
基于注意力机制的3D卷积神经网络孤立词手语识别
2022-03-26 09:16张瀚文杨萌浩
湖南工程学院学报(自然科学版) 2022年1期
胡 瑛,罗 银,张瀚文,杨萌浩
(湖南工程学院 计算机与通信学院,湘潭 411104)
0 引言
手语是聋哑人之间、聋哑人与正常人之间表达交流的桥梁,手语识别是通过计算机技术将手语转换为文字或语音,方便聋哑人与正常人的交流.传统的手语识别方法通过人工提取的特征来建立时序模型,采用隐马尔科夫[1]、条件随机场[2]、动态时间规整[3]等时序模型.人工提取特征依赖设计者的经验,且时序建模过程烦琐,多年来一直未取得突破.近几年,深度学习在图像分类、目标检测等领域取得了非常好的效果,研究人员借助卷积神经网络(Convolution Neural Network,CNN)来提取手形特征取得了不错的性能[4-5].手语词由视频序列组成,使用2D-CNN网络提取特征会丢失时间信息,3DCNN网络可以提取视频的时空特征,在行为识别中取得了重大突破,这为手语识别提供了新的启示[6].
孤立词只包含一个词语,是手语识别的一个研究方向,本文提出了一种基于注意力机制的3DCNN孤立词手语识别方法,解决了目前手语识别中的3个问题:提取手部区域和关键帧作为3DCNN的输入,专注于手部的动作并忽略背景区域;采用3D-CNN提取手语视频中的时空特征,可以捕获手语的运动信息;引入注意力机制,重点关注表达手语含义的视频帧.
1 基于注意力机制的3D-CNN手语识别模型
基于注意力机制的3D-CNN手语识别框架如图1所示,包括预处理、3D-CNN卷积神经网络和注意力机制三个部分.

图1 基于注意力机制的3D-CNN手语识别框架
1.1 预处理
预处理由提取手部区域和关键帧两个步骤组成,减少无用的特征,使神经网络训练更快速准确.预处理过程如图2所示.
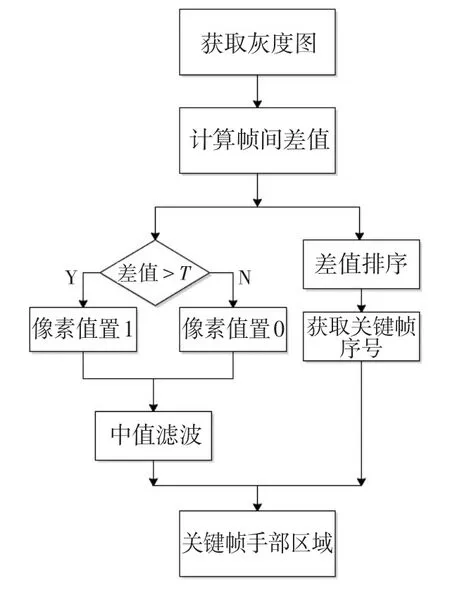
图2 预处理流程图
手语主要由手部动作组成,而手部在视频帧的尺寸太小,本文在预处理中检测出手部区域,去除与手部无关的信息.手部动作是手语视频中幅度最大的动作,可以通过检测视频中的动态区域来确定手部区域.本文通过帧间差分法提取手部区域[7],首先获取视频图像的灰度图,设Gk(x,y),Gk+1(x,y)分别是相邻两帧灰度图像的像素值,计算帧间差值,阈值设为T,大于阈值的视为动态区域,则将此像素点置为1,反之视为静态区域,则将像素点置为0:
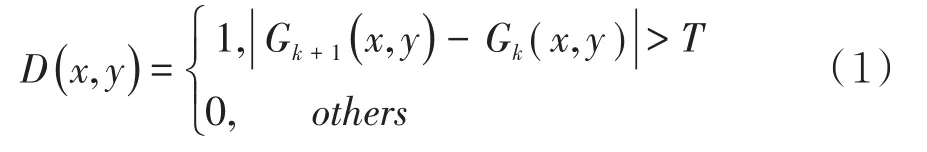
经过阈值化的差分图会产生脉冲噪声,使用3×3中值滤波滤除孤立的点,可得到清晰的手部轮廓图,最后将这些图片保存,合成手语视频.

图3 手部区域提取图
按照30帧/s的录制速度,一个手语孤立词帧数在50~200范围内,这些视频帧中大部分是过度帧,能表达语义特征的关键帧并不多.相邻两帧的信息变化较大时,则认为是关键帧.本文使用帧间差分法提取手语视频中运动明显的帧作为手语视频中的关键帧.将上文计算所得的帧间差分值按大小排序,选取前30帧作为关键帧,将关键帧按原视频中的位置恢复顺序,使关键帧恢复时间逻辑.
1.2 特征提取
本文参照文献[8]设计了一种3D-CNN网络架构,将预处理后得到的30帧关键帧输入到3DCNN中提取时空两个维度的信息.针对手语识别任务,3D-CNN网络架构在C3D网络结构上做了一些修改,网络参数如表1所示,该结构由5个卷积层、4个最大池化层和2个全连接层组成[9].3DCNN模型的输入数据的维度为160×120×30×1,每一帧图像的长和宽分别为160和120,30代表视频序列的帧数,1代表图片是单通道的二值化图像.卷积运算可以从输入数据中自动学习特征,每一个卷积核都可以提取特定的特征.3D-CNN网络可以提取手语的手形、手的位置空间特征,以及帧与帧之间特征关系的时间维度特征.本文所设计网络结构中包含5个卷积层,每一层卷积核的数量分别为:32、64、128、256、512,卷积核大小均为3×3×3,卷积核参数通过反向传播算法确定.3D卷积操作就是将多个连续帧同时叠加在一起,在空间上形成一个三维的立方体,再与一个三维的卷积核进行卷积操作,3D卷积定义如公式2所示:
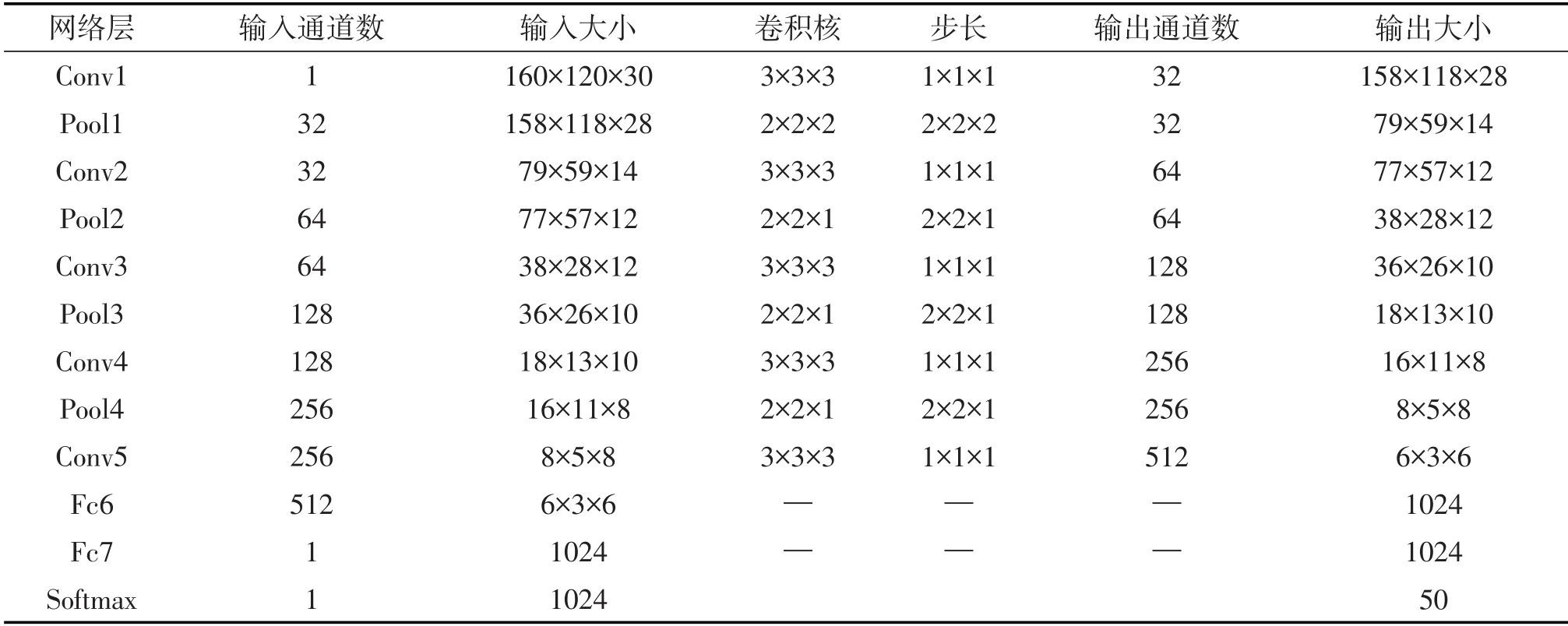
表1 3D-CNN网络参数
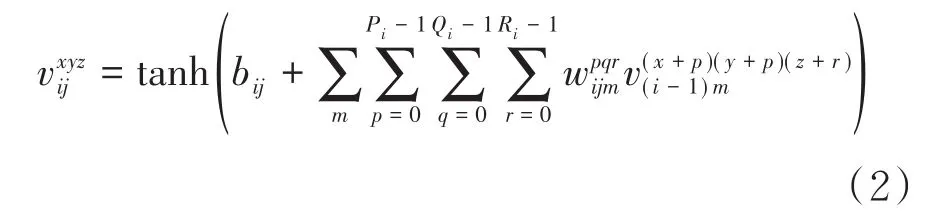
其中,为第i层第j个特征图上的输出值,bij为偏置项,m为i-1层特征图连接到当前特征图的集合的坐标,为权重系数,Pi、Qi和Ri分别是卷积核的长度,宽度和时间维度的尺寸.
3D-CNN网络架构的参数量大,需要足够的样本数据训练,本文采用迁移学习的方法解决训练样本数据少的问题.UCF-50行为识别数据库收集了50个动作类别,首先用UCF-50数据集对3D-CNN网络模型进行预训练,学习到图像的底层特征,将预训练得到的权重作为手语识别网络模型的初始化参数,迁移到手语数据集上,对整个网络进行训练微调.

图4 迁移学习模型
1.3 注意力机制
人类观察外部事物时,一般不会观察事物每个角落,注意力会集中在对观察目标感兴趣的地方.注意力机制[10]学习人类的视觉系统,能学习每个时刻的权重分布,筛选出更为重要的信息.每个孤立词通过预处理获得了30帧关键帧,但每一帧对手语语义的贡献是不同的,不同的帧应给予不同的权重.本文在3D-CNN网络的Conv5网络层后添加了注意力机制,采用自注意力机制[11]来实现对不同视频帧给予不同的权重,注意力模型如图5所示.
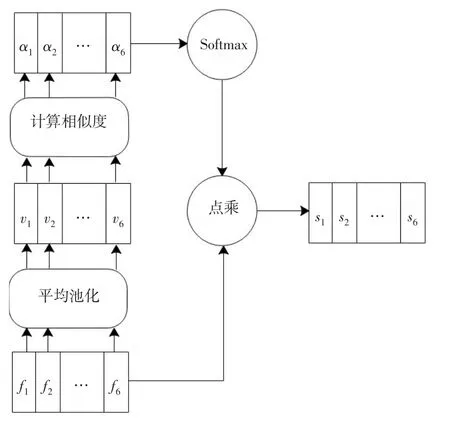
图5 注意力模型
F=(f1,f2,…,f6)是Conv5网络层输出的特征,大小为6×3×6×512(长×宽×时间深度×通道数).为了方便计算,将长度和宽度采用平均池化变为一维特征[12],V=(v1,v2,…,v6)为时间深度特征,大小为1×1×6×512(长×宽×时间深度×通道数).采用两层神经网络(激活函数选择tanh函数)计算vi之间的相似度,得到注意力权重αi,如公式3所示.
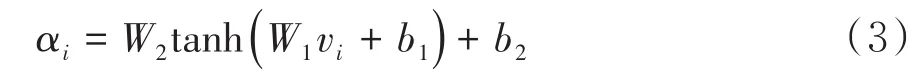
W1、W2、b1、b2为神经网络的学习参数.为计算各时间维度上的加权特征,首先采用Softmax函数归一化注意力权重αi,然后与fi做点乘运算,得到加权后的特征序列si:

2 实验结果与分析
2.1 运行环境和数据集
服务器的硬件配置:CPU为Intel Xeon E5-2680,128 GB内存,4个NVIDIA TITAN XP GPU.运行的软件环境为Ubuntu16.04操作系统,搭建了tensorflow2.0深度学习框架.
本文采用公开手语数据集DEVISIGN-D[13],数据集由500个词汇组成,每一个手语词汇录制12个手语视频,由8人录制,共6000个视频,帧率为30 fps.本文选用DEVISIGN-D中的50个常用词汇作为实验样本,按4∶1随机划分为训练集和测试集.
2.2 训练参数
每次迭代随机选取32个视频样本,损失函数选用交叉熵,使用Adam优化器,动量取0.9.初始学习率设置为0.001,学习率衰减引入余弦退火算法[14],可以跳出局部最优解.卷积层采用ReLU激活函数,网络参数使用批量归一化处理.loss值变化曲线如图6所示,经测试集的loss值随着迭代次数的增加而减少,表明模型没有发生过拟合现象.
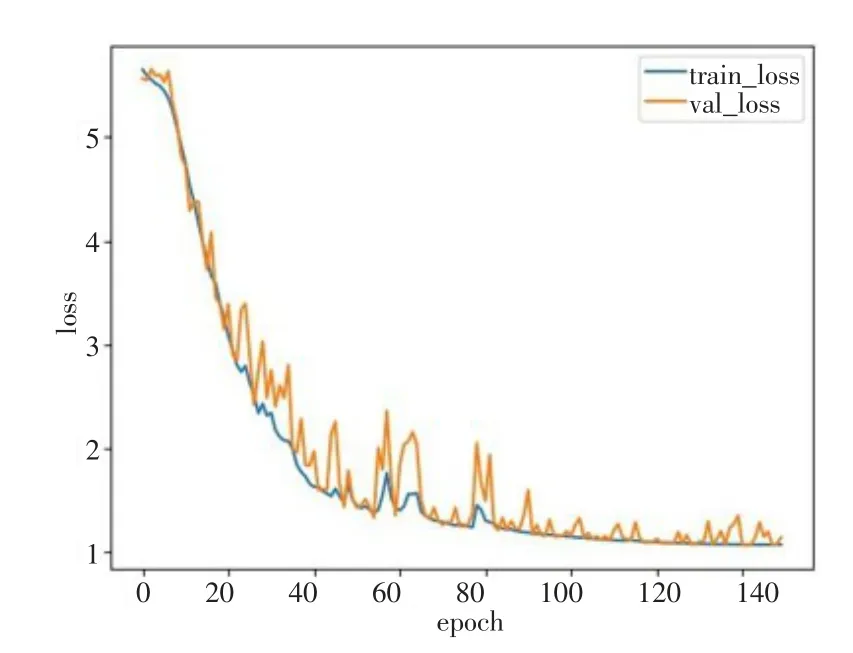
图6 loss值曲线图
2.3 实验分析
引入注意力机制可以给不同的帧分配不同的权重,让更重要的帧对结果的影响力更强.图7为手语词“领袖”的部分帧,该手语词由两套独立的动作组成,前一部分动作为“领导”的动作,后一部分为最高级别的意思,最高级别的“领导”即为“领袖”.将此视频帧输入到网络,通过自注意力模型,输出结果为:

图7 手语词“领袖”部分帧
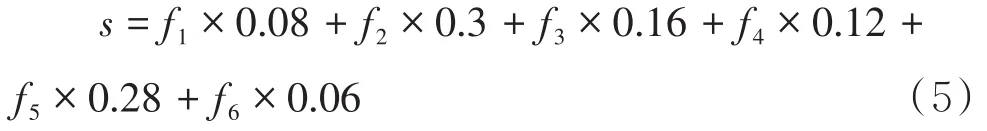
此例可以看出,通过注意力机制能学习每个时刻的权重分布,筛选出更为重要的信息.
在上文所提的基于注意力机制的3D-CNN手语识别模型中,去除预处理和注意力机制部分后的模型称为基础模型,为验证预处理和注意力机制是否能提高模型的性能,在相同的参数设置和数据集下进行了对比实验,实验结果如表2所示,添加了预处理和注意力机制后,手语识别的准确率都有一定程度的提升.

表2 基础模型与增强模型准确率比较
为了验证本文所提模型的可行性,与GMMHMM[15]、3D-CNN[16]、CNN-LSTM[17]3种手语识别方法进行了对比实验.在相同数据集下,根据文献[15]-[17]所提算法思路,通过编程实现了上述3种算法和本文所提算法,实验结果如表3所示,说明采用深度学习方法比传统方法更有优势,实验结果验证了本文所提模型的有效性.
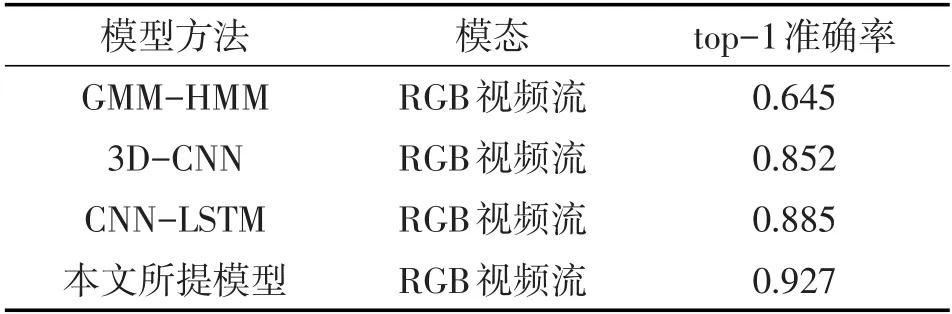
表3 本文方法与其他方法的准确率比较
3 结束语
本文提出了一种新颖的3D卷积神经网络孤立词手语识别模型,通过预处理提取了手部区域和关键帧,去除了与手语信息无关的冗余信息,在网络中引入了注意力机制,重点关注语音信息丰富的视频帧,提高了网络模型的特征表达能力.使用UCF-50数据集对3D-CNN网络参数进行初始化,解决了手语视频数量少的问题.实验结果验证了本文所提出的方法对孤立词手语识别有较高的准确率,但是该方法还存在一些不足,也是今后还需努力的方向:(1)引入多模态机制,结合RGB视频流、深度信息和骨骼信息,考虑多模态特征的融合;(2)利用Faster-RCNN等深度学习目标检测方法提取手势区域,进一步提高3D-CNN的识别准确率.
猜你喜欢
实用手外科杂志(2022年2期)2022-08-31
重庆科技学院学报(自然科学版)(2022年6期)2022-02-04
微型电脑应用(2020年12期)2020-12-25
活力(2019年15期)2019-09-25
大连理工大学学报(2017年4期)2017-08-07
现代特殊教育(2016年21期)2016-12-14
西北工业大学学报(2015年3期)2015-12-14
青少年科技博览(中学版)(2015年8期)2015-10-28
中国医疗美容(2015年1期)2015-07-12
中华皮肤科杂志(2014年4期)2014-12-19
