
基于残差网络和门控卷积网络的语音识别研究
2022-04-08 03:42朱学超任晓颖
计算机工程与应用 2022年7期
朱学超,张 飞,高 鹭,任晓颖,郝 斌
内蒙古科技大学 信息工程学院,内蒙古 包头 014000
自动语音识别(ASR)是一种将语音转为文字的技术,语音是人与机器之间最便捷高效的交互方式之一。如今出现了越来越多的语音交互产品,服务于医疗、教育等领域,为人们生活带来了巨大的变化。传统语音识别最常用的算法是基于混合高斯模型的隐马尔可夫模型(GMM-HMM)[1-3],虽然取得了不错的成果,但是该模型组件复杂,在训练过程和解码过程中效率都比较低。随着深度学习技术的跨越式发展,端到端神经网络在许多语音识别任务上取得了很好的效果。这些模型使用一个单一的、端到端训练的神经网络取代了传统的多组件ASR模型,从而,极大地简化了训练过程。端到端的ASR模型是一种序列到序列模型,直接将特征映射到对应的字符或单词。其中,文献[4]首次提出联结时序分类(connectionist temporal classification,CTC)结构,并验证了CTC对于声学建模的有效性。基于CTC的ASR模型通过引入CTC准则,不仅解决了输入输出序列不对等问题,而且不需要输入输出序列在时间维度上进行任何预对齐。
随后,改进的循环神经网络(recurrent neural networks,RNN)被广泛应用于基于CTC的端到端ASR模型中。文献[5]提出了基于双向长短时记忆神经网络-联结时序分类(BLSTM-CTC)的端到端声学模型,该模型取得了较好的效果,并成功解决了声学模型和语言模型难以融合的问题。文献[6]提出了一种基于序列级转录的端到端语音识别系统,该系统改进了BLSTM,以音素为基本建模单元,并通过序列区分度训练技术提升了CTC声学模型的建模效果。文献[7]提出一个CNNBLSTM-CTC的端到端中文语音识别模型,采用卷积神经网络(CNN)学习局部语音特征,BLSTM学习上下文信息,使用CTC进行解码。文献[8]提出了基于ResNet-BLSTM-CTC的端到端声学模型,该模型以语谱图作为输入,通过残差网络中的并行卷积层提取不同尺度的特征。虽然RNN具有较强的长时建模能力,但由于RNN结构复杂,容易导致梯度消失问题,而且RNN训练需要耗费大量时间,对硬件性能要求也很大。针对RNN存在的问题,文献[9]结合前馈神经网络和RNN的优点,提出了前馈序列记忆神经网络(feedforward sequential memory networks,FSMN),FSMN是通过在前馈神经网络的隐层中添加一些可学习的记忆模块,从而可以对语音的上下文进行有效地建模。但是标准的FSMN仍具有较多的参数,文献[10]借鉴了矩阵低秩分解的思想在FSMN网络中引入了一个project层进行降维,提出了紧凑前馈序列记忆网络(compact FSMN,cFSMN),在语音识别交换机任务中,该模型识别性能明显优于BLSTM。而目前在很多领域,深层网络模型被证明具有更强的性能。因此文献[11]在cFSMN的基础上增加了跳跃连接(skip connection),提出了深度前馈序列记忆神经网络(deep FSMN,DFSMN),构建了一种效率较高的实时语音识别端到端模型。文献[12]在中文数据集上,验证了DFSMN识别效果比cFSMN的好。同时在大规模语言任务上,文献[13]提出了门控卷积神经网络(gated convolutional neural network,GCNN),摆脱了RNN对上下文相关性建模的依赖,且其效果明显优越于RNN。文献[14]提出了基于GCNN的声学模型,通过堆叠一维GCNN提取上下文信息,取得了较好的效果。
基于RNN的声学模型还存在另外一个问题。在基于RNN的声学模型中,常常使用CNN解决语音信号频率维度的多变性[15-18],以此提升模型的稳定性,但CNN提取有效特征的最大性能是有限的,对于具有不同程度冗余信息难以进行有效的特征提取,从而会导致RNN输出的上下文信息不具有不变性和鉴别性,会对原始特征的变化变得敏感,使得模型的识别效果和鲁棒性较差。语谱图正是具有这样高度冗余信息,因此,RNN需要大量的数据才能进行正确训练。
为了解决基于RNN模型存在的训练需要耗费大量时间和需要大量数据才能进行正确训练两个问题,本文结合了残差网络(residual networks,ResNet)[19]和一维GCNN的优点,首先ResNet和GCNN均是卷积操作,可以实现并行计算,加快模型训练速度。然后通过ResNet可以提取高层抽象特征,使模型具有一定的鲁棒性,通过堆叠GCNN可以捕获有效上下文信息,提高模型的识别率。同时本文对ResNet进行了优化,并且为了提升GCNN的性能使用了一维深度可分离卷积,并在此基础上加入前馈神经网络层(feedforward neural network,FNN),提出了门控卷积前馈神经网络(gated convolutional feedforward network,GCFN)。基于此,本文构建了联合CTC的ResNet-GCFN端到端声学模型。并在Aishell-1中文数据集上,验证了该模型具有较好的识别率和鲁棒性。
1 相关研究
1.1 残差网络
残差网络主要由卷积层、批量归一化(batch normalization,BN)和激活函数基本部分组成。卷积层主要用于特征提取,同时也可以用于设置适当的卷积层中卷积核步长对信息进行下采样,以此减少计算量,其卷积计算公式如(1)所示。BN操作是一种特征标准技术,由于在训练过程中,后面层输入的数据分布会随着前面层训练参数的更新而变化,因此可以使用BN操作对网络参数进行自适应调整,以此解决输入数据发生偏移或者增大的影响[20]。激活函数是用于增加更多的非线性,以此拟合更加复杂的任务。

式中,x i表示输入特征图x的第i层通道,y j表示输出特征图的第j层通道,k表示卷积核,b表示偏置,M j是x的所有通道,被用于计算输出特征图的第j层通道。
通过堆叠上述卷积层、BN层和激活函数,并加入恒等映射层,构建了残差网络中的残差结构单元(residual building unit,RBU),如图1所示。
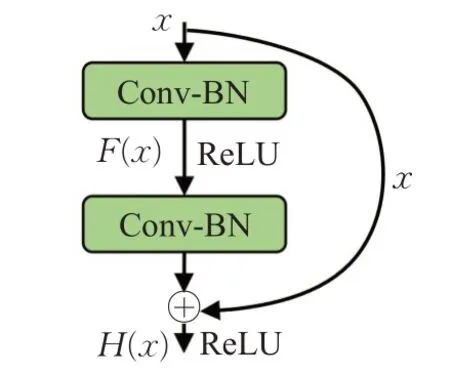
图1 残差结构单元(RBU)Fig.1 Residual building unit(RBU)
其中,设RBU输入为x,输出为H(x),F(x)表示网络的学习残差函数。因此RBU可以表示为F(x)=H(x)-x。如果x的维度与学习残差函数维度不同,则可以利用1×1的卷积核进行升维或降维。加入恒等映射层,可以缓解梯度消失和网络退化现象。
1.2 门控卷积神经网络
门控卷积神经网络(GCNN)主要由卷积层和门控线性单元(gate linear unit,GLU)组成,GLU可以理解为是卷积神经网络中的一种门控机制,它仅具有输出门,该输出门可以控制网络层级之间的信息传播,能够使有用信息通过网络,抑制无用的信息[13]。因此通过堆叠GCNN可以精确控制依赖项的长度,捕获有效的长时间记忆。GCNN只有一个输出门与循环神经网络(LSTM,GRU)相比不同的是更加容易进行梯度传播,不易造成梯度消失和梯度爆炸问题,而且在计算时间上也大幅度减少。其GCNN结构,如图2所示。公式(2)可用于表示GLU计算结果。
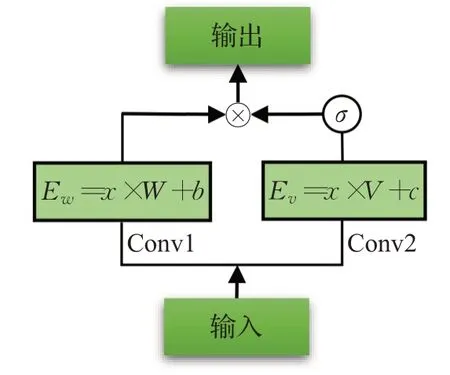
图2 GCNN单元Fig.2 GCNN unit

其中,E表示输入的全部信息,E w表示传入下一层的信息,而E v决定了E w传入下一层的信息量,H表示最终输出信息,σ是Sigmoid激活函数,⊗是矩阵元素之间的乘积。
1.3 CTC算法
CTC可以理解为是一种序列到序列映射的技术,它不仅解决了输入输出序列不对等问题,而且不需要输入输出序列在时间维度上进行任何预对齐。CTC是通过引入一个“blank”符号对静音等状态建模,来实现特征序列与文本序列的自动对齐。基于CTC的声学模型训练目标是在给定输入序列X下,通过调整声学模型中的参数最大化输出标签序列的对数概率从而使得输出标签序列Y*无限接近正确标签序列,该过程极大地简化了声学模型的训练过程,其计算公式如下:
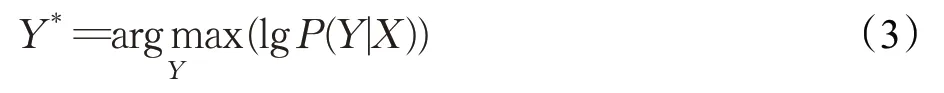
CTC即给定语音特征序列X=(x1,x2,…,x T)映射到对应的文本序列Y=(y1,y2,…,yU),通常T≥U。根据实际情况,会对特征序列X进行适当的下采样操作,减少训练过程的计算量,使得特征序列X的长度成倍数缩小,即T=nT′,但T′≥U。然后由CTC在每帧上计算得到一个N维的向量,其中,N表示建模单元总数。CTC是通过Softmax函数将输出向量转换为概率分布矩阵Y′=(y′1,y′2,…,y′T′),其中,y′tk代表t时刻在第k个建模单元的概率。按照时间序列将每帧特征对应的建模单元进行合并,则可以得到一个输出序列π,称之为一条路径。在输入为X的条件下,输出路径为π的概率,其计算公式如下:
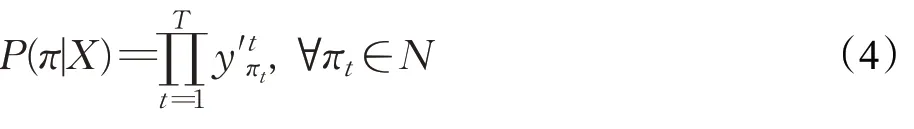
虽然在训练过程,会进行下采样操作。但预测的文本序列仍然会比标签文本的序列要长。因此,需要对预测的文本序列进行路径合并操作,首先进行删除重复的非空白标签,然后移除空白标签。由于空白标签表示这一帧没有输出,因此应该删除它以获得最终预测的文本序列。可以发现,最终预测的文本序列可以有多种路径可能。将最终预测的文本序列记作l,即π与l为一对多关系,将π与l之间的转换函数记作A。则给定输入X的情况下,计算最终的文本序列为π的概率,其计算公式如下:

式(6)通过将所有文本序列的负对数概率求和,得到最终CTC损失函数,然后反向传播训练不断降低CTC损失值使得到的输出序列无限接近正确标签序列,并通过CTC解码可以得出最终的文本序列,式(7)、(8)可表示CTC解码计算过程,π*表示最佳路径,Y*表示最终的解码结果:
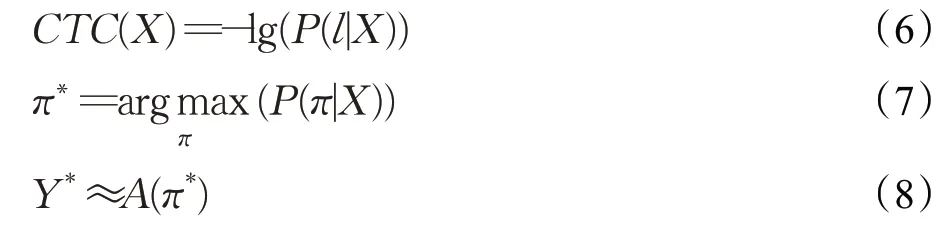
2 ResNet-GCFN声学模型
ResNet-GCFN模型主要由ResNet和GCFN组成,该模型将语谱图作为输入,通过ResNet提取语谱图的高层抽象特征,然后由GCFN对特征进行上下文建模,其网络具体结构如图3所示。
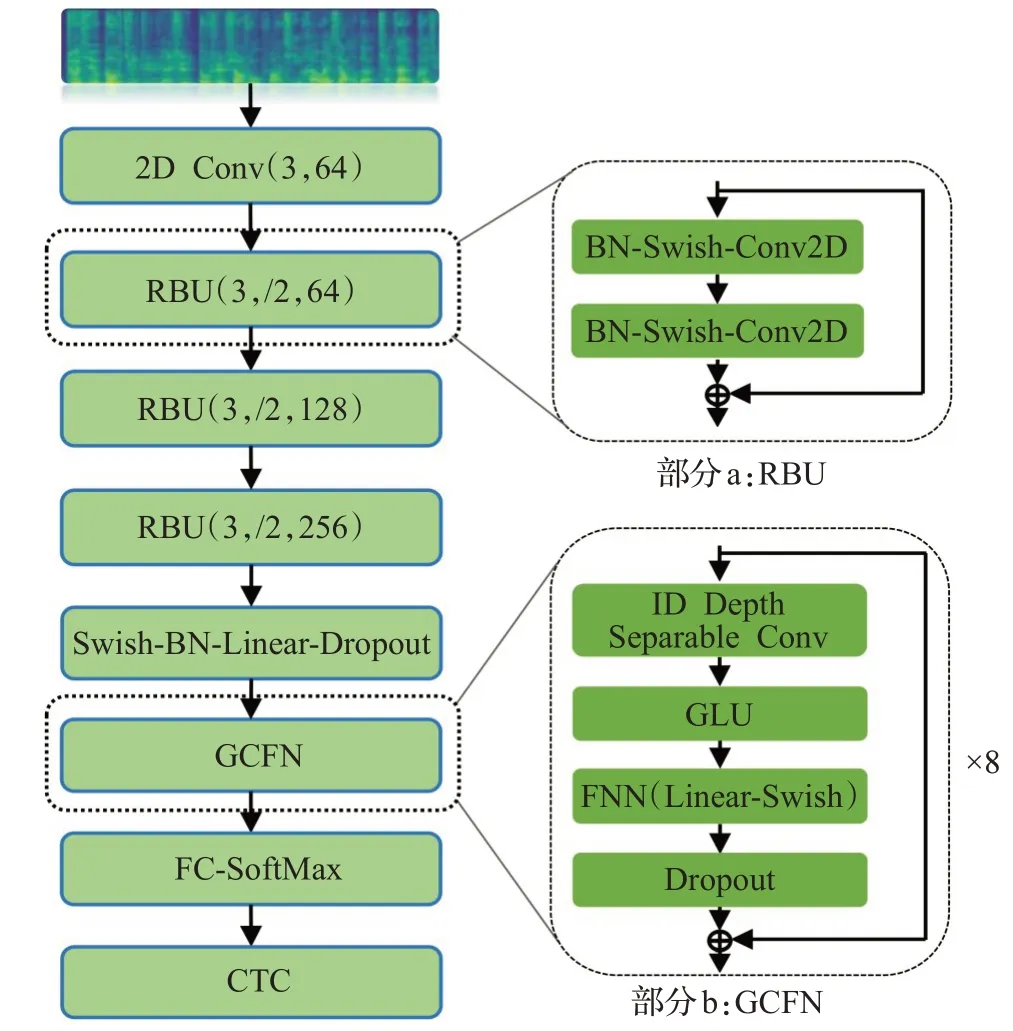
图3 ResNet-GCFN声学模型Fig.3 ResNet-GCFN acoustic model
2.1 输入特征
ResNet-GCFN模型使用的输入特征是语谱图,通过对原始语音信号提取语谱图,其中设置时间窗宽度为25 ms,窗移10 ms,使用汉明窗对原始语音信号进行分帧、加窗。然后经过快速傅里叶变换(FFT)和谱线能量计算得到200维的语谱图特征,语谱图最大程度保留了语音的原始信息。而传统使用的语音特征(Fbank、MFCC)在FFT之后使用人工设计的滤波器组来提取特征,不可避免造成了频域信息的损失。因此,该模型相比其他以Fbank,MFCC作为输入的语音识别模型具有天然的优势。
2.2 优化残差网络
图3中的a部分表示的是ResNet中的RBU结构,该RBU使用了文献[21]的结构,该结构主要是将BN和激活函数放在卷积层之前,通过保持恒等映射层的“干净”,可以让信息在前向传播和反向传播中更加平滑传递。同时将Swish激活函数引入到RBU中,因为ReLU强制稀疏处理会减少模型有效容量,使某些参数得不到激活,产生神经元“坏死”现象。同时在实验过程中,发现使用ReLU激活函数模型不能进行学习。而Swish弥补了ReLU的缺点,并且有利于缓解网络中存在的梯度爆炸问题,在深层网络模型中,Swish的效果是优于ReLU的[22],其Swish计算公式如下:

式中,β是常数或可以训练的参数。
2.3 优化门控卷积神经网络
本文GCNN是融合了GLU的一维深度可分离门控卷积神经网络。深度可分离卷积主要分为深度卷积和逐点卷积两个过程[23],如图4所示,假设输入C×T的特征图,深度卷积首先实现通道分离,然后进行逐通道卷积,一层通道只被一个卷积核卷积,一个卷积核也只负责一层通道,这个过程产生特征图的通道数C和输入的通道数是一样的;而逐点卷积将得到的C×T′特征图进行多通道卷积,逐点卷积决定了最终输出特征图的通道数。与常规卷积相比,深度可分离卷积极大地减少了计算量,在计算量相同的情况下,深度可分离卷积可以将网络层数比常规卷积做得更深。因此,使用一维深度可分离卷积能够极大程度提高了GCNN的层数,使得能够捕获更加有效的长时间记忆。
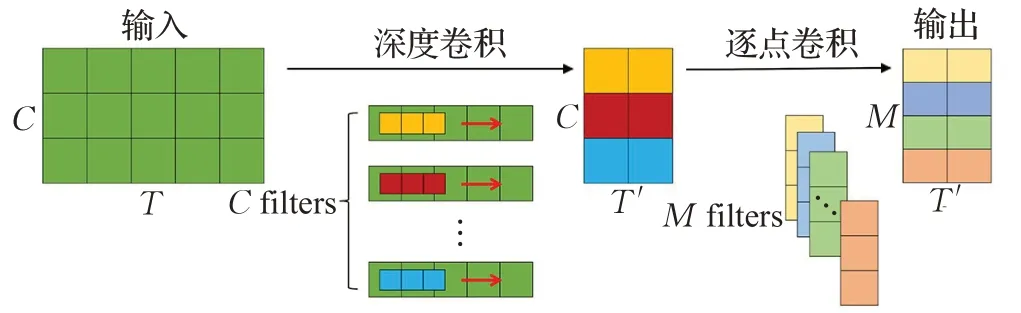
图4 一维深度可分离卷积Fig.4 1D depth separable convolution
为了进一步提升GCNN的性能,为GCNN加入了FNN层,该层包括了矩阵线性变化linear层和swish非线性激活函数。通过FNN来变换GCNN的输出空间,在一定程度上增加了GCNN网络的有效容量,以此增加模型的表现能力[24],公式(10)可表示该层网络。同时,为了防止过拟合,增加了dropout层。然后,通过一条“捷径”连接,缓解了网络层数较多引起的梯度消失和网络退化问题。基于此,提出了门控卷积前馈网络(GCFN),如图3中的b部分所示。
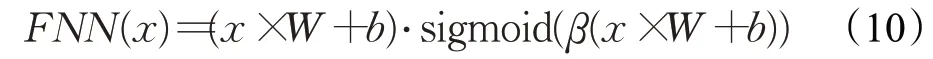
3 实验与分析
3.1 实验环境和数据
本文使用希尔贝壳开源的Aishell-1[25]数据集进行实验,该数据集是中文普通话语音数据集,其采样率为16 000 Hz。数据集包含了400个说话人的141 600条标准语料,其中训练集、验证集以及测试集分别包含120 098、14 326以及7 176条标准语料,数据总时长约为178 h。并且本文使用了Thchs30数据集提供的咖啡馆噪声(cafe)、汽车噪声(car)和白噪声(white)3种类型噪声,用于模型在不同噪声环境下的性能测试。实验所用的硬件配置为I7-9750H处理器,16 GB运行内存,GPU显卡为RTX2080Ti;操作系统是Ubuntu18.04,使用的深度学习框架是Tensorflow2.3。
3.2 实验设置
(1)声学模型参数:本文直接以汉字为建模单元,在Aishell-1数据集中收集到4 329个汉字,加上一个“blank”符号,因此本文的实验模型最后一层全连接网络的网络节点是4 330。Batch size设置为8,使用的优化器是Adam,初始学习速率为1×10-3,在训练过程中,当损失值突然增大或者趋于稳定时,将学习速率调为上一阶段的1/10,继续训练,最终学习速率达到1×10-5。
(2)解码:本文采用宽度为5的束搜索对声学模型最后概率分布进行解码。并通过训练集数据训练一个字符级3-元语言模型,通过浅融合集成到束搜索中,其中设置语言模型权重为0.2。
(3)实验评价指标:为了测试识别结果的准确性,本实验使用的评价指标为字错误率(character error rate,CER),其公式如下:

其中,R为替换错误字数,I为插入错误字数,D为删除错误字数,N是正确标签序列的总字数。
3.3 模型的性能比较
表1将本文ResNet-GCFN模型(CER)结果与CNNBLSTM-CTC[7]、ResNet-BLSTM-CTC[8]、DFSM-3-gram[12]、DFSM-T[12]和1DCNN-GLU-CTC[14]模型在测试集上进行了比较。其中,ResNet-GCFN和ResNet-BLSTM-CTC模型输入是语谱图特征,CNN-BLSTM-CTC、DFSM-3-gram、DFSM-T和1DCNN-GLU-CTC模型输入是Fbank特征。由表1的数据表明,在没有语言模型(language model,LM)的情况下,本文模型的性能已经达到了11.83%,表现优于其他模型;添加了LM,ResNet-GCFN实现了最低的CER,达到了11.43%。这验证了ResNet和GCFN组合的有效性。
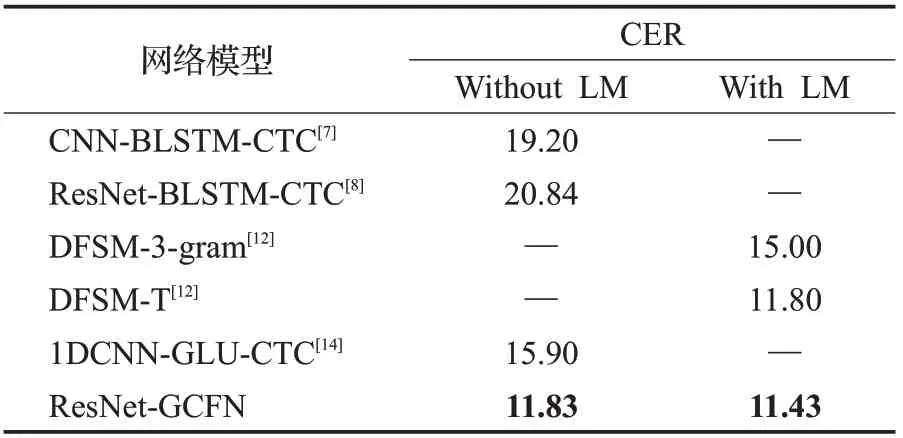
表1 模型的性能比较Table 1 Performance comparison of model %
3.4 消融实验
为了进一步验证ResNet-GCFN各部分的有效性以及改进的有效性,本文设置了DCNN-BLSTM、ResNet-BLSTM、DCNN-GCFN、ResNet-GCNN和ResNet-GCFN这5个模型,其中输入均是200维的语谱图,在均不外接语言模型情况下,分别在验证集和测试集上进行了对比实验,其网络具体配置如表2所示。

表2 网络结构配置Table 2 Network structure configuration
图5和图6分别表示训练时的损失值曲线和错误率曲线。可以看出随着迭代次数的增加,声学模型损失值和错误率逐渐收敛到一个固定的范围内。基于BLSTM的模型损失值减少至5.5以上,而基于GCNN的模型可以减少至3以下,可以得出,基于GCNN的模型相较于基于BLSTM的模型训练收敛速度更快。并且基于改进的GCFN模型比基于BLSTM的模型显著降低了声学模型错误率,具体实验结果如表3所示。
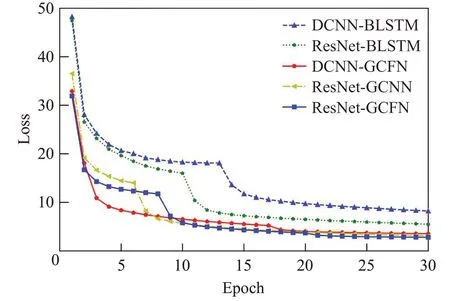
图5 损失值曲线Fig.5 Loss curve
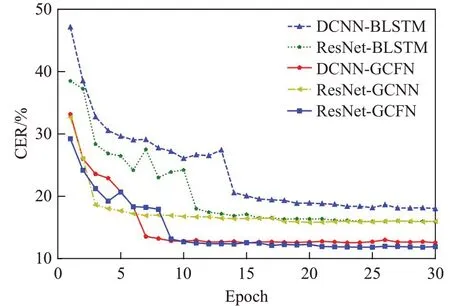
图6 错误率曲线Fig.6 Error rate curve
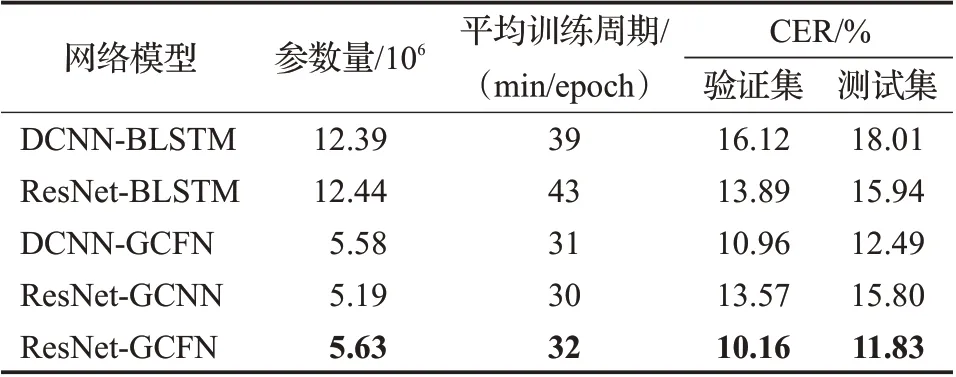
表3 不同模型的训练时间及CERTable 3 Training time and CER of different models
通过表3可知,本文提出的ResNet-GCFN模型在验证集和测试集上字错误率均低于其他模型。在测试集上,分别比DCNN-BLSTM、ResNet-BLSTM、DCNNGCFN和ResNet-GCNN模型的字错误率降低了6.21、4.11、0.66个百分点和3.97个百分点,取得了较好的效果。通过ResNet-GCNN和ResNet-GCFN实验,验证了模型增加FNN层的有效性,GCFN极大地提高了模型的性能,这是因为GCNN存储信息的容量是一定的,堆叠多层GCNN会导致传入后面网络的有效信息逐渐减少,而通过增加FNN层在一定程度上增加了GCNN的有效容量,使得模型具有较强的表现能力。通过对比DCNNBLSTM和DCNN-GCFN与ResNet-BLSTM和ResNet-GCFN两组实验,验证了GCFN上下文相关性建模能力是优于BLSTM网络的。这是因为CNN提取特征的最大性能是有限的,对于具有不同程度冗余信息的语谱图难以进行有效的特征提取,从而会导致BLSTM网络输出向量可能不具有不变性和鉴别性,而GCFN可以通过GLU消除无用的信息,并且通过堆叠GCFN能够精确控制依赖项的长度,捕获有效的长时间记忆,从而使得模型识别效果较好。同时通过比较DCNN-BLSTM和ResNet-BLSTM与DCNN-GCFN和ResNet-GCFN两组实验,得出ResNet性能是优于单一堆叠的CNN网络的,这是因为ResNet中的残差结构能够减轻训练过程中网络层数较多引起的训练误差,从而提高模型的性能。值得注意的是ResNet-GCFN的参数量仅仅是基于BLSTM模型的1/2左右,并且在每epoch训练花费时间也相对较少,验证了ResNet-GCFN模型在提高识别率的同时,也加快了训练速度。
3.5 低信噪比下的识别率变化
本文在表3的实验基础上,继续研究ResNet-GCFN模型的鲁棒性。将Thchs30数据集提供的咖啡馆噪声(cafe)、汽车噪声(car)和白噪声(white)3种类型噪声,用于实验模型在不同噪声环境下的性能测试。设置5组不同信噪比的测试集,信噪比范围是[-5,15],步长是5。每个测试集中的语音随机含有不同类型的噪声(white、cafe、car)。实验结果如表4,CNN具有一定的抗噪声能力,但DCNN-GCFN和ResNet-GCFN模型抗噪性能比其他模型都要好。因为模型在不同信噪比条件下,模型识别率的变化程度是不同的,可以看出DCNNBLSTM和ResNet-BLSTM识别率随着信噪比的降低下降速率越快,不利于实际环境的应用,而DCNN-GCFN和ResNet-GCFN模型识别率随信噪比降低下降速率相对缓慢。通过ResNet-GCFN和ResNet-GCNN对比实验,可以发现改进的GCFN极大提高了ResNet-GCFN的鲁棒性。ResNet-GCFN不仅受信噪比环境影响相对较小,而且在低信噪比下识别率相对较高。这是因为ResNet网络能够学习到高层抽象特征,使得对环境变化变得不敏感,此外GCFN网络会将ResNet输出特征转换为更加具有不变性和鉴别性的特征,使得语音识别效果较好。
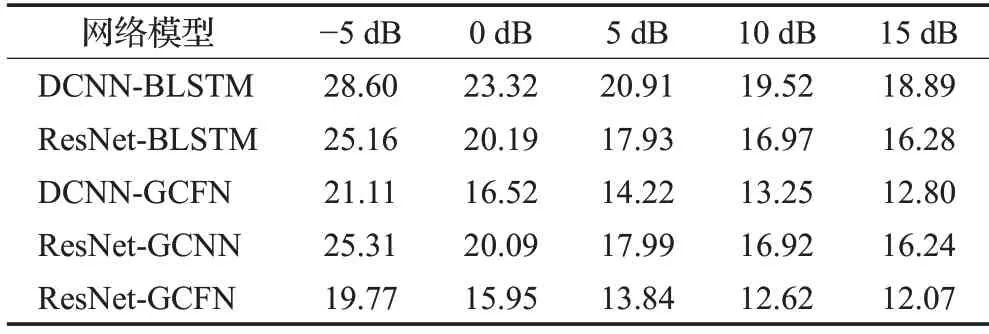
表4 不同信噪比下的CERTable 4 CER under different signal-to-noise ratio %
4 结语
为了捕获有效上下文信息以及加快模型的训练速度,提高语音识别的准确率和鲁棒性,本文提出了一种基于残差网络和门控卷积前馈网络的端到端声学模型(ResNet-GCFN)。该模型不再使用传统循环神经网络对上下文相关性建模,而是通过GCFN网络捕获有效的长时间记忆。通过实验验证了GCFN改进的有效性,并且验证了GCFN的性能是优于BLSTM的。同时在不同信噪比下,验证了基于GCFN模型的抗噪能力同样是优于基于BLSTM模型的。ResNet-GCFN模型不仅提高了识别率和鲁棒性,还加快了模型的训练速度,相对于其他模型,有着更好的实用性。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
家庭影院技术(2020年6期)2020-07-27
电子制作(2019年13期)2020-01-14
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年11期)2019-07-04
电子制作(2019年9期)2019-05-30
家庭影院技术(2019年1期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
小说界(2018年5期)2018-11-26
