
基于可穿戴设备的障碍人群问题行为识别
2022-04-14 06:33:38王瑞平廖桂生张亚静
数据采集与处理 2022年2期
马 仑,王瑞平,赵 斌,刘 鑫,廖桂生,张亚静
(1.长安大学信息工程学院,西安 710064;2.西安电子科技大学雷达信号处理国家重点实验室,西安 710071)
引言
人类行为识别(Human activity recognition,HAR)技术已经在人机交互、移动和普适计算等领域得到了广泛的关注和应用。将HAR 应用于医疗保健这个新兴领域,涉及老年人和体弱者的健康监测和康复评估等[1]。基于可穿戴设备的HAR 已成为帮助患者进行康复治疗、日常行为监测以及其他健康问题的重要工具[2],如老年人的跌倒[3]和中风的康复监测[4]等。
相比于普通人群,在临床上被诊断为生理和心理层面有残疾(如自闭症、抽动症等)和有特殊需要的人群(障碍人群)所表现出的问题行为尤为引人关注。通常情况下,问题行为根据严重性和复杂性分为3 类[5]:自我刺激性行为,如不停的眨眼、挤眉、点头和摇头等;自我伤害性行为,如打自己的头、抽搐和撞墙等;破坏性行为,如打架等;这3 种问题行为普遍具有刻板性和周期性。国内外大量研究表明[5-6],问题行为已严重影响障碍人群的健康及发展。然而,鲜有研究考虑到障碍人群的行为识别。将先进的HAR 系统应用于问题行为识别,可以解放人工成本,对障碍人群融入社会提供更好的帮助。
基于传感器的HAR 研究主要集中在特征提取、特征选择和算法设计等方面。从特征角度来看,特征提取主要包括时域和频域等[7],特征选择主要包括嵌入法和包装法等[8]。特征提取作为行为识别的重要环节,提取结果的好坏在很大程度上影响着行为识别效果的实时性与准确性。特征选择能提升模型的效率,增加模型的可解释性。从算法角度来看,常用的算法分为深度学习和机器学习两类。深度学习能自动提取特征,包括卷积神经网络(Convolutional neural networks,CNN)[9]等;机器学习需要根据先验知识手动提取特征,主要包括K 近邻(K-nearest neighbor,KNN)[10]、支持向量机(Support vector machine,SVM)[11]、决策树(Decision tree,DT)[12]等基分类器和随机森林(Random forest,RF)、装袋算法(Bootstrap aggregating,Bagging)等[13]集成分类器。研究发现集成分类器可以提高识别准确率[14]。近年来,国内外研究者对不同识别算法展开研究并取得了一定的进展,虽然基于可穿戴设备的HAR 研究已取得一些成果,但目前仍没有统一的分类方法。根据所分析行为的种类、最终的应用程序、可用的计算能力和处理时间,可以选择不同的算法对行为进行识别。如何对数据进行预处理并提取有效特征,如何设计有效的算法以实现不同行为的准确识别,仍需要进一步开展研究工作。
目前,对障碍人群的问题行为进行智能感知尚未引起HAR 研究领域的广泛关注,且缺少与之相应的数据处理方法。本文拟利用可穿戴设备内置的9 轴传感器,结合先进的人工智能技术对障碍人群的问题行为进行识别。首先,通过分析问题行为的运动学特性,使用采样频率为20 Hz 的可穿戴设备对3 个位置(颈部、手腕和脚踝)的5 种行为(走路、用拳猛击头部、头部撞墙、拳打脚踢他人和抽搐)进行数据采集;进一步,探索适用于问题行为分类器的特征集,在数据处理初始阶段提取尽可能多的特征,并采用特征融合和两种特征选择方法,将所有特征划分为3 个特征子集;最后,采用2 种验证方法、5 种评价指标以及6 种分类器(SVM、KNN、DT、RF、极限梯度提升(eXtreme gradient boosting,XGBoost)和轻量梯度提升机(Light gradient boosting machine,LightGBM)进行性能评价,进而为HAR 面向障碍人群提供理论以及实践支撑。
1 数据采集和特征提取
1.1 数据采集
通过走访特殊教育学校以及文献检索[6],如表1 所示,本文选定4 种问题行为和1 种正常行为作为研究对象(样本)。其中自伤行为(行为2 和3)与伤人行为(行为4)多见于脑瘫与自闭症,尤其是特殊儿童,而抽搐行为(行为5)则多见于脑瘫与癫痫。通过分析5 种行为的运动学特征,发现行为3 和5 的主要发力部位为躯干而行为2 和4 为四肢。因此,将3 个传感器分别佩戴于测试者的颈部、手腕和脚踝。图1 为5 种行为合加速度幅值示例,根据主要发力部位,行为1、行为2 和行为4给出手腕可视化数据,行为3 和行为5 给出颈部可视化数据。

表1 问题行为描述Table 1 Description of impaired behaviors
本文使用采样频率为20 Hz 的MPU9250 传感器模拟感知障碍人群的问题行为,其由一个三轴加速度计、一个三轴陀螺仪和一个三轴磁强计组成[15]。自采集数据集收集了22 名测试者(年龄从18~39 岁,18 名男性,4 名女性)模拟障碍人群的4 种问题行为与1 种正常行为,每人每种行为分别做3 次,每次持续时间为10 s,共得到330 个样本。自采集数据集包含全身3 个部位(颈部、手腕和脚踝)数据,佩戴于3 个位置的传感器通过内置的同步模块保证其同步记录行为数据。值得说明的是,每一位测试者在实验中均佩戴实验防护装备并签署了《测试者知情同意书》。
1.2 特征提取
通常情况下,人类日常行为提取的统计特征主要为均值、方差、最大值等,以上特征能够很好区分静态行为与动态行为,且除走路等是周期性行为外,很多行为不具有周期性。由图1 可知,障碍人群的问题行为表现出较强的“类周期性”和“突变性”,且自伤行为(行为2)和伤人行为(行为4)在某种程度上存在较强的相似性。“类周期性”和“突变性”为区分正常行为与问题行为提供更高的可行性,但对于不同问题行为的分类还缺乏区分度。为探索适用于问题行为分类的特征集,如表2 所示,本文在数据处理初始阶段提取尽可能多的特征,即对3 个位置的传感器数据提取了时域、频域和小波域共108 维特征[4,7]。
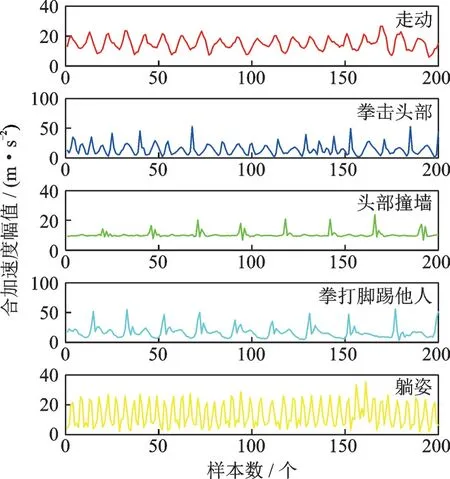
图1 5 种行为合加速度幅值示例Fig.1 Five examples of acceleration amplitude combined with behavior
考虑到问题行为的“类周期性”(自采集数据的周期一般小于2 s,对应40 个采样点),本文选取步长为20,窗口为40,重叠率为50%的滑动窗口[16]对自采集数据集进行处理,将数据分割成相同长度的序列,然后对每个序列样本提取特征,构成特征样本。值得说明的是,为了更好地从时序样本中分离出问题行为,在表2 中提取特征27~36 时,对时序样本进行了高通滤波(截止频率1 Hz)[4]。
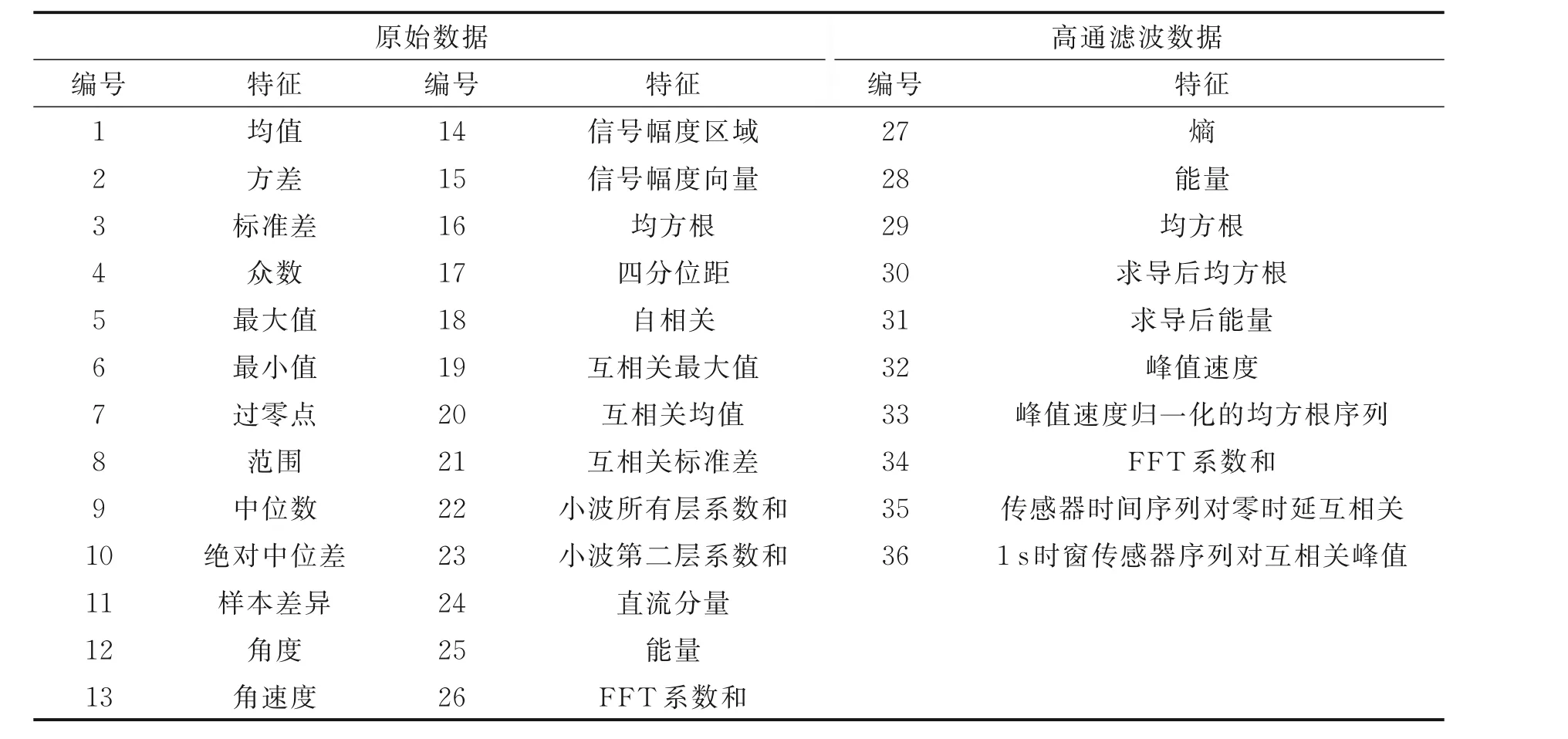
表2 传感器数据提取的特征Table 2 Extracted features of sensor data
2 数据处理
2.1 特征融合
信息融合可以用来克服单个传感器的局限性,融合可以在信号级、特征级和决策级实现[17]。本文致力于探索适用于障碍人群问题行为的特征集合,因此采用特征级融合,将不同位置提取的特征进行拼接,构成特征集。
2.2 特征选择
如上所述,本文首先建立尽可能大的特征集,从中探索适用于问题行为分类的特征子集。但高维度的特征集将引入巨大的运算开销,因此,有必要对初始特征集进行降维,选出真子集,在保证识别精度的前提下降低运算开销,进而提升模型的效率、降低学习任务的难度。
2.2.1 原理性分析进行特征选择
结合问题行为采集信号的数学特性,针对表2 特征集中各个特征对于问题行为识别的贡献进行原理性分析:
(1)特征2、特征3 能较好地反映行为中的平动[18],有助于区分行为1 和其他4 种问题行为。
(2)特征10 和17 常用于异常值检测,是识别异常值的一个标准,考虑到问题行为表现出的“突变性”,这两个特征对于区分不同的问题行为应具有较大贡献;表1 中的5 种行为均为动态行为,常规用于区别动态行为和静态行为的特征显然不适用于本文,考虑到特征19 被广泛应用于识别不同波形的相似性,进而对不同的动态行为进行分类,因此,该特征有助于问题行为识别。
(3)特征8 反映数据分布的变异范围和离散幅度,能体现一组数据波动的范围,对于类似的行为,如行为2 和行为4,标准差或平均值等特征可能是相同的,但最大值和最小值的差值却有较大的可能性是不同的,如果最大值和最小值的差值足够小,说明佩戴者处于静止状态,反之,可以根据差值的大小来对相似的行为进行分类,因此,这个特征对于区分相似的问题行为应具有较大贡献。
(4)特征25、28 和31 常用于识别具有周期性的行为[19],特征26 和34 可作为识别特定动作的关键指标[20],以上特征均是基于FFT 的频域特征,已被广泛用于捕捉与周期有关的传感器信号的重复性质,考虑到表1 中5 种行为表现出的“类周期性”,因此,上述特征对于区分这5 种行为应具有较大贡献。
(5)特征27 常用于识别具有相似能量的不同行为[21],特征16、29 和30 表示时域信号的有效值,常用于识别相似行为[22],考虑到行为2 和4 都是手腕特征较为明显,且两种行为比较相似,很可能具有相似的信号能量,以上特征对于区分这两种行为应有较大贡献。另外,文献[2]指出特征27 以及特征16、29和30 是判别运动障碍的最佳特征,鉴于运动障碍行为与本文研究的问题行为从行为学的角度来看较为相似,故认为上述特征有助于本文讨论的问题行为识别。最后,文献[4]提到特征33 和36 是检测中风后的运动能力主要依据之一,中风后患者常表现出现各种肢体运动功能障碍(如抽搐),具有较高的参考性。
综上所述,结合问题行为的运动学特点与表2 特征的数学特性,初步认定特征2、3、8、10、16、17、19、25、26、27、28、29、30、31、33、34 和36 能更好地区分表1 中的5 种行为。
2.2.2 随机森林进行特征选择
采用随机森林[23]对3 个位置的108 维特征(手腕1~36、脚踝37~72 和颈部73~108)进行重要性评估,筛选重要性分数大于0.01 的特征,如图2 所示,将108 维特征降为32 维。将随机森林选择的特征与原理性分析选择的特征进行对比,可以看出特征选择的结果基本一致,其中随机森林额外选择了特征21 同时未选择特征16、25、28 和29。
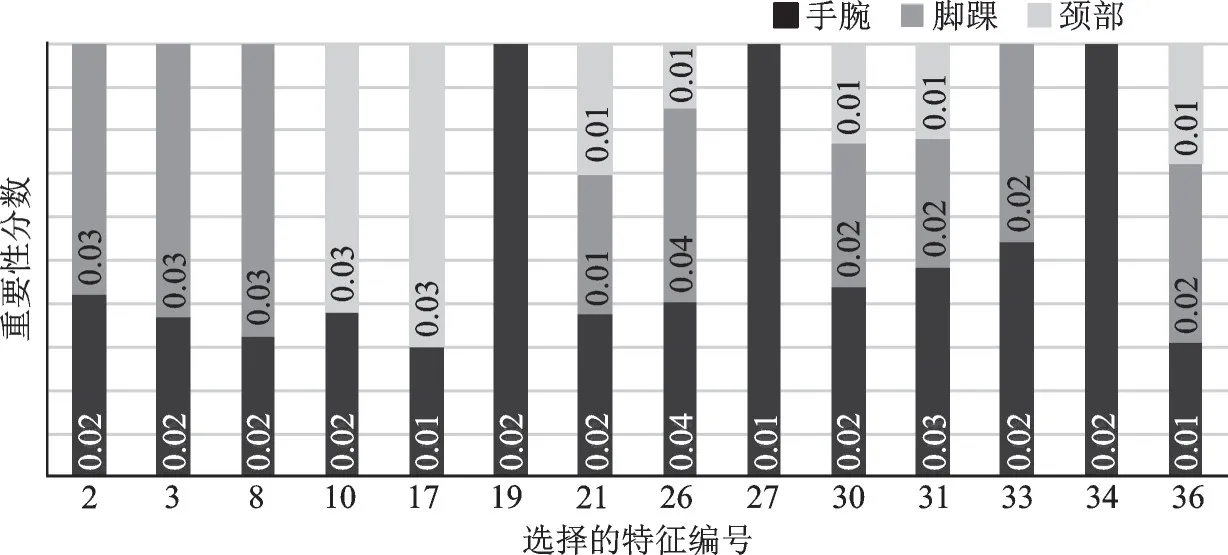
图2 随机森林特征选择结果Fig.2 Random forest feature selection results
为验证以上特征选择的可行性,进一步将特征数据划分为3 个特征子集,特征子集1:根据表2,选取初始完备特征集合共108 维特征(颈部、手腕和脚踝各36 维特征);特征子集2:根据表2 特征集中各个特征对于问题行为识别进行原理性分析选择的51 维特征(颈部、手腕和脚踝各17 维特征);特征子集3:如图2 所示,随机森林筛选的32 维特征。
3 分类方法及评价指标
本文选取3 种基分类器SVM、KNN、DT 和3 种集成分类器RF、XGBoost 和LightGBM 构成分类模型。以上6 种分类器都是在Python(scikit-learn 库)环境下实现的,分别将第2 节所选的特征输入到分类器,以完成5 种行为(4 种问题行为和1 种正常行为)识别。
本文通过两种验证方法:(1)10 倍交叉验证(将数据集分成10 份,轮流将其中9 份作为训练数据,1 份作为测试数据),将10 倍交叉验证的平均准确率作为算法识别精度的估计;(2)Holdout 验证(包含80%的训练集和20%的测试集),将测试集的准确率作为算法识别精度的估计。以准确率、精确率、召回率、F1-score[13,24]和混淆矩阵[3]作为评价指标。
4 实验结果与分析
4.1 特征融合结果与分析
如图3 所示,不同位置分类器的识别率不同,由高到低为手腕、脚踝和颈部;相同位置分类器的识别率也不同,由高到低依次为LightGBM、XGBoost、RF、DT、KNN 和SVM。将3 个位置的特征进行融合后,所有分类器的识别率都有显著提升,与手腕相比,SVM 识别率提高7%,KNN 识别率提高7%,DT 识别率提高9%,RF 识别率提高10%,XGBoost 识别率提高9%,LightGBM 识别率提高9%,故采用特征融合可以提高分类器的识别率。
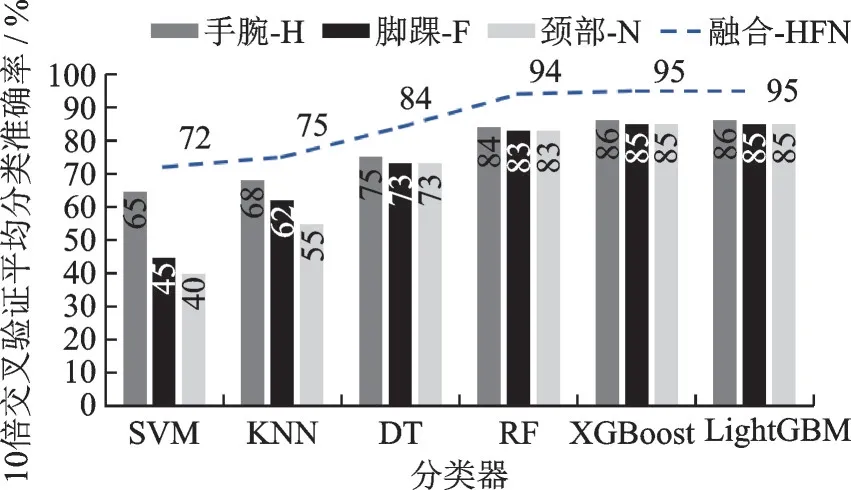
图3 颈部、手腕和脚踝传感器特征融合的分类结果Fig.3 Classification results of fusion of sensor features in neck, wrist and ankle
4.2 特征选择结果与分析
如图4 所示,对于基分类器采用特征选择后,SVM 和KNN 识别率有所提升,在特征子集3 上识别率最高约为82%,DT 的变化较小。对于集成分类器采用特征选择后,LightGBM、XGBoost 和RF识别率略微下降,在特征子集1 上识别率最高,相较于特征子集1,在特征子集2 和3 上降低约2%。3 个特征子集上分类器识别率由高到低为LightGBM、XGBoost、RF、DT、KNN 和SVM,集成分类器总体表现优于基分类器。总体来看,基分类器在特征子集3 上识别率最高,集成分类器在特征集1 识别率最高,且集成分类器在特征子集2 和3 上的识别率基本一致,说明原理性分析进行特征选择是可行的,两种特征选择方法都保留了问题行为识别的关键特征。
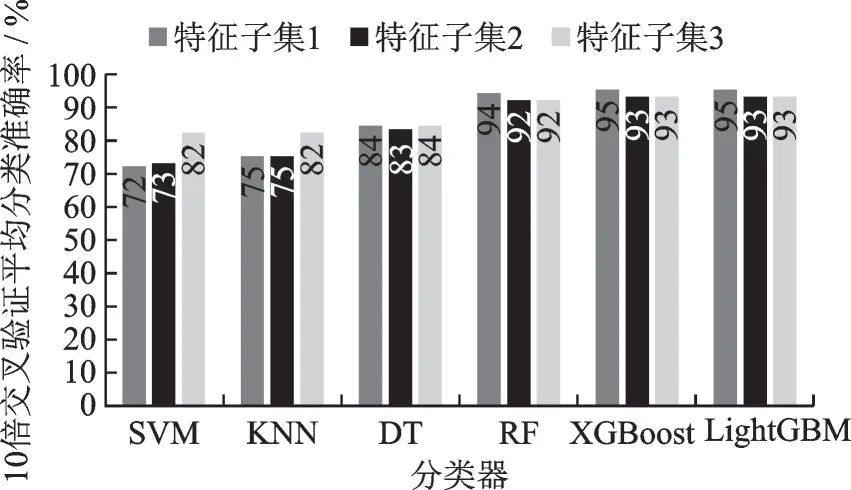
图4 不同特征集的分类结果Fig.4 Classification results of different feature sets
结合分类器的性能进一步分析,如表3 所示,Holdout 验证下,集成分类器在特征子集1 上的识别率高于特征子集3 上的识别率,但是,集成分类器在特征子集1 上的运行时间明显高于特征子集3 上的运行时间,特征选择后,集成分类器的识别率相对减少约1%,而运行时间相对减少51.9%~67.4%,说明特征子集3 能在保证识别精度的前提下降低时间开销。

表3 Holdout 验证下集成分类器的准确率和运行时间Table 3 Accuracy and running time of the integrated classifier under Holdout verification
对于基分类器,SVM 适合小样本及高维数据,但存在内存消耗大和运行速度慢的问题;KNN 容易实现,可用于非线性分类,适合小样本且精度要求不高的数据;DT 计算简单,可解释性强,运行速度比较快,但容易过拟合。对于集成分类器,RF 处理高维特征的数据训练速度快,易实现并行;而XGBoost时间消耗大,占用更多的硬件资源;LightGBM 占用的硬件资源更低,速度更快。本文要求分类器在保证精度的前提下具有较低的运算开销,根据以上分析,LightGBM 分类器在实际应用中更适用于本文针对的问题行为识别。
为进一步研究不同分类器对5 种行为的分类性能,在特征子集3 下观察识别率最高的LightGBM 分类器和识别率最低的SVM 分类器对单个行为的识别结果。如表4 所示,LightGBM 分类器和SVM 分类器10 倍交叉验证的平均识别率分别为93%和82%。在精确率方面,LightGBM 分类器在行为3 上最高为97%,SVM 分类器在行为1 和5 上最高为89%,对于其他行为,LightGBM 分类器在85%至96%之间比SVM 分类器(77%至78%)显示出更优的精确率结果。在召回率方面,LightGBM 分类器在行为1和3 上最高为97%,SVM 分类器在行为3 上最高为93%,对于其他行为,LightGBM 分类器在87%至96%之间比SVM 分类器(63%到90%)显示出更优的召回率结果。在F1-score 方面,LightGBM 分类器在行为1 和行为3 上最高为97%,SVM 分类器在行为1 上最高为89%,对于其他行为,LightGBM 分类器在87%至96%之间比SVM 分类器(69%到85%)显示出更优的F1-score 性能。LightGBM 分类器对于5 种行为识别率由高到底为行为3、1、5、2 和4,SVM 分类器对于5 种行为识别率由高到底为行为1、3、5、2 和4。综上,不同评价指标下,LightGBM 对于5 种行为的分类性能均优于SVM,且对于不同分类器,行为1、3、5 容易识别而行为2 和4 不易识别。
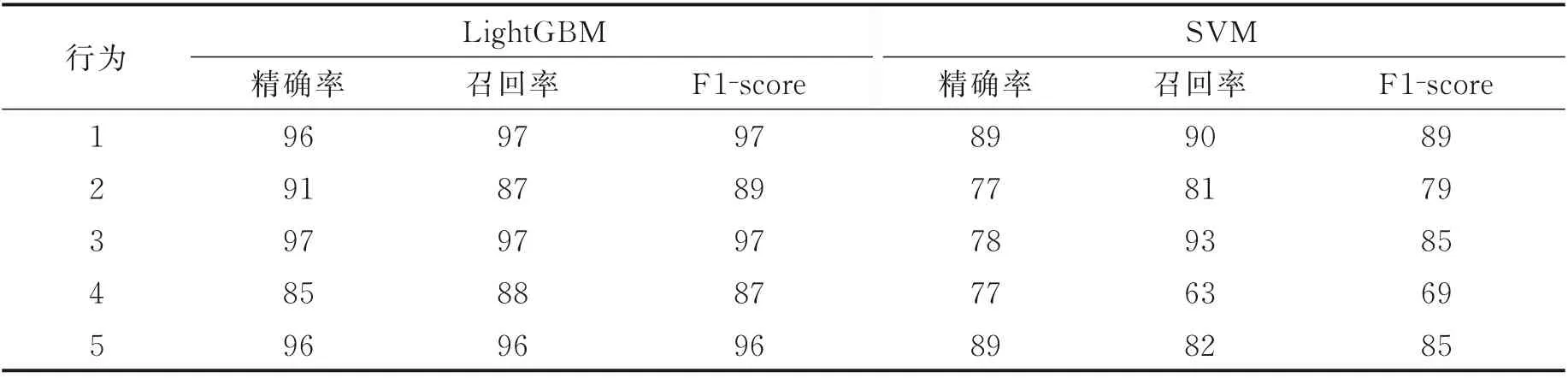
表4 LightGBM 和SVM 10 倍交叉验证的分类报告Table 4 10-fold cross-validation classification reports of LightGBM and SVM%
如图5 所示,观察LightGBM 分类器和SVM 分类器10 倍交叉验证的混淆矩阵,发现两个分类器最易混淆的行为是行为2 和行为4。如上所述,以捶打为主的行为2 和以击打为主的行为4 在腕部的运动特征较为相似,容易产生混淆,这与之前的理论分析是一致的。值得说明的是对图5 中错误概率小于0.01 的元素置零。
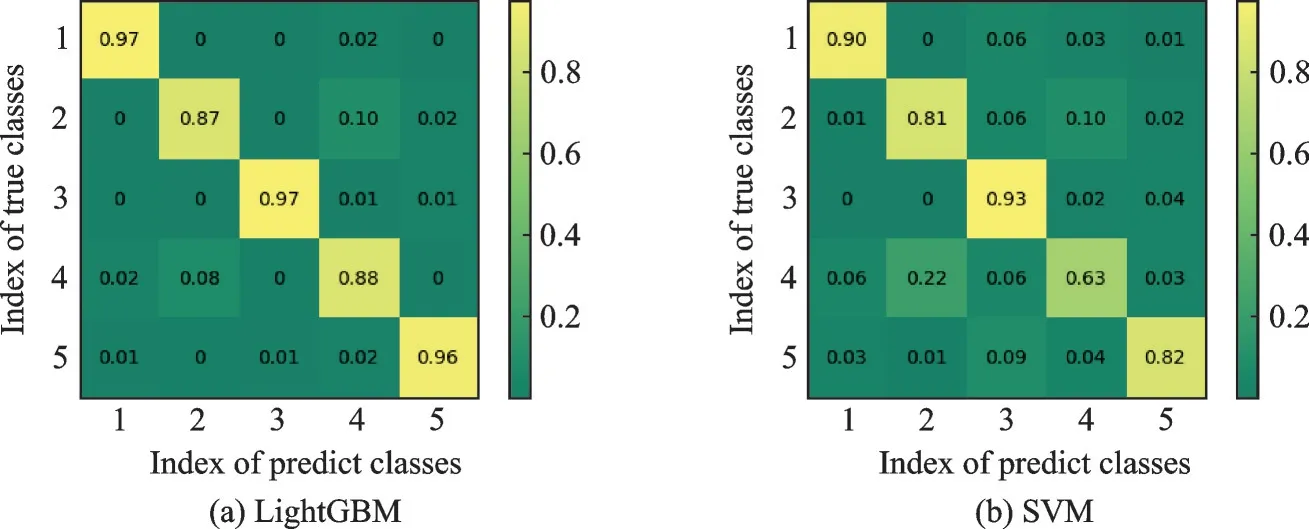
图5 特征子集3 下LightGBM 和SVM 10 倍交叉验证混淆矩阵Fig.5 10-fold cross validation of the confusion matrix of LightGBM and SVM under feature subset 3
5 结束语
针对障碍人群的问题行为,本文展开探索性研究。首先,利用可穿戴设备内置的9 轴运动传感器模拟感知障碍人群的1 种正常行为和4 种问题行为;然后,对自采集数据集进行分析和预处理,为探索适用于问题行为分类的特征集,采用特征融合和两种特征选择方法将初始特征集划分为3 个特征子集;最后,采用2 种验证方法和5 种评价指标,对6 种分类器在3 个特征子集上的分类性能进行评估。实验结果表明,本文对问题行为进行智能感知的探索性研究在理论上是可行的,有利于HAR 系统应用于障碍人群的问题行为监测,可为障碍人群融入社会提供更好的帮助。
猜你喜欢
语数外学习·高中版下旬(2023年7期)2023-09-25 00:45:13
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28 11:06:20
计算机工程(2020年3期)2020-03-19 12:24:50
南京大学学报(数学半年刊)(2020年1期)2020-03-19 02:24:44
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
中国交通信息化(2018年3期)2018-06-13 03:27:58
电子制作(2017年23期)2017-02-02 07:17:06
中国交通信息化(2016年2期)2016-06-06 07:28:02
西北工业大学学报(2015年4期)2016-01-19 03:31:47
都市丽人(2015年4期)2015-03-20 13:33:22
