
自适应重加权池化深度多任务学习的表情识别
2022-04-21 07:24王晓峰
计算机工程与设计 2022年4期
王晓峰,王 昆,刘 轩,郝 潇
(1.山西大学 物理电子工程学院,山西 太原 030006;2.国网山西省电力公司检修分公司,山西 太原 030000)
0 引 言
人脸表情作为人类最为直观的一种情感表达方式,随着计算机技术的发展,人脸表情识别一直受到了广泛的关注[1]。自动人脸表情识别不仅在安全防范、辅助医疗等领域有广泛应用,在智能控制、自动驾驶等人机交互领域也起着关键性作用[2]。然而,人脸表情识别也是计算机视觉中一项具有挑战性的任务。传统表情识别方法通常包括图像预处理、特征提取和表情识别3个步骤,其中特征提取质量直接影响人脸表情识别分类的鲁棒性,并且图像预处理的效果对保证识别准确度至为重要[3]。
传统的表情识别特征提取方法一般分为基于静态图像和基于动态图像的特征提取算法。其中Gabor小波法、局部二值模式(local binary pattern,LBP)等方法[4]是鉴于静态图像进行的特征提取的算法。而根据动态图像进行的特征提取算法主要有差分图像法、光流法以及根据特征点来进行跟踪等方法。在表情识别中,特征提取对于识别的准确率至关重要,直接影响到表情分类的准确性,其中表情分类法主要是隐马尔科夫以及人工神经网络算法[5]。
随着深度学习方法的发展,深度学习算法逐步替代了表情识别中的传统方法,基于深度学习的多任务学习方法(deep multi-task learning,DMTL)也被用于解决人脸表情识别中的分类识别问题。多任务学习利用包含在多个相关任务中的宝贵信息来改善所有相关任务的性能[6]。此外还开发了很多基于DMTL的面部表情识别方法,其中包括使用DMTL推断面部信息以识别面部特征[7]。但现有表情识别方法大多只考虑类别标签信息,而忽略样本空间分布的局部信息。针对这一问题,提出了一种自适应重加权池化深度多任务学习的表情识别方法。其主要创新点如下:
(1)为了同时考虑类别标签信息和样本空间分布的局部信息,提出一种判别式DMTL方法,将判别性局部空间分布信息添加到softmax损失中;
(2)为了利用来自训练样本的判别信息,设计了一个孪生神经网络,通过自适应重加权模块并利用具有不同置信度的类别标签信息来评估局部空间分布;
(3)针对常用池化算法存在特征信息提取模糊,甚至丢失等问题,所提方法通过参数的选取改进自适应池化方法以提高特征提取的灵活性。
1 相关研究
1.1 多任务学习
作为一种机器学习范例,多任务学习利用多个相关任务中包含的有价值的信息来改善所有相关任务的性能。通过在不同任务之间共享信息并利用这些任务之间的相似性,这是一种转移学习[8]。文献[9]提出了一种新颖的任务自适应激活网络(task adaptive activation network,TAAN),从具有完全共享的网络其它参数的数据中导出针对不同任务的灵活激活功能。文献[10]提出了一种多任务人脸推理模型(multi-task facial inference model,MT-FIM),在多任务学习的框架下,通过提取和利用适当的共享信息来同时学习人脸识别和表情识别,MT-FIM同时最小化了类内分散,最大化了不同类之间的距离,从而使每个单独的任务都具有健壮的性能。但这些方法对于多任务的学习均忽略了局部样本信息,导致识别效果不佳。
随着深度多任务学习(DMTL)的发展,其作为一种高效的机器学习技术,在人脸表情识别中得到了广泛的应用。文献[11]提出了一种区改进DMTL面部表情识别方法,通过同时考虑类别标签信息和样本的局部空间分布信息来获得完整的人脸特征,用于完成表情识别。然而,现实中的情况往往更为复杂,在进行人脸图像的采集过程中往往会出现光照强度不一、姿势不断变化、人脸出现略微变形以及障碍物对人脸造成遮挡等,这也是导致人脸表情识别率相对较低的主要原因。因此,对于满足实际的需求来说,还存在着一定的差距[12]。
1.2 深度神经网络
随着深度学习技术的发展,已有包括卷积神经网络(convolution neural network,CNN)和孪生神经网络等多种神经网络算法得到了广泛应用[13]。其中孪生神经网络由两个使用共享参数的重复子网组成。当前,孪生神经网络已被应用于诸如语音特征分类和文本分类等诸多领域。如文献[14]研究了面部图像序列中的情绪强度估计的连体和三联体网络能力,其中提取了由于面部表情模式中自然起始顶点偏移变化而出现的时域中的顺序关系,并且连体和三联体网络的分支有助于产生更确定的输出。当处理相似的顺序图像时,此属性提高了网络通用性。但是,由于人脸表情的微妙和复杂性,这些方法在实际条件下效果不佳。
CNN尤其是在图像处理和视频处理领域体现出了其优越的能力。文献[15]提出了一个新颖的框架,可以共同学习人脸表情图像的空间特征和时间动态,使用深度网络从每个帧中提取空间特征,同时通过卷积网络对时间动态建模。但是,该方法不能充分利用人脸图像中的信息,容易导致关键信息的错判和漏判。另外,文献[16]提出了一种基于深度学习方法的面部表情识别方法,采用长短期记忆网络(long and short term memory network,LSTM)存储单元的卷积神经网络从图像序列中提取相关信息,并基于单帧图像和历史相关信息进行表情判断。该方法实现了深度学习模型构建过程中参数的自适应初始化,但在整个处理过程中自适应程度较低,因此,识别准确度仍存在提升的空间。
2 提出的人脸表情识别方法
为了提高人脸表情识别的准确度,提出了一种利用自适应重加权和自适应池化的DMTL人脸表情识别模型,主要由两部分组成,分别是生成器和判别器,其中生成器由特征提取器和特征合成器组成,如图1所示。
对于特征提取,提出改进的自适应池化方法,用于改善特征提取的灵活性。且设计了一个孪生神经网络,通过自适应重加权模块并利用具有不同置信度的类别标签信息来评估局部空间分布。
同时,在判别器中利用判别式DMTL算法,充分考虑样本的局部信息。判别式DMTL的结构如图2所示。
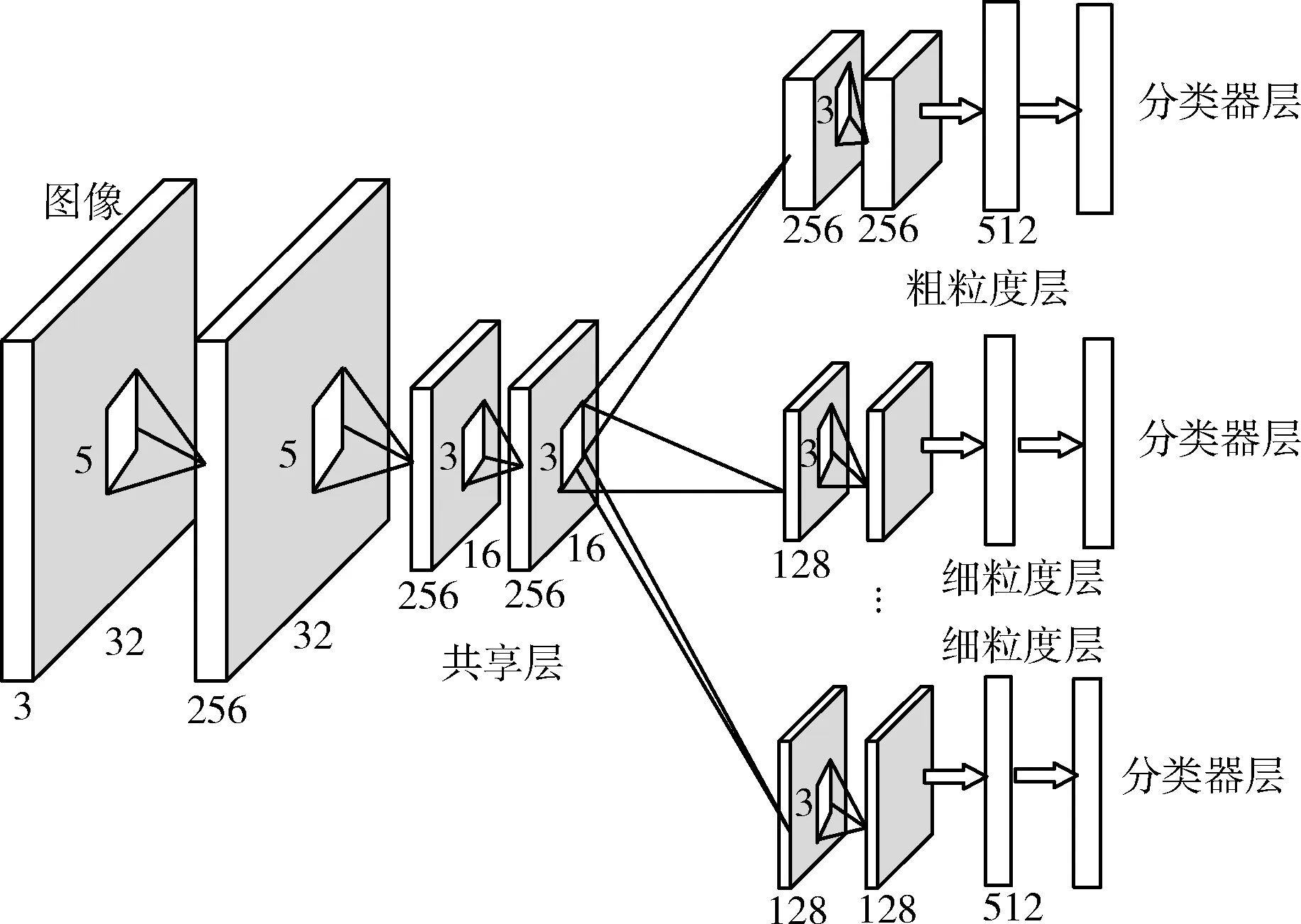
图2 判别式DMTL的结构
判别式DMTL网络中的前3个卷积层为共享层,后3层为粗粒度层和细粒度层,细粒度层的卷积层卷积核数降低至原来的1/4。
2.1 判别性深度多任务学习
本文基于判别式DMTL方法,使用自适应重加权模块,以softmax损失进行判别,从样本中获取局部空间分布信息[17,18]。为了结合类别标签信息与约束损失,设计一种具有两种损失函数的孪生神经网络:判别性softmax损失,使用类别标签信息和样本的局部空间分布信息;对比损失,有助于有效防止过度拟合问题。假设给定一个数据集X,该数据集X由来自M个不同类别的N个样本组成,则判别性softmax损失可以表示为
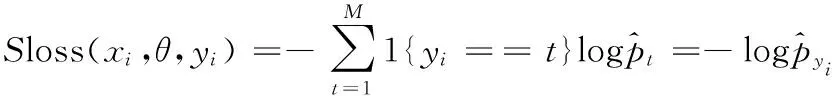
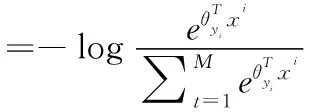
(1)
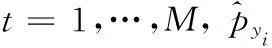
判别式DMTL的目标是利用来自训练样本的判别信息。因此,提出了一个自适应重加权模块ωk,将局部空间分布信息添加到提出的孪生神经网络中。另外,基于样本对之间的置信度将权重分配给每个样本的重加权模块既可以最小化相似样本之间的距离,又可以最大化不同样本之间的距离。则该方法的判别性softmax损失函数定义为
SL(xi,xj,φ1,φ2,yi,yj)=

(2)
式中:xi和xj是与训练样本xi和xj对应的网络输出;yi和yj是与xi和xj对应的类标签;φ1和φ2是两个softmax损失的参数。自适应重加权模块ωk通过提供特定的本地分布信息来提高分类性能。
2.2 自适应重加权
为了设计自适应重加权模块ωk,考虑用高级表示来表征同一类别的样本,而不使用不同类别的样本。因此,可以将pCON(xi,xj)定义如下
(3)
式中:Nk(xi)是xi个k个最近邻的集合,max{k-d(xi),d(xi,xj)} 是从xi到xj的可达距离。即,如果xi和xj足够接近,则可达距离为k-d(xi);如果xi远离xj,则可达距离为d(xi,xj)。当k=5时,可达距离的说明如图3所示。
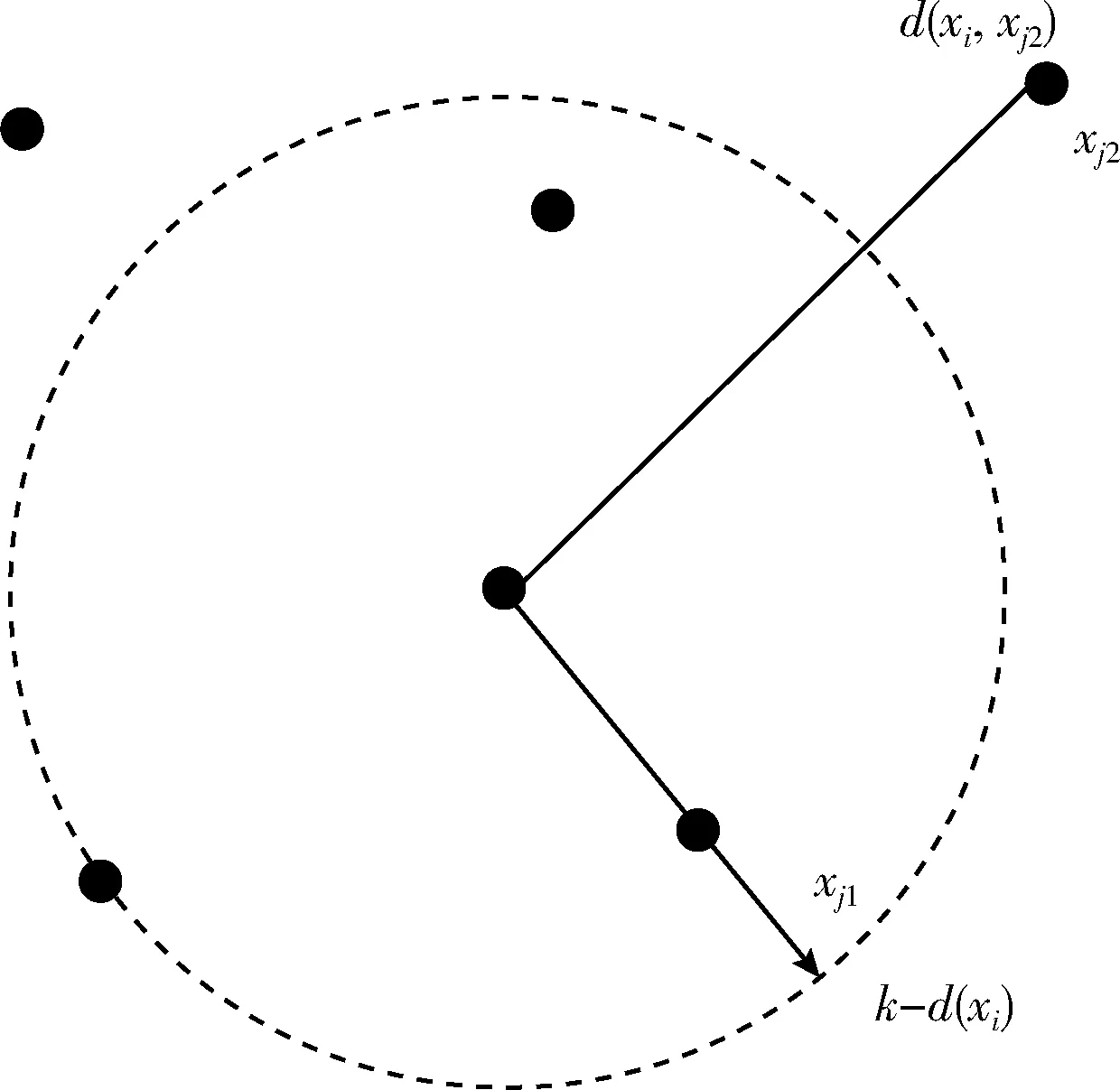
图3 d(xi,xj2)和k-d(xi)
如果对象xj远离xi(如图3中的xj2),则两个对象(即对象xi和对象xj2)之间的可达距离是它们的实际距离。如果对象xj足够接近xi(如图3中的xj1),则在计算两个对象(即对象xj和对象xj1)之间的可达距离时,实际距离将由xi的k距离代替。因为对于所有接近xi的xj,d(xi,xj)的统计波动都可以大大减少。因此,参数k可以控制平滑效果的强度,这将导致接近的对象达到相似的可达距离。
由于pCON(xi,xj)是一种概率算法,因此可以将自适应加权模块ωk定义为
(4)
式中:T表示迭代次数,G表示局部高斯统计量转换,可用于缩放概率值。判别式DMTL迭代不能有复杂的过程。但可以通过足够长的迭代收敛到相似的结果[19]。
2.3 自适应池化算法
2.3.1 常用池化算法的劣势
由于各种不同类型的池化算法间的区别只取决于所选的卷积核,因此,池化算法通常被视为卷积运算,池化操作后的特征矩阵S为
(5)
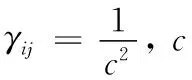

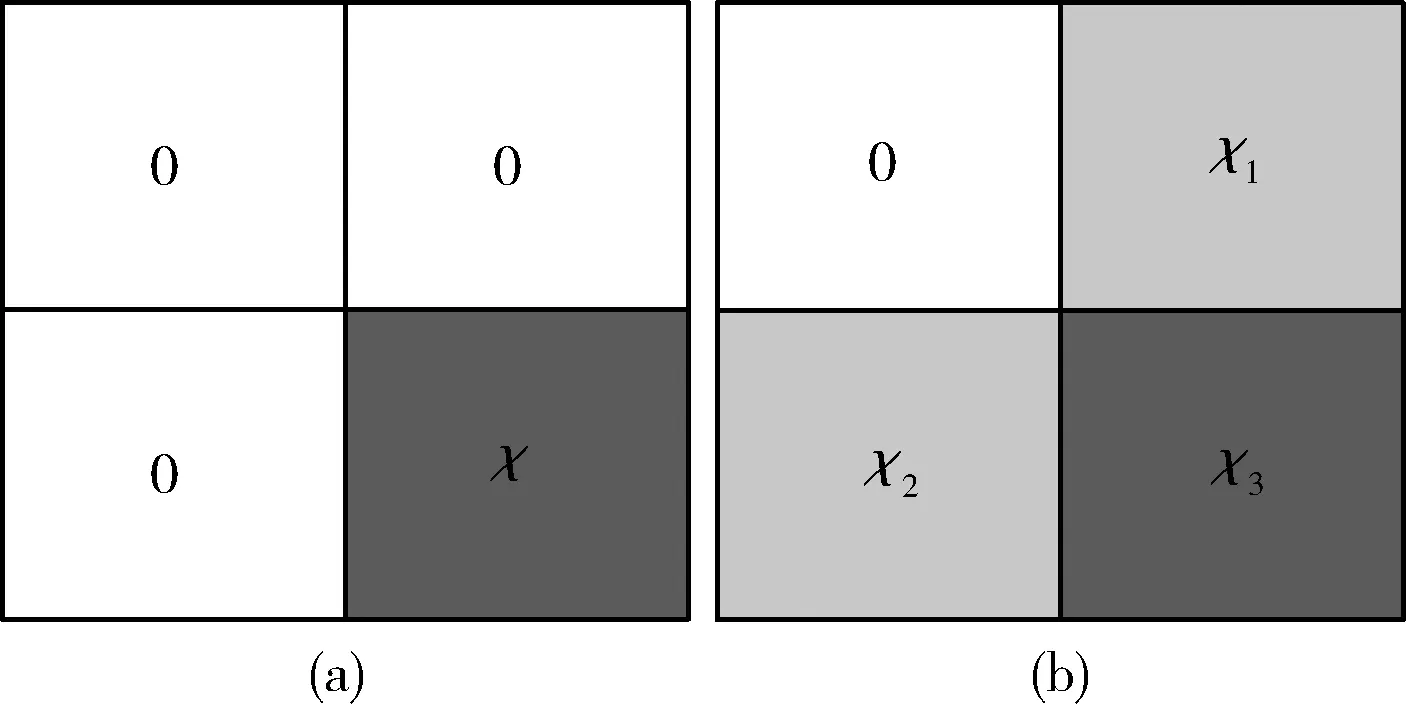
图4 不同池化域
2.3.2 自适应池化算法的原理
由上文的分析中我们得知,对于传统的池化算法来说,在进行卷积神经网络训练时卷积核的参数取值是固定的。此外,也无法基于训练样本和在训练过程中发生的变化来选择合适的参数。因此,该方法会造成提取的特征信息存在不清晰,以及重要特征信息缺失等问题,仍不是最佳的方法。
能对人脑的自主学习能力进行模仿,这是人工神经网络中最重要的特征。其中,人脑主要是通过阅读、倾听等方式来对外界信息进行接收从而完成自主学习的过程;同理,人工神经网络也有一个学习的过程,该过程是通过对所得样本集进行训练的过程,也可以理解为是对复杂函数关系的一个寻找过程。若神经网络定义的函数式能满足训练样本集时,就表示完成了网络模型训练;反之,便再次对网络模型参数进行相应的调整,该过程直至定义的函数关系能满足训练样本集时才停止[20]。
上文所提的几种传统的池化方法都存在着各自的缺陷,而人工神经网络由于其自身的特点,即能通过在大量的训练集中不断进行监督训练,从而能对参数的特点进行多次修正,最终得到在各种的场景下都能适用,并且能够进行自适应动态修正的卷积核参数[21]。
2.3.3 实现方法
本文在根据自适应池化算法的基础上,对其进行了改进提出了一种自适应改进池化算法。该算法的主要步骤为:①对池化内的参数都进行初始化操作,也就是对卷积核参数γ进行初始化;②在训练中,池化值是在采用卷积操作后得到的;③在进行训练迭代时,通过采用梯度下降法对参数γ进行更新;④在多次迭代和优化参数后,最后完成了自适应池化操作[22]。
自适应池化算法的过程为:
第一阶段:将人脸图像所得到的灰度矩阵作为输入,再经过判别式DMTL的映射关系后,最后输出对人脸表情类别的预测值。
第二阶段:基于之前得到的预测值以及真实值,使用损失函数对两者之间的差值进行计算。其中,SVMLoss和SoftmaxLoss这两种损失函数是在进行判别式DMTL的训练过程中使用最为广泛的两种函数,本文采用的是SoftmaxLoss,其表达式如下所示

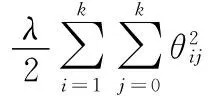
(6)
其中,最后的预测值记为y;θ表示神经元间的权值;示性函数由l{} 进行表示,若 {} 中表达式为真则取1,反之取0;权重衰减项则是由式中第二项所表示。
在每次训练迭代中,基于所得的SLoss值对网络模型的参数进行适当的调整,使得损失函数的参数能达到最小,从而使预测的结果能更加接近实际值。
第三阶段:基于损失函数,并使用梯度下降法对池化参数γ进行更新,以得到最优参数,也就是找到损失函数的极小值。表达式如下
(7)
其中,步长以及学习率均由ε进行表示;损失函数记作f()。
最终池化算法的参数值在经过多次的迭代和更新,以及不断收敛达到损失函数的极值后便可获得。
3 实验结果与分析
实验基于MATLAB仿真平台展开,其中实验的硬件环境设置成:主要采用的操作系统为Linux、系列为E5-1620 v4 的CPU、CPU的时钟频率为3.5 GHz、型号为NVIDIA Quadro M2000,显存的大小为2 GB。使用的深度学习平台是基于Caffe。
本次实验中对多种数据集进行了采集,在CK+数据集和MMI数据集上分别采集了2940幅和31 570幅图像,在FER2013数据集上分别对其训练集和测试集采集了572 796幅和71 620幅图像。由于不同数据集采集的图像在数量上存在着差异,因此,分别对不同数据集图像的输入大小进行了处理,将CK+和MMI数据集上的图像分别调整为227×227 像素和128×128像素后再进行输入;在FER2013数据集上将图像大小调整为42×42像素。为确保本次实验结果是有效的,采用了10倍交叉验证的方法。该方法是通过将CK+数据集以及MMI数据集平均分为10组,再将其中9组均作为训练集,剩下一组作为测试集;共进行10次实验,以 10次实验结果的平均值作为最终结果。在FER2013数据集中,原始测试集的扩展图像被划分成10份,在每次需要测试时便选取其中的一份,并将10个预测结果的均值作为最终的得分。如此,便可以确保每个样本都能作为测试集和训练集,还有效解决了由于一些误差较大的数据对识别率造成负面影响的问题。
在小型数据集上直接对深度神经网络进行预训练可能会导致过度拟合的问题。因此,判别式DMTL的实验模型由4个卷积层、一个完全连接层和一个softmax层组成,其中每个卷积层后面是一个最大池化层和一个局部响应归一化层。从完全连接层中提取的特征将被输入到softmax层中进行分类。
实验中将初始网络学习率设置为0.05,并且学习率在每个时期都会下降,优化处理中使用随机梯度下降法来更新判别式DMTL的参数。将所提方法与文献[10]、文献[13]、文献[16]中方法在3个数据集上进行对比论证。文献[10]提出了一种MT-FIM,在多任务学习的框架下,通过提取和利用适当的共享信息来同时学习人脸识别和表情识别。文献[13]提出一种用于面部表情识别的紧密连接CNN结构,将每个卷积层的输出连接到该结构中下一个卷积层的输入。文献[16]提出一种基于深度学习方法的面部表情识别方法,采用LSTM存储单元的卷积神经网络从图像序列中提取相关信息,并基于单帧图像和历史相关信息进行表情判断。
3.1 CK+人脸表情数据集
其中,在对人脸表情识别系统的评估中,最常用的实验室控制数据集是CK+数据集。该数据集拥有593个视频序列,都是从123个对象中进行提取得到的。该数据集中的序列持续时间各不相同从10帧到60帧,将人脸表情由中性到高峰表情的转变过程进行了展示。在这些视频序列中从118个实验对象中提取的327个视频序列中,均有着7个基础的表情标签,它们分别为:生气、蔑视、讨厌、害怕、高兴、伤心和惊讶等表情,这些都是根据面部运动编码系统得到的。其中在CK+数据集中的中性表情是通过采用蔑视的表情来代替的,由于CK+数据集并没有特意设置训练集、验证集以及测试集,因此,其并没有统一的算法评估。借鉴静态图片的方法,一般情况下,大部分人采用的方法是将图像中拥有高峰表情的最后1帧到3帧和每个序列的第一帧(中性面)进行提取,再将提取的数据分为n组,最后进行n倍的交叉验证实验,一般n取5、8、10。CK+表情分类的图像示例如图5所示。

图5 CK+数据集上7个表情图例
经过10万次的迭代训练之后,计算10倍交叉验证后的人脸表情识别率,所提方法与3种对比方法在CK+数据集上得到的最终结果如图6所示。
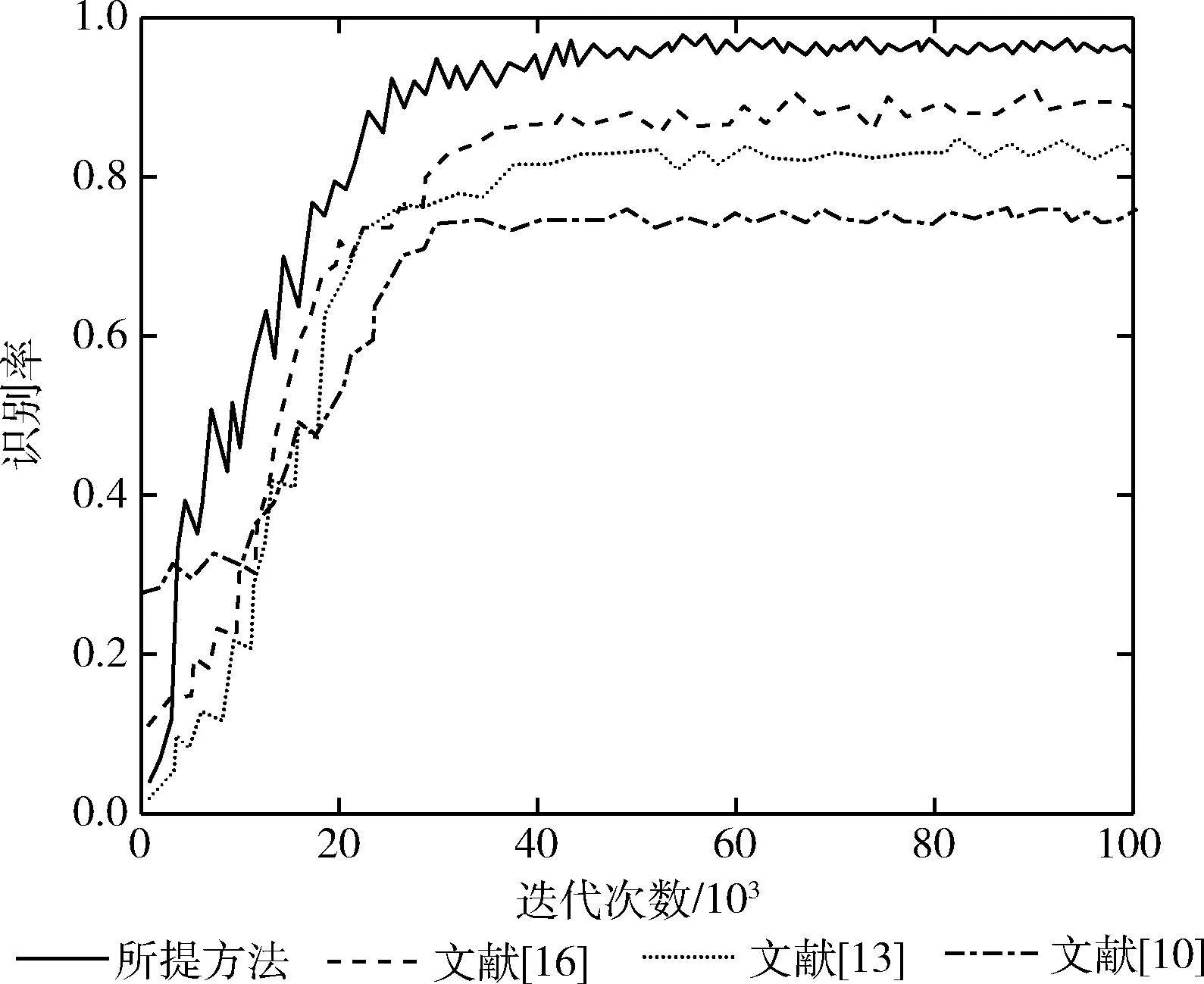
图6 CK+数据集上不同方法的识别率对比
从图6中可以看出,经过40 000次的迭代,测试的识别率已逐步趋于稳定,即表示这是在经过充分收敛后得到的结果。在CK+数据集中,相比于其它方法,所提方法的识别准确率最高,为95.2%。文献[10]中的MT-FIM方法利用适当的共享信息完成表情识别,受信息特征的影响较大,识别准确率较低。文献[13]和文献[16]均采用了深度神经网络,但文献[16]结合LSTM网络提取表情特征,因此识别准确度稍高。
为更好的对所提方法和其它方法的性能优势做出说明,本文将测试集作为其它对比网络的输入,并将混淆矩阵作为评判性能的指标,在CK+数据集上的结果如图7所示。
从图7中可以看出,所提方法在7种表情的识别率均优于其它对比方法,并且对于高兴和惊讶表情的识别准确率超过97%,对于讨厌和蔑视表情的识别准确率低于90%,对于害怕表情的识别准确度最低。这是因为害怕和悲伤的表情在某些情况下彼此相似,导致它们在像素空间中并没有区别,因此经常会引起混淆。此外,所提方法中采用判别式DMTL中使用样本之间的局部空间分布信息实现最佳的表情识别效果,将相似样本之间的距离最小化,并将不同样本之间的距离最大化。
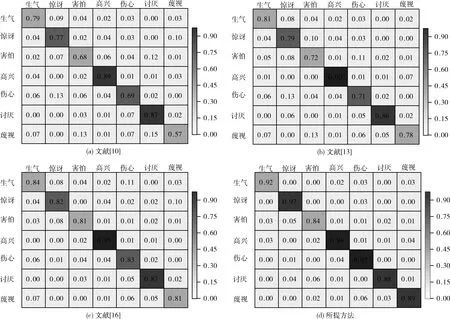
图7 CK+数据集上不同方法的混淆矩阵
3.2 MMI人脸表情数据集
MMI数据集是实验室控制的数据集,包括来自32个受试者的326个序列,其中213个序列用6种类型的表情标签标记,并且在正面视图中捕获了205个序列。每个序列以中性表达开始和结束,在序列中间附近达到面部表情的峰值。在实验中,选择序列中间附近的3个帧作为峰值帧,并将其与它们的表情标记相关联。图8显示了MMI数据集中的一些样本图像。由于MMI数据集仅包含少量样本数据,这不足以训练深度神经网络,因此从CK+数据集中补充了具有相同表情的其它数据作为实验数据。将8组MMI数据集与其它CK +数据集组合为训练集,并将其它2组MMI数据集用作评估和测试集。

图8 MMI数据集的部分示例图像
经过10万次的迭代训练之后,计算10倍交叉验证后的人脸表情识别率,所提方法与3种对比方法在MMI数据集上得到的最终结果如图9所示。
从图9中可以看出,经过40 000次迭代,测试的识别率趋于稳定。文献[10]和文献[13]的识别准确度较低,低于0.8,而所提方法的实验结果仍保持着较高的识别准确度,最高时比文献[16]大约高7%以上。由于所提方法采用判别式DMTL包含样本的其它判别信息,因此其性能优于其它对比方法,由此也验证了判别式DMTL的稳定性和鲁棒性。

图9 MMI数据集上不同方法的识别率对比
本文通过将测试集分别输入到不同的对比网络中,并以混淆矩阵作为评判性能的指标,来进一步验证所提方法相比于其它方法具有更好的性能,最终MMI数据集上的结果如图10所示。
从图10可以看出,与CK+数据集上的实验结果相比,所有表情的识别准确率均有所下降,尤其是所提方法害怕表情的识别准确率仅为54%,这表明人脸表情识别是一项艰巨的任务。但所提方法在7种表情的识别率均高于其它对比方法,这也论证了其鲁棒性,适用于多种数据集。
3.3 FER2013人脸表情数据集
由35 886张人脸表情图片组成了FER2013人脸表情数据集,该数据集中共有28 708张测试图,其中包括公共验证图3589张、私有验证图3589张,并且每张图片有固定大小为48×48灰度图像,其中主要有7种表情,为生气、厌恶、恐惧、开心、伤心、惊讶和中性。该数据集是将人脸的表情、图片的数据以及用途数据直接存储到csv文件中,而非以图片形式给出。实验中使用pandas解析csv文件,即可提取表情图片。
经过10万次的迭代训练之后,计算10倍交叉验证后的人脸表情识别率,所提方法与3种对比方法在FER2013数据集上得到的最终结果如图11所示。
从图11中可以看出,经过30 000次的迭代,测试的识别率基本保持平稳。在FER2013数据集中,相比于其它方法,所提方法的识别准确率最高,为73.6%。由于FER2013数据集的图像像素较小,且数量庞大,在人脸表情的识别过程中容易混淆,因此识别率低于CK+和MMI数据集。
为更好验证所提方法相较于其它方法而言更具性能优势,本文将测试集输入到其它对比网络中进行计算,并以混淆矩阵作为评判性能的指标,最终得到FER2013数据集上的结果如图12所示。

图12 FER2013数据集上不同方法的混淆矩阵
从图12可以看出,相比于CK+和MIM数据集,FER2013数据集中的各表情识别率均有所下降,这是由数据集的特征造成的。但所提方法的识别率仍高于其它对比方法,尤其是对于高兴和伤心表情的识别,准确率高于80%。
3.4 执行时间对比
为了论证所提方法的识别效率,将其与文献[10]、文献[13]、文献[16]的识别时间进行对比,在CK+数据集上的实验结果见表1。
从表1中可以看出,所提方法的识别时间仅为0.082 s,由于判别式DMTL中采用了自适应重加权和自适应池化,加快了算法的收敛速度,因此完成识别的时间较短。文献[10]中MT-FIM通过提取和利用适当的共享信息来同时学习人脸和表情识别,选取信息的过程耗时较长。文献[13]采用CNN进行人脸表情识别,由于参数以及层数的原因,迭代一次所耗费的时间较长。而文献[16]采用LSTM存储单元的卷积神经网络从图像序列中提取相关信息,相比文献[13],执行速度较快,耗时较短。

表1 识别时间对比结果
4 结束语
该文提出了用于人脸表情识别的判别式DMTL方法,可以同时利用类别标签信息和样本空间分布的局部信息来处理空间分布中的局部信息丢失。判别式DMTL基于具有共享权重的孪生神经网络,旨在通过自适应重加权模块测量局部分布,同时利用改进的自适应池化方法动态调整优化参数,以提高面部表情识别的准确性。在CK+、MMI和FER2013这3个广泛使用的人脸表情数据集上对所提方法进行实验论证。实验结果表明,所提方法的识别率和执行时间均优于其它对比方法,尤其是在训练样本相对于局部信息而言较小的情况下。尽管如此,当处理组合的人脸表情数据集(即训练集由多个人脸表情数据集组合)时,虽然所提方法仍取得了理想的识别结果,但识别准确均略有下降。因此,接下来的研究将侧重于如何提高处理组合人脸表情数据集时的识别准确性。
猜你喜欢
计算机应用(2022年9期)2022-09-25
语数外学习·初中版(2022年4期)2022-06-10
软件导刊(2022年3期)2022-03-25
四川大学学报(自然科学版)(2021年6期)2021-12-27
计算机应用(2020年12期)2020-12-31
中等数学(2020年7期)2020-11-26
计算机技术与发展(2019年1期)2019-01-21
智能计算机与应用(2018年2期)2018-05-23
中学生数理化·中考版(2016年8期)2016-12-07
文苑(2015年9期)2015-09-10
