
结合图卷积的深层神经网络用于文本分类
2022-04-08 03:42董春阳
计算机工程与应用 2022年7期
郑 诚,陈 杰,董春阳
1.安徽大学 计算机科学与技术学院,合肥 230601
2.计算智能与信号处理教育部重点实验室,合肥 230601
文本是传递信息的重要途径和载体,在如今的大数据的时代,海量文本信息的管理成为了一个难点。文本分类作为自然语言处理的基本任务和核心技术,如何快速准确的判别文本所属类别从而更好地服务自然语言其他任务,一直以来都是研究的重点方向。
最近有研究人员将文本表示成图结构,通过图卷积网络捕获文本的结构信息还有单词间非连续和长距离的依赖关系,但是图卷积网络应用在文本上存在有两方面的限制:一是由于将单词表示为节点,通过邻接矩阵聚合节点的邻域信息,忽略了文本的顺序结构,导致损失了文本的上下文语义信息;二是对文本局部特征信息(如关键短语)的提取不足。从而在一些上下文语义信息和局部特征信息丰富的文本上表现欠佳。
为解决上述提到的问题,本文提出了一种新的模型,该模型主要由3个特征提取层和一个图池化层组成。第一个特征提取层是由GCN和双向长短时记忆网络(Bi_LSTM)组成,利用Bi_LSTM模型在建模上下文语义信息的优势对文本的上下文语义信息特征进行提取。第二个特征提取层是由GCN和CNN组成,利用CNN模型对局部特征信息提取的优势对文本的局部特征信息进行提取。然后通过图池化层筛选出重要节点送入第三个由GCN和CNN组成的特征提取层,目的是帮助CNN捕获文本更深层次的局部特征信息。其中GCN模型起到的作用有两方面:一方面是捕获文本中非连续和长距离的单词依赖关系;第二方面是通过聚合邻域信息扩大模型的信息感知能力。模型中文本图的节点由词性为名词、形容词和动词3种类型的单词构成,节点之间的边由单词是否在滑动窗口中决定。最后,将提取的特征信息送入全连接层再通过SoftMax函数得到文档的预测类别。
本文的贡献如下:提出了一种新型模型,通过Bi_LSTM和CNN混合提取文本的上下文语义信息和局部特征信息去弥补GCN在文本特征信息提取上的不足。并采用了图池化层帮助CNN提取更深层次的局部特征,以更好地表示文本信息。
在3个英文数据集上的实验结果表明,本文模型相较于基准模型,取得了一定的效果。
1 相关工作
传统的文本分类方法主要是基于特征工程,特征工程有词袋模型[1]和n-grams等,后来也有将文本转换为图形并对图形进行特征工程的研究[2-3],但这些方法不能自动学习节点的嵌入表示。
基于深度学习的文本分类方法相较于传统文本分类方法,有自动获取特征和进行端到端学习的能力,并且深度学习模型能够学习到文本深层的语义信息。深度学习在词嵌入研究方面,文献[4]提出Word2Vec模型,该模型通过使用深度学习的方法将单词表示为低维度且稠密的向量,使用词向量距离衡量单词之间的语义相似度,能更好地表达出单词本身所具有的语义信息。2016年,文献[5]提出fastText模型,该模型与Word2Vec模型中的CBOW相似,但是两者的任务不同。fastText模型在维持较高精确度的情况下加速了模型的训练过程,词向量表示效果良好。在深度学习模型方面,文献[6]提出使用文本卷积神经网络(textCNN)用于文本分类,利用多个不同尺寸的滤波器来捕获文本的局部特征信息,在多个数据集上获得很好的效果。但是仅提取文本的局部特征信息在文本表示上仍有不足,因为文本的上下文是有联系的,脱离了上下文对于文本的理解是不充分的。为此文献[7]提出使用循环神经网络用于文本分类,由于循环神经网络在处理序列相关任务时有着独特的优势,能够捕获序列的历史信息,使得循环神经网络在文本分类任务中能够捕获文本的上下文语义信息,成为了文本分类中重要的深度学习模型之一。此外,大部分基于深度学习的神经网络模型往往只关注于文本内容本身的信息而忽略了标签信息在文本分类中的重要性,文献[8]提出联合嵌入单词和标签信息的模型,通过将标签和单词共同嵌入到同一个向量空间中,以获取标签信息进行文本分类。
近年来,许多研究尝试将卷积运算应用到图形数据上,文献[9]提出了图卷积网络(GCN),该网络是卷积神经网络的一种变种,采用半监督的方式学习图中内在结构的特征,并且模型在节点分类任务上取得了不错的效果。由于GCN中节点之间边的权重是固定不变的,在聚合节点的邻域信息时不能聚合那些具有重要特征的信息。为此文献[10]提出图注意网络(GAT)使用注意力机制文献[11]对节点的邻域信息进行权重分配,突出与分类任务相关的重要信息,给邻居节点中较为重要的节点分配较高的权重,相比于没有添加权重的图卷积网络有较好的提升。后来,文献[12]提出了textGCN模型,首次将图卷积网络引入到文本分类中,通过将文本建模成图,图中的节点由单词和文档构成,然后在图上应用图卷积网络进行文本分类最终获得了不错的效果。
2 结合图卷积的深层神经网络
2.1 模型总体框架
为解决上文中的问题,本文提出一种新的模型,其总体框架如图1所示。
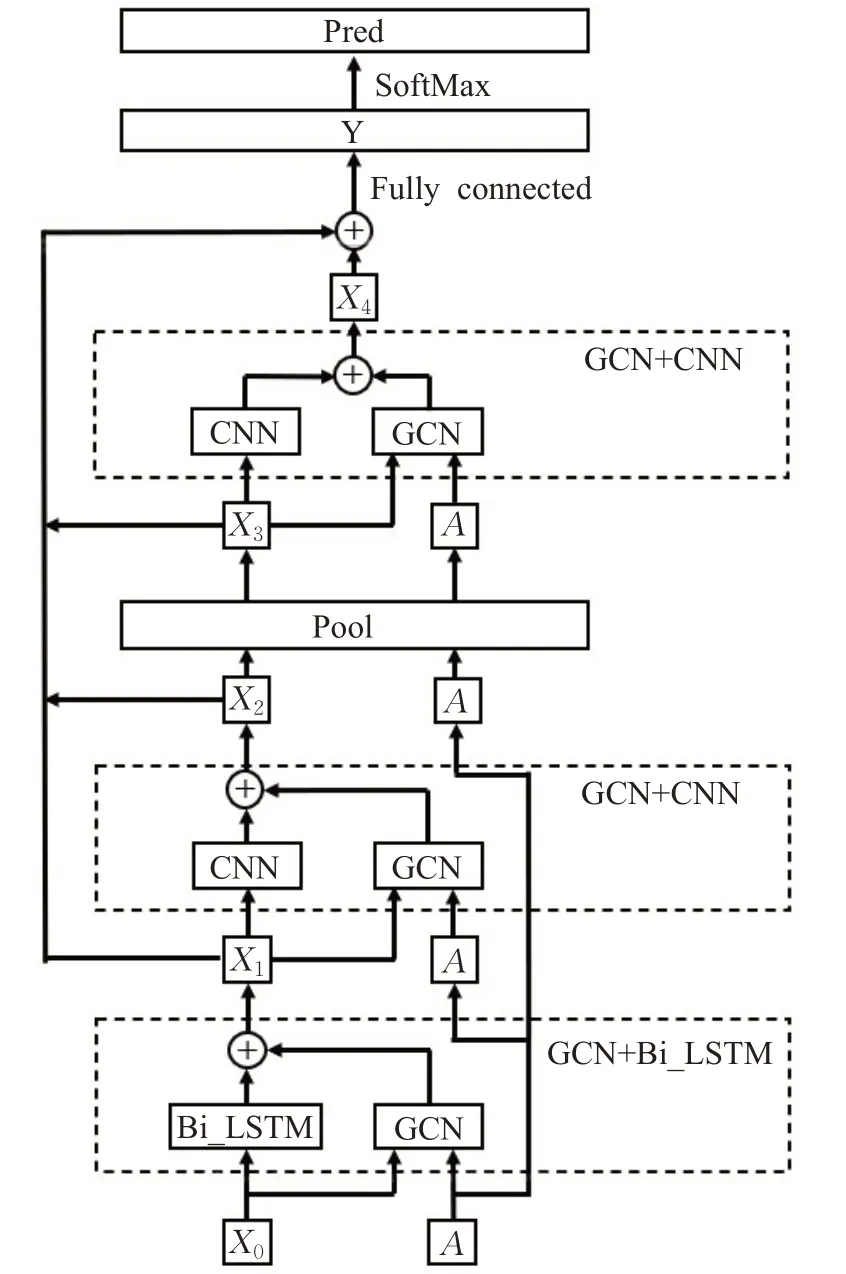
图1 模型总体框架Fig.1 Overall framework of model
2.2 文本图构建和单词表示
首先,利用NLTK工具包筛选出文本中的名词、形容词和动词,其他词性的词作为停用词删除。图中节点的边由滑动窗口决定,规则是如果两个单词在同一个滑动窗口出现则在两个单词间添加一条无向边,从而构成本文的文本图。如图2所示为将一个文本转化为图的例子。
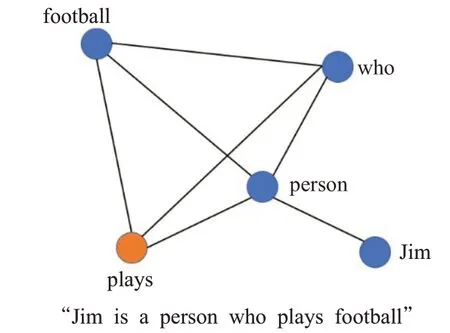
图2 文本图示例Fig.2 Text diagram example
因为选取名词、形容词和动词作为图的节点,所以选取了“Jim”“person”“who”“plays”“football”作为图中的节点,并且使用了一个大小为4的滑动窗口在文本上滑动。例如,在文本中“Jim”和“person”在同一个滑动窗口中,所以图中“Jim”和“person”两个节点间存在一条无向边。
本文模型的单词表示由单词嵌入向量和位置嵌入向量共同组成,使用fastText预训练词向量作为单词嵌入向量。它包含超过200万个预训练的单词向量,与其他预训练的单词嵌入向量如Glove[13]相比,使用fastText能帮助人们避免大量的未知单词。例如在AG News数据集中,使用fastText预训练词向量只有几百个未知单词,这比使用Glove预训练词向量要少得多。除了单词嵌入向量以外,还使用了文献[14]提出的位置嵌入方法,将文本中单词的位置编码成一个独热向量,然后将其与单词嵌入向量连接。最后将单词的向量表示相叠加,得到模型所需要的特征矩阵。
2.3 图卷积网络
图卷积网络是一种处理图数据的模型,该模型通过卷积运算将节点的邻域信息聚合到自身节点,经过多次聚合能够提取到高阶的邻域信息和节点间非连续的依赖关系。
假设一个图表示为G=(V,E),V是图中节点的集合,E是图中边的集合。一个一层的图卷积网络运算公式如下:
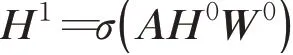
其中H0=X,X∈ℝN×D是图卷积网络的第一层输入,N为图中节点的个数,D代表节点的嵌入维度,A∈ℝN×N为邻接矩阵表示图中节点之间的连接关系,W0∈ℝD×K为权重参数矩阵,σ(·)代表一个非线性激活函数。若要捕获节点的高阶领域信息,则需要进行多层GCN叠加,其运算过程如下:
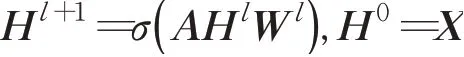
其中l表示层数。
2.4 GCN+Bi_LSTM层
图卷积神经网络在对图型数据进行处理时,往往是对节点的邻居节点进行卷积运算,从而通过邻域信息来更新自身节点。但其中忽略了节点之间的顺序信息,尤其是对于文本这种有着丰富的上下文语义信息的数据,让模型具有提取这种信息的能力尤为重要。虽然本文试图将文本数据建模为图形数据,但这些文本数据本质上仍是网格状的数据,进而保留了节点间的顺序信息,所以可以使用循环神经网络提取文本的上下文语义信息。
循环神经网络是一种处理时序数据的模型,在处理与序列相关的任务时获得了优异的表现。但在利用反向算法和梯度更新算法对模型进行权重更新时,循环神经网络出现了严重的梯度消失问题。于是本文采用循环神经网络的改进模型Bi_LSTM。该模型通过前向LSTM和后向LSTM组合而成,前向LSTM使单词获取上文信息,后向LSTM使单词获取下文信息。所以在建模上下文语义信息方面有着独特的优势。GCN+Bi_LSTM层如图3所示。
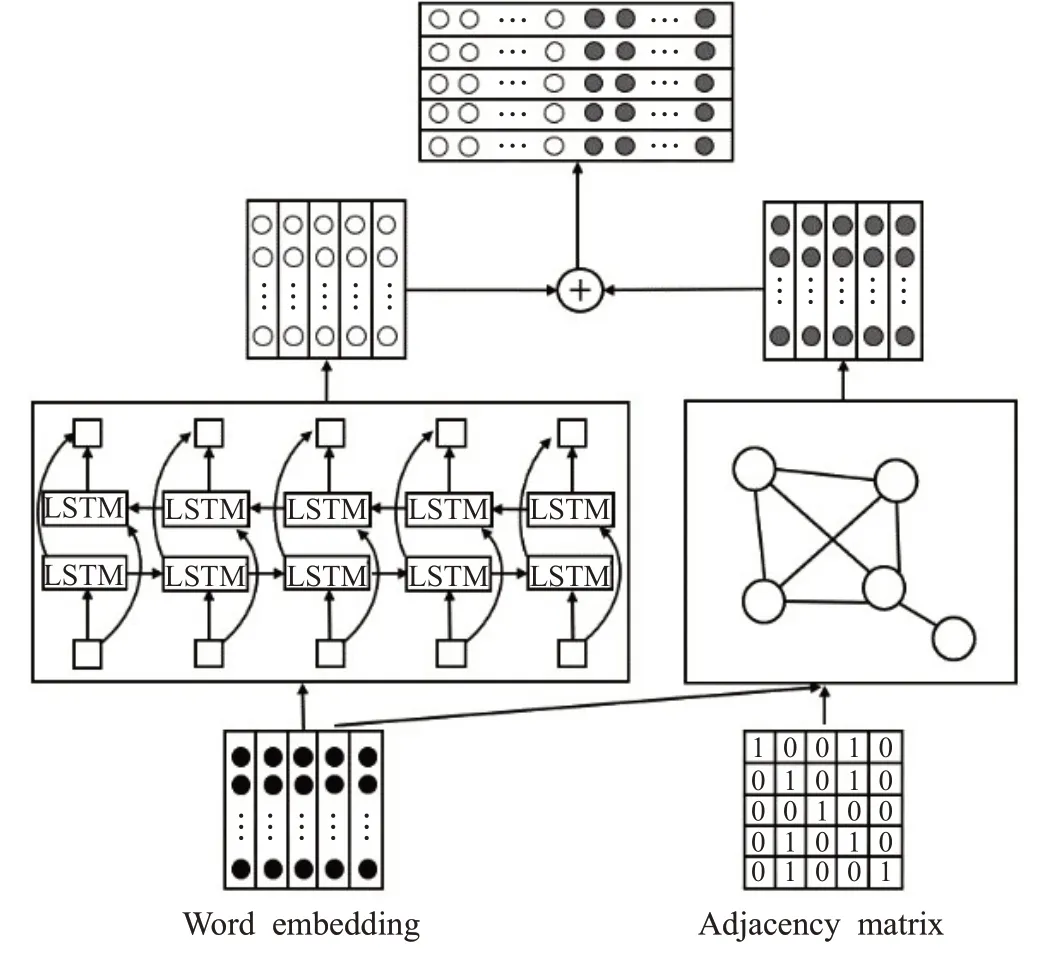
图3 GCN+Bi_LSTM层Fig.3 GCN+Bi_LSTM layer
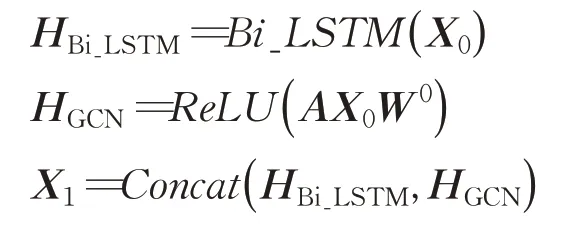
本文将文本表示为邻接矩阵和节点的特征矩阵,文本图中的每个节点对应着文本中一个单词,模型保留了文本中节点初始位置的顺序信息,即本模型中的特征矩阵是具有顺序信息的网格状数据。通过图卷积网络捕获单词间长距离依赖关系的同时利用Bi_LSTM去提取文本的上下文语义信息,进而弥补传统图卷积网络在上下文语义信息方面捕获能力不足的问题。
2.5 GCN+CNN层
由于传统的图卷积网络只在单个节点上进行卷积运算,并没有使用像卷积神经网络那样的可训练空间滤波器,所以导致图卷积网络在提取局部特征方面不如卷积神经网络。并且因为图中节点的邻居数量不统一进而导致图中禁止使用卷积核大于1的卷积运算。由于本文的文本数据是网格状的数据,所以可以使用卷积神经网络提取局部特征信息。
卷积神经网络最先在计算机视觉领域应用,后来才应用在自然语言领域。相比于循环神经网络,卷积神经网络更注重局部特征信息的提取,如在文本中对一些关键短语信息进行识别等,而这些关键短语对于文本的分类有着关键的作用。GCN+CNN层如图4所示。
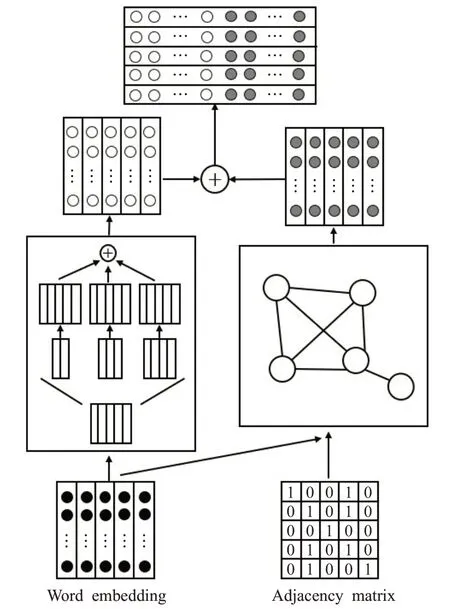
图4 GCN+CNN层Fig.4 GCN+CNN layer
文中卷积神经网络使用的是一维卷积,即只在文本序列的一个方向做卷积。由于是文本数据,所以网络中卷积核宽度和单词向量的嵌入纬度相等,高度分别采用2、3、4,即采用3种不同尺寸的卷积核提取文本不同类型的局部信息。
经过GCN+Bi_LSTM层得到的新特征矩阵X1作为本层的输入之一,另一个输入仍为邻接矩阵A。经过CNN输出得到HCNN,经过GCN输出得到HGCN,然后将两者连接得到新的特征矩阵X2,运算过程如下:
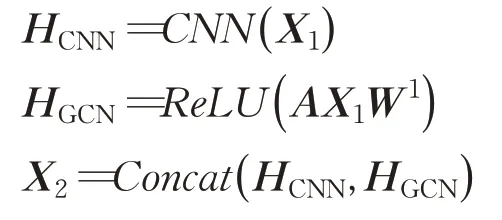
由于本文的图形数据是具有节点间的顺序信息的,即特征矩阵为具有顺序信息的网格状数据。所以可以使用卷积核大于1的卷积运算在特征矩阵上进行文本局部特征信息的提取。通过图卷积神经网络和卷积神经网络的组合,可以充分利用两个模型的优点并克服两者各自的局限性。具体来说,一方面,卷积神经网络利用了可训练的空间滤波器提取局部信息,在提取过程中为了避免产生大量的可训练参数,使用了尺寸较小的卷积核。但这会导致卷积运算在特征矩阵上的感受野较小,对于远距离的文本特征捕获能力不足。而图卷积神经网络通过文本图中节点之间的连边可以迅速地增加模型的感受野,从而捕获文本长远距离的特征,补充了卷积神经网络的不足。另一方面,卷积神经网络通过其在捕获局部特征信息方面的优势去弥补图卷积神经网络在该方面的不足,二者相辅相成。
本文模型包含两个GCN+CNN层,第一个GCN+CNN层是为了初步提取文本的局部特征信息,捕获文本浅层的词与词之间的关系。第二个GCN+CNN层在经过池化层筛选后的新的文本子图上进行更深层次的局部特征信息提取,从而捕获文本中潜在的、深层次的词与词之间的语义相关性,能使模型更好地提取文本特征信息。
Ruff项目[13],把边缘计算的概念和区块链结合在一起,提供了统一的IoT应用接口,并提供IoT主控设备和受控设备的全局管理,它属于IoT数据应用层面的项目。该项目中轻节点代表具体的IoT受控设备,该设备通过存储主控设备的公钥来识别主控设备的命令。通过智能合约,主控设备可以把受控设备的部分功能以租赁或转移的形式提供服务。该项目搭建自己的公链,采用了股份授权证明(DPoS)共识算法,每轮选择105个节点参与区块生成。该公链能否承载其设备租赁的服务模式,还需要在实践中检验。
2.6 池化层
在使用卷积神经网络在网格状数据上提取局部特征信息时,池化层非常重要,因为池化层能够快速扩大卷积神经网络的感受野捕获更大范围的信息。于是本文使用图池化层选择出重要的节点构成新的子图送入下一层卷积神经网络中,有助于卷积神经网络进一步捕获更深层次的局部特征信息。图池化层结构如图5所示。
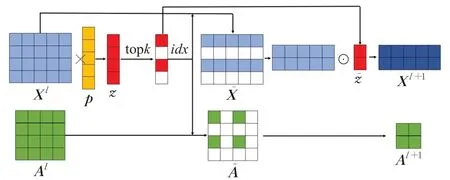
图5 图池化层Fig.5 Graph pooling layer
其中,图池化层的输入由特征矩阵X l∈ℝN×D和邻接矩阵A l∈ℝN×N构成,D表示节点的嵌入维度,N表示图中节点的个数。整个图池化层的传播规则定义如下:
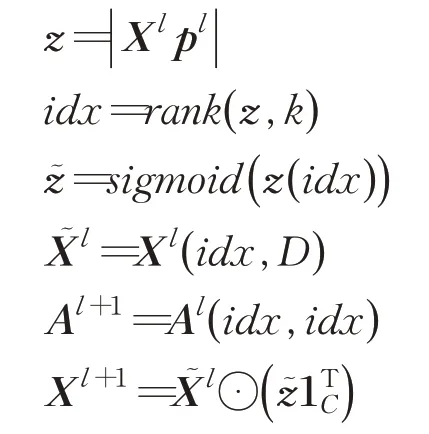
其中k是从文本图中被选出来构成新的文本子图的节点数量。p是一个可训练的投影向量,通过p与X l相乘的结果z来衡量节点的重要性,其中从中选择数值最大的k个节点作为新文本图的节点。rank(·)操作表示选取z中最大的k个数所对应节点的序号,并且这些序号对应于图中的节点。͂是将z(idx)进行sigmoid[16]归一化后的结果。是根据rank(·)操作所得到的节点序号提取到的节点特征矩阵,同理A l+1是依据rank(·)操作得到的节点序号对邻接矩阵进行行列提取所获得的新邻接矩阵。X l+1表示新特征矩阵,1TC表示一个单位向量的转置,将其与͂相乘会得到͂每个元素的和,X l+1中第i行的向量由中第i行向量和͂中对应的标量按元素相乘得到。图池化层的输出X l+1和A l+1作为下一层特征提取层的输入。
2.7 分类
初始数据在经过模型3个特征提取层和1个池化层处理后,得到最终的特征矩阵X4。这里,将之前每一层得到的特征矩阵和X4进行拼接操作,然后将X4输入到全连接层再通过SoftMax函数得到最终的预测值。其运算过程如下:
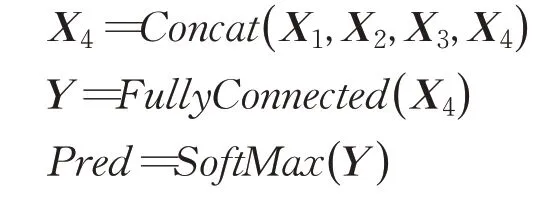
对于模型中的所有参数采用梯度下降算法进行更新优化,使用交叉熵损失函数作为模型的损失函数。
3 实验及结果分析
3.1 数据集介绍
本文在3个英文数据集上进行了实验,下面是对3个英文数据集的介绍。
AG News:数据集来自文献[17]是一个包含4个主题的新闻数据集:世界、体育、商业和科技。
R8:是路透社新闻数据集的一个子集,来自文献[12],包含8个主题。共有5 485个训练数据和2 189个测试数据,并且每个数据只与一个主题相关。
MR:是一个电影评论数据集,其中每个评论只有一句话[18]。同时每个评论的情感极性只能从积极和消极中选一个,是一个二分类。
表1展示了3个数据集的统计信息。
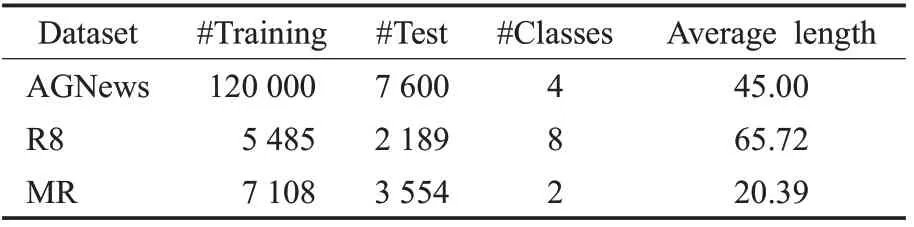
表1 数据集统计表Table 1 Dataset statistics
3.2 对比实验
(1)CNN:卷积神经网络[6],这里使用随机初始化的单词嵌入向量作为输入。
(2)LSTM:长短时记忆网络模型[19],使用模型最后一层隐向量作为文本的表示。
(3)PTE:大规模预测文本嵌入[20],模型将标签和共生单词表示成一个异质信息网络,然后将该网络降维到一个低维度向量空间,进而得到文本表示。
(4)fastText:一种文本分类方法[5],模型由输入层、隐含层和输出层组成。输入层是由多个向量表示的单词组成,隐含层是对多个词向量的平均,输出层输出类别。
(5)LEAM:一种联合嵌入单词和标签的文本分类方法[8],通过将标签信息嵌入到单词向量中,以更好地获得文本表示。
(6)textGCN:一种使用图建模文本的文本分类方法[12],将文本中单词和文档作为节点,其中文档和单词的边基于单词在文档中的出现信息,单词和单词的边基于词的全局词共现信息。
3.3 实验参数设置
在生成文本图的过程中,滑动窗口大小设置为4,滑动窗口的步长设为1。图中最大节点数设置为100,单词嵌入维度设为300,使用Adam训练器[21]进行epoch=30的训练,学习率初始化为0.001,在15至25 epoch之间衰减0.1;dropout率设为0.55,批处理大小设为256。在模型中使用RELU作为非线性激活函数,基线实验中的参数均采用原论文或者复现的设置。
3.4 实验结果
表2为本文在3个数据集上实验的结果,分类的评价标准是错误率。从表中可以看出本文模型相较与各基线模型有着良好的分类效果,证明了本文模型的有效性。其中本文模型相比于textGCN模型有着一定程度上的效果提升,说明本文模型引入了CNN和LSTM两种模型,确实丰富了GCN的上下文语义信息和局部特征信息,使得本文模型相较于textGCN有着较好的分类性能。
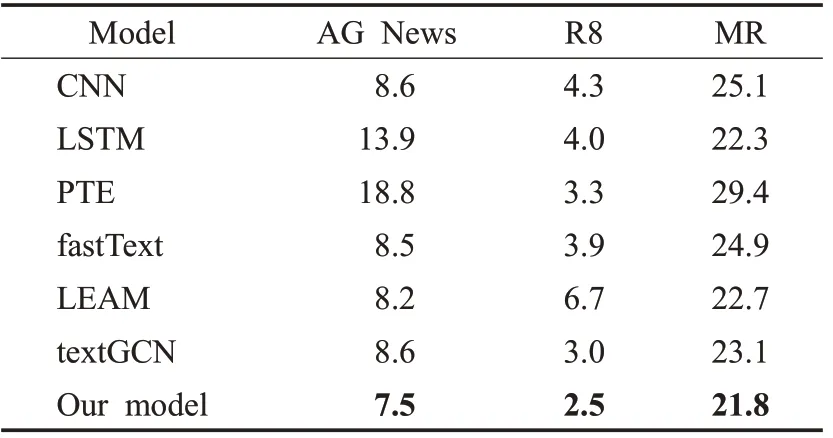
表2 实验结果(错误率)Table 2 Experimental results(Error rate)%
3.5 消融实验
本文对所构建模型的有效性进行了消融实验,其结果如表3所示,其中(w/o)表示删除该模块的模型。从表中可以看到删除相应模块的模型相较于总模型在性能上均存在一定程度的下降,说明模块之间是相辅相成的。从中可以观察到不同的模块在不同的数据集中有着不同的作用。例如,在不使用GCN+Bi_LSTM模块的情况下,在MR数据集上取得了最坏的分类结果。这是因为MR数据集是情感分类数据集,文本中带有情感信息,而Bi_LSTM能够捕获文本的上下文语义信息进而提取到文本的情感信息。对比消融实验中第二个实验和第三个实验的结果,可以看出第一个GCN+CNN层在初步提取文本局部特征信息和浅层词与词之间关系上的有效性。此外,第三个实验的错误率比总模型高,说明了第二个GCN+CNN层在进一步提取文本的局部特征信息,捕获文本深层次的关键短语信息上有着重要的作用,能帮助模型更好地表示文本信息,从而说明了该模块的有效性。
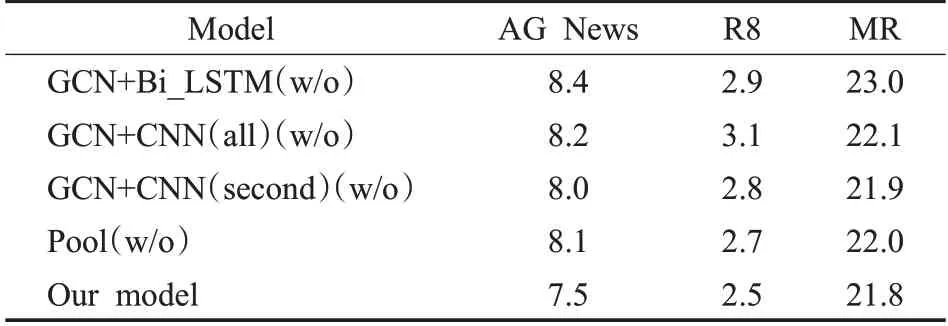
表3 消融实验结果(错误率)Table 3 Ablation experimental results(error rate)%
3.6 参数分析
本文模型中引入了池化层,为了探究增加池化层带来的参数变化对分类效果的影响,在AGNews数据集上进行参数分析实验,得到了表4的实验结果。从表中看出,使用了池化层的模型相比于未使用池化层的模型,模型参数增加了0.08个百分点,分类效果却提升了0.6个百分点。这表明虽然引入了池化机制增加了模型的参数数量,但数量很少不会增加模型过度拟合的风险,且在这种情况下模型获得了一定程度的效果提升。

表4 池化层参数分析Table 4 Parameter analysis of pool layer
图6~8分别展示了模型在3个数据集上使用不同滑动窗口大小对分类的影响,从图中可以看出模型在R8和AG News两个数据集上错误率是先减少,当窗口大小大于4时错误率反而增加。而在MR数据集上错误率的变换是先增加,在窗口大小为4时错误率取得最小值,当窗口大小继续增大时错误率也接着增加。从3个数据集上错误率的变化可以看出,滑动窗口过大过小都不好,窗口过大导致一个窗口中容纳的单词数量增加,进而使得文本图中节点之间的边数增多,在为节点增加更多邻域信息的同时会引入与分类无关的信息;而窗口过小会导致一个窗口中的单词数量减少,使得文本图中的节点之间的边数减少,这样会将节点的一些关键信息丢失从而降低分类性能。
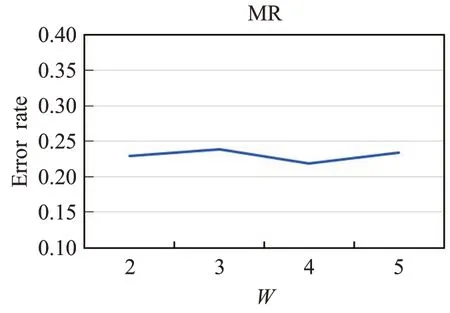
图6 窗口大小W对MR分类效果影响Fig.6 Effect of window size W on MR classification
图9~11分别展示了模型在3个数据集上使用不同的节点数k对分类的影响。从图中可以看出当节点数k过多或者过少,分类的错误率相比于k=50的时候要高。节点数k过多导致池化后留下较多节点,一些与分类无关的信息被保留下来使得池化的作用被削弱。节点数k过少导致重要的节点被丢弃,节点中包含的关键信息没有捕获到,也违反了池化的目的。所以本文选择k=50作为模型的重要节点数。
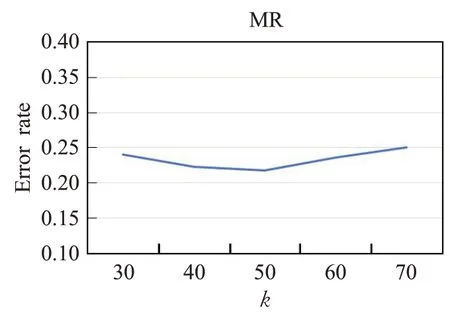
图9 重要节点数k对MR分类效果影响Fig.9 Effect of number of important nodes k on MR classification
4 总结
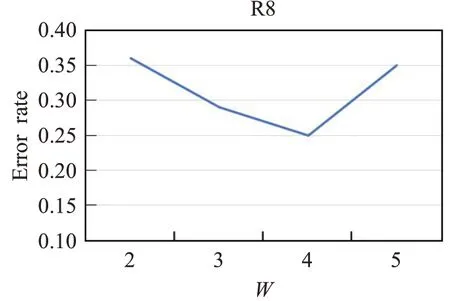
图7 窗口大小W对R8分类效果影响Fig.7 Effect of window size W on R8 classification
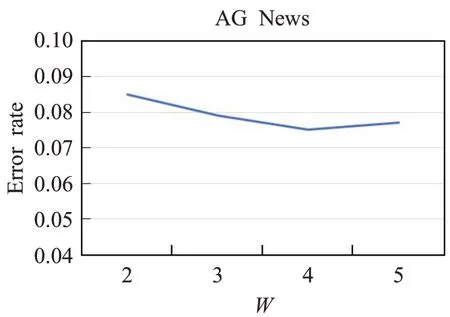
图8 窗口大小W对AG News分类效果影响Fig.8 Effect of window size W on AG News classification
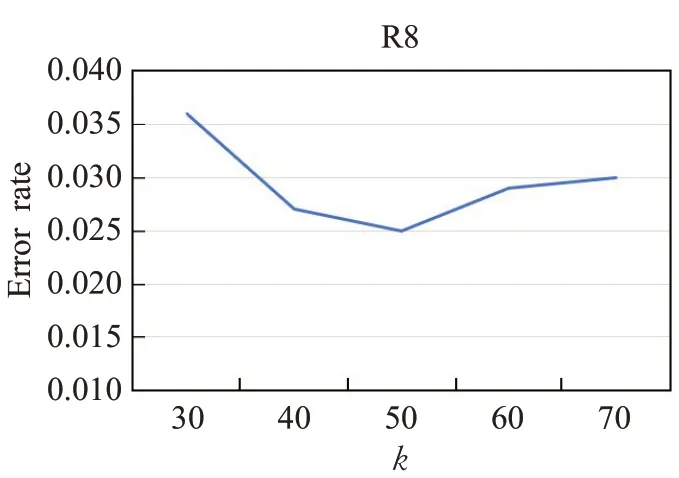
图10 重要节点数k对R8分类效果影响Fig.10 Effect of number of important nodes k on R8 classification
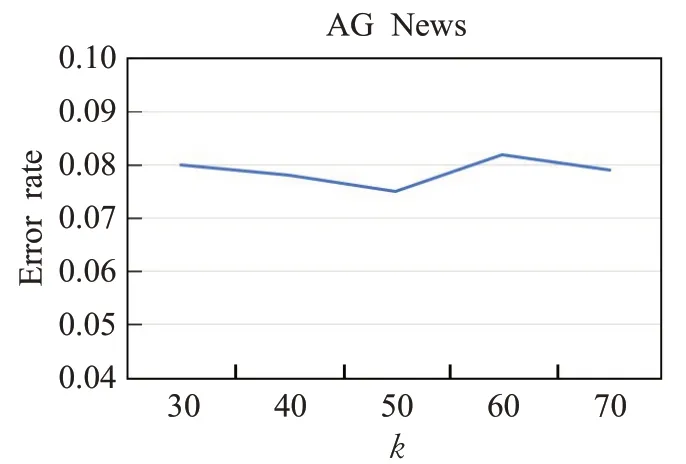
图11 重要节点数k对AG News分类效果影响Fig.11 Effect of number of important nodes k on AG News classification
本文构建了一个深层神经网络和图卷积网络相结合的模型,利用卷积神经网络和双向长短时记忆网络能够捕获局部特征信息和上下文语义信息的优点去补充图卷积网络在文本表示上的不足,同时采用了图池化层进一步提升了模型对深层局部特征信息的提取能力,丰富了模型对文本信息的表示,提高了文本分类的效果。本文在3个英文数据集上进行了实验,相较于基线模型均取得了一定程度的提升。在将来的工作中,会考虑在深层学习模型中添加常识信息,以提升模型的泛化能力。
猜你喜欢
现代电力(2022年2期)2022-05-23
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
北京航空航天大学学报(2018年1期)2018-04-20
高中生学习·高三版(2016年9期)2016-05-14
