
基于对比预测编码模型的多任务学习语种识别方法
2022-04-14 06:33:30赵建川杨浩铨崔忠伟
数据采集与处理 2022年2期
赵建川,杨浩铨,徐 勇,吴 恋,崔忠伟
(1. 贵州师范学院数学与大数据学院,贵阳 550018;2. 贵州师范学院大数据科学与智能工程研究院,贵阳 550018;3.哈尔滨工业大学(深圳)计算机科学与技术学院,深圳 518000)
引言
语种识别(Language identification,LID)[1]通过计算机自动判断某段音频属于哪一种语言,是智能语音处理领域的一个分支。语种识别技术在新一代信息技术中应用广泛,例如,多语种识别的语音处理技术、语音实时翻译和跨语言通信等[2]。语种识别的过程实际上是一个分类判决的过程,关键是获取分类判决有用的特征[3],其实现过程可分为3 个步骤:从语音片段中获得声学特征、从声学特征中提取有用的特征和对提取的特征进行分类判决。
语种识别的声学特征是直接从音频中提取语谱特征参数,属于帧级特征。常用的声学特征包括移位分倒谱参数(Shifted delta cepstrum,SDC)[4]、感知线性预测系数(Perceptual linear predictive coefficient,PLP)[5]、梅尔倒谱参数(Mel frequency cepstral coefficient,MFCC)[6]和梅尔标度滤波器组(Filter bank,Fbank)[7]等。语种识别技术的实现主要基于底层声学特征,其发展经历了非深度学习和深度学习两个阶段。
非深度学习阶段主要又分为基于高斯混合模型(Gaussian mixed model,GMM)和基于身份向量(Identity vector,i-vector)特征的语种识别方法。文献[8]提出了高斯混合模型-通用背景模型(Gaussian mixed model-universal background model,GMM-UBM)的方法,该方法需要庞大的数据来估计协方差矩阵。数据量不足容易导致模型参数估计不准确,且跨信道使用时性能不佳。文献[9]提出了高斯混合模型-支持向量机(Gaussian mixed model-support vector machine,GMM-SVM)的均值超向量分类算法,该方法相对于GMM-UBM 方法的识别性能有一定改善。i-vector 特征是将每条音频的GMM 超向量映射为含有音频显著特征的低维向量,这个低维向量即为i-vector。文献[10-11]使用从音频中提取的i-vector 特征进行语种识别,有效地提高了识别效果,成为当时语种识别的主要方法之一。
基于深度学习的语种识别主要有i-vector 语种识别方法和x-vector 语种识别方法。文献[12]将增加了瓶颈层的神经网络(Bottleneck deep neural network,BN-DNN)作为i-vector 的特征提取模型,对声学特征进行多层非线性映射和降维压缩,以得到鲁棒性更强的高层抽象特征。该方法有效改善了基于GMM 模型的i-vector 语种识别系统性能,对长时语音效果好,对短时语音则效果不佳。文献[13]提出了x-vector 方法,通过延时神经网络(Time delay neural network,TDNN)将不定长的语音片段映射到固定维度的embedding,这个embedding 就是x-vector。使用x-vector 特征进行语种识别相比于i-vector 特征具有更好的系统性能[14]。
研究者在x-vector 特征提取TDNN 网络的基础上进行了多种改进,以获得更有用的特征。文献[15]对TDNN 网络进行改进提出了Extended-TDNN 网络。Extended-TDNN 网络拓展了时间上下文,并加入了Dense 层,增加了网络深度。Extended-TDNN 提取的x-vector 相比于基础TDNN 提取的x-vector 性能有所提升。文献[16]提出了ECAPA(Emphasized channel attention)-TDNN 网络,采用自注意力机制和多层聚合等增强方法,进一步拓展了时间上下文,并关注到全局属性,提取出的x-vector特征在语种识别中表现出更优异的识别性能。
ECAPA-TDNN 网络是当前x-vector 特征提取最先进的网络架构[17]。 因此,本文在ECAPA-TDNN 网络的基础上结合对比预测编码(Contrastive predictive coding,CPC)模型的思想,提出一种ECAPA-TDNN+CPC 的多任务学习网络模型。以ECAPA-TDNN 为主干网络,提取语音的全局特征;改进的CPC 模型为辅助网络,对ECAPA-TDNN 提取的帧级特征进行对比预测学习。最后,通过联合损失函数进行优化训练。实验结果表明,本文提出的网络相比于基础网络ECAPA-TDNN 具有更好的语种识别性能。
1 语种识别模型
1.1 标准TDNN 的x-vector 特征提取网络
语音信号是有时序性的数据,对于语音信号的时序相关性TDNN 网络具有很好的描述能力,它能够获取语音的上下文信息,体现语音的动态特性。标准的TDNN 网络由帧级别层、统计池化层和段级别层组成[18]。帧级别层为5 层的时延网络结构,处理语音的帧级别特征。语音片段的声学特征序列X={x1,x2,…,xn}作为该层的输入,其中n表示声学特征的帧数。统计池化层对每一条语句的帧级别特征计算均值μ和标准差δ,表达式为
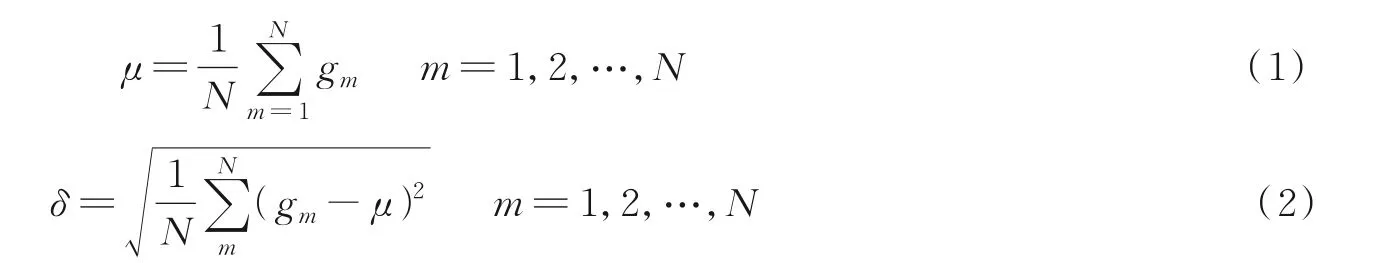
式中:gm表示帧级别特征;N表示语句的长度。
统计池化处理后得到整条语句的全局特征,但这个过程容易丢失部分语句的时序结构信息[19]。段级别层处理代表整个语音片段的全局性特征,由两层全连接层组成,靠近统计池化层的层称为Near 层,远离统计池化层的层称为Far 层,分别提取不同的x-vector 特征,输入到全连接层后面Softmax 层。
1.2 ECAPA-TDNN 的x-vector 特征提取网络
ECAPA-TDNN 网络基于标准的TDNN 网络结构设计,引入了多项增强功能以获取更强大的嵌入功能,网络结构如图1 所示。首先,池化层依赖于通道和上下文注意力机制,使得网络可以关注每个通道的不同帧,赋予每一帧不同的权重,通过自注意力机制观察语句的全局属性,扩展池化层的时间上下文信息。 其次,ECAPA-TDNN 网络加入了SE-Res2Block 模块。如图2 所示,网络通过SE 块与残差块Res2net[20]结合,重新调整帧级别层的通道数,在局部操作的卷积块中插入全局上下文信息,通过构建内部分层残差连接来处理多尺度特征,从而减少模型参数的数量。最后使用多层特征聚合将所有SE-Res2Block 的输出特征映射相连,在池化之前合并补充信息,获取更细粒度语种特征以增强系统的鲁棒性。
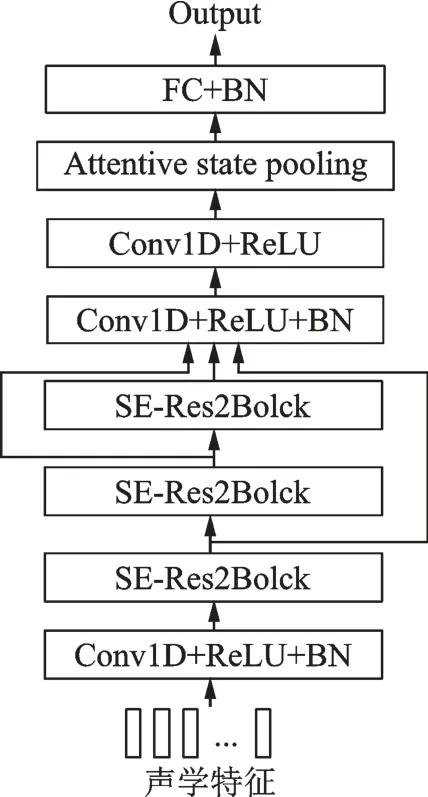
图1 ECAPA-TDNN 网络结构图Fig.1 Structure of ECAPA -TDNN network
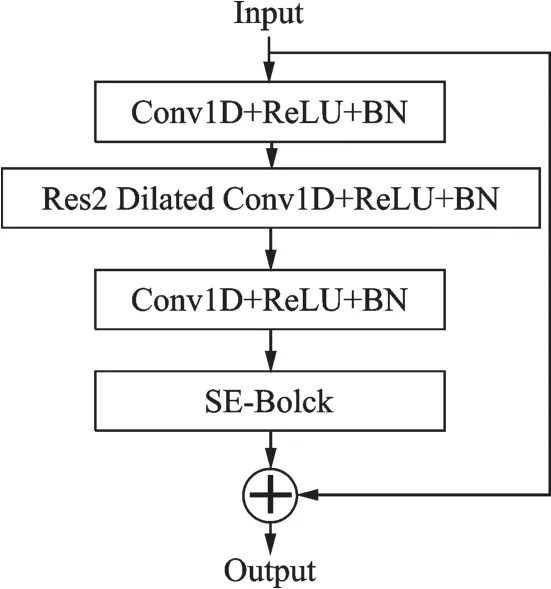
图2 SE-Res2Block 模块Fig.2 SE-Res2Block module
SE-Res2Block 模块在训练过程中为特征图分配权重,与目标关联大的分配较大权重,关联小的分配较小权重。
SE 模块首先进行压缩操作,为每一个通道生成一个描述符,得到一个帧级特征的均值向量z,表达式为

式中ht表示每个特征的embedding 向量。
然后进行激励操作,使用z中的描述符来计算每个通道的权重,即

式中:σ(·)为sigmoid 函数;f(·)为非线性函数;W1∈RR×C,W2∈RC×R,C为通道数,R为降维数;b1,b2表示偏移量。向量s包含介于0 和1 之间的权值sc。这些权重通过乘法作用于原始输入,即

式中hc表示每个通道上的原始输入。
标准的TDNN 网络在帧级层使用了较短的时间上下文信息,忽略了语音片段的全局信息。ECAPA-TDNN 网络充分考虑了语音片段的全局属性,扩展了上下文信息,在信道估计过程中关注不同帧子集,性能更好,参数更少。
1.3 CPC 模型方法
与预测编码模型相比,CPC 模型[21]是一种无监督的特征提取模型,可以从高维数据学习到对预测最有用的表征,其依赖噪声对比估计训练模型,在图像、语音、自然语言处理和强化学习等多个领域都可以学习到高层信息。CPC 模型结构如图3 所示。
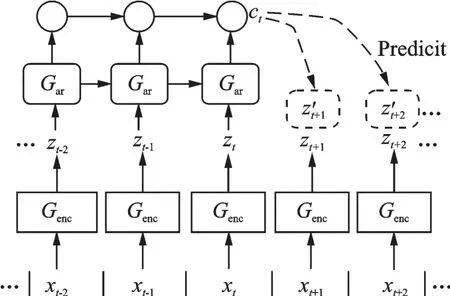
图3 CPC 模型结构Fig.3 Structure of CPC model
CPC 模型以原始语音信号作为输入,采用一个非线性编码器将分割到时间窗口上的每个特征向量xt进行编码,得到一系列的表征向量zt,表达式为

然后再将zt以及潜空间中之前所有时刻的相关信息输入到一个自回归模型Gar中,生成当前时刻的上下文表示为ct,即
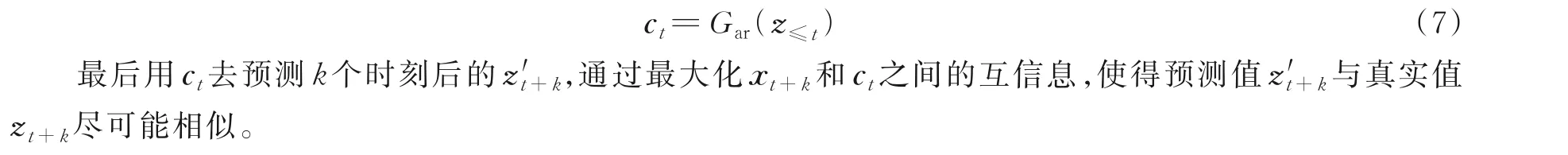
2 本文方法
多任务学习[22]是把多个相关的任务放在一起并行学习,通过多个梯度同时反向传播、多个任务参数共享来补充学习的一种机器学习方法,其参数共享方式分为硬参数共享和软参数共享两种模式。本文采用硬参数共享的多任务学习模型,把语种识别的训练任务分为主任务——语音特征提取和辅助任务——对比预测学习。主任务采用ECAPA-TDNN 网络模型,首先提取语音片段的帧级特征,然后经过注意力池化层和全连接层进行语种的分类判决。辅助任务采用改进的CPC 网络模型,以帧级特征作为输入进行对比预测学习。网络架构如图4 所示,其中:J表示卷积核大小;d表示空洞卷积率,d=1 表示正常卷积;C表示通道维度;T表示时间维度;S表示语种的类别数;GRU 为门控循环单元;Z为经过Conv1D+ReLU 层处理后得到的帧级特征;k为时间步长,一般取偶数。
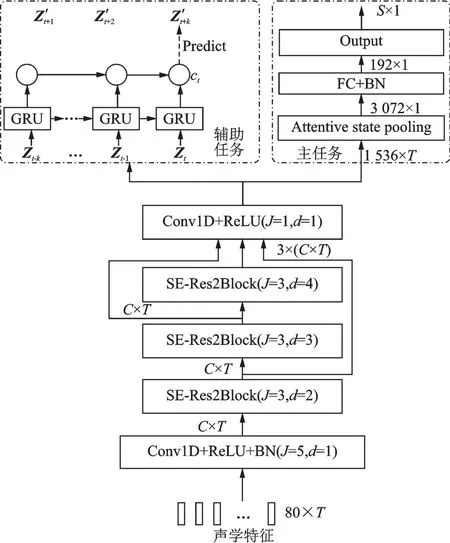
图4 本文方法网络整体架构图Fig.4 Network architecture of the proposed method
2.1 主任务模块
主任务模块以ECAPA-TDNN 作为主干网络,ECAPA-TDNN 网络的帧级别层首先从声学特征中提取帧级特征向量z。然后将网络进行分支:一个分支为辅助任务模块,另一个分支为主任务模块。两个分支均以帧级别特征向量z作为输入,最终网络由这两个分支共同优化训练。
2.2 辅助任务模块
多任务学习网络的辅助任务模块为改进的CPC 模型。改进的CPC 模型以ECAPA-TDNN 网络的帧级网络取代CPC 模型的非线性编码器,ECAPA-TDNN 网络处理得到的帧级特征输入到改进的CPC模型自回归模块中,然后通过自回归模块进行对比预测学习构造正负样本对。
辅助任务模块中Z={zt-k,…,zt-2,zt-1,zt}作为输入特征,自回归模型选用网络。GRU 网络可以通过调节被提取特征的语音序列长度,得到丰富的上下文信息ct,即

2.3 联合损失函数
在语种识别任务中,语种识别特征训练模型的优化由多任务学习网络的损失函数共同完成。因此,为了提高正样本对的相似度和负样本的区分度,本文使用交叉熵损失函数Lce和改进的噪声对比估计损失函数LinfoNCE对训练网络进行联合监督学习。交叉熵损失函数Lce表达式为

式中:B表示批次的大小;xi表示第yi类中第i个样本的特征;Wj为W的第j行的参数;b为偏置量。
改进的噪声对比估计损失函数可以实现互信息最大化,损失值越小说明正样本对的相似度越高,表达式为
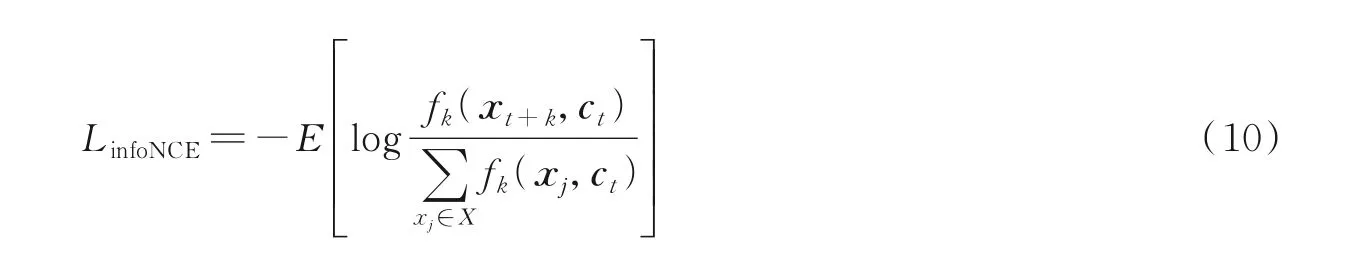
式中:X={x1,x2,…,xN}为一组样本;(xt+k,ct)为正样本对;(xj,ct)为负样本对,正样本对取自与时间上下文ct间隔k个时间步长的样本,负样本为序列中随机选取的样本。fk(xt+k,ct)为密度比函数,表示信息上下文ct的预测值和未来真实值xt+k之间相似程度,正比于未来真实值与随机采样值的概率之比,即
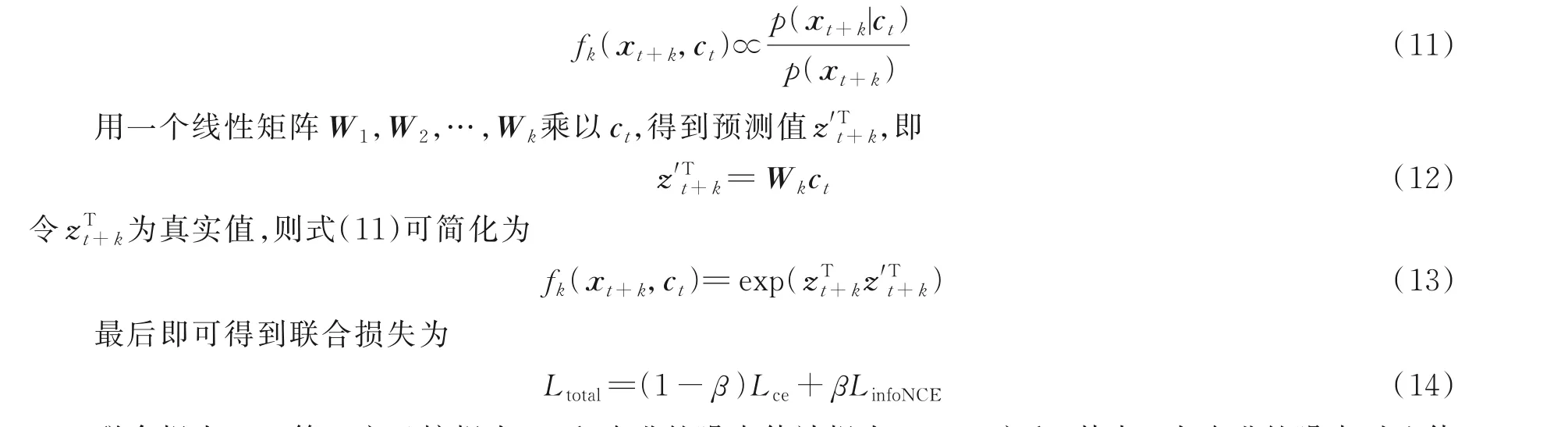
联合损失Ltotal等于交叉熵损失Lce和改进的噪声估计损失LinfoNCE之和,其中β为改进的噪声对比估计损失的权重系数,取值范围为0 到1 之间。
3 实验配置及效果分析
3.1 实验设置
实验使用东方语种识别竞赛提供的10 种不同语言数据集AP17-OLR[23],10 种语言分别为日语、韩语和哈萨克语(时长分别为5.8 h、5.9 h 和5.4 h);粤语、普通话、印度尼西亚语(时长分别为7.7 h、7.6 h 和7.5 h);越南语和俄语(时长分别为8.4 h 和9.9 h),藏语和维吾尔语(时长均为10 h)。每个语种的语音采样频率为16 kHz。实验中随机抽取80%为训练集,20%为验证集。测试集包含1 s,3 s 和全长(All)三个不同持续时间的子集。
本文实验中训练模型选用Adam 优化器,epochs 设置为50,batch_size 设置为128。在多任务学习的辅助任务模型CPC 模型的自回归选用GRU 网络,损失函数权重系数β设置为0.001。实验选用准确率Acc 作为评价指标[24-25]。
我们从大堆的复印资料中迅速翻阅和挑选,凡是五线谱的曲谱,就挑出来,最后竟挑出了两百多页!当时由于时间匆忙,完全没有顾及查看都是什么内容,只觉得是沉甸甸的一包。欧阳鹭英十分慷慨地让我们全部带了回来。
3.2 实验效果分析
3.2.1 多任务学习模型的性能分析
本节对多任务学习ECAPA-TDNN+CPC 网络模型进行性能分析。将每类语种的MFCC 声学特征输入到网络中,以3 s 时长的语音作为测试集,改进的CPC 网络模型中时间步长k取12,分别记录每一次迭代训练的损失、准确率和学习率,得到如图5、6 所示周期性训练时系统参数变化曲线。由图5 可知,在模型的训练过程中,学习率调整的机制为先增加后减小。由图6 可知,第1 次迭代训练的损失为1.926 左右,准确率为92.75%,说明模型刚开始训练时,损失较大,准确率较低。随着迭代周期增加,损失开始下降,准确率逐渐增加。第10 次迭代训练时,损失降为0.063 左右,此时的准确率大约为99.31%,后面训练过程中损失逐渐减小,准确率会有小幅波动,说明模型收敛速度快。第40 次迭代训练时模型已经基本趋于稳定。第48 次迭代训练时准确率最高,达到99.54%,损失为0.020 4,此时得到的网络参数就是最终优化的网络参数指标。
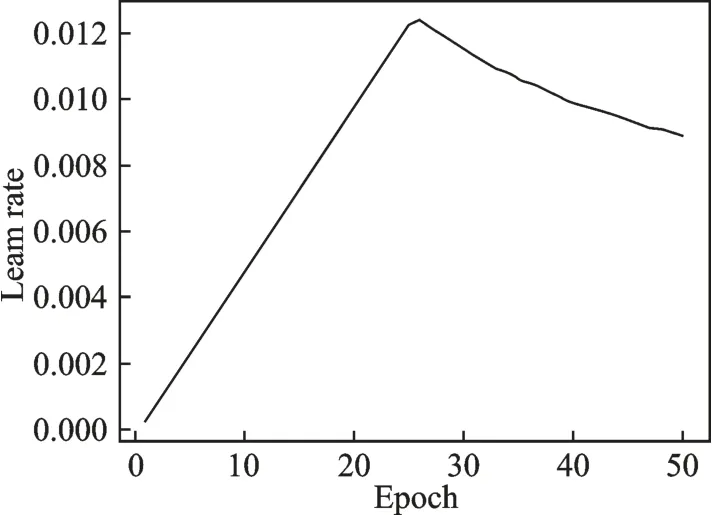
图5 周期性训练时学习率变化曲线图Fig.5 Change curve of learning rate during periodic training
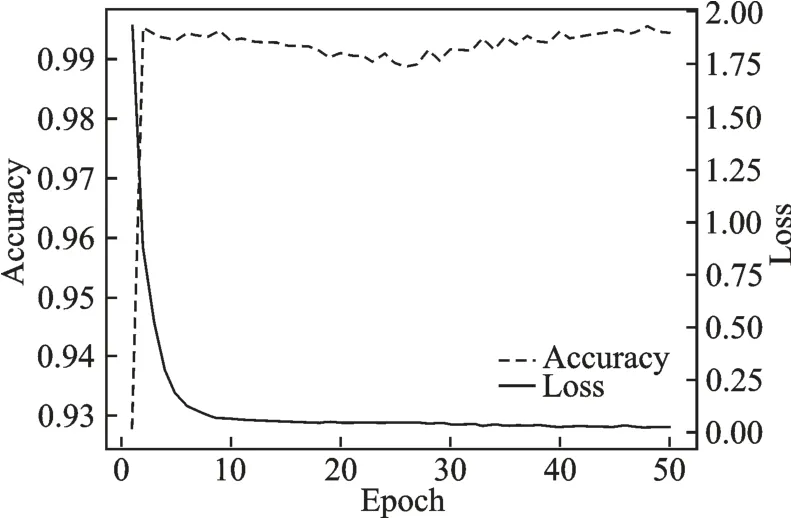
图6 周期性训练时准确率与损失变化曲线图Fig.6 Change curve of accuracy and loss during periodic training
图7 为单图形处理器(Graphic processing unit,GPU)下ECAPA-TDNN 网络和ECAPA-TDNN+CPC 网络周期性训练时运行时间变化曲线图。由图7 可知,ECAPA-TDNN 网络每次训练时间在331~333 s 之间,平均运行时间为331.12 s。ECAPA-TDNN+CPC 网络每次训练的时间在336~339 s 之间,平均运行时间为337.79 s,相对于基础网络相差了6.67 s。ECAPA-TDNN 网络参数量为4.57 MB,ECAPA-TDNN+CPC 网络参数量为7.47 MB,相对于基础网络增加了63.46%。虽然改进多任务学习网络的参数量增加了,但是与基础网络的系统运行时间并没有太大区别。
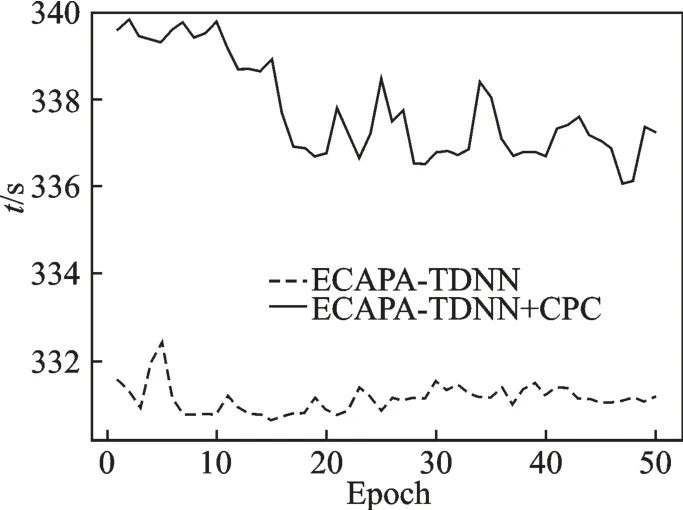
图7 周期性训练时运行时间变化曲线图Fig.7 Change curve of running time during periodic training
3.2.2 多任务学习模型的实验效果分析
本节以MFCC 和FBank 声学特征作为输入,时间步长k取12,在1 s、3 s 和All 测试集上分别验证多任务学习ECAPA-TDNN+CPC 网络和基础网络ECAPA-TDNN 和CPC 的语种识别准确率。实验分析结果如表1、2 所示。
由表1 可见,1 s、3 s 和All 三个测试集的实验中,多任务学习网络的识别准确率相比于ECAPA-TDNN 网络分别提高了1.92%、3.69%和2.80%,相比于CPC 网络分别提高了49.42%、36.15%和40.86%。
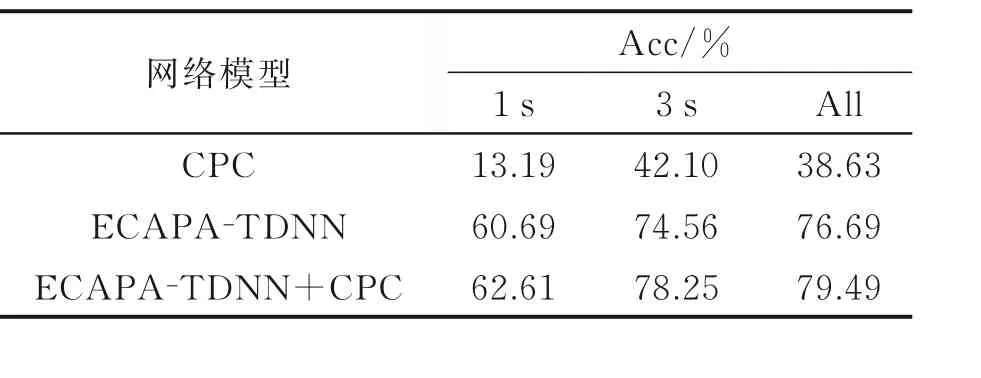
表1 多任务学习模型中输入为MFCC 声学特征的准确率Table 1 Accuracy of multi-task learning model when inputting MFCC acoustic characteristics
由表2 可见,1 s、3 s 和All 三个测试集的实验中,多任务学习网络的识别准确率相比于ECAPA-TDNN 网络分别提高了6.01%、4.11%和3.12%,相比于CPC 网络分别提高了51.73%、25%和41.31%。
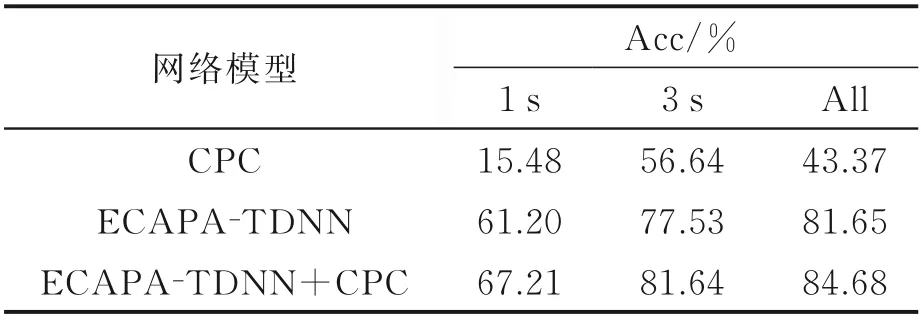
表2 多任务学习模型中输入为FBank 声学特征的准确率Table 2 Accuracy of multi-task learning model when inputting FBank acoustic characteristics
同时,由表1、2 的实验数据对比可知,对于同一个网络FBank 特征作为输入时比MFCC 特征作为输入时的语种识别准确率更高,说明FBank声学特征提取了更有用的语种特征。
3.2.3 不同时间步长的实验效果分析
在ECAPA-TDNN+CPC 网络中,时间步长k取不同值对网络的识别准确率也有一定的影响,本节分别对k取8、12、16、20 进行实验,分析不同时间步长时网络的性能。网络的输入选用MFCC 声学特征。时间步长k取不同值时的实验结果如表3 所示。由表3 的实验数据可见,当测试的音频时长为1 s、k取16 时,测得的识别准确率最高,相对于k取8、12、20 分别增加了4.06%、2.38%和0.62%。测试的音频时长为3 s、k取12 时,测得的识别准确率最高,相对于k取8、16、20 分别增加了1.92%、0.12%和0.90%。测试的音频为All、k取20 时,测得的识别准确率最高,相对于k取8、12、16 分别增加了0.73%、0.66%和1.02%。
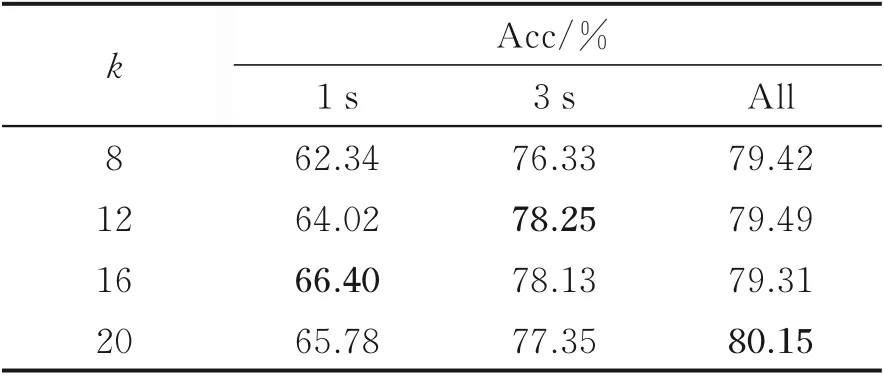
表3 k 取不同值时的准确率Table 3 Accuracy when k taking different values
3.2.4 不同网络上的实验效果分析
本节以MFCC 和FBank 声学特征作为网络输入,时间步长k取12,在不同网络上进行实验效果对比,结果如表4、5 所示。由表4、5 的实验数据可见,ECAPA-TDNN+CPC 网络的实验效果相对于TNDD+CPC 网络和EX-TDNN+CPC 网络的语种识别正确率均有提高。当输入特征为MFCC 声学特征时,在1 s、3 s 和All 数据集的实验效果相比于TDNN+CPC 网络准确率分别提高了10.57%、18.52% 和16.58%,相比于EX-TDNN+CPC 网络准确率分别提高了4.9%、11.53%和9.44%。

表4 不同网络中输入为MFCC 声学特征时的准确率Table 4 Accuracy of different networks when inputting MFCC acoustic characteristics
当输入特征为FBank 声学特征时,在1 s、3 s 和All 数据集的实验效果相比于TDNN+CPC 网络准确率分别提高了16.98%、22.99% 和24.84%,相比于EX-TDNN+CPC 网络准确率分别提高了10.78%、20.68%和20.92%。
4 结束语
本文提出一种融合CPC 模型的多任务学习语种识别网络,ECAPA-TDNN+CPC 模型。该模型在主干网络ECAPA-TDNN 中加入一个自回归模块,对ECAPA-TDNN 网络提取的帧级特征进行对比预测学习,构造正负样本对,通过最大化正样本对之间的相似度和最小化负样本对之间的相似度来优化网络,增强所提特征的一致性。最后在东方语种竞赛数据集AP17-OLR 上进行验证。实验结果表明,提出的ECAPA-TDNN+CPC 网络可以快速收敛,识别准确率明显提高,能够更好地对语种进行分类。
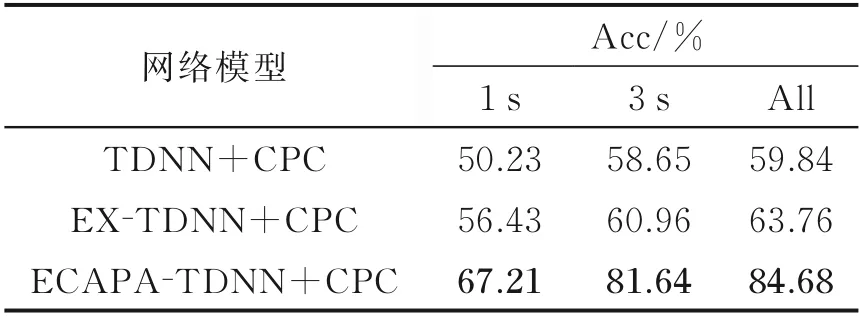
表5 不同网络中输入为FBank 声学特征时的准确率Table 5 Accuracy of different networks when inputting FBank acoustic characteristics
猜你喜欢
时代邮刊(2021年8期)2021-07-21 07:52:44
家庭影院技术(2020年6期)2020-07-27 01:37:54
中国生物医学工程学报(2019年6期)2019-07-16 07:52:40
家庭影院技术(2019年1期)2019-01-21 02:25:04
家庭影院技术(2018年11期)2019-01-21 02:20:50
家庭影院技术(2018年10期)2018-11-02 05:35:26
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:05
自动化学报(2016年3期)2016-08-23 12:02:56
电测与仪表(2016年5期)2016-04-22 01:13:46
计算机工程(2014年6期)2014-02-28 01:26:17
