
一维空洞卷积神经网络的矿物光谱分类
2022-03-11 07:17田青林郭帮杰叶发旺刘鹏飞陈雪娇
光谱学与光谱分析 2022年3期
田青林,郭帮杰,叶发旺,李 瑶,刘鹏飞,陈雪娇
1.核工业北京地质研究院遥感信息与图像分析技术国家级重点实验室,北京 100029 2.Zachry Department of Civil and Environmental Engineering,Texas A&M University,Texas 77843,USA
引 言
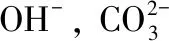
近年来,深度学习技术不断发展,被广泛应用于图像分类[2]、语音识别[3]、医学信号处理[4]等领域。卷积神经网络(convolutional neural network,CNN)[5-6]是深度学习中一个重要网络结构,其强大的学习和分类能力远超传统机器学习方法,具有广泛适用性。何东远等[7]提出一种一维CNN模型对恒星光谱进行分类,并给出了不同波段对不同恒星类型的贡献率,具有较高的分类精度和鲁棒性。赵勇等[8]提出一种一维CNN模型,对雌激素粉末拉曼光谱进行分类,无需光谱预处理和特征提取步骤,展现出良好的分类性能和抗噪声干扰能力。
本工作通过引入空洞卷积,将一维空洞卷积神经网络(one-dimensional dilated convolutional neural network,1D-DCNN)应用于矿物光谱分类领域,研究矿物类别的端到端检测,分析了卷积类型和迭代次数对模型分类结果的影响,并与反向传播算法(back propagation,BP)和支持向量机(support vector machine,SVM)方法结果进行对比。
1 实验部分
1.1 光谱数据采集
测量矿物光谱的仪器为美国ASD公司的FieldSpec@3型便携式光谱仪(350~2 500 nm),共2 151个波段,考虑到边缘波段噪声及数据量的原因,在380~2 420 nm波长范围,按3 nm间隔进行重采样,得到511个波段。光谱仪视场角为25°,数据采集过程中将光纤探头垂直于矿物样本,距离约2 cm,尽量使采集到的光谱数据不受干扰。
按照上述方法采集白云母、白云石、方解石、高岭石四种矿物光谱样本,数量分别为478条、972条、540条、976条,如图1所示。
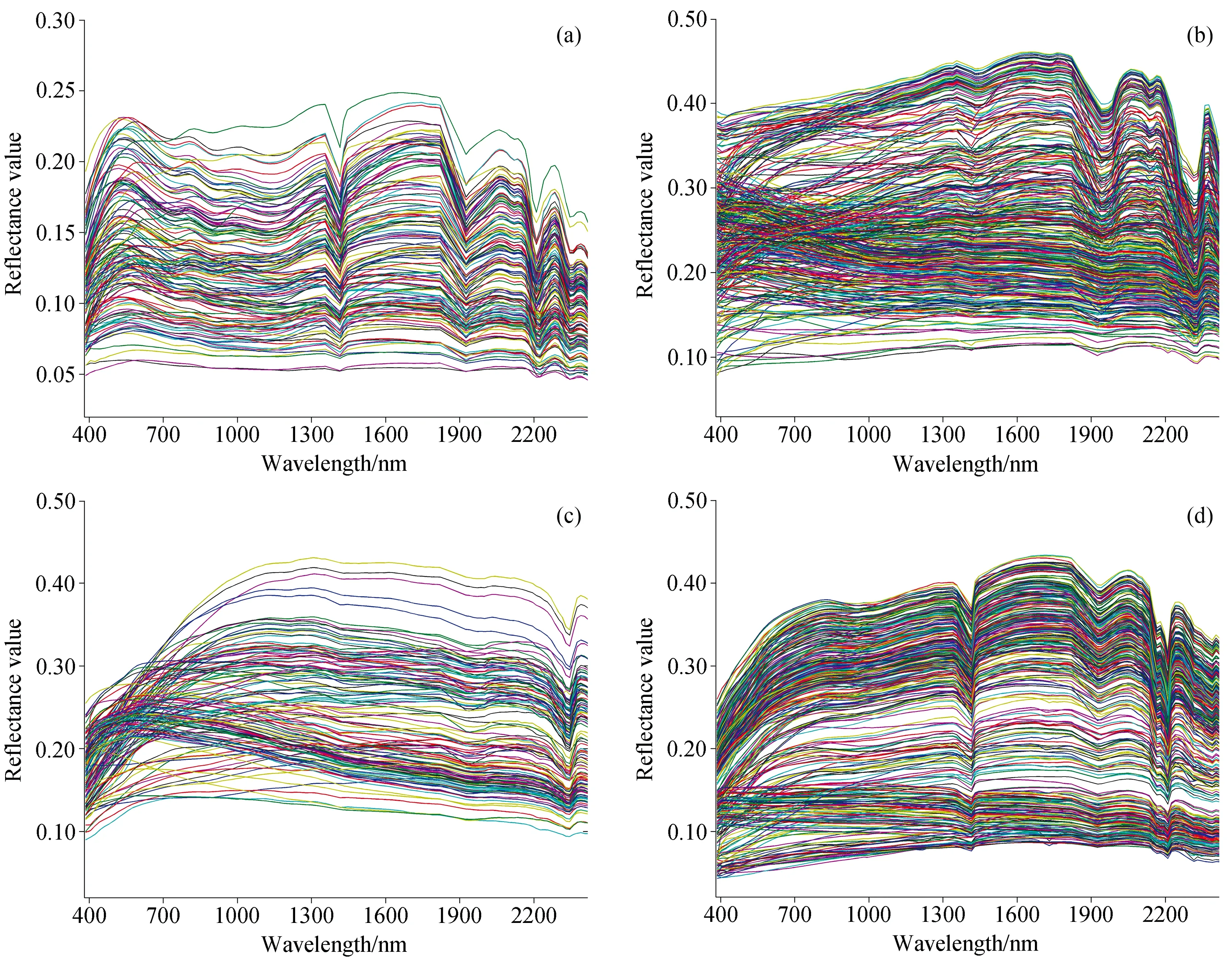
图1 部分矿物光谱数据(a):白云母;(b):白云石;(c):方解石;(d):高岭石Fig.1 Part of the mineral spectra(a):Muscovite;(b):Dolomite;(c):Calcite;(d):Kaolinite
1.2 模型与算法
1.2.1 光谱数据增强
CNN的优异性能需要大量数据样本作为支撑。充足的训练样本有助于网络模型充分学习样本类内特征和类间区别。而受样本数量、采集环境、测量设备等限制,一般较难获取大量带有标签的矿物光谱数据,故采用数据增强的方式扩充样本。具体方法是向原始矿物光谱数据中添加强度不等的随机高斯白噪声,将白云母光谱扩充至1 434条,白云石光谱扩充至2 916条,方解石光谱扩充至1 620条,高岭石光谱扩充至2 928条。经过数据增强,得到包含四类矿物光谱样本的数据集共8 898条,并按照6∶1∶3比例划分为训练集、验证集和测试集,用于模型训练、参数优化及精度测试。
1.2.2 一维空洞卷积神经网络模型
CNN模型应用于图像语义分割领域时,重复的卷积、池化操作会降低特征图分辨率,导致图像细节结构和边缘信息丢失[10]。而在光谱分类中同样面临上述问题,为此通过引入空洞卷积来解决这一问题,在保持分辨率的同时扩大滤波器感受野,尽可能地保留光谱细节特征。对一维光谱信号的情形,需要进行一维空洞卷积操作,如图2所示,当空洞率rate=1时,空洞卷积相当于标准卷积,滤波器以连续的方式对输入信号进行处理,当rate=2时,在原始滤波器的每个元素间插入一个0,以跳跃的方式处理信号。
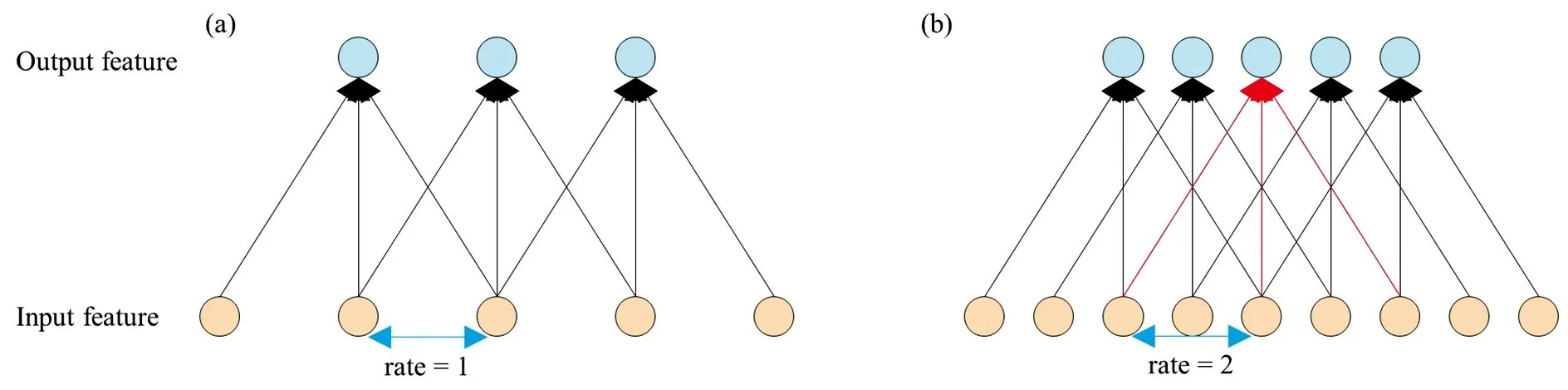
图2 一维空洞卷积示意图[9](a):标准卷积;(b):空洞卷积Fig.2 Schematic of one-dimensional dilated convolution(a):Standard convolution;(b):Dilated convolution
因此,针对矿物光谱数据的特点,设计了1D-DCNN模型,其结构如图3所示,详细参数见表1。模型包含1个输入层,3个空洞卷积层,卷积核大小分别为5×1,3×1和3×1,卷积核数量均为64,步长为1,空洞率为2,选择ReLU作为激活函数。2个池化层紧接在第1个和第2个空洞卷积层之后,池化核大小均为3×1,步长为2,池化类型为最大池化。第3个空洞卷积层之后紧接2个全连接层,最后通过softmax输出层得到分类概率预测。
图3 一维空洞卷积神经网络结构Fig.3 The structure of one-dimensional dilated convolutional neural network
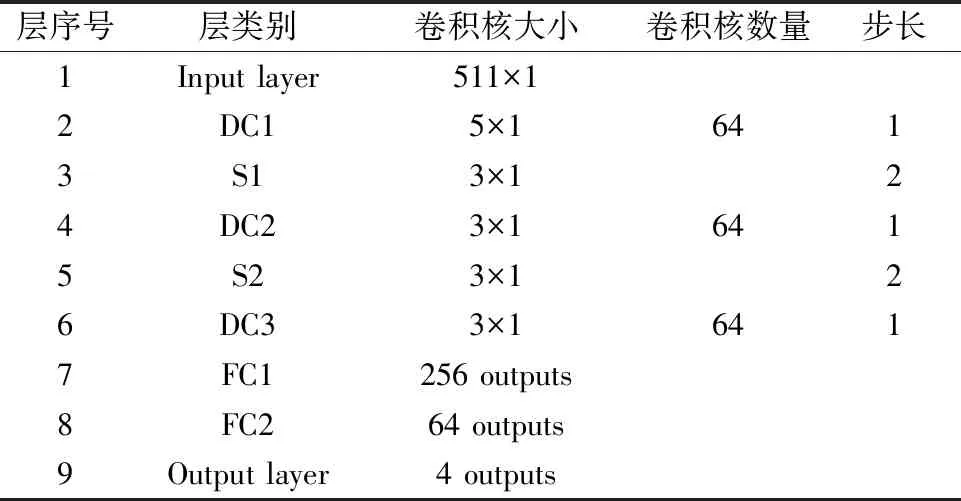
表1 1D-DCNN网络各项参数Table 1 The parameters of 1D-DCNN
1.2.3 模型训练
1D-DCNN网络模型采用交叉熵作为损失函数,使用SGD(stochastic gradient descent)优化器进行训练,具体参数设置为学习率lr=0.008,权值衰减系数decay=0.000 000 1,动量momentum=0.5,Epoch=200。为实现1D-DCNN模型快速收敛,训练集被分成多个批次(batch),批处理样本数量(batch size)设置为40。
1.2.4 模型评价方法
采用训练集和测试集的判别准确率作为模型评价指标。判别准确率P可表示为
(1)
式(1)中:Nc为判别正确的样本数目,Na为样本总数目。
2 结果与讨论
2.1 卷积类型对1D-DCNN模型的影响
为检验卷积类型对模型性能的影响,将1D-DCNN中空洞卷积替换为标准卷积,记为1D-CNN,其他参数保持不变,比较二者分类精度和收敛速度差异,结果如图4所示。
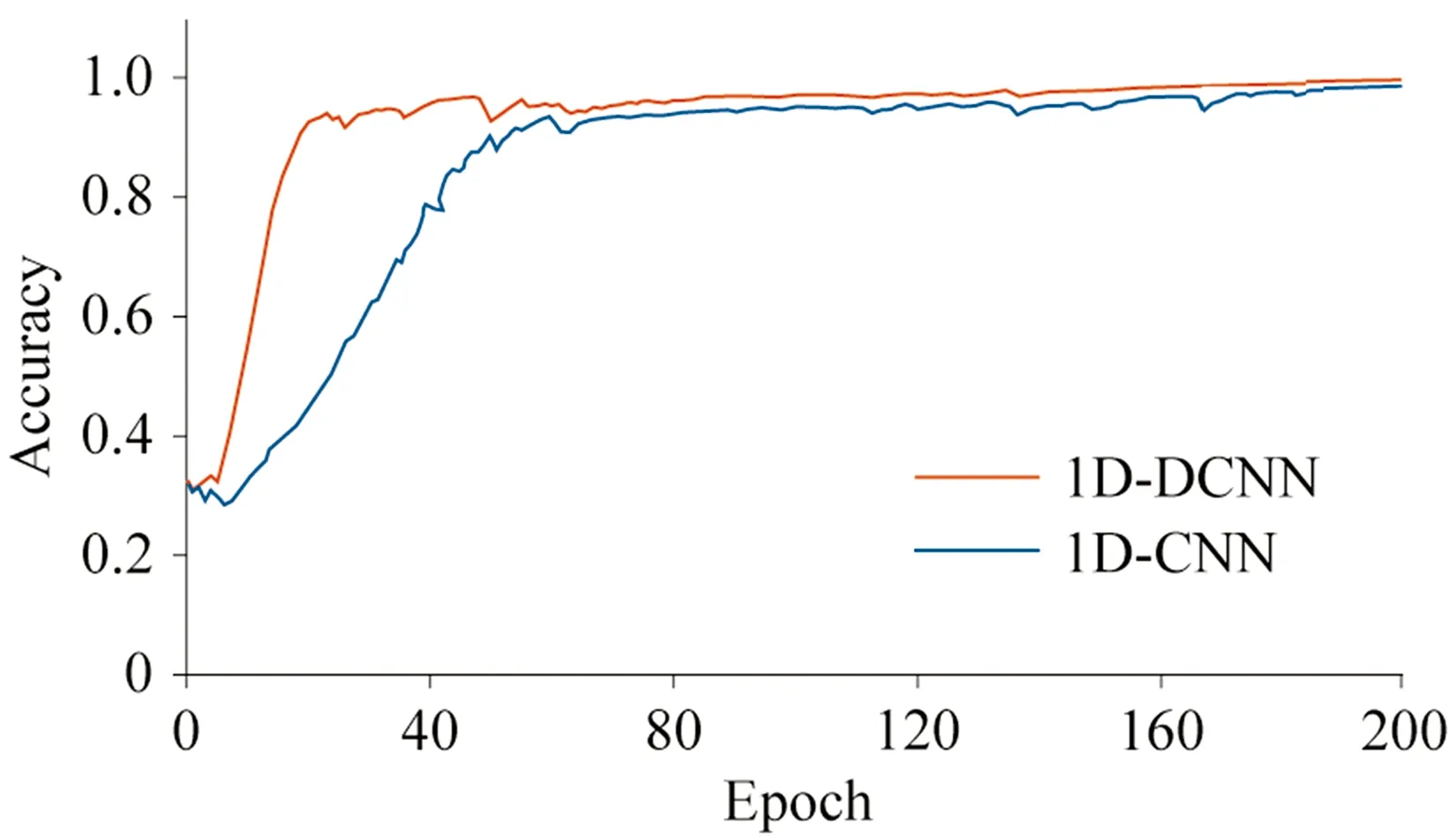
图4 不同卷积核类型的模型性能比较Fig.4 Model performances with different convolution kernel types
从图4可以看出,在网络训练过程中,1D-CNN模型的最佳分类精度为98.78%,而引入空洞卷积的1D-DCNN模型精度更高,达到99.40%,提高了0.62%。在收敛速度方面,1D-DCNN模型在迭代23次后便达到94%的分类准确率,而1D-CNN模型达到相近精度需要迭代60次。由此可见,引入空洞卷积同时能够加快收敛速度,提高计算效率,使模型更快得到精确结果。
2.2 迭代次数对1D-DCNN模型的影响
为选取最优的网络迭代参数,对比了不同迭代次数对模型精度的影响,结果如表2所示。当迭代次数很少时,模型训练不够充分,网络参数未达到最优,分类准确率较差;随着迭代次数增加,准确率随之提高;当迭代次数达到足够量时,模型分类效果变化不大,网络达到收敛状态。综合考虑模型精度和效率,选择迭代次数为200。

表2 不同迭代次数的1D-DCNN模型判别结果Table 2 1D-DCNN model discrimination results of different number of iteration
2.3 不同分类方法精度对比
为验证1D-DCNN模型的矿物光谱分类性能,将BP算法、SVM与1D-DCNN进行对比,各分类器均已经过参数调试和优化,分类结果如表3所示。

表3 不同算法分类准确率Table 3 The classification accuracies of different algorithms
根据表3结果可以看出,1D-DCNN分类效果最好,准确率达到99.32%;其次是BP算法,准确率为98.65%;最后是SVM,准确率为97.94%。相比于BP、SVM等传统机器学习算法,本文提出的1D-DCNN方法是通过构建具有多个隐含层的学习模型和大规模训练数据,提取低层光谱特征并组合形成更抽象的高层语义类别信息,从而提高光谱分类的准确率。
3 结 论
提出了基于一维空洞卷积神经网络的矿物光谱分类方法。设计了9层网络结构,采用交叉熵为损失函数,随机梯度下降为优化器,无需任何数据预处理操作,实现了白云母、白云石、方解石、高岭石四种矿物类别的端到端检测。
(1)1D-DCNN模型展现出强大的特征学习和表达能力,避免了复杂的光谱预处理及特征提取过程。通过引入空洞卷积,在保持特征分辨率的同时扩大滤波器感受野,尽可能地保留光谱细节信息,提高分类精度。
(2)实验结果表明,与BP、SVM方法相比,1D-DCNN模型对矿物光谱分类准确率更高,达到99.32%,展现出良好的分类性能。
在后续研究中,会尝试增加矿物种类和样本数量,设计更高效的深度学习模型,为矿物光谱规模化检测提供可靠的技术支持。此外,还可将1D-DCNN模型推广到煤炭、油气、月壤等其他领域的光谱分类应用中。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
空间科学学报(2021年1期)2021-05-22
上海金属(2021年2期)2021-04-07
学生天地(2020年18期)2020-08-25
矿产综合利用(2020年1期)2020-07-24
消费导刊(2018年8期)2018-05-25
中成药(2018年2期)2018-05-09
故事作文·高年级(2017年2期)2017-03-01
中国光学(2015年5期)2015-12-09
食品工业科技(2014年23期)2014-03-11
