
KCPNet:张量分解的轻量卷积模块设计、部署与应用
2022-03-15 02:03王鼎衡赵广社姚满李国齐
西安交通大学学报 2022年3期
王鼎衡,赵广社,姚满,李国齐
(1.西安交通大学自动化科学与工程学院,710049,西安;2.清华大学精密仪器系,100084,北京)
卷积神经网络(CNN)是近年来重要的深度学习模型之一[1],卷积模块出众的特征提取能力使CNN得到了广泛的研究和应用。为了获取更好的数据识别与处理能力,CNN一直在向着深度更深、规模更大的方向发展,但在面向实际应用环境时,却不得不解决资源受限条件下的CNN模型部署问题。因此,对深度神经网络模型,尤其是深度CNN模型的压缩,成为了目前深度学习领域最为热点的研究方向之一[2-3]。在多种模型压缩方法中,模型裁剪、知识迁移、精细模块设计等方法[3]一般需要复杂的训练-压缩-再训练过程[4-5]或高训练成本的网络结构搜索[6-7]。张量分解凭借其坚实的数学理论基础[8],具有方便实现、压缩率可观等独特优势[9-10],还可以根据张量分解的具体形式直接设计轻量化的CNN模型并训练,完成后即可部署而无需进一步调整或压缩[11-12]。
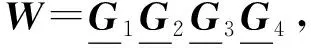
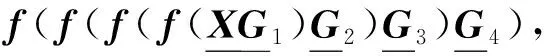

(a)原权重矩阵

(b)估计方式

(c)映射方式图1 张量分解压缩神经网络的两种形式Fig.1 Compressing neural networks by tensor decomposition in two formats
更重要的是,这些以映射方式得到的卷积模块帮助研究者们在应用方面取得了大量有实际意义的进展,尤其是以MobileNet模型[25]为代表的可分离卷积和以IGCV模型[26]为代表的分组卷积这两种典型卷积模块,几乎已经成为CNN应用领域的标准件。例如:基于可分离卷积,文献[4]结合裁剪方法实现了实时目标跟踪,文献[13]实现了高效的情感识别,文献[27]综合多级特征完成了高效的实例分割任务;围绕分组卷积,周云成等和杨贤志等分别开发了农作物实时识别和轻量级目标检测应用[28-29]。
然而,这些卷积模块虽然比原始卷积在理论上有更低的复杂度,但在面向部署应用时仍然存在一些实际效率方面的工程问题。例如:CUDA的官方库cuDNN直到第7版才对可分离卷积作出了有限的优化,其实际效率仍较差,文献[4]辅以裁剪方法才取得了较好的运行效率;文献[24]提到分组的瓶颈卷积在理论上虽有着明显的并行计算优势,但在cuDNN等通用计算框架上的实际效率较差,同时更多的特征图处理使其内存消耗反高于普通卷积。并且,除少数张量分解估计方式的应用[11-12]之外,其他应用方面的研究[4,13,25-29]对如何将张量分解映射方式得到的轻量卷积模块与具体硬件结合部署着墨甚少。
为了解决这些卷积模块在实际部署应用中内存消耗高、计算效率低的问题,本文在深入研究Kronecker CP(KCP)张量分解[30]的基础上,将KCP映射为一种以变通道可分离卷积为核心的瓶颈卷积模块(KCPNet)。分析了KCPNet的多种表现形式可对应于一些其他现存的张量分解卷积模块。在ImageNet大规模数据集上的实验表明,KCPNet相比其他瓶颈卷积模块能够同时达到较高效的空间和计算复杂度。基于CIFAR-10标准图像分类数据集的实验验证了KCPNet对普通卷积具有良好的压缩效果。结合GPU内存架构的特点给出了将KCPNet部署于嵌入式GPU的具体方法。结合KCPNet与深度相机开发了动态手势识别应用,测试结果表明,在消耗22 MB内存的前提下,可实现超过100帧/s的识别效率。
1 KCPNet轻量卷积模块设计
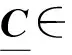
1.1 KCP分解
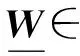
(1)

(2)

(3)
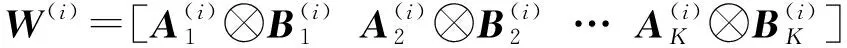

1.2 KCPNet轻量卷积模块
(4)
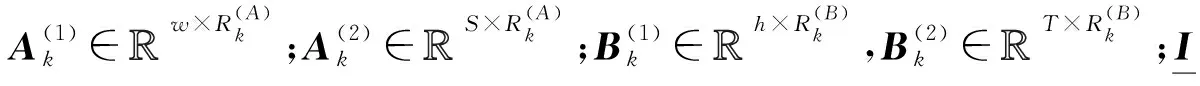
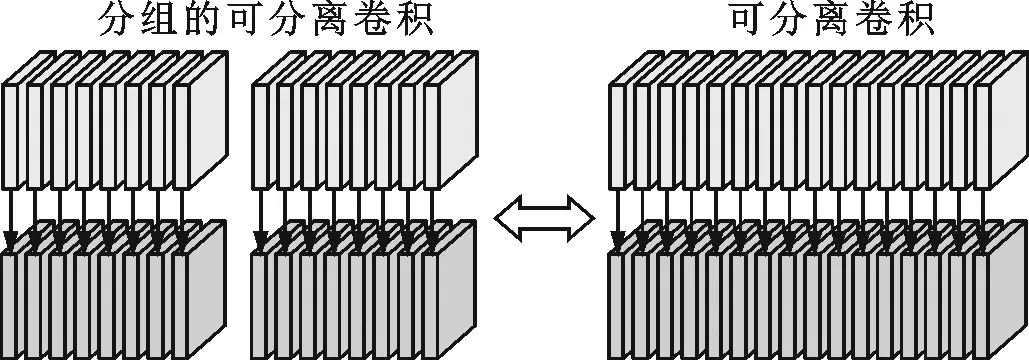
图2 一对一计算的可分离卷积Fig.2 Depthwise convolutions with one-to-one calculations
一般而言,可分离卷积相对于传统卷积能够极大地降低参数量和计算量[4]。例如:图3a的普通卷积与输入特征图对应计算后需要相加来得到一张输出特征图;图3b的可分离卷积在与输入特征图进行一对一的计算后无需相加。显然,可分离卷积缺少特征图通道融合的相关操作,因此经常与独立负责通道融合的1×1普通卷积搭配使用[13]。从张量分解的角度,可分离卷积与CP分解关系密切[19-20],这是因为CP的因子张量中只存在矩阵和超对角张量(非主对角线元素皆为0),而不存在其他张量分解中的高阶因子。例如,Tucker分解必然存在与原张量阶数相同的核,也就无法得到能够表示可分离卷积的因子。KCP的所有因子实际上皆为矩阵,故可自然映射为可分离卷积与1×1普通卷积。
(a)普通卷积
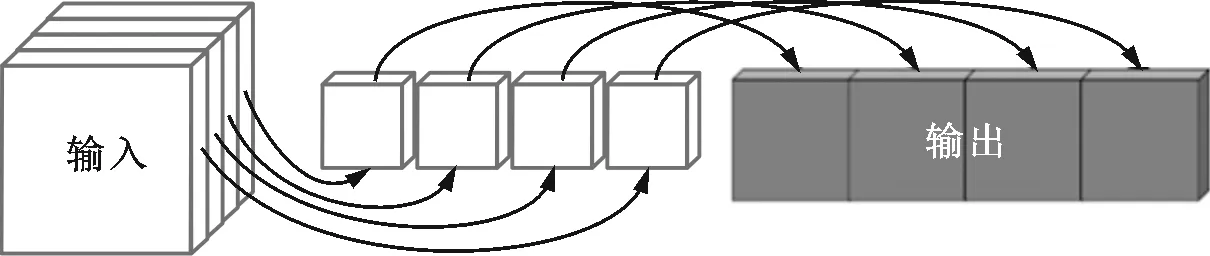
(b)可分离卷积图3 普通卷积和可分离卷积Fig.3 Normal convolutions and depthwise convolutions
于是,由式(4)可定义分块矩阵
(5)

(6)
2 KCPNet性能分析
2.1 KCPNet的可变表现形式
根据式(6),KCPNet在宏观张量层面的表现形式可描述为
(7)
式中※与○*分别表示普通卷积与可分离卷积。式(7)更易于和图4a所展示的KCPNet网络结构相对照,图中可见KCPNet呈现明显的瓶颈结构。
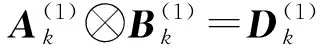
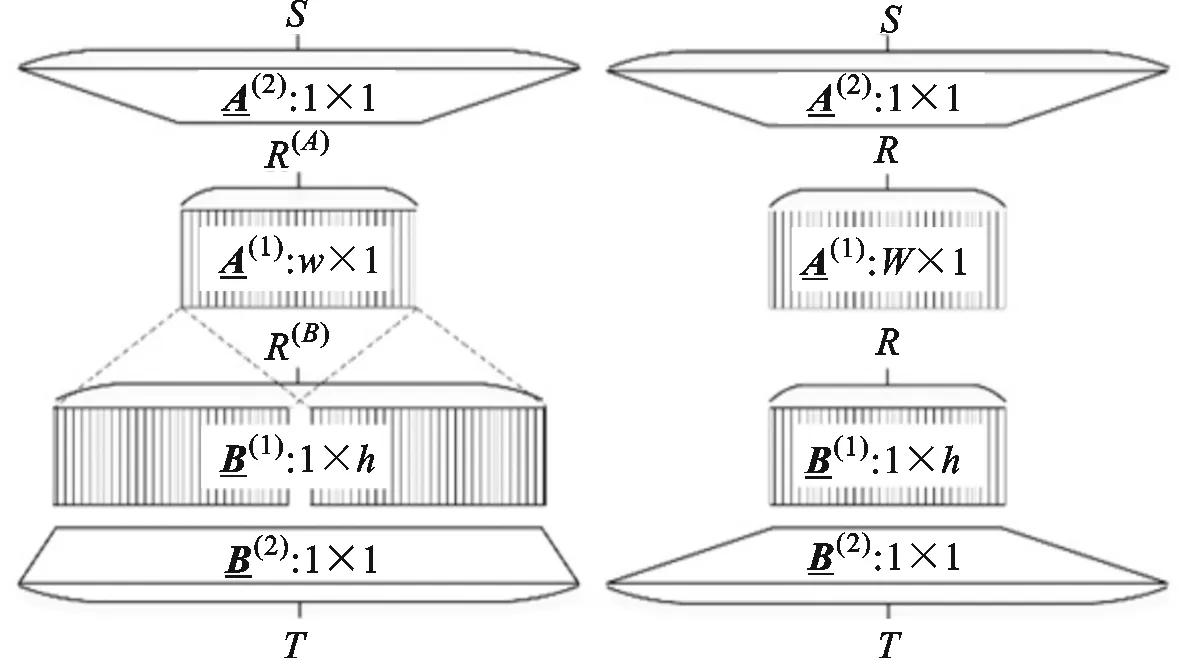
(a)KCPNet瓶颈结构 (b)非对称可分离卷积瓶颈结构

(c)分组卷积瓶颈结构 (d)普通卷积瓶颈结构图4 KCPNet及可转换的瓶颈结构Fig.4 KCPNet and its transformable bottleneck structures
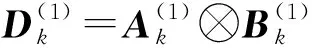
2.2 ImageNet图像分类对比实验
考虑到具备瓶颈结构的卷积模块发展历程,本小节基于ImageNet标准大规模图像分类数据集[32],以Tucker分解映射[21]的ResNet-50[22]和BT分解映射[23]的ResNeXt-50[24]为主要参考对象,在整体卷积神经网络总参数量相近的前提下,对比普通可分离卷积[20]、非对称可分离卷积[19]以及KCPNet的变通道可分离卷积之间的性能差异。所有网络的结构如表1所示。表中,对网络结构的描述遵循文献[22-24]的标准:“w×h,T,步长z”表示窗口尺寸为w×h、输出通道为T、步长为z(z=1则忽略)的卷积;多个卷积组成的block之后的乘数y表示该block重复堆叠y个;池化参数“w×h,步长z”指池化的窗口尺寸为w×h,池化步长为z(z=1则忽略);全连接的参数“M×N”为该全连接权重矩阵的尺寸。
由表1可知:ResNet的计算量虽小但其参数量却最大;ResNeXt和另外两个基于CP分解的模型虽然参数量稍少,计算量却超过了5×109;只有KCPNet能够在参数量较低时仍然保持较少的计算量,相对更能兼顾空间与计算复杂度;Tensor power网络和Speeding-up网络的通道数相同,虽然理论上后者的非对称卷积参数量更少,但由于绝大部分参数都由1×1卷积所贡献,故总参数量并无明显区别。

图5 KCPNet非对称可分离卷积改进Fig.5 Amelioration of the asymmetrical depthwise convolutions in KCPNet
需要注意的是,KCPNet的R(A)和R(B)之间的倍数关系δ决定了图4a中1×h卷积的数量倍于w×1卷积的数量,造成了KCPNet这种变通道可分离卷积在不同方向上的特征提取程度有异,从而影响整个CNN模型的识别精度。为了优化该特征采集不平衡的问题,需要对图4a的可分离卷积部分略作改进。具体地,可将第1层R(A)通道的w×1卷积改为R(A)/δ通道的w×1与R(A)/δ通道的1×h卷积,并对第2层R(B)通道的卷积作出类似处理,最后将这两层可分离卷积按w×1的通道与1×h的通道对应即可,如图5所示(图中δ=2)。改进之前,图5的KCPNet可分离卷积所输出的特征图更多地包含了1×h提取的高度方向特征,改进之后的输出特征图在高度和宽度方面的特征提取程度将变得均衡。这样的改进虽然使其不能严格符合式(7)的KCP分解数学形式,但在神经网络的实际应用中,能提供1%~2%的性能提升。
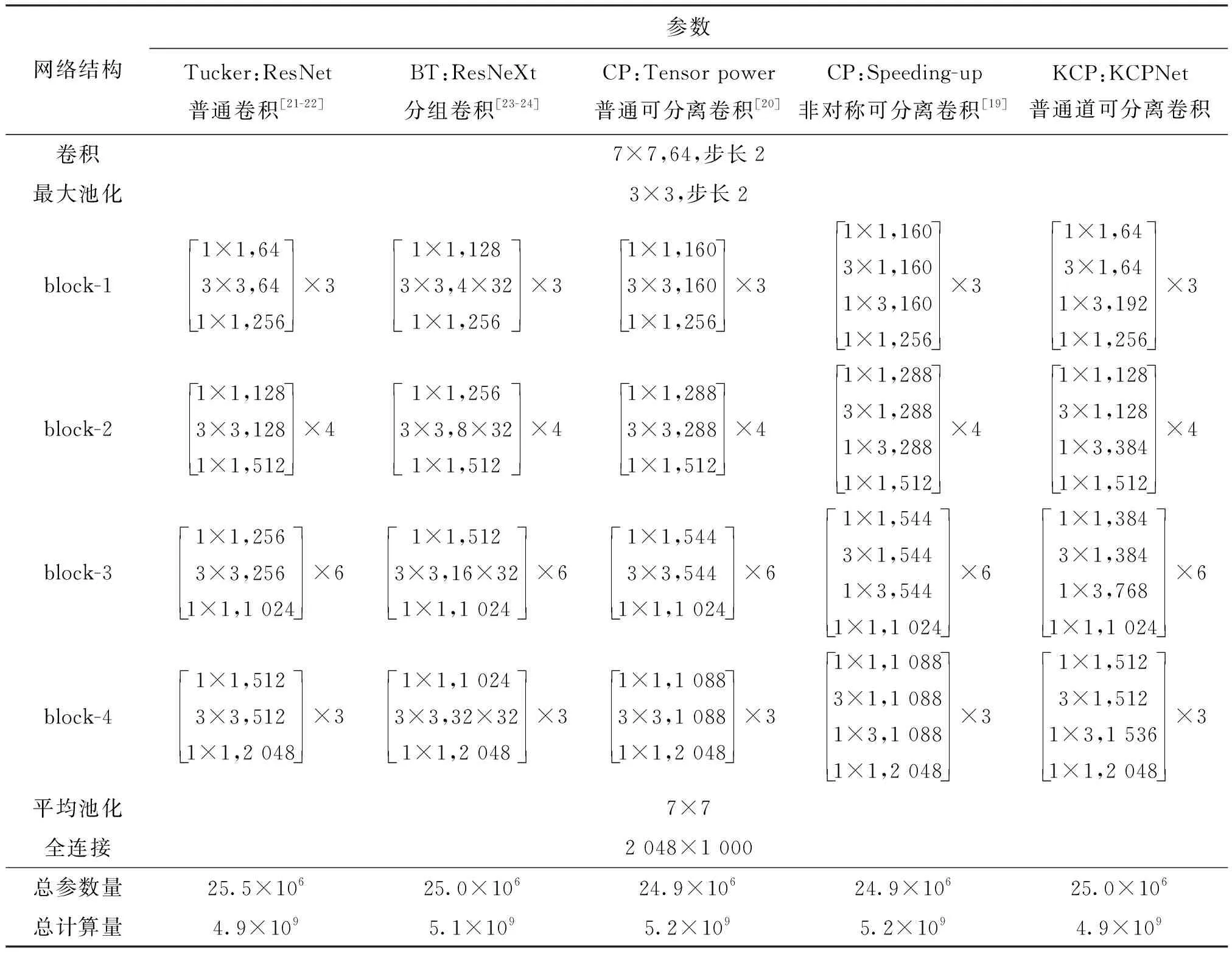
表1 ImageNet数据集图像分类对比实验的不同网络结构
ImageNet数据集图像分类对比实验结果如表2所示。可以看出,KCPNet与其他基于CP分解的高效卷积模块相比具有相当的精度,且相对于ResNet的精度损失十分有限(在0.5%以内)。虽然以BT分解映射的ResNeXt准确率最高,但其特殊的分组卷积架构在实际训练中运行效率最低,使其与实际应用部署之间仍有一定的距离,这一点与文献[24]结论相一致。
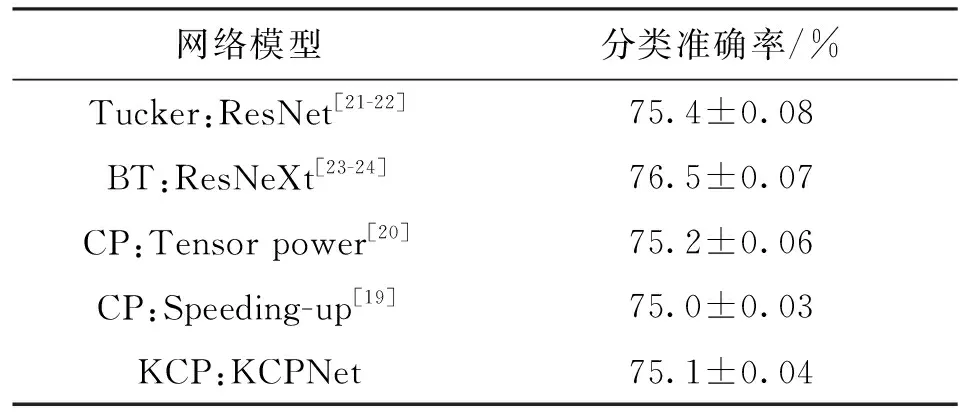
表2 ImageNet数据集图像分类对比实验结果
3 KCPNet卷积模块压缩与部署
3.1 CIFAR-10图像分类网络压缩实验
作为一种源自KCP张量分解的方法,KCPNet除了体现从张量结构到卷积模块的映射设计方式之外,同样能在传统卷积网络压缩的方面起到一定作用。本小节基于CIFAR-10标准图像分类数据集,以一个自设计的传统VGG卷积网络为参考,将其以KCPNet形式压缩,并与相关的Kronecker张量分解压缩方法KConv[14]和GKPD[15]进行对比,结果如表3所示。
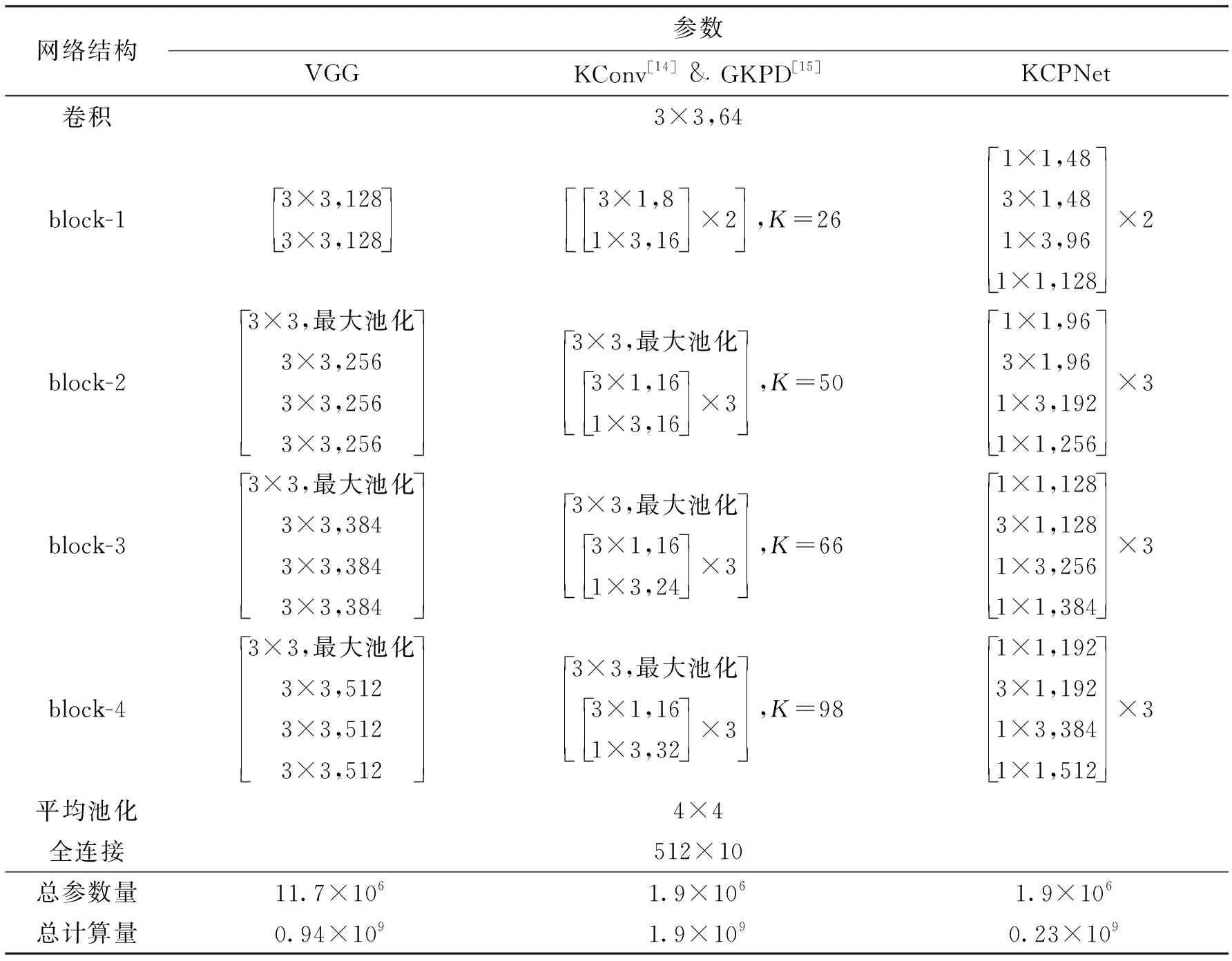
表3 CIFAR-10数据集图像分类对比实验的不同网络结构
由表3可以看出,KCPNet在计算效率上的优势十分明显,原因在于KCP张量分解本就是Kronecker张量分解的进阶方法,其结合了CP分解的特性从而使普通卷积可以转变为计算高效的可分离卷积。
VGG及两个网络压缩模型在CIFAR-10上的实验结果如表4所示。可以看出,KCPNet的精度损失在0.3%左右,KConv的精度损失超过1%,文献[14-15]的实验记录也表明KConv难以在CIFAR-10这类中等规模数据集上弥补精度损失。

表4 CIFAR-10数据集图像分类对比实验结果
结合本小节实验可知,KCPNet可将VGG压缩至原先的16.1%,且无明显精度损失,并可节省75.5%的计算量,相对基于Kronecker张量分解的KConv方法[14-15]有较明显综合优势。
3.2 可分离卷积的部署
KCPNet卷积模块的部署目标主要考虑为嵌入式GPU等通用并行计算设备。虽然目前的绝大多数深度学习平台都已经有了基于CUDA的接口,但对可分离卷积的实现并不十分高效,因为这些平台一般采取将整个模型的所有卷积模块转化为矩阵乘法来计算,以便于使用成熟的并行矩阵乘法。如此,将对GPU造成很大的存储压力[33],这也是目前深度神经网络训练往往需要大显存GPU的原因。另一方面,大多平台皆是基于CUDA开发,这就迫使相关具体应用只能选择NVIDIA的产品。

图7 可分离卷积在GPU内存架构上的部署Fig.7 Deployment of depthwise convolution on memory architecture of GPU
本小节在图6所示的GPU的3层内存架构下讨论可分离卷积的部署,采用跨硬件平台的OpenCL并行编程框架,具体方式与CUDA中cuDNN将卷积简单转化为矩阵乘法的方式相异。部署不考虑神经网络的训练过程,仅与前向推理计算相关。

图6 GPU内存架构Fig.6 Memory architecture of GPU
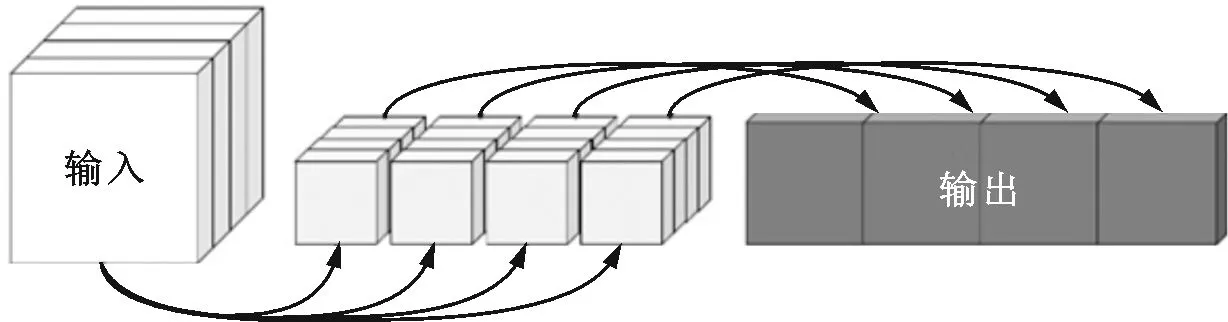
由图6可知,GPU内存架构具有多层次分组的特点,部署的原则为尽量平衡地将可并行的计算内容分配至各个工作组内。因此,如何对可分离卷积的计算过程进行分组分块即为部署的关键。由于GPU一般允许至多两个不同维度方向的分组,再考虑实际的卷积模块通道数往往远大于单个特征图的边长,故这里一方面设为按特征图通道进行分组,另一方面则将单个特征图分割为若干组。
以图7所示的3×1卷积为例,特征图通道数D=9,每张特征图有W=8、H=3。对计算进行分组:第一个方向的分组将每张特征图分为gp_1(1)、gp_1(2)和gp_1(3)共3个部分;第二个方向则在通道上进行,每3个通道为一组,记为gp_2(1)、gp_2(2)和gp_2(3);总工作组数为这两个分组方向交叉对应所得,即3×3=9组。如此,GPU的每个工作组内将被分配3块局部内存,每块局部内存负责3个通道的一部分特征图计算。从另一个角度来看,每张特征图的计算被分配至3个不同工作组内。由于绘图空间限制,故图7并未画出所有工作组,仅描绘了gp_2(3)分别与gp_1(1)、gp_1(2)和gp_1(3)交叉对应所得的3个工作组。每块局部内存之内的卷积计算可展开并行处理,每个独立的3×1卷积由一个执行单元负责计算。
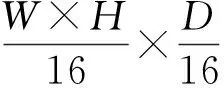
4 手势识别应用的开发
4.1 时间飞行深度相机
时间飞行(ToF)是一种较新的深度相机,其利用发射激光及其反射光之间的相位差对被摄物体的距离进行定位,并能得到被摄物体表面点云[34]。ToF技术目前已在一些特定场景中实际应用,如Melexis与BMW公司合作在汽车中控台部位安装ToF相关应用,以替代部分传统的接触式人机交互[35]。本文选用PMD公司生产的型号为pico-flexx的ToF深度相机[34],该相机具有体积小、功耗低的特点[36]。
4.2 数据集构建
ToF相机是带有光源的主动拍摄设备,会生成红外和点云两路不同的视觉数据。对于手势识别,手轮廓外的其余信息是多余甚至是有干扰的,而ToF相机可通过红外的光强阈值和点云的距离阈值互相滤波来得到较好的手势轮廓图像。本文实验中令同时满足距离大于500 mm的点云和灰度值大于110的红外数据作为手势轮廓中的有效像素,如图8所示。

图8 手势数据的互滤波获取方法Fig.8 Method for obtaining gesture data by cross filtering
为保证应用的健壮性和泛化性,对数据集进行扩充。在数据集容量方面,相对文献[37]进行扩充,训练集和验证集分别扩大至10 000和4 000幅手势轮廓。在手势轮廓的形状表达上,尽力做到多样化,如图9的第2行中,不仅以食指和中指表示数字2,也要考虑其他任何两根手指的组合。

图9 手势轮廓的形状多样化Fig.9 Variant shapes of gesture profiles

图10 手势识别应用软件架构Fig.10 Architecture of gesture recognition application software
4.3 应用软件开发
应用软件开发采取界面框架与驱动引擎相结合的两层架构,如图10所示。其中,上层界面以微软的WPF为开发框架,下层引擎以C++的DLL动态链接库形式进行开发,二者之间以DLL提供的C语言API为接口。界面框架的逻辑相对简单,以主界面框架为总体,下辖若干子功能界面框架,这些子功能包括了手势识别的界面和一些ToF镜头设置相关界面。ToF引擎稍显复杂,内部主要包含4部分内容:①与ToF相机相关的传感器监听模块,分别实时地接收相机端的红外与点云数据;②OpenGL引擎和OpenCL引擎联合实现镜头数据的显示,前者主要负责点云的显示渲染,后者则承担位图的一些快速计算;③以表3的KCPNet为基础的手势识别模块,负责将实时的手势轮廓位图数据送入KCPNet并将结果送于接口;④接口模块,由负责管理任务的控制器(ToF Controller)和纯C语言所包装的API接口(ToF Interface)组成。
该软件执行手势识别的流程可描述为:①红外监听器和点云监听器实时获取ToF相机的数据,二者都通过OpenGL引擎帮助生成各自的位图;②OpenCL以图8所示的方法快速生成手势轮廓图,并送于手势识别模块;③手势识别模块调用KCPNet对手势轮廓作出判断,这里KCPNet应以图7所示的方式部署于GPU上;④手势轮廓和手势识别结果通过接口模块同时送给上层的界面框架。本文完成的手势识别应用软件视觉效果如图11所示。
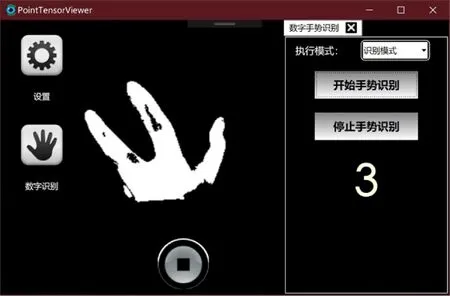
图11 手势识别应用软件截图Fig.11 Screenshot of gesture recognition application software
4.4 手势识别应用的效果
为了凸显KCPNet的优势,手势识别应用同时部署了表3的VGG和KCPNet两个模型,综合的识别效果对比如表5所示。可以看出,KCPNet相对于传统的VGG网络节省了大量的运行时内存占用。虽然KCPNet的理论计算复杂度低于VGG,但如图1所示,KCPNet实际上是将一个传统卷积模块分解映射为多层卷积的形式,从而使得网络模型的深度加深,这就必然带来更多层次的特征图处理过程。即便KCPNet在内存使用上可以通过内存复用或及时清理使其总运行时内存占用处于很低的水平,但更多的特征图处理过程却难以令KCPNet在真实运行时间上相比VGG产生优势。

表5 VGG和KCPNet的手势识别效果对比
从表5还可看出,KCPNet在面向实际应用时依旧有着可观的优势。首先,一些实际应用的数据集往往并不如ImageNet、CIFAR-10等有挑战性的标准数据集复杂,这使得KCPNet在网络模型压缩的角度更容易取得无损效果。在该手势识别应用中,KCPNet与VGG同样达到99.5%的验证集分辨率,而内存占用仅为后者的16.1%。KCPNet的网络模型压缩效果很好,在节省大量内存的基础上能够保证实际执行时间不受影响,手势识别应用的单次识别用时在9 ms左右,即运行速度超过100帧/s,能够达到动态即时识别的实用效果。
5 结 论
本文在KCP张量分解的基础上,将KCP的因子张量结构映射为变通道可分离卷积瓶颈结构,从而提出了一种轻量化卷积模块KCPNet。性能分析表明,所提的KCPNet能够转换为其他已有的多种张量分解卷积模块,在ImageNet上的实验验证了KCPNet能够兼顾空间和计算复杂度的高效性。在CIFAR-10上的CNN压缩实验表明,KCPNet可将其对应的VGG压缩至16.1%而无明显精度损失,同时可节省75.5%的计算量。针对KCPNet中的可分离卷积,提出了在嵌入式GPU上部署的方法,使KCPNet对CIFAR-10的识别效率达到100帧/s。围绕ToF深度相机开发了手势识别应用,该应用识别率可达99.5%,内存占用22 MB,识别效率超过100帧/s。总之,KCPNet相比已有卷积模块,具有最优的复杂度和可观的压缩能力,所提的部署方法在实际内存占用和计算耗时方面皆有较高效率,体现了在实际应用中的高效性能优势。
猜你喜欢
科技信息·学术版(2022年8期)2022-02-25
北华大学学报(自然科学版)(2021年1期)2021-03-12
智能计算机与应用(2020年10期)2020-11-26
电子技术与软件工程(2020年18期)2020-02-02
红领巾·萌芽(2019年9期)2019-10-09
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
小学阅读指南·低年级版(2017年6期)2017-06-12
电脑爱好者(2015年21期)2015-09-10
数学大世界·小学低年级辅导版(2010年9期)2010-09-08
