
认同度修正下的近相邻改进推荐算法研究
2022-04-08 03:41李剑锋封林慧于天一
计算机工程与应用 2022年7期
李剑锋,封林慧,于天一
大连海事大学,辽宁 大连 116026
随着互联网技术的飞速发展,网上购物消费已深入人们的日常生活。根据用户的历史信息,分析用户的兴趣爱好,为用户提供更好的个性化服务,已成为企业的重要任务,企业所应用的推荐算法发挥着日益显著的关键作用[1]。推荐算法研究起源于20世纪90年代,美国明尼苏达大学Grouplens小组最先开始研究,他们希望制作一个为用户个性化推荐电影的Movielens系统[2]。随后,众多学者也逐步深入扩展多个相关方面的研究,但电影推荐始终是一个重要研究领域。如Hwang等人[3]利用电影评分信息评测电影类型之间的关联性,并在电影类型修正基础上依据协同过滤方法确立目标用户的推荐电影,结果表明此方法比原协同过滤方法具有更高的推荐准确性。何明等人[4]考虑项目的类型信息,填充分类信息下的评分矩阵,改进用户兴趣度计量方法,解决协同过滤算法的稀疏性问题,提高了推荐的准确性、多样性和新颖性。这些学者实际上希望以电影为特定对象,用以展现推荐算法的效率,然而,由于影响因素众多,如何有效融合多方因素,更加准确地为用户提供个性化产品一直是关注的难点。本文则基于认同度的视角,融入大众化认同度和个性化认同度,提出一个新的近相邻改进算法,可以更加高效地挖掘隐藏信息,多种评价指标结果表明此算法在很大程度上提升了推荐效果。
1 推荐算法分类及认同角度
推荐算法的种类繁多,如基于内容的推荐、基于规则和知识的推荐、协同过滤推荐等等,从不同角度具有不同的划分方法,但如果仅从涉及到的用户数量角度,推荐算法可以大致划分为单用户特征推荐和多用户融合推荐。
单用户特征推荐算法主要是以特定用户的历史行为数据为基础,通过分析用户的个性化特征加以推荐商品。这与信息过滤技术较为相似:从特定用户获取信息,利用某种方法,如概率统计、语义分析、马尔可夫预测等,分析出能够代表此用户偏好的特征描述,再将符合此特征的物品信息过滤出来,推荐给此目标用户。例如,杨宝强[5]利用自然语言处理工具,通过词频统计方法,获取用户评论产品的情感色彩,以此构建用户兴趣演化模型,可以为用户提供更好的推荐服务;江周峰等人[6]在信息熵思想基础上提出一种社会标签模糊化方法,形成模糊识别标签下基于内容的推荐算法,可以提升高校图书推荐的准确率;张丹等人[7]加入用户驻留时间元素,改进隐马尔可夫模型,以此分析用户的阅读轨迹,并寻求用户下一步可能阅读的新闻,其结果显示此推荐算法较大提高了F1评价指标值。
多用户融合推荐算法则更多强调从多用户关系上挖掘隐含信息,利用相似多用户的共同经验,避免内容信息不完全所导致的推荐不准确。基于用户和基于物品的协同过滤推荐算法实际上属于这一分类。基于用户协同过滤算法是把用户按照相似度聚类成不同的组,使得同一组内的用户行为特征相像,进而将组内用户相似性高的信息或频繁交互的物品视作备用的推荐。同样,尽管基于物品的协同过滤算法是以物品聚类,但这种聚类也是以多个用户认知的一致性为基础,对于某两个物品,如利用多个用户的评分情况或参与情况来确立物品的相似度,而这如果从用户视角,也是利用了多个用户看法相似的融合信息。另外,一些关联规则推荐也可以看作是利用了多个用户的共同行为信息,在一定支持度和置信度基础上,啤酒和尿布具有关联关系,可以放在一起推荐给购买者,而一些网络群组推荐也可以划分为此类,如闵磊论述了利用社区发现技术使相似兴趣的物品进行聚类,可以缓解冷启动问题[8]。
多用户融合推荐算法并不意味着摒弃了用户的个性化特征,而是强调个性化特征的聚合,这个聚合表明用户具有相似的偏好"认同感",以此作为推荐的依据。例如,范波等采用对不同项目类型的多个评分相似度来进行预测评分,可以准确描述用户对不同类型的偏好[9];刘国梁[10]提出利用项目的客观标签(如电影的类型)描述用户自身兴趣偏好,对数量过多的“热门项目”有独特见解的用户的评分准确性有一定提高;李征等人[11]利用用户对项目类型的兴趣偏好填充传统矩阵,将用户评分差异因素和项目质量因素融入相关系数中,再进行混合推荐,得到了更好的推荐效果;陆航等人[12]针对单一评分相似性计算不准确问题,融合用户兴趣和评分差异提出一种新的协同过滤算法,其算法具有更高的推荐精度;Cramer等人[13]强调信任增加了用户的认同感,而这种认同感会有利于增加用户适应推荐系统的效率;Pinata等人[14]将用户情绪融入传统的协同过滤推荐算法中,实证表明此情绪认知下的协同过滤算法优于传统的协同过滤推荐算法;Jonice等人[15]提出融入物品描述、用户兴趣和社会关系网的联接开放数据的推荐方法,此方法比一般的推荐方法具有更好的推荐准确性。
综上所述,用户是使用物品的主体,推荐物品建立在用户某程度认同的基础之上,单用户特征推荐是寻求特定用户的个性化认同,而多用户融合推荐则寻求相似用户组的共同性认同,然而,如何有效地综合这些认同度信息、避免信息缺失并提升推荐效果,这则是一个关注难点。以基于物品的协同过滤推荐算法为例,求解近相邻相似度是反映多用户融合信息的基础,大多数研究采取事先个性化特征填充矩阵的方法,这样会增强物品之间的相异性,更好地区分物品相邻对象,但这也意味着有可能降低受用户欢迎物品的地位。在电影推荐中,用户观看了某个一般性电影,从用户认同角度,受到相似用户组认同的等价地位电影得到的推荐评分值靠前,然而,不可否认,多数用户还是倾向于观看大众观看较多的电影,其近相邻算法会削弱这个特性,这可以表现为大众化认同度影响。另外,由于用户认同程度不一致,采取统一的相似度计算度量无法体现用户的个性化特征,对于同一电影,不同用户的偏好不同,其近相邻电影也应该是不同的,这也表现为用户个性化认同度影响。这样,本文则采取这两种认同度事后修正的思想,即大众化和个性化认同度修正,提出一个新的近相邻改进算法,力求更加高效地挖掘隐藏信息,提高推荐算法的效果。
2 基于认同度下的推荐算法
2.1 算法基本流程
此推荐算法首先求解电影项之间的皮尔逊相关系数以表现用户的基本认同程度。对于任何两个电影项j和i,根据N个用户对它们的打分情况x和y,如果没看则打分为0,其电影项相似度cor(j,i)如公式(1)所示:
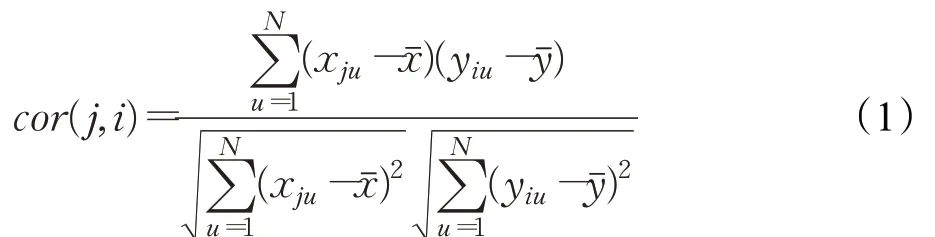
随后,分别乘以大众化认同度和个性化认同度修正系数,这里不同用户的修正值有所不同。最后,以修正后的电影相关项为标准,利用top-K近相邻方法,求解出不同用户的推荐列表。由此对基础的算法做出补充改进,以更好地融合多方因素,减少信息损失,如图1所示。
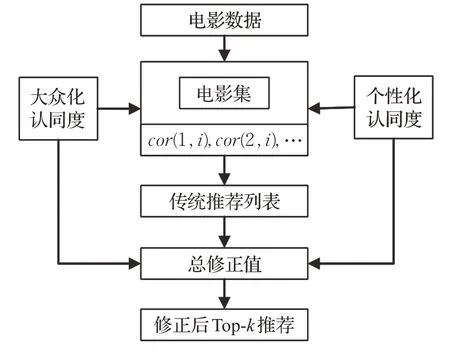
图1 认同度修正下的推荐算法流程Fig.1 Algorithm process under revised approval-degree recommendation
2.2 大众化认同度修正系数
认同度修正系数是算法关键,在实际应用中,电影已观看的用户数量会对潜在用户产生一定的影响,这是因为羊群效应,人们很容易受到大众认同度的影响,所以,从大众角度加入大众认同度修正系数,计算公式(2)和(3)如下:

其中,N j表示为某个电影j的用户观看数量;P j表示为电影j的用户观看数量对所有电影的平均用户观看数量的比值;b表示为偏移值,通常取0.5;R j则表示为观看某个电影j的大众化认度修正系数。这实际上是以电影观看的平均值为度量标准,利用Sigmoid函数进行幅度归一化处理并进行偏移,对比分析大众对于电影的喜好程度。如果某电影观看数量恰好是电影观看用户数平均值,则其相对比值减去1之后为0,其Sigmoid函数值为0.5,再加上偏移值0.5等于1,而其他的电影观看用户数值则经过上述公式计算围绕着1变动,体现为放大或缩小效果。另外,对于没人观看新电影的最初大众化认同度修正系数也设为1,之后则根据其用户观看情况动态地加以调整。
2.3 个性化认同度修正系数
上述从大众化角度对算法进行了修正,但用户还存在着自身的个性化偏好特点,例如,虽然冒险类电影很受大众欢迎,但有的用户就是不喜欢这种紧张刺激的类型,宁愿看一些轻松欢快的喜剧类型,这样就需要在改进算法中加入个性化认同度因素,本文利用用户个体观看电影的类型因素来求解个性化认同度修正系数,计算公式(4)如下:

其中,N ug表示为用户u看过的g类型电影数量,t表示为电影类型总数。这里采用了近似求相对比值方法,因为存着一些看电影数较少的用户,如果他只看了一次某类型电影,很难说此用户就完全不喜欢其他类型电影,所以增加了修正常数1,模糊这种数量少时类型偏好划分,而当用户观看的电影数量逐渐增大,这种修正常数的模糊效果会逐渐减少,用户喜欢电影类型会更加明确,并且,这也可以避免求解没看过任何电影冷用户时分母数值为0的情况。
之后,仍然利用sigmoid函数归一化处理,防止数据的幅度偏大而导致传递时效果不好的问题,并且,引入了偏移值b=0.5,使得平均值通过计算定位于1,如公式(5)所示:

然而,电影的类型并不一定唯一,可能存在着多种类型,可能是冒险类型,同时又是动作和罗曼蒂克类型,所以对于某个电影,用户的个性化度量值需要进行平均化处理,计算公式(6)如下:

其中,h表示某个电影j所具有的类型数(h≥1),这样,对于不同的用户u而言,喜欢的电影类型不有所同,所面对的电影j的修正系数也是不同的,从而体现个性化认同度的修正效果。
2.4 认同修正后top-k近相邻算法
求解大众化认同度系数和个性化认同度系数之后,就可以借此将大众趋势和个性偏好融入传统的近相邻算法中,如公式(7)所示:

其中,u表示为某个用户,i表示为用户u看过的电影,j表示用户u还可能选择看的电影,cor(j,i),R j和R uj分别为前文公式的中相关系数、大众化认同度系数和个性化认同度系数,R uji则是用户u在电影i相邻的可供选择电影j集合的综合排序值,这样,选择不同的k相邻值,就可以限定阈值范围为用户推荐不同的电影,如图2所示。
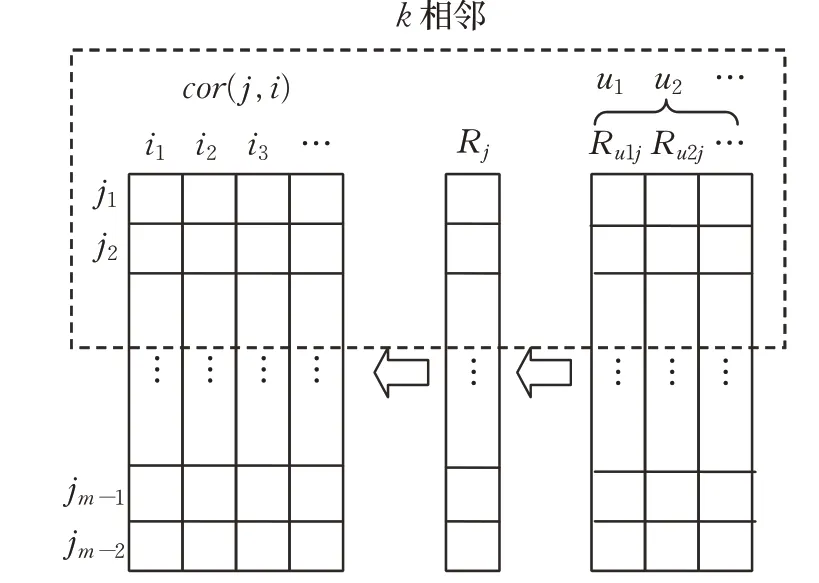
图2 认同度修正下k相邻改进过程Fig.2 Improving process of k-nearest neighbors under revised approval-degree recommendation
3 实验及结果分析
3.1 实验数据
本文采用明尼苏达大学Grouplens小组的两个推荐算法的经典数据集,分别是ml-latest-small和ml-100k数据集,两者都去除了非类型标记的记录(no genres listed和unkown),包括10万条左右的评价记录数,对两个数据集都进行随机八二划分,形成训练集和验证集合,之后求证上文所提出的认同度修正下的近相邻改进算法的效果。
3.2 评价指标
经过多个评价指标分析,都表明此算法在很大程度提升了推荐效果,评价指标包括:查准率(precision)、查全率(recall)、假正率(FPR)、F1值(F1)、深度(depth)和提升度(lift)。
依据预测值与实际值相互对映,实验样本可以分为真正例(TP)、假正例(FP)、真反例(TN)和假反例(FN)。查准率又称之为精确率,表示为预测中真的正例数占所有预测为正的例数比值,反映预测正例的可信性;查全率又被称为召回率、灵敏度和真正率,表示为预测中真的正例数占实际为正的例数比值,反映推荐正例的覆盖性;假正率表示为被错误地预测为正的例数占所有实际为负的例数比值,反映多少负样本被错误地预测为正样本;F1值表示为2倍查准率和查全率的乘积占两者之和的比值,反映查准率和查全率的调和程度;深度表示为预测为正的例数占全部样本数C的比值,反映推荐正样本的进度;提升度表示为预测正例的可信性与实际正比例的比值,也等于真正率(TPR)与深度(depth)的比值,反映推荐的提升效果。如公式(8)~(13)所示:

在算法求解过程中,主要将近相邻的k值设为从1到100的10等分数值,依次求解推荐算法的评价指标值,这样可以在不同状况下,分析基于认同度修正下的改进算法与传统近相邻算法的对比效果,具体如表1和表2所示。
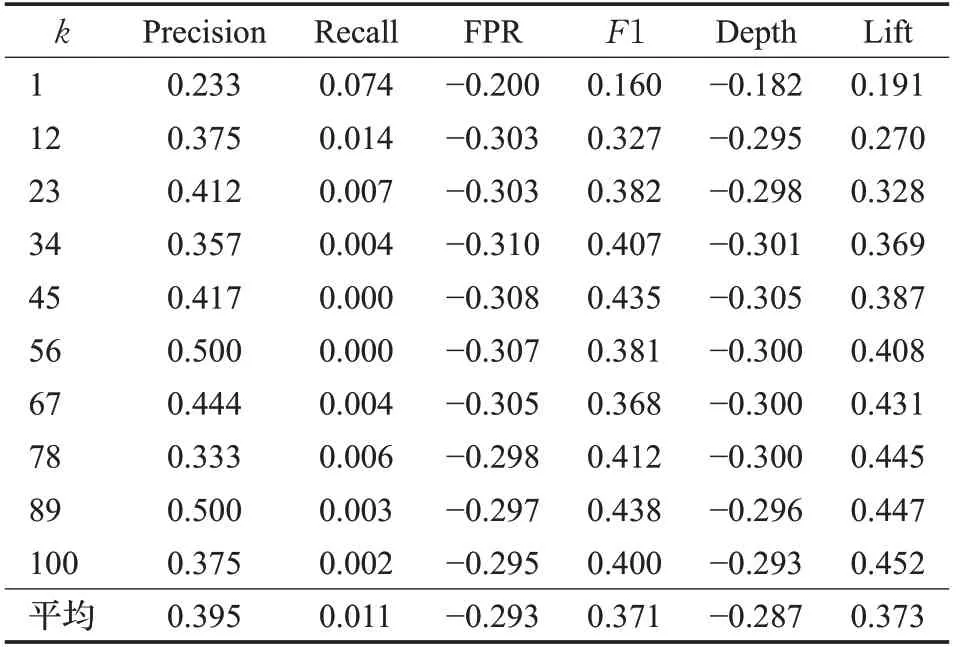
表1 数据集ml-latest-small的评价指标变动比率Table 1 Change ration of evaluation indicators through ml-latest-small dataset
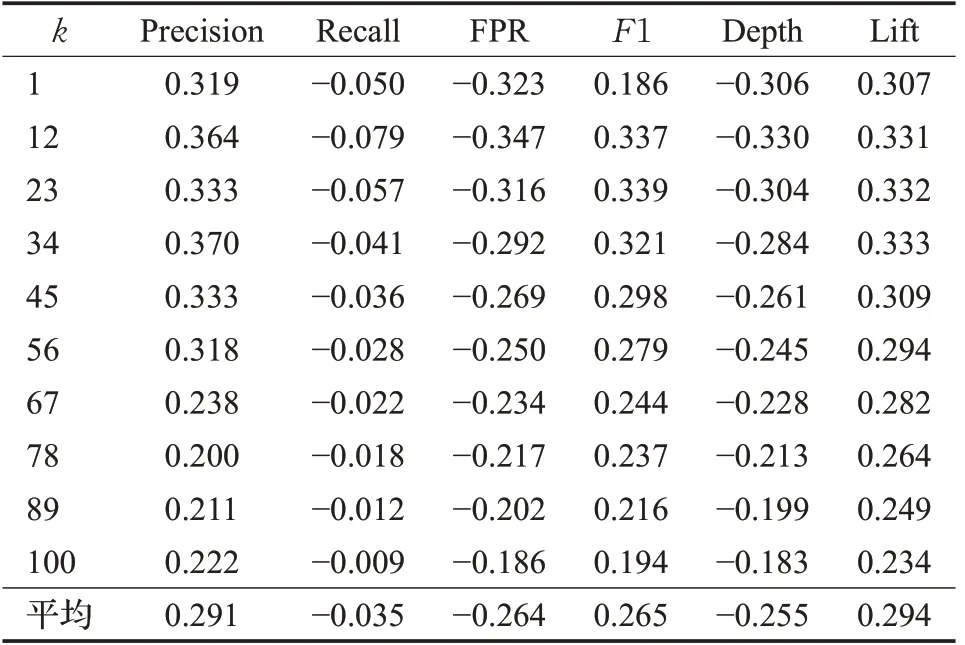
表2 数据集ml-100k的评价指标变动比率Table 2 Change ration of evaluation indicators through ml-100k dataset
从表1可以看到,在ml-latest-small数据集中,相对于传统的近相邻算法,认同度修正下的推荐算法各方面评价值都得到了提高。表1中数为修正算法值减去传统算法值再除以传统算法值,表示为变动比率。近相邻的k值从1到100过程中,各用户平均假正率变动都是负值,说明修正算法比传统算法的认错性得以降低,不同k值下的平均假正率减少了29.3个百分点。深度变动也都是负值,说明改进算法的推荐数量比例比传统算法有所减少,不同k值下平均减少了28.7个百分点,但这种推荐数量减少仍实现了查准率、查全率、F1值和提升度各个评价指标的提高:查准率变动都是正值,说明修正算法比传统算法的预测可信性得以增加,平均提高39.5个百分点;查全率变动都大于等于0,说明修正算法比传统算法的预测覆盖性也有所增大,平均提高1.1个百分点;F1值变动也都是正值,尽管查准率和查全率存在冲突,说明修正算法比传统算法对于两者的调和程度也有所变好,平均提高37.1个百分点;提升度变动也都是正值,说明修正算法比传统算法的提升效果也有所增长,平均提高37.3个百分点。由此可见,通过mllatest-small数据集测试,无论是越小越好的负向指标(假正率和深度),还是越大越好的正向指标(查准率、查全率、F1值和提升度),修正算法推荐效果都优于传统算法,并且具有较为明显的提高比例。
同样,从表2可以看到,在ml-100k数据集中,相对于传统的近相邻算法,认同度修正下算法也具有较好的推荐效果。对于不同的近相邻k值,各用户平均假正率变动也都是负值,修正算法的认错性得以降低,不同k值下的平均假正率减低了26.4个百分点。深度变动也都是负值,不同k值下修正算法的推荐数量比例平均减少了25.5个百分点。然而,查全率指标却有所减弱,不同k值下的平均查全率降低了3.5个百分点,但查准率、F1值和提升度这些指标都得到大幅度提高:查准率变动皆为正值,说明修正算法所提供的正例比值增加,其预测可信性得以加强,平均提高29.1个百分点;F1值变动皆为正值,说明尽管查全率变弱,但查准率和查全率的综合评价调合指标F1值仍然得到较大提高,平均提高26.5个百分点;提升度变动皆为正值,修正算法的提升效果也有所增长,平均提高29.4个百分点。由上所述,虽然ml-l00数据集的测试结果不如ml-latest-small数据集,且查全率指标有所减弱,但波动幅度较小,而其他评价指标(假正率、深度、查准率、F1值和提升度)都得到大副度提升,这些负向指标和正向指标的变好程度都达到20%~30%,因此,通过ml-l00k数据集测试,同样表明修正算法具有显著的推荐效果。
3.3 评价曲线
由于评价指标存在关联性,也可以利用指标之间关联评价曲线来形象反映推荐算法的效果,常用推荐评价曲线有受试者特征曲线(receiver operating characteristic curve,ROC)和提升曲线(depth-lift)。
ROC曲线最早于二战时雷达探测中评判信号侦察模型的好坏,后用于分析推荐算法效果的优劣。该曲线中横坐标为假正率(FPR),纵坐标为真正率(TPR),或称查全率、召回率和灵敏度,曲线上各点表示为针对不同阈值信号刺激下的假正率和真正率的共同感受性。通过该曲线进行度量所考虑的目的是:尽可能保持少负样本被错误地预测为正样本(假正率),同时检验出更多的正类个体(真正率)。
图3和图4分别显示根据ml-latest-small和ml-100k数据集所计算的认同度修正算法和传统近相邻算法的ROC曲线,修正算法符号为“■”,传统算法符号为“○”,图中点表示近相邻k值从1到100的10等分数值所对应于假正率和真正率。可以明显看出,相同k点情况下,两个数据集的实验结果都表明修正算法比传统算法具有更小假正率和更大真正率,并且,修正算法点更加聚集于二维图左侧,说明修正算法可以在较小错误情况下推荐更多地覆盖用户所看的电影,其推荐算法效果更加显著。
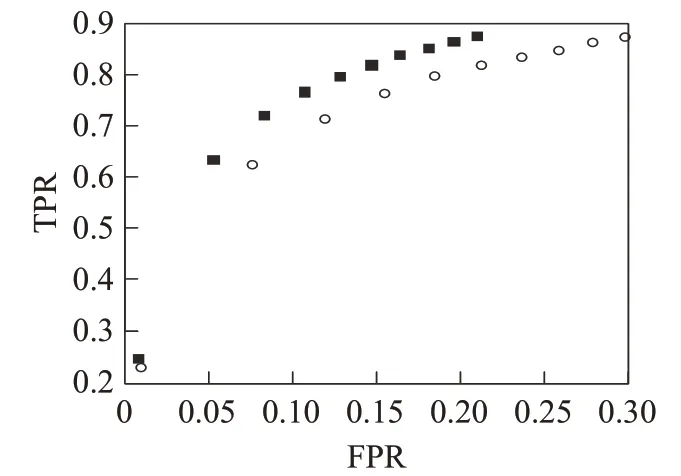
图3 数据集ml-latest-small的受试者特征曲线ROCFig.3 Receiver operating characteristic curve through ml-latest-small dataset
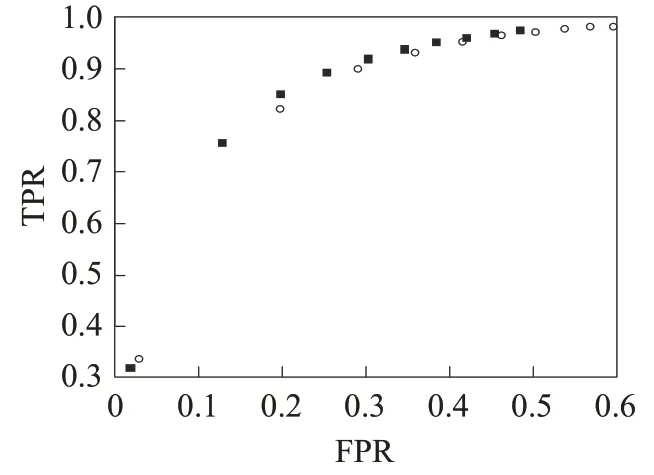
图4 数据集ml-100k的受试者特征曲线ROCFig.4 Receiver operating characteristic curve through ml-100k dataset
除了ROC曲线,提升曲线也是常用的推荐算法效果的评价曲线,提升曲线的横轴表示为深度(depth),纵轴表示为提升度(lift),该曲线反映算法随着不同挖掘深度所对应的不同提升效率。
图5和图6则分别显示两个数据集下所计算的认同度修正算法和传统近相邻算法的提升曲线。图中样本点表示近相邻k值从1到100的10等分数值所对应于两者指标,修正算法符号为“■”,传统近相邻算法符号为“○”。很明显可以看出,相同k点情况下,两个数据集下修正算法比传统算法都具有更小深度和更大提升度,说明修正算法可以在较小推荐数量条件下(深度)得到较大的提升效果(提升度),即更大的预测正例的可信性与实际正比例的比值,也可以说明深度随之的正样本覆盖比例也有所增加。
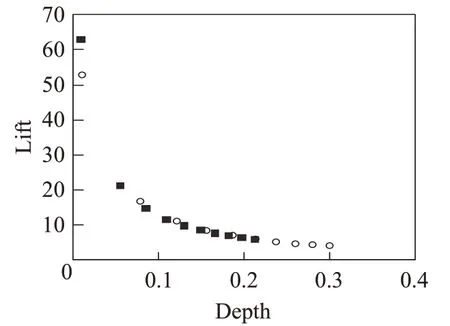
图5 数据集ml-latest-small的提升曲线Fig.5 Lifting curve through ml-latest-small dataset
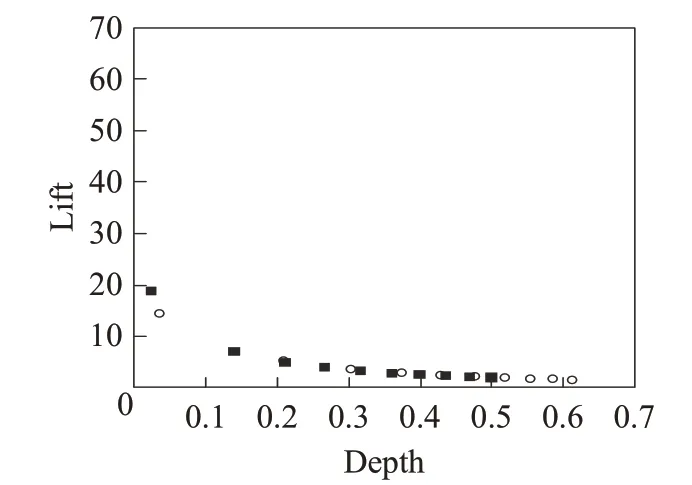
图6 数据集ml-100k的提升曲线Fig.6 Lifting curve through ml-100k dataset
4 结论
本文提出了一种认同度修正下的推荐算法,将大众化认同度和个性化认同度系数融入近相邻算法中,可以更加高效地挖掘隐藏信息。通过在两个数据集mllatest-small和ml-100k数据集进行对比实验,结果表明:尽管查全率小幅度上下波度,但其他多个评价指标都得到极大提升,假正率和深度有所减少,查准率、F1值和提升度得以增加,并且,受试者特征曲线和提升曲线也都说明此修正算法具有更为显著的推荐效果。
猜你喜欢
现代电子技术(2018年20期)2018-10-24
现代电子技术(2018年16期)2018-08-21
现代情报(2018年11期)2018-01-07
现代电子技术(2017年23期)2017-12-20
计算机应用(2016年10期)2017-05-12
新教育时代·教师版(2016年46期)2017-03-02
党史博采·理论版(2017年1期)2017-01-21
求知导刊(2016年22期)2016-10-08
中国管理信息化(2009年10期)2009-06-19
