
基于原始单通道脑电图的高效睡眠自动分期方法
2022-04-15 06:08陶雨洁
郑州大学学报(理学版) 2022年3期
陶雨洁,杨 云,2,3
(1.云南大学 软件学院 云南 昆明 650504;2.昆明市数据科学与智能计算重点实验室 云南 昆明 650504;3.云南省高校数据科学与智能计算重点实验室 云南 昆明 650504)
0 引言
睡眠是人类最重要的生理活动之一。《2015年中国睡眠指数报告》显示,我国约有31.2%的人存在严重的睡眠问题。长期的睡眠紊乱不仅会降低生活质量,影响个人的工作和生活,还会引发一系列躯体和精神疾病[1]。多导睡眠图是一项客观评估睡眠质量的睡眠研究,它由多个传感器采集到的多种电讯号构成,包含脑电图、眼电图和心电图等数据。其中,脑电图的使用最为广泛,通常由训练有素的睡眠专家根据睡眠手册[2-3]将脑电图分类为不同的睡眠阶段。由于手动划分睡眠阶段的过程对睡眠专家的专业知识要求较高,并耗费大量时间与人力,因此难以大规模应用。在早期使用机器学习方法处理睡眠分期任务中,研究者们热衷于先提取各类统计特征,再使用机器学习方法对选取的最佳特征子集进行分类,但因特征难以穷尽且评价标准多样,给睡眠分期任务带来了巨大的工作量。随着深度学习的迅速发展,凭借其无须先验知识便能提取高水平特征并进行自动分类的出色能力,逐渐被研究者们应用在睡眠分期任务上。
现代生活中具有睡眠困扰的人越来越多,但绝大多数人尚未达到就医标准。因此,使用少量数据实现高效的睡眠分期,对睡眠质量的日常监测显得愈发重要。不同于现有的多通道特征提取工作,基于原始单通道脑电图的高效睡眠自动分期方法是利用原始单通道脑电数据实现高效便捷的端到端睡眠分期。本文设计了一种混合神经网络模型,将Inception结构增加网络宽度以及将并行学习多尺度特征的思想应用在睡眠分期任务上,并使用长短期记忆网络(LSTM)学习脑电信号中的时间依赖关系;提出时移滚动方法与加权交叉熵损失函数,缓解因数据类别不平衡导致的模型过拟合问题。所提方法仅使用原始单通道脑电数据便可实现高效的端到端学习,且无须任何手工处理,有利于降低实验对数据采集设备的要求。
1 方法
1.1 模型结构
卷积神经网络(CNN)是深度学习的代表算法之一。Inception[4-7]是一种典型的二维CNN结构,其核心思想是通过多个卷积提取不同视角的特征并进行融合,以得到更好的图像表征。Inception由多个并行的卷积操作(通常采用1*1卷积、3*3卷积、3*3池化等不同尺度的卷积操作堆叠而成)共同组成,如此小且并行的卷积操作使得Inception模型参数量约为VGG 16的1/28,且性能相似,因此更适合内存或计算资源有限制的场合,为家庭可穿戴设备的模型开发提供了很好的思路。具体而言,本文采用Inception v4结构中的reduction A模块,使用两个级联的3*3滤波器代替一个5*5滤波器,以减少一定的计算量。在使用1*1滤波器对数据进行降维的同时引入更多的非线性,使用Batch normalization[5]修正均值和方差并加速神经网络的训练。与多数CNN睡眠分期方法[8-9]不同的是,本文并不将脑电信号转换为二维频谱图来提取图像相关特征。本文提出结合CNN与LSTM的混合神经网络模型,模型整体结构如图1所示,主要包括多尺度时不变特征提取、时间依赖特征提取、分类共三个部分。具有不同尺度的CNN分支结构,一方面通过增加网络的宽度有效防止过拟合现象的发生,另一方面强化了网络对不同尺度信息的综合学习能力。
1.2 时移滚动方法与加权交叉熵损失函数
以公开数据集Sleep-EDF[10-11]为例,所有数据被睡眠专家按照R&K标准[3]手动划分为8个阶段,分别为W、N1、N2、N3、N4、REM、MOVEMENT、UNKNOWN。根据美国睡眠医学会(AASM)的建议,将N3、N4阶段合并为单个N3,并删除MOVEMENT、UNKNOWN数据。因此,睡眠阶段分期是一个五分类问题,即W、N1、N2、N3和REM。观察发现,数据集中有近90%的数据是具有左右相同标签的数据,近6.9%的数据是具有单边相同标签的数据。该数据集的39个文件中过渡数据与非过渡数据的比较结果如图2所示,图中纵坐标代表各文件中具有左右相同纪元、单边相同纪元和左右不同纪元的标签数据量,可以得出左右纪元具有相关信息的结论。此外,睡眠阶段的分布是高度不平衡的,其中N1阶段的数据量仅占总数据量的6.6%。在睡眠分期任务中,N1阶段往往因为数据比例小、持续时间短,且与REM阶段特征相似,分期错误率极高。为了缓解N1与REM阶段易被错误划分为多类或邻近类的状况,将每个文件中N1阶段的脑电信号沿时间轴顺向或逆向滚动移位5、6、7、8、9 s,使每个阶段包含其左或右纪元的信息,同时在每个训练周期中合成具有多样性和可靠性的新数据。通过训练数据集各类别数据的数据量来设置权重,进而修改交叉熵损失函数,具体表达式为
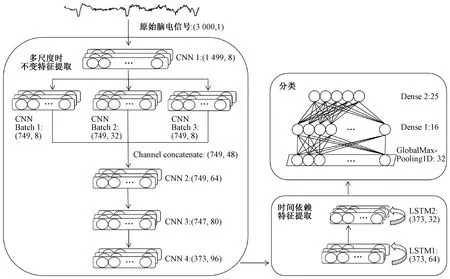
图1 模型整体结构Figure 1 Overall structure of the model

(1)

(2)
其中:c代表类别;N代表该类别的数据量;y代表标签是否与预测结果相同;p代表分类概率。

图2 39个文件中过渡数据与非过渡数据的比较Figure 2 Comparison of transitional data and non-transitional data in 39 files
2 实验设置
2.1 实验数据集
实验使用PhysioBank提供的基准睡眠数据集Sleep-EDF,该数据集可在网上公开获取(https:∥www.physionet.org/content/sleep-edfx/1.0.0/)。数据集Sleep-EDF中的数据采集于21~35岁的健康白种人,包括39个文件的多导睡眠图记录。每个记录包含水平眼电信号(EOG)、Fpz-Cz和Pz-Oz通道的脑电信号(EEG)等多种生理数据,采样频率为100 Hz。实验数据共有42 308条,各类别分布存在着明显的不平衡现象,例如N2阶段有17 799条数据,N1阶段仅有2 804条数据。
2.2 评价指标
脑电睡眠分期任务是一个多分类问题,因此除了采用整体准确率(Acc)、宏观平均F1值(MF1)外,还采用每个类的精确率(P)、召回率(R)以及F1值作为模型预测评价指标,计算公式如式(3)~(7)所示。
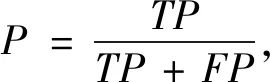
(3)

(4)

(5)
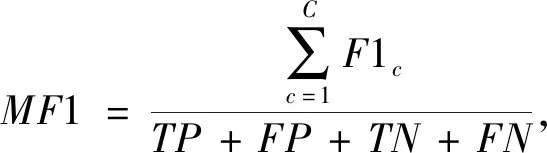
(6)

(7)
其中:TP代表真实标签为正例且被正确分类为正例的数量;FP代表真实标签为负例但被错误分类为正例的数量;FN代表真实标签为正例但被错误分类为负例的数量;TN代表真实标签为负例且被正确分类为负例的数量。
3 实验结果与分析
3.1 数据增强消融实验
实验结合时移滚动增强方法与加权交叉熵损失函数缓解数据类别不平衡问题。为了证明本文方法的有效性,与常用的两种数据增强方法(随机上采样与随机下采样),以及分别只使用时移滚动增强方法或加权交叉熵损失函数进行少类阶段(N1与REM)的F1值对比。结果表明:过采样效果优于欠采样效果,两者在N1阶段上的分类效果明显不佳;单独使用一种方法缓解不平衡问题,结果仅在一个类别上表现良好,由此说明两种方法结合使用在一定程度上实现了互补与提升。
3.2 模型组件消融实验
为了更好地理解模型各部分的重要性,进行了如下消融实验:实验1代表本文方法;实验2代表在实验1基础上将并行的卷积结构替换为单个卷积;实验3代表在实验1基础上去除LSTM结构。模型组件消融实验的F1值对比如表1所示。可以看出,实验2和实验3在睡眠各个阶段的F1值都有不同程度的下降,有效证明了本文模型中各部分的贡献。

表1 模型组件消融实验的F1值对比Table 1 Comparison of F1 values in ablation experiments of model components
3.3 实验结果分析
表2展示了在Sleep-EDF数据集Fpz-Cz通道上的总混淆矩阵及从混淆矩阵计算出的性能指标。混淆矩阵的行和列分别代表由睡眠专家和本文方法划分的每个睡眠阶段的纪元个数,加粗的数字表示模型正确分类的数量。从表2可以看出,N1阶段分类效果最差,F1值仅为44.0%;而其他睡眠阶段的F1值在79.3%到90.6%之间。其中N1阶段往往与W、N3、REM阶段发生混淆,这符合各阶段特征波的相似性。N1阶段分类效果差,这可能是由于N1阶段作为最短暂的过渡阶段,最易受到多类、邻近类与相似类的共同影响。通过观察混淆矩阵可见,预测结果并不倾向于占大多数数据量的N2阶段,这说明本文方法在一定程度上缓解了类别不平衡带来的过拟合问题。

表2 总混淆矩阵及性能指标Table 2 Overall confusion matrix and performance index
3.4 对比实验结果
表3显示了不同睡眠分期方法的性能对比结果。为公平起见,实验数据均使用Sleep-EDF数据集Fpz-Cz通道的EEG数据。结果表明,在综合指标MF1上本文方法取得最佳效果,在指标Acc上本文方法达到较优水平。

表3 不同睡眠分期方法的性能对比结果Table 3 Performance comparison results of different sleep staging methods
4 小结
本文提出一种基于原始单通道脑电图的高效睡眠自动分期方法,使用Inception并行结构学习多尺度时不变特征,利用LSTM学习脑电信号中的时间依赖关系,通过时移滚动增强与加权交叉熵损失函数缓解数据类别不平衡问题,实现了端到端的高效睡眠分期方法。在公开数据集Sleep-EDF上的实验结果表明,模型各部分能在一定程度上提升少类阶段的分类性能,与其他睡眠分期方法相比,本文方法拥有较优的性能表现。未来工作中将尝试更多的网络结构,并对睡眠各阶段的相似性开展更加全面的研究,让模型学习到更多的特征信息,进一步提升模型的整体性能。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
电脑爱好者(2020年19期)2020-10-20
海峡姐妹(2018年3期)2018-05-09
软件导刊(2018年3期)2018-03-26
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
