
互联网突发事件监测信息分类方法研究
2022-03-26 02:10罗年学
数字制造科学 2022年1期
张 昱,罗年学
(武汉大学 测绘学院,湖北 武汉 430079)
突发事件是指突然发生,可能会导致严重的经济损失、社会危害的风险事件。目前我国应急体系中,突发事件灾情获取通常采取政府部门采集、层层上报的方法,虽然数据更为专业、准确,却有中间层级过多,反应较慢的问题[1],需要监测互联网突发事件进行信息补充。获取、分析主流新闻网站、社交网络数据,可以快速捕获大部分的突发事件,适应当前应急体系建设需求。
在中文互联网文本的监测与分析中,白晓雷等[2]使用支持向量机模型构建二分类或多分类问题,对网络反讽文本、舆情文本情绪进行识别;夏彦等[3]将规则对比与统计相结合,对新闻的正文内容进行突发事件关键词识别;Sakaki等[4]对Twitter上的有关地震的推文进行分析,使用支持向量机进行事件检测,并基于卡尔曼滤波估计地震发生位置;姚占雷等[5]研究者从情报学角度切入,利用词间距策略构建了突发事件识别模型。目前关于突发事件文本挖掘的研究主要集中在突发事件文本的初始识别和具体事件内容的信息提取两方面,突发事件的分类作为数据获取与深入挖掘的中间环节获得较少的关注度。笔者研究以互联网为平台,选取多源数据内容,将突发事件新闻语料完成分类分析,实现突发事件的监测,为应急决策情报体系服务。
1 互联网突发事件监测信息分类方法
机器学习是采用数值建模的计算方法,自动获取知识的学习过程,可以用于预测问题,即基于给定的输入变量预测输出变量,其基本思想是基于训练样本属性信息得到分类或者决策函数,估计测试样本属性信息。为探究更适合突发事件监测的自动分类模型,笔者使用了朴素贝叶斯、BP(back propagation)神经网络、支持向量机和随机梯度下降-支持向量机分别对语料进行分类。
1.1 突发事件分类流程
根据突发事件的基本类型,利用计算机遵循某种分类法则,按照其语义特征对文本进行有监督分类,实现突发事件自动分类处理。文中基于机器学习方法的中文文本自动分类主要有8个步骤:①垃圾文本过滤。剔除互联网文本尤其是社交媒体和论坛类短文本数据中可能出现纯符号文本、重复文本。②文本标注。为文本类型进行手工标注,用于有监督学习的训练模型构建和精度评价的计算。③中文分词。利用结巴分词将语句切分成词为文本表示模型做准备。④文本预处理。将临时停用词阈值设为0.5,即若超过50%的文档出现了某词,则将此词设为临时停用词,不作为向量空间的特征项,在一定程度上控制了过拟合现象发生的几率。⑤划分数据集。将数据划分为训练集和测试集。⑥特征提取。使用TF-IDF(term frequency-inverse document frequency)模型进行词权重计算表示文本特征,构建向量空间模型。⑦分类建模。使用依据已有训练集构筑的分类模型,经过机器学习算法,对待分类文本的类别进行预测,实现自动分类。⑧精度评价。检查测试集的分类预测结果,使用混淆矩阵评价分类模型精度。突发事件的机器学习自动分类流程如图1所示。
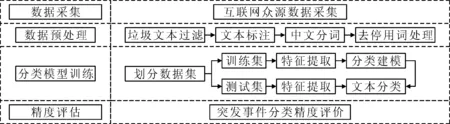
图1 突发事件的机器学习自动分类流程图
1.2 突发事件分类模型
(1)朴素贝叶斯。朴素贝叶斯分类(naive bayes classification,NBC)是基于概率统计理论,建立在特征项之间相互独立假设上的一种贝叶斯学习方法。朴素贝叶斯分类可以处理多类问题,常用于文本分类问题,基本思想是根据训练集文档的特征项(词)和类别之间的条件概率,预测新样本的类别。
按照贝叶斯公式,已知样本为y类的概率是p(y)、样本某特征x出现的概率是p(x),对于该确定样本特征x,此样本属于y类别的概率为:
(1)
(2)BP神经网络。BP神经网络是一种多层前馈网络,其具有单向传播、误差逆传播的特点[6]。多层感知机BP神经网络如图2所示,多层感知机BP神经网络由输入层、隐含层和输出层构成,经测试选择2层隐含层,各层内部神经元无连接,层与层之间的节点相连通,根据输入向量和目标输出向量计算目标值与实际值的平方误差,根据阈值完成迭代和权值调整。
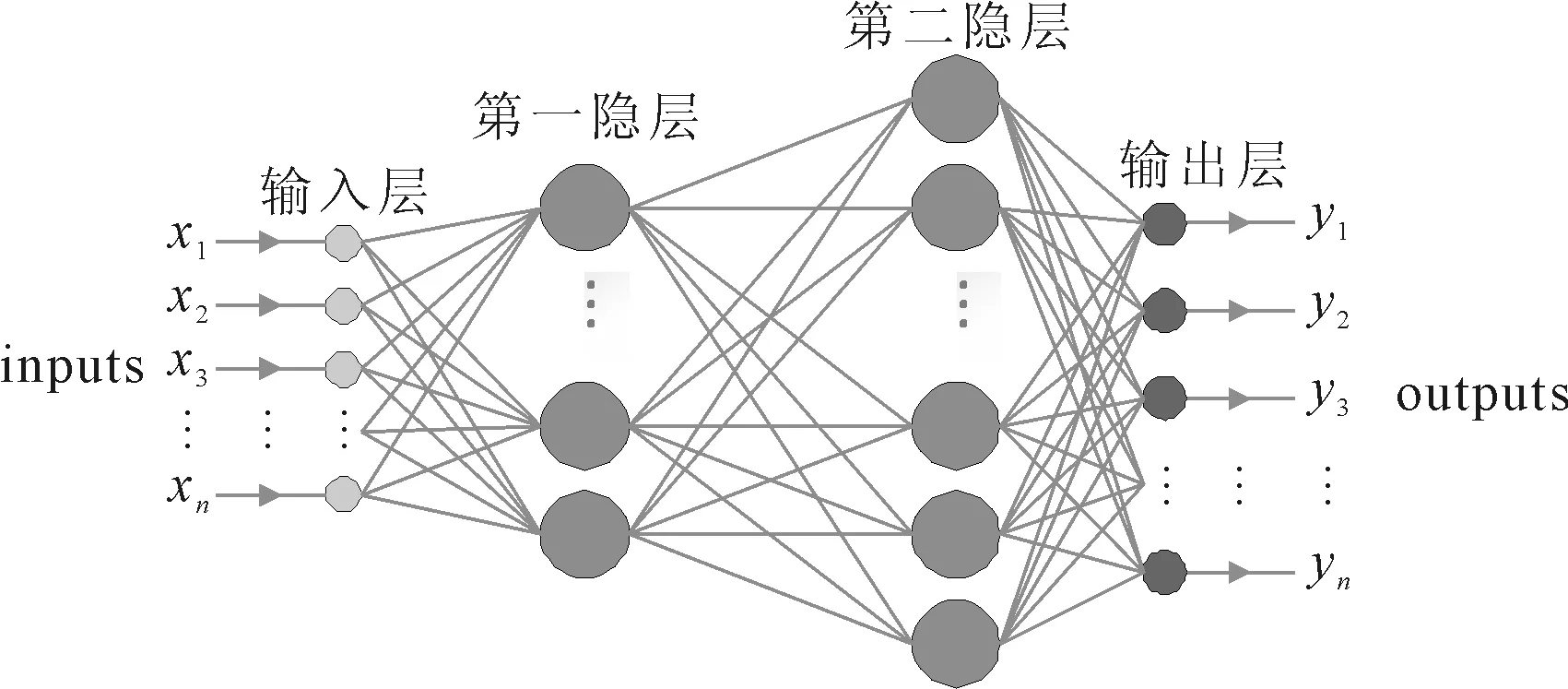
图2 多层感知机BP神经网络
(3)支持向量机。支持向量机(support vector machine,SVM)算法对于解决高维问题有明显优势,并且对样本稀疏性不敏感,而文本分类有着稀疏、高维、特征关联度较高的特点,因此SVM非常适合处理文本分类问题。支持向量机的基本核心思想是:①求解最优分类面(边界)以优化泛化能力;②使用松弛变量引入软间隔处理线性不可分问题;③构造核函数向高维隐式映射来处理非线性问题。文中用到的多分类支持向量机模型中,在求解目标函数时用来计算样本预测值与真实值的差,称为损失函数,其为铰链损失函数,可用式(1)表示,其中C为正则化参数,n为样本个数;β为系数向量,y为类标记。
C×max(0,1-yi(βxi))]
(2)
(4)随机梯度下降-支持向量机。在本文研究中随机梯度下降(stochastic gradient descent,SGD)算法,在信息冗余时表现更佳,相较于非随机算法能够更有效利用信息[7]。对于支持向量机的随机梯度下降算法中,对于每个实例求解方程对于β的偏导,有
(3)
再利用迭代策略,设置一定步长,迭代时随机选取样本计算梯度,即以梯度的无偏估计代替精确值,向负梯度方向搜索可以得到单调递减的序列,直到下降到极小值,计算得到全局最优解。其代码如下所示,其中C为正则化参数,η为学习速率,β初始化为系数的随机值向量。

input:random parameter βoutput:optimal parameters βfor i in alldata: for instance in range X_length:xi= X[random index]yi= y[random index]if 1-yi(βxi)≤0: gradient=βelse: gradient=β-C×yixiβ=β-η×gradient
2 突发事件监测信息分类实验分析
2.1 突发事件数据集构建
突发事件基本类型为实际救援的相关部门权责分配提供参考,突发事件的具体种类则在具体灾害应对策略中提供基本方向,如“地震”灾害和“泥石流”灾害有着不同的应对措施,为构建突发事件分类模型,需要建立突发事件语料训练集。
笔者对突发事件监测信息的研究范围确定在中国境内事件,突发事件文本数据来源于网络,通过八爪鱼爬虫选择有一定热度的突发事件早期网络公开信息共5 821条,其中3 766条来自于微博、195条来自于微信、其余1 860条来自于其他新闻门户网站,文章作者一般为媒体、记者或者当地政府,相比网民个人主体用户具有较好信息可信度。同时使用Scrapy框架获取新浪新闻和新浪微博,并人工筛选出财经、体育、教育、娱乐、生活等表意明确为非突发事件的语料400条。为保证新闻语料信息涵盖全面以及进一步分类,本文选取的数据集语料涵盖了4大基本类型中常见的30种突发事件,并予以人工标注,每种突发事件新闻语料样本不少于2条。突发事件分类构建标准如表1所示。

表1 突发事件分类构建标准
笔者利用jieba分词词性标注模块,得到分词后每个中文词汇的词性,并且挑选出地名(词性为ns)词汇,对比各省市的标准行政区划名称,抽取文本中出现的第一个行政区划地名信息作为该突发事件的发生地点,使用高德地图API(application program interface)完成地理编码。我国2020年6月至11月主要报道的突发事件监测信息样本信息如表2所示,分类地理分布如图3所示,可以看出东部地区发生较多引起舆情关注的突发事件,可能与人口密度相关。使用Scikit-learn框架中的LDA(latent dirichlet allocation)主题模型,完成对监测信息数据的主题提取,主题模型如表3所示,可以看出该段时间内重要的主题和各类事件比例符合实际情况。
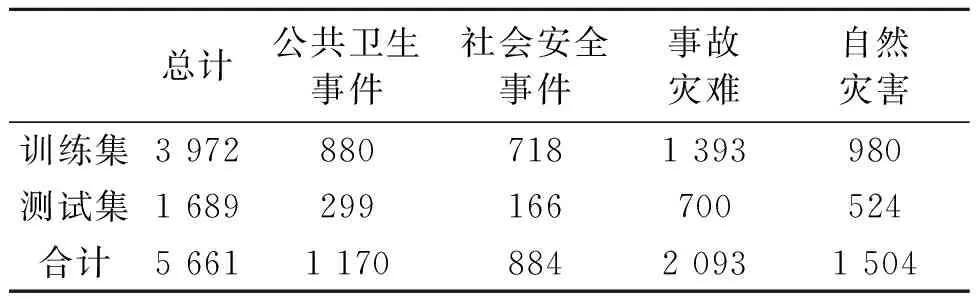
表2 突发事件监测信息样本信息
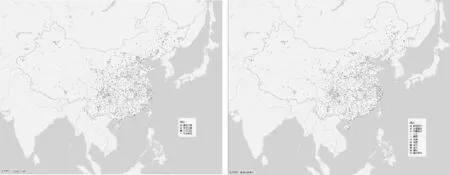
图3 全国突发事件分类地理分布图
2.2 分类实验分析及精度评定
(1)分类实验分析。在本文试验中,笔者选择了4种模型进行分类测试。为测试出更优的突发事件分类方案,笔者对分类器的精度进行比较,并在输入相同向量模型的情况下单独计算各分类模型训练模型和预测分类函数程序运行所需CPU(central processing unit)时间。从构建的突发事件数据集中随机抽取若干条突发事件新闻,不再用于本次模型训练,作为本次测试样本,使用朴素贝叶斯、BP神经网络、支持向量机和SGD支持向量机对突发事件测试语料进行分类对比,再针对模型分类结果的混淆矩阵进行对比评估。其中使用BP神经网络模型时对其参数进行调试,使用适用于大数据集的基于随机梯度下降的优化算法作为优化权重的求解器,确定使用2个隐藏层、第一、二层分为7个和9个隐藏单元下的模型即达到较好效果。支持向量机与SGD支持向量机均使用线性核策略和铰链损失函数求解目标函数。
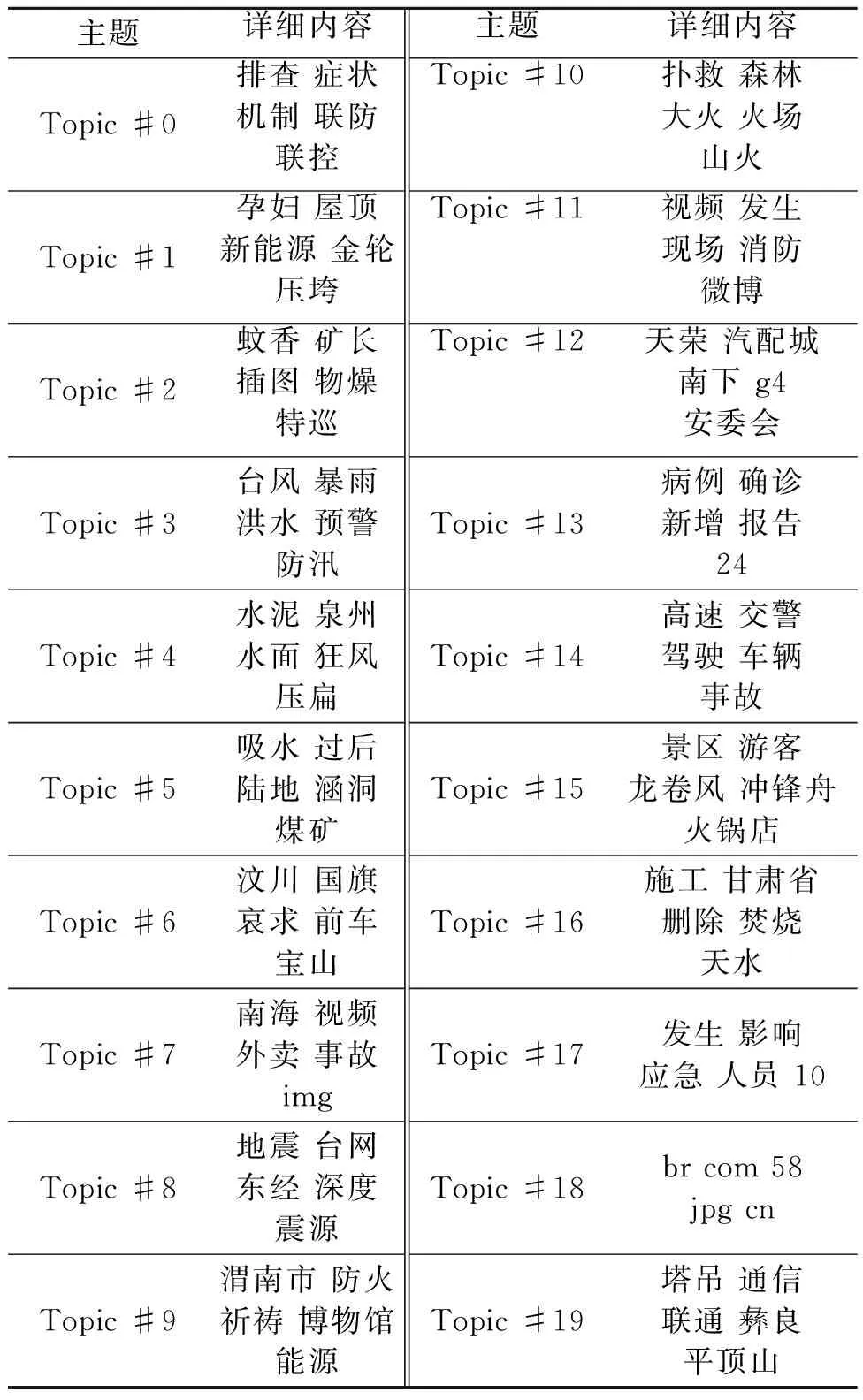
表3 突发事件监测信息主题模型
(2)分类算法精度评定。混淆矩阵是机器学习领域中统计分类的一种可视化工具,包含由某种分类器完成的实际和预测分类的信息,通常使用矩阵中的数据来评价这种分类器的性能。混淆矩阵第一列表示实际类别,第一行表示预测类别,对角线上的数字表示分类正确的数量,非对角线则表示错误分类,混淆矩阵精度评定指标如图4所示。
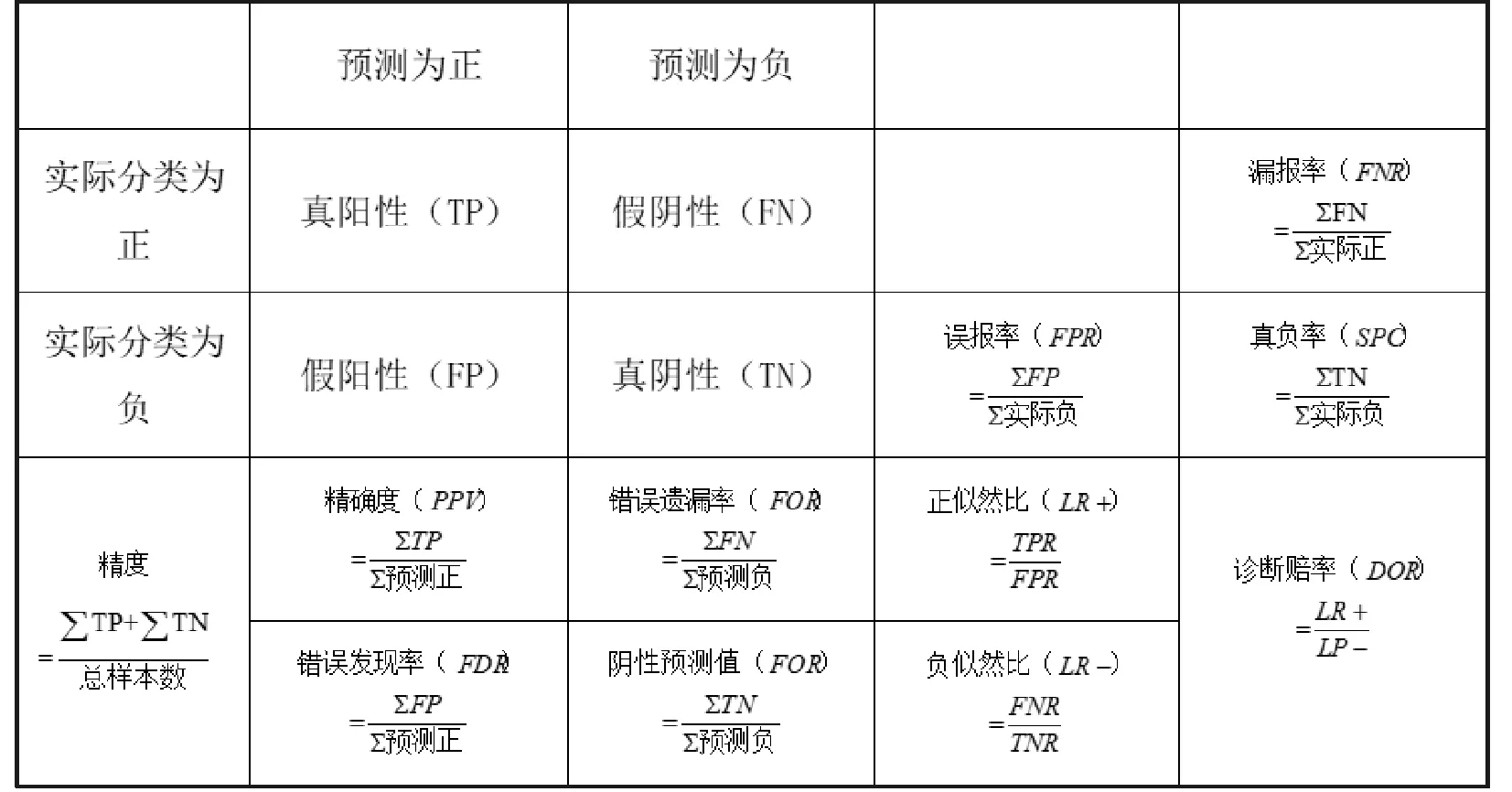
图4 混淆矩阵精度评定指标
文中选择其中的召回率(recall)和精确度(precision)作为评价的主要指标。召回率是从样本的实际分类角度出发,是指被模型正确预测的概率,精确度是从样本的预测分类角度出发,指被预测为正的样本中实际为正的样本比例。精确度和召回率的取值范围都介于0与1之间,一般情况下,两者的大小和模型分类效果的好坏成正相关。召回率和精确度两个指标在很多情况下是相互制约的,为了综合评价召回率和精确度,引入信息检索领域的一常用综合评定指标F-Score,用于计算召回率和精确度的加权调和平均,其中最常见的参数α为1,即F1-Score。
(4)
式中:P为精确度;R为召回率。
测试分类结果如表5所示。从表5可知,4种模型对于整体精确度、召回率和F1-score有明显分层差异,支持向量机的分类效果最优,随机梯度下降(SGD)-支持向量机与之相近,BP神经网络次之、朴素贝叶斯表现较差。图5的混淆矩阵显示两种分类方法对角线上均有预测正确的数值,都未出现过拟合现象。4种分类器对于事故灾难和公共卫生事件的识别均可以较好识别,差异主要出现在对非突发事件语料的分类识别中,此处语料的种类较为繁杂、离散型强,而朴素贝叶斯对于此处的离散性较为敏感。由于突发事件分类同时具有突发事件类间重叠和非突发事件类内离散两种属性,基于支持向量机的模型对于此类数据有着较为弹性的解决方案,在此处其优势得到了体现,并在各分类中均具有最佳表现。对比计算时间,使用随机梯度下降的线性核支持向量机损失了0.2%精确度。
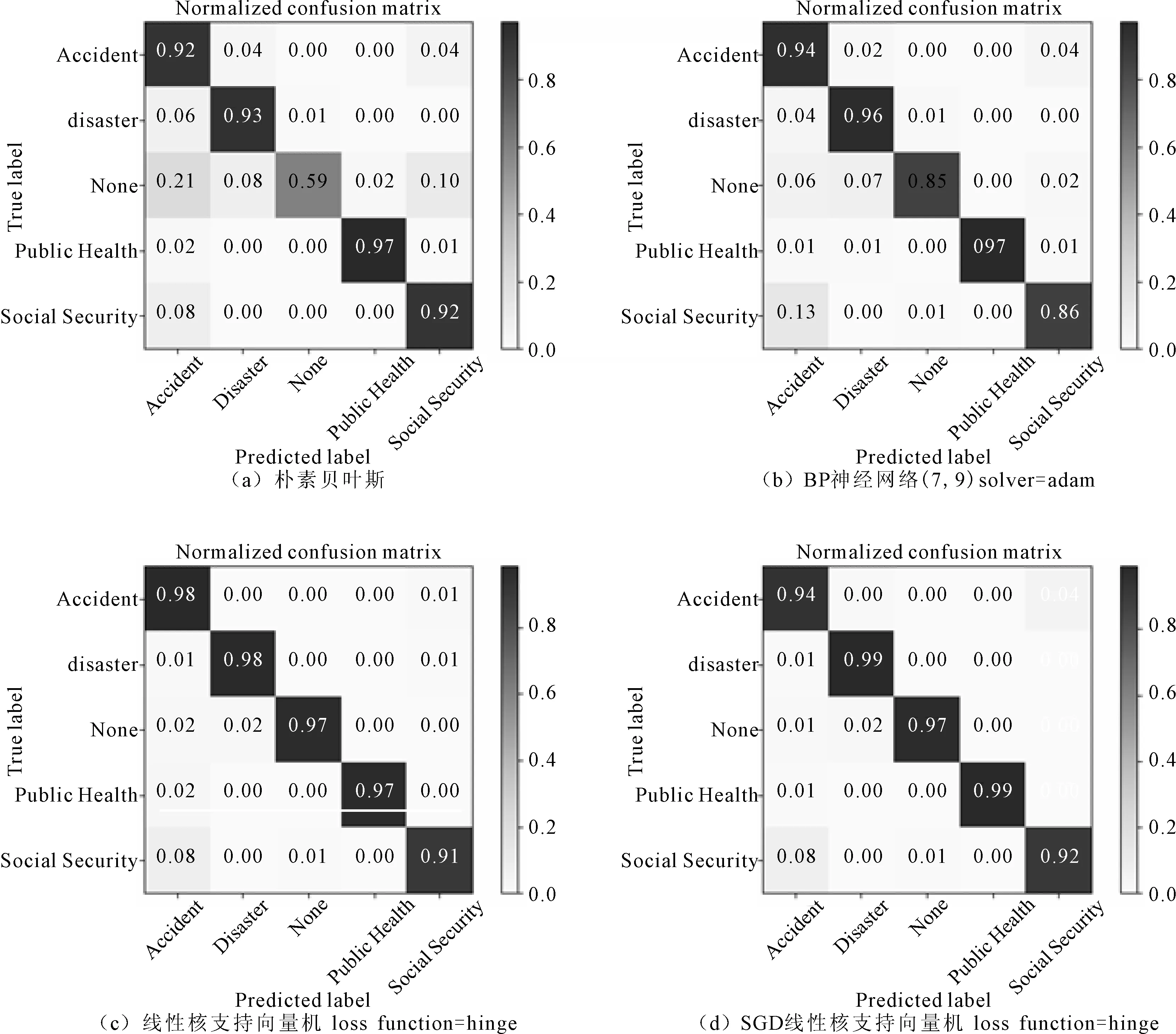
图5 突发事件类型分类效果混淆矩阵界面图
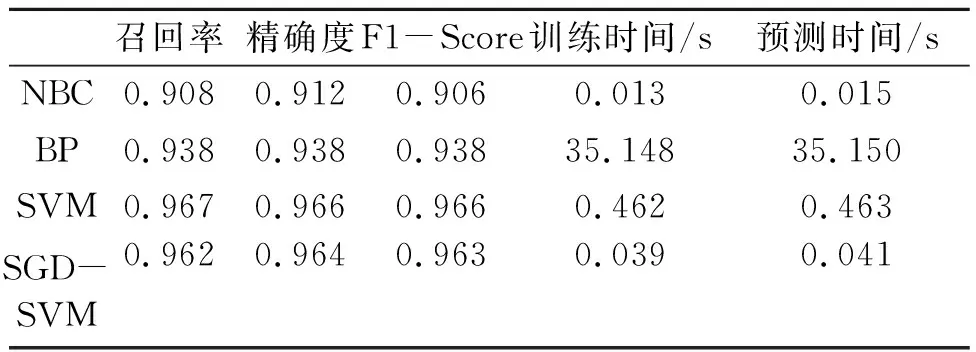
表5 使用突发事件新闻测试分类效果
同时,模型训练时间和预测时间下降了91.63%和91.11%。虽然BP神经网络总体表现较为优异,但在同样运算环境下,仅2层隐藏层在计算时间上已经表现出明显的运算速度劣势。在小范围计算中,线性核支持向量机表现最佳,考虑到实际应用的大规模数据运算和有限的精确度损失前提下,SGD支持向量机求解此类问题较优。
3 结论
针对互联网文本数据突发事件监测信息分类的快速响应情境,笔者对比朴素贝叶斯、BP神经网络、支持向量机和随机梯度下降支持向量机的分类效果,提出在突发事件监测信息识别分类中随机梯度下降支持向量机模型的使用可以在保证精度的同时快速完成分类。
猜你喜欢
厦门大学学报(自然科学版)(2021年4期)2021-06-22
法律方法(2021年4期)2021-03-16
法律方法(2021年4期)2021-03-16
计算机应用与软件(2018年9期)2018-09-26
智富时代(2018年11期)2018-01-15
智富时代(2018年11期)2018-01-15
领导科学论坛(2016年10期)2016-06-05
文史春秋(2016年8期)2016-02-28
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
外语教学理论与实践(2014年2期)2014-06-21
