
多头注意力与字词融合的中文命名实体识别
2022-04-08 03:41赵丹丹黄德根孟佳娜
计算机工程与应用 2022年7期
赵丹丹,黄德根,孟佳娜,谷 丰,张 攀
1.大连理工大学 计算机科学与技术学院,辽宁 大连 116024
2.大连民族大学 计算机科学与工程学院,辽宁 大连 116600
命名实体识别(named entity recognition,NER)是自然语言处理(nature language processing,NLP)的基础任务。NER对许多领域都有非常重要的影响,比如实体链接、关系抽取、智能问答等[1]。NER的目的是确定文本中实体的边界,并将实体划分为不同类型,如人名、地名和机构名等。以句子“任正非创建了华为”为例,NER的任务是识别出“任正非”是一个“人名”的命名实体,而“华为”是一个“公司名”的命名实体。目前实体识别工作相对成熟,对于上述语境简单的文本中进行NER任务可以取得较好的识别效果。但是,在上面的例句中,“华为”是作为公司名出现还是品牌名出现,就是中文的一词多义给命名实体的类型确定造成的困难,需要根据上下文的语义信息来判断。另外,中文的分词歧义对于实体边界的确定也有很大影响。如典型的“南京市长江大桥”的例子[2],实体边界划分错误也会影响中文NER的结果。研究发现,NER中实体边界的划分与单个汉字和汉语分词都密切相关。以往的工作或者采用汉字作为特征输入,或者利用词语作为特征输入,没能充分考虑字和词的共同特征。即便有的工作开始采用字词融合的方式作为特征输入,也仅仅是当前单词的特征与构成单词的字的特征相融合,依然不能很好地解决类似“南京市长江大桥”可能出现多种分词的问题。因为在传统的字词结合方法中,如果单词边界的划分错误,那么词向量与词内字向量结合,其信息的参考价值往往是在错误增强。本文提出的方案则是采用字向量与该字附近可能成词的词向量相融合以增强原有字向量的语义表达,以此来提高字向量的表达能力,同时降低分词错误的影响。
对已有用深度学习进行NER任务总结发现,其进行特征提取因关注文本的全部特征,分散了对重要特征的注意力,导致多层嵌套实体识别效果较差。例如在句子“中国驻美国大使馆提醒留学生戴好口罩”中提到的“中国驻美国大使馆”就是一个嵌套实体。其中“美国”和“中国”是地名,“中国驻美国大使馆”是机构名。通常的命名实体识别模型大多只能识别出其中的地名,而忽视了整体的组织机构名。造成这种结果是因为仅使用长短时记忆网络(bidirectional long short-term memory,BiLSTM)在计算过程中虽然能够提取到整个句子的语义信息,但无法将文本中的重要特征进行重点关注。已有方法开始将注意力机制应用到NER任务中,这样可以使得模型关注重要的特征信息。在已有研究的基础上进行改进,提出利用多头注意力机制对BiLSTM的输出调整不同权重,捕获语义相互关联信息的多重特征,使各个字之间成词的紧密程度、各个词之间联系的相关性得以有效体现。
针对上述NER任务的难点,本文提出了多头注意力与字词融合的命名实体识别模型,简记为CWA-CNER模型。该方法贡献在于:(1)将字向量和词向量结合送入BiLSTM提取上下文语义信息,兼顾字特征与该字附近可能成词的词特征,使命名实体识别实体边界划分错误影响降低,同时又可以获得相对丰富的中文词语的语义特征;(2)利用多头注意力机制对BiLSTM模型输出调整不同权重,捕获语义相互关联信息的多重特征,使各个字之间成词的紧密程度、各个词之间联系的相关性得以有效体现,对中文命名实体识别任务的分类标注提供重要依据。
1 相关工作
早期的命名实体识别方法主要使用手写规则和词典的方法[3]。这类方法大多依赖语言学家手工构造规则模板,其中最具代表性的是文献[4]提出的可以借助机器自动地发现和生成规则的DL-CoTrain方法,这种方法根据预定义种子规则集,再根据数据集进行监督训练得到更多规则。这种方法表现优秀,但可移植性较弱。随着机器学习的兴起,将统计方法和概率知识相融合,使用手写特征将训练样本表示为特征向量,利用机器学习算法将句子中的每个单词进行标签分类,如文献[5]最早提出了利用隐马尔可夫模型进行命名实体识别的系统,用于识别名称、日期、时间表达式和数字表达式。一般来说,使用隐马尔可夫模型速度较快,最大熵模型[6]和支持向量机模型[7]准确率较高。给定带标签的样本,最大熵原理可用于估计概率分布将实体类型分配至给定句子的上下文。但最大熵模型时间复杂度高,易导致训练代价高,并且需要明确的归一化计算,造成计算开销难以承受。
文献[8]提出了一种基于多通道神经网络(multiple channel neural network,MCNN)的新能源汽车实体识别模型,该模型融合了字词特征和片段特征,不再将实体识别当作传统的序列标注任务,利用半马尔科夫条件随机场(semi-Markov CRF,SCRF)针对片段特征建模,对输入的句子切分片段并对片段整体分配标记,同时完成实体边界的识别和实体分类。基于统计的方法对特征选取的要求较高,需要从文本中选择影响处理任务的各种特征,主要做法是通过对训练语料所包含的语言信息进行统计和分析。但传统机器学习的模型依赖人工设置特征,对语料库依赖较大,并且通用的大规模语料库较少,难以解决全新领域的中文命名实体识别。
近年来,深度学习不仅在计算机视觉、图像处理等方面取得了巨大的成功,而且在自然语言处理领域也取得了很大的进步。基于深度学习的NER模型已经成为主流[9-11]。文献[12]提出一种基于CNN-BiLSTM-CRF的网络模型,该模型不使用任何人工特征,通过神经网络充分对文本的局部信息特征进行抽象化抽取和表示,并学习和利用文本的上下文信息,实现对景点实体的识别。文献[13]对Transformer模型进行训练优化,以提取文本特征;利用条件随机场对提取到的文本特征进行分类识别。文献[14]提出了一种融合字词BiLSTM模型的命名实体识别方法。首先分别用BiLSTM-CRF训练得到基于字的模型Char-NER和基于词的模型Word-NER,然后将两个模型得到的分值向量进行运算和拼接,将拼接后的向量作为特征送入SVM进行训练,使用SVM对Char-NER和Word-NER进行模型融合。受此启发,本文采用字词融合的方式作为模型的输入。
文献[15]提出了TENER(transformer encoder for NER)模型,设计了带有方向与相对位置信息的Atteniton机制。文献[16]通过迭代的膨胀卷积神经网络(IDCNN)充分利用GPU的并行性大大降低了使用长短时记忆网络的时间代价。然后,采用层次化注意力机制捕获重要的局部特征和全局上下文中的重要语义信息。文献[17]将文本序列向量化表示,在词向量的基础上通过多头注意力机制学习单词的权重分布,再通过胶囊网络和BiLSTM分别提取局部空间信息和上下文时序信息的特征表示,平均融合后由sigmoid分类器进行分类。本文受此启发,为了使模型在不同的表示子空间里学习到相关的信息,采用多头注意力机制。
在中文命名实体识别中,深度学习模型可以灵活运用字、词、句子的上下文特征,在实体抽取方面效果优于以前的方法。本次研究首先利用Word2Vec训练的字向量和多个词向量拼接后送入BiLSTM提取上下文语义信息,兼顾字特征与该字附近可能成词的词特征,使分词错误对识别实体边界造成的影响降低,同时又可以获得相对丰富的中文词语的语义特征;之后利用多头注意力机制对BiLSTM模型输出调整不同权重,捕获语义相互关联信息的多重特征,使各个字之间成词的紧密程度、各个词之间联系的相关性得以有效体现,为中文命名实体识别任务的分类标注提供重要依据。
2 多头注意力与字词融合的CNER模型
2.1 模型介绍
本文建立了一个多头注意力与字词融合的中文命名实体识别模型,模型总体结构如图1所示。
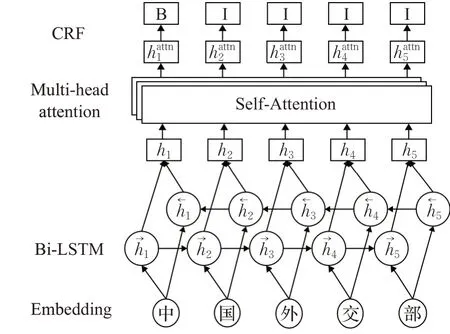
图1 模型总体结构图Fig.1 Frame structure of CWA-CNER
模型由字向量和词向量融合的嵌入层、BiLSTM层、Multi-head Attention层和CRF标签解码层构成。首先利用Word2Vec将文本分别映射成字向量和词向量,再将训练好的字向量和词向量融合,做为神经网络的输入。通过嵌入层将文本信息输入BiLSTM层进行特征提取后,接下来将包含文本中的上下文隐层输出与多头注意力机制进行融合,利用多头注意力机制解析字之间的结构及联系,将BiLSTM提取的隐含特征利用多头注意力机制进行权重调节。最后,利用CRF解码器计算最优标签序列,提升模型的准确率。
2.2 字符向量、词向量融合
数据预处理时,One-hot编码导致数据稀疏性高,维度高,在数据庞大的深度学习中容易造成维度灾难;并且任意词向量孤立,不能体现词与词之间的关系。而Word2Vec不需要大量的人工标记样本,能够降低维度,通过计算向量之间的距离来体现词与词之间的关系。
词向量虽然语义丰富,但由于受中文分词的限制,有些分词错误会影响CNER的结果。因此前序很多研究采用字嵌入来进行CNER。但是单个汉字所能表达的语义与丰富的中文词汇语义距离还是相差很远的。如何既利用汉语分词的结果,又最大程度地克服不同分词结果对NER的影响,本文提出的方案是采用字向量与该字所能成词的词向量相融合以增强原有词向量的语义表达。字向量和其所在各个词的词向量进行融合表示如图2所示。
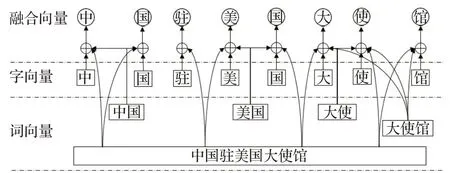
图2 模型输入向量的形成Fig.2 Input vector formation of CWA-CNER
根据分词的粒度不同,将字所在词的所有词向量相加后取平均,然后与字向量拼接得到模型输入。
例如对于图2的文本“使”,设训练好的字向量为c6,“大使”的词向量为w61,“大使馆”的词向量为w62,“中国驻美国大使馆”的词向量为w63,则“使”字的融合向量e6表示如公式(1):
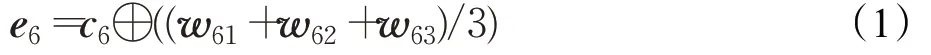
对于输入的整体文本来说,计算所有字的融合向量原则上应将该字在句中所有可能成词的词向量叠加取平均。为简化处理,本文采用中国科学院计算技术研究的ICTCLAS分词、大连理工大学的NiHao分词、基于Python的jieba分词3种分词方法对实验语料进行分词处理,取每个字在3种分词环境下的一个分词结果,然后取3个词的词向量相加取平均,再将结果与字向量拼接,一般的表示如公式(2):
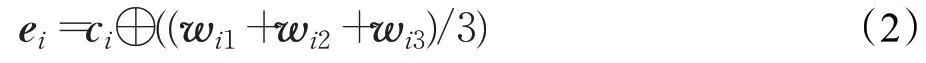
其中c i表示该字所对应的字向量,w i1、w i2、w i3分别表示句子中第i个字在3种分词环境下组成词语的词向量,⊕表示向量拼接。e i表示句子中的第i个字融合后的特征表示。最后将拼接得到的各特征向量送入模型进行训练。
2.3 BiLSTM特征提取
RNN是一种非线性自适应深度神经网络模型,它可以学习得到输入的深度结构化信息。传统的RNN能有效的利用句子的结构信息,但是它存在梯度爆炸和梯度消失等问题。BiLSTM是一种改进的RNN模型,它引入了门控机制,通过其特殊的门结构使得模型可以有选择地保存上文信息,对长距离信息进行有效利用,克服了传统RNN由于序列过长而产生的梯度弥散问题。BiLSTM对每个句子分别采用顺序和逆序计算,可以有效利用上下文信息,并且不会产生梯度爆炸问题。因此,BiLSTM逐渐成为解决序列标注任务的标准解法。LSTM单元结构如图3所示。
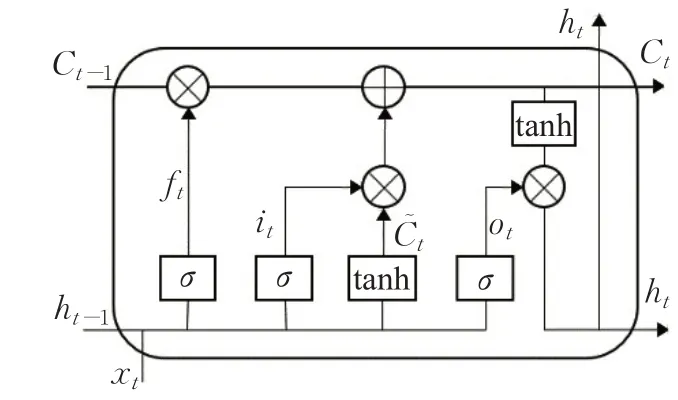
图3 LSTM单元结构Fig.3 Structure of LSTM unit
遗忘门:图3中表示一个LSTM门控单元,x t表示前一时刻隐藏层的输入状态,遗忘门的作用是决定从单元状态中丢弃哪些信息,使用sigmoid作为激活函数,单元状态中每个元素输出0到1之间的值:
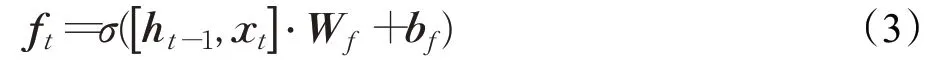
输入门:输入门可以确定要添加到单元状态的信息,主要可以分为两步:一个sigmoid层,决定要更新的值;另一个是tanh层,它创建要添加到单元状态的新值:
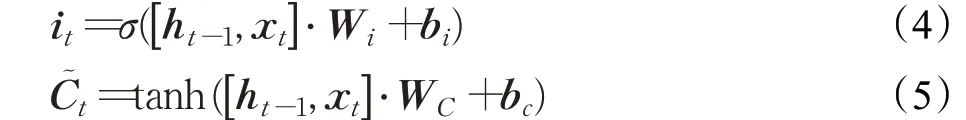
更新细胞状态:有了输入门的激活函数i t,以及遗忘门的激活函数f t以及代表状态候选值,就可以计算记忆单元在时间t的最新状态:

其中,符号⊙代表向量元素乘法。
输出门:输出门的作用是基于细胞状态保存的内容来进行决定,以此将处理好的值进行输出。选择性的输出细胞状态保存的内容,使用sigmoid激活函数确定输出的内容,使用tanh激活函数对细胞状态计算后,通过向量元素相乘得到需要输出的值:
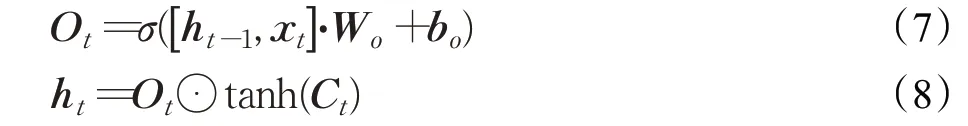
为了能够有效利用上下文信息,采用双向LSTM结构(如图4),对每条文本分别采用正向和反向输入,通过计算 得到两个不同的中间层表示,然后将两个向量进行拼接并作为隐含层的输出:
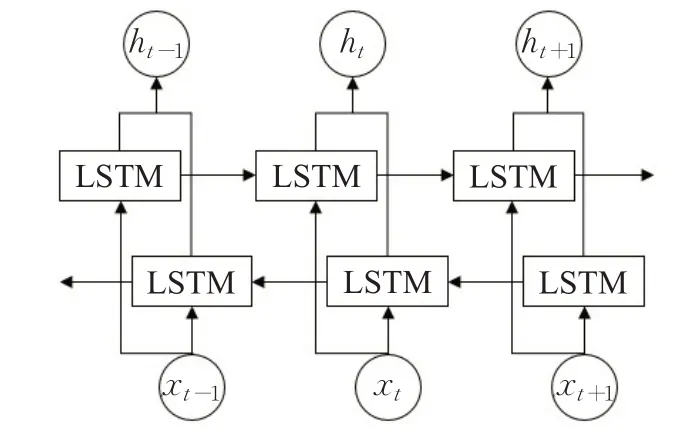
图4 双向LSTM结构Fig.4 Structure of bidirectional LSTM
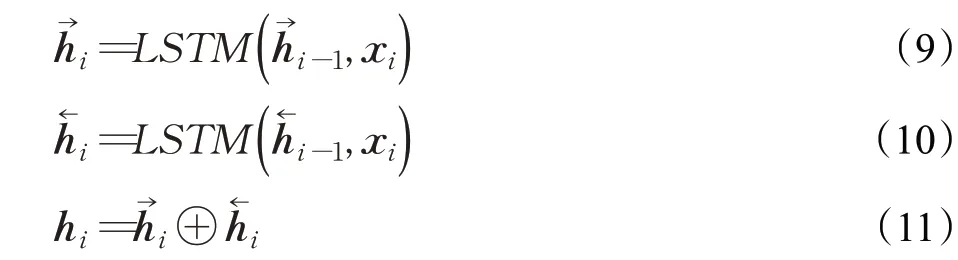
其中,和表示位置i的前向和后向LSTM表示;⊕表示连接操作。
2.4 多头注意力机制的权重分配
虽然BiLSTM在计算过程中可以将上下文信息都计算在内,但无法突出上下文中关键信息的重要性。注意力机制模仿人的认知方式,从众多信息中选择对当前任务目标更关键的信息,然后对需要重点关注的目标区域投入更多的注意力。在BiLSTM神经网络提取文本的全局特征之后,运用注意力机制,选择性地对文本中关键的内容赋予更高的权重,利用上下文的语义关联信息可以有效弥补深度神经网络获取局部特征方面的不足。
文本局部特征可以表示文本中部分内容之间的关联特征。例如在句子“张云雷被粉丝戏称为太平歌词的老艺术家”中,“张云雷”这个命名实体中各个字之间的关联更加密切,权重较大;而句子中其他字关联较弱,则权重较小;同时“老艺术家”对确定“张云雷”这个实体是人名这一实体类别又有积极作用。又如句子“我站在南京市长江大桥的尽头”中,“站”和“在”两个字对“南京市长江大桥”这一地名实体的判断具有更强的影响,所以将为他们分配的更高的权重。
模型中加入注意力机制,可以使模型中更侧重于样本中的重要特征,减少对非重要特征的关注,优化资源分配。多头注意力机制在命名实体识别任务中可以学习词之间的依赖关系,更加准确的捕获句子之间的语义信息。通过权重分配,获取词与词之间的相关度,提升模型识别率。利用该机制进行特征提取首先把字向量和词向量融合后的字符表示序列输入BiLSTM网络提取全局特征,然后,通过多头注意力机制给全局特征中不同的特征向量赋予不同的权重,以提取局部特征,最后,生成包括全局特征和局部特征的联合特征向量序列。
通过BiLSTM的特征提取,得到输出值h t,包含了神经网络编码后的信息,通过对当前单词的隐藏层状态多头注意力权重进行训练,将Q(Query)和K(Key)进行相似度计算得到权重,如下:
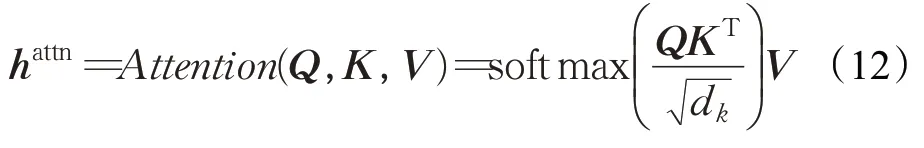
矩阵的维度由d k表示,softmax函数可以将Q、K点积运算后进行归一化处理,与V(Value)相乘后得到多头注意力权重求和结果。
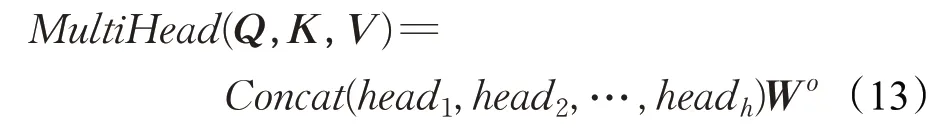
式中,W O为进行线性转换的参数矩阵,head j(j=1,2,…,h)为单头注意力单元,h为拼接数量。每个节点多头注意力值拼接变换得到最终的多头注意力值h attni。
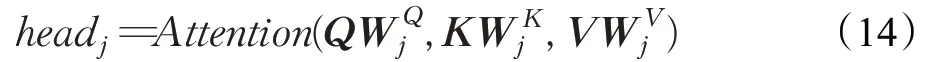
多头注意力机制具有速度快,可解释性强的优点,文本的丰富性使多头注意力机制在解析复杂的文本内容时起到好的提升效果。
2.5 基于条件随机场的标签预测
条件随机场是一种特征灵活、全局最优的标注框架。CRF可以从训练数据中学习到约束条件,从而保证预测标签的有效性。CRF给从神经网络模型输出的每个标签的得分进行筛选,具有最高得分的标签为训练得出的最好结果。CRF损失函数包含了真实路径得分和所有可能路径的总得分,在预测正确的情况下,真实路径在所有可能路径中得分最高。
3 实验结果与分析
3.1 实验环境设置
为了验证模型的有效性,本文实验所用的数据集为1998年《人民日报》、2014年《人民日报》和Boson数据集。不同的数据集可能采用不同的标注方法,常见的有IOB标记法、BIOES标记法和Markup标记法。本文数据集采用的是IOB标记法。“B-XXX”表示命名实体的开始,“I-XXX”表示命名实体的内部,“O”表示非实体字符。
语料规模如表1所示,实体类别包括人名、地名、组织机构名和时间。2014年的《人民日报》语料因数据集较大,随机抽取了其中的20 000条进行实验。
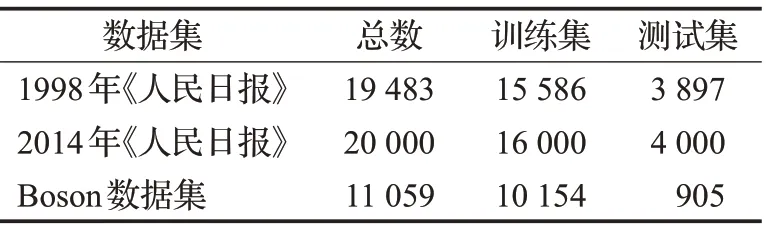
表1 实验数据集Table 1 Experimental datasets
具体实验环境设置如表2所示。
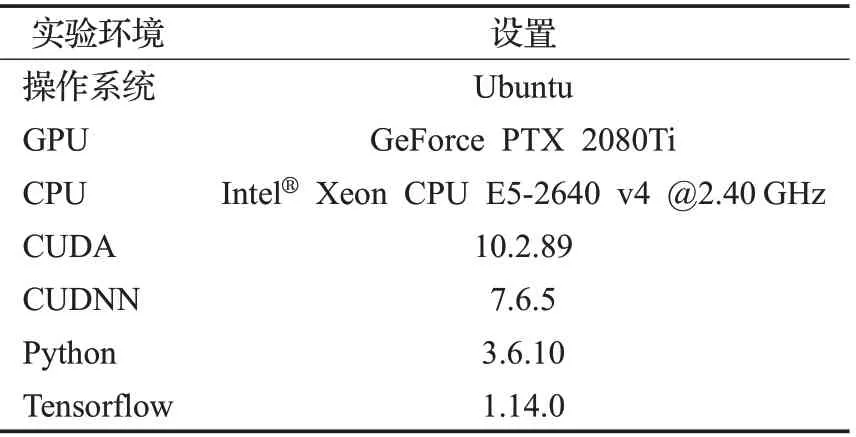
表2 实验环境设置Table 2 Experimental setting
3.2 实验参数确定
实验中利用word2vec训练字向量,词向量使用维基百科训练生成。实验中基于字的识别模型和基于词的识别模型超参数设置相同,如表3所示。

表3 实验中主要的超参数设置Table 3 Main parameters setting of experiments
为使模型达到最优的性能,首先在1998年《人民日报》语料上对实验过程中几个主要参数调节过程分析如下。
3.2.1 vector_dim参数设置
模型采用100维和300维字词向量分别进行实验,实验结果见表4。实验结果中300维的输入向量比100维输入向量精确率下降,召回率上升,总体F1值反而比100维向量输入低了0.13%。

表4 输入向量维度对模型性能的影响Table 4 Effect of input vector_dim on model performance%
从实验结果分析认为,用300维向量进行实验,模型出现了过拟合。但向量维度增加,总体上承载信息量要比100维的高,所以召回率有所提升。不过,在总体实验精度没有提升的情况下,实验时间复杂度增加,得不偿失。所以,考虑到运算复杂度,模型选择100维向量作为字词的输入。
3.2.2 多头注意力头数设置
将注意机制融合到深度网络中,可以提高对输入信息子集的处理能力。注意力机制是根据各个词语对目标词语的重要程度,把关联性更大的特征赋予更重要的权重,一定程度上可以弥补了深度学习的不足。
本文在此基础上为了使模型在不同的表示子空间里学习到相关的信息,捕获语义相互关联信息的多重特征及句子内部结构特征,采用多头注意力机制。图5验证了注意力机制的头数对实验的影响。其中8头时效果最优;当头数为1时,不能够充分考虑不同的表示子空间的相关信息;当头数增多为12头时,注意力机制会关注更多的特征信息,此时会带来一定的冗余信息,所以会导致模型效果不增反降。
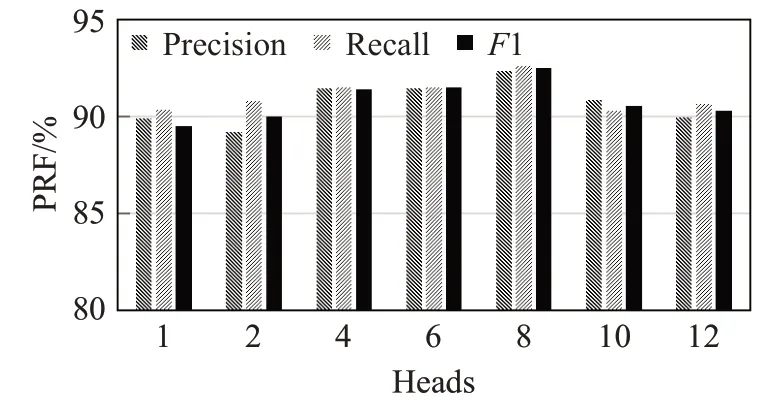
图5 多头注意力头数对模型性能的影响Fig.5 Effect of multi-heads attention mechanism number on model performance
3.2.3 rnn_units参数设置
rnn_units代表的是LSTM网络隐藏层中的单元数量,具体参数实验结果如图6所示。因为每个LSTM单元有3个门,对应了3个sigmoid,1个tanh,4个激活函数,即为4个神经元层中每一层有rnn_units个单元。LSTM输出单元lstm_dim与隐藏层单元rnn_units数量等于。当LSTM隐藏单元数逐渐增多,模型参数逐渐增多,可以学习更多的知识。但是模型参数过多时,首先是计算效率下降,同时模型还会出现过拟合,效果不增反降。本文模型在rnn_units取100时性能达到最优。

图6 rnn_units对模型性能的影响Fig.6 Effect of rnn_units on model performance
3.2.4 batch_size参数设置
设置batch_size的目的是让模型在训练过程中每次选择批量的数据来进行处理。设置batch_size的优点是可以充分利用计算机的并行运算结构,提高数据处理速度;考虑一定数量的样本数据,可以比较准确地代表梯度下降方向;跑完一次全数据集所需的迭代次数减少,对于相同数据量的处理速度进一步加快。
没有batch_size,梯度准确,只适用于小样本数据库;batch_size等于1时,梯度变来变去,非常不准确,网络很难收敛。batch_size增大,梯度变准确,batch_size增大到一定值,梯度已经非常准确,再增加batch_size也没有用。
batch_size的大小不能无限增大,如果取过大的batch_size,会导致每个epoch迭代的次数减小,要想取得更好的训练效果,需要更多的epoch,会增大总体运算量和运算时间;此外,每次处理大量数据时,虽然可以发挥计算机并行计算的优势,但是也要充分考虑计算机内存大小的限制。如图7所示batch_size为32时,模型最优。
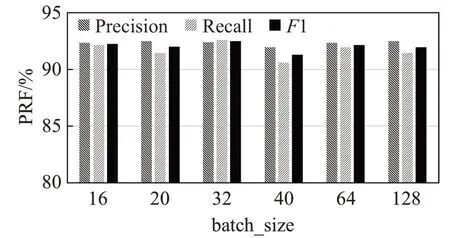
图7 batch_size对模型性能的影响Fig.7 Effect of batch_size on model performance
3.2.5 dropout参数设置
为进一步防止过拟合,探讨dropout对模型性能的影响,将dropout值分别设置为0.1~0.9,得出实验结果曲线如图8所示。
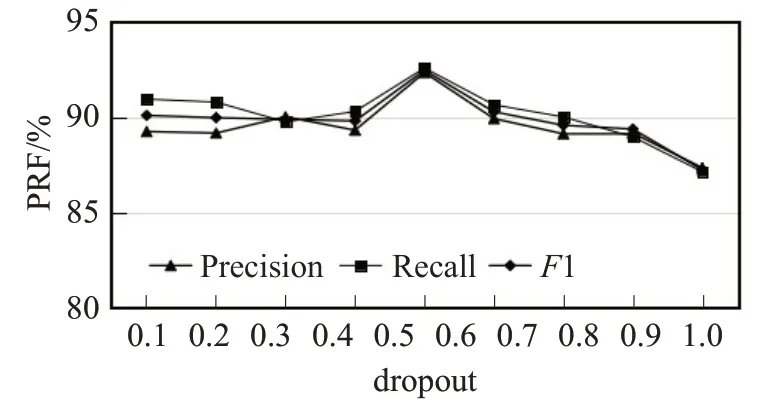
图8 dropout对模型性能的影响Fig.8 Effect of dropout on model performance
dropout是在前向传播的时候,让某些神经元以一定的概率值停止工作,这样可以使模型的泛化性更强。这样模型可以有效降低对某些局部特征的依赖性。该模型在dropout为0.5时模型性能达到最优,此时神经元有50%的概率被保留下来,50%的概率被失活,此时随机生成的网络结构最多,可以在很好的学习特征信息的同时,又能够防止过拟合。
3.3 实验结果对比
为了验证模型的有效性,对模型框架不同部分在Boson、1998年《人民日报》和2014年《人民日报》3个数据集上进行效果对比,以字向量+BiLSTM+CRF为基础模型(Baseline),在此基础上将单纯的字向量替换为字词融合向量形成中间模型1,再在Baseline基础上加入Attention机制,形成中间模型2,最终模型为将baseline模型的字向量替换为字词融合向量,并加入多头注意力机制形成本文提出的模型(CWA-CNER),实验结果如表5所示。
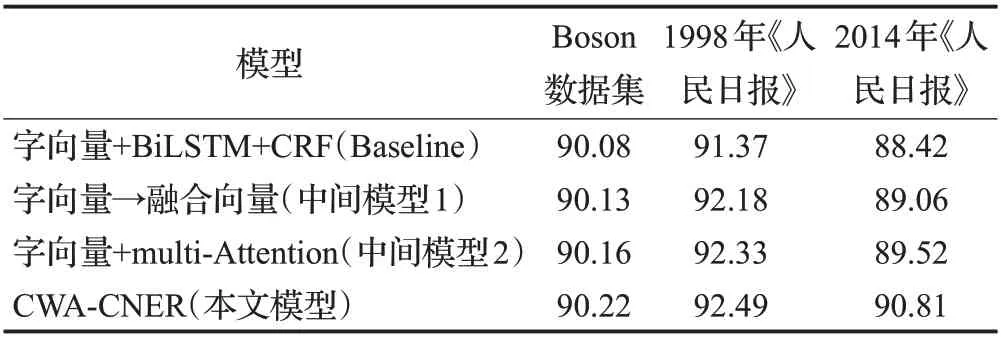
表5 消融实验结果Table 5 Ablation experimental results %
实验结果表明,在所有的数据集上,加入字词融合的向量输入,中间模型1的识别效果较基础模型在三个数据集上都有所提升,说明汉字成词信息的融入对CNER是有价值的。相比较而言,在Boson数据集上提升的程度略小,分析认为主要是由于Boson数据集相对较小,在深度学习模型上运行的效果不够明显。在Baseline基础上加入了多头注意力机制的中间模型2也较基础模型识别效果有所提高,证明了多头注意力机制的作用。同时,中间模型2的F1值均比中间模型1的效果略好,某种程度上表明多头注意力机制比字词融合的作用更大。
在融合了字词向量的基础上,同时加入多头注意力机制,本文提出模型的实验F1值效果最好。主要原因可以归结为模型既考虑到了输入信息字词特征的多方融合,又让多头注意力机制学习到了字之间的依赖及联系程度,进而提升了命名实体识别的效果。
为进一步证明本文提出模型的先进性,在1998年的《人民日报》语料上,与其他模型的识别结果进行对比,如表6所示。

表6 在1998年《人民日报》语料上与其他模型对比Table 6 Comparison with other models on corpus of People’s Daily 1998
由表6,本文与文献[18]和文献[19]提出方法的结果进行了对比,前者的工作是利用CNN对字(符)进行卷积,取得词特性再与字表示融合作为BiLSTM的输入进行NER,结果与本文提出的字词融合模型的结果接近。但相比简单的向量拼接,采用CNN模型进行获得单词的局部特征要略显复杂,并且他的CNN需要局限于分词结果范围内,对错误分词的影响很难通过后续与字向量拼接克服。模型总结果与本文提出方法的距离应该产生自多头注意力机制,进一步反映了注意力机制的效用。后者提出的模型使用字嵌入作为模型输入,除了加入注意力机制外,还融合了顺序遗忘编码(fixed-size oradinally forgetting encoding,FOFE)但实验结果比本文提出的模型低0.84个百分点,可见本文提出的字词融合机制对中文命名实体识别更有效。同时,结果也表明本文采用的多头注意力机制在命名实体识别任务上优于自注意力机制模型。
3.4 实验性能及效果可视化
按照消融实验在数据集上运行不同模型的顺序,将模型运行时间记录如表7所示。

表7 模型运行时间Table 7 Model running time
随着模型复杂度的增加,运行时间也相应增加。但本文提出的模型总计运行时间基本在可以接受的范围内。
为了能够更加清楚明显地看出本文模型实验效果,将实体类别和相对应的F1值进行可视化,如图9所示,纵坐标表示实验的文本数据,横坐标表示实体类型,分别为“人名”“地名”“组织机构名”“非实体”。可以看出本模型对中文命名实体识别准确率较高,“人名”和“地名”的准确率较高,相比较而言,“组织机构名”准确率处于中等水平,但都能准确识别大部分实体,并且能够取得较好的结果。
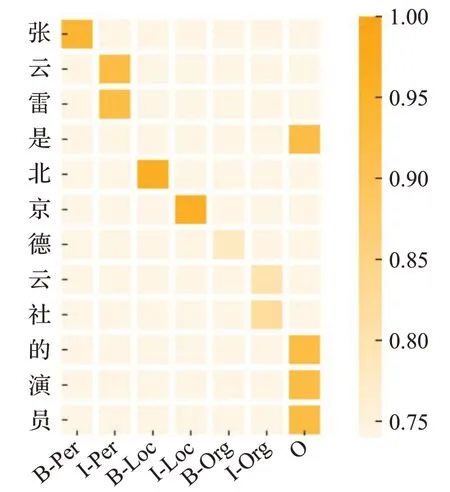
图9 中文实体识别效果图Fig.9 CNER effect vision diagram
本文使用多头注意力机制和字词融合来解决命名实体识别问题有以下优点:通过字词向量融合,增加了语义信息的完整度,有效避免错误信息的干扰和有效信息的遗漏;同时多头注意力机制来解析词语之间的结构和联系。将多头注意力机制和字词融合思想与经典的BiLSTM-CRF模型相结合,进一步提升了CNER的实验结果。
4 结束语
本文构建了基于多头注意力机制和字词向量融合的CNER模型,首先对语料集进行了预处理并采用了多种分词方法来进行分词并训练词向量。利用word2vec提取句子中的字向量,并将字向量和该字所能成词的三个词向量融合后输入到BiLSTM神经网络中获取句子语义特征;然后利用多头注意力机制来捕获整个句子各个字之间联系的关键信息;最后再通过CRF解码,得到整个句子命名实体标注的最优序列。
本文研究以字、词向量结合作为输入层,在深度学习的神经网络模型中加入多头注意力机制进行中文命名实体识别,取得了较好的实验效果,证明了模型的有效性。汉字本身的意义和其成词的多种可能让字词融合机制变得十分必要,多头自注意力机制可以有效判断文本之间的联系,并在句子级别和词语级别寻找更多关键信息,对于实体识别任务具有显著优势。未来工作考虑将该模型思想迁移到对除基本命名实体以外的其他类型实体的识别研究,以便为实体和关系联合抽取做准备。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
校园英语·月末(2021年13期)2021-03-15
甘肃教育(2020年22期)2020-04-13
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
