
基于AI技术的英语阅读文本难度影响因素分析
2022-02-01 09:56蒋东辰张键飞
英语教师 2022年20期
蒋东辰 刘 源 张键飞
引言
在语言学习中,阅读、写作、听力、口语是交流的四项基本技能。阅读是人们获取信息、学习知识的主要手段(Charles Alderson 2011)。在非英语环境中,由于受现实条件的限制,阅读往往在英语学习者各项技能训练中耗时最多。提升英语学习者的阅读水平,既能提升他们通过阅读获取信息的效率,又能促进他们其他英语技能的提升。因此,英语阅读能力的培养在英语教学中具有重要作用。
阅读往往被看作阅读者与文本交互的过程。阅读者通过阅读理解文本、获得知识,并以此为基础推断信息、运用信息。在阅读过程中,阅读者自身的知识、动机、策略、状态会影响阅读的效果,文本的词汇、句法、篇章组织、主题等因素会影响文本可读性(与“阅读难度”“文本难度”同义)。从阅读能力评价的角度看,阅读者的主观因素通常会被视为确定值,而将阅读者能够理解文本的难度水平作为衡量阅读者阅读水平的指标。当读者能够理解较难的文本时,其阅读理解能力较强;反之,其阅读理解能力较弱。因此,可通过分析影响文本可读性的语言学因素确定提升英语学习者阅读能力的关键。
可读性研究的早期工作集中在创建难词列表和人工设计可读性公式(Vajjala 2021)。随着自然语言处理和人工智能技术的发展,基于统计和机器学习的方法逐渐被用于可读性评估:司和卡伦(Si&Callan 2001)最先将可读性问题归为文本分类这一机器学习问题,在传统特征上使用统计语言模型,提高了Web文档难度预测的准确性;瓦贾拉和默尔斯(Vajjala&Meurers 2012)利用陆小飞(Lu 2010)提出的第二语言习得测量方法,结合词频特征和心理语言学等相关特征,在二语语料库Weebit上训练,实现了二语文本难度的准确预测。瓦贾拉和卢契奇(Vajjala&Lui2018)将特征扩展到155个,包括传统特征、语篇衔接、词汇语义和句法特征等模块,在二语语料库Onestop上训练预测模型。这些研究以文本的多种深层语言学特征为基础,通过大规模语料训练获得具有高准确性的文本难度预测模型,用于文本筛选和难度判断。
与当前文本难度分级预测的研究工作有所差异,本文的目标在于以分级阅读语料为基础,使用机器学习的方法分析影响文本难度的核心语言学要素,确定其影响程度,为英语教学设计提供数据支持。结构安排如下:第一部分回顾文本可读性研究相关工作;第二部分介绍本文用于分析影响文本可读性的语言特征;第三、四部分分别阐述文本可读性影响因素的判定实验及主要结果;第五部分是结论。
一、相关研究
早期的可读性研究主要使用一些浅层特征判定文本难度,如平均句子长度、平均单词长度;部分文献还利用难词表、词频估算文本的可读性(Dale&Chall 1948)。随着计算语言学的发展,以语言学为基础的多种数字化特征越来越多地被用于分析文本、预测可读性和构建文本难度模型。
词汇特征是文本可读性研究最多的语言特征。陆小飞(2011)研究词汇丰富度与英语学习者口语叙述内容质量之间的关系,分析词汇密度、词汇复杂度和词汇多样性对文本难度的影响,这些特征后来被广泛用于二语语料的可读性评估。勒罗伊和考查克(Leroy&Kauchak 2014)研究发现,单词频率与实际难度(人们如何选择正确的单词定义)和感知难度(单词看起来有多难)密切相关。陈小彬和默尔斯(Chen&Meurers 2018)进一步研究不同形式的词频与文本可读性的关系,他们发现:更丰富的词频表示可以构建出更好的难度预测模型。
在词汇之外,各种语法特征也被用于文本可读性预测研究。施瓦姆和奥斯滕多夫(Schwarm&Ostendorf 2005)在传统特征和统计语言模型的基础上增加了平均句法解析树高度、名词短语平均数量、动词短语平均数量、从句平均数量等特征,他们发现:这些语法特征可提高模型的预测性能。海尔曼、柯林斯-汤普森和卡伦等人(Heilman、Collins-Thompson&Callan,et al.2007)提出带有时态、语态、情态等语言特征的统计模型,实验说明这些特征对二语文本可读性预测有很好的效果。瓦贾拉和默尔斯(2012)研究发现,陆小飞(2010)筛选的14个句法指标对二语阅读文本的可读性测量十分有效。
除了常规的词汇、语法统计特征,柯海特(Coltheart 1981)从心理语言学角度研究词汇特征对文本可读性的影响。克罗斯利、格林菲尔德和麦克纳马拉(Crossley、Greenfield&McNamara 2008)认为以认知为基础的词汇特征在二语文本的可读性测量中尤为重要。田中、加藤和加藤等人(Tanaka、Jatowt&Kato,et al.2013)将具体性纳入文本可理解性度量,实验表明文本的具体性和可理解性存在正相关。这些研究中提出的多种心理语言学特征如具体性、熟悉性、可想象性、意义性、词汇习得年龄等被广泛用于二语文本可读性评估。
此外,实体密度特征、文本连贯性等因素也被用于文本可读性研究。皮特勒和内尔科娃(Pitler&Nenkova 2008)结合词汇、句法、语篇等特征预测英语文本可读性,认为语篇关系与文本可读性密切相关。芬格、詹采和惠恩福斯等人(Feng、Jansche&Huenerfauth,et al.2010)讨论了实体密度等语篇特征对文本可读性的影响,提出了9个密度特征用于预测文本难度,取得了良好的效果。
二、语言特征
本文的目的在于通过机器学习的方法,通过语料分析找到影响英语阅读文本可读性的关键语言学因素,为英语教学提供数据支持。为此,首先要确定潜在语言因素的范围和指标。
库珀(Cooper 1984)认为区分读者阅读能力的文本主要特征涉及时态/语态、词汇、句子关系与句子连接、词法关联、上下文连贯性,以及读者对主题的现有理解水平。本文选取了以往文献中的140个语言特征并对其进行分类:88个特征可由瓦贾拉(Vajjala 2015)提供的 nishkalavallabhi工具提取,其包括10个传统特征、10个词汇特征、29个词法特征、28个句法特征和11个心理学特征;52个特征可由李、张、李(Lee、Jang&Lee 2021)开发的LingFeat工具提取,其包括24个词汇特征和28个语篇特征。
为保证特征选择的全面性,实现与教学实践的紧密结合,进一步调研了一线英语教师和英语编辑,结合他们的英语教学经验,补充三组新特征并开发提取工具:语篇词汇难度特征、句法结构特征和谓词结构特征。这三组特征具体刻画如下:
(一)语篇词汇难度特征
词汇对语篇理解的影响除了与词汇在语料库中的频率相关之外,还与其在语篇中出现的数量相关。因此,提出语篇词汇难度这个概念刻画上述特征。目标文本的语篇词汇难度由a%word表示,它是目标文本前a%难词的文本难度值累加。
一般来说,一个词汇在语篇中出现得越多,其对语篇认知难度的影响越大;两个在语篇中出现频率相同的词汇,在语料库中出现频率较低的词汇对语篇认知难度的影响越大。基于上述分析,一个词汇在语篇中的难度值计算公式如下:
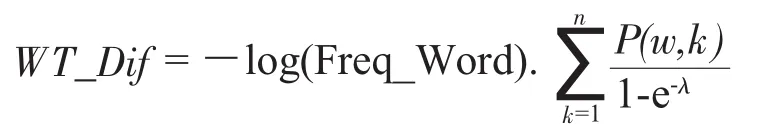
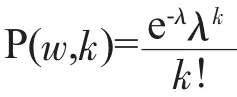
语篇词汇难度a%word由对文本难度影响最大的前a%难词计算。对于读者来说,当文本中生词占比超过某一阈值时,就难以通过阅读文本获取信息。参考王金巴(2015)关于生词密度对英语阅读理解影响的研究,选择前20%难词累加其语篇难度,并将其作为语篇词汇难度特征。
(二)句法结构特征和谓语结构特征
为了使特征构建与实际英语教学相一致,进一步细化实现了句法结构特征和谓语结构特征的计算机自动识别。
开发了细粒度的句法识别提取工具,该工具能够识别常见的主语从句、宾语从句、表语从句、定语从句和状语从句。以此为基础,将文本中各类从句数量与文本句子总数的比值作为新的句法结构特征(见表1)。同时,新的工具还能识别包括时态、情态、语态在内的255种谓语结构和非谓语结构。从中选择与日常英语教学及阅读文本难度分级相关性最高的20个谓语结构,将这些结构在文本中出现的次数与文本句子总数的比值作为新的谓语结构特征(见表2)。
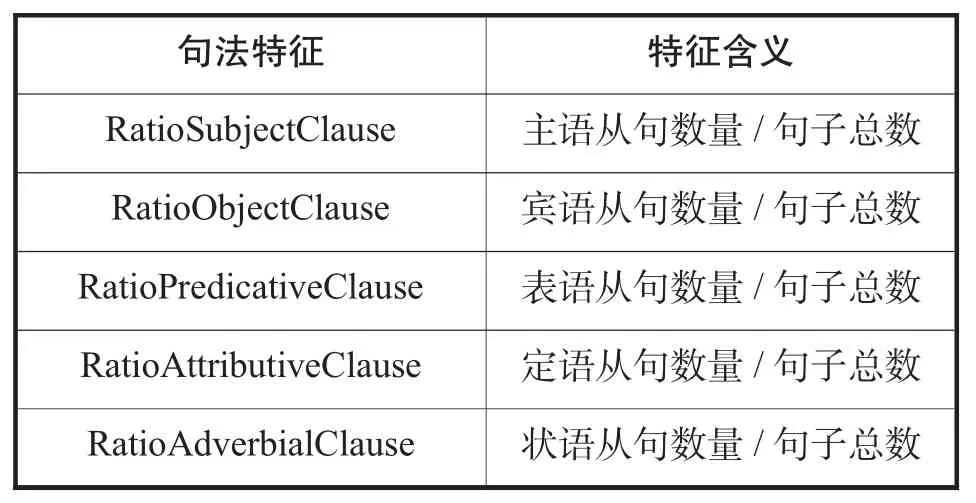
表1:句法结构特征
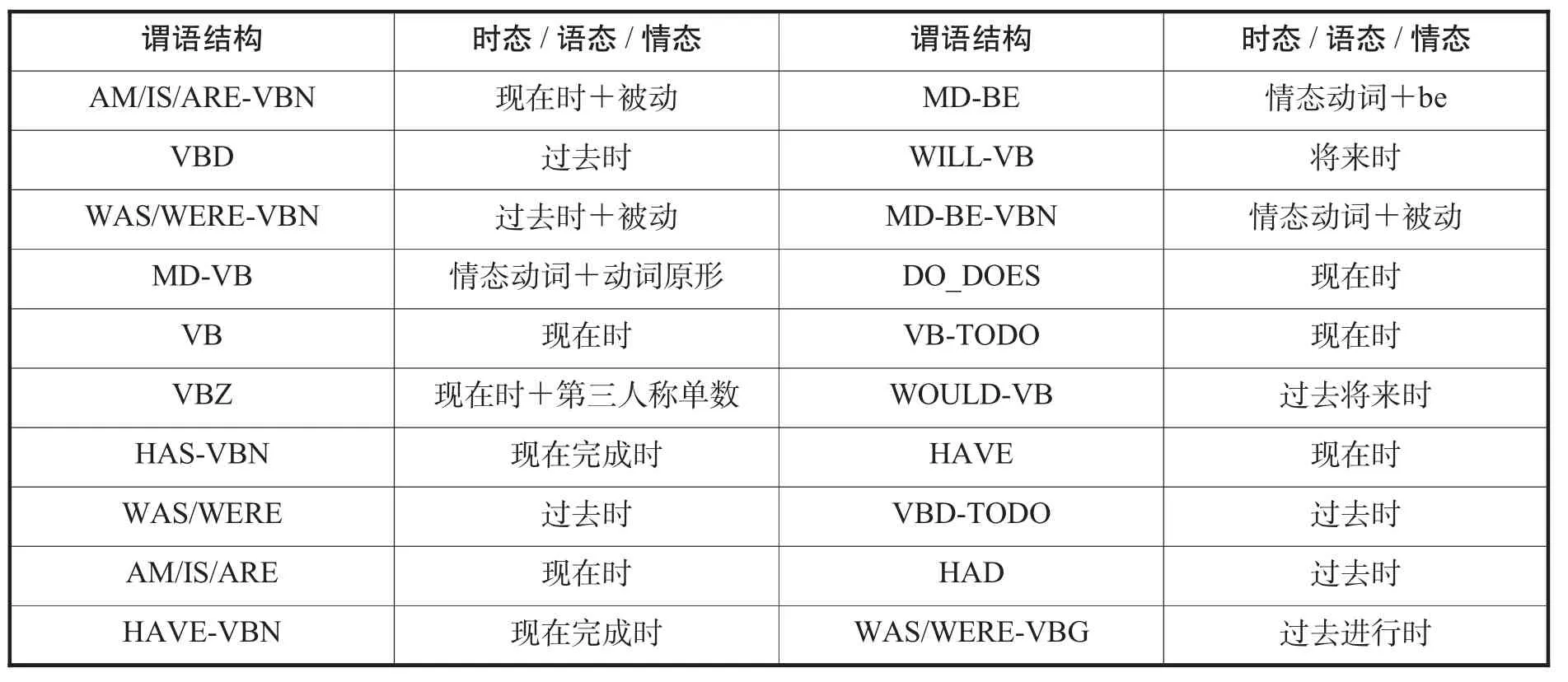
表2:主要谓语结构特征(按相关性强弱排序)
综上,实验关注的特征包括以往文献中已有的140个语言特征和三类新引入的语言特征(包括1个词汇难度特征、5个句法结构特征、20个谓语结构特征),总计166个语言特征。
三、语言特征重要性排序实验
使用《双语学习报》小学四年级至高中三年级九个年级的900篇阅读文本作为分级语料(每个年级100篇),将阅读文本的年级归属作为文本难度的数值刻画。
为了确定各类语言特征对文本难度的影响,实验将全部166个语言特征分为传统特征、词汇特征、词法特征、句法特征、语篇特征、心理学特征、谓语结构特征等7组。这7组特征内部的各个特征表现出很高的相关性,实验将通过依次筛选代表特征的方法,找到影响英语阅读的核心因素及其重要性排序。
本实验使用线性核的支持向量机(SVM)算法基于各种语言特征在《双语学习报》上拟合文本难度。在每次拟合后,选择难度影响因素最大的一个特征保留,并将其所在组的其他特征删除。然后,与剩余的其他组特征进行下一轮拟合,直到所有特征组筛选结束。由于传统特征大都是其他各组基础特征的组合,不能直观展现各类特征的影响,仅对其他6组156个特征训练文本难度预测模型。在评价指标方面,柯林斯-汤普森和卡伦(Collins-Thompson&Callan 2004)认为相邻年级文本具有强相关性。因此,采用临近准确度评价模型预测效果。具体实验结果见表3。

表3:语言特征筛选结果
表4所示实验筛选出的语言特征依次是词汇特征20%word(语篇词汇难度)、词法特征POS_correctedVV1(动词多样性)、心理学特征AoA_Kup_Lem(词汇认知年龄平均值)、句法特征SYN_num NPsPerSen(名词短语句中占比)、语篇特征ra_NX To_C(实体在前句非主语宾语,在后句作为其他成分句子的比例)、谓语结构特征WAS/WERE_VBN(过去时+动词原形)。6个特征组合预测的相邻准确度达83.6%,较好地实现了文本难度预测。
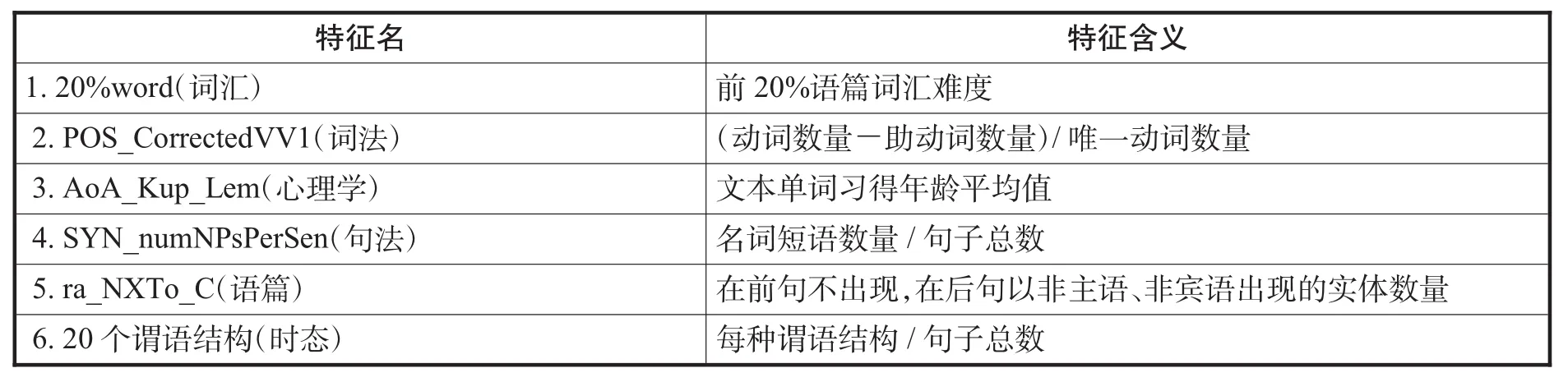
表4:特征排序及含义
实验结果表明,第一,词汇相关的两个典型特征对文本可读性的影响居于首位:前20%语篇词汇难度(可理解为读者完全理解文本所需掌握的词汇量)和动词使用的多样性。这一结果与马克斯、多克托罗和维特罗克(Marks、Doctorow&Wittrock 1974)的观点一致:在所有影响文本可读性的因素中,词汇难度的影响最大。瓦贾拉和默尔斯(2012)也有类似结论:词汇特征比句法特征在第二语言阅读文本预测中表现得更好。这说明提升词汇量、加深词汇的理解和灵活掌握对提升阅读能力是最关键的。
第二,心理学语言特征单词习得年龄对文本难度的影响在句法、时态之上。对单词习得年龄特征的理解:单词习得年龄是一语的语言特征,对于二语学习者,可以将其理解为语言使用者对相关事实、知识了解和掌握的年龄。对二语学习者来说,如果能够理解词汇背后所表征的事物和知识,那么就可以利用已有知识理解文本,而不再依赖于对句子的语法解析理解文本;如果缺乏相应背景知识,则只能通过对句子句法、语态、时态等语法特征的解析构建和理解知识。显然,具有相关经验、知识理解文本会更容易。因此,扩展认知广度可能比学习语法知识更有助于理解能力的提升。
第三,文本连贯性是一个与文本写作相关的因素:连贯性好,文本的可读性好;连贯性差,文本内概念的跳跃和转换越多,理解难度大。实验结果显示:语篇连贯性特征ra_NXTo_C影响效果比时态、语态等语法因素的影响大。这表明时态、语态等因素对于阅读文本可读性的影响较小。尽管通过与其他语言特征的融合,细粒度时态、语态特征能够改善文本可读性预测,但与词汇、心理认知、句法、语篇等特征相比,其并非影响文本可读性的重要因素。
四、核心影响因素筛选实验
语言特征重要性排序实验说明了常见语言特征对英语阅读文本可读性影响的大小。下面通过实验进一步阐述影响文本可读性的核心语言学特征。
核心影响因素筛选实验是在不考虑特征类别的基础上,利用交叉验证的递归特征消除算法(RFECV),从所有166个语言特征中筛选出影响文本可读性的核心要素。具体的,采用Scikit库RFECV算法实现,基模型选择具有线性核的支持向量机。RFECV包括RFE阶段(Recursive feature elimination)和 CV 阶段(Cross Validation):在 RFE阶段,算法通过递归逐步消除特征,实现对所有特征重要性评级;在CV阶段,算法通过交叉验证,选择最佳的特征组合。
本文对比了使用瓦贾拉(2015)和李、张、李(2021)的研究中140个已有特征与引入本文提出的26个特征后的实验效果,结果见表5。实验显示:在引入26个新特征后,使用RFECV方法获得的相邻准确度提升到86.2%,且核心特征数量由23个降到8个。在提升预测准确性的同时提升了文本可读性影响因素的可解释性。筛选得到的影响文本可读性的8个核心特征见表6。
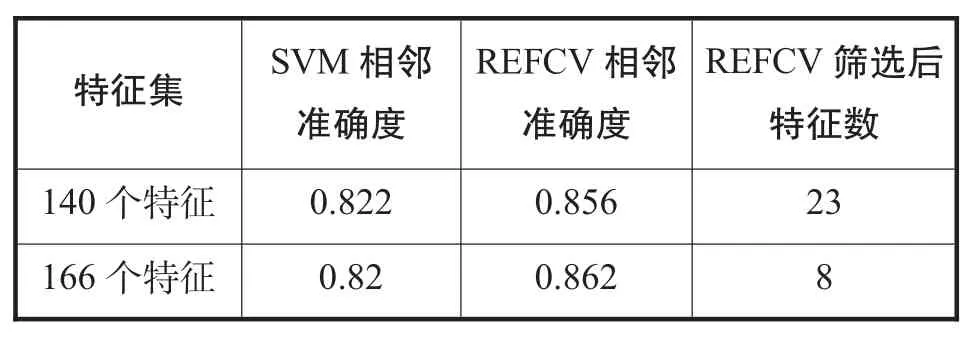
表5:核心影响因素的相邻准确度
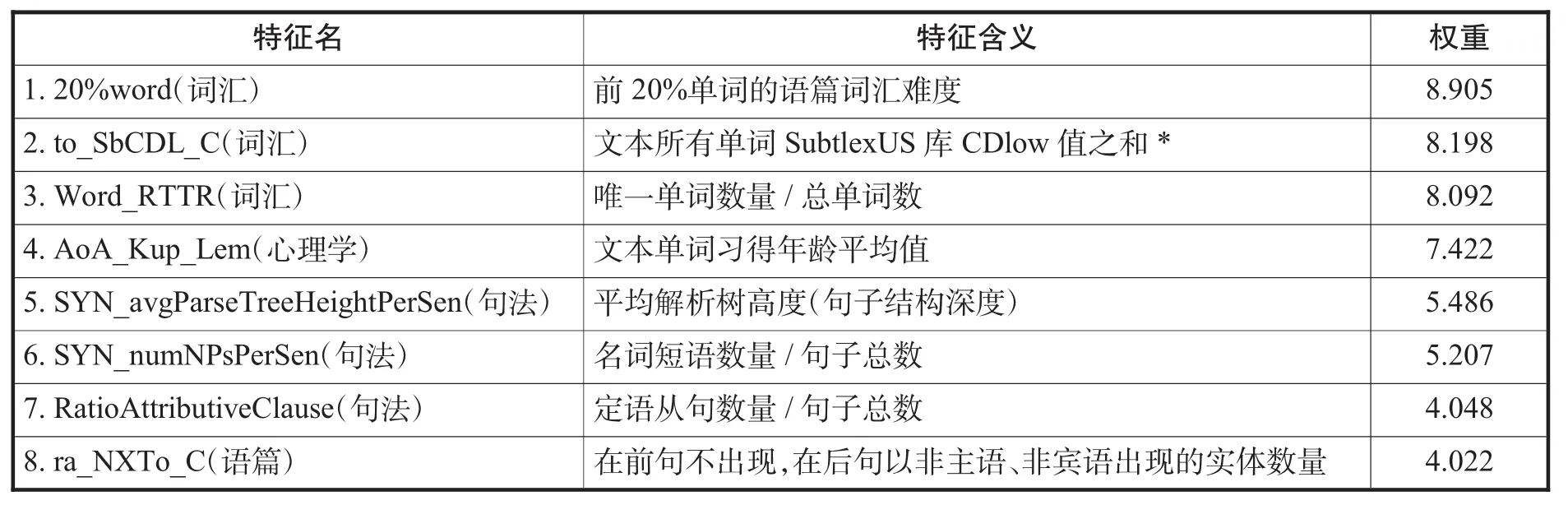
表6:特征排序及权重
综合两项实验:影响文本可读性的关键因素涉及词汇、心理、句法和语篇,重要性依次递减,时态、语态等谓语结构特征并非主要因素。结合英语教学经验认为:提升英语阅读能力的关键在于:提升词汇量(包括词汇数量、重点词汇区分和使用)、扩展认知广度、提升复杂长句解析能力。这些对学生英语阅读水平的提高有重要意义。从实验数据看,时态、语态等语法特征对英语文本可读性的影响不大,但其对于英语学习的其他方面,特别是写作和口语表达,依然具有重要意义,不应该被忽视。
五、结论
利用自然语言处理和人工智能技术的研究成果,分析了《双语学习报》小学四年级至高中三年级九个年级共900篇英语阅读文本。实验结果显示:影响二语阅读的关键语言因素包括难词、词汇丰富度、心理认知水平、句法结构和语篇连贯性等。通过与一线英语教师和英语教学编辑的交流,认为数据分析结果与一线英语教学经验一致:英语阅读能力的提升可重点从词汇教学、认知扩展和句法分析等方面入手。希望这一工作可为广大英语教育工作者提供数据支持:通过语料分析验证英语工作者的经验,实现信息技术与英语教学实践的有机结合,利用人工智能技术助力英语教学。
猜你喜欢
意林·作文素材(2022年3期)2022-03-19
中国卒中杂志(2021年7期)2021-07-31
大连民族大学学报(2021年2期)2021-07-16
天津外国语大学学报(2021年1期)2021-03-29
中华诗词(2018年3期)2018-08-01
中华诗词(2018年11期)2018-03-26
新闻前哨(2015年2期)2015-03-11
中国记者(2014年2期)2014-03-01
当代修辞学(2014年3期)2014-01-21
当代修辞学(2014年1期)2014-01-21
