
融合MobileNetv2和注意力机制的轻量级人像分割算法
2022-04-08 03:42王美丽边党伟
计算机工程与应用 2022年7期
王 欣,王美丽,2,3,边党伟
1.西北农林科技大学 信息工程学院,陕西 咸阳 712100
2.农业农村部农业物联网重点实验室,陕西 咸阳 712100
3.陕西省农业信息与智能服务重点实验室,陕西 咸阳 712100
4.西北机电工程研究所,陕西 咸阳 712100
图像分割是计算机视觉领域的重要热门之一,其在医学、农业、军事等诸多领域都得到了广泛的关注。图像分割是根据图像的内在性规则,如像素点之间的明暗关系、图像纹理、像素灰度级等来将图像划分为若干个子图像区块的过程,以使得每个区块具有特定特征,与其他区块形成显著对比。
人像分割是图像分割的一项重要研究内容,人像分割在自动驾驶、行人检测、智能搜救、医学影像等领域应用十分广泛并发挥了极其重要的作用。人像分割方法分为传统的人像分割方法[1]和基于深度学习的人像分割方法[2]。传统的人像分割方法主要利用了视觉层的图像低级语义信息,如图像的颜色、形状、纹理等信息作为分割依据,典型方法有基于阈值的分割方法、基于边缘的分割方法等。基于阈值的分割方法[3-5]是依据计算得到的灰度阈值,按照图像像素灰度值与阈值的大小关系,将像素点进行分类,然而若人物和背景的像素值差异并不大,边界信息往往容易丢失。基于边缘的分割方法[6]利用不同的微分算子[7]来进行边缘检测,但噪声对算子影响较大,所以基于边缘的分割方法只适合低噪声且构图简单的图像。真实场景拍摄的人像通常有着庞杂的背景信息,所以该算法一般不适用于人像分割[8]。
由于传统方法存在分割噪点、边缘粗糙等问题,难以胜任精细分割的任务,研究人员提出了基于深度学习的人像语义分割技术。该人像分割技术主要利用了深度学习的相关理论,通过卷积神经网络从大量已标注的人像数据中提取出图像特征并且挖掘出每个像素的语义信息进行分类。何冀军等[9]提出了一种用于人像提取及半身像合成的生成对抗网络算法,利用生成对抗网络进行标准的人像证件照合成,该算法具有良好的适应性。Shen等[10]设计了一种基于全卷积神经网络的人像分割算法,能够有效地分离人物与背景,并且可以较好地处理人物头发边缘,取得了良好的分割效果。但是以上分割网络往往为了追求分割效率以及精度需要庞大的计算资源和较强的硬件设备,不利于网络的迁移使用。Sandler等[11]设计的轻量级网络MobileNetv2解决了上述问题,MobileNetv2利用Linear Bottleneck和Inverted Residuals既可以提取到图像足够多的信息又能够提升整体的计算速度,使得模型在保持轻量级时速度与精度也能得到保证。另外,张航等[12]在进行婴儿脑部MR图像分割时发现,分别使用FCN、2D FCN、3D FCN比U型网络分割效果差,证明了U型网络结构相较于普通全卷积结构来说,具备更好的特征学习能力以及复原图像细节的能力。因此,本文引入Unet网络的encoder-decoder(编码器-解码器)结构[13]并与轻量级MobileNetv2网络相结合以获得更好的算法鲁棒性、更强的泛化能力和更精细的人像分割效果。为了解决深度卷积神经网络难以训练的难题,Ioffe等[14]在2015年提出了BN层(batchnormalization layer),BN层用于减少内部协变量漂移(ICS)现象,该现象指的是层层叠加的神经网络,在低层向高层传递和更新参数时,高层参数变化十分剧烈,导致训练者必须十分谨慎地设定初始化权重、学习率等。另外,Hinton等[15]提出Dropout层可以使模型具有更好的泛化能力,不过分依赖局部特征,能够有效防止过拟合的出现。卷积核通常是在局部感受野上聚合多尺度空间信息以及特征通道信息,然而任一通道都无法利用上下文信息并从全局信息入手学习到各个特征通道的重要程度。Hu等[16]提出一种基于通道的注意力机制模块SE block,该模块关注特征通道之间的内在联系,显式地表达各个特征通道的重要影响程度,针对训练者提出的不同任务进行加强或抑制不同的通道,有助于从全局角度学习有效特征。此外人像由半人体及其背景组成,适合二分类处理方式。原始Unet使用的分类交叉熵损失函数和输出层激活函数softmax均适合多分类模式,会给模型训练造成不必要的算力开销,不利于模型最终对像素点的分类结果。在实际分割时,由于样本类别分布不均衡造成目标人物周围像素点粘连的情况。Dice loss[17]广泛应用于医学影像分割,能够有效抑制目标像素以及背景像素的类别不平衡问题。但是若单独使用Dice loss则会由于其数学形式,造成反向传播时梯度形式不优导致训练的稳定性极低的问题。BCE loss(binary cross entropy loss)[18]具有极优的梯度形式,弥补了Dice loss的不足,使用Dice loss与BCE loss组成的混合损失函数[19]使得模型能更好地优化,解决了上述问题。
本文在保留U型编码器-解码器结构的基础上,通过将MobileNetv2作为编码器部分用于特征提取,使用特征拼接连接上采样与下采样,增加注意力机制,使用混合损失函数等方式提出一种融合MobileNetv2和注意力机制的轻量级人像分割算法对人像进行精细分割,该模型同时支持在安卓平台上使用。
1 传统Unet模型简介
传统Unet网络是由传统FCN网络变化而来的典型编码器-解码器类的U型网络结构,Unet可以在数据集较小的情况下,对目标进行有效的分离。传统Unet网络[20]结构如图1所示。该网络有5层,在编码时经历4次下采样,每次下采样都要经过3×3卷积,再经过2×2池化到下一次下采样;经过中间层后,进入解码,经过4次上采样输出分割结果,每次上采样都要经过特征图融合和3×3卷积,再经过反卷积-卷积到下一次的上采样,最终形成了U型结构。Unet采用分类交叉熵损失函数+输出层激活函数softmax的组合形式,有利于多分类情况的图像分割。
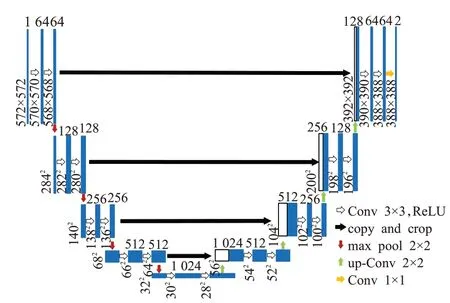
图1 原始Unet模型示意图Fig.1 Figure of original Unet
2 本文分割算法
本文在Unet网络[20]编码器-解码器类的U型网络结构的启发下构建轻量级的人像分割网络,以获得更高的人像分割精度和良好的人像分割效果。
详细分割流程图,见图2,本文算法以人像半身图作为输入,随后进行图片预处理,其中包括数据增强、尺寸缩放和归一化处理,最终输入模型并输出该人像图片对应的分割掩膜。
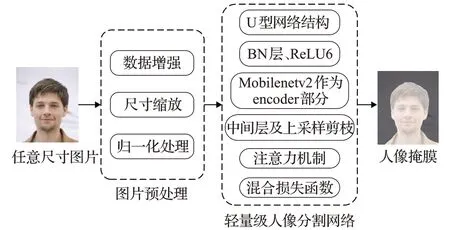
图2 本文算法流程示意图Fig.2 Flow chart of proposed algorithm
本文在保留U型编码器-解码器结构的基础上,将轻量级MobileNetv2网络作为U型结构的编码器部分;MobileNetv2网络具备极强的特征提取能力,没必要在中间层使用卷积层进行特征传递与提取,取消中间层结构;解码器部分有四次特征拼接,每次特征拼接后都经过反卷积-卷积-注意力机制到下一次上采样。特征拼接增加了相关语义特征信息的提取,另外使用注意力机制利用全局信息选择性的增强有益特征的学习,有利于图像的还原过程;针对目标像素点存在样本不均衡导致难以进行分类的问题,引入混合损失函数来更好的适应训练集的训练过程。本文设计的人像分割算法网络结构图具体如图3所示。
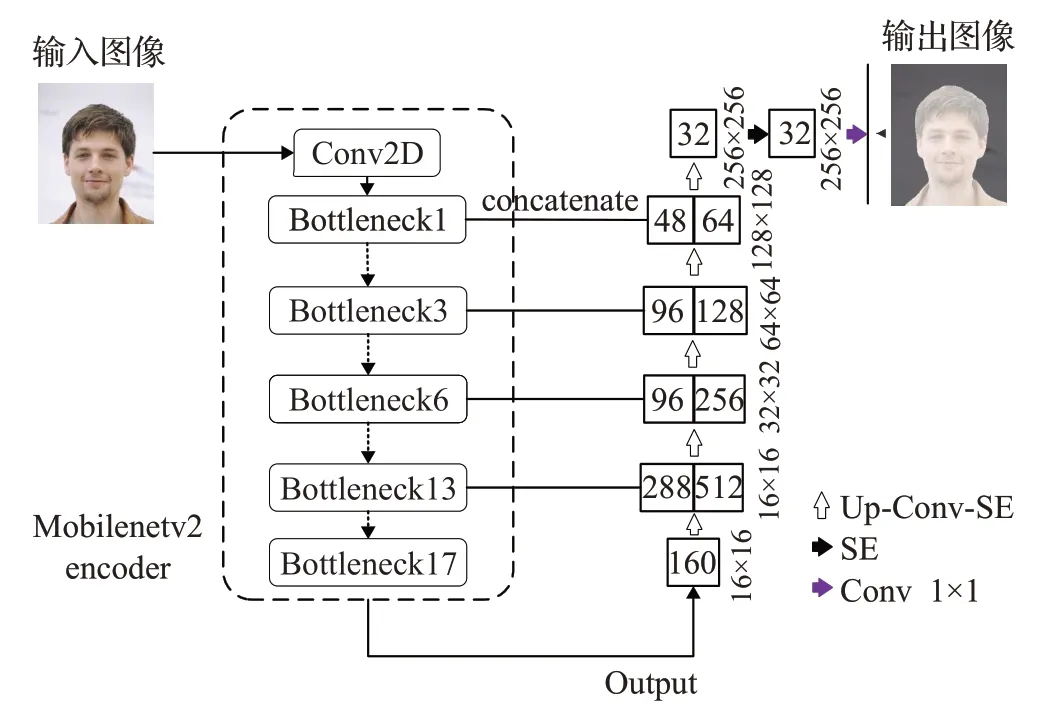
图3 本文算法网络结构图Fig.3 Structure figure of proposed algorithm
2.1 网络主要框架结构
原始Unet网络层数是5,最大特征融合维度数是1 024,模型总参数量为31.38 MB,体量过大。具体模型参数见表1。为了降低模型体量使其具有可移植性,便于后期移植到移动端(移动端使用.h5文件转换后的.tflite模型文件),在保留U型结构的基础和保证模型精度与速度的情况下尽量减少模型的体量。本文将MobileNetv2作为编码器部分的骨干网络,设定输入图像大小为256×256。MobileNetv2提出了一种具有线性瓶颈的倒残差结构,有助于模型学习到更精细的特征并且保证了模型的运行速率。由于轻量级MobileNetv2保证了下采样已经提取到足够多的特征,并不需要中间层使用层层叠加的卷积核来进行特征的二次提取与传递,本文对中间层结构进行剪枝操作。在decoder部分分别用17个linear bottlenecks中第1个、第3个、第6个、第13个的输出结果对维度数为512、256、128、64的卷积核进行特征融合,特征融合后经过一个反卷积-卷积-注意力机制到下一次特征融合,4次维度拼接后经过反卷积-卷积-注意力机制恢复到256×256的图片分辨率,形成了一个5层的U型结构。

表1 模型参数表Table 1 Parameters of model
2.2 增加BN层和ReLU6
BN层用于减少ICS现象、防止梯度弥散和加速模型的训练。Dropout层可优化模型训练过程,避免模型过拟合情况的发生。BN层和Dropout层叠加可应用于模型decoder部分中任意卷积层后、激活函数ReLU6[11]前。本文算法在上采样卷积层后引入了BN层和Dropout层,有助于模型学习策略的制定和提高模型训练速度。
采用激活函数ReLU6,见公式(1),导数见公式(2)。该函数作为非饱和激活函数类的代表,在防止梯度消失方面有无可替代的优势。原始Unet使用ReLU函数,随着激活函数的发展,ReLU6表现出了更好的性能优势[20]。ReLU6可用在Dropout层之后,在防止梯度消失同时还可保持模型的可移植性。
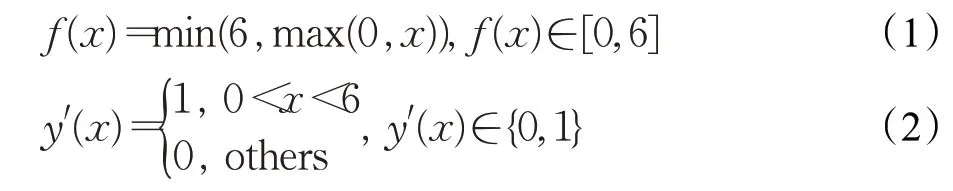
公式(1)和(2)中,x代表输入,f(x)代表输出,f(x)范围在0到6之间,f′(x)范围在0到1之间。
2.3 注意力机制
本文将注意力机制融入到U型网络的decoder部分,用于每次反卷积-卷积模块后和输出前,可以有效地学习到有益特征通道的信息,有利于模型的学习训练过程。
注意力机制模块SE block依据所构建的特征通道间的相互依赖关系,从全局角度构建特征通道间的重要性关系网。它主要由两部分组成:压缩部分(squeeze)和激励部分(excitation)。squeeze见公式(3),全局平均池化,将每个通道的信息浓缩为一个标量,得到全局信息。excitation见公式(4),利用全局特征建立通道关系模型,全面捕获通道依赖性。该操作具体为全连接层-relu-全连接层,由于ReLU6性能更优越[11],本文采用ReLU6函数,精度提升1.2%,交并比提升0.9%。利用各通道重要性逐通道加权到先前的特征上,得到最终特征,见公式(5)。详细流程图如图4所示。
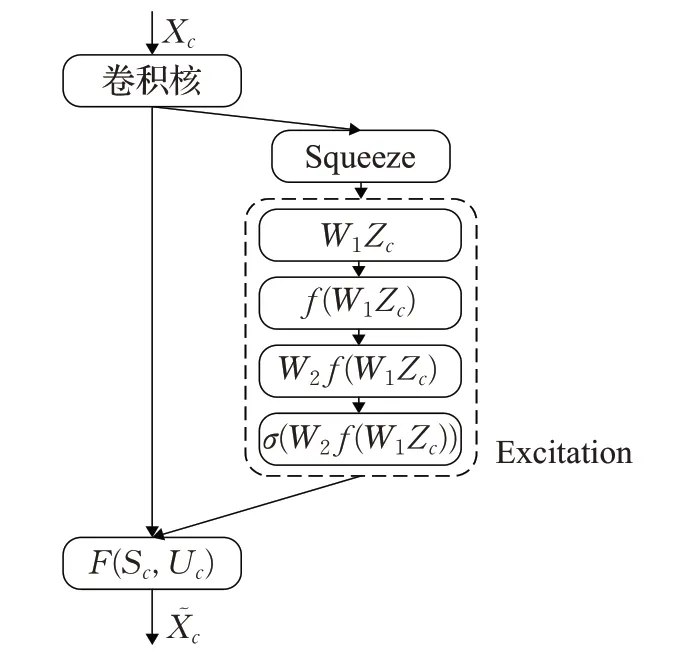
图4 CE block流程图Fig.4 Flow chart of CE block
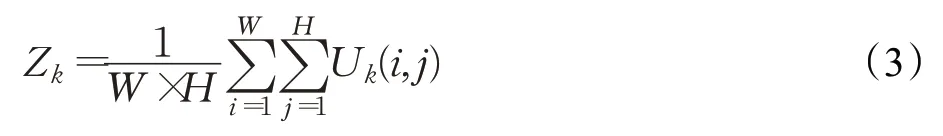
公式(3)中,U k(i,j)表示上一个卷积核输出的c维矩阵U c中第k维矩阵第i行j列的元素,W和H分别表示U k的宽和高,Z k表示第k维通道的压缩值。

公式(4)中,Zc表示squeeze操作得到的c维特征图,和,r为16[11],f表示ReLU6激活,σ表示sigmoid激活,S c表示c维通道重要性权值。

公式(5)中,͂表示c维最终特征(Xc表示c维原始特征)。
2.4 损失函数
2.4.1 原始Unet网络损失函数
原始Unet采用分类交叉熵损失函数,见公式(6)。模型输出层运用softmax激活函数进行多分类,计算像素点的分类概率[20]。
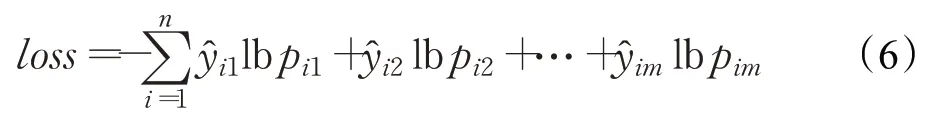
公式(6)中,n是样本数,m是类别数,指的是第i个样本在第一类的类别,指的是第i个样本在第一类的概率,最终得到n个样本的loss值。
2.4.2 混合损失函数
本文在二分类场景下对目标人物进行分割,引入适合二分类的混合损失函数和输出层激活函数sigmoid来解决部分图片人物边缘难以分割和正负样本像素点不均衡的问题。该混合损失函数[19]由Dice loss[17]和BCE loss[18]两部分组成,解决了直接使用Dice loss会对模型训练时反向传播造成不利影响使得训练的稳定性降低的问题,有利于模型的收敛与训练。
混合损失函数见公式(10);Dice loss(LDL)见公式(8)。Dice loss是在Dice系数的基础上取得的,Dice系数(s)具体形式见公式(7),公式(7)中A表示预测掩模人物像素区间,B表示真实标定人物像素区间。BCE loss(LBCE)具体形式见公式(9),公式(9)中,p表示该像素点的预测概率值,y表示该像素点的类别。

3 模型训练和验证
3.1 实验平台
实验硬件平台是2块RTX 2080 GPU,共48 GB显存,Intel至强处理器,共96核,2 TB内存。软件环境是ubuntu18.04、python3.6、tensorflow1.14。本文算法最佳超参数如表2所示。表2中,变量Epoch代表训练迭代次数;Batchsize表示每小轮训练时输入模型的图片数;优化器代表用来调整影响模型训练的网络参数;Lr表示学习率;Factor表示训练精度不再提升时,学习率衰减的比率。

表2 本文算法最佳超参数Table 2 Best hyper-parameter of proposed algorithm
3.2 数据集和评价指标
本文训练数据集通过爬取网络人像半身照并且手工标注mask标签的方式进行采集,采集的人像半身照共3 900张。为了检验网络的通用性,在Human_Matting[22]数据集和EG1800[10]数据集上分别进行测试,测试图像均为.jpg格式下的RGB图像。本文算法及对比算法均在训练过程中采用十折交叉验证的方式,最后使用测试集对最优模型进行评估测试。
本文采用的数据增强方式是在送入模型学习之前,在小批量(min-batch)上采用图片随机转动、颜色变换、水平翻转、垂直翻转、亮度增强、裁剪等方式进行数据增强。
模型评价指标采用分割模型常用的像素准确率PA和IOU(交并比)指标。像素准确率PA指的是预测类别正确的像素点数占总像素点数的比例。IOU指标[23]指的是预测掩模人物像素区间占真实标定人物像素区间的比例,见公式(11)。

其中,A表示预测掩模人物像素区间,B表示真实标定人物像素区间。
4 实验对比及分析
4.1 改进前后实验指标对比
本文算法保持了U型结构,通过将轻量级网络MobileNetv2作为骨干网络、中间层剪枝、精简上采样过程等方式来优化模型结构和模型训练过程,通过调参来优化训练过程和实验结果。模型结构消融实验性能变化情况如表3所示。
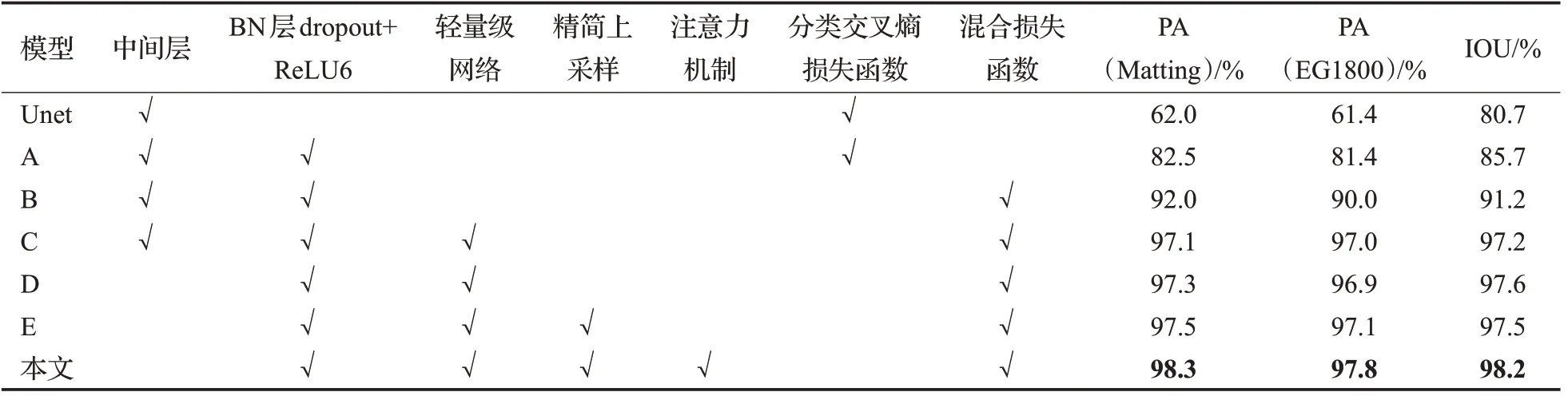
表3 模型结构变化情况Table 3 Changes of model structure
根据表3可知,在U型网络中通过增加BN层、ReLU6有利于模型收敛和训练;引入混合损失函数之后解决了样本分布类别不均的问题,模型精度和IOU指标有较为明显的提升;使用MobileNetv2有助于模型学习到更丰富的特征;去掉中间层不影响特征的传递和学习;精简上采样之后对模型的影响并不大;添加注意力机制后,通过特征分配,加强了有效特征的学习,精度和IOU指标有一定的提升。模型在训练与验证精度变化曲线分别如图5所示。
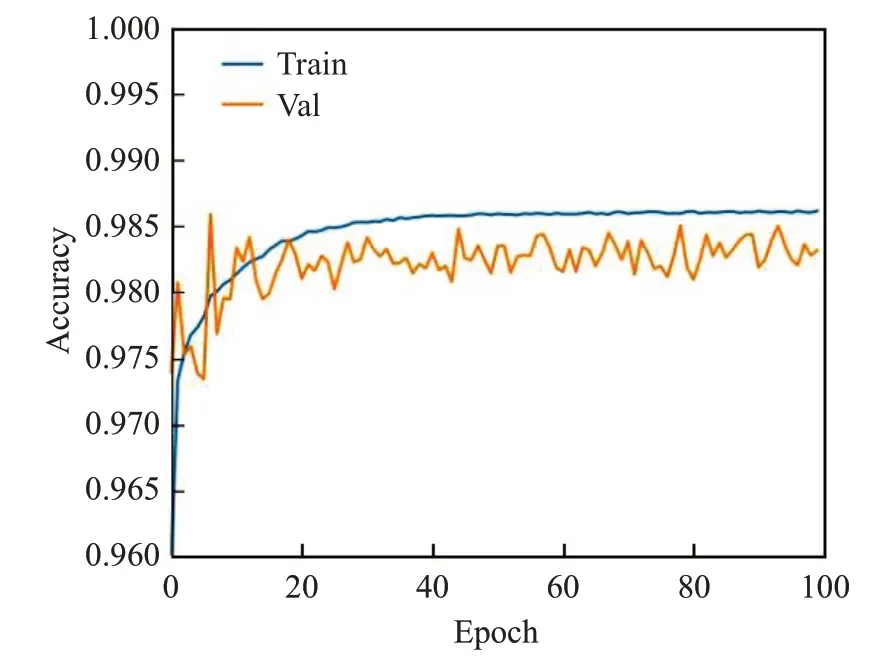
图5 本文模型训练精度变化图Fig.5 Variation diagram of model training accuracy in this paper
本文算法指标IOU优于周鹏等[24]于2020年文献中92.29%的IOU值,指标PA优于杨坚伟等[25]于2020年文献中95.57%的准确率。
4.2 Human_Matting数据集算法对比分析
在Human_Matting数据集上设计了一组对比实验,本文算法与模型FCN[26]、Enet[27]、Segnet[13]、Fusionnet[28]、PortraitNet[29]、DeepLabv3+[30]进行对比,实验结果详见表4。
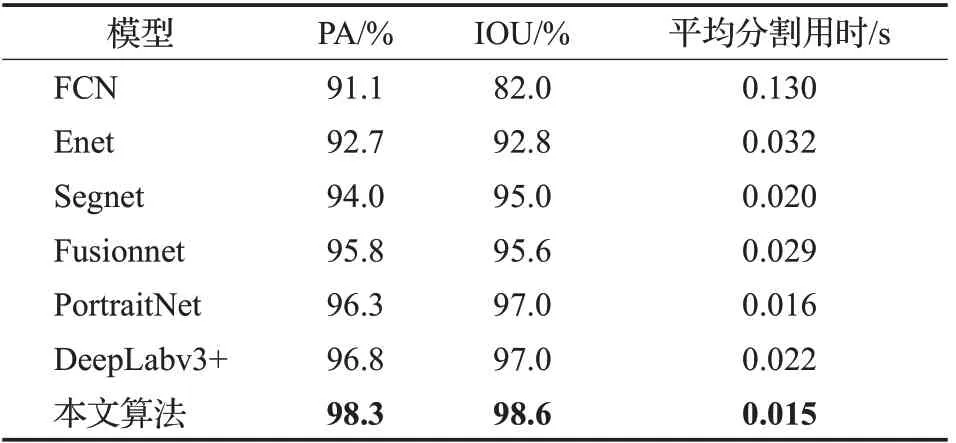
表4 分割算法比较(Matting)Table 4 Comparison of segmentation algorithms(Matting)
图6和图7直观地展示了对比算法的掩膜分割效果。每组图第一层是人像分割掩膜,第二层是相应的细节放大图。FCN、Enet在两组人像中背景误判现象较为严重;Segnet在图6(d)人像颈部边缘的粘连较多,在图7(d)人像肩部及手指尖端有轻微的背景误判现象;Fusionnet对人物掩膜边缘的处理较柔和,但仍然存在人物边缘漏分情况;PortraitNet在图6(f)人物右腋下孔洞未分离出,图7(f)分割效果较好,所需分割用时较少;DeepLabv3+在图6(g)人物左右腋下具有背景误判现象,图7(g)人物左肩上方有较小孔洞出现;本文算法能较为精细地处理人物细节信息,能分离出6(h)人物右腋下的背景,同时也能较好的识别7(h)人物手指尖端。

图6 算法分割掩膜第一组效果图Fig.6 First group of segmentation mask of algorithms

图7 算法分割掩膜第二组效果图Fig.7 Second group of segmentation mask of algorithms
4.3 EG1800数据集算法对比分析
为了更加客观地评价本文算法,在EG1800数据集上设置了一组对比实验。本文算法与模型FCN[26]、Enet[27]、Segnet[13]、Fusionnet[28]、PortraitNet[29]、DeepLabv3+[30]进行对比分析,实验结果详见表5。
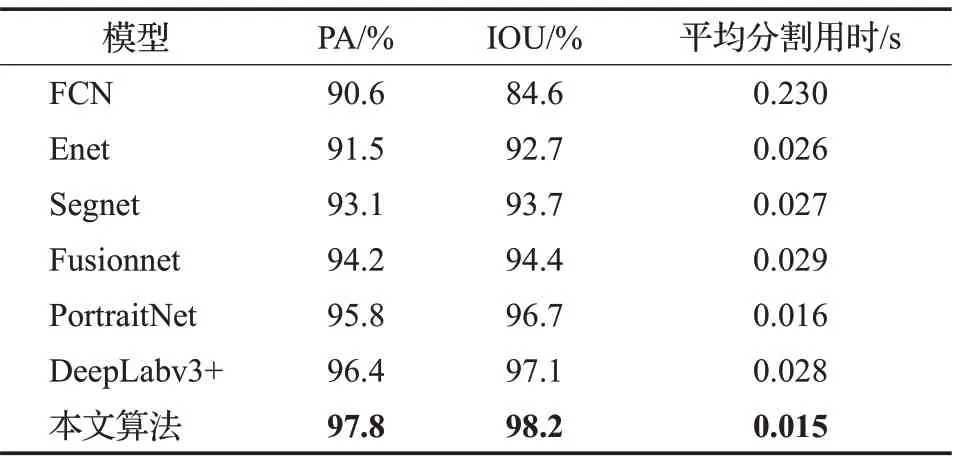
表5 分割算法比较(EG1800)Table 5 Comparison of segmentation algorithms(EG1800)
为了更直观地观察分割效果,对比算法的分割掩膜效果图,见图8~10。图8~10中,每组图第一层是人像分割掩膜,第二层是相应的细节放大图。FCN的人像效果存在严重的背景误判现象,耗时较长;Enet在三组人像上有部分粘连,用时较FCN少;Segnet效果较前两个对比算法好,人像粘连较少,但是粘连或缺失部分仍然可以很清楚地辨别,平均分割用时与Enet相近;Fusionnet在图8(e)男性头顶与背景有部分粘连,在图9(e)肩部划分有误判,但是头发边缘细节分割效果较好,在图10(e)人脸左边有部分缺失;PortraitNet在图8(f)人像头顶头发与背景有部分粘连,图9(f)人像左部耳朵有大部分缺失,图10(f)人物左边发型部分有孔洞;DeepLabv3+在图8(g)人像左耳下半部分有缺失,图9(g)人物左耳外耳廓有背景误判现象,图10(g)分割效果较好,但在人物头发边缘处理不够平滑;本文算法在三组图中表现良好,能较好地将图像中人物与背景分离,同时分割用时最短。通过以上分析可知,本文提出的算法可以有效地用于常见的人像前景背景二分类处理场景。

图8 算法分割掩膜第一组效果图Fig.8 First group of segmentation mask of algorithms

图9 算法分割掩膜第二组效果图Fig.9 Second group of segmentation mask of algorithms

图10 算法分割掩膜第三组效果图Fig.10 Third group of segmentation mask of algorithms
4.4 本文算法分割失败样例分析
本文算法在Human_Matting和EG1800数据集上并不是所有的图片都完美的将人物与背景分离,抽取两数据集失败样例进行分析,分别见图11和图12。

图11 失败样例分割掩膜效果图(Matting)fig.11 Segmentation mask of failed examples(Matting)

图12 失败样例分割掩膜效果图(EG1800)Fig.12 Segmentation mask of failed examples(EG1800)
本文算法在Human_Matting数据集样例1中人物手中托举的水果未能良好地同人物一起分离开,样例2中人物右脸颊与肩部之间的空隙有背景粘连情况;EG1800数据集样例1中小女孩左半部分效果良好,但在右部手以下部分有背景误判现象,样例2中人物手部边缘部分未能准确地进行识别并分离,并由于头发蓬松,在头发边缘的处理也不够精细。由此可见,本文算法虽已达到轻量级,但是也同样由于轻量级过于精简使得本文算法在人物手部特别是小指指尖,头发边缘等部位的精细分割上有所欠缺,在人物之外的干扰物体的影响下也有漏分的情况出现。
5 结语
本文采用融合MobileNetv2和注意力机制的轻量级人像分割算法对自行收集标注的人物半身像数据集进行训练。通过设置MobileNetv2为encoder部分、精简中间及上采样部分、增加注意力机制、结合混合损失函数等一系列操作,提升了模型分割效率,得到了具有一定通用性的人像分割网络。本文通过与其他算法进行分割指标和人物半身像分割效果图的对比,证明本文算法具有较好的分割效果,可有效用于人物目标检测、绿幕抠图等人物图像处理阶段。但本文算法同样存在人物指尖及头发边缘处理不够精细的情况,仍需要对上采样卷积核特征提取和还原部分进行一定的改进。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
新世纪智能(数学备考)(2021年9期)2021-11-24
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·中考版(2021年3期)2021-07-22
电子技术与软件工程(2021年5期)2021-06-16
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
电子制作(2019年13期)2020-01-14
证券市场红周刊(2019年44期)2019-11-23
电子制作(2019年11期)2019-07-04
