
基于集成学习的转子部件脱落故障诊断方法
2022-03-26 02:10马圣杰
数字制造科学 2022年1期
周 晓,马圣杰
(武汉理工大学 机电工程学院,湖北 武汉 430070)
转子系统是发动机的核心系统,一旦发生转子部件脱落的故障,便会给机组的运行留下严重隐患。因此,能及时发现征兆信息,对于转子机组的健康管理具有重要意义[1-2]。
常用的转子故障诊断方法有基于模型的方法。转子系统动力学模型主要是从系统机理、故障原因和转子系统状态的影响角度出发的物理或数学模型。主要通过安装特定传感器,依托于内积运算[3],通过傅里叶变换和全息谱等方法[4-5]实现故障特征提取与故障识别。
随着机器学习相关技术被广泛应用于工业场景。传统的故障诊断方法已逐渐无法满足诊断要求[6]。常用的机器学习算法有决策树、神经网络和支持向量机(support vector machines,SVM)等算法[7]。
工业大数据时代下的转子故障数据具有信息复杂和耦合不确定等特点[8],因此需要使用大数据计算框架。基于Spark框架实现的算法在时间效率和伸缩性方面均具有优越性[9],相比于其他框架,在迭代和机器学习算法上具有更好的性能[10]。
笔者将大数据分析技术与故障诊断技术相结合,研究基于数据驱动的转子脱落故障诊断模型,提高故障诊断的识别准确率,帮助运行人员发现转子脱落故障的早期征兆,实现智能诊断转子的故障。
1 转子部件脱落故障特征工程
在机器学习工作流程中,特征工程的作用是将原始数据转换成算法可理解的形式。这个过程从数据中提取出对于表征业务逻辑来说更合适的特征,将依次进行数据清洗、特征提取和特征优选,为后续的故障诊断模型的构建提供支持。
本文采用的转子故障数据集是由国内某工厂提供的真实运行数据,通过在转子两端和轴端布置电涡流位移传感器进行振动位移值的采集,包含联端XY、非联端XY和轴向AB6个通道的位移数据,联端表示传感器安装在靠近联轴器的轴承上。采集数据包含采样率、转速、采样点数、转动周数和振动数据。共有10台机组的数据,其中5台故障机组的数据采集自发生转子部件脱落之前的半年内。另外5台机组在获取数据之后的一年以上,未发生此类故障。
1.1 转子数据清洗
为保证模型建立时输入数据的完整性和可靠性,首先进行数据清洗。对转速分析后发现,部分机组存在转速为0的无效数据,对这些数据进行删除处理。此外,少数时段内存在各通道测点数据的采集时间不对齐的现象,表现为某通道缺失一个时间单位的数据,使得该通道后续数据相比其他通道均有所提前。为了提高模型的准确率,将该缺失时间点的其他通道数据删除,保持数据采集时间一致。数据对齐前后的转速变化如图1所示。
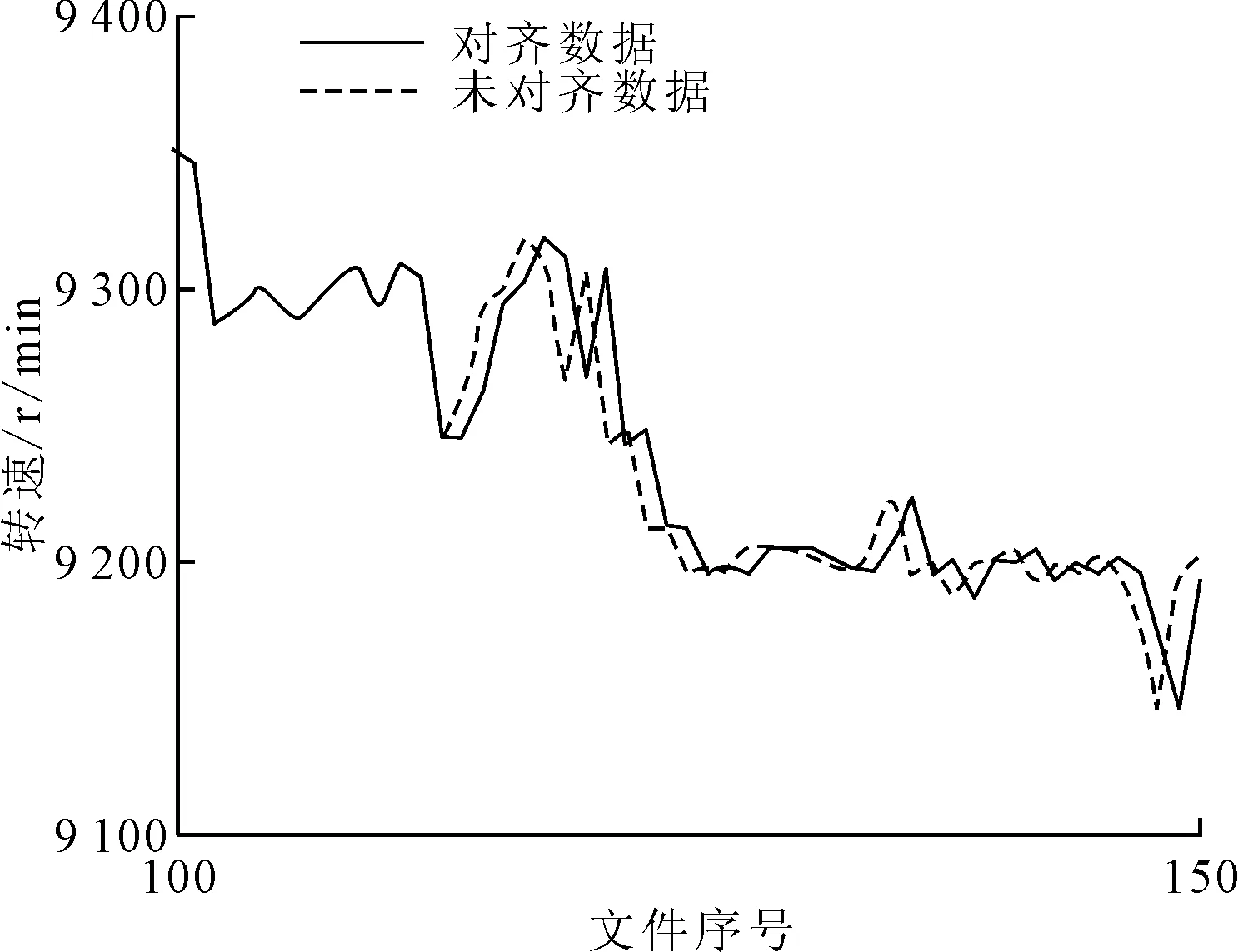
图1 数据对齐前后的转速变化图
1.2 转子数据特征提取
为了从多个角度全面分析转子运行状况,将从振动信号的时域、频域中提取不同的故障特征量,使用的信号处理方法如图 2所示。
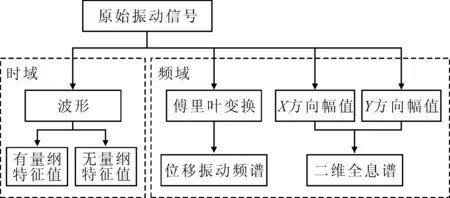
图2 信号处理方法
1.2.1 时域特征提取
转子的时域信号分为有量纲和无量纲特征值。有量纲特征值针对转子振动波形数据进行提取,包括振幅的最大值、最小值、平均值、峰-峰值、整流平均值、方差、均方值和均方根值。除提取有量纲特征值外,还提取了多种常被应用于旋转机械故障诊断中的无量纲指标,包括振动信号的峭度、偏度、波形因子、峰值因子、脉冲因子和裕度因子,以此来提高特征对于不同转子运行情况的泛化描述能力。
1.2.2 频域特征提取
由于转子故障的发生,常表现为一定的频谱分布特点,因此使用快速傅里叶变换作为频域分析方法。在位移振动频域中,提取一倍转频、二倍转频、三倍转频的幅值和相位,以及一倍转频、二倍转频、三倍转频占位移振动总能量的百分比作为故障特征。
由于转子数据同时使用了XY方向的传感器进行数据采集,针对传感器方向是互成90°的关系,采用全息谱技术对于振动信号进行诊断分析。全息谱技术实质上是对于多传感器信息的融合,使用合成的椭圆来描述不同倍频分量下转子的振动表现。
对于转子某截面k在频率(ωj)对应的振动数据,其全息谱参数使用式(1)进行计算:
xk=Akxsin(ωkjt+αkj)cosαn-
Bkysin(ωkjt+βkj)sinαn
yk=Akxsin(ωkjt+αkj)sinαn-
Bkysin(ωkjt+βkj)cosαn
(1)
式中:Akx、αkj、Bky、βkj分别为X、Y方向的幅值和相位;ωkj为旋转频率;αn为X、Y方向传感器之间的安装夹角;xk、yk分别为X、Y方向的频率分量信号。
若X方向代表水平时,某截面的工频振动信号可表示为:
(2)
式中:sx,cx分别为X方向振动信号的正弦和余弦系数;sy,cy分别为Y方向振动信号的正弦和余弦系数;ω为转子的工频;x,y分别为X、Y方向的频率分量信号。
在转子故障数据中,非联端X与非联端Y,联端X与联端Y分别是两组相互垂直的振动信号。这里分别挑选故障机组和非故障机组的全息谱进行绘制,如图3和图4所示。
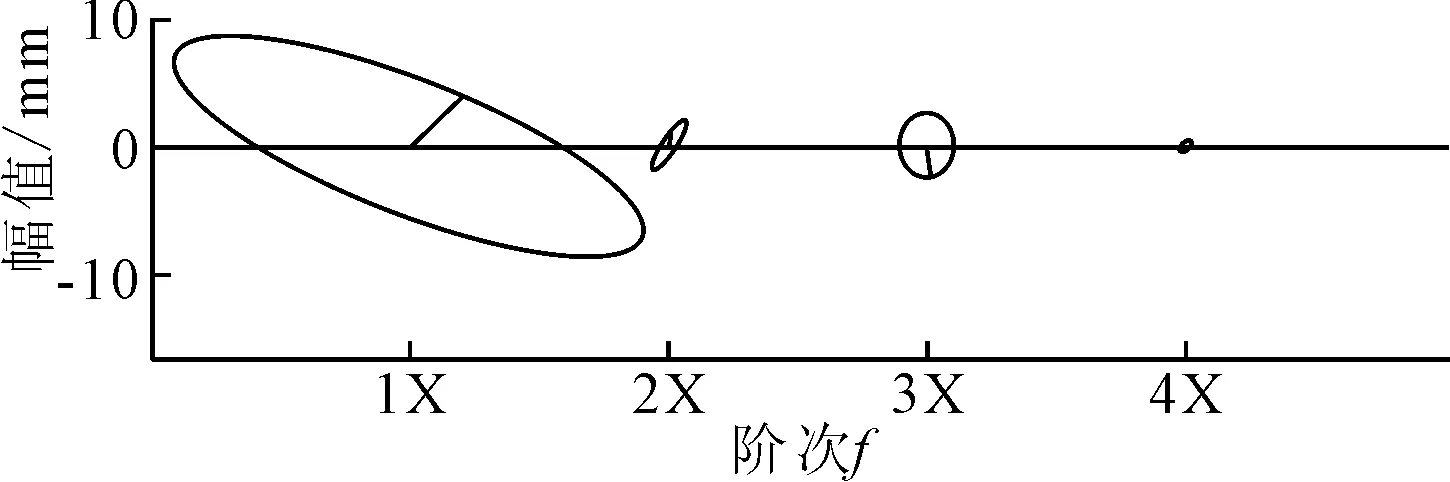
图3 故障机组的全息谱
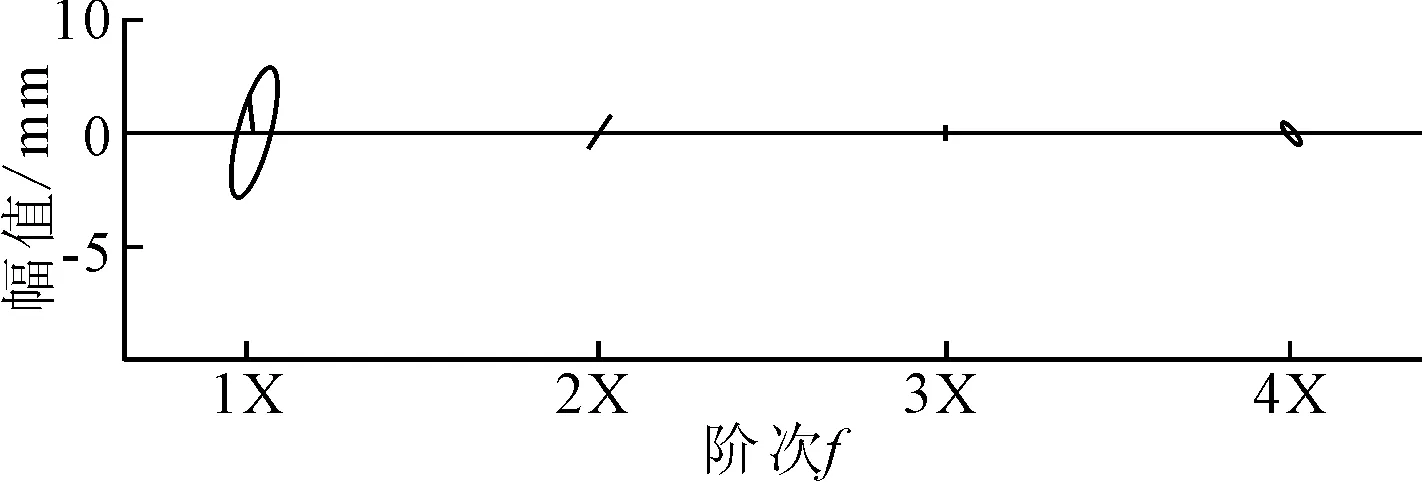
图4 非故障机组的全息谱
由于四倍频的椭圆在故障和非故障机组中差异不明显,这里选择一倍频到三倍频的椭圆长半轴半径、短半轴半径以及椭圆离心率作为全息谱分析技术提取的特征。
1.3 转子数据特征优选
由于提取的特征之间可能存在高度相关性,在建模之前需要对特征进行优选。笔者结合低方差过滤、信息增益以及高相关筛选3个特征选择方法对转子故障数据进行优选。
首先进行低方差过滤。通常认为低方差变量携带的信息量很少,可对其直接过滤。接下来计算信息增益。这是以熵为基础的特征选择方法,通过度量不确定性的减少程度算出每个特征对于目标的贡献度。最后结合皮尔逊相关性系数进行高相关筛选。计算两两特征之间的相关性,相关系数的绝对值越大,代表相关性越强。当相关性过强时,则选择删除其中一个特征。由于应尽量保留与目标特征具有高相关性的特征,选择结合两个特征的信息增益进行判断,删除信息增益更低的一个特征。
2 基于集成学习的转子部件脱落故障诊断
为了提高故障诊断的准确率,提出一种两层结构的Stacking集成学习模型。集成学习的构建思路是将多个学习器进行集成,以得到比单独学习器更优的故障诊断效果,其效果来自于不同学习器对于不同特征的学习能力。由于超过两层的结构会面临更为复杂的过拟合问题,且收益有限,因此采用两层结构。
模型的第一层由多个基模型构成,针对决策树和支持向量机适合二分类任务的特点,将它们作为基模型。第二层由元模型构成,为了防止模型出现严重的过拟合现象,元模型一般使用原理简单的模型,因此选择逻辑回归作为元模型。
2.1 基于Stacking集成学习的故障诊断模型构建
决策树通常作为二元分类器,并且不需要对特征进行归一化处理,能很好地识别非线性对应关系。决策树算法的核心过程就是将整个转子故障数据训练集作为整颗树的根节点,然后根据是否能够使得整个树的叶子结点纯度更高来决定当前节点是否需要分裂成子节点。
SVM是一种基于几何意义的非概率线性二分类模型,是定义在数据特征空间上的间隔最大的线性分类器。SVM不对数据概率进行建模,而是基于判别式找到最优的超平面作为二分类问题的决策边界。
逻辑回归是一种广义线性分类模型,使用似然度来区分回归结果,根据回归值和似然性的关系输出样本属于某个类别的概率。
在第一层的基模型训练中,以SVM模型为例进行说明,首先使用5折交叉验证对转子脱落故障训练集进行划分,接下来针对每一折里的训练子集训练一个SVM模型,并对测试子集进行预测,在5个模型全部预测完成后将预测结果进行合并。在转子脱落故障测试集上,则分别使用5个训练好的模型对全部测试集进行结果预测,并将5个预测结果进行取平均值的处理。同理,决策树也采取一致的步骤进行训练和预测。当基模型全部预测完毕后,将每个基模型的输出聚合,作为元模型的输入训练数据和输入测试数据。当两层模型都训练完毕时,即可得到最终预测模型,其中元模型输出的便是最终的诊断结果。Stacking集成学习框架流程如图5所示。
从图5可知,Stacking集成学习实质上是利用不同模型对特征提取能力的不同而使结果的准确率提高。
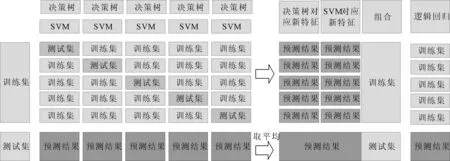
图5 Stacking集成学习流程图
2.2 基于Spark的集成学习算法并行化实现
随着转子监测数据不断积累,数据的处理速度将会限制故障的诊断效率。由于传统的单机模式难以达到处理海量数据的要求,引入Spark计算框架对算法实现并行化,通过多节点进行并行计算,从而及时高效地处理离线数据。
集成学习模型中的每个基模型相互孤立,可分别针对每个基模型的可并行化部分的训练来实现并行化。决策树并行设计流程如图6所示。
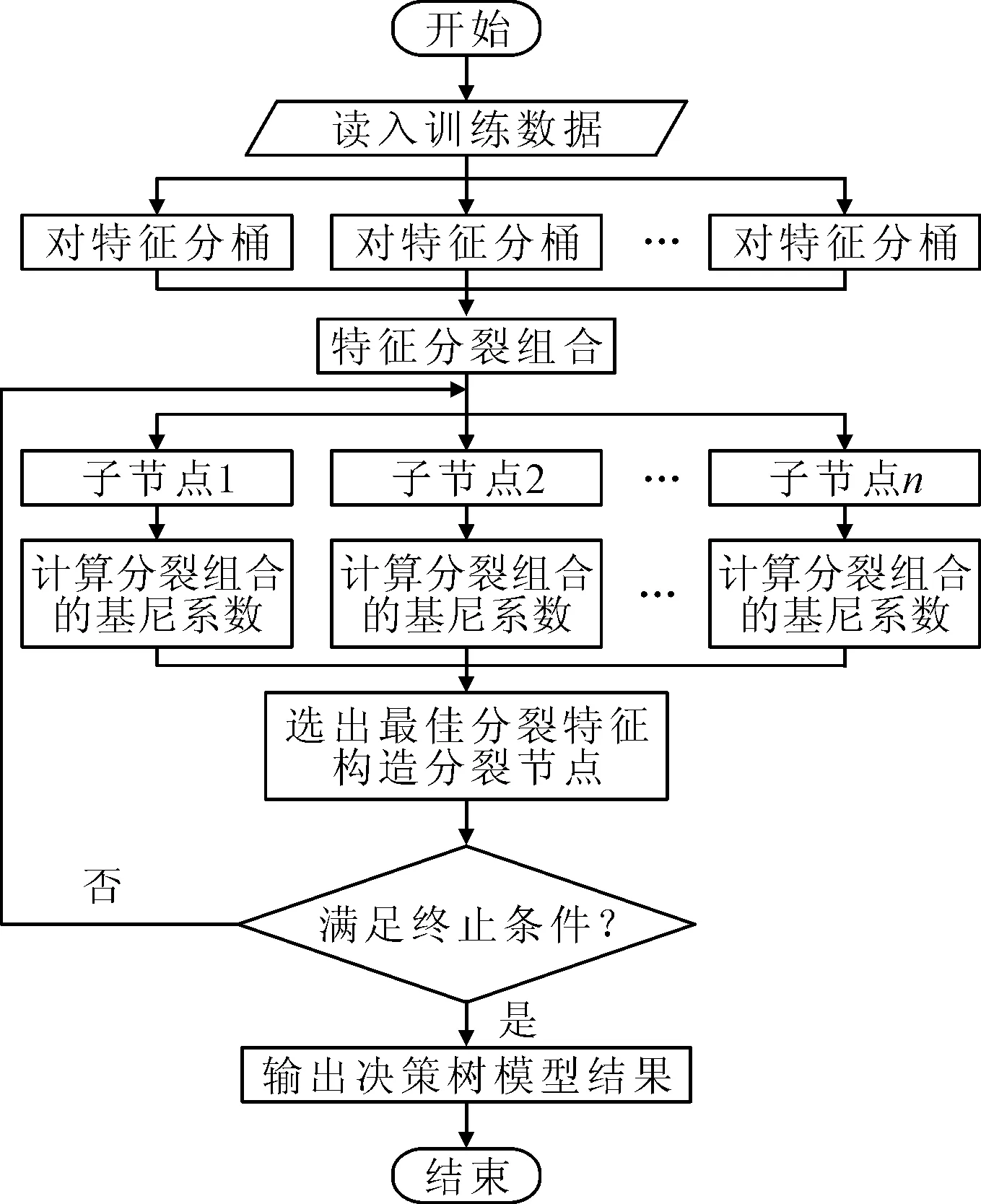
图6 决策树并行设计流程图
决策树并行化设计的思路如下:
(1)首先统计每个特征值出现的次数,之后根据次数进行排序,然后等频分割;
(2)根据分裂组合将节点分裂成左右子节点后,通过reduceByKey,将同一个节点的数据合并到一起,根据Gini系数并行计算每个特征的增益,并排序选出其中最小的特征进行分裂,进而得到最优分裂组合;
(3)每次迭代分裂节点的过程都将取出若干个节点,将一组节点并行分配到不同的Executor上处理;
(4)在达到建树的最大深度或分类增益小于设定阈值后停止建树,从而完成建模。
支持向量机并行流程设计如图7所示。其并行化设计的思路如下:
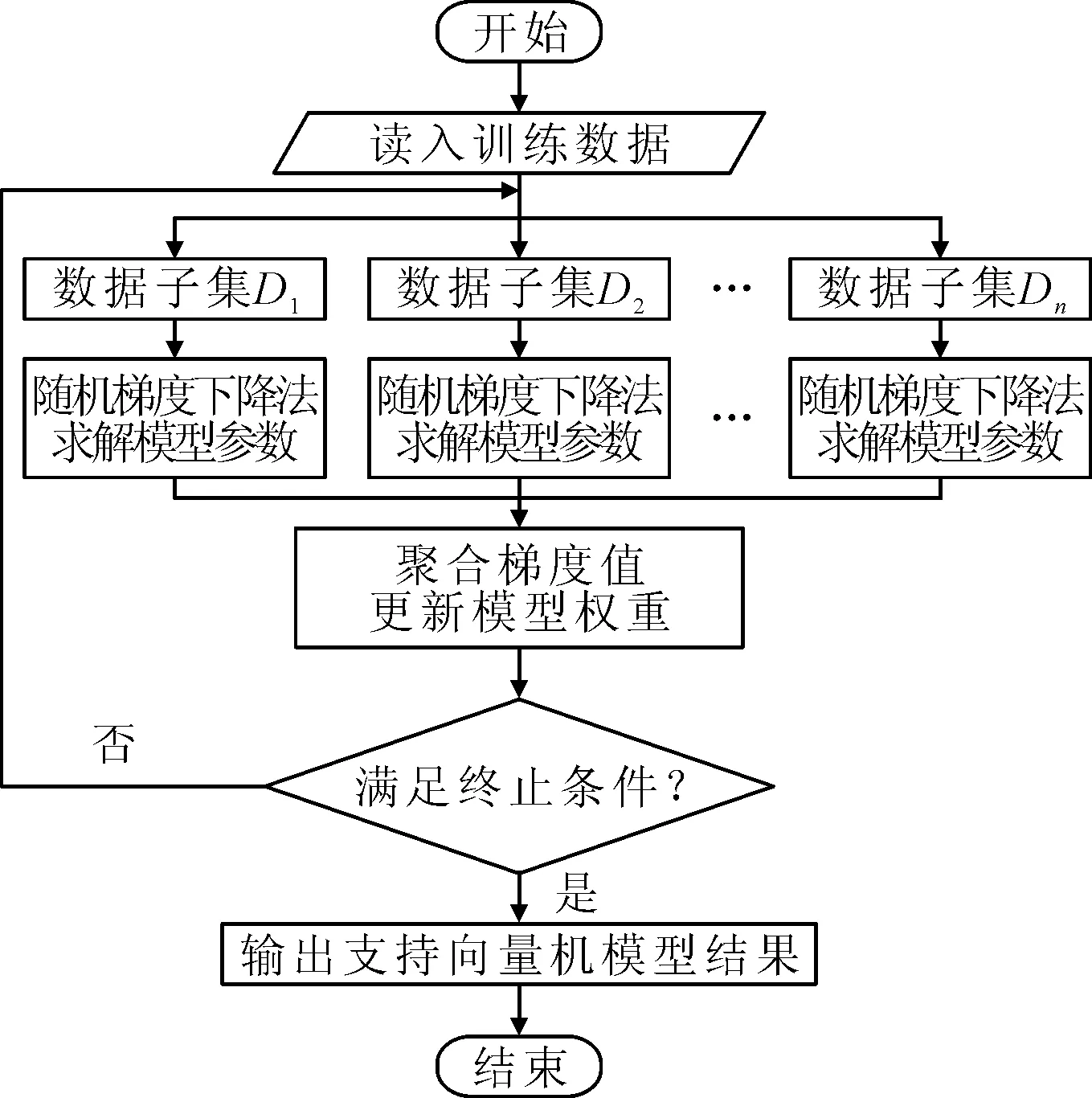
图7 支持向量机并行设计流程图
(1)首先读入转子故障数据集,并将其转换为RDD(resilient distributed dataset),通过map分片到各计算节点Worker上。初始化模型的参数;
(2)对读入的数据利用随机梯度下降来求解模型参数,以得到有故障征兆和无故障征兆所对应于的支持向量;
(3)每个Executor上对数据进行抽样得到数据子集,然后计算数据子集上的梯度值Gradient;
(4)利用treeAggregate的RDD操作实现梯度的分布式聚合计算,利用所得梯度,完成模型权重更新,至此完成模型的一次迭代;
(5)当模型的误差收敛或者到达迭代次数时,停止模型的训练,完成支持向量机模型的生成工作;否则对整个训练过程重复迭代。
逻辑回归并行化设计流程如图8所示。
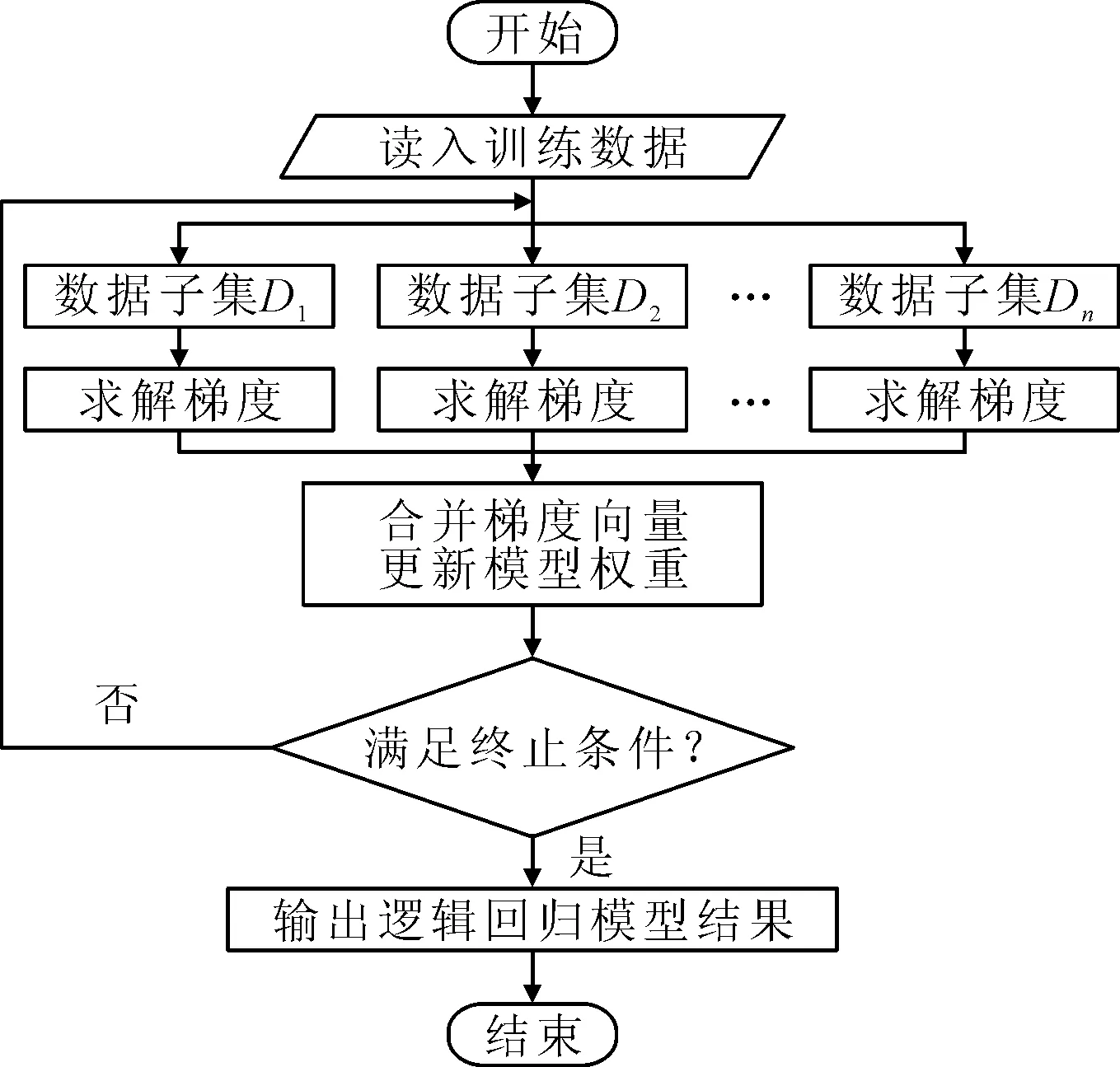
图8 逻辑回归并行化设计流程图
其并行化设计的思路如下:
(1)首先读入转子故障数据集,并将其转换为RDD,通过map分片到各计算节点Worker上。初始化模型的参数;
(2)对读入数据中的特征进行训练,利用随机梯度下降迭代求解梯度;
(3)实现分布式聚合计算,利用所得梯度完成模型权重更新,至此完成模型的一次迭代;
(4)当模型的误差收敛或者到达迭代次数时,停止模型的训练,完成模型的生成工作;否则对整个训练过程重复迭代。
通过对3个单模型的并行化设计,完成了集成学习模型的并行化设计。
3 故障诊断实验及结果分析
3.1 实验数据准备
经过时域和频域分析后提取的特征参数如表 1所示,序号1~23号特征为1个通道的特征参数情况,该转子系统共有 6个通道,序号24~32为联端和非联端所共有的特征,即得6×23+2×9=156维高维故障数据集。通过结合3种特征选择方法,最终从特征集中筛选出30个敏感特征,得到利于模型建立的优选转子故障数据集。在数据划分上,将转子故障数据集中的两台故障机组和3台非故障机组的数据作为训练集,余下的机组数据作为测试集。转子故障数据集组成如表2所示。
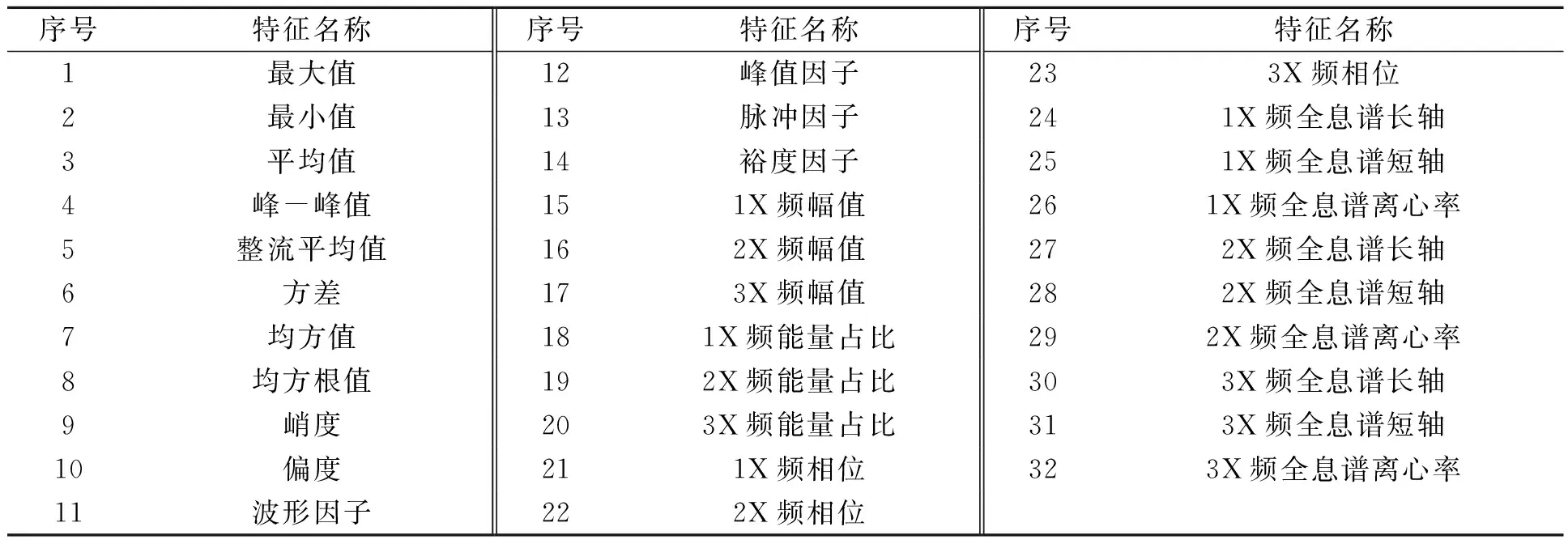
表1 各通道故障特征参数

表2 转子故障数据集组成表
3.2 实验及分析
进行两组对比实验,分别比较不同单模型和集成模型的效果以及并行化算法的加速比效果。
3.2.1 模型诊断能力比较
由于集成学习模型主要通过基模型完成对训练数据的信息提取,因此这里将对比基模型与集成学习模型的效果。在模型的选择上,采用决策树、支持向量机以及集成学习模型进行训练,并对测试数据预测其是否故障,来判断转子的状态。
以集成学习模型的试验过程为例进行说明:首先使用交叉验证对训练集进行划分,在每次实验中,使用训练子集来训练模型,并结合验证子集进行模型参数的优化,选出诊断效果最好的模型。然后将测试集输入已训练好的模型中得到结果。另外两种算法的实验过程同上,不再赘述。
为了准确地描述故障诊断模型的性能,需要使用相关指标对模型预测结果进行评价。分类效果指标的计算通常都基于混淆矩阵,如表3所示。
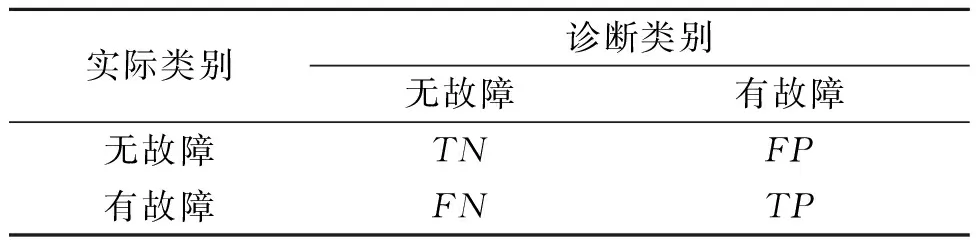
表3 混淆矩阵
矩阵中每个位置的单位均为数据量大小,其中,TN为被模型成功诊断识别的无故障征兆数据;FN为被模型错误诊断识别为无故障征兆类别的有故障征兆数据;FP为被模型错误诊断识别为有故障征兆类别的无故障征兆数据;TP为被模型成功诊断识别的有故障征兆数据。
准确率(accuracy)是在进行模型诊断时的一个常用指标,它反映地是在全部数据中诊断成功的数据占比,准确率的表达式为:
(3)
F1分数(F1-score)是针对两个概率的调和平均值,分别在所有诊断为有故障的样本中实际为故障样本的概率,与在所有实际有故障的样本中被诊断为故障样本的概率。其取值范围为0到1,值越大代表诊断能力越强。F1分数能综合评价模型的性能,其表达式为:
(4)
分别对模型进行实验,并针对诊断效果进行评价指标的计算,诊断效果如表 4所示。
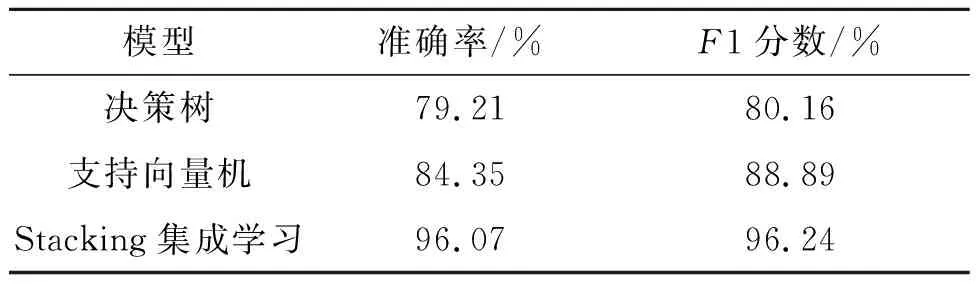
表4 模型诊断效果表
从表4可知,基于Stacking集成学习的诊断模型的故障识别准确率均高于单模型,平均准确率可达到96.07%。此外,在F1分数的度量下,Stacking集成学习模型的性能同样优于决策树和支持向量机,达到了96.24%。这说明相较于单模型,集成学习模型在分类效果和稳定性方面均具有优势,在转子部件脱落故障诊断上具有良好的诊断效果。
为了深入探索Stacking集成学习故障诊断模型能提高故障识别准确率的原因,对作为基模型的决策树和支持向量机的混淆矩阵输出进行分析,其混淆矩阵输出分别如表5和表6所示。
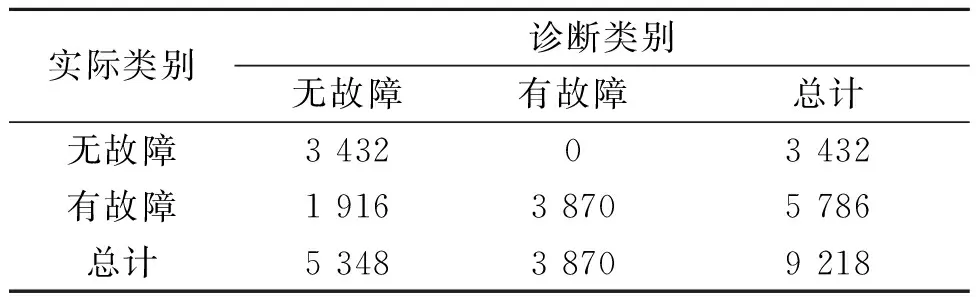
表5 决策树的混淆矩阵
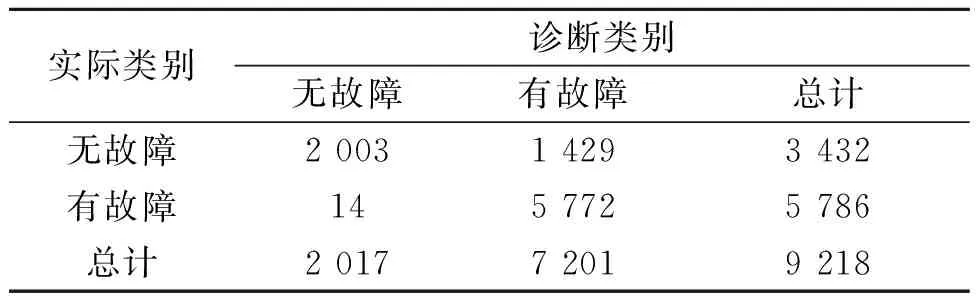
表6 支持向量机的混淆矩阵
从表5和表6可知,决策树诊断错误主要发生在将有故障征兆的样本错误预测为了无故障征兆的样本,而支持向量机诊断错误主要发生在将无故障征兆的样本错误预测为了有故障征兆的样本。从混淆矩阵中可以看出,当决策树对支持向量机诊断错误的样本进行诊断识别时,大部分样本都能正确诊断,而支持向量机相对决策树也是如此,两者在诊断识别能力上可以进行互补。集成学习正是通过综合两种算法各自对故障诊断识别的优势,使用逻辑回归作为元模型,对基模型输出的数据再次拟合,达到了提升效果的目的。
3.2.2 并行算法加速效果实验
在Spark集群环境下进行集成学习模型加速效果验证。本实验在5台服务器上进行测试,服务器之间通过千兆核心交换机来互联交换数据。
这里引入加速比这个衡量指标来度量算法的并行加速效率,其计算公式为:
σ=t1/tN
(5)
式中:t1为当集群中只有一个计算节点时的模型运行时间;tN为集群开启多个计算节点时的模型运行时间。
使用该指标能直观地衡量模型并行化的效果,加速比越大,说明对数据的并行处理性能越好。该集成学习模型在配置不同节点数的情况下,运行时间如表7所示。
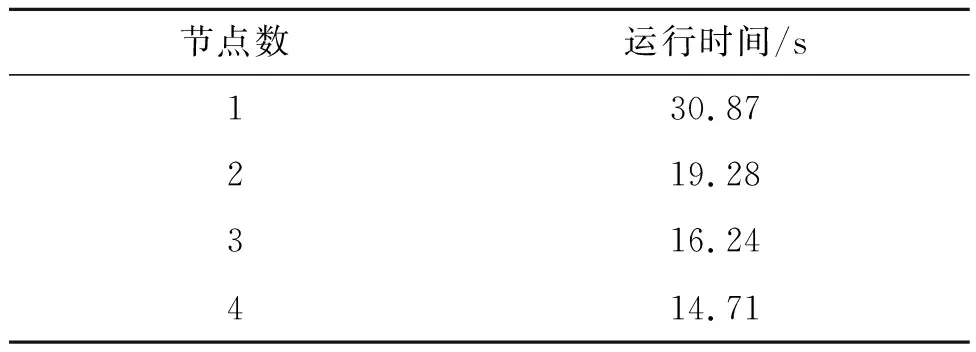
表7 模型运行时间对比
集成学习模型的加速比趋势如图9所示。
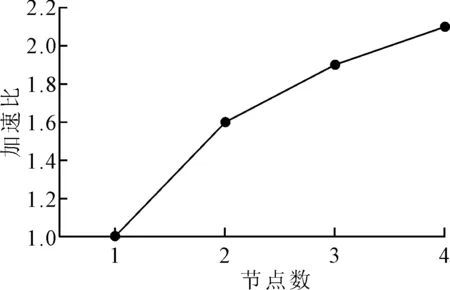
图9 加速比趋势图
由图9可知,以集群只有1个节点时的模型运行时间为基准,集成学习诊断模型随着工作节点数量的持续增加,其运行效率也在不断提高,从而基于Spark实现了良好的加速扩展性能。但与此同时可以发现,更多的工作节点数量也意味着更高的数据通信负担,额外消耗的增加使得模型的加速比并不能保持线性增加,而是表现出斜率呈现逐渐减少的趋势。因此,基于Spark对模型的加速效果不是无限制的,在实际应用中可以结合加速比的变化趋势,选择一个合适的节点数目。从上述分析可知,基于Spark进行并行化的Stacking集成学习模型能够有效地进行转子故障诊断的大数据分析处理。
4 结论
围绕转子部件脱落故障的诊断,结合机器学习和大数据相关理论和技术对其进行了深入研究,通过特征工程技术,采用时频域分析等方法提取出了故障数据集的相关特征。针对转子脱落故障诊断识别准确率的问题,提出并验证了一种基于集成学习模型的转子部件脱落故障诊断方法。并基于Spark计算框架,对模型进行了并行化的分析和设计,取得了一定的效果。
猜你喜欢
一重技术(2021年5期)2022-01-18
电子制作(2018年16期)2018-09-26
电子制作(2018年10期)2018-08-04
青年文学家(2016年34期)2017-03-31
科学与财富(2016年32期)2017-03-04
电子制作(2017年24期)2017-02-02
北京航空航天大学学报(2016年6期)2016-11-16
小星星·阅读100分(高年级)(2016年5期)2016-05-14
小星星·阅读100分(高年级)(2016年4期)2016-04-28
汽车电器(2014年5期)2014-02-28
