
人脸活体检测综述
2022-01-27 04:27谢晓华卞锦堂赖剑煌
中国图象图形学报 2022年1期
谢晓华,卞锦堂,赖剑煌
1. 中山大学计算机学院, 广州 510006; 2. 广东省信息安全重点实验室, 广州 510006
0 引 言
人脸识别是一种方便、自然且高精度的生物特征识别技术,一直是模式识别和计算机视觉领域的研究热点。近年来,人脸识别无论在技术上还是应用上均取得了重大进展。人脸识别技术的不断成熟得益于数十年间研究人员对人脸特征提取技术和机器学习方法的不断推进。早在20世纪90年代初,随着特征脸方法 (Turk和Pentland,1991) 的引入,关于人脸识别技术的研究便开始流行。在21世纪初,基于局部特征如Gabor(Liu和Wechsler,2002)和局部二值模式(local binary patterns,LBP)(Ahonen等,2006)的人脸识别技术开始进入商用。随着深度学习 (Krizhevsky等,2012;LeCun 等,2015;He等,2016) 在大规模目标分类图像数据集ImageNet (Deng等,2009)取得突破性成功,研究人员将之应用于人脸识别。在随后几年里,研究人员提出了各种基于深度神经网络的人脸识别方法,并在复杂的人脸识别数据集上取得了较高的识别精度,在某些任务上甚至超越了人类识别水平。如今,人脸识别技术在人们的日常生活中得到了广泛的应用,如手机解锁、账户验证、门禁系统、金融支付和公安追逃等,给智慧城市和平安城市建设提供了重要支撑。
然而,现有的人脸识别系统仍存在诸多安全隐患。由于人脸信息的易获取性,冒名顶替者可以简单地通过呈现合法用户的面部伪装来骗过人脸识别系统,该行为称为人脸欺诈攻击或者人脸伪装(face spoofing)(Biggio 等,2012;Chingovska等,2014;Akhtar等,2015)。人脸伪装技术严重威胁到人脸识别技术的安全性和可信度,不仅给用户的财产和隐私造成巨大的安全隐患,还给公共安全管理带来较大挑战。
常见的人脸欺诈攻击方式包括打印人脸照片、屏幕播放人脸和戴3维面具等。经过巧妙设计,这些攻击方式不仅能提供逼真的人脸纹理,还能提供3维结构信息和动态信息,甚至能虚实结合,具有较高欺诈性。近年来,人脸识别系统对上述人脸欺诈攻击的脆弱性已经越来越多地得到了学术界和工业界的重视。研发具有反欺诈攻击能力的安全可信人脸识别系统是十分必要的。人脸反欺诈(face anti-spoofing)亦称呈现攻击检测(presentation attack detection,PAD)或者人脸活体检测(face liveness detection),顾名思义,这是一种检测或验证待识别对象是真正人脸还是伪造人脸的技术。随着人脸识别技术在社会生产生活各行各业中越来越广泛的应用,为了保障人脸识别系统的安全性,发展人脸欺诈检测技术十分必要且迫切。研究人员已提出了大量相关技术,并有部分技术已经进入实际应用。
近年来,一些研究者发表了人脸反伪装技术的综述论文。但是已有论文一般都针对其中某一类型技术进行总结或者涉及更大技术范围而非聚焦于人脸活体验证。譬如,Ramachandra和Busch(2017)仅对基于传统手工特征的人脸活体验证方法进行了总结;Husseis等人(2019)对生物特征识别系统中的人脸、指纹、虹膜和手写签名等的活体检测方法进行了总结,由于其涵盖范围较广,对人脸活体验证技术的总结比较宏观;Jia等人(2020a)侧重对面向3D面具攻击的人脸活体验证技术进行总结; El-Din等人(2020)侧重对基于卷积神经网络的人脸和虹膜活体验证研究进行总结;孙哲南等人(2021)对生物特征识别近年来的发展做出了一个全面的总结,其中对人脸活体验证技术只做了篇幅有限的大体介绍;卢子谦等人(2020)对人脸活体检测方法的综述侧重于算法层面且内容偏少。
不同于先前的综述研究,本文从人脸反欺诈公开数据集、硬件、算法、业界应用与行业标准等方面力争对人脸欺诈检测的整个研究和应用体系进行系统论述,归纳总结已有的技术与应用进展,并讨论未来的研究挑战。
1 人脸欺诈问题及欺诈检测技术总览
人脸欺诈攻击主要目的是冒充特定人的身份,应用场景主要为通关、代替考勤和盗取账户进行支付等。常用的欺诈方式主要包括打印攻击(即用打印在纸上的面像欺骗人脸识别系统)、屏显攻击(即在数字屏幕上展示人脸视频、照片或者3维模型来欺骗人脸识别系统)与面具攻击(即伪装者戴上面具欺骗人脸识别系统)。在实际中,以上攻击方式还会加载多种技巧,譬如将打印人脸进行弯曲使其具有大体的人脸3维结构;亦有将眼睛和嘴巴位置挖空的打印人脸盖在假冒者脸上(实际上等同于一个简易面具),从而实现将真脸关键部件的运动融入假脸中。一般而言,一个好的人脸假冒技术旨在呈现逼真的表观纹理、精准的3维人脸结构、合理的人脸运动和鉴别性的目标身份特征。
为了保证人脸识别系统使用的安全性和可信性,如何在人脸识别之前检测上述攻击已经成为人脸识别界日益关注的问题。早在本世纪初就有部分研究人员开发了人脸活体验证技术(Frischholz和Dieckmann,2000;Frischholz和Werner,2003;Chetty和Wagner,2006)。针对不同类型的伪装攻击模式,传统的人脸活体检测方法主要通过分析视频图像的纹理信息、运动信息、图像质量、结构信息和3维形状信息来鉴别真伪,必要时通过用户交互动作以及通过闪光等改变环境的方法来辅助分析。一些特殊的方法则通过测量生理特征如心率、血液流动来进行活体检测。为了采集上述各种类型的信息,有时需要借助特有的传感硬件。常见的人脸欺诈攻击方式如表1所示。

表1 常见的人脸欺诈攻击方式Table 1 Common methods of face spoofing
值得指出的是,近年来出现一类新的人脸识别攻击技术,其目的是防止暴露被识别者的身份,即用户旨在引导人脸识别系统的识别结果不是自己的身份即可,其应用场景主要为反追逃、主动保护隐私等。该类攻击采取的方式主要为戴眼镜(Sharif等,2016)、在真脸上张贴局部贴纸(Komkov和Petiushko,2019;Guo等,2021;Yin等,2021)、胡子和眉毛。由于这种方式在真实人脸上进行局部改动,可以骗过一般的活体检测方法,从而对人脸识别系统的安全性构成威胁。目前,针对这类攻击的检测方法研究还不多,因此不属于本文的主要讨论内容。
2 人脸活体检测的传感设备
为了提取丰富的信息实现欺诈检测,研究人员已经尝试采用多种传感设备进行数据采集。除了最常用的RGB摄像头,双目相机、(近)红外相机、深度相机、3维扫描仪、光场相机和多光谱成像仪均处于应用之列,此外,闪光灯也被用于辅助。
根据RGB相机采集的图像,可以获取人脸的表观颜色、纹理和阴影等信息,从而可以根据表观特征或者成像质量来进行人脸伪装检测。如果采用视频,还可以进一步捕捉人脸的运动信息甚至估计人脸的3维信息、活性生理信息用于人脸活体检测。
如表1所示,打印照片或者屏显均无法提供丰富的人脸3维形状,因此应用3维信息可以有效检测上述两类攻击。为了获取待检测人脸的3维形状,双目相机、深度相机和光场相机均可考虑。
虚假人脸与真实人脸的一个重要区别在于表面反射特性。热红外、近红外和多光谱成像(Zhang等,2011)均可实现提取诸类信息,因此也被研究人员应用于人脸活体检测。譬如,在近红外光谱的上部波段,人类皮肤具有极低的反射率,因此使用双波长的反射率测量可以将真实人脸与部分人工材料区分开来(Zhang等,2011)。
在实际应用中,研究人员发现采用单一传感数据很难同时应对多种类型的欺诈攻击。譬如,使用深度相机可以有效地检测打印照片或者屏显攻击,但是难以应对3D面具攻击;热辐射可以区分人造材料与真实皮肤,但是热辐射也会穿透人工材料,当把人工材料覆盖在活体人脸上时又容易骗过基于热辐射的检测器。此外,由于人工材料的多样性,基于近红外传感的方式有时候难以捕捉真实人脸和人工材料面具之间的反射率差异。因此部分研究人员考虑采用多种传感数据结合以提升人脸活体验证系统的性能,当然这也会明显增加硬件成本,尤其在部分移动终端设备上无法装置。
除了考虑采用不同的传感硬件,在实际应用中有一个可以考虑辅助应用的硬件设备是闪光灯。闪光可以协助相机拍摄物体的阴影与反光,间接反映对象目标的3维信息以及反射性质,从而可以增强真实人脸和虚假人脸之间的成像差异。如果采取多种颜色的闪光,所获得的区分信息会更加丰富。此外,闪光可以减少环境光对成像的影响。Chan等人(2018)就提出了一种基于闪光灯的人脸活体验证方法。当然,闪光灯也会降低用户体验。
3 人脸伪装相关数据集
为了支持人脸活体检测研究,研究人员已经构建了许多人脸伪装数据集。本节对相关的数据集进行简单介绍。图1给出了部分数据集的示例,表2—表5给出了所有数据集的内容摘要。

图1 人脸欺诈数据集示例Fig.1 Examples of face spoofing datasets

表2 人脸欺诈数据集内容摘录1Table 2 Abstract of face spoofing datasets-1
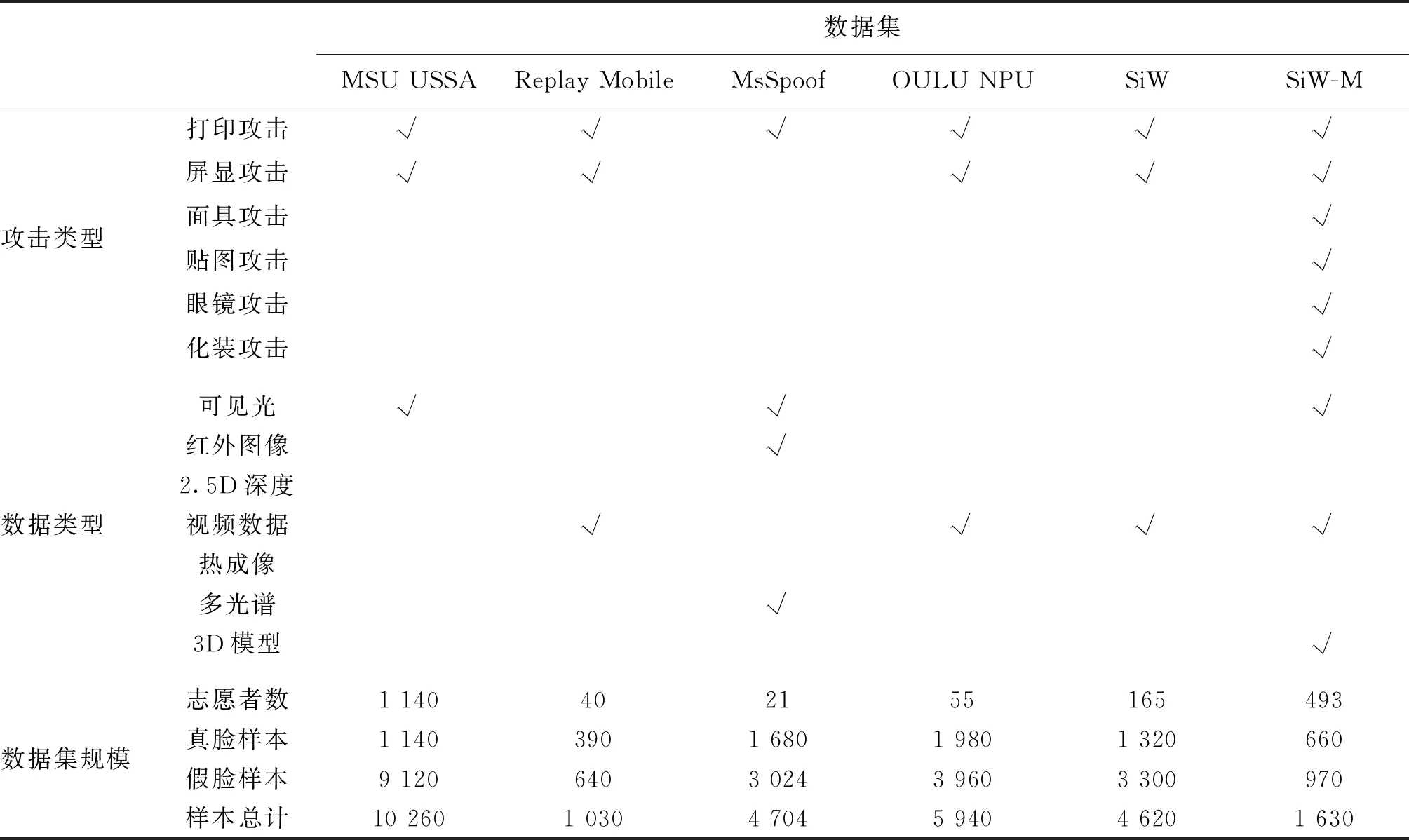
表3 人脸欺诈数据集内容摘录2Table 3 Abstract of face spoofing datasets-2

表4 人脸欺诈数据集内容摘录3Table 4 Abstract of face spoofing datasets-3
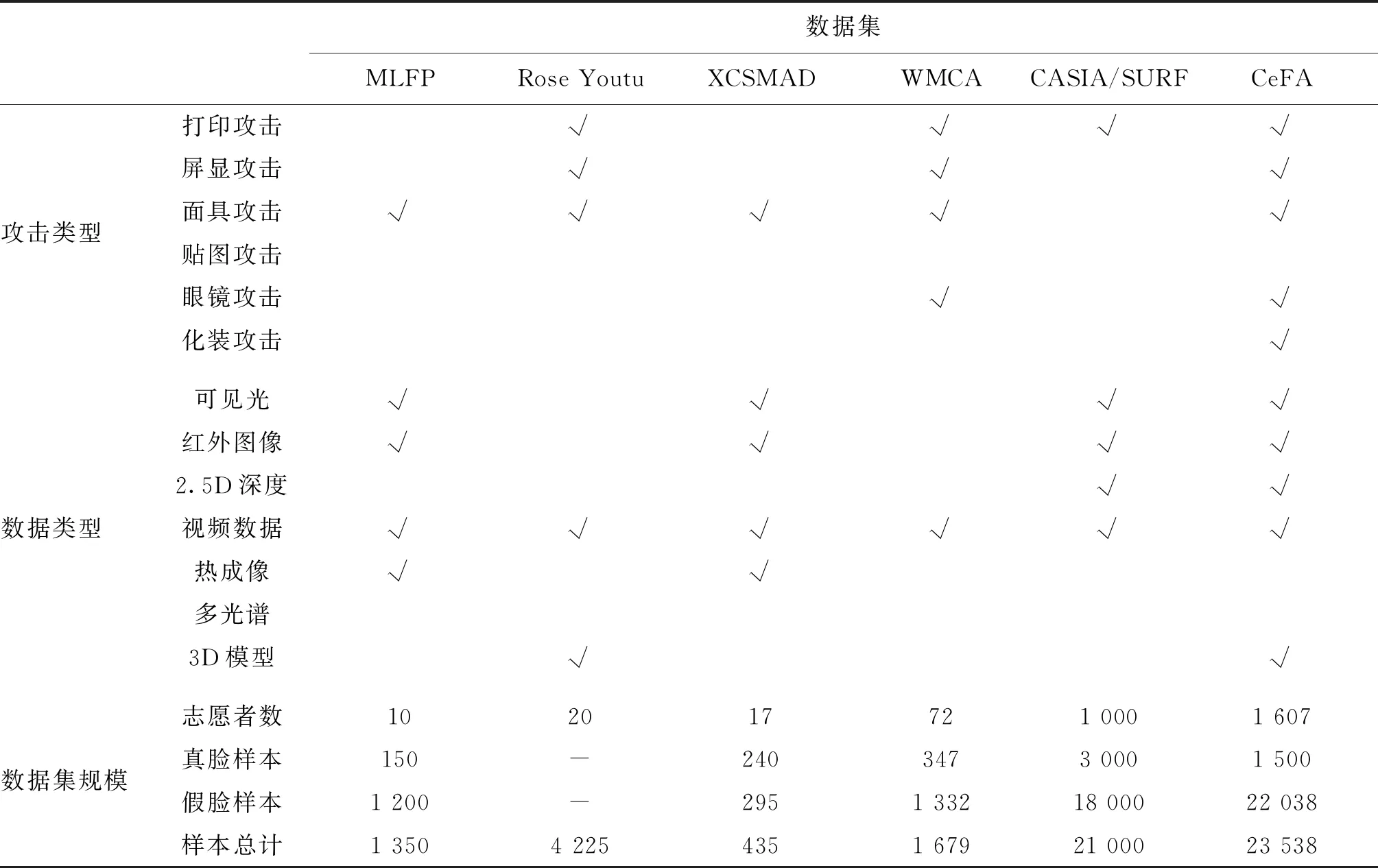
表5 人脸欺诈数据集内容摘录4Table 5 Abstract of face spoofing datasets- 4
3.1 打印及屏显攻击数据集
3.1.1 图像数据集
NUAA数据集(Tan等,2010)是最早公开的人脸欺骗数据集之一,包含来自15名受试者的12 614幅图像,包括真人面部图像及手持打印人脸照片翻拍图像。所有图像用普通的电子摄像头采集。
YALE-Recaptured数据集(Peixoto等,2011)包含来自10名不同受试者的2 560幅图像,其中640幅是真实用户的静态人脸图像,1 920幅是攻击样本。其中的真实样本图像来源于Yale 人脸数据库—B数据集(Georghiades等,2001)。攻击样本在3种不同的LCD(liquid crystal display)液晶显示器上显示真实图像: 1)LG Flatron L196 WTQ Wide 19”;2)CTL 171Lx 1700 TFT;3)DELL Inspiron 1545 notebook。然后用两台不同的相机,一台分辨率为820万像素的柯达C813和一台500万像素的三星Omnia i900重新拍摄了这些图像。在重新捕获过程后,样本被裁剪并标准化为大小是64×64像素的灰度图像。
3.1.2 视频数据集
PRINT-ATTACK数据集(Anjos和Marcel,2011)由来自50名不同受试者的200个真实访问视频和200个打印照片攻击视频组成。该数据集的视频序列由MacBook笔记本的摄像头采集,分辨率为320×240像素,帧率为25帧/s,每段视频平均持续时间约10 s。攻击使用50名用户的高分辨率打印照片。这些照片是在相同的照明和背景设置下,用一台1 210万像素的佳能PowerShot SX150 IS相机拍摄的,然后用Triumph-AdlerDCC250彩色激光打印机打印在普通A4纸上。
IDIAP Replay-Attack数据集(Chingovska等,2012)由1 300个视频组成,记录了50个不同主题的真实用户人脸访问和欺骗攻击行为。在相同的数据采集条件下(受控光照和逆光照),分别通过打印照片,用手机上屏幕显示照片/视频,用高清屏幕显示照片/视频实现欺骗攻击。
CASIA FASD(CASIA face anti-spoofing dataset)数据集(Zhang等,2012)包含600个真实人脸和虚假人脸的视频。该数据集记录了50名不同被试者的真实访问和欺诈攻击行为。CASIA数据集在采集设备(高分辨率索尼NEX-5相机和低质量USB相机)、面部变化(姿势和表情变化)和攻击方式(扭曲照片、剪切照片和高清显示视频)方面均具有多样化。
MSU MFSD(MSU mobile face spoofing dataset)数据集(Patel等,2016)由采集自35名被试者的包含真实和虚假人脸的280个视频组成。这些数据用两种相机拍摄:一种是MacBookAir 13英寸笔记本电脑的内置摄像头,另一种是谷歌Nexus5Android手机的前置摄像头。笔记本电脑摄像头的视频分辨率为640× 480 像素,手机摄像头的视频分辨率为720×480 像素。每个视频的持续时间至少为9 s。
无约束智能手机欺骗攻击(MSU unconstrained smartphone spoof attack, MSU USSA)数据集(Patel等,2015)包含采集自155名受试者的465段视频。在这465个视频中,155个视频是真实人脸视频,其余310个视频是通过在MacBook屏幕上显示CASIA FASD和MSU MFSD数据库的人脸视频并分别使用谷歌Nexus5的内置后置摄像头和iPhone6、4的内置后置摄像头进行翻拍重现。Replay-Mobile(Costa-Pazo等,2016)数据集包含40名受试者在两种光照条件下(房间内开灯与关灯)采集的视频,每个视频大约10 s时长,帧率为30 帧/s,分辨率为720×1 280 像素。在每个照明条件下,用户使用两种设备捕获受试者的视频,包括iPad Mini 2 6平板电脑和LG-G4 7智能手机。
MsSpoof数据集(Chingovska等,2016)由采集自21名受试者的4 704个视频组成,其中1 680个真实访问样本,3 024个攻击样本。数据集用可见光和近红外两种摄像头进行采集,使用照片打印攻击。
OULU-NPU数据集(Boulkenafet等,2017a)由4 950个真实访问和攻击视频组成。这些视频使用6个移动设备(三星Galaxy S6 edge、HTC Desire EYE、魅族X5、华硕Zenfone Selfie、索尼XPERIA C5 Ultra Dual和OPPO N3)的前置摄像头在3个不同光照条件和背景场景的会话中录制。包含的攻击类型为打印和视频重放攻击。
SiW(spoof in the wild database)数据集(Liu等,2018b)由493名受试者的视频组成,共包括660个真实样本和968个攻击样本,由13种不同的攻击类型组成,收集于不同的会话、姿势、灯光和表情变体中。攻击类型包括打印和屏显,视频分辨率为1 920×1 080像素。
SiW-M(spoof in the wild database with multiple attack types)数据集(Liu 等,2019)包含自493名受试者的660个真实访问视频和968个攻击样本视频。数据集包含两种欺骗场景:模拟(需要使用欺骗来识别为其他人)和混淆(需要使用移除攻击者自己的身份)。总共录制了13种欺骗攻击的1 080 P高清视频,包括打印攻击、屏显攻击、5种面具攻击、3种化妆攻击和3种部分贴图攻击。视频由罗技C920网络摄像头和佳能EOS T6录制。
3.2 3维面具攻击数据集
3DMAD(3D mask attack database)数据集(Erdogmus和Marcel,2013b)包含17名不同受试者的255个视频序列,采用微软Kinect RGB-D摄像机记录。视频内容包括真实人脸访问和3D面具欺诈攻击。为每名受试者提供两种面具,一种真人大小的可穿戴面具和一种纸工艺面具。
Morpho数据集(Erdogmus和Marcel,2014)是一个非公开的3D面具攻击数据集。这个数据集包含20名被试者的406个样本,其中207个真实用户和199个面具攻击样本,包含3维扫描和2维灰度图像。
3DFSDB(3D-face spoofing database)数据集(Galbally和Satta,2016)包含26名受试者(13名男性和13名女性)的真实人脸和虚假人脸两类样本。每一类样本都包含2D视频、2.5D数据以及3D模型。面具使用两种较低成本的3D打印机ShareBot Pro和CubeX进行打印。面具材料使用丙烯腈—丁二烯—苯乙烯(ABS)塑料材料。
BRSU(BRSU skin/face database)数据集(Steiner等,2016)包含佩戴各种面具和伪装的137名受试者的多光谱短波红外图像和RGB图像。数据集考虑了两种场景,即使用硅胶、塑料和其他合成材料制作的面具进行人脸伪装。
HKBU-MARs-v1(HKBU 3D mask attack with real world variations database-v1)数据集(Liu等,2016)采用分别由ThatsMyFace和REAL-F两家公司生产的12个外观质量不同的面具作为攻击。从7种摄像机和6类典型的照明设置组合下采集了1 008个视频。
HKBU-MARs-v2(HKBU 3D mask attack with real world variations database-v2)数据集(Liu等,2020)总共包含采集自16名受试者的480个视频,每段视频时长10 s。在每种照明条件下,每名真实和戴面具受试者分别拍摄了三个和两个视频。

MLFP(multispectral latex mask based video face presentation attack database)数据集(Agarwal等,2017)包含戴面具和不戴面具的共10名受试者的1 350个视频。这些视频在无约束的环境中拍摄。其中1 200个视频的受试者戴着面具,剩下的150个视频中的受试者不戴面具。受试者的年龄为23—38岁,最短视频持续时间约为10 s。
Rose Youtu(Rose-Youtu face liveness detection dataset)数据集(Li等,2018b)由20名受试者的4 225个视频组成。这些视频使用多个不同分辨率的采集设备(分辨率为640× 480像素的Hasee智能手机,分辨率为640× 480像素的华为智能手机,分辨率为640× 480像素的iPad4,分辨率为1 280×720像素的iPhone 5s手机,以及分辨率为1 280× 720像素的中兴智能手机)拍摄。主要有3种不同的欺骗攻击,即打印照片攻击、视频重放攻击和面具攻击。
XCSMAD(extended custom silicone mask attack dataset)数据集(Kotwal等,2019)包含采集自17名受试者的240个真实样本和295个攻击样本,每个样本视频时长约10 s。数据类型包括3种模态,分别是可见光图像、红外图像和热成像图像。对于每个演示捕获4个视频数据通道:可见光、近红外(860 nm)和两个长波红外通道。其中两个外红通道分别使用低成本紧凑型热像仪和昂贵的Xenics Gobi热像仪进行数据采集。
WMCA(wide multi-channel presentation attack)数据集(George等,2019)包含72名受试者的1 679个视频。数据集包括4种模态数据,即颜色、深度、红外和热成像,包含多种不同类型的攻击:打印、屏显、眼镜、假头、硬面具、软硅胶面具和纸面具。使用Inter RealSense TM SR300捕捉RGB、近红外和深度视频流,同时使用Thermal Compact PRO记录热通道的热成像视频。
CASIA-SURF(Zhang 等,2019)是一个大规模跨模态人脸欺诈攻击数据集,包含RGB图像、深度图像和红外图像3种模态数据,包含采集自1 000名中国受试者的21 000个视频。每名受试者有1个真实人脸视频和6个假脸视频。使用Intel RealSense SR300相机同时捕获RGB、深度和红外数据。数据库分成训练集、验证集和测试集,分别包含300、100和600名受试者以及14.8万、4.8万和29.5万帧视频。
CeFA(cross-ethnicity face anti-spoofing)数据集(Liu等,2021)采集来自美洲、东亚、中亚的1 500名受试者的2D攻击样本。数据类型包括RGB可见光图像、2.5D深度图像以及红外图像。真实样本4 500个,攻击样本13 500个,共计18 000个。另外包含采集自107名受试者的3D攻击样本共5 538个,其中采集自99名受试者在6种光照条件下的面具攻击样本5 364个,采集自8名受试者在4种光照条件下的胡子或者眼镜攻击样本192个。针对3D攻击的样本全部以视频形式存储。
4 人脸活体检测算法
本文对已有的人脸活体检测算法进行分类介绍,主要包括基于经验手工特征的方法、基于深度学习的方法、新范式学习方法和面向未知类型攻击的检测方法。
4.1 基于手工特征的方法
根据提取特征的特性,将基于手工特征提取的方法分为基于纹理、图像质量、脸部运动、生理信号和3维结构的方法。
4.1.1 基于纹理的方法
基于纹理分析的方法广泛用于人脸活体验证技术的研究。Li等人(2004)提出了基于傅里叶谱分析的方法,主要假设为真实人脸图像比打印照片图像包含的高频成分多。Tan 等人(2010)利用基于变分Retinex的方法和高斯差分(difference of Gaussian, DoG)的滤波器提取人脸图像的潜在反射特征,然后训练稀疏低秩双线性判别模型进行分类。受此工作启发,Peixoto等人(2011)提出结合DoG滤波器和标准稀疏Logistic回归模型在极端光照条件下的人脸活体验证算法。之后,Määttä等人(2011)提出根据局部二值模式(LBP)特征进行人脸活体验证。de Freitas Pereira等人(2012)使用时空纹理特征来检测欺诈攻击,具体而言,提出一种称为三正交平面的局部二值模式(LBP from three orthogonal planes, LBP-TOP)算子,将时间和空间信息结合起来作为一个统一的描述子。在Replay-Attack数据集上的实验结果表明,该方法的性能要优于Määttä等人(2011)的方法。Komulainen等人(2013)提出一种基于HOG(histogram of oriented gradient)特征的人脸活体验证算法。Boulkenafet等人(2016b)采用颜色纹理特征对人脸欺诈攻击进行分析。田野和项世军(2018)提出一种将局部二值投影(local binary pattern, LBP)特征与离散余弦变换(discrete cosine transform, DCT)结合起来的人脸活体验证方法,该方法使用支持向量机(support vector machines, SVM)分类器将LBP特征进行多层离散余弦变换后得到的局部二值模式—多层离散余弦变换(local binary pattern and multilayer discrete cosine transform, LBP-MDCT)特征进行二分类,区分真实人脸与虚假人脸。
研究发现纹理分析方法对3维面具攻击的检测同样有效。Kose和Dugelay(2013a)较早将LBP特征用于3D面具攻击检测。Erdogmus和Marcel(2013a)在不同分类器上结合了不同类型的LBP特征进行人脸活体检测。Naveen等人(2016)将LBP和二值化统计图像特征(binarized statistical image features, BSIF)进行融合检测。Agarwal等人(2016)提出了一个基于Haralick纹理特征的人脸活体验证算法,该算法从视频的冗余离散小波变换帧中提取分块Haralick纹理特征用于人脸活体检测。
基于纹理分析的方法的主要缺点是需要高分辨率的输入图像,以便区分欺诈人脸与真实人脸的细微纹理区别。如果图像质量不够好,会导致较高的错误拒绝率。此外,由于图像采集条件和欺骗媒体的多样性,图像纹理模式也变化多样,这使得基于纹理分析的人脸活体验证系统难以具有高鲁棒性。
4.1.2 基于图像质量的方法
假脸实际上为真实人脸的特殊重现,中间经过对纸质打印、屏幕和3维面具等媒介的翻拍,因此相应的人脸图像质量可能会降低。图像质量是人脸活性检测的一个重要依据。Galbally等人(2014)采用25个图像质量评估指标进行人脸活体检测。Wen等人(2015)采用4种不同的特征(镜面反射、模糊度、颜色矩和颜色差异)进行人脸活体检测。该方法先用Tan和Ikeuchi(2008)的方法提取镜面反射分量,然后计算基于镜面反射分量百分比、镜面反射像素均值和方差的统计特征进行真假脸区分。该方法能有效捕捉虚假人脸图像的本征失真。基于图像质量的方法对屏显假脸、低质量的打印脸以及粗糙的3D面具假脸检测比较有效。但是对高质量打印脸以及高仿真面具脸的检测会产生较高的错误接受率。
4.1.3 基于3维结构的方法
所谓的结构信息是指真实人脸在空间中拥有的3维形状信息(Bhattacharjee和Marced,2017)。3维信息是检测打印假脸以及屏显假脸的重要依据。为获取人脸的3维信息,最直接的方式是采用双目相机或者深度相机。但是在实际应用中,单RGB摄像头是最常见的硬件配置,因此大量研究工作仍然聚焦于如何基于单目摄像头估计人脸的3维信息用于真假脸判别。
基于纸张或者屏幕均为平面的假设,de Marsico等人(2012)提出了一种基于3维投影不变量的运动人脸反欺骗方法,有效对平展的打印假脸以及屏幕脸进行了检测。然而,由于共面假设对扭曲的照片无效,因此该方法难以防止弯曲照片攻击。Wang等人(2013)提出恢复人脸图像的稀疏3维形状来检测各种照片攻击。Kim等人(2015)基于2维表面的光照比3维表面的光照扩散慢、强度分布更均匀的客观事实,使用扩散速度来检测真假脸。
Kose和Dugelay(2013b)运用扭曲参数(warping parameters, WP)提取了人脸3维形状信息用于真假脸辨别。Tang和Chen(2017)提出综合几何属性、主曲率测度和网格尺度不变特征变换(scale invariant feature transform, SIFT)的人脸活体验证方法。Hamdan和Mokhtar(2018)提出利用角—径向变换(angular radial transformation,ART)进行真假人脸的判别。Wang等人(2018b)提出了一种联合使用纹理和形状特征来抵抗3D人脸面具攻击的新方法,其中通过3维变形模型从RGB图像中重建几何形状。
作为新一代相机,光场相机(light-field camera),也称为全光相机(plenoptic camera)采用显微镜阵列成像,可以较好地估计景深信息。光场相机也可应用于人脸活体验证任务。Kim等人(2014)较早借助光场相机获得人脸的结构信息,将之用于人脸活体验证。Raghavendra等人(2015)提出一种利用光场摄像机的固有特性,通过估计多幅深度图像的焦距变化来检测人脸攻击。Zhe等人(2016)基于光场相机提出了一种新的综合颜色强度分布和景深分布光场(light and flow histogram of oriented gradients, LFHoG)描述子,并将之用于人脸检测和活性判别。Xie等人(2017)利用光场相机的聚焦效应来区分假人脸和真人脸,即对4D光场进行采样得到两幅不同焦距的图像,并基于这两幅图像提取3种特征用于人脸的活性检测。
简而言之,基于3维结构的方法从理论上检测打印假脸及屏显假脸具有较大合理性。存在问题在于如何从单目图像中估计3维信息本身是一个病态问题,另外此类方法的计算复杂度高。
4.1.4 基于脸部运动的方法
脸部运动是一种重要的活体信号,是区别活体与假体比较有效的依据,已经成功应用于人脸活体检测商业软件中。
部分基于运动特征提取的人脸活体验证方法在验证过程中需要用户予以动作配合,如眨眼、嘴唇运动、摇头等。Pan等人(2007,2008)提出使用眨眼作为活体验证的依据,构建了条件随机场来模拟眨眼的不同阶段。也有研究者(Kollreider等,2007)使用嘴唇运动作为活体验证的依据。Chetty(2010)提出一种使用音频和视频信号的多模态匹配方法来验证人脸是否是活体信号。Alsufyani等人(2018)提出通过跟踪用户的注视同时对随机移动的视觉刺激作出反应来检测人脸识别系统的活性。该方法假设如果凝视与刺激轨迹足够相似,用户的尝试就被认为是真实的。
部分方法通过捕捉用户的微运动特征进行活体检测而不需要进行交互。Chingovska 等人(2013)将由于人体血液的自然流动导致脸上出现的微小颜色和运动变化作为活体人脸的验证依据。Tirunagari等人(2015)则提出用面部表情变化作为检测依据。
尽管基于脸部的运动特征是一个有效的活体验证方法,但是在面对具有运动特征的攻击,例如视频回放,使用基于运动特征的方法仍存在风险。
4.1.5 基于生理信号的方法
生理信号是另外一种重要的活体信号,也是区别真实人脸与人造材料比较有效的依据,因此也被应用于人脸活体检测。这类方法也是目前受业界重视的人脸活体检测方法之一。
相关领域的研究者们提出了远程光体积描记术(remote photo plethysmo graphy,rPPG)(Heusch和Marcel,2019)。这是一种新的生物医学技术,基于接触式PPG的原理,可以通过普通RGB摄像机远程测量人类的心跳,进而通过模拟心跳引起的肤色变化来测量血液脉搏流量。通过对远程光电体积描记术rPPG信号的频域分析,可以直观地提取出rPPG信号的活性特征。由于人造材料具有低透射率特性,基于rPPG的活性信号只能在真实人脸上观察到,而在面具、打印脸和电子屏幕上无法观测到,因此rPPG信号非常适用于人脸活体检测。
Heusch和Marcel(2018)提出根据rPPG提取方法获得脉冲信号的长期谱统计(long term spectrum statistics,LTSS),进而将LTSS特征与SVM相结合进行人脸欺诈攻击检测。Li 等人(2016b)将rPPG检测方法应用于3D面具欺诈检测。Liu 等人(2018a)提出一种针对3D人脸面具攻击检测的rPPG的对应特征CFrPPG,该特征能够更准确地反映人脸的活性证据。为了在缩短观测时间的同时获得更好的性能,Liu等人(2020)提出了时间相似性rPPG(temporal similarity of rPPG,TSrPPG)方法用于快速3D面具攻击检测。与在频域利用长期观测的心跳信号进行频谱分析的方法不同, TSrPPG通过对rPPG信号的时域波形分析,在1 s内就能够提取出心跳信号的痕迹。
4.2 基于深度学习的方法
在计算机视觉领域,数据驱动的深度学习方法经常表现优于基于手工特征的方法。深度神经网络也已经用于人脸活体验证技术,且成为当前的研究热点。
4.2.1 单纯数据驱动的深度学习方法
Yang等人(2014)较早使用卷积神经网络提取特征用于人脸活体验证,其中使用支持向量机进行二分类。Menotti等人(2015)将网络搜索技术应用于人脸活体检测。Li等人(2016b,2018a)提出基于3维卷积神经网络的视频人脸活体检测方法。Yu等人(2020a)提出了运用双边卷积网络(bilateral convolutional networks)聚合多层次的双边宏观和微观信息来捕获内在的基于材料的模式,此外,该方法利用多级特征求精模块(multi-level feature refinement module)和多头监督来学习更具鲁棒性的特征。Xu等人(2015)提出了一种结合长短时记忆(long short term,LSTM)单元和卷积神经网络(convolutional neural networks,CNN)的深度神经网络结构,利用LSTM单元从输入序列中寻找长关系,并通过卷积运算提取局部和稠密特征,有效地检测了人脸欺诈攻击。Yu等人(2021)将像素级的监督学习应用于人脸活体检测,具体而言,他们提出了一种新的插入式金字塔监督机制,能够为细粒度学习提供丰富的多尺度空间上下文信息。提出的金字塔监督机制不仅可以提高现有像素级监督框架的性能,而且可以提高模型的可解释性。
即使基于单张照片,深度学习方法对3维面具假脸的检测效果仍然比较明显(Li等,2016a)。Menotti 等人(2015)研究了两种不同的生物特征深度表示模型。一种是网络结构超参数优化(architectures optimization,AO),另一种是反向传播滤波器权重优化(filter optimization,FO)。并探索了AO、FO、AO+ FO等3种方法在3维面具攻击检测上的应用。Feng等人(2016)将图像质量分析的剪切波(shearlet)与运动线索中的稠密光流结合起来,提出一个检测3D面具攻击的分层深度神经网络模型。Shao等人(2017)提出深度卷积动态纹理学习,即从卷积神经网络的卷积层中学习动态纹理信息用于3维面具假脸检测,该方法能够捕捉到真假人脸细微的运动差异。
深度学习方法在融合多模态数据用于人脸活体检测方面也具有较大优势(Parkin和Grinchuk,2019)。George和Marcel(2021)提出了一种帧级RGB-D人脸防伪方法,其中提出采用跨模态焦点损失(cross-modal focal loss,CMFL)处理多流结构中对单个通道的监控。Zhang等人(2019)提出了一个融合3种模态数据用于人脸活体检测的深度学习方法,该方法对模态相关的特征进行重加权,以选择信息量较大的信道特征。Wang等人(2019b)提出一种基于空间和信道注意力的端到端学习多模态融合方法,该方法使用不同的深度网络通道处理不同模态的数据,包括2D和3D可见光图像、红外数据等。
基于深度学习的人脸活体验证方法取得了比传统手工特征方法更好的性能,大大提高了人脸活体验证方法的精度,尤其在用单幅图像时也可以较好地检测出3维面具欺诈,极大地促进了人脸活体验证技术的发展。由于深度学习方法的不可解释性和低泛化能力,如何进一步提高基于深度学习的人脸活体验证方法的可解释性、可控性和泛化能力是值得继续研究的问题。
4.2.2 跨域迁移的深度学习方法
当面向某种特定场景的训练数据集充足的时候,基于深度学习的方法一般可以取得不错的检测效果。但是在实际应用中难以保证在每种场景下都有足够多的训练集。因此,当特定场景的训练数据受限的情况下,如何充分利用其他场景的数据集来提升特定场景的模型性能,成为机器学习领域研究人员重点关注的问题。为解决这个问题,各种迁移学习或者域自适应学习方法相继提出。迁移学习和域自适应的目的是解决目标域在某一分布下而源域的训练数据在另一分布下的学习问题,即将源域学习到的知识或者模型迁移到目标域(Ganin和Lempitsky,2015)。
在人脸活体验证领域,相关的研究人员也发展出了许多基于域自适应的人脸活体验证方法来克服模型泛化能力差的问题。Yang等人(2015)提出了一种针对特定人的人脸活体验证方法。这种方法使用为每个主题(人)专门训练的分类器识别欺诈攻击,从而消除主题之间的干扰。考虑到训练中虚假样本的稀缺性或无效性,他们使用域自适应方法来合成虚拟假样本进行模型训练。Lucena等人(2017)提出了一种基于迁移学习的深度神经网络来识别照片、视频和3D面具攻击,在3DMAD数据库上实现了0%的半全错误率(half total error rate,HTER)。Li等人(2018b)提出了一种无监督域自适应的人脸活体验证框架,将源域数据和目标域数据映射到一个可度量分布相似性的新空间,然后通过最小化最大平均偏差(maximum mean discrepancy,MMD)(Gretton等,2012)将源域特征空间转换为未标记的目标域特征空间,从而学习到泛化能力更强的分类器。Wang等人(2019a)提出了一种端到端跨域学习方法,利用源域的先验知识通过对抗域自适应学习共享的嵌入空间,最后在嵌入空间中使用分类器对目标域进行人脸活体验证,提高了人脸活体验证的泛化能力。Wang等人(2020b)提出了一种新的端到端可训练人脸活体验证方法,称为无监督域自适应解纠缠表示(unsupervised domain adaptation with disentangled representation,DR-UDA)。该方法利用目标域中的未标记数据和源域中的标记数据建立鲁棒人脸活体验证模型,以提高人脸活体验证模型在新场景中的泛化能力。El-Din等人(2021)提出了一种基于域自适应的端到端学习框架,利用标记的源域样本,训练特征提取器和分类器,再利用目标域的无监督数据进行对抗性数据挖掘,使模型学习到域不变特征。为了保持目标域的固有特性,他们对目标样本进行深度聚类。
除了使用域自适应方法外,也有相关研究使用到了自域自适应方法(Li等,2020)。自域自适应指在推理过程中,在不访问源数据的情况下,使部署的模型适应于不同的目标域,非常适合于人脸反欺骗应用。Wang等人(2021)提出了一个人脸活体验证的自域自适应框架,利用未标记的目标域数据进行推理。特别地,他们设计了一个域自适应器来适应目标域的模型。为了更好地学习自适应器,提出了一种基于元学习的自适应器学习算法。基于域自适应的人脸活体验证方法能够有效提高模型的泛化能力,但是还需要在目标数据空间进行学习,才能够挖掘出源域与目标域之间的关系。而域泛化(domain generalization,DG)(Ghifary等,2015)方法在不访问任何目标数据的情况下,也能显式地挖掘出多个源域之间的关系,从而更好地泛化到不可见域中进行人脸活体验证。DG方法大多着眼于最小化多个源域之间的分布差异来提取域不变特征。Shao等人(2019)为提高人脸活体验证模型的泛化能力,提出了一种新的多对抗判别深度域泛化框架来学习泛化特征空间。在该框架下,在双重三元组挖掘约束下进行了多对抗的深度域泛化,保证了所学习到的空间的判别性。由于特征空间由多个源域共享,该模型对于新的人脸欺诈攻击的泛化能力较强。Jia等人(2020b)提出了一个端到端的单边域泛化框架来提升人脸活体验证模型的泛化性能。具体而言,他们设计了单侧对抗学习和不对称三元组损失函数来得到真实人脸和虚假人脸的不同最优目标,并且执行特征和权重归一化来进一步提升模型性能。Shao等人(2020)将人脸活体验证问题归结为一个域泛化问题,并通过开发一个新的称为正则化细粒度元学习的元学习框架来解决这个问题。该框架在领域知识监督正则化的特征空间中进行元学习。通过这种方法,可以获得更好的用于人脸反欺诈的泛化学习信息。
域泛化方法未从目标数据中学习到任何信息,因此源域的泛化是很难确定的。在学习过程中,一般要施加给模型一些先验信息或者约束,也可能导致过拟合的出现。因此在实际中,基于域泛化模型的泛化能力可能会不适用于实际中人脸活体验证数据的检测和验证,需要结合其他学习范式来增强模型的泛化能力。
4.2.3 结合先验知识的深度学习方法
单纯数据驱动的学习方法一般过度依赖于数据集的分布,难以获得具有强泛化能力的模型。为提高算法的泛化能力,将先验知识结合深度学习成为新的范式。研究人员也将这种范式引入到人脸活体检测器的构建,如采取相关多任务学习、数据特殊预处理和人工提取特征进一步学习等。
Liu等人(2018a)提出基于CNN-RNN(convolutional neural networks-recurrent neural networks)模型借助像素级监督学习来估计图像深度,并通过序列级监督来估计远程心率(rPPG)。估计得到的景深和rPPG进一步应用于人脸活体验证任务。George等人(2019)提出了一种基于多通道卷积神经网络(multi-channel convolutional neural network,MC-CNN)的人脸活体验证学习框架。MC-CNN引入人脸身份识别任务来辅助人脸活体检测学习。Jourabloo等人(2018)提出将虚假人脸逆分解为欺诈媒介和真实人脸,然后利用分解得到的欺诈媒介进行分类以达到人脸活体检测。该方法借助图像分解来辅助人脸活体检测器构建,其中提出了一种具有适当约束和监督的CNN结构,克服了CNN分解没有基本真值(ground truth)的问题。Wang等人(2019a)将从时间序列中恢复的深度信息用于人脸活体验证。该方法提出了一种从多个RGB帧中估计深度信息的新方法,并提出了一种深度监督结构,该结构可以有效地对时空信息进行编码,用于欺诈攻击检测。马玉琨等人(2019)提出了一种基于对抗样本生成模型的人脸活体验证算法,该方法利用人的视觉连带集中特性加入扰动点的间距约束,生成不易被人眼感知的对抗样本。Wang等人(2019b)提出建模空间流和时间流的双流网络用于活体检测,用光流估计任务来进行辅助。Chen等人(2020)提出将双流卷积神经网络(two stream convolution neural network,TSCNN)作用于两个空间:RGB空间和Retinex空间(一种光照无关的空间)。用光照分离任务辅助人脸欺骗鉴别特征的学习。马思源等人(2020)提出基于深度光学应变特征图的人脸活体验证算法,通过提取图像的LBP特征、光流和光学应变图来区分真实人脸与虚假人脸。李策等人(2021)提出使用超复数小波生成对抗网络进行人脸活体验证,借助小波变换来加强深度学习。
4.3 基于更多学习范式的人脸活体验证方法
近年来,各种机器学习范式如神经架构搜索(neural architecture search,NAS)、元学习(mate learning, ML)、非纠缠表征学习(disentangled representation learning,DRL)、对比学习(contrastive learning,CL)和联邦学习(federated learning,FL)等取得了日新月异的发展,促进了模式识别与计算机视觉领域的发展,也成功应用到人脸活体验证。在本节对这些方法做简要介绍。
Yu等人(2020a)提出了一种新的卷积算子,称为中心差分卷积(central difference convolution,CDC),它能够很好地描述细粒度不变信息。该研究展示了在不同的环境中,中心差分卷积比普通卷积更可能提取内在欺骗模式。此外,在一个专门设计的中心差分卷积搜索空间上,利用神经架构搜索(neural architecture search, NAS)发现适合深度监督人脸活体验证任务的优秀帧级网络。进一步地,Yu等人(2020a)提出了一种新的由中心差分卷积算子(central difference convolution,CDC)和池算子(central difference pool,CDP)组成的搜索空间。为了充分挖掘人脸活体验证感知的时空差异,提出了一种高效的静态—动态表示方法。此外,他们提出了域/类型感知的元—神经架构搜索(Meta-NAS),利用跨域/类型的知识进行鲁棒的搜索。Qin 等人(2020)将人脸活体验证问题看做是零元和少元学习问题,为了解决零元和少元学习的人脸活体验证问题,他们提出了一种基于元学习的方法,即自适应内部更新元人脸反欺诈方法(adaptive inner-update meta face anti-spoofing, AIM-FAS)。该方法在零元和少元学习的人脸活体验证问题中融合训练一个元学习器与一个自适应内部更新(adaptive inner-update,AIU)策略。Wang等人(2020a)提出了一种新的跨域人脸欺诈攻击的非纠缠表示学习方法(disentangled representation learning,DRNet),该方法能够将人脸活体验证的信息性特征从对象分类的信息性特征中通过交叉解耦分离出来,使得人脸活体验证的特征学习更加独立于对象。此外,还提出了一种有效的多域特征学习方法来获取与域无关的人脸活体验证特征,增强了人脸活体验证模型的鲁棒性。Mishra等人(2021)提出了使用有监督的对比学习(Jaiswal等,2021)来增加伪造人脸和真实人脸图像之间的域间距,以便进行人脸欺诈检测。Shao等人(2021)提出了联邦人脸活体验证框架,寻求在保护数据隐私的同时,充分利用不同数据拥有者的人脸活体验证信息。
随着新的机器学习范式的提出,各种各样新的人脸活体验证方法也将会被提出,这将会在较大程度上进一步促进人脸活体验证技术的发展,使之在更复杂的现实情境中得到广泛应用。
4.4 面向未知类型攻击的人脸活体验证方法
前面介绍的所有方法均假设人脸欺诈类型是已知的,因而可以根据先验知识设计针对性的特征或者运用相应的数据集进行特征学习,进而进行人脸欺诈检测。在实际中,人脸欺诈的样式和方式层出无穷。基于先验以及数据驱动的模型往往无法识别新类型的人脸欺诈。
针对以上问题,一个直接的解决方案是将不可见攻击作为异常样本处理,对异常样本进行检测。单类分类器(one-class classifiers, OCC)(George和Marcel,2020)通过单独建模真实类别的分布,提供了一种处理不可见攻击场景的直接方法(Perera和Patel,2019)。Arashloo等人(2017)和Nikisins等人(2018)已经证明了OCC对未知攻击的有效性。Fatemifar等人(2019)提出了一种融合多个OCC的方法。Pérez-Cabo等人(2019)从异常检测的角度提出了一种新的人脸活体验证方法,提出了一个新的深度度量学习模型来使网络学习判别特征,然后使用支持向量机进行分类。Liu 等人(2019)提出了一种新的检测不可见攻击的方法,称为零元人脸对抗攻击,具体地说,该方法提出了一种深度树网络(deep tree network),以无监督的方式将攻击样本划分为语义子组。网络中的每个树节点由一个卷积残差单元(convolutional residual unit,CRU)和树路由单元(tree routing unit,TRU)组成,其目的是将未知的攻击发送到最合适的叶节点,以便对其进行正确的分类。Jaiswal等人(2019)提出了一种基于无监督对抗的人脸活体验证端到端深度学习模型。该模型将判别信息和干扰因素在对抗环境中分离,最终只保留判别信息用于人脸欺诈识别。George和Marcel(2021)提出一种基于多通道单类分类器的未知攻击检测方法。
4.5 人脸活体检测方法的应用选择
在上述介绍的人脸活体检测方法中,有的侧重于某类攻击方式,有的则具有一定通用性,因此在实际应用中需要根据具体的应用场景选择适合的人脸活体检测方法。譬如,针对平面打印或屏显照片假脸攻击,几乎所有的人脸活体检测方法都可以应对,基于3维结构、脸部运动和生理信号的方法尤佳,如果配合交互则效果更好。针对一般质量的3维面具攻击,采用基于脸部运动、生理信号和深度学习的方法仍然可以达到较好的防范,甚至一些基于纹理分析的方法也能获得不错的效果。但是针对高逼真度的柔性3维面具攻击,只有基于生理信号以及深度学习的方法能达到一定的防范效果。整体而言,采用多模态数据驱动的深度学习方法以及多传感设备融合方式均有利于应对多种攻击方式。
5 代表算法在主流数据库的检测性能
本节中列举了部分人脸活体检测方法在几个主流数据集上的实验结果,以便从整体上了解当前人脸活体检测算法的水平。相关实验数据直接摘录于方法相应发表的论文。
5.1 性能评估指标
人脸活体检测方法的性能评估指标主要包括:1)攻击表示分类错误率(attack presentation classification error rate, APCER),表示将攻击样本错误分类为真实样本所占的比重;2)真实表示分类错误率(bonafide presentation classification error rate, BPCER),表示将真实样本错误分类为攻击样本所占的比重;3)平均分类错误率(average classification error rate, ACER),ACER为APCER和BPCER的平均值。此外常用的评价指标包括半全错误率(half total error rate, HTER),是错误拒绝率(false rejection rate, FRR)和错误接受率(false acceptance rate, FAR)总和的一半。曲线下面积(area under the curve, AUC)也常用于作为人脸活体检测方法的性能评价指标。实际中一般同时使用多种指标进行综合评价。
5.2 测试结果
实验方式包括数据集内部测试(即训练集与测试集来源于相同数据库)和跨数据集测试(即训练集与测试集来源于不同数据库)。数据集内部测试实验在OULU-NPU数据集和SiW数据集上进行,结果分别见表6和表7。跨数据集测试实验也在两种数据集,即CASIA-MFSD 和 Replay-Attack数据集上进行,结果如表8所示。OULU-NPU数据库包含4种实验协议,以寻求在不同条件下测试活体检测方法的性能。协议1用于评估在不同照明和背景场景下的人脸活体检测算法的泛化性能。协议2旨在通过在测试集中引入以前看不见的表示攻击工具来评估攻击工具变化对人脸活体检测方法性能的影响。协议3在每次迭代中,使用5部智能手机录制的真实视频和攻击视频来训练和调整对抗模型,然后使用其他智能手机录制的视频评估该方法的通用性。协议4将前3个协议的场景混合起来,旨在评估人脸活体检测方法在综合场景下的性能。

表6 在OULU-NPU数据集上进行内部测试的结果Table 6 The results of intra testing on OULU-NPU dataset /%

表7 在SiW数据集上进行内部测试的结果Table 7 The results of intra testing on SiW dataset /%

表8 在CASIA-MFSD 和Replay-Attack数据集上进行跨数据集测试HTER结果Table 8 HTER results of cross dataset test on CASIA-MFSD and Replay Attack dataset /%
本文选取CPqD(Boulkenafet等,2017a),GRADIANT(galician research and development center in advanced telecommunications)(Boulkenafet等,2017a),DeepPixBiS(deep pixel-wise binary supervision) (Boulkenafet等,2017a),MixedFASNet(mixed face anti-spoofing network)(Boulkenafet等,2017a),MILHP(Lin等,2018),Auxiliary(Liu等,2018b),FaceDs(face de-spoofing)(Jourabloo等,2018),FAS-TD(face anti-spoofing with temporal and depth information)(Wang等,2019c),STASN (spatio temporal anti-spoof network)(Yang等,2019),CDCN++(central difference convolutional networks attention mechanism)(Yu等,2020a)等活体检测方法进行对比,实验结果对比如表6所示。评估标准包括攻击表示分类错误率(APCER)、真实表示分类错误率(BPCER)及平均分类错误率(ACER)。从实验结果可以看出,使用其他机器学习范式进行人脸活体检测的误差要比基于卷积神经网络的方法的误差小。这也说明使用其他学习范式对活体检测技术的发展具有很大的促进作用。表7展示了部分人脸活体检测方法在SiW数据集上进行检测的实验结果。SiW数据集包含3种实验协议,以寻求在不同条件下评估人脸活体检测方法的性能。协议1选取90个对象的前60帧视频进行训练,使用剩下75个对象所有视频进行测试。协议2使用90个对象的3个屏显视频进行训练,使用75个对象的1个屏显攻击视频进行测试。协议3的训练集使用打印攻击(或屏显攻击),而测试集使用屏显攻击(或打印攻击)。本文选取进行比较的人脸活体检测方法包括Auxiliary(Liu等,2018b),STASN (Yang等,2019),CDCN++(Yu等,2020a)以及NAS-FAS(Yu等,2020b)。评估标准包括攻击表示分类错误率(APCER)、真实表示分类错误率(BPCER)以及平均分类错误率(ACER)。从实验结果可以看出,相比于其他方法,使用神经架构搜索的CDCN++(Yu 等,2020a)和NAS-FAS(Yu等,2020b)具有更小的检测误差,这是因为其搜索空间更大,使得检测误差更低。
表8展示了在CASIA-MFSD 和Replay-Attack数据集上进行跨数据集测试的结果,即在CASIA-MFSD数据集上进行训练,然后再在Replay-Attack数据集上进行测试,以及在Replay-Attack数据集上训练模型,然后在CASIA-MFSD数据集上进行测试的实验结果。本文选取了手工特征提取方法和基于深度学习的方法进行性能比较,这些方法包括Motion(Tirunagari等,2015),LBP(Määttä等,2011),LBP-TOP (de Freitas Pereira等,2012), SpecCub(spectral cubes)(Pinto等,2015),CoTex(colour texture)(Wen等,2015),卷积神经网络CNN(Yang等,2014),Auxiliary(Liu等,2018b),STASN (Yang等,2019),CDCN++(Yu等,2020a),FaceDs(Jourabloo等,2018),FAS-TD(Wang等,2019c),MMDD (model matters, so does data)(Yang等,2019)。评估指标为半全错误率(HTER)。结果表明,基于深度学习的方法检测错误率要低于基于手工特征设计的方法。并且由于引入各种学习范式,检测错误率相对于单纯地提取深度卷积特征变得更低。
6 人脸活体检测技术的业界应用情况
随着人脸识别技术的广泛应用,人脸活体检测技术的应用也越来越普及。尤其在移动端用户身份验证应用上,人脸活体验证已经成为人脸识别系统不可缺少的一部分。
在现实中,人脸活体验证技术主要应用于无人值守的身份验证场景,如手机开锁、移动端APP登录、银行自助终端机和考勤机。在已有的应用中,目前主要采用了如下几种方式:1)基于单摄像头的交互式验证,即通过指令要求受测者进行配合式动作,如摇头、眨眼、张口和读阿拉伯数字。其中读阿拉伯数字目的除了配合唇语识别之外,有时候还可以附加语音识别。2)基于“可见光+近红外”双模态摄像头的活体验证,其中近红外图像有利于区分皮肤与其他材质。3)基于“可见光+深度”双模态摄像头的活体验证,其中深度摄像头用于获取对象的3维信息。后两种方式通过多种硬件组合可以提取较为丰富的特征用于活体验证。
随着人脸活体检测技术应用的逐步普及,业界也开始考虑相关技术标准的制定。早在2018年,全国信息安全标准化技术委员会发布的《信息安全技术—基于可信环境的远程人脸识别认证系统技术要求》就确立了人脸识别系统中活体检测技术的标准、活体检测防范能力以及活体检测的安全要求等。该标准将人脸识别认证系统的功能、性能和安全要求分为基本级和增强级。其中要求人脸活体检测防范能力活体检测正常通过率宜不小于99%,活体检测攻击拒绝率宜不小于99%。
2020年, 电气与电子工程师协会(Institute of Electrical and Electronics Engineers,IEEE)发布了首个生物特征活体检测国际标准《生物特征识别活体检测标准》(IEEE Std 2790-2020)。该标准规定了人脸活体检测系统的主组成部分,确立了生物特征活性检测领域的术语和定义,并对非活体攻击的特征和活体检测方法进行了辨识,分析了非活体攻击工具,详细说明了活跃度检测过程、实现模型和度量方法。
2020年,中华人民共和国国家市场监督管理总局、中华人民共和国国家标准化管理委员会发布了《信息安全技术——远程人脸识别系统技术要求》(GB/T 38671-2020)国家标准。该标准适用于采用人脸识别技术在服务器端远程进行身份鉴别的信息系统的研制和测试,其中对活体检测的方法、假脸攻击类型均做了阐述。同年,全国金融标准化技术委员会发布了《人脸识别线下支付安全应用技术规范(试行)》,阐述了假体攻击类型并规定了活体检测性能指标,其中描述了2维静态纸质图像、2维静态电子图像、2维动态图像、3维高仿面具、3维高仿头模等不同方式的欺诈攻击。
当然,人脸识别应用的场景丰富多样,人脸活体验证的技术需求也是充满变化,而且随着欺诈攻击手段的变更需要逐步升级更新,未来需要制定更多细分行业且与时俱进的人脸活体验证技术标准。
7 结 语
7.1 总结
人脸活体验证技术对提升人脸识别系统的安全性、可信性具有十分重要的意义,已经成为无人值守模式下人脸验证不可缺少的一部分。随着人脸识别技术的快速发展尤其在实际应用中的推广,人脸活体验证技术也得到了研究人员越来越多的关注,大量相关研究成果产生,并有部分技术得到实际应用。本文对人脸活体验证相关研究与实际应用情况进行了全面回顾,形成观点如下:
1) 基于视觉传感数据实施的纹理分析、成像质量分析、3维结构分析、生理活性分析和深度学习特征分析均可以在一定程度上对人脸欺诈进行检测,然而,难以定论哪种特征表现更为优秀。大量实验与实际应用证明,将多种特征相结合可以获得更佳的活体检测效果。一般而言,针对已知类型的攻击,在训练数据集充足的情况下,基于多模态数据采用深度学习方法可以构建高精度的活体检测模型。如果采用新型学习范式,并采取知识与数据协同驱动的学习方式,效果会更佳。
2)大量传感设备均可用于支持人脸活体检测系统的部署,但是在实际应用中需要综合考虑硬件成本以及实际应用需求进行硬件选型。按照算法性能以及当前硬件成本,采用RGB-D摄像头是一种比较合适的方案,如果再加上一个近红外摄像头就可以支持目前绝大部分的算法部署。
7.2 展望
随着新的欺诈手段的出现,人脸活体检测研究也会遭遇到新的困难,一些需要解决的潜在问题和研究方向如下:
1)人脸欺诈和人脸欺诈检测技术将长期保持相互促进升级,因此研究未知类型人脸欺诈攻击的检测方法显得格外重要。随着欺诈技术的升级,人脸活体检测面临防范未知类型攻击更加困难的问题。
2)人脸欺诈手段的升级与欺诈媒介的更新相关,尤其高精度3D打印、柔性屏幕和仿生理面具等技术的进步将使得人脸欺诈行为更加难以检测,因此人脸活体检测在硬件层面也需要保持不断进步更新。基于此,当前探索多光谱仪、光场相机甚至超声波等先进传感设备在人脸活体检测上的应用具有前瞻性和必要性。
3)在现有的人脸活体检测算法中,以深度神经网络为主的机器学习方法在获得高准确度方面占有主导地位。然而,缺乏可解释性也是深度学习面临的一大诟病。因此,有必要深入研究在人脸活体检测应用中的深度学习解释方法。可解释性机制有助于通过学习探索不同特征在人脸活体检测中的具体作用,这有利于设计更合适的特征学习模型,同时有利于将学习方法与先验知识相结合。
4)当前的人脸活体检测算法与人脸识别算法是互相分离的,未来有必要发展两者的统一模型。统一有利于共享模型参数以压缩模型空间,还可以简化数据采集等工作流程,更重要的是两者若形成闭环工作机制有利于同时提升两者的准确度。
猜你喜欢
文萃报·周五版(2021年4期)2021-09-13
奥秘(2021年5期)2021-06-15
社会观察(2020年5期)2020-11-15
现代世界警察(2019年3期)2019-09-10
小雪花·初中高分作文(2017年9期)2018-05-21
课外生活(小学1-3年级)(2018年2期)2018-02-10
米娜·女性大世界(2016年8期)2016-08-17
奇闻怪事(2014年5期)2014-05-13
银行家(2012年11期)2012-01-17
全国新书目(2004年7期)2004-07-09
