
基于深度学习的直觉模糊集隶属度确定方法
2022-03-14 08:09那日萨
运筹与管理 2022年2期
那日萨, 孔 茸, 高 欢
(大连理工大学 经济管理学院,辽宁 大连 116024)
0 引言
随着社会进步和科技发展,人们越来越希望通过精确可靠的方式或借助科学计算工具来处理模糊现象,模糊集(Fuzzy Sets,FS)的提出突破了经典集合中二值逻辑的约束,使计算机在外延不分明的模糊问题中也能发挥作用,直觉模糊集(Intuitionistic Fuzzy Sets,IFS)在模糊集的基础上加入了犹豫度的概念,对模糊现象具有更精确的表示能力。近年来IFS相关研究中,隶属度、非隶属度的确定始终是一个重要问题[1,2],并直接影响着IFS的应用范围。
已有方法虽然考虑了研究问题和数据分布[2~4],但是大多采用模拟数据验证方法有效性,极少应用至实际数据。大数据时代使实际数据比以往更易获得,数据类型也从结构化向非结构化转变,能够应用非结构化数据的隶属度确定方法更易于在实际问题中发挥作用,更加符合现实需求和技术趋势。
近年来,深度学习在模式识别、文本挖掘等研究中广泛应用,它可以从数据中自动学习特征和隐藏结构。IFS隶属度、非隶属度和犹豫度确定问题与深度学习处理分类问题时前几步的运算过程相似,前者是通过某种方式确定样本属于IFS三种关系证据的程度,后者则是通过深层神经网络构建样本与类别之间的映射关系,所以IFS隶属度、非隶属度和犹豫度确定问题本质上可看作一种“分类问题”,与深度学习的思想一致。
本文提出一种针对非结构化数据的新方法,基于深度学习确定IFS隶属度、非隶属度和犹豫度。首先根据数据特点和IFS具体含义设计模型结构,然后在有标签数据上确定超参数并训练,最后使用成熟的模型计算无标签数据在IFS上的隶属度、非隶属度和犹豫度。本文在文本数据集上进行实验证明了方法可行性,新方法突破了传统方法的技术和思维局限,为IFS隶属度确定问题开辟了新的思路。
1 相关研究综述
1.1 直觉模糊集相关研究
直觉模糊集[5,6]由Atanassov于1986年提出,是对Zadeh模糊集理论最有影响的扩充和发展。FS可以描述“亦此亦彼”的模糊概念,IFS在FS隶属度基础上,提出了非隶属度和犹豫度,可以进一步描述“非此非彼”的中立状态,所以IFS可以更准确、全面地反映客观世界的模糊现象。
在IFS的应用中,隶属度、非隶属度、犹豫度的确定至关重要,也是当下的研究热点与难点。雷阳等[7~10]对IFS非隶属度确定进行了许多探索:基于模糊统计提出了三分法非隶属度确定方法,对论域模糊划分,将界点的概率分布作为隶属度函数;针对元素具有属性优先特性的问题,提出了对比平均法和绝对比较法两种非隶属度确定方法;针对确定多属性优先次序问题,提出了基于优先关系定序法的非隶属度确定方法;总结了规范化确定非隶属度的过程,理论证明了方法的正确性并进行了算例分析,但其所提方法对数据结构均有要求,算例规模小且没有实际数据验证。邢清华和刘付显[11]基于证据理论,通过分析信任函数、似然函数与隶属度函数、非隶属度函数的互通性,建立了隶属度函数、非隶属度函数确定模型,但是仅在数值型数据中进行了实验。魏志远和岳振军[12]将IFS应用于情感分析,将积极、消极情感词在句中出现的频率作为隶属度、非隶属度,通过I-IFHA混合平均算子计算句子情感倾向,但是该方法仍是频率统计方法。Zhang等[2]将IFS与在线评论情感分析相结合,应用到电商排序中,采用专家评分法确定隶属度、非隶属度。综上所述,在IFS隶属度确定问题中,普遍存在主观性强、缺乏一致性等问题,而且应用研究大多采用仿真实验,或使用的实际数据规模较小。随着大数据时代到来,基于实际数据确定IFS隶属度、非隶属度、犹豫度成为当前急需解决的科学问题。
1.2 深度学习相关研究
深度学习模型能够从数据中自动学习输入信息与目标输出之间复杂的非线性关系,它从模仿人脑的信息处理机制发展而来,而人脑思维擅长处理模糊信息,很多研究将深度学习和模糊理论结合。Hatri等[13]将深度学习与模糊逻辑结合,使用模糊逻辑适应性调整网络参数来降低过拟合概率、跳出局部极小值,该方法被用于城市交通事故监测的仿真实验中。Deng等[1]使用模糊深度神经网络将信息的模糊表示和神经元表征融合,增强了模型表示数据不确定性的能力,并在图像分类、金融预测等实际任务中验证了模型有效性。
尽管深度学习与模糊逻辑结合取得了应用进展,但是尚未见到利用深度学习构建IFS的相关研究。本文提出利用深度学习确定IFS隶属度、非隶属度和犹豫度的新思路,这有利于解决隶属度确定过程中主观性强和标准难以统一等问题,另外深层神经网络的学习能力也使确定的隶属度、非隶属度和犹豫度更加贴近真实情况。
2 直觉模糊集的定义及问题描述
2.1 直觉模糊集的定义
直觉模糊集[5,6]的定义如下:设X是一个给定论域,则X上的一个直觉模糊集A表示为式(1),其中μA(x),γA(x)是x在A上的隶属度、非隶属度,犹豫度πA(x)=1-μA(x)-γA(x),μA(x),γA(x),πA(x)满足式(2)条件。
A={
(1)
(2)
μA(x)表示x隶属于A的程度,γA(x)表示x不隶属于A的程度,πA(x)表示对x是否隶属于A的犹豫程度。论域X上的直觉模糊集A可简记为A=
2.2 问题的描述
现实中的困难是IFS隶属度、非隶属度和犹豫度的数据很难获得,但与此相关的带有类别标签的数据则可以获得。在本文研究中,数据样本集X由N条数据x1,x2,…,xN构成,即X={x1,x2,…,xN},并且在X上存在一个对应具体语义的直觉模糊集A,其形式如(1)、(2)所示,μA(xi),γA(xi),πA(xi)表示xi在A上的隶属度、非隶属度、犹豫度。在X中有N1(N1 类别标签实际上是传统集合的一种形式,可以将类别标签理解为IFS的极端形式。设类别标签具有3个水平,即{Y1,Y2,Y3}。根据A的语义,选出距离A最近、最远的标签,假设分别为Y1,Y3,然后确定语义距离居于Y1,Y3两者中间的标签,设为Y2。于是可以理解为,在直觉模糊集A上,标签为Y1的样本μA(xi)=1,πA(xi)=0,γA(xi)=0,标签为Y2的样本μA(xj)=0,πA(xj)=1,γA(xj)=0,标签为Y3的样本μA(xz)=0,πA(xz)=0,γA(xz)=1,如式(3)~(5)所示。 μA(xi)=1,πA(xi)=0,γA(xi)=0,∀yi=Y1 (3) μA(xj)=0,πA(xj)=1,γA(xj)=0,∀yj=Y2 (4) μA(xz)=0,πA(xz)=0,γA(xz)=1,∀yz=Y3 (5) 这样有标签数据x的标签y就可以表示为A上的μA(x),πA(x),γA(x),然后通过构建深度学习模型,在有标签数据上训练,使用训练好的成熟模型将无标签数据在A上的隶属度、非隶属度和犹豫度计算出来。 为了针对文本特性设计模型结构,使模型训练后可用于确定文本数据的隶属度、非隶属度和犹豫度。首先根据文本长度n和词向量维度d构建n×d维的输入层,然后使用卷积神经网络(Convolutional Neural Networks,CNN)和长短时记忆神经网络(Long Short-Term Memory,LSTM)结合的CNN-LSTM模型学习文本到输出的映射关系,最后通过全连接层得到代表隶属度、非隶属度和犹豫度的输出,模型结构如图1所示。 图1 CNN-LSTM模型结构 输入层将x用向量Vx表示,Vx既是对输入的描述,也是模型训练的基础。文本表示中,分布式词向量[14]是较为成熟的方法之一,它将每个词语表示为一个d维向量。例如当xi∈X代表一句话,句中有ni个词语,那么这句话可以表示为(ni,d)维向量,可理解为ni×d维矩阵。输入层既要满足模型的结构要求,又要充分表示数据集X和直觉模糊集A中包含的信息。 3.2.1 卷积神经网络 卷积神经网络(CNN)是一类包含卷积计算、以多层感知机为基本结构的深层神经网络[15],它能学习数据的局部特征。CNN的核心在于卷积层和池化层的结构与参数设计,以及针对不同问题的灵活组合方式。文本数据适合使用1D卷积,1D卷积能够学习句中相邻词语间的关联关系。本文使用的1D卷积由一层卷积和一层池化构成,卷积计算公式如式(6)所示,X代表输入层,W代表卷积核,即卷积运算的权值,⊗代表卷积计算,b代表偏置向量,f代表激活函数,C代表输入层经卷积计算后得到的隐层特征。f采用relu函数,如式(7)所示,可以增加网络的非线性能力。 C=f(W⊗X+b) (6) (7) (8) 3.2.2 长短时记忆神经网络 长短时记忆神经网络(LSTM)[17]擅长处理序列数据,文本属于一种序列数据,词语在句中出现的先后次序存在关联。LSTM在循环神经网络(Recurrent Neural Network,RNN)的基础上,增加了记忆控制单元,避免了长序列中反向传播梯度消失和梯度爆炸问题,使模型学习到相距较远的词语依赖关系。 (9) (10) (11) (12) (13) dt=ot×tanh(Cellt) (14) 使用CNN可以学习文本中相邻词语间关系,同时保留强特征、减少噪音信息,使用LSTM可以学习文本中相距较远的词语间关系。CNN-LSTM模型将两者结合,学习局部特征和全局特征,从而更准确地拟合文本在直觉模糊集上隶属于、非隶属于和犹豫的程度。 为了使模型的最终输出代表x在直觉模糊集A上的隶属度μA(x)、非隶属度γA(x)和犹豫度πA(x),使用全连接层将输出维度固定为3,分别对应γA(x),πA(x),μA(x)。然后使用softmax函数归一化,使其满足IFS规范,softmax函数如式(15)所示,k为向量维度,xi代表向量中第i个分量。 (15) 本文使用百度“用户评论情感极性判别”大赛公布的文本数据集及情感极性标签,数据集共包含82025条文本评论,每条评论对应“消极”、“中性”、“积极”三种情感标签中的一个。数据集共有消极标签评论12240条、中性标签评论4187条、积极标签评论65598条。数据集涉及医疗服务、物流快递、金融服务、旅游住宿、食品餐饮五个领域,数据分布如表1所示。 设定直觉模糊集A的具体含义为“积极评论”,X为文本数据集,标签的取值范围是{消极,中性,积极}。根据A的语义,距离其最近的标签为Y1=积极,最远的标签为Y3=消极,居于两者中间的标签为Y2=中性。因此由式(3)~(5),将标签转换为A上的隶属度、非隶属度、犹豫度。 表1 实验数据集 对评论分词、去停用词和词向量转换,通过word2vec工具构建词向量,取数据集中评论的平均长度n=100作为输入定长。将医疗服务、物流快递、金融服务、旅游住宿四个领域数据记为Corpus1,用于确定模型超参数和训练,将食品餐饮领域数据记作Corpus2,用于检验模型稳健性。将Corpus1随机划分为训练集、验证集和测试集,训练集、验证集、测试集的数据量之比为8:1:1。 (16) (17) (18) (19) (20) CNN-LSTM模型中的超参数将影响神经元数量和神经元之间的连接,通过实验调节模型超参数。根据已有研究[18,19],对模型影响较大的超参数有CNN中卷积核的宽度kernel、卷积层的输出维度filter、LSTM层的输出维度hidden,以及全连接层随机失活的神经元比例dropout,各超参数的取值范围如表2所示。 表2 超参数的取值范围 将超参数的初始值设置为kernel=3,filter=32,hidden=64,dropout=0.5,然后在取值范围内调节,每次仅使单一超参数变化,其余不变。评价指标采用Pw、Rw、F1w,实验结果如图2~5所示。从图中可得,kernel=2,4,filter=16,64,hidden=128,dropout=0.1,0.3,0.5,0.8时,F1w大约到达最高点。将各参数在新的取值范围内调参,共有2×2×4=16种参数组合,采用网格搜索法实验,取F1w表现最优的参数组合,即kernel=2,filter=16,hidden=128,dropout=0.8。 图2 kernel调参结果 图3 filter调参结果 图4 hidden调参结果 图5 dropout调参结果 4.4.1 模型输出结果介绍 将Xno_label作为测试集,使用训练好的模型计算x∈Xno_label在含义为“积极评论”直觉模糊集A上的隶属度、犹豫度、非隶属度,部分结果如表3所示。从表中可以看出模型较好地确定了样本隶属于A的程度,文本1,2情感积极,隶属度较高;文本2中有部分中性犹豫,“太_了”、“额度不太高”,相比于文本1犹豫度、非隶属度更高;文本3情感更偏向中性,其犹豫度较高;文本4,5情感消极,非隶属度较高;文本5中有少量积极情感,“服务态度很好”,相比于文本4非隶属度更低,犹豫度和隶属度更高。 4.4.2 对比实验及模型稳健性 使用CNN、LSTM、CNN-RNN和支持向量机(Support Vector Machine,SVM)在相同的数据上训练,CNN、LSTM、CNN-RNN输入与CNN-LSTM相同,SVM使用OVO(One Versus One)多分类模式,分别计算各模型的评价指标Pw、Rw、F1w。如表4所示,CNN-LSTM的F1w值最高,即综合来看CNN-LSTM优于其他模型。 模型计算的隶属度、非隶属度、犹豫度的优劣是难以评价的,这与比较标准、实际情景等都有关系,但是各模型Pw、Rw、F1w值可以反映其学习文本信息的能力优劣,可以评价模型对隶属度、非隶属度相对大小的计算准确性和识别能力,F1w值越大,模型综合学习能力越强,确定的隶属度、非隶属度和犹豫度越准确。 表3 计算结果(部分) 表4 各模型评价指标 使用优化好超参数的模型在Corpus1∪Corpus2数据集上训练和测试,评价指标为Pw=0.9479,Rw=0.9622,F1w=0.9549,说明该模型在新领域数据集上也展现出较好的性能,具有一定的扩展性和稳健性。 在IFS理论与应用研究中,隶属度、非隶属度和犹豫度的确定方法始终是一个研究热点与难点,该问题直接影响着IFS应用和模型可扩展性。随着大数据时代到来,非结构化数据比以往更易获得,文本就是其中一种,相比于其他数据,文本中包含更多模糊信息。本文提出基于深度学习的IFS隶属度、非隶属度和犹豫度确定方法,并将该方法应用至文本数据集。根据文本特点构建CNN-LSTM模型,经训练后模型计算的隶属度、非隶属度和犹豫度与文本实际含义相符。CNN-LSTM的F1w值优于CNN、LSTM、CNN-RNN和SVM,说明CNN-LSTM在学习文本信息方面优于其他模型。在新领域文本数据Corpus2上,CNN-LSTM表现出较好的稳健性和扩展性。 本文具有一定的理论与实践意义: (1)理论意义:提出一种基于深度学习的IFS隶属度、非隶属度和犹豫度确定方法,为IFS相关研究开辟了新的思路。 (2)实践意义:通过构建CNN-LSTM模型将该方法应用至文本数据,为进一步应用至其他非结构化数据提供了参考。3 直觉模糊集隶属度的深度学习方法构建
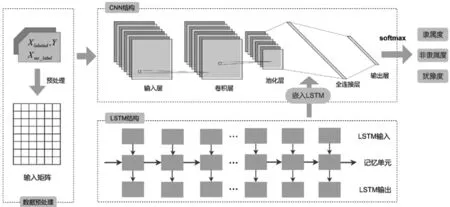
3.1 基于IFS的输入层
3.2 CNN-LSTM网络结构
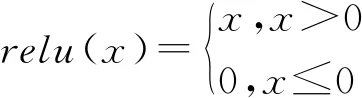

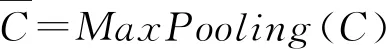

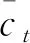
3.3 IFS隶属度的确定
4 实例研究
4.1 实验数据及预处理

4.2 实验评价指标
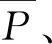


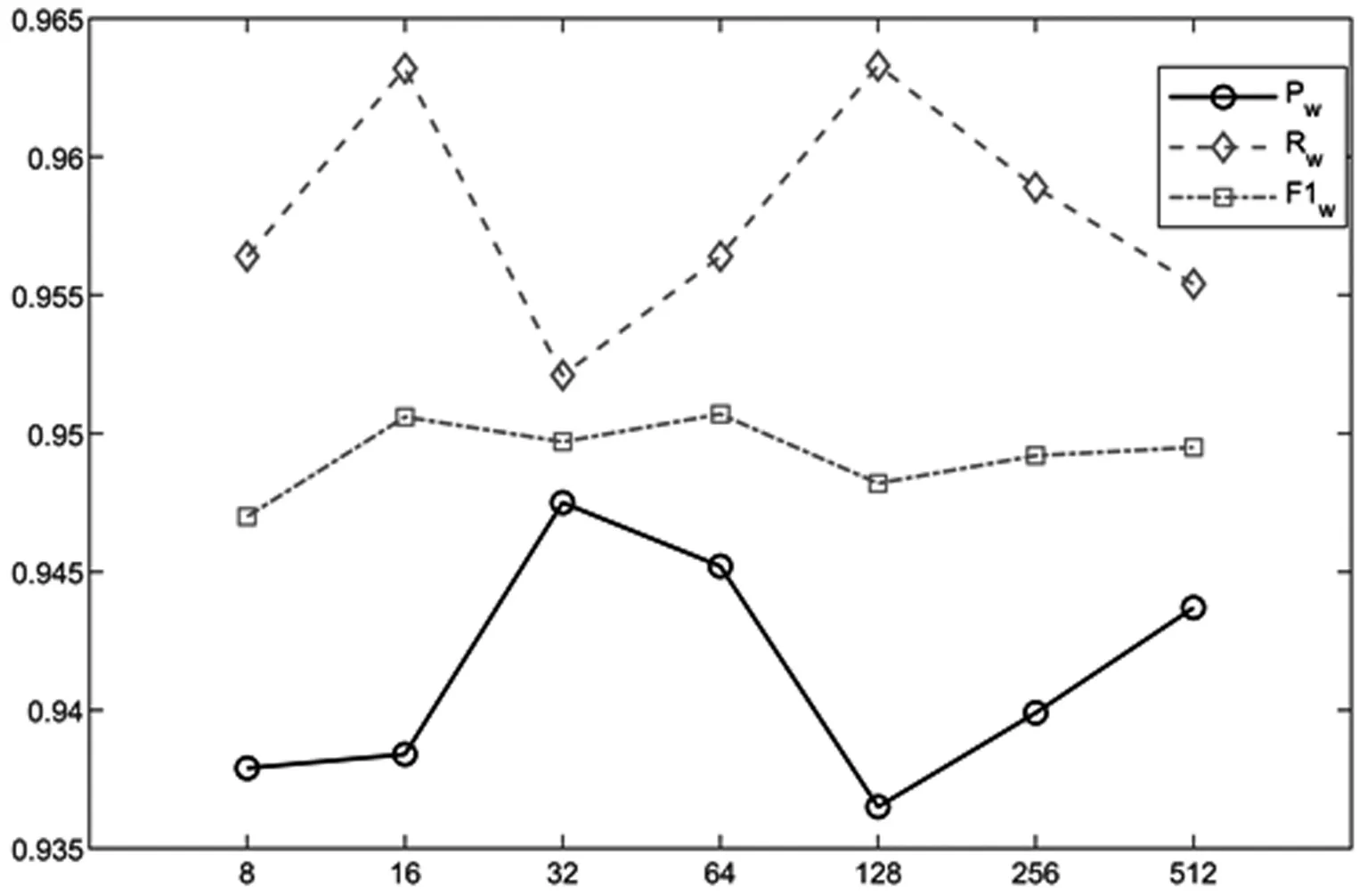
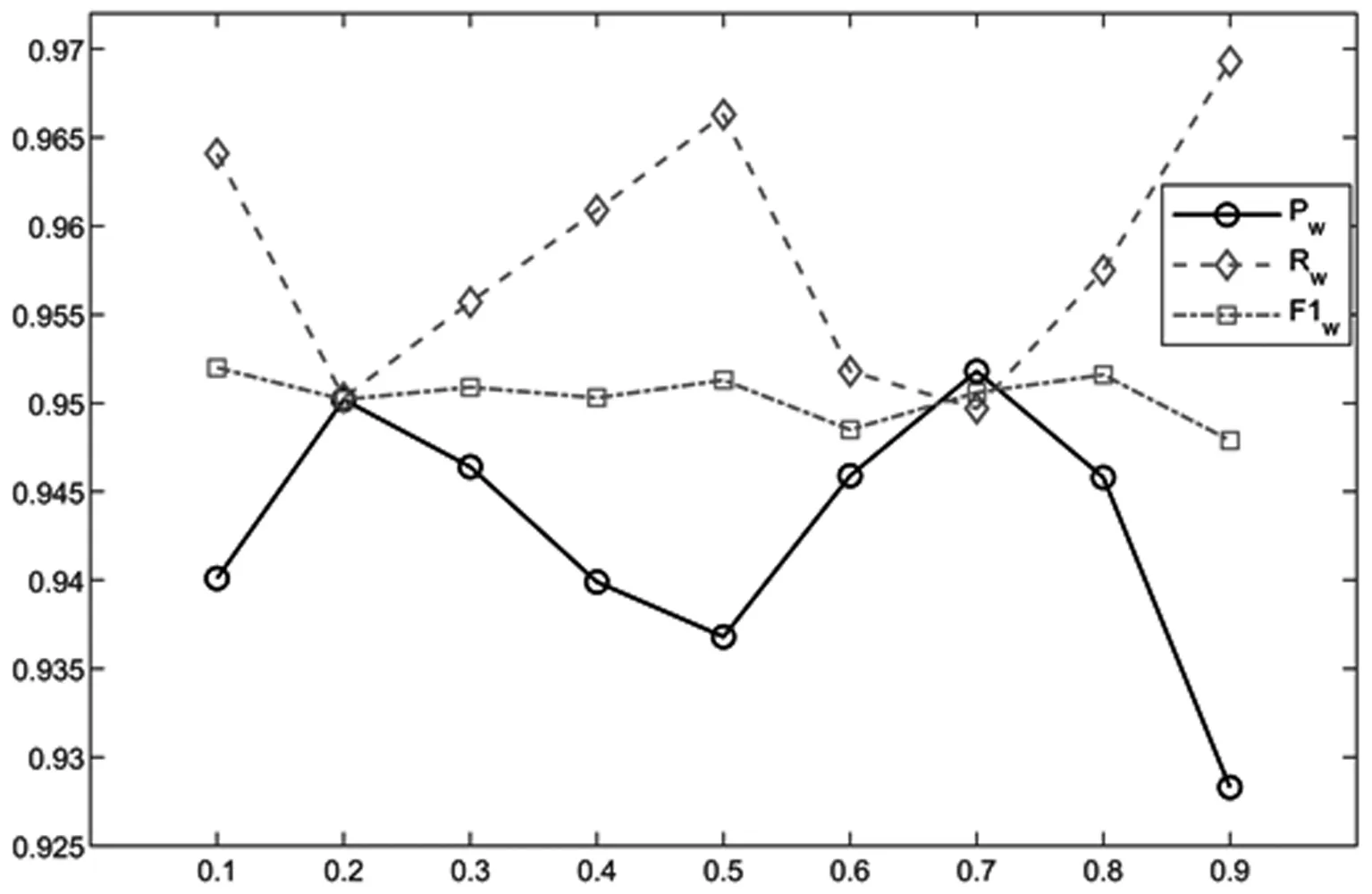
4.3 实验参数设置



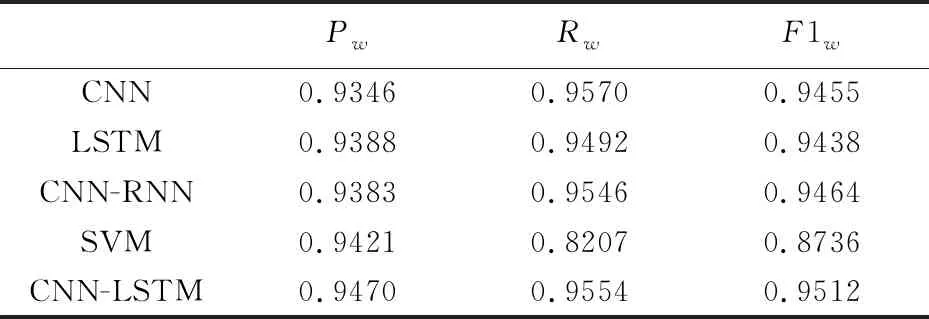
4.4 实验结果和分析

5 结论
猜你喜欢
河北理科教学研究(2021年3期)2022-01-18
新世纪智能(数学备考)(2021年5期)2021-07-28
湖北民族大学学报(自然科学版)(2021年1期)2021-04-02
数学大世界(2021年4期)2021-03-30
山东农业大学学报(自然科学版)(2020年5期)2020-11-02
海峡姐妹(2020年7期)2020-08-13
空军工程大学学报(2020年2期)2020-07-01
新世纪智能(数学备考)(2020年12期)2020-03-29
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
