
融合LDA主题模型和支持向量机的商品个性化推荐方法
2022-04-15 06:08穆晓霞董星辉柴旭清李钧涛
郑州大学学报(理学版) 2022年3期
穆晓霞,董星辉,柴旭清,李钧涛
(1.河南师范大学 计算机与信息工程学院 河南 新乡 453007;2.河南师范大学 教育人工智能与个性化学习河南省重点实验室 河南 新乡 453007;3.河南师范大学 数学与信息科学学院 河南 新乡 453007)
0 引言
随着电子商务的普及,网络购物凭借其方便迅捷的特点成为消费者购买商品的重要方式。根据中国互联网络信息中心发布的第47期《中国互联网络发展状况统计报告》,我国网购消费者总量已经从2016年12月的4.667亿上升至2020年12月的7.82亿,累计占全部网民的79.1%[1],这说明网络购物越来越受到人们的青睐。在网络购物中,买方往往通过浏览之前购买过该商品用户的评论,对该商品进行模糊估计,以便做出符合自己需求的明智选择。然而网购平台往往充斥着冗余的用户评论数据,无法直观地为买方提供有效的信息。如何高效地利用用户的评论数据,降低买卖双方的时间成本,成了一个亟待解决的问题。
目前,针对数量巨大、种类繁多和爆炸式增长的用户评论数据,张敏[2]提出利用LDA主题模型实现对其倾向性判断以及所隐藏信息的挖掘与分析;冯兴杰等[3]通过建立一种基于评论个性化多层注意力的商品推荐算法,使得用户和商品相匹配;孙含笑[4]通过朴素贝叶斯分类算法对用户评论进行类别训练,并提取评论中的敏感词汇,进而找到商品改进的突破点。
在现有研究中,多数推荐算法仅注重挖掘评论文本,而极少考虑如何制订适合每个用户的个性化推荐方案。电商平台应该从用户的喜好出发,推荐满足用户需求的个性化产品,降低用户的时间成本和搜寻成本,达到帕累托最优状态。本文以智能手机商品为例,提出了一种融合LDA主题模型和支持向量机的商品个性化推荐方法。首先通过对评论数据进行主题建模,得到不同商品的特点并对其进行量化;然后利用支持向量机寻找与用户期望评分最为匹配的商品,以实现个性化的推荐。
1 相关理论
1.1 LDA主题模型
LDA主题模型是一种在概率潜在语义分析的基础上以Dirichlet先验分布为主的文档主题生成模型[5]。LDA主题模型采用词袋的方法把复杂的、非结构化的用户评论信息转化为简单的数字信息[6]。LDA主题模型产生的贝叶斯网络如图1所示。其中,θ表示文本中主题分布向量;z表示文本在每个单词上的N维主题向量;w表示文本中单词的向量表示;M代表文本数量;N代表每个文本中词语的数量;α表示文本所对应Dirichlet分布的参数;β表示单词所对应Dirichlet分布的参数。

图1 LDA主题模型的贝叶斯网络Figure 1 Bayesian network of LDA topic model
LDA主题模型的生成过程为:首先从参数α、β的先验分布中取样,生成文本在主题上的分布θ以及主题在单词上的分布φ;其次从θ和φ的多项式分布中采样主题向量z和单词向量w,其中主题向量z和单词向量w可以通过Gibbs抽样技术以及变分EM算法[7]获得。本文选用实用性较高的Gibbs抽样技术来对LDA主题模型的参数进行估计。
此外,主题数目对LDA主题模型的抽查率和独立性有较大的影响[8],如何适当地选取主题数目是非常关键的。在现有研究中,通常利用层次Dirichlet过程[9]、贝叶斯模型[10]、LDA矩阵分解等方法确定最优主题数目。由困惑度确定的主题数目往往偏大,导致不同主题之间的相似度过高,不利于商品个性化的推荐。基于此,本文采用基于困惑度与主题相似度相结合的指标(Perplexity-Var)[11]来确定主题数目。
困惑度的计算公式为
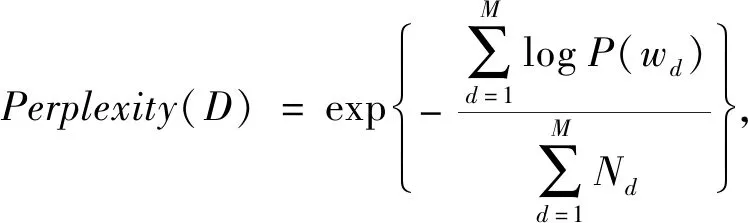
(1)
其中:M代表文本数量;Nd代表每个文本中单词的数量;wd代表文本d中的单词;P(wd)表示文本中单词wd产生的概率。
考虑到KL散度方法不满足对称性,本文采用JS散度方法来计算不同主题之间的相似度,JS散度计算主题相似度的公式为

(2)

困惑度-主题相似度的计算公式为
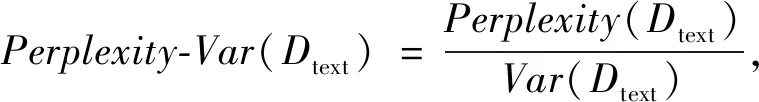
(3)
其中:Dtext代表文本的测试集;Perplexity(Dtext)代表测试集的困惑度;Var(Dtext)代表测试集的方差。
1.2 支持向量机多分类算法
支持向量机[12-13]是一种基于统计学习理论对数据进行分类的方法。非线性支持向量机通过映射函数将原有的样本数据投射到更高维度的特征空间上,并构造线性分类函数进行分类。本文选择高斯径向基函数作为核函数,
K(Xi,Xj)=exp(-‖Xi-Xj‖2/2δ2),
(4)
其中:X为训练元组;δ为高斯径向基函数的参数。选择核函数后,支持向量机的性能就主要受两个参数的影响,即错分样本的惩罚因子C以及核函数的参数δ[14]。相较于网格搜索算法优化支持向量机以及遗传算法优化支持向量机[15-16],基于粒子群优化算法的参数选择方法具有能够大范围遍历搜索、收敛速度快等优点[17],故本文选用基于粒子群算法的参数选择方法来确定支持向量机的参数。
通过采用数据划分策略,二分类支持向量机能够被用来处理多分类问题。常用的数据划分策略有一对一、一对多、有向无环图多分类方法,纠错输出编码方法等。为了进一步简化分类器的复杂度,减少大规模样本的训练时间,选择一对一支持向量机分类方法来解决对训练样本的多分类问题。采用一对一支持向量机分类方法,共需要N(N-1)/2个分类器。其中,在训练i、j两类样本时,需要解决以下优化问题:
(5)
其中:K是将xt映射到高维特征空间的高斯径向基函数;C为惩罚因子。
2 融合LDA主题模型和支持向量机的个性化推荐方法
为了更好地利用已有商品评论数据来拟合潜在用户的喜好,本文提出一种融合LDA主题模型和支持向量机的商品个性化推荐方法,主要包括以下四个步骤:① 对评论数据进行预处理;② 提取评论数据的主题关键词;③ 量化关键词;④ 利用支持向量机算法,将用户对不同主题下的期望评分与已有评分标准相匹配,实现个性化推荐。
2.1 评论数据预处理
为了提高用户评论数据的质量,保证数据质量的准确性、完整性和一致性,需要对现有的用户评论数据进行预处理。本文主要对评论数据进行去重与清洗、文本分段与分句、分词、去除停用词、词性标注以及词频统计等六步预处理工作。
2.2 提取关键词
首先,建立用户评论的LDA主题模型,通过Gibbs抽样技术可以得到用户评论的“文档-主题”和“主题-单词”两个概率分布。然后,对每个主题下的内容进行分词以及词频统计,得到各个主题所包含的高频词,将这些高频词进行归纳处理,可得出用户购买商品时所关注的商品属性。
2.3 量化关键词
在弄清影响用户购买商品的主要因素后,需要对商品在不同主题下的特点进行量化。通过SnowNLP类库来判断用户评论数据中的每个词语是否为情感态度词,然后对每条评论进行打分。打分的依据是评论中含有积极情感态度词语的占比,其数值介于0到1之间。将打分阈值设置为0.3,得分不小于0.3的评论视作积极、正向的评论;得分小于0.3的评论视作消极、负向的评论。然后利用LDA主题模型以及SnowNLP类库得到某一具体用户评论在对应主题下的得分并循环遍历,直至得到所有评论数据在相对应主题下的得分。
2.4 个性化推荐
在得到量化得分后,利用粒子群优化算法来选择支持向量机的参数。在参数确定之后,把其中某一类商品的用户评论数据样本作为一类,记为正类别;把剩余的用户评论数据样本作为另一类,记为负类别。重复上述操作,依次进行学习训练,直到所有的类别都被分离出来为止。在决策时,利用“投票法”进行待分类样本的类别判断,根据待分类样本类别的结果,寻找出与潜在用户期望评分最接近的商品,从而实现个性化推荐。
3 实验结果与分析
3.1 数据来源
为了验证模型的可靠性,从京东旗舰店按照销售量找出最热销的三款智能手机,分别记为甲(HUAWEI Mate10)、乙(HUAWEI nova3)、丙(HUAWEI P20)。利用Python的Request库和Re正则表达式循环爬取这三种类型智能手机在2020年2月12日到2021年2月12日的用户评论数据,共计18 346条。
3.2 数据的预处理
数据的预处理步骤如下。
Step 1 评论数据的去重与清洗。删除重复的评论或者用户没有回复但系统自动评论的无用数据,共215条;删除存在缺失或者超短的用户评论数据,这些评论不具备可参考性,共81条。
Step 2 文本分段与分句。先删除用户评论中的空格以便对文本进行分段,然后通过识别评论数据中的断句符号来进行分句。
Step 3 评论数据的分词。相较于基于统计分词方法以及基于混合分词方法,基于规则分词方法较为方便、可靠。因此,本文通过使用Python中较为成熟的Jieba分词工具来对用户评论数据进行分词。
Step 4 评论数据去除停用词。在分析用户情感时,这类词没有太大的参考意义且出现频率很高,在一定程度上会影响用户情感分析的结果。本文使用哈尔滨工业大学的停用词表来过滤这类词。
Step 5 评论数据的词性标注。常用的词性标注方法有基于规则的方法、基于统计模型的方法以及基于转换的方法三种。本文使用基于统计模型的词性标注法对用户评论数据进行标注。
Step 6 词频统计及生成词云图。从理论上来说,某一个词在某一类型产品中出现的次数越多,就越能代表该产品的共同特征。利用Python进行词频统计,可以分别得到甲、乙、丙的词频统计以及词性标注,并生成甲、乙、丙的用户评论的词云图,如图2所示。

图2 三种类型手机的词云图Figure 2 Word cloud pictures of three types of mobile phones
通过图2的词云图可以直观地看出,智能手机的外观、电池续航能力、拍照、运行速度等是大多数用户所关注的重点。
3.3 基于LDA的主题建模
在对用户评论数据预处理之后,采用LDA主题模型对用户评论数据的主题进行提取。具体步骤为:采用Gibbs抽样技术进行参数估计,并设置LDA的先验参数α=50/T,β=0.01,其中T为模型的主题数目。运行迭代次数越多,模型的效果越优。为了防止过度拟合,设置运行迭代次数G=500,利用基于困惑度与主题相似度相结合的方法来确定最优主题数目,可以分别得到主题数目与Perplexity的关系(图3),以及主题数目与Perplexity-Var的关系(图4)。

图3 主题数目与Perplexity的关系Figure 3 The relationship between the number of topics and Perplexity

图4 主题数目与Perplexity-Var的关系Figure 4 The relationship between the number of topics and Perplexity-Var
从图3可以看出,当主题数目T=28时,LDA主题模型的Perplexity指标达到最小;从图4可以看出,当主题数目T=5时,Perplexity-Var指标达到最小。通过对两者进行比较,从侧面表明评论数据中可能存在一些相似度极高而干扰主题的文本。因此,选取T=5作为LDA主题模型的主题数目。
3.3.1关于文档-主题的概率分布 选取用户评论数据,通过LDA主题模型可以得到用户评论数据的文档-主题概率分布,结果如表1所示。

表1 部分用户评论数据的文档-主题概率分布Table 1 The probability distribution of document-topic for partial user comment data
3.3.2关于主题-单词的概率分布 基于LDA模型还可以得到用户评论数据的主题-单词概率分布,结果如表2所示。
对每个主题下的具体内容进行分词以及词频统计,可以得到各个主题所包含的高频词,结果如表3所示。
从以上5个主题可以看出,用户在购买智能手机时大体都会考虑两个方面的问题:第一个是商品本身的一系列性能是否符合自己预期的标准;第二个是商家的服务、物流速度是否令自己感到满意。

表2 部分用户评论数据的主题-单词概率分布Table 2 The probability distribution of topic-word for partial user comment data

表3 各个主题所包含的部分高频词Table 3 Some high-frequency words contained in each topic
3.4 量化关键词
利用LDA主题模型以及SnowNLP类库可以得到每一条用户评论在相应主题下的得分,遍历甲、乙、丙三种类型商品的用户评论,最终得到甲、乙、丙三种类型手机的得分数据,结果如表4所示。
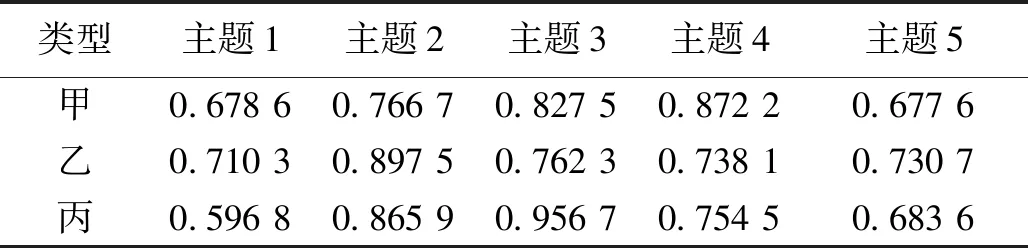
表4 三种类型手机的部分得分数据Table 4 Some score data of three types of mobile phones
3.5 支持向量机多分类个性化推荐
从已有的用户评论得分数据中随机选取3 000条作为实验数据,其中甲、乙、丙用户评论各1 000条。依据商品类型,从每100条中随机选取25条评论得分数据作为测试集,共计750条;剩余的评论得分数据作为训练集,共计2 250条。同时,为防止过度拟合,采用5折交叉验证,并设置惩罚因子C的取值范围为0.1~100,核函数的参数δ的取值范围为0.01~10。最终得到的适应度曲线如图5所示。可以看出,当遗传算法运行到150代以后,最佳适应度达到最大值且保持稳定,此时输出的最优参数C=15.764 7,δ=3.782 7,适应度为98.88%。

图5 适应度曲线Figure 5 Fitness curve
3.6 实验结果验证
在得到分类结果之后,需要进一步对分类结果进行评估。甲、乙、丙三种类型手机的分类准确率如表5所示。

表5 三种类型手机的分类准确率Table 5 Classification accuracy of three types of mobile phones
从表5可以看出,甲、乙、丙的分类准确率均超过了98%,表明该方法具有一定的有效性和可行性,可应用到其他一般商品的推荐中,为潜在用户提供一种切实可行的商品选择方案。当用户想要购买某种商品时,只需要输入关于该商品在不同主题下的预期评分,系统便会通过支持向量机多分类算法为用户推荐合理化的选择方案,这在一定程度上减少了用户在进行信息搜索时所带来的时间成本,更有利于用户做出满意的决策。
4 小结
针对网络商品评论数据不能有效引导买方做出合理选择的问题,提出一种融合LDA主题模型和支持向量机的商品个性化推荐方法。本文在方法上的一个创新是对评论数据建立LDA主题模型,并利用SnowNLP类库对其进行量化。此外,通过支持向量机将潜在用户期望评分与已知的商品评分相匹配,能够在众多商品中寻找出与之最为接近的商品,进而实现个性化推荐的目标。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
文苑(2020年4期)2020-05-30
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
少儿科学周刊·少年版(2015年3期)2015-07-07
小天使·四年级语数英综合(2015年7期)2015-07-06
中学生物学(2008年2期)2008-07-07
