PointNet++ serves as our backbone for the fusion of the information obtained and the semantic prediction of point clouds.
We summarize the contributions of this paper as follows.First, detailed feature information from 2D images is subtly acquired rather than being ignored or roughly extracted. Second, the generated sparse point cloud is no longer without any structural adaptation. The metric learning loss has the capability to conduct reasonable correction to the inner relations between points,which makes for better prediction performance. Then, the fusion of 2D and 3D information is processed by PointNet++ and the abundant scene features are passed through the whole network and fully exploited.Finally, the framework of the proposed SAFNet can be trained efficiently in an end-to-end manner.We perform extensive experiments on the widely-used ScanNetV2 and S3DIS datasets which consist of indoor scenes captured by RGB cameras. Plentiful comparative experiments and ablation studies demonstrate that the proposed method achieves very competitive performance.
2. Related work
2.1. 3D semantic segmentation
3D semantic segmentation focuses on predicting a label for each point in 3D point cloud data and various methods have been proposed up to now. For example, PointNetmakes use of multilayer perception to learn high-dimensional local features and applies the max pooling operation to get global features, which takes 3D coordinates as input and outputs the corresponding labels. Nevertheless, PointNet fails to capture local structures from neighboring points and point clouds are predicted without connection. In view of that, PointNet++is improved based on PointNet and designs set abstraction structures to learn local features,achieving better performance on sparse point classification tasks. As for PointSift, Jiang et al.proposed a sift-like network, which does not apply the same set abstraction approach as Point Net++ and obtains more valid points for semantic segmentation. Besides, SGPNconstructs three branches using PointNet to predict point grouping proposals and a semantic class for each proposal.As for SPG,the authorsapplied super point graph to capture the organization of 3D point clouds in order to tackle the challenges in large scale point clouds.The 3P-RNNis proposed to exploit the inherent contextual features in unstructured point cloud semantic segmentation. Furthermore, pointwise convolutional neural networkcould be operated on every point and is simple to implement. In addition, as for xMUDA,an unsupervised domain adaptation method is proposed for 3D tasks. In this paper,we focus on fusing 2D image information and 3D geometric information as well as exploring the inner structural relations between sparse point clouds, which results in positive semantic prediction performance.
2.2. Networks for 3D data
The existing network architectures for 3D data include 3D convolutional networks and point cloud based networks. To be specific,Ji et al.proposed a novel 3D convolutional neural network which extracts both spatial and temporal features by generating several channels from the input frames and combining them to obtain the final feature. As for VoxNet, the authorsproposed a supervised 3D convolutional neural network to fully utilize rich sources of 3D information by integrating a volumetric occupancy grid representation. As for point cloud based networks, PointNet and PointNet++ directly take point clouds as input and output the corresponding semantic prediction, as mentioned before. Kd-networkperforms multiplicative transformations and uses Kd-trees to divide the point clouds in order to share the parameters of transformations, which also avoids poor scaling behavior. PointCNNlearns an χ-transformation from the input to tackle the problem of desertion of shape information as well as variance to point ordering. Additionally,EdgeConvincorporates local neighborhood information and learns global shape properties. In this paper, we apply Point-Net++ as our backbone, which directly processes point cloud data and is of inherent sparsity.
2.3. Data lifting
Lifting 2D image features to 3D forms tends to improve the performance in various 3D tasks. For example, 3DMVcreates voxel-volumes and unprojects 2D image features to 3D forms before applying a 3D convolutional neural network to conduct 3D semantic scene segmentation. Liang et al.proposed a bird view based method to gather 2D image features at the nearest neighbor locations. Besides, Qi et al.selected high-level 2D features and then lifted them to 3D frustums.Srivastava et al.focused on autonomous vehicles, utilizing 2D to 3D lifting from 2D monocular images to address the problem of 3D object detection. NRSfM++further introduces an unsupervised approach for 2D to 3D lifting. In this paper,we employ a pixel-to-point lifting method,which makes it easier for the structural relation computation for point clouds.
2.4. Deep metric learning
Deep metric learning is devoted to construct suitable embedding space to represent relative distance between samples with the help of deep neural networks. Generally, researches on deep metric learning are divided into two directions: loss design and sampling strategies. For the former, discriminative loss functions aim to increase the inter-class distance while decrease the intra-class distance between samples. For instance, contrastive losspushes negative pairs away to a defined margin in the embedding space and pulls positive pairs as close as possible. The widely used triplet lossconsiders a distance ranking between the positive and negative pairs,which involves a predefined margin between them as well.Sohnproposed a deep metric learning loss to process N + 1 samples at the same time by pulling one positive pair while pushing N-1 negative pairs in order to obtain richer sample relations. In addition,Fathi et al.utilized a metric learning loss to conduct semantic instance segmentation while Wang et al.classified different metric losses into three similarity representations. However, except for researches about losses, effective sampling methods are equally crucial to deep metric learning algorithm due to the numerous numbers of training samples. Hard negative miningchooses discriminative samples that are challenging for the training process to speed up the convergence and semi-hard sampling approachselects false positive samples which will not be classified as noise to form the triplets.Besides,Wu et al.emphasized sampling strategies in metric learning frameworks and proposed a distance-based sampling method by computing the corresponding data distributions. Xuan et al.took easy positive samples into consideration and improved the generalization ability of deep metric learning. Furthermore, Zheng et al.applied linear interpolation to adaptively generate hard samples in order to fully exploit latent information from all of the samples, which challenged the metric with proper difficulty. In our method, we wish to explore the relations in 3D point clouds with the help of deep metric learning. Therefore,we propose a structural deep metric learning method to calculate the similarity between points and restrain their relative distances for better 3D prediction performance.
3. Proposed approach
3.1. Overview
Our SAFNet is designed to both fuse complementary information from the two data types and combine the structural relations between pixels and point clouds.Various RGB-D frames and sparse 3D point clouds comprise the original data, one point cloud for each scene.Similar to PointNet++,the whole scene is first divided into multiple chunks for which we will choose the most informative views in order to richen the coverage of the point cloud mentioned before. After that, a 2D encoder-decoder deep neural network is applied to extract the feature maps from the RGB views. In order to augment the above sparse point cloud and consider the structural information at the same time, we lift the qualified pixels to a 3D point cloud and then concatenate these point clouds altogether to form a dense point cloud.Using k nearest neighboring sampling,we obtain k points from the dense point cloud and merge them to adaptively generate the features for points in the sparse point cloud. Besides, a structural deep metric learning loss is employed on the features for better prediction performance. Finally, PointNet++ is used to fuse the image features and point clouds in a common canonical space for semantic prediction. The overall process of the proposed method is illustrated in Fig.1.Some of the structures in the figure are utilized from MVPNet.First,we choose several RGB images from the original video based dataset to maximize the coverage of each 3D scene. Second, a deep neural network extracts the feature maps from the RGB images. After that,the feature maps are lifted to 3D point clouds and concatenated as a dense point cloud. Then, aggregation operation is applied to form a sparse point cloud where the metric learning loss is used.Finally,we employ PointNet++to fuse the information from the two data types and make the final semantic prediction.We argue that certain structural information exists in the features that can be exploited for more robust semantic segmentation. The structural relations refer to the semantic relations among features. For example, the bed and the floor are more likely to be adjacent than the bed and the ceiling.However, the existing methods only impose a classification task and fail to consider the relations among different features.On the contrary, the proposed SAFNet can learn the similarities between features and use them as semantic priors to help the subsequent segmentation process.
3.2. View choice and feature extraction
Generally,the original data is in the form of continuous video stream,of which the frames are enormous and of high overlap.Under such circumstance, in order to save the computation cost, we choose some of the views to richen the coverage of the original point cloud. To begin with, we downsample the scene point cloud and compute the overlaps not only for the point cloud, but also for all the frames from the video stream.The frame choice part happens during the training process, in which we apply a greedy algorithm to select the most informative frames with the help of the overlaps calculated before.After the chosen RGB-D frames are well prepared, we construct a 2D deep neural network in the form of U-Netso as to extract the feature maps. The neural network serves as an encoder-decoder network.To be specific,we restrict the output size to be totally the same with the size of input frames,making it convenient for the following operation. U-Net works well enough in our method because of its low resolution and we pretrain our U-Net using ScanNetV2 on 2D segmentation just like other methods,which further provide a better and smooth training process.
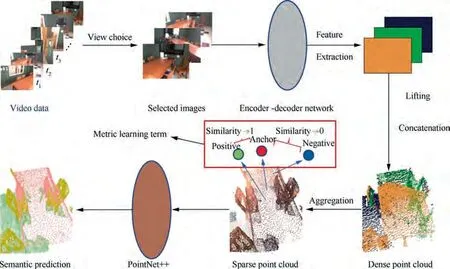
Fig. 1 Overall process of the proposed method.
3.3. Feature lifting and aggregation
The feature maps obtained above could not be directly used to aggregate the point cloud.Therefore,we need to first unproject the feature maps to a corresponding 3D point cloud.We apply the common lifting approach with the help of the camera inner parameters, which provide a fixed way of coordinate transformation.Specifically,a 2D feature map could be regarded as an overlap of several 2D images, which is of size H×W×C,where C means the channel numbers of a feature map. After the lifting operation, every feature map will be transformed to a N×C point cloud, and N is a hyperparameter defined before,which stands for the pixel numbers in 2D frames.Then,the dense point cloud could be obtained by concatenating all of the points together with the size of MN×C. However,the dense point cloud is still not qualified for the PointNet++ input, and the final prediction task is aimed at the input sparse point cloud. Hence, we use a feature aggregation method to make a connection between the dense point cloud and the target sparse point cloud.The method is similar to that in Ref.15,which employs the k nearest neighboring to directly distill new features.To be specific,let xbe a point in the target sparse point cloud,N(i)be its corresponding k nearest neighbors in the dense point cloud and fbe the feature of a certain nearest neighbor in the dense point cloud. The distilled new feature is as follows:

In this way, the sparse point cloud used for the subsequent research is completed, which is connected to the 3D coordinates.
3.4. Structural metric learning loss
Original 3D segmentation methods usually impose no constraints on the new features computed above, which may ignore some significant structural information between them.Therefore, we design a structural metric learning loss in the sparse point cloud above so that the features belonging to the same label are pulled close while the features from different labels are pushed far away.Firstly,given the distilled features,we calculate the similarity between them as follows:
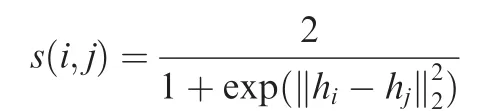

On this occasion,we can naturally formulate our structural metric learning loss as a form of cross entropy, which is as follows:
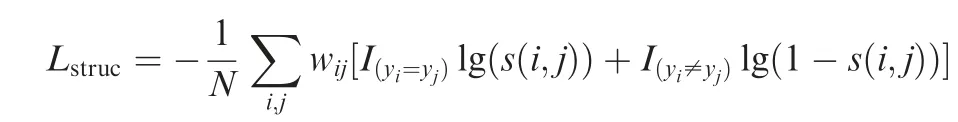
where N denotes the number of the feature pairs involved; I denotes the label; ydenotes the corresponding label; the weights ware inversely proportional to the real size of the samples, where i and j denote the sample indices.
During training,the structural metric learning loss will give punishment provided that features from the same labels are far away as well as features from different labels become close,which further improves the reliability of the sparse point cloud.
3.5. Fusion and prediction
We adopt PointNet++as our backbone which adopts a hierarchical point set feature learning structure involving a few set abstraction layers.The network takes the point cloud as input and provides the score of each point as output. Specially, the set abstraction output would concatenate the 3D coordinates in order to acquire both global features and local specific features. As for feature fusion methods, three different approaches are listed in Fig.2.The early fusion structure concatenates the 2D image features and 3D geometry before they are fed into the network, while in the late fusion, the 2D features are added to the output of the last layer before the segmentation network. Besides, the mid-model fusion method divides the encoder structure into two parts to process the 2D features and 3D geometry respectively before they are concatenated and fed into the decoder. In our method, we focus on the early fusion algorithm. Among them, the early fusion algorithm is widely applied, which concatenates the 2D image features and 3D geometry in the beginning. Under such circumstance, we could easily distinguish that abundant feature information will be extracted and utilized through PointNet++. In addition, the late fusion is commonly seen as well,which fuses the 2D image features with the output of the final propagation layer that has already encoded and decoded the 3D geometry data.However,in the mid-model fusion strategy,the encoder is divided into two parts respectively processing 2D image features and 3D geometry information, followed by the concatenation operation as well as the decoder part.Compared with the other two approaches, in this paper, we employ the early fusion strategy which not only is clear and liable to implement but also combines the detailed information of 2D image features and the geometric information of 3D point clouds through the whole structure,resulting in superior prediction performance.
4. Experiments
We conducted various experiments on the ScanNetV2and S3DISdatasets to evaluate the effectiveness of the proposed SAFNet. We also performed an ablation study to verify the contribution of each module of our SAFNet.
4.1. Datasets
4.1.1. ScanNetV2 dataset
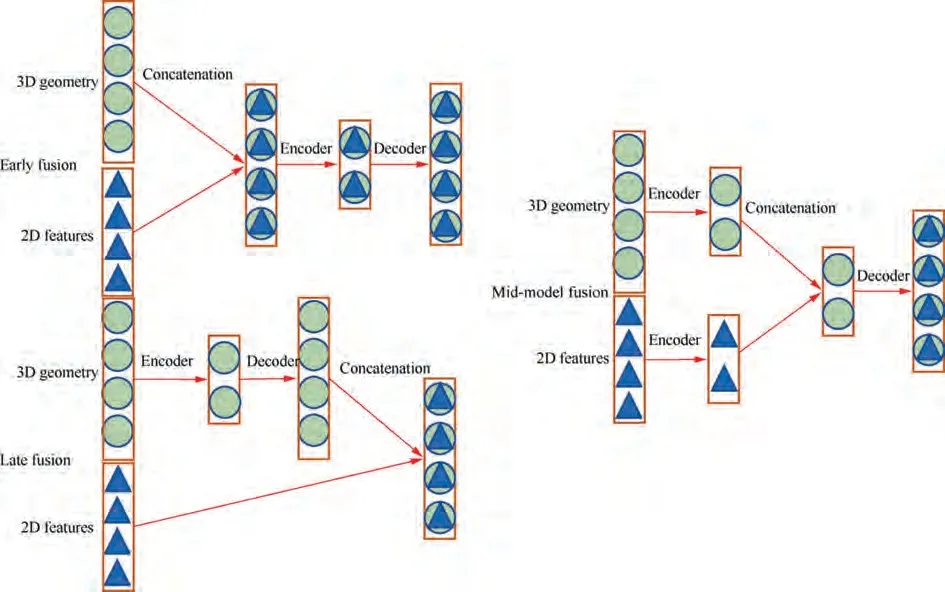
Fig. 2 Three kinds of fusion strategies using PointNet++ backbone.
The ScanNetV2 datasetcontains a number of indoor scenes such as offices and living rooms. It captures 2.5 M frames using the internal camera of an iPad equipped with another mounted depth camera. The data of each scan is composed of RGB-D sequences with related poses, the entire scene grid,and semantic and instance labels.1201 training and 312 verification scans were performed in 706 different scenes, so each scene was captured approximately 1 to 3 times. The test set is composed of 100 scans of hidden ground truth for benchmark testing. Fig. 3 shows several examples of the ground truth segmentation annotations from the ScanNetV2 3D semantic label dataset.
4.1.2. S3DIS dataset
The S3DIS datasetconsists of five large indoor areas sampled from three different buildings,where each of them covers approximately 1900, 450, 1700, 870, and 1100 square meters(total 6020 square meters). These areas present a variety of characteristics in architectural style and appearance, mainly including office areas,educational exhibition spaces and meeting rooms, personal offices, toilets, open spaces, halls, stairs,and corridors. One area includes multiple floors, while the remaining areas have one floor. Each entire point cloud is automatically generated using the Matterport scanner without any manual intervention. They detect 12 semantic elements containing structural elements (ceilings, floors, walls, beams,columns,windows,and doors)and common objects and furniture (e.g., tables, chairs, sofas, bookcases, and wooden boards).
4.2. Experimental settings
We strictly follow the experimental settings of MVPNetfor fair comparison. For 3D semantic segmentation, we follow the same chunk-by-chunk pipeline as PointNet++.During training, if the entire scene contains more than 30% of annotation points,a chunk(1.5 m×1.5 m on the xy plane,parallel to the ground)is randomly selected from the entire scene.Random rotation along the upper axis is used for data augmentation. During the test, the network predicts all chunks with a span of 0.5 m in a sliding window through the xy plane.Majority voting is performed on points with multiple chunk predictions.
We downsample each image and depth map to reach a resolution of 160 × 120. During the training process, we apply random horizontal flips to augment the image. For a resolution of 160 × 120, we fix the number of un-projected points of each RGB-D frame to 8192 pixels out of 19,200 pixels.Even if a number of pixels are not lifted to the 3D space, they are still of great importance for the feature calculation in 2D in the receptive field of the un-projected pixels.
We adopt the ImageNet pre-trained VGG16with batch normalization and dropout as the backbone of the 2D encoder network.We customize the 2D decoder network using a lightweight variant of UNet,same as MVPNet. We add a BN layer and ReLU after each convolutional layer in the decoder.
For each chunk, we sample 8192 points from the input point cloud and expand them by the view selected by the aforementioned method. We further use a two-layer MLP with 128 and 64 channels as the feature aggregation module.In order to predict the labels of multi-view feature-aggregation point clouds, we adopt PointNet++ together with Single-Scale Grouping (SSG) method as the 3D backbone.
Each epoch includes 20000 randomly sampled chunks,where the batch size of each chunk was set to 6. We use the SGD optimizer to train the network for 100 epochs.We adopt a weight decay of 0.0001 and a momentum of 0.9 for the SGD optimizer. We set the learning rate to 0.005.

Fig. 3 Examples of ground truth segmentation annotations from ScanNetV2 3D semantic label dataset.

Table 1 Comparison of the proposed SAFNet with state-of-the-art methods (with point clouds as the input) on ScanNetV2 3D semantic label dataset.

Table 2 Comparison of the proposed SAFNet with state-of-the-art methods (with point clouds and RGB data as the input) on ScanNetV2 3D semantic label dataset.

Table 3 Comparison of the proposed SAFNet with state-ofthe-art methods (with voxels as the input) on ScanNetV2 3D semantic label dataset.
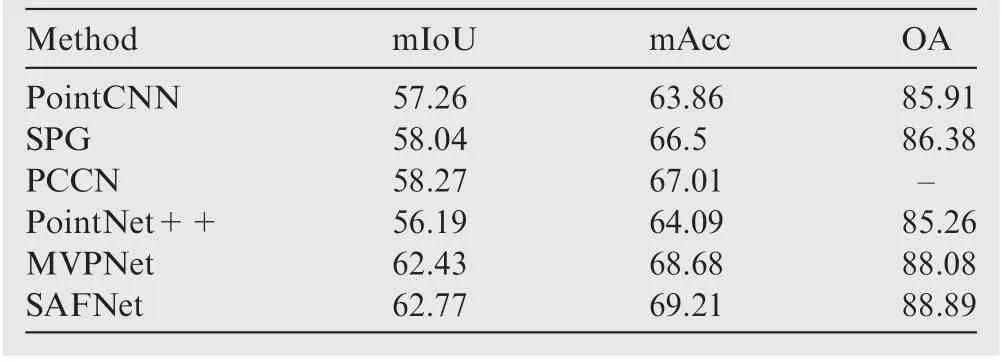
Table 4 Comparison of the proposed SAFNet with state-ofthe-art methods on Area 5 of S3DIS dataset.
4.3. Results and analysis
4.3.1. Comparison with state-of-the-art methods on ScanNetV2 3D semantic segmentation benchmark
We first evaluated our SAFNet based on the ScanNetV2 3D semantic labeling benchmark. We used the average IoU(mIoU) of the total 20 categories as the evaluation metric.For fair comparison, we ensembled 4 models of SAFNet containing 5 views with ResNet34 as the 2D backbone.
We compare the proposed SAFNet with the state-of-the-art point cloud based methods as shown in Table 1. We can see that our SAFNet achieves better results to all published point cloud based methods including PointConvand PointCNN.This demonstrates the effectiveness of the proposed SAFNet of lifting 2D image features to 3D for structural fusion. This is especially essential for flat-shaped classes (e.g., refrigerators,pictures,curtains,etc.),since they lack discriminative information for point-cloud-based methods to predict.
Table 2 shows the comparison of the proposed SAFNet with state-of-the-art methods with both point clouds and RGB data as the input on the ScanNetV2 3D semantic label dataset. The superior results of our methods demonstrate the effectiveness of using a structural metric learning loss to aggregate the information from both RGB and 3D point cloud data.
Table 3 shows the performance of our method compared to the recent voxel-based methods.3DMVis similar to our joint 2D-3D network only in the voxel-based domain and does not match our performance. We can see that there exists a gap between our results and those of SCNHowever, we argue that our SAFNet is much faster to train compared with SCN.
4.3.2. Comparison with state-of-the-art methods on S3DIS dataset
We also evaluated our SAFNet on the S3DIS dataset to further verify its effectiveness. Table 4 shows the performance of the proposed SAFNet compared with the existing state-ofthe-art methods, where mAcc denotes mean accuracy, OA denotes overall accuracy. We observe that our method can outperform the other methods on all the evaluating metrics.This further verifies the importance of mining the structural relations between the 2D RGB data and the 3D point cloud data.
4.3.3. Qualitative results of SAFNet
We conducted additional experiments on the ScanNetV2 dataset. Fig. 4 shows the qualitative results on 3D semantic segmentation of our SAFNet on the ScanNetV2 dataset. We can see that the proposed method can output good segmentation results due to the exploitation of structural relations. We also visually compared the 3D segmentation results of our SAFNet with the counterpart using only the 3D point clouds as inputs, as shown in Fig. 5. We observe that incorporating 2D information clearly improves the quality of the segmentation results. Specifically, we can see that only exploiting 3D information tends to output segmentation areas with irregular boundaries, while the proposed SAFNet utilizes 2D information to correct these falsely classified boundaries.
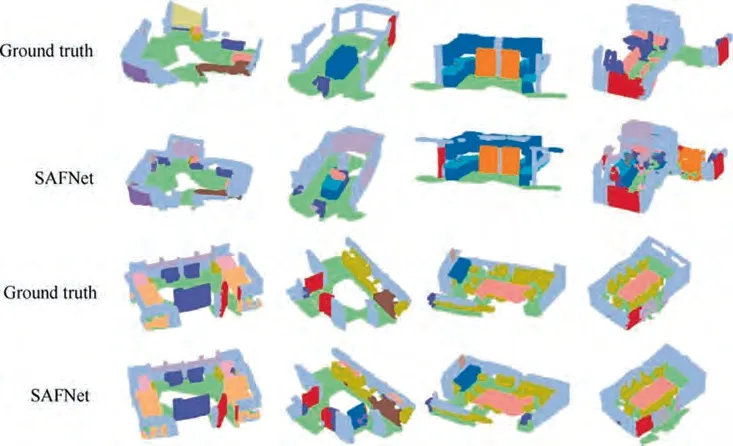
Fig. 4 Qualitative results on 3D semantic segmentation of the proposed SAFNet on ScanNetV2 dataset.

Fig. 5 Qualitative comparison of the proposed SAFNet with the counterpart using only 3D point clouds as inputs.

Table 5 Performance of the proposed SAFNet under different model settings on ScanNetV2 3D semantic label dataset.
4.3.4. Analysis of each module of SAFNet
We present the ablation study of the proposed method. We conducted all the following experiments on the ScanNetV2 dataset, but we observe similar results on the S3DIS dataset.
Table 5 shows the performance of the proposed SAFNet under different model settings on the ScanNetV2 3D semantic label dataset. We observe that removing the proposed structural loss hinders the performance of the network, which demonstrates the importance of the structural loss. We can also see that only using the point cloud data without additional RGB feature decreases the performance by a large margin.This justifies the necessity of fusing both point cloud features and RGB features as complementary information.
5. Conclusions
(1) In this paper, we have presented a structure-aware fusion network (SAFNet) for 3D scene understanding.
(2) The proposed SAFNet improves the performance of the existing data fusion methods by using a structural deep metric learning method on pixels and points to explore the relations.
(3) We further utilize them to adaptively map the images and point clouds into a common canonical space for prediction.We have conducted an ablation study to verify the effectiveness of the proposed network design and demonstrated the competitive performance of the proposed method on the widely used ScanNetV2 and S3DIS datasets for 3D scene understanding.
(4) In the future,we are interested in extending our method to more general data fusion problem,which can be used to further improve the performance of various tasks such as face recognition using both RGB and infra-red data.
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgement
This study was supported by the National Natural Science Foundation of China (No. 61976023).