
宁夏盐池荒漠植物光谱特征分析及光谱识别
2022-03-11 07:17杨军银何国兴潘冬荣柳小妮
光谱学与光谱分析 2022年3期
纪 童,王 波,杨军银,李 强,何国兴,潘冬荣,柳小妮*
1.甘肃农业大学草业学院,甘肃 兰州 730070 2.草业生态系统教育部重点实验室(甘肃农业大学),甘肃 兰州 730070 3.甘肃省草原技术推广总站,甘肃 兰州 730070
引 言
高光谱遥感在世界各地都受到高度的重视,发达国家把农业遥感作为国内决策支持的重要手段,对主要农产品的产量、全球资源环境变化等状况进行长期动态监测。高光谱遥感具有分辨率高波段多且连续的特点,满足连续性与光谱可分性的要求,能够区别同一种地物的不同类别,可以作为植物和群落分类的依据。王波等[1]研究了东祁连山高寒灌丛6种灌木植物的光谱特征,通过原始光谱数据的变换,提高了不同灌木植物光谱曲线间的可辨析度,并筛选出了灌木植物识别的敏感区,发现敏感波段的REF均值或GABS面积计算的NDVI值和RVI值可有效辨别东祁连山高寒灌丛的6种灌木植物;尼加提·卡斯木等[2]为解决沙漠腹地绿洲遥感图像植物群落背景较易混淆问题,提出了一种基于深度卷积神经网络(convolutional neural network,CNN)的高分辨率遥感影像植物群落自动分类方法,分类结果表明,训练样本数量不低于200时,基于CNN的Res Net50模型表现出最佳的分类结果。
在高光谱分析中,单一原始光谱反射率有时对植物指标反映不敏感且光谱测定时易收到外界环境影响如土壤背景、大气溶胶等影响,此时常常对原始光谱数据进行适当的变换和筛选处理,或结合不同波段的原始光谱反射率,形成了各种植被指数,以增强植物某一指标特征或消除环境因子的影响。自高光谱发展至今,光谱植被指数已有150多种,如典型的归一化植被指数(NDVI)、比值植被指数(EVI),植物分类领域中利用光谱数据转换和植被指数进行植被光谱特征分析十分常见,束美艳等[3]对小麦(Triticum aestivum L.)叶面积指数高光谱反演研究结果表明,新构建的红边抗水植被指数(RRWVI)取得了比NDVI、标准化差分红边指数(NDRE)等常用植被指数更为可靠的效果。贾学勤等[4]利用筛选出的特征色素简单比值指数c(PSSRc)、改进红边比值植被指数(MSR705)和中分辨率陆地叶绿素成像指数(MTCI)建立了复合式PLSR模型,提高了冬小麦地上干生物量估测精度。很多分类模型也被广泛应用于植物遥感分类识别中。如李婵等[5]采用K最邻近(KNN)、支持向量机(SVM )和随机森林(RF)3种方法对农业区域8种不同植物进行分类,结果表明SVM模型分类精度要优于KNN与RF模型;杨珺雯等[6]以北京小汤山农业试验区高光谱作为数据,利用RF与SVM模型对目标进行分类,结果表明RF各项分类精度优于SVM;邵琦等[7]通过Boruta算法对玉米品种533~893.4 nm光谱进行筛选,在全波段、全波段和纹理信息、有效波段以及有效波段和纹理信息4种特征组合下,利用RF与偏最小二乘法进行玉米品种识别,结果表明RF分类准确率优于偏最小二乘法判别模型。
目前随机森林(RF)、支持向量机(SVM)与K-邻近(KNN)分类模型被广泛应用于森林植物和农作物的遥感分类,并取得了较好的分类识别效果。但针对草地尤其是荒漠草地植物的分类识别研究较少。宁夏盐池县荒漠草地属于中温带干旱气候,由于过度利用出现不同程度的退化,退化指示种比重增大,造成不同荒漠草地群落组成差异也很大。如何区别不同荒漠草地植物,并据此对退化指示种进行动态监测是了解荒漠草地退化程度的关键。为此,通过对宁夏盐池县荒漠草地主要植物反射光谱的分析,利用随机森林模型(RF)、支持向量机(SVM)与K-邻近(KNN)分类方法,建立了主要植物的分类模型。
1 实验部分
1.1 研究区概况
盐池县位于宁夏东部,处于半干旱区与干旱区的过渡地带,地势南高北低,由东南至西北为广阔的干草原和荒漠草原。属典型的大陆性季风气候,光能丰富,热量偏少。受季风影响,降水主要集中在夏秋两季,年际变化大,气候干燥,蒸发强烈,年均蒸发量是年均降水量的6~7倍,境内土壤主要为灰钙土、风沙土,大多数土壤结构松散、肥力较低,土壤瘠薄,部分地区土壤的次生盐渍化严重。
试验地位于宁夏盐池县二步坑、冯记沟、高沙窝和麻黄山的温性荒漠草原,试验地概况如表1所示。
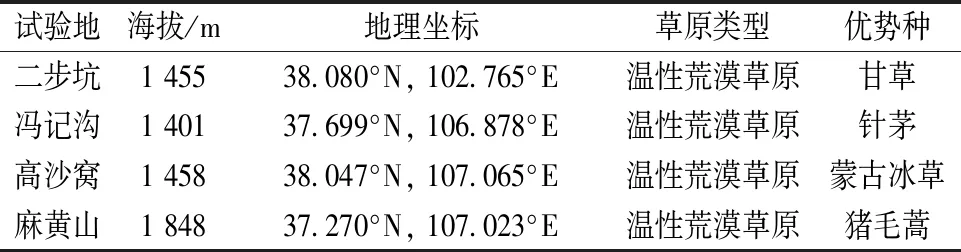
表1 样地设置Table 1 Types and geographical positions of the grassland communities
1.2 方法
1.2.1 光谱数据获取与校正
2017年7月,在上述4个样地,采用ASD地物光谱仪(表2)采集主要植物的光谱数据。光谱采集时光纤探头垂直向下,距植被冠层垂直高度依据样品冠层大小及探头视场角(25°)确定,使样品冠层恰能位于探头视场范围内。如待测植物冠层范围存在其余杂物,则清除杂物,以保证光谱准确性。每种植物随机测定10株,每株测定10次,取其均值作为该株植物的原始光谱反射率。共采集32种植物(表3)。每测一个点前用标准白板进行校正,减少天气变化带来的误差。

表2 仪器参数及要求Table 2 Instrument parameters and requirements
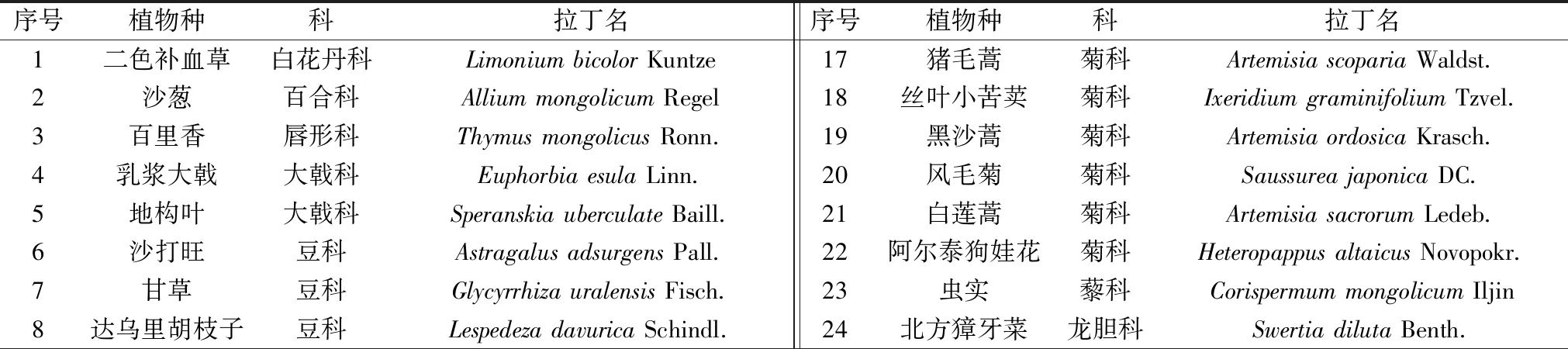
表3 植物名录Table 3 Plant directory
光谱测量易受天气、空气水分、冠层水分等因素影响,光谱曲线难免会出现异常,因此在进行光谱数据分析之前,应剔除有明显异常的数据。使用地物光谱仪自带的View Spec Pro软件对植物光谱进行多次重复测量值进行平均处理,消除光谱噪音的影响,得到光谱反射率数据。
1.2.2 植被指数选取
植物光谱除受自身生理生化指标影响外,还易受周围环境变化影响如土壤背景、大气溶胶等影响,常常利用不同的植被指数以增强植物某一指标特征或消除环境因子的影响[14]。根据宁夏荒漠植被与环境特点,筛选出7个植被指数(表4)。
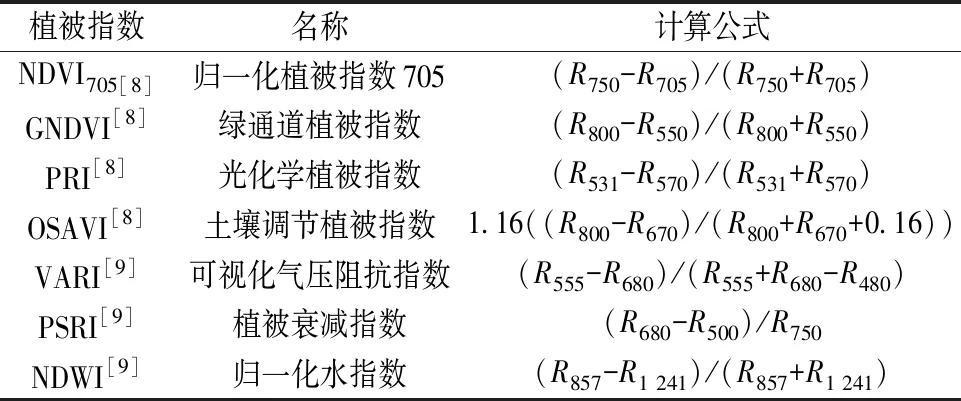
表4 植被指数Table 4 Spectral Index
这些植被指数与植物特征密切相关,或有助于光谱精度提升。如NDVI705对植被冠层结构、GNDVI对植被冠层绿度、PRI对植物类胡萝卜素、NDWI对植被冠层水分较敏感;PSRI多用于植被健康的监测与检测,OSAVI可有效消除土壤背景的影响,VARI可以有效矫正大气溶胶影响,消除部分辐射误差。
2 结果与讨论
2.1 不同植物的原始光谱特征
植物冠层反射光谱(图1)表明,不同植物光谱反射率均符合绿色植物特征,但各植物原始光谱不同波段之间存在明显差异。
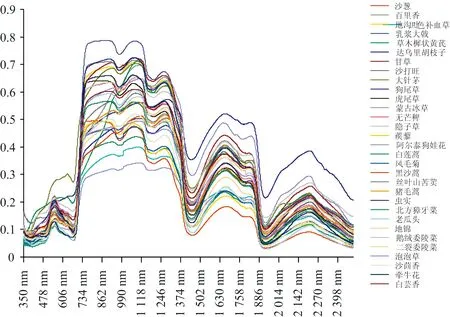
图1 荒漠草地植物原始光谱反射率Fig.1 The original reflectance spectra of desert grassland plants
可见光波段550 nm附近,出现了第一个叶绿素吸收峰,北方獐牙菜波峰光谱反射率最低无芒稗、虎尾草、大针茅较高。
植株在680 nm附近反射率快速上升,形成植物所特有的 “红边”,与其他植物不同。其中白莲蒿的红边斜率最低,乳浆大戟的红边斜率最高,白莲蒿红边斜率区别于其余植物,但整体红边趋势相差不大。
在近红外波段,甘草、大针茅的光谱反射率较高。所有植物在954~973,1 084~1 198和1 440~1 462 nm这3个波段均存在明显的吸收谷,在1 450 nm附近水分吸收谷处光谱反射率最大值为0.35(狗尾草),最小值为0.079(沙葱)。
2.2 植物分类模型
2.2.1 RF分类模型
RF分类模型n_tree误差表明,当ntree=100时模型内草种误差基本稳定,即ntree取100。
由图2可知,白莲蒿(4.3%)、白云香(9.5%)、虫实(4%)、甘草(3.3%)和乳浆大戟(33%)存在分类误差。RF模型精度为0.9816,袋外误差OOB为1.04%,说明RF分类结果较好,可区分32种荒漠植物。
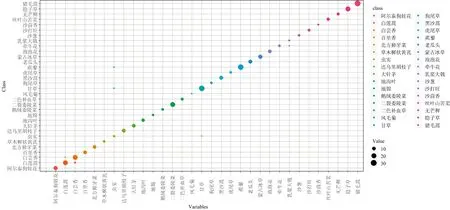
图2 随机森林模型混淆矩阵图注:图中对角线以外的气泡代表误判,气泡大小代表判断数量,样本数量越大气泡越大,Error代表植物误判率,下同Fig.2 Obfuscation matrix of random forest modelNote:the off-diagonal bubbles represent misjudgment,and the size of the bubbles represents the number of judgment.The larger the number of samples,the larger the bubble
图3为RF模型变量重要性图。
由图3可知,RF模型重要性指标由大到小分别为NDWI,PRI,OSAVI,NDVI705,GNDVI,VARI和PSRI。RF模型Gini系数由大到小分别为NDWI,PRI,VARI,OSAVI,GNDVI,NDVI705和PSRI。NDWI为重要性指标和Gini系数最高的变量。
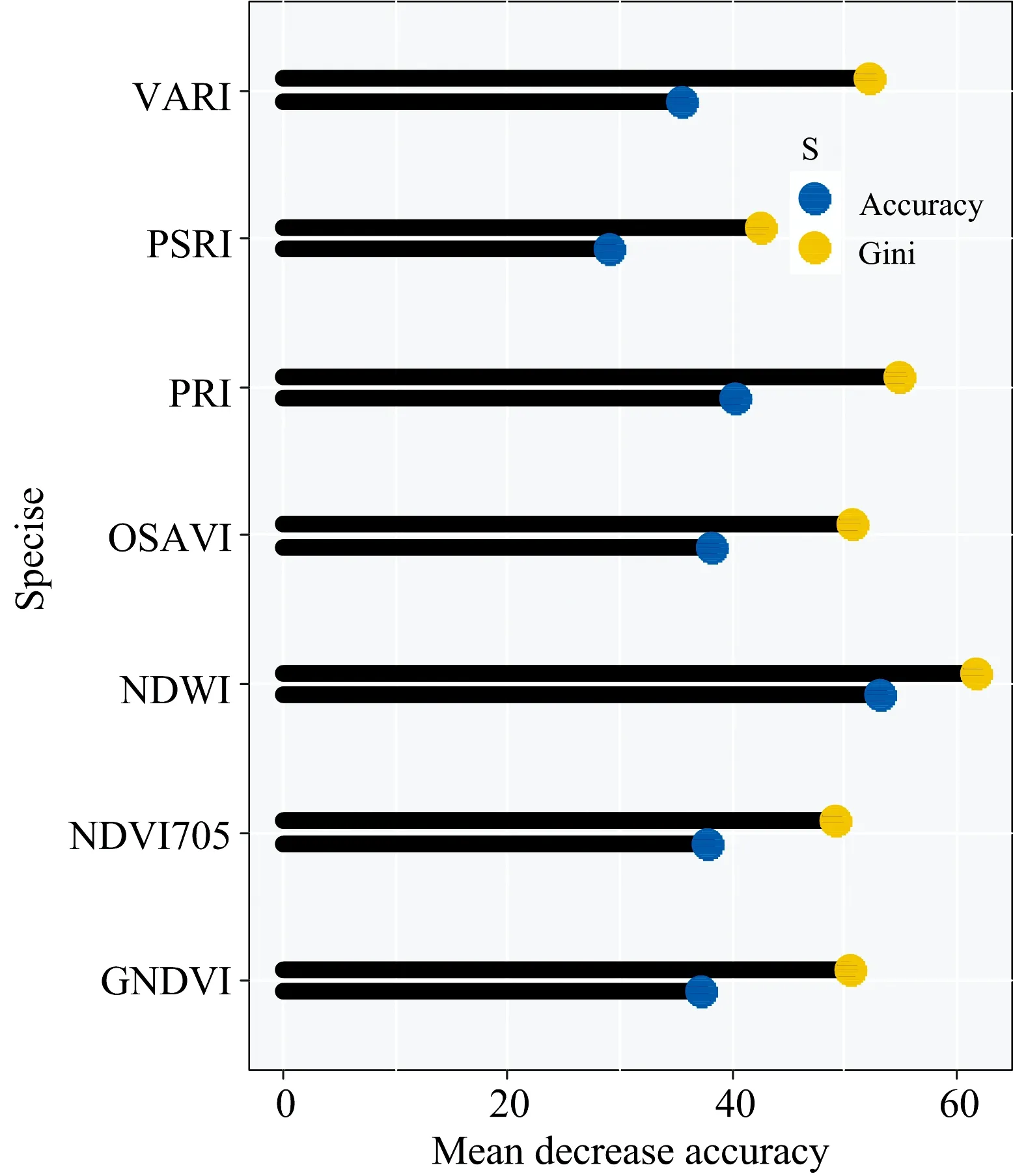
图3 随机森林分类模型变量重要性图注:图中蓝色圆柱为变量重要性,变量值越大说明变量的重要性越强,黄色圆柱为基尼系数,图中系数越高,分类切割越好Fig.3 Variale importance of random forest classification modelNote:The blue column in the figure is the importance of the variable.The larger the value of the variable,the stronger the importance of the variable.The yellow column is the Gini coefficient.The higher the coefficient,the better the classification cut
2.2.2 SVM分类模型
表5为支持向量机gamma与cost不同参数设置错误率。
根据表5所示当选择gamma=1×10-1、cost=100作为SVM分类模型参数时误差最小,将gamma=1×10-1,cost=100作为SVM分类模型原始参数。
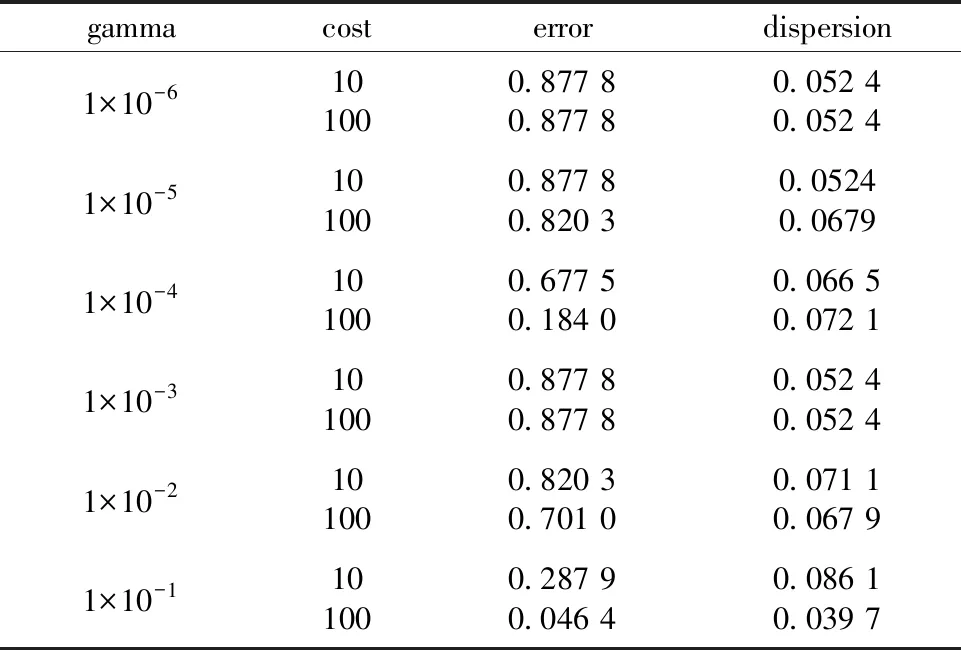
表5 gamma与cost设置Table 5 Gamma and cost
图4为支持向量机SVM分类模型的混淆矩阵气泡图。由图可知32种植物进行分类时,支持向量机SVM分类模型的混淆矩阵中,18份白莲蒿,有8份被误判为北芸香(44.4%)、15份甘草样本有1份被误判为虫实(6.7%),总样本数162,误判样本数9。
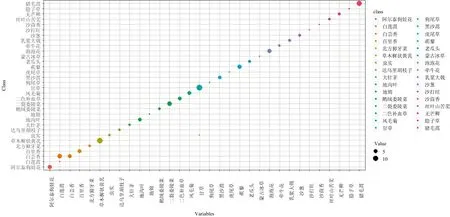
图4 支持向量机SVM模型混淆矩阵图Fig.4 Obfuscation matrix of SVM model
支持向量机SVM模型精度为0.94,kappa系数为0.94,说明支持向量机SVM模型较好,能较好的区分32种荒漠植物。
2.2.3 KNN分类模型
采用交叉验证法来选择较优的K值,图5为不同k值下KNN模型误差图。
由图5可知,当k=1时,KNN模型精度最高(0.981 8),因此选取k=1作为模型k值。
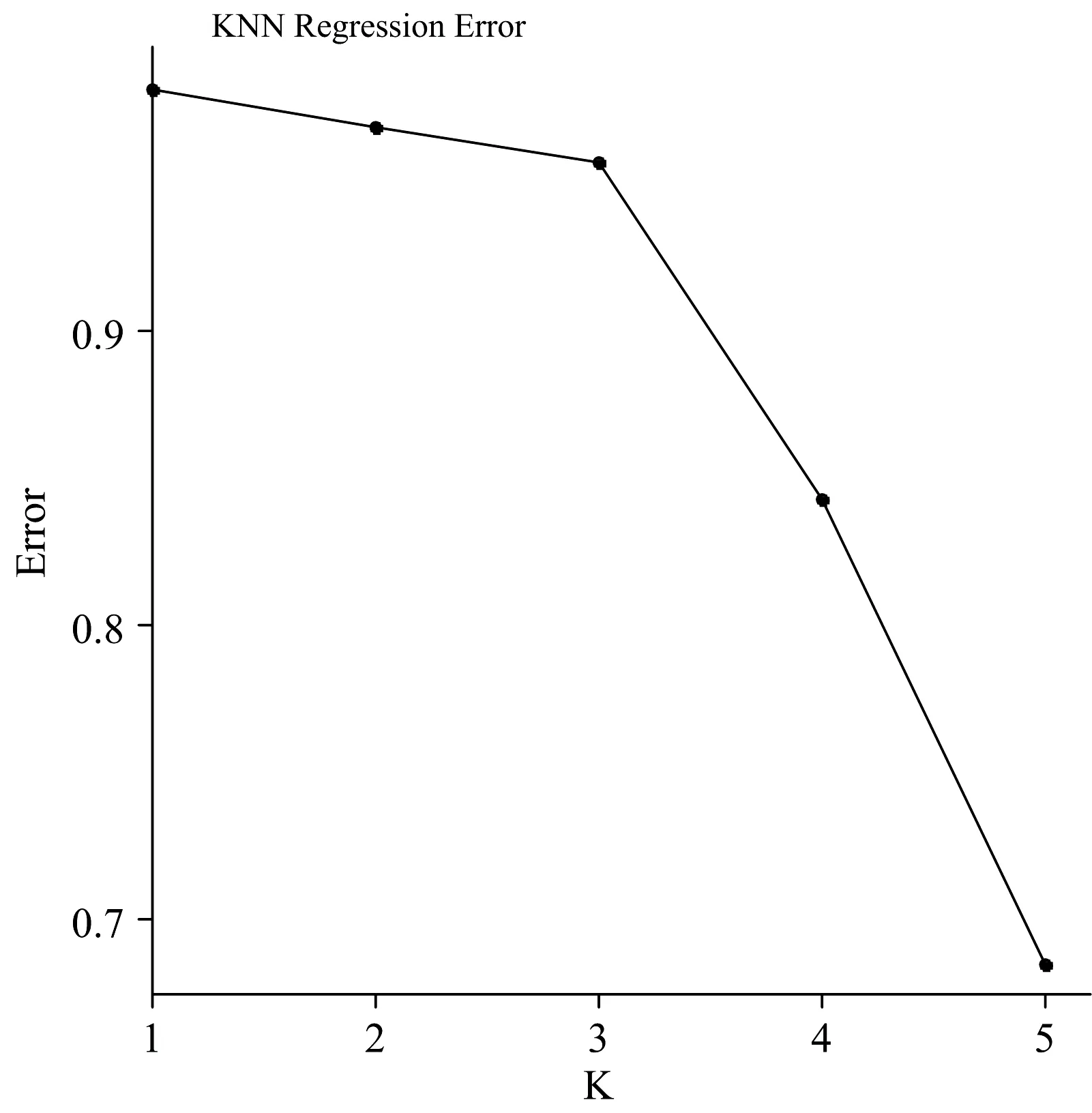
图5 KNN模型误差图Fig.5 KNN model error graph
图6为KNN分类模型的混淆矩阵气泡图。由图6可知,32种植物进行分类时,KNN分类模型的混淆矩阵中,其中12份白莲蒿中2份被误判为北芸香(16.7%)、4份虫实样本中1份被误判为甘草(25%),总样本数165,误判样本数3。KNN模型分类精度为0.982。
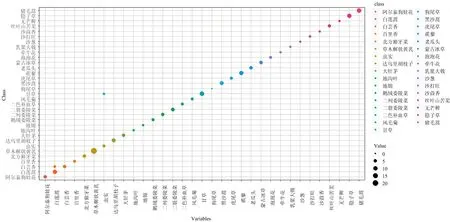
图6 KNN模型混淆矩阵图Fig.6 Obfuscation matrix of KNN model
2.3 荒漠草地植物的光谱特征
绿色植物区别于其他地物具有明显的光谱反射特征,植物反射光谱与植物生长发育、健康状况有着密切关系[10]。植物体内含有大量色素,其中以叶绿素对可见光波段光谱响应较为敏感,在蓝光(450 nm)与红光(650 nm)的两个波段内,叶绿素会吸收光辐射能量,从而在550 nm附近形成吸收峰[11]。本研究发现,32种荒漠草地植物中,大针茅反射率最高,北方獐牙菜反射率最小。造成此类现象的可能因素是因为大针茅、虎尾草、无芒稗均已抽穗,植株冠层多为褐色,叶绿素含量较少,光辐射吸收较小,导致绿光波段反射率高。
在可见光波段与近红外光波段之间680~760 nm附近处,反射率急剧上升,形成植物所特有的红边现象,这是植物区分于其他地物光谱最明显的特征,是植物光谱研究的重点。但本研究中荒漠草地植物与其他植物有所不同,在干旱胁迫下发生了红边蓝移现象,在680 nm形成“红边”。干旱环境下荒漠草地植物形态有着很大变化,如植株紧凑、低矮、叶片萎缩,细胞结构的改变成为各植物在近红外波段差异的重要因素。
中红外波段主要与叶片水分有关,受干旱气候影响,所有荒漠草地植物均在(1 350~2 500 nm)出现了两个水分吸收峰,且各植物水分吸收峰光谱反射率差异显著。魏怀东等[12]对民勤10种荒漠植物冠层含水率与光谱进行相关性分析,发现10种荒漠植物冠层含水量差异显著,且10种植物冠层水分含量指数与冠层含水量相关系数较高,与本研究结果相似。
2.4 荒漠草地植物的识别模型
本研究结果表明3种分类模型中,RF分类精度为0.980 6,带外数据OOB为1.04%,精度最高,能够对宁夏地区32种荒漠草地植物进行良好区分。这主要是RF引入了2个随机性——随机选择样本(bootstrap sample)和随机选择特征进行训练,使RF不容易陷入过拟合,并增加了其的抗噪能力。植被指数NDWI与PRI在RF中的Mean Decrease Accuracy与Mean Decrease Gini中数值较高,说明NDWI与PRI在RF分类模型中重要性极高。究其原因,主要是在干旱胁迫下,不同植物于水分的利用率不同,其冠层叶片相对含水量也存在显著差异,表现在光谱水分吸收波段的差异,因此对冠层水分含量的变化十分敏感的NDWI成为分类识别的重要指标。另外,类胡罗卜素具有抗氧化胁迫和猝灭光诱导的激发能,因而具有保护植物免受胁迫伤害的作用[13],荒漠草地植物叶片(同化枝)类胡萝卜素含量相对较高,且一般随其抗干旱胁迫能力的增加而增加[14],体现在植物光谱上,从而使对植物类胡萝卜素变化十分敏感的PRI成为影响植物分类的重要因素。相关研究中魏怀东等[12]对10种的光谱反演也发现NDWI与荒漠草种含水率相关性较高;杨红飞等[15]对新疆3种草地类型进行光谱特征分析,发现PRI与荒漠类草地相关性高,与本文植被指数NDWI、PRI为区分荒漠草地植物的主要植被指数的观点相同。
3种分类模型均对白莲蒿与北芸香、虫实与甘草发生了误判。从图7可看出,北芸香与白莲蒿在水分敏感波段的原始光谱反射率非常接近;而甘草与虫实在全波段上也较为相似,存在异物同谱的现象,较难区分。
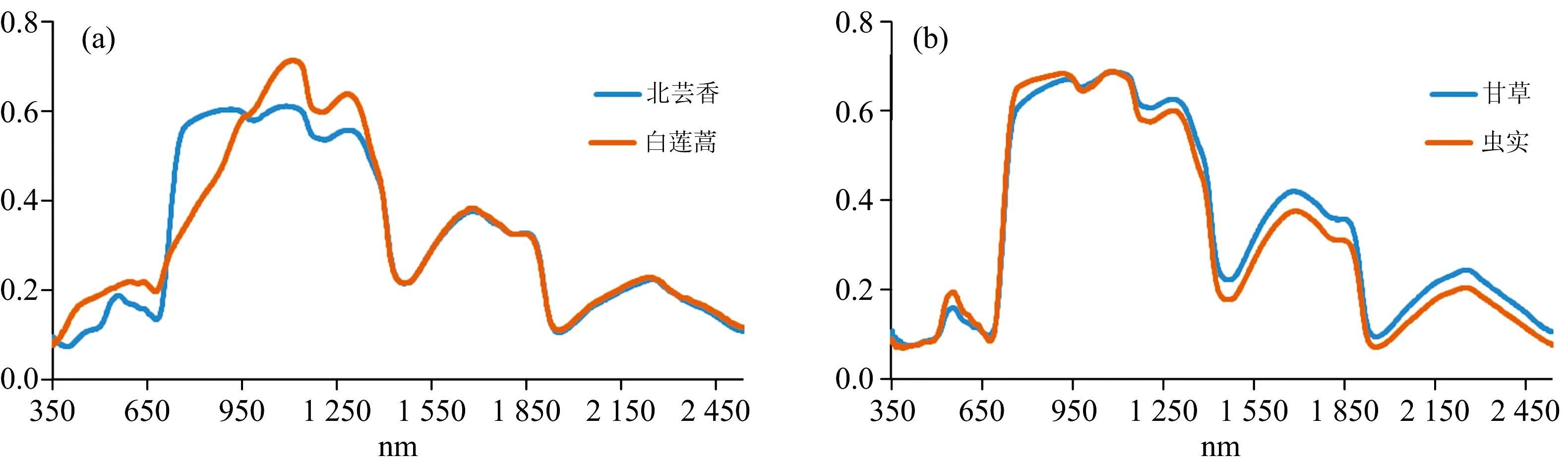
图7 原始光谱反射率Fig.7 Original reflectance spectra
2.5 分类模型比较
利用植被指数建立荒漠草原植物分类模型(SVM,RF和KNN)。RF分类模型的分类精度为0.980 6,带外数据OOB为1.04%,支持向量机SVM模型精度为0.94,kappa系数为0.94,KNN模型分类精度为0.982,其中随机森林分类模型精度最高,原因主要为RF具有很高的预测准确率对异常值和噪声具有很好的容忍度,且不容易出现过拟合;RF不仅是一种自然的非线性建模工具,也是一种极佳的分类工具,是目前数据挖掘、生物信息学的最热门的前沿研究领域之一。
3 结 论
(1)荒漠草地植物光谱具有典型植物的光谱特征,但因环境的干旱和高温胁迫,出现红移现象,各植物原始光谱水分吸收波段差异也较明显;
(2)RF和KNN分类模型对32种荒漠草地植物的识别效果较好;
(3)植被指数NDWI与PRI为区分荒漠草种的关键指标,即荒漠植物冠层水分含量与类胡萝卜素含量是影响光谱分类的重要因素。
采用的高光谱数据是基于叶片冠层光谱反射率,通过比较不同植被指数和机器学习算法进行植物的分类识别,由于植物样本有限,可能对模型的分类精度有一定程度的影响。
猜你喜欢
小哥白尼(趣味科学)(2022年5期)2022-08-15
作物杂志(2022年3期)2022-07-06
中国农业信息(2022年1期)2022-05-25
农业机械学报(2021年11期)2021-12-07
农业机械学报(2021年8期)2021-08-27
绿色中国(2019年14期)2019-11-26
农业机械学报(2019年6期)2019-06-27
中国农业信息(2018年2期)2018-07-28
——一种分层模拟的方法
自然资源遥感(2017年2期)2017-04-27
儿童故事画报·智力大王(2016年7期)2017-02-08
