
海量图书馆档案信息的快速检索方法
2018-10-24 04:39陈春阳
现代电子技术 2018年20期
陈春阳

摘 要: 海量图书馆档案信息的快速检索对实现图书馆的发展具有重要意义,成为加强图书馆档案管理工作的主要策略和发展方向。传统方法主要是利用图书馆档案信息的分类顺序进行分析,忽略了档案信息的查全率和查准率。因此,提出一种基于模糊集的海量图书馆档案信息快速检索方法。利用多个向量代表档案信息的对象,建立特征向量模型对图书馆档案信息进行处理,需要在数据库中对档案信息的语义索引和语义特征向量进行处理。在对图书馆档案信息处理完成的基础上,计算索引项在档案信息中的频率,并且计算索引项的大小来决定档案信息项位置的权重,对图书馆档案信息检索式进行量化和划分,并建立权重向量,获得档案信息向量,利用档案信息向量计算相似度函数,最终实现模糊集的图书馆档案信息快速检索方法。实验结果表明,所提方法具有查全率和查准率高的优点,对海量图书馆档案信息检索起到重要作用。
关键词: 图书馆档案信息; 快速检索; 模糊集; 分类顺序; 查全率; 查准率
中图分类号: TN911.2?34; TP311 文献标识码: A 文章编号: 1004?373X(2018)20?0042?03
Abstract: In the traditional method, the classification order of library archive information is mainly used for analysis, in which the recall rate and precision rate of archive information are ignored. Therefore, a rapid retrieval method of massive library archive information is proposed based on fuzzy sets, in which multiple vectors are used to represent the objects of archive information. The feature vector model is established to process library archive information, which needs to process the semantic indexes and semantic feature vectors of archive information in the database. On the basis of completion of library archive information processing, the frequency of the index item in archive information is calculated, and the size of the index item is calculated to determine the location weight of the archive information item. The retrieval formulas of library archive information are quantified and divided, and the weight vector is established, so as to obtain the archive information vector. The similarity function is calculated by using the archive information vector to realize the fuzzy set based rapid retrieval method of library archive information. The experimental results show that the proposed method has the advantages of high recall ratio and precision rate, which plays an important role in retrieval of massive library archive information.
Keywords: library archive information; rapid retrieval; fuzzy set; classification order; recall ratio; precision rate
0 引 言
在信息無序的社会中,有价值的档案信息和无价值的档案信息相互交错并且混乱,需要从海量的图书馆档案信息中检索出所需要的档案信息进行整理[1],这一方法成为人们研究的难题和热点,信息快速检索方法也是计算机科学与技术专业的重要学习方法。在信息丰富的时代,海量图书馆档案信息的快速检索方法能够缓解检索工具与图书馆档案信息之间的问题,在图书馆的服务中心,信息的快速检索方法起到不可替代的作用[2]。
文献[3]提出一种基于关键词关系算法的海量图书馆档案信息快速检索方法。对图书馆档案信息建立模型,并计算模型的参数,检索到隐藏的档案信息,对其进行主题分布,在主题分布的基础上计算并检索档案信息关键词的相似度,得到检索后的图书馆档案信息。但该方法不能够将图书馆的重要档案信息全部检索出来,说明存在查全率低的缺点。文献[4]提出一种基于空间自相关统计算法的海量图书馆档案信息快速检索方法,对图书馆档案信息中的数据在不同空间间隔上进行相关计算,测试聚集程度,获得档案信息的自相关参数。档案信息的检索具有有序性,但该方法对档案信息的检索不够准确,说明查准率较低。
针对上述两种方法存在的问题,提出基于模糊集的海量图书馆档案信息快速检索方法。
1 海量图书馆档案信息的快速检索研究方法
1.1 图书馆档案信息处理
在对图书馆档案信息进行处理时,可以参考向量空间模型,档案信息的向量模型需要建立一个关键词条字典,包括单词、短语等[5]。把图书档案信息当作多维向量,利用二进制或者反转档案信息等不同的表示方式将图书馆档案信息表示出来;利用本体库来代替档案信息关键词;利用对档案信息的描述,将信息属性构成的向量来代替图书馆档案[6],对图书馆档案信息进行处理,处理方式与用户查询方式相似,每一份档案信息都有固定的内容和编号。档案中的每一部分也可以对概念信息进行描述,提取出图书馆档案中的关键信息,使用关键信息的属性和概念进行概括,对于概念信息来说[7],在档案中提取的信息属性值,可以构成描述图书馆档案信息的语义向量。具体分析如表1所示。
为了提高图书馆档案信息的处理效率,对档案进行分类,利用效率高的管理形式和档案整理方式。在档案语义特征向量处理的结果中[8],利用本体的档案概念树当作信息分类的依据。分类处理后的图书馆档案信息,通常每个档案的特征向量都是由多个属性和概念组成。在概念的类中对档案信息进行映射,为了对档案信息进行处理,在图书馆档案信息库中建立管理结构,并建立档案信息的语义索引。将处理后的档案信息进行索引,按照顺序排列。在此基础上建立有序链表,包括档案信息的语义特征向量[9]。在档案信息索引文件中插入指针,可以利用指针快速了解和处理海量图书馆档案信息。
1.2 基于模糊集的图书馆档案信息快速检索方法
在对图书馆档案信息处理完成的基础上,利用索引项在档案信息中出现频率和索引项的大小计算档案信息项位置的权重;对图书馆档案信息检索式进行量化,对图书馆档案信息从结构上进行划分,并建立权重向量[10],得到多层的档案信息向量;利用档案信息向量计算相似度函数。最终实现模糊集的图书馆档案信息快速检索方法。
假设有4个档案信息[D1],[D2],[D3]和[D4],[T]表示信息索引项,4个档案中均包含[T],并且出现的次数一样,在档案信息[D1]中,[T]包含在档案开头;在档案信息[D2]中,[T]包含在档案信息中间部分,在[D3]和[D4]中,[T]包含在档案信息的最后部分。档案信息的信息搜索引擎会理解为4部分档案信息的索引[T]作用相同[11]。根据上述分析,出现在档案信息开头的索引比出现在档案信息中间部分的索引作用更大些,出现在档案信息最后部分的[D3]和[D4]中的索引主要作用在结尾部分。
式中,[ηt]表示可以调节的参数。海量图书馆档案信息的快速检索分以下几个步骤:
1) 利用查詢条件检索出图书馆档案中的信息权重,得到检索后的信息表达形式。
2) 抽取图书馆档案信息中索引项来代替原图书馆档案,将其出现的频率当作权重,获取档案的表达形式。
3) 建立图书馆档案信息的权重向量。
2 实验结果与分析
2.1 查全率
本文利用模糊集的图书馆档案信息快速检索方法来进行实验。选取www.ustc.edu.cn等网页来对图书馆档案信息进行查询,实验采用的计算机内存为4 GB,计算机系统为Windows 7,测试提出方法的查全率和查准率。档案信息的检索次数为52次,一共有1 000条实际的档案信息,需要全部检索出来。建立数据集对档案信息进行统计,统计如表2所示。
由表2可知,本文方法能够把实际档案信息数全部检索出来,其他两种方法只能检索出800条和825条实际档案信息。说明所提方法具有较高的查全率,可以避免有遗漏的档案信息,且不存在信息丢失现象,实现了海量图书馆中实际档案信息数的检索,为图书馆档案信息的管理提高效率。
2.2 查准率
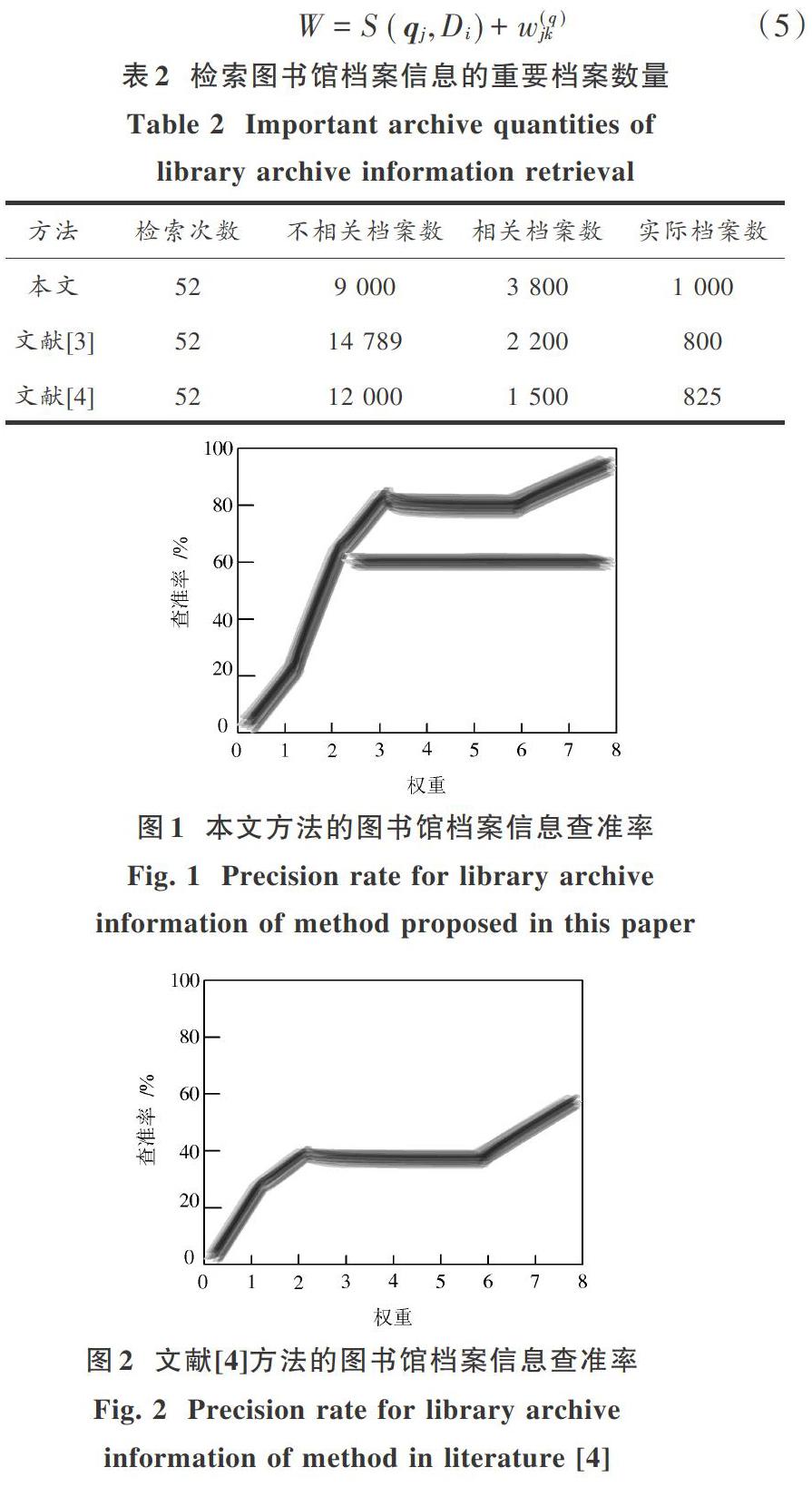
在此基础上,利用档案信息索引项的权重值对图书馆档案信息检索的查准率进行实验,实验对比如图1、图2所示。
分析图1、图2可知,本文方法中权重为2时,档案信息的查准率为60%;权重为3~6时,档案信息的查准率为80%;当权重为7和8时查准率逐渐升高接近100%。文献[4]方法中,权重为2~6时的档案信息查准率为40%;权重为6~8时,档案信息的查准率为40%~60%。对比结果得到,本文方法的查准率更高,可以准确检索出图书馆的档案信息。
3 结 论
本文对海量图书馆档案信息进行快速检索,检索出重要的档案信息,并对其进行统计,获得所提方法档案信息查全率高的优点。在分析档案信息检索查全率基础上,利用档案信息索引项的权重值对图书馆档案信息的查准率进行测试。实验结果表明,本文方法的图书馆档案信息检索具有较高的查全率和查准率。
参考文献
[1] 王莉军.海量数据下的文本信息检索算法仿真分析[J].计算机仿真,2016,33(4):429?432.
WANG Lijun. Text information retrieval algorithm simulation analysis under massive data [J]. Computer simulation, 2016, 33(4): 429?432.
[2] 程锋利,胡文娟,杨瑞.基于概率统计的小差异数据的分类模型仿真[J].科技通报,2016, 32(3):114?117.
CHENG Fengli, HU Wenjuan, YANG Rui. The small difference data classification model based on probability and statistics simulation [J]. Bulletin of science and technology, 2016, 32(3): 114?117.
[3] 张晓民,祁薇,张俊,等.T?STAR:一种基于关键词的关系数据库时态信息检索方法[J].计算机应用研究,2017,34(10):3051?3056.
ZHANG Xiaomin, QI Wei, ZHANG Jun, et al. T?STAR: keywords?based temporal information retrieval method over relational databases [J]. Application research of computers, 2017, 34(10): 3051?3056.
[4] 季斌,周涛发,袁峰,等.地球化学的空间自相关异常信息提取方法[J].测绘科学,2017,42(8):24?27.
JI Bin, ZHOU Taofa, YUAN Feng, et al. A method for identifying geochemical anomalies based on spatial autocorrelation [J]. Science of surveying and mapping, 2017, 42(8): 24?27.
[5] 崔道江,陈琳,李勇.智能检索引擎中的网络数据挖掘技术优化研究[J].计算机测量与控制,2017,25(6):189?191.
CUI Daojiang, CHEN Lin, LI Yong. Research on optimization of network data mining technology in intelligent retrieval engine [J]. Computer measurement & control, 2017, 25(6): 189?191.
[6] 曲朝阳,孙立擎,潘峰,等.基于流形排序的电网截面数据检索[J].科学技术与工程,2016,16(15):239?244.
QU Zhaoyang, SUN Liqing, PAN Feng, et al. The grid section data retrieval based on manifold ranking [J]. Science technology and engineering, 2016, 16(15): 239?244.
[7] 谷参.基于分布式结构的图书馆信息检索服务系统研究[J].现代电子技术,2017,40(1):83?85.
GU Shen. Research on library information retrieval service system based on distributed structure [J]. Modern electronics technique, 2017, 40(1): 83?85.
[8] 闫瑶瑶,李永先.基于“稀缺理论”的信息检索认知模型研究[J].情报杂志,2016,35(11):136?140.
YAN Yaoyao, LI Yongxian. Research on cognitive information retrieval model based on the "scarcity theory" [J]. Journal of intelligence, 2016, 35(11): 136?140.
[9] 李爱勤.多级索引驱动的地名信息检索方法[J].测绘科学,2017,42(4):103?107.
LI Aiqin. Multilevel index?driven place name information retrieval method [J]. Science of surveying and mapping, 2017, 42(4): 103?107.
[10] 刘萍,李斐雯,杨宇.国外交互式信息检索研究进展[J].情报理论与实践,2017,40(5):132?138.
LIU Ping, LI Feiwen, YANG Yu. Research progress of interactive information retrieval at abroad [J]. Information studies: theory & application, 2017, 40(5): 132?138.
[11] 韩其琛,李冬梅.基于叙词表的林业信息语义检索模型[J].计算机科学与探索,2016,10(1):122?129.
HAN Qichen, LI Dongmei. Semantic model with thesaurus for forestry information retrieval [J]. Journal of frontiers of computer science & technology, 2016, 10(1): 122?129.
[12] 程煜华,赖茂生.基于D?S证据理论的信息检索模型研究[J].图书情报工作,2017,61(21):5?12.
CHENG Yuhua, LAI Maosheng. Research on the information retrieval model based on D?S theory [J]. Library and information service, 2017, 61(21): 5?12.
猜你喜欢
数学大世界(2021年4期)2021-03-30
现代情报(2018年11期)2018-01-07
计算机应用(2016年10期)2017-05-12
网络安全与数据管理(2016年12期)2016-08-01
电测与仪表(2016年23期)2016-04-12
佳木斯大学学报(自然科学版)(2014年4期)2014-07-09
河北大学学报(自然科学版)(2013年5期)2013-03-01
中国管理信息化(2009年10期)2009-06-19
