
大数据生态链的数据整合模型构建与运作研究
2022-03-07 12:22吴绍波余维新
决策咨询 2022年1期
◆吴绍波 余维新 王 琳 周 全
一、引言
近年来,伴随着互联网与计算机产业的兴起,我国大数据产业得到了飞速发展,数据经济成为中国经济增长的重要引擎。国家网信办发布的数据显示,2018年中国数字经济规模达到了31.3万亿元,所占GDP的比例为34.8%。大数据作为继云计算、物联网之后IT行业又一颠覆性的技术,其技术环节包括数据采集、数据管理、数据分析、数据分析等环节,数据在不同环节的主体之间流动,各个环节相互依存,相互支撑,通过彼此合作形成类似于生物生态学上的大数据生态链,大数据生态链通过数据集成与整合实现价值增殖。大数据生态链在医疗、电商等多个行业应用广泛,例如,在电商领域,阿里巴巴通过淘宝平台、天猫平台与菜鸟物流采集用户数据,利用阿里云平台进行数据分析与归类,通过OneService平台对外提供数据服务,最后,用户利用在平台上获取的数据进行分析,用来做信息推荐、信用评级、需求挖掘等各种用途。不难发现,大数据生态链的存在与应用对于企业、用户都有一定的实践价值。
在理论上,目前国内外对大数据的应用有一定研究。主要包括如下几个方面:①数据开放与共享。例如,满芮和王健[1]研究了大数据背景下科学数据的开放共享模式;李成赞等[2]探讨了科学大数据开放共享的机制;甄晓非[3]对教育大数据平台信息共享的影响因素进行了分析;刘译阳和姜珊[4]从理论层面对大数据下的社会网络知识共享管理进行了分析。②数据伦理治理。例如,孟晓明和贺敏伟[5]针对社交网络大数据商业化开发利用的五种模式提出了个人隐私泄露的保护策略;任竞和易红[6]提出了图书馆大数据服务背景下用户隐私权危机的治理策略;朱光等[7]提出了问责情境下的大数据隐私溯源框架;孙卓和孙福强[8]基于制度信任构建了用户大数据隐私制度保护体系;安小米等[9]提出了互补互认的大数据治理体系构建框架;马广惠等[10]采用案例研究方法,研究了跨系统和跨部门的政府大数据平台如何实现数据治理。③大数据的数据挖掘与应用。例如,施雯[11]把基于大数据的情报分析应用于城市的科学决策和综合管理领域;刘自强等[12]以我国图书情报领域大数据研究为例,提出了基于语义分类的学科主题演化分析方法;曾文等[13]研究了基于图书出版行业大数据的选题决策分析模型;舒洪水和李燕飙[14]以GTD中的7133次恐怖袭击为样本,基于大数据视角对恐怖袭击的特点与趋势进行了分析;余传明等[15]以Twitter为数据源,以大数据环境下的文本情感分析这一特定任务为目的,对规模适配问题进行了研究。从已有理论研究来看,虽然对大数据的研究比较多,但对于大数据生态链的理论探索还不够,大数据生态链的数据整合过程模型还不清楚,由此提出了本文的研究论题。
一、大数据生态链的内涵与特征
大数据融合了计算机、云计算、互联网等新兴产业技术,以数据为基础,围绕大数据的采集、整理、挖掘、处理分析等活动,各数据主体交互协作,通过数据流动的串联形成了类似于生物生态链条的大数据生态链,其概念模型如图1所示。不同学者已在管理学、情报学领域引入生物生态概念进行研究[16][17],借鉴前人的研究,本文把大数据生态链定义为在一定的空间范围内,各组织在大数据采集、整理、挖掘、处理分析等活动过程中,通过物质、能量和数据流动而相互作用、相互依存形成的生态链条。在生态链上各组织之间相互依赖、互利共生,它们以数据为基础实现价值创造。
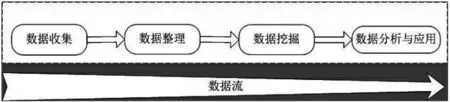
图1大数据生态链概念模型图
类比生物生态链条,大数据生态链具有如下特征:
(1)整体性。整体性是指大数据生态链是各环节的有机集合而非简单相加,其存在的目标、功能表现出整个链条统一的整体性,不同于各组织各环节在独立状态下所呈现出的性质、功能与运动规律。例如,大数据最后数据应用的结果与绩效,不仅仅与最后的数据分析与应用环节有关,与链条上的数据收集范围,数据整理质量,数据挖掘程度都有关。
(2)种群多样性。大数据生态链包含领导种群、关键种群、支持种群、寄生种群等多种生物种群[18]。领导种群、关键种群、支持种群、寄生种群彼此交互作用,共同为用户提供大数据解决方案,实现信息交流。例如,在腾讯的大数据生态链中,腾讯作为领导种群在生态链中占据核心中枢位置,提供大数据关键技术;小米、VIVO等关键种群在大数据生态链中提供关键的互补支持性的配套,利用手机终端收集各种用户信息;各种外卖APP(如美团)、共享单车APP(如青桔单车)是支持种群,它们利用APP收集信息,同时,它们也是寄生种群,利用腾讯的信息进行数据应用,识别用户需求。
(3)系统开放性。在大数据生态链中,围绕领导种群平台,多种支持种群与寄生种群在应用领域和数据服务领域是相关参与者。随着外部数据业务需求的变化,这个生态链条可能会淘汰一部分参与者,也会有一部分新的参与者带着技术与资源进入该生态链条。例如,在腾讯的大数据生态链中,共享单车作为数据的使用者,原有的参与者摩拜单车已经淘汰逐步退出,而新的参与者如青桔单车、哈罗单车又加入该大数据生态链,该大数据生态链面临着新老更替,与生物生态链进化的过程类似。
二、大数据生态链的运作模型构建
借鉴PórG[19]所构建的知识生态的三元网络模型,本文对大数据生态链的基本要素进行提炼,识别出大数据信息、环境、用户三个基本要素,构建出大数据生态链的三元模型(如图2所示),用来描述大数据生态链的运作模式。
(1)大数据信息。大数据信息是大数据生态链的客体,它在互联网环境下广泛存在,数据集的规模体量很大,数据纷繁复杂,大量有用信息中可能掺杂着无用信息。大数据的纷繁复杂甚至有可能超过数据末端的个人的认知能力,个人有可能无法在有限的时间内用现有的技术、方法获取与分析[20]。正是基于大数据本身的复杂性,才催生了大数据生态链的出现。大数据信息来源广泛,例如互联网的大数据信息可能来源于网民的文字输入记录、网购记录、网页浏览等。
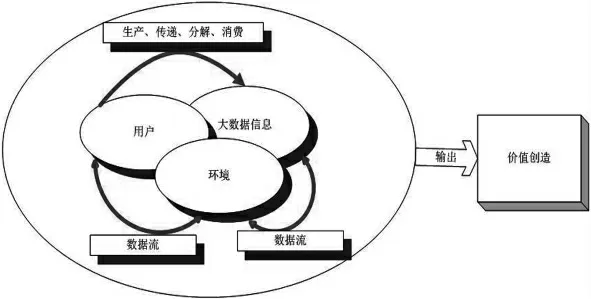
图2大数据生态链三元模型图
(2)环境。环境是大数据生态链赖以发展的基础,在大数据生态链中,环境要素涵盖了用户和大数据信息这两类主体以外的空间。大数据的环境层主要包括政治环境、经济环境、社会环境和技术环境,环境层是大数据生态链存在和发展的基础。例如,腾讯的大数据生态链的蓬勃发展,得益于中国近年来经济的飞速发展以及移动互联网技术的兴起。特别是移动互联网的发展,使得人们沟通更加顺利,人们在运用移动终端沟通过程中每天都会产生海量数据,移动互联网改变了人们的生活方式。
(3)用户。用户是大数据生态链的主体,在大数据生态链中或独立存在,或种群集聚。用户包括大数据生产者、传递者、分解者和消费者。大数据生产者在大数据生态链中负责输入信息资源,例如,在腾讯的大数据生态链中,各类手机APP具有识别用户通话语音和打字输入功能(所涉及用户隐私不在本文讨论之列);大数据传递者在大数据生态链中负责信息传递,充当传递媒介,例如,小米手机、VIVO手机微信大数据生态链中充当着传递着角色;大数据分解者对数据进行整理挖掘,使无序的数据变成有用的数据,便于大数据消费者使用,例如,腾讯的内部大数据平台会对收集的数据进行归类整理,运用数据挖掘工具进行分析,识别出消费者需求等各类有用的信息,便于精准推送给用户;大数据消费者是大数据的最终使用者,它们利用大数据进行消费者需求识别、管理决策,例如,在腾讯的大数据生态链的末端,各类餐饮企业、汽车企业、食品企业可以利用腾讯收集的数据进行精准广告投放与需求发掘。
从用户角度看,大数据的生产、传递、分解、消费过程是信息的传递与流动过程,如图3所示,该图的左边是数据的生产与传递过程,右边部分是数据的分解与消费过程。在图3中,首先,数据源中的海量信息经过采集与过滤、数据传输进入数据库储存;其次,平台企业利用计算平台与数据整合管理体系对数据进行计算处理(即数据挖掘);然后,当数据被整合好之后,平台企业向外部提供大数据产品和服务;最后,数据消费者在数据评估的基础上把数据应用于消费需求识别、广告推送、信用评级等方面。
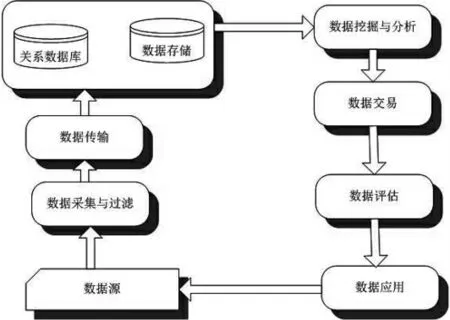
图3大数据传递过程图
三、溪流医疗大数据生态链的运作模型分析
“溪流医疗”是北京无极慧通科技有限公司在医疗行业着力打造的大数据产品品牌。溪流医疗基于大数据挖掘和支撑的关键技术,为合作医疗单位提供临床数据中心、科研数据平台、人工智能决策支持、精准健康管理、数据化运营服务等基于大数据技术的医疗服务功能和解决方案。溪流医疗的大数据生态链运作模型图如图4示,溪流医疗作为大数据生态链的领导种群,居于大数据生态链的核心位置,它主要负责建设健康管理、慢病平台,进行数据收集与管理。
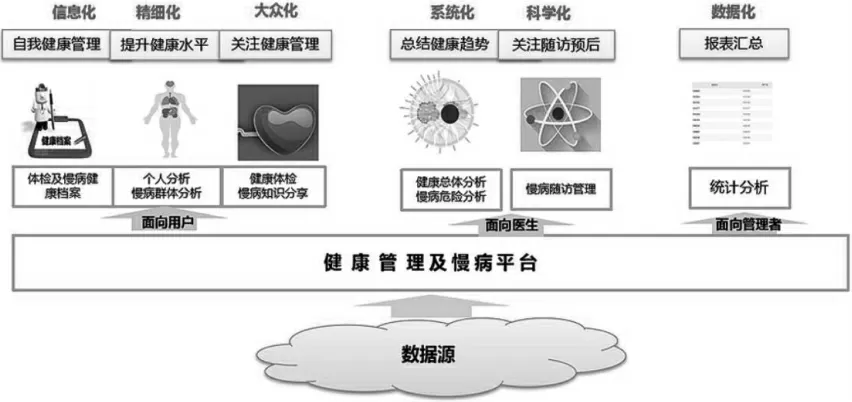
图4溪流数据的大数据生态链运作图
(1)数据收集。在数据采集方面,溪流医疗采用分布式采集方式,支持对结构化、非结构化数据的实时、非实时采集,同时具备单日海量数据处理能力及用户服务能力。溪流医疗的数据源主要来源于医院、社区卫生服务机构和公共卫生机构(包括各级卫生行政机构、疾病控制机构、卫生监督机构、妇幼保健机构、慢性病防治机构等),这些机构和个人在大数据生态链中既是数据提供者也是数据使用者,既是支持种群也是寄生种群。溪流医疗平台分为健康管理平台和慢病平台,其中,健康管理平台把医院的日常体检信息制作成电子体检报告。在慢病平台,溪流医疗与医院门诊系统对接,对病人的年龄、职业、既往病史等信息进行采集。
(2)数据整理。溪流医疗在进行数据收集与过滤之后,要把所收集到的数据通过数据传递,储存到内部的数据库中(如图3左边所示)。溪流医疗采用分布式无共享计算方式,如MapReduce、流式计算模型等。溪流医疗通过构建关系型数据库、分布式数据库、内存数据库等形成大数据存储计算环境。溪流医疗用于数据储存的设备规模可达千台服务器,支持PB级数据。
(3)数据挖掘。溪流医疗在把所采集到的数据存于数据库之后,最重要的环节就是进行数据挖掘与分析(如图3右上部分)。溪流医疗通过先进的机器学习和人工智能技术,实现海量医疗数据分析挖掘,帮助数据增值。来自健康平台的数据,溪流医疗要对个人健康状况进行整体报告分析、健康预警、身体趋势预测、多维整体分析等,最终形成检验分析报表。来自慢病平台的数据,溪流医疗要进行人群分类(如职业、年龄、城乡、地区等)、危险评估、随访管理等,最终形成总体分析与报表汇总。
(4)数据应用。经过溪流医疗挖掘与分析的健康数据,可以为医生、患者、医疗健康服务机构提供全面的医疗大数据分析应用服务。病人和医生是主要的使用者,如果病人和医生认为溪流医疗的数据很有价值就会加以购买。对于个人用户,溪流医疗的数据可以用于评估体检用户身体状况,对相关疾病进行预测,患者通过对比相关指标可以进一步了解身体状况,并对重点指标进行监控,辅助后期干预随访。对于医生用户而言,溪流医疗的数据融入权威专家医疗经验所建立的医疗数据挖掘模型,如不良事件危险因素分析模型、不良事件智能预警模型、疾病诱发因素分析模型、合理用药模型、个体化诊疗模型等,可以直接辅助医生科研临床管理与分析、临床决策支持,提升医疗诊疗与服务水平。此外,溪流医疗的数据也可以面向管理者提供服务,经过数据挖掘的信息可以向管理者提供营销策划、用户管理、产品管理、合作伙伴管理等运营支持服务。
此外,在溪流大数据生态链的运作过程中,政治环境、技术环境、经济环境以及社会文化环境也是健康稳定运行的重要外生变量。例如,在政府政策方面,政府支持溪流医疗获取患者个人信息至关重要,因为信息获取过程中涉及到患者的隐私问题;在技术环境方面,溪流医疗需要具备数据采集与存储技术、数据挖掘技术等相关技术能力;在社会文化环境方面,患者是否有健康意识,患者自身能主动体检、主动预防、主动索取健康数据对于溪流医疗的健康运行也很重要。
四、结束语
本文在梳理大数据生态链的内涵与特征的基础上,基于三元网络模型对大数据生态链的运作过程模型进行了分析。大数据生态链的运作需要关注大数据信息、环境、用户三要素,大数据的生产、传递、分解、消费过程是信息的传递与流动过程,这个过程包括数据收集、数据传递、数据储存、数据挖掘、数据应用。在理论分析的基础上,本文以溪流医疗的大数据生态链为例,对大数据生态链在互联网医疗领域的应用进行了案例分析,为大数据生态链在我国互联网医疗领域的应用实践提供了思路。在实践上,本文可以为我国大数据生态链的运作管理提供理论指导。当然,本文也存在一些不足,例如,本文存在案例选取单一的问题;此外,本文没有对大数据生态链的微观运作机制、稳定运行的影响因素进行深入探讨,这也是笔者下一步需要进行研究的方向。
猜你喜欢
今日农业(2022年15期)2022-09-20
风流一代·经典文摘(2021年10期)2021-10-25
意林(2021年13期)2021-07-29
湖南电力(2021年1期)2021-04-13
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
艺术评鉴(2019年9期)2019-06-17
红土地(2018年7期)2018-09-26
小溪流(画刊)(2017年12期)2018-01-10
智能系统学报(2013年1期)2013-01-28
