
视觉深度伪造检测技术综述
2022-01-27 04:27王任颖储贝林杨震周琳娜
中国图象图形学报 2022年1期
王任颖,储贝林,杨震,周琳娜
北京邮电大学网络空间安全学院, 北京 100876
0 引 言
深度伪造由“DeepFake”一词翻译而来,该单词是“Deep learning”和“Fake”的组合,即深度学习与伪造的结合。深度伪造是一种基于深度学习的技术,指的是通过交换人的脸部来制作假视频和图像。DeepFake这个词源于Reddit用户DeepFake在2017发布的一种机器学习算法,并声称该算法可以帮助他将名人脸转换成色情视频。该算法一经发布就受到了民众与媒体的热议,随之而来的是视觉深度伪造算法研究的一股热潮。2018年,BuzzFeed发布了一段关于巴拉克·奥巴马发表演讲的深度伪造视频,该视频使用Reddit用户制造的FakeApp软件制作。自2017年至2020年,关于深度伪造相关的论文由原先的3篇增长至250余篇,同时,FakeApp、Faceswap、Zao、FaceApp等能够实现无技术成本的面向大众的快捷深度伪造软件也被依次开发,由视觉深度伪造技术制作的各种类别的伪造视频也引发了人们对身份盗窃、假冒以及在社交媒体上传播虚假信息的担忧。
目前现有的视觉深度伪造方法大致可以分为3种类型:合成新脸、面部修饰和面部互换。其中,合成新脸指的是使用GAN(generative adversarial network)创建不存在的人脸图像;面部修饰指的是为原始存在的人脸进行某些部位的修改;面部互换指的是对两张人脸进行局部或整体的交换。
合成新脸方法利用强大的生成对抗网络GAN,完全创造出整个原本不存在的人脸图像,目前合成新脸技术的数据库都是基于ProGAN和StyleGAN架构创造的,并且每个被创造出来的伪造图像都会携带其特定的GAN指纹。面部修饰方法主要是为目标人脸增添一些面部修饰,如改变头发颜色或肤色、修改目标人物的性别、为目标人物增加眼镜等等,该方法也需要基于生成对抗网络GAN,目前较新的StarGAN技术可以同时将面部分成多个领域并对其进行修饰操作。面部互换方法由两部分组成,第1种是将另一个人的脸用于替换视频中目标人物的脸,这是目前视觉深度伪造方向上最流行的方法,如DeepFakes、FaceSwap都是利用的这种方法,不同于前两种方法将面部合成操作放在图像上,此方法可以用于深度伪造视频的合成;第2种方式是面部表情交换,也被称为面部重现,即将另一个人脸上的面部表情替代到目标人物的面部表情上,如通过改变奥巴马的表情和动作使其完成伪造的“演讲”。目前该方法上较流行的是Face2Face和NeuralTextures等技术,同时FaceApp等手机应用使用基于StarGAN的技术,也可以一定程度上完成不同情绪表情的修改。
深度伪造技术在带来新奇的同时也带来了非常大的隐患。越来越多的视觉深度伪造视频的出现引起了人们对身份盗窃与冒充、虚假信息与影片的传播等现象的恐慌。因此,为了更好地应对这项日益复杂的技术,越来越多的研究团体针对深度伪造视频进行研究,提出了视觉深度伪造技术检测的方法。
本文搜集了目前针对视觉深度伪造技术检测的研究论文,并对其进行了分类与统计。与梁瑞刚等人(2020)、李旭嵘等人(2021)近期发表的综述不同,本篇综述主要针对视觉深度伪造检测,总结了深度伪造检测至今最新的研究进展,并对其采用了全新的分类方法,将其分为基于具体伪影的视觉深度伪造检测,基于数据驱动的视觉深度伪造检测,基于信息不一致的视觉深度伪造检测,和其他类型视觉深度伪造检测4类,并对其进行了具体分析和展望,对视觉深度伪造和伪造检测的未来发展具有推动作用。
1 视觉深度伪造方法
传统图像、视频的篡改技术通过截取源内容并嵌入目标物等方法进行,深度伪造检测则以深度学习为基础。早期的伪造视频主要依靠自动编码器产生,而生成对抗网络(GAN)的出现使得伪造视频更加逼真。
生成对抗网络GAN包含生成模型和判别模型两部分,是一种采用互相博弈的方法来学习数据分布规律的生成式网络。生成模型生成数据样本;判别模型预测数据是否属于真实数据。两者相互对抗提升性能,努力达到让判别器无法识别样本是否真实的状态。GAN 具有不依赖先验知识、可以产生更逼真样本的特点,在图像视频生成和伪造方面应用广泛。
2 视觉深度伪造相关数据集
视觉深度伪造检测大部分在视觉深度伪造相关数据集上实验,深度伪造数据集随着深度伪造技术和深度伪造检测技术的提高也在不断发展。当前使用范围较为广泛的经典视觉深度伪造数据集如表1所示。
Liu等人(2015)通过标记CelebFaces(Sun等,2014)和LFW(labeled fales in the wild)(Huang等,2008)两个人脸数据集中的图像,构建了两个人脸属性数据集:CelebA和LFW A。其中CelebA 数据集是人脸模型预测训练的重要数据集之一。
Rössler等人(2018)构建了FaceForensics数据集,该数据集由1 004个视频中的约50万幅图像构成,同时使用Face2Face方法对图像进行人脸篡改处理,得到最终的数据集。
Yang等人(2019)提出了数据集UADFV,由一组深度假视频以及其所对应的真实视频组成。该数据集包含49个由YouTube搜寻的真实视频,并且同时使用FakeApp对这些真实视频实现深度伪造生成假视频。Khodabakhsh等人(2018)提出了数据集FFW(fake face in the wild),该数据集同样由FakeApp对搜集到的高质量真实视频生成。
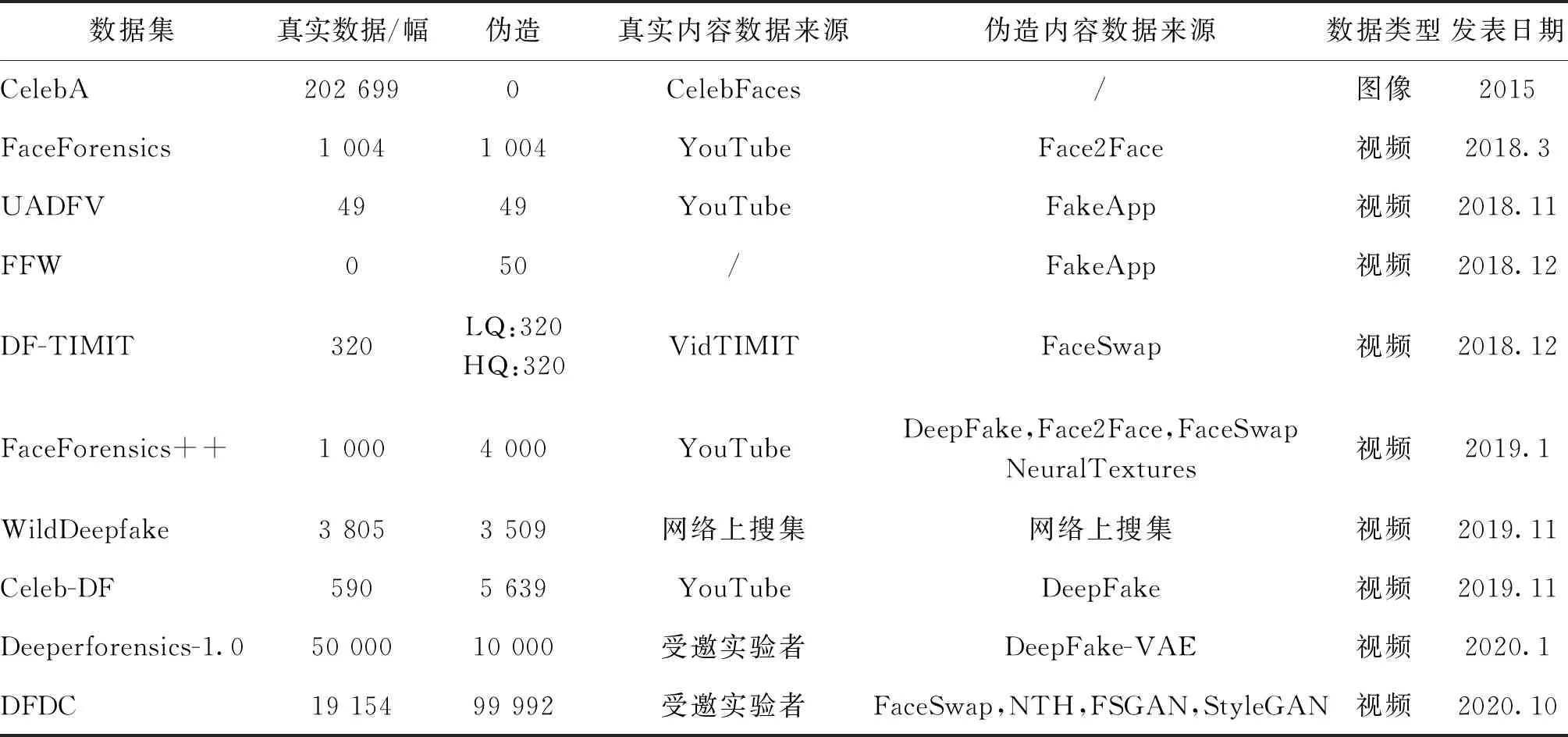
表1 视觉深度伪造数据集Table 1 The datasets of Deepfake
Korshunov和Marcel(2018a)提出了DeepFake-TIMIT数据集,该数据集基于VidTIMIT数据库的视频生成。作者从公开的VidTIMIT数据库中手动挑选了16对相似的人。对于该32名受试者,使用开源的GAN方法对其分别训练两个清晰度,分别是低质量的DF-TIMIT-LQ(64×64像素),和高质量的DF-TIMIT-HQ(128×128像素),每个人有其对应的10个视频,作者生成了每个版本对应320个视频,总共有620个视频的数据集。
以上数据集视频及图像的规模都不大,数量与使用的生成技术类别都较少,属于视觉深度伪造数据集的初步尝试。
Rössler等人(2019)提出了FaceForensics++数据集,该数据集选择了YouTube上的1 000个真实视频,共包含509 914幅图像为原始数据集,利用FaceSwap、DeepFake、Face2Face及NeuralTextures这4个先进的自动化深度伪造方法对原始数据集进行深度伪造处理。FaceForensics++数据集因为数据量大、使用的深度伪造技术类型多,成为很多深度伪造检测使用的数据集。但是也有其缺点,数据集在视觉效果上较为普通,视频面部合成的痕迹比较明显。
Zi等人(2020)提出了数据集WildDeepfake。该数据集由707个精心手动筛选过的深度造假视频,通过手动标注,最终筛选出7 314个人脸序列的1 180 099幅人脸图像。相比于之前的数据集,WildDeepfake数据集的视觉效果更加真实,更符合真实的生活场景。但是由于主要数据是从网上搜集,该数据集没有在伪造生成技术方面进行研究。
Li等人(2020c)提出了数据集Celeb-DF(celeb-DeepFake forensics)。Celeb-DF数据集包含590个真实视频和5 639个深度伪造视频。该数据集虽然只聚焦于DeepFake伪造技术,但是作者在视觉效果上做了很大幅度的提升:提升人脸分辨率至256×256像素;对伪造人脸与真实人脸进行颜色转换,使合成效果更好;更好地融合伪造人脸轮廓部分,减少边缘处的伪影;视频合成时减少抖动,使视频在时间轴上更加连续。基于这些对伪造视频及图像的处理,Celeb-DF数据集在视觉效果上非常好,截止目前,许多视觉深度伪造检测算法在该数据集上实验的精确率都不高。
虽然Celeb-DF数据集在数据规模和视觉效果上提升了很多,但是部分数据由于某些未经受试者同意却出现在数据集中的情况而被限制。鉴于此情况,Dolhansky等人(2020)提出的DFDC(Deepfake Detection Challenge)数据集在所有参与者同意的情况下发布了。DFDC数据集没有使用当前公开的数据库,而是寻找了一批实验者在经由其同意的情况下进行拍摄,总共邀请了3 426名受试者,平均每人有14.4个视频,共48 190个视频,大多数视频拍摄于1 080p。然后对原始数据集进行DFAE(Deepfake autoen-coder)、MM/NN face swap(morphable-mask/nearest-neighbors face swap)(Huang和de La Torre,2012)、NTH(neural talking head models)(Zakharov等,2019)、FSGAN(face swapping GAN)(Nirkin等,2019)、StyleGAN(Karras等,2019)等深度伪造技术进行处理,最终生成完整的DFDC数据集。DFDC数据集数量大,并且考虑了多种深度伪造生成技术,视觉效果也很好,相对其他视频而言更加生活化,所以人脸所占视频的部分会比较小,较难被检测。Jiang等人(2020)则提出了Deeperforensics-1.0数据集。该数据集包含60 000个视频(其中10 000个伪造视频),共1 760万帧,同时作者自己设计了一个伪造人脸生成技术DF-VAE(DeepFake variational auto-encoder)来制造假脸视频,并且考虑了不同姿态、照明条件和表情的因素,以此能够更好地模仿现实世界的场景。
3 视觉深度伪造检测技术
3.1 检测算法流程
视觉深度伪造检测技术主要由特征提取、模型建立、检测分类等步骤进行。首先,研究人员将待检测的图像或视频数据进行预处理,并根据先验知识或图像处理的手段确定待检测特征。接着,设计相应算法提取出确定的特征,并建立与检测任务相匹配的网络模型。最后,使用待检测数据对检测算法的性能进行测试,从而验证所选取特征的科学性及分类模型的有效性。其中,决定检测性能的关键就在于如何选择可以有效区分真假人脸的相关特征,以及如何建立分类效果良好的模型。图1展示了检测算法的具体流程。
不同的深度伪造检测方法体现在检测算法流程中的侧重点不同,因此可以对检测方法进行分类:
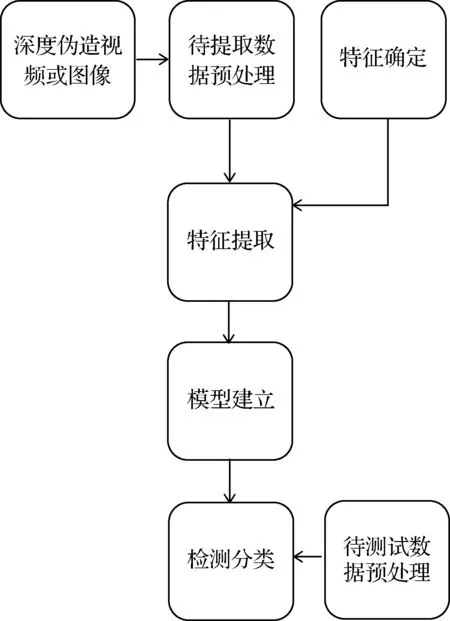
图1 视觉深度伪造检测算法流程Fig.1 Deepfake detection algorithm flow
1)基于具体伪影的视觉深度伪造检测技术侧重于检测流程图(图1)中的特征确定部分,从图像处理角度出发,以像素级粒度捕捉生成图像或视频中存在的模糊、抖动及叠影等异常现象。伪影特征的区分度高低直接影响着检测算法的性能优劣。
2)基于数据驱动的视觉深度伪造检测技术侧重于检测流程图(图1)中的模型建立部分,使用精心设计的神经网络对提取到的伪造品中的时域与频域信息进行训练分类。优秀的网络设计能够更加有效地提取出潜在的细微特征。
3)基于信息不一致的视觉深度伪造检测技术重点在于从生物固有特征、时间连续性以及运动向量等高级语义出发,捕捉伪造品与客观规律间的不一致部分。由于高级语义特征的提取过程较为复杂,因此此项技术侧重于检测流程图(图1)中的特征确定以及特征提取两个部分。
除了以上3种分类,部分技术采用了非常规的深度伪造检测算法流程,但同样以不同的方法达到了令人满意的检测效果。因此本文将其分为其他类型视觉深度伪造检测技术。
以下使用Peng等人(2017)以及Wang等人(2020b)的研究为例,具体阐述视觉深度伪造检测算法流程。
在Peng等人(2017)的研究中,研究人员选择了人脸表面3D光源信息作为区分真假人脸的特征。在实验过程中,研究人员选用了几个公开的图片数据集,并通过一系列数学方法对各人脸光源信息进行3D建模。由同一图像中各人脸之间的3D光源信息是否不一致,即可判断此图像是否由深度伪造技术生成。该研究即着重于上述算法流程(图1)中的特征确定部分,旨在提出一种全新有效的特征提高检测效果。本文复现了论文中的开源代码,其检测结果的误差分布如图2所示。横坐标代表在不同测试批次上的误差率,纵坐标代表该误差率占总测试批次数的百分比。
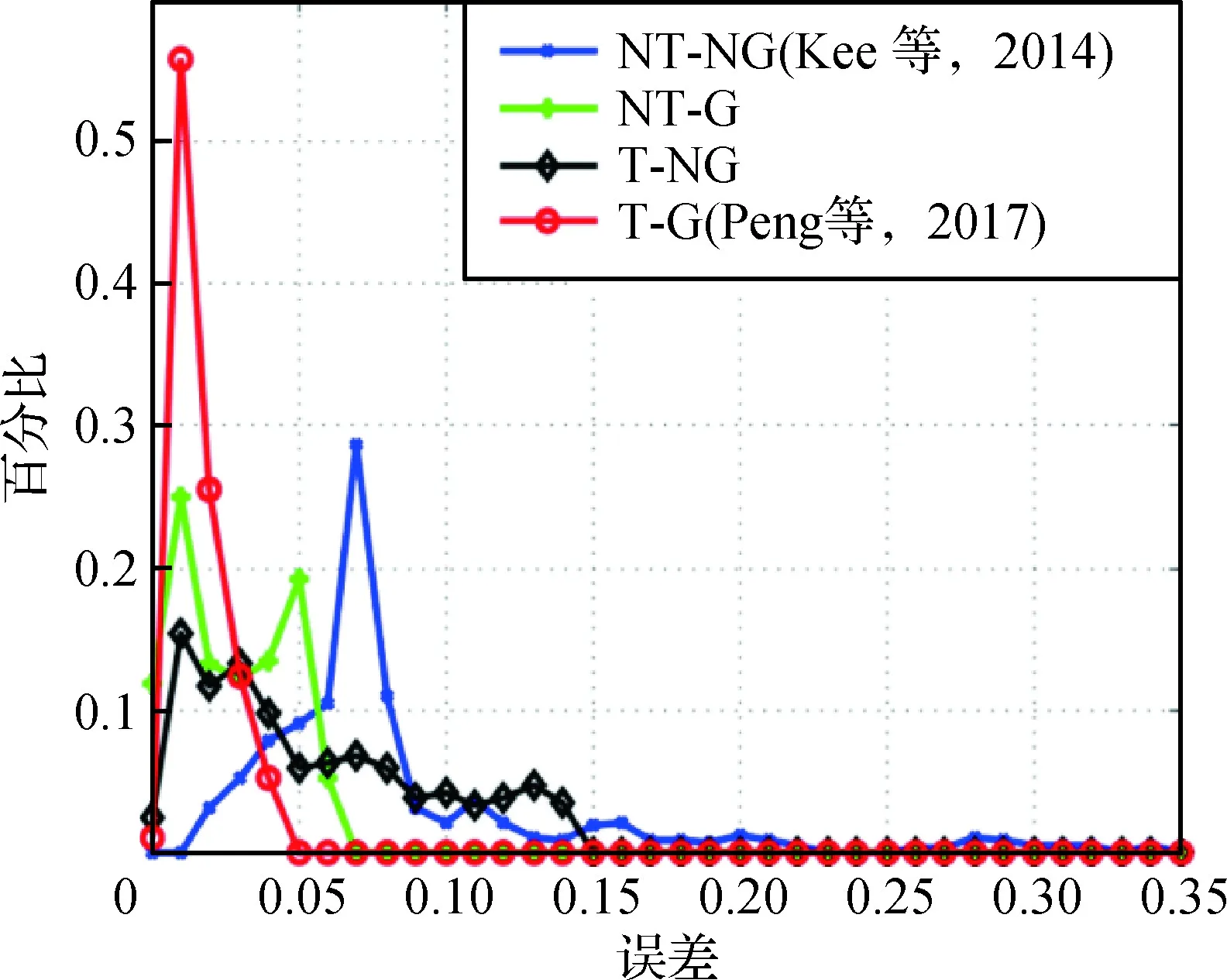
图2 Peng等人(2017) 实验测试误差分布Fig.2 Experimental result of Peng et al.(2017)
在Wang等人(2020b)的研究中,研究人员发现了一种由ImageNet训练的ResNet-50模型对于基于CNN(convolutional neural networks)架构的GAN具有良好的检测效果。在实验过程中,研究人员选取了几个数据集,每个数据集均由一种GAN模型生成,接着将经预处理的数据集对ResNet-50模型进行训练。结果显示,仅经由一种GAN模型生成的训练数据集训练的分类模型,可以在其他基于CNN架构的GAN模型上具有良好的分类结果。该研究即着重于上述算法流程中的模型建立部分,通过对模型的改进,增强对基于CNN架构的GAN上伪造品检测的泛化能力。本文复现了论文中的开源代码,其在作者提供的24 000幅图像的验证集上取得了100%的识别准确率。
3.2 技术分类与介绍
针对现有的视觉深度伪造检测技术,将其按照检测方法原理分为以下4类(表2—表5):基于具体伪影的视觉深度伪造检测,基于数据驱动的视觉深度伪造检测,基于信息不一致的视觉深度伪造检测,以及其他类型视觉深度伪造检测。

表2 基于具体伪影的视觉深度伪造检测文献Table 2 Classification of Deepfake detection based on specific artifacts

表3 基于数据驱动的视觉深度伪造检测文献Table 3 Classification of data-driuen DeepFake detection

表4 基于信息不一致的视觉深度伪造检测文献Table 4 Classification of DeepFake detection based on mconsistent information

表5 其他类型视觉深度伪造检测文献Table 5 Classification of DeepFake detection based on other types
3.2.1 基于具体伪影的视觉深度伪造检测
一些视觉深度伪造产品会伴随着人工伪影,这些伪影对于肉眼难以观察,然而通过机器学习则可得以辨别和检测,一些论文针对深度视觉伪造制品中某种特定的人工伪影进行机器学习,从而区分视觉深度伪造制品与真实人脸的方法。此种方法着重于视觉深度伪造检测流程中的特征确定部分,尝试通过图像纹理、色彩、亮度等差异有效定位人工篡改的位置。
1)基于伪造人脸混合框架处的伪影。如图3所示,某些深度伪造技术在将其伪造人脸混合回原脸的框架轮廓及背景处时,可能在混合边缘处留下某些伪影,以下论文基于此对伪造人脸进行检测。

图3 眼镜的臂部与面部边缘留下的伪影Fig.3 Artifacts from the arm of the glasses and the edge of the face
Mo等人(2018)发现一些深度伪造图像中的轮廓边缘看起来不自然,提出了可以将伪造图像裁剪成小块,单独处理轮廓边缘。Nirkin等人(2020)提出了将待检测图像分别裁剪成包含不同区域内容的两类小块,一类是面中主要区域(如眼睛、鼻子等区域),另一类是面部轮廓与背景部分交界处(如头发、耳朵等部分),对两类图像分别建立向量,各自监督学习后,对比训练提取特征,以得到检测深度伪造人脸的目的。同样,Li等人(2020b)也将图像裁剪成小块处理,在该基础上加入了伪造假脸与真实人脸的对比训练这一分支。该方法检测准确率较高,然而仅在较老的Faceforensics等数据集上进行了实验,对新数据集的实验效果不得而知。
Li等人(2020a)更加清晰地明确了混合边界检测的概念和方法。他们基于大部分深度伪造人脸都有将伪造后的人脸混合回原图背景中这个步骤,训练了一个用于预测图像混合边界的CNN网络,以此判断输入图像是否可以被视作来自不同的两幅图像的混合体。该方法重点关注混合轮廓边界,排除了其他伪影带来的干扰,在比较新的数据集DFDC和Celeb-DF上也取得了不错的准确率。
2)基于伪造人脸面中区域的伪影。一些深度伪造人脸制品在人脸内部也会出现伪影,如图4中展示了在面部中的眼睛区域因两只眼睛颜色不同而造成的伪影,以下论文通过捕获面中区域的某些伪影特征,对深度伪造人脸进行检测。

图4 因眼睛颜色不同产生的伪影Fig.4 Artifacts based on color of eyes
Li和Marcel(2018b)观察到许多DeepFake算法,为了使制造出的低分辨率伪造制品匹配上原始图像,需要进行扭曲等变换,而这种变换会在伪造制品中留下其伪影,并且可以被CNN捕获。Matern等人(2019)发现在一些利用DeepFake和Face2Face伪造的人脸中,会产生包括双眼颜色不一致、五官某处几何形状不准确等一系列的伪影,于是他们提取了这些特征,并且使用KNN(K-nearest neighbor)算法对其进行分类。Durall等人(2019)提出了通过频谱分析放大伪影,以便于分类器更好捕捉的方法;Guo等人(2020)提出了一种用残差网络AREN作预处理,用以抑制图像从而加深伪影的方法。
如图5所示,Chen等人(2021)发现许多DeepFake伪造制品都会有一定程度的图像干扰,导致其伪影不能被检测,于是构造了一种基于掩膜的检测器和重建器。通过人脸掩膜检测图像是否经过干扰处理,若检测到图像经受过干扰,则对其进行重建,通过对重建后的干净图像进行基于伪影的检测,能够获得极高的检测准确率。该方法很好地解决了经过扰动处理的伪造制品难以被检测到的问题,很大程度上提高了检测的准确率,然而对于本身伪影就难以发现的伪造制品效果一般。

图5 对受干扰图像的检测和重建(Chen等,2021)Fig.5 Detection and reconstruction of disrupted image (Chen et al., 2021)
以上几种方法对于能够找到具体伪影的伪造人脸制品非常有效。它们在一定程度上弱化了图像本身的内容,突出了各自针对的伪影部分,可以提高其检测的准确率,但是仅能应用于以上提到的可以捕捉到具体伪影的检测方法中,泛化性不强。
3)基于深度伪造制品的颜色问题。McCloskey和Albright首先(2018)发现利用GAN进行深度伪造的人脸图像与真实的人脸图像有颜色上的不同,提出了检测伪造图像的新方法。Nataraj等人(2019)在深度伪造制品的每个红、绿、蓝通道上的图像像素上计算共现矩阵,并且用CNN学习共现矩阵中的重要特征,从而达到检测伪造人脸的目的。针对两种GAN数据集:cycleGAN(Zhu等,2017)和StarGAN(Choi等,2018)进行实验。
Masi 等人(2020)则提出了一个两分支结构的新模型:其中一个分支以检测RGB通道颜色因素,而另一个分支则加入高斯拉普拉斯算子(Laplacian of Gaussian,LoG)作为瓶颈层来放大伪影,以便神经网络更好地捕捉特征。两个特征图融合后,使用以新的损耗公式监控的双向长短期记忆人工神经网络(long short-term memory,LSTM)循环建模。该方法新颖之处在于融合了两种特征:颜色和时间序列,使得该模型在FaceForensics++和DFDC数据集上都有不俗的表现,但是其在比较新的Celeb-DF数据集上准确率稍有欠缺。
朱新同等人(2021)从YCbCr色彩空间和RGB色彩空间中提取特征,并使用两种不同的滤波方法组成双通道特征提取层,从而获得丰富的图像特征进行训练。
4)基于光源的伪影问题。Peng等人(2017)提出了一种结合非凸几何学和纹理特征的优化的3d光源估计模型,该模型能够更加便捷并有效地对人脸进行建模,并分析出表面光源信息,依靠对光源距离的计算判断待检测图像是否为伪造制品,如图6所示。该方法从3D光线入手提出伪造检测方法,开拓了基于伪影检测的新思路,然而由于真实情况下拍摄的人脸图像也受到外界光源变化的影响,该模型容易混淆某些深度伪造制品与真实人脸,故而对DeepFake类伪造图像的检测效果不好,也容易将一些真实人脸误检测为伪造制品。

图6 基于光源估计模型的不同检测出为伪造制品的图像(Peng等,2017)Fig.6 Images is detected as deepfake because of light model (Peng et al., 2017)
5)基于GAN指纹的方法。对基于相机拍摄的数字图像,在相同的光条件下,感光元件的每个像素块的表现并不是完全相同的,该现象称为光响应非均匀性(photo response non-uniformity,PRNU)(Lukas等,2006)。在一般情况下,每个不同的相机PRNU都是不同的,就像人类的指纹一样。Koopman等人(2018)将深度伪造视频逐帧抽取并分组,进行PRNU计算分析,获得归一交叉联合分,根据分数判断该视频是否经过篡改。
由PRNU可以视作每一台相机设备的指纹得到灵感,Marra等人(2019a)提出了设想:GAN很可能也会在输出图像上留下自己独特的印记。通过实验最终证实GAN会在其生成的图像上留下特定的指纹。基于该结论,Yu等人(2019)进一步通过实验发现:如图7所示,不同种类的GAN和训练GAN时存在的微小不同都能导致图像中出现不同的指纹特征,并且该指纹能够十分有效地免疫图像噪声。基于以上结论,他们提出了一种全新的通过对图像GAN的指纹识别判断图像是否为深度伪造的方法。这种方法简单,准确率高,且可以直观地检测出篡改痕迹,但是当伪造技术绕过GAN生成方法和生成指纹时,这种方法没有办法对这类伪造人脸进行检测。

图7 不同类型的GAN可以导致不同的指纹(Yu等,2019)Fig.7 Different GANs can result in different fingerprints (Yu et al., 2019)
表6展示了基于具体伪影的检测方法在FaceForensics++数据集上的性能比较,其中Li等人(2020a)提出的Face X-ray方法准确率最高。基于具体伪影的视觉深度伪造检测方法十分有效且简洁,只需要针对某个特定的伪影即可检测出输入人脸的真伪,然而随着近年来视觉深度伪造技术的逐渐发达,越来越多被发现的伪影在新型GAN的制品中已然不复存在,是否能够发现更多新的技术制造的伪影成为了这些检测方法需要攻破的首要难题。

表6 伪影类论文在FaceForensics++上的性能Table 6 Paper of artifacts on FaceForensics++
3.2.2 基于数据驱动的视觉深度伪造检测
一些作者没有把重点聚焦于在某一个特殊的伪影或不一致性上,而是把深度神经网络训练成通用的分类器,然后让网络来决定分析输入数据集的哪些特性,图8展示了一个经典的基于数据驱动的视觉深度伪造检测的网络结构。此种方法着重于视觉深度伪造检测流程中的模型建立部分,尝试通过创新分类模型的架构与改变模型的参数来提升真假图像的分类性能。
早期研究基于数据驱动的视觉深度伪造检测的论文,展示了许多标准的CNN架构是如何有效检测深度伪造制品的:Zhang等人(2017)提出了一种用稳定特征加速算法(sped up robust features,SURF)(Bay等,2006)和词袋模型(bag of word,BOW),使用SVM进行分类的机器学习识别方法;Do等人(2018)提出了使用CNN经典架构VGG-Net(Simonyan和Zisserman,2015)对GAN生成的伪造加练进行检测;Tariq等人(2018)训练了VGG16、VGG19、ResNet(He等,2016)、DenseNet(Huang 等,2017)、NASNet(Zoph等,2018)、XceptionNet(Chollet,2017)和ShallowNetV1(Tariq等,2018)等基于CNN的模型来检测伪人脸图像;Afchar等人(2018)使用了自己设计的两种简单CNN架构Meso- 4以及MesoInception- 4,着重检测DeepFake和Face2Face两种技术生成的伪造制品;Jain等人(2018)基于SVM分类器,提出了一种基于CNN的有监督的算法,通过简单卷积处理,达到判断图像是否为伪造人脸图像的目的。这些方法训练时十分便捷,但是往往只针对论文原创的或是比较旧的数据集检测,在新的GAN生成技术及其构成的数据集被建立起来以后,这些方法逐渐无法完成有效的伪造人脸检测功能。
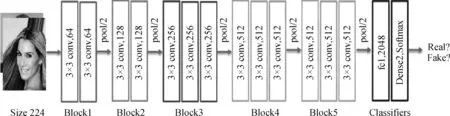
图8 基于标准架构的简单数据驱动检测网络Fig.8 Data-driven detection network
于是许多论文在以上基础方法上提出了不同方向的优化改良:
1)定位被篡改的区域位置。一些论文尝试定位深度伪造制品中被深度伪造技术篡改的位置,通过对定位区域进行特征提取从而能够更精准地做出检测判断。
一般而言,定位目标图像中被操作区域有两种常用的方法:使用滑动窗口重复执行二值分类,和分割整个输入图像。Nguyen等人(2018)采用滑动窗口方法,用于检测由计算机生成的欺骗区域。Nguyen等人(2019)提出了另一种基于分割方法的模型用于检测移除、复制—移动和拼接攻击,使得最终检测准确率得到了一部分提升。
Li等人(2019)将深度伪造检测视作像素级的分割任务,通过对比评估XceptionNet、MesoInception- 4、U-Net(Ronneberger等,2015)、VGG16、FN3等模型,发现了分割模型的准确率往往高于分类模型,展示了分割角度的优越性。Dang等人(2020)提出了一种利用注意力机制来处理和改进用于分类任务的特征方法。通过估计图像特定的注意力图来自动定位图像被篡改的区域,估计监督和弱监督方式下的注意力图,以进一步改善对真假脸的二分类。
Wang和Deng(2021)提出了一种基于注意力机制的数据分片方法——representative forgery mining (RFM)。该方法由两部分组成:forgery attention Map (FAM),用以定位检测器敏感的人脸区域,并为后续的数据增强提供信息。suspicious forgeries erasing (SFE),在FAM的指引下可以让检测器对于可疑的篡改区域分配更多的注意力。采用RFM方案,分类器可以检测出先前可能被忽略的面部区域的可疑篡改部分。该模型可以在DFFD和Celeb-DF数据上展现最先进的分类性能。
2)优化网络模型。Nguyen等人(2019a)提出了一种基于胶囊网络的检测方法。然后又在此基础上构建了一个基于胶囊网络的通用检测模型(Nguyen等,2019b)。该模型将深度伪造制品的异常外观作为关键特征,每个捕捉到关键特征的主胶囊都会将该信息传递给其他胶囊,每个胶囊对其输出其判定结果。Rana和Sung(2020)提出了一种改良的胶囊网络,名为DeepfakeStack的深度集成学习方法,模型会根据基础学习者的输出标签返回一个类预测,最终返回一个输出结果。胶囊网络可以通过很小部分的训练量获得很好的输出效果,并且可以更好地建模内部分层关系,在深度伪造人脸检测上有非常广阔的应用前景。
Zhou等人(2017)提出了一种基于双流网络的检测方,两个流结合了高级篡改伪影和低级噪声残留特征。Hsu等人(2020)也采用双流网络的架构,通过成对的输入真伪图像提炼出通用伪特征CFF。并且使用CNN与暹罗网络(Chopra等,2005)训练出一个通用伪特征网络CFFN(the common fake feature network)。
Guarnera等人(2020)提出了一种基于最大期望算法(expectation-maximization algorithm, EM)(Moon,1996)的深度伪造检测模型。提取一组特定的局部特征来建模图像中可以找到的卷积痕迹,然后训练朴素分类器以进行深度伪造检测。
Ding等人(2020)提出了一种基于迁移学习(transfer learning)的检测方法,只使用了ResNet-18中的卷积滤波器,并抛弃了其中的非卷积层,训练新的层以解释输入图像的潜在空间特征表示。
另一些论文则提出了在神经网络模型中加入记忆的方法,可以使深度伪造检测的准确率得到提升。Marra等人(2019b)提出了用于检测并分类由GAN生成图像的多任务增量学习模型。该模型可以在不遗忘先前分类的情况下,对新的分类具有良好的适应能力。Fernando等人(2019)提出了一种层次记忆网络HMN,能将视觉线索存储在神经记忆中,对感知到的面孔进行推理,并预测未来的语义嵌入,从而成功地检测出伪造的面孔。
张亚等人(2021)提出了一种基于自动编码器的 Deepfake 检测方法。利用自动编码器对图像进行特征提取,并在编码器中添加注意力机制模块以获取更好的分类效果,该方法可以对多种GAN生成的伪造图像进行检测。Zhao等人(2021)将深度伪造检测表述为细粒度分类问题进行研究,提出基于multi-attentional的检测网络。网络由3个关键部分组成:采用多注意力机制,可以使得网络关注到不同的面部局部特征;使用纹理增强模块,从而获得图像像素级尺度的细微伪影;采用attention maps,聚合层次的纹理特征和高层次的语义特征。该模型在检测准确性上展现了优越性,在最新的DFDC数据集上表现良好。
耿鹏志等人(2022)针对现有的检测方法参数量大、网络较深,模型结构复杂等情况,对模型XceptionNet进行优化,提出一种轻量化的取证模型Xcep_Block8,在降低模型参数量的同时,仍保持了较高的检测精度。相比于其他基于数据驱动的检测方法而言,此方法的优点是模型占用效率高、占用空间小,如何在压缩模型的基础上进一步提高精度将是未来基于数据驱动检测方法需要攻克的难题。
表7展示了基于数据驱动的论文在FF++数据集上的性能,其中Rana和Sung(2020)展现了最高的准确率。表8展示了基于数据驱动的论文在Celeb-DF数据集上的性能,可以看到大部分在FF++上表现优秀的论文在Celeb-DF上都准确率不高,Wang和Deng(2021)的论文以99.53%取得了最高准确率。基于数据驱动的视觉深度伪造检测方法的优点是非常方便,大部分分类特征都由神经网络模型自己判断,同时不会因为某种伪影被新的深度伪造技术所改进而失去其使用价值,但是由于其往往需要由网络自动提取特征,容易耗费大量的时间空间资源。
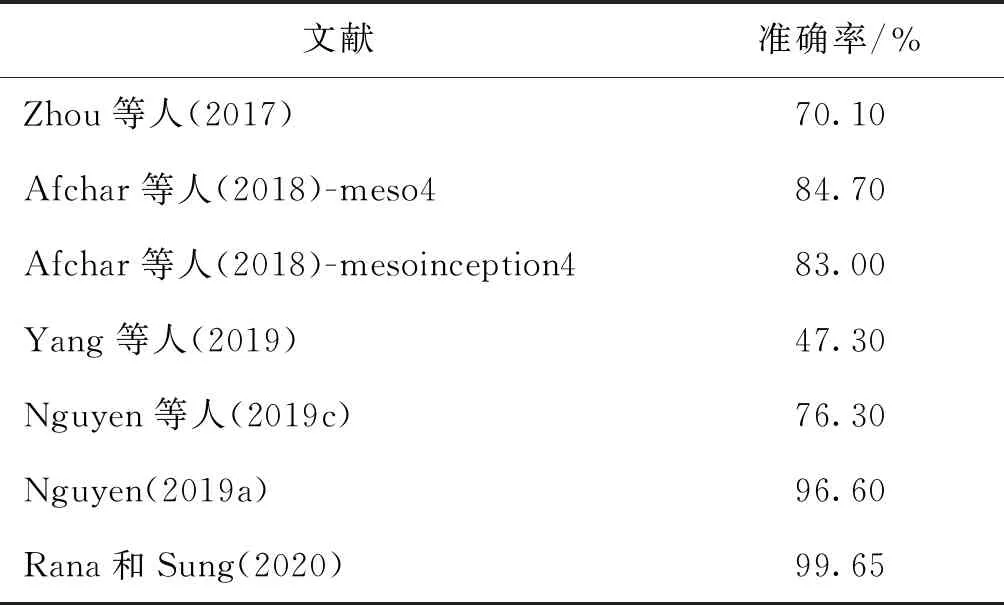
表7 数据驱动类论文在FaceForensics++上的性能Table 7 Paper of data on FaceForensics++
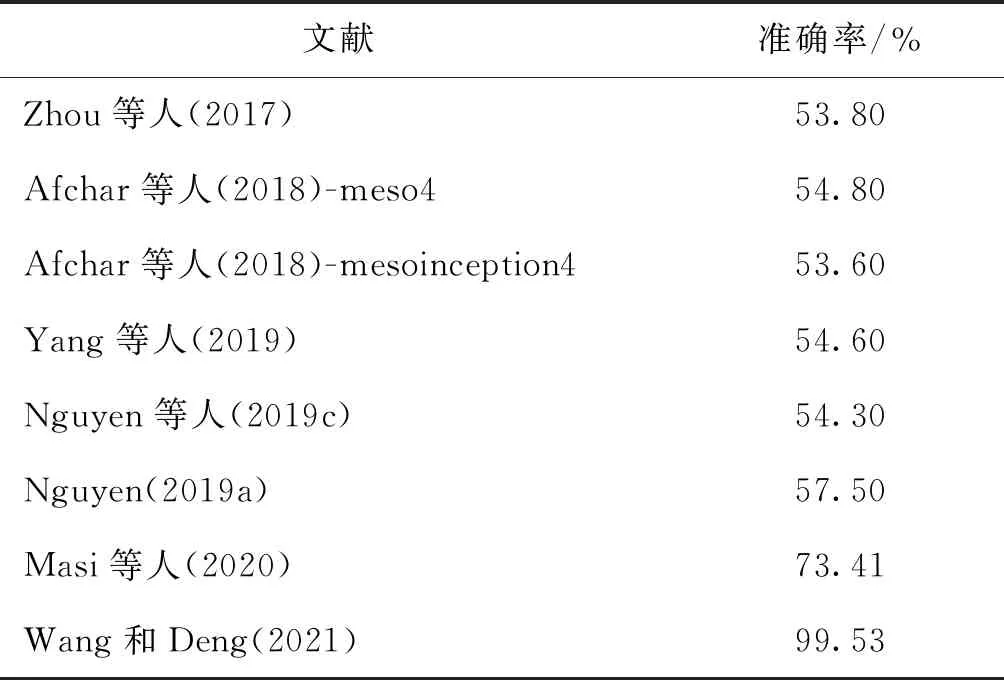
表8 数据驱动类论文在Celeb-DF上的性能Table 8 Paper of data on Celeb-DF
3.2.3 基于信息不一致的深度伪造识别技术
基于信息不一致的深度伪造识别技术主要分为3种,分别为:生物信号的不一致性、时间序列的不一致性、与真人行为的不一致性。此种方法着重于视觉深度伪造检测流程中的特征确定部分,尝试找寻到可以有效区分真伪且难以被模型移除的图像视频特征。
1)基于生物信号不一致性的方法。真实情况下,人具有一定的生物信号,例如:眨眼频率、脉搏次数等,并且这些信号在视频中可以被捕捉到并存在特定的规律。然而,深度伪造技术往往会在生成图像的过程中,丢失或修改这类规律。根据这一现象,研究人员提出了基于生物信号不一致的深度伪造识别技术。
(1)颜色脉搏。如图9所示,Conotter等人(2014)提出了一种基于人物前额颜色抖动的脉搏提取方法。研究人员分别对真实人脸视频以及CG游戏动画使用3-D面部追踪方法,发现真实人脸视频可以提取出明显且规律的颜色抖动,而CG游戏动画则无法提取出这类信息或提取信息不规律。文章主要针对的是CG动画,然而对深度伪造的检测方向提出了一种新的思路。

图9 由脉搏引起的可视变化(Connotter等,2014)Fig.9 A visible change caused by the pulse(Connotter et al., 2014)
(2)眨眼频率。Li等人(2018a)提出了针对真
人眨眼频率的深度伪造识别技术。由于深度伪造技术中的核心GAN模型是在基于大量人像的基础上训练的,与真实情景中人的眨眼频率不同。如图10所示,文章基于此使用了一种将CNN与递归神经网络结合起来的模型,称为长期循环CNN(LRCN),进而根据眨眼频率,判断视频是否被篡改。该论文发表于2018年,深度篡改技术未经过大量眨眼数据的训练,因此产生了此类缺陷。如果能提供大量不同眨眼阶段的图像,那么深层神经网络学会眨眼只是时间问题。深度伪造技术发展至今,其也能够与原视频人物同步眨眼。此外,针对保留眼部特征,仅对其他部位进行篡改的视频无法进行检测。因此这条研究方向没有后续的跟进。
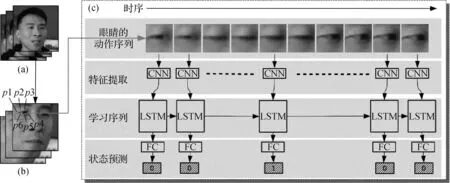
图10 Li 等人(2018a)使用的眨眼检测架构Fig.10 Detection on eyes by Li et al. (2018a)
(3)PPG。Ciftci等人(2020a)提出了基于光电容积脉搏波(PPG)生物信号的深度伪造识别技术,利用PPG信号检测视频人物的脉搏信号。Ciftci等人(2020b)在此基础上,又提出了PPG单元的概念。PPG单元在原来的空域信息的基础上,又增加了频域信息。论文提出的PGG检测架构如图11所示,作者在CelebDF数据集上进行了测试,并用VGG网络进行分类,最终的结果较之前的文章又有了进一步的提升。
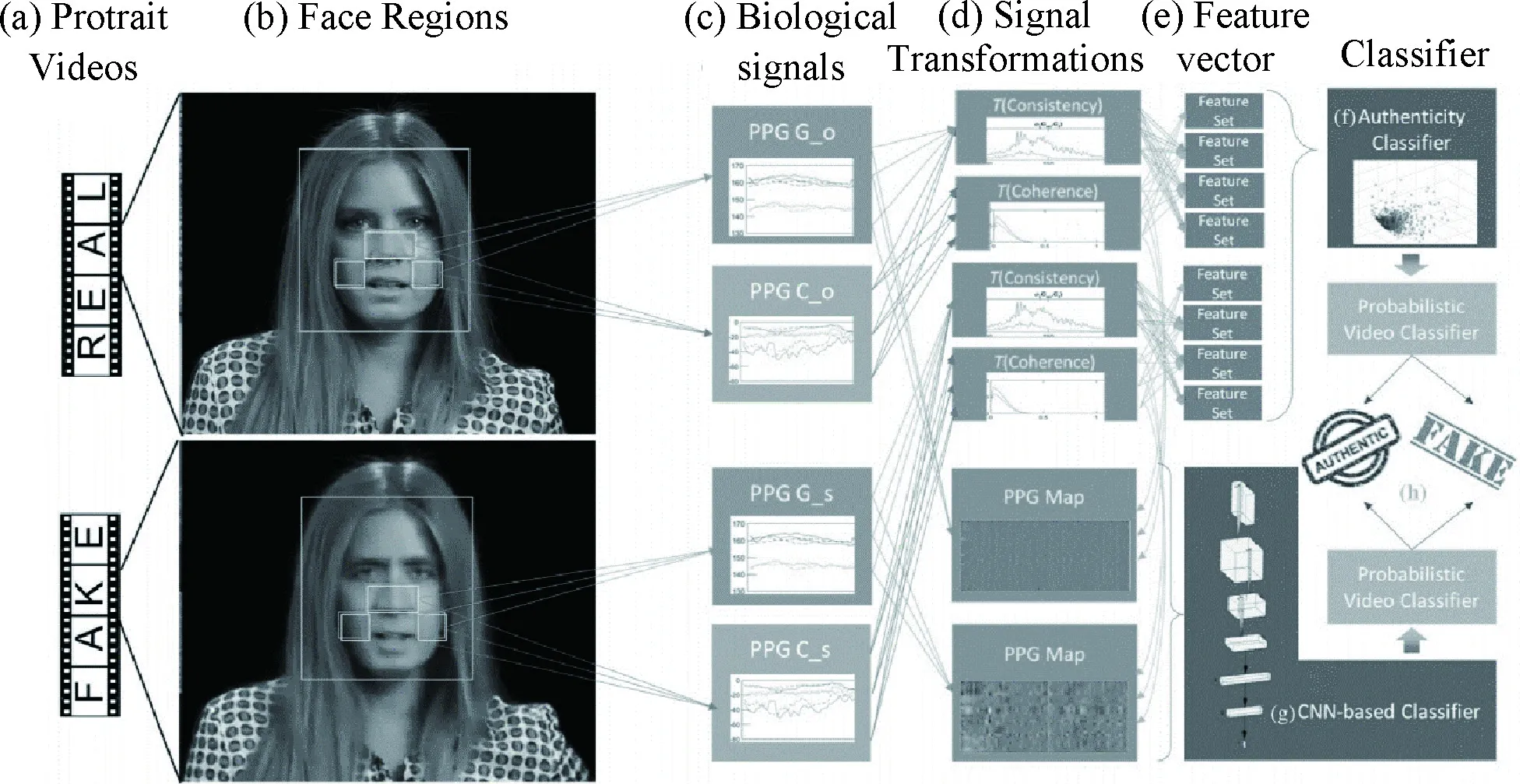
图11 PGG检测架构(Ciftci 等, 2020)Fig.11 Detection on PGG(Ciftci et al., 2020)
2)基于时间序列不一致性的方法。因为深度伪造视频在生成过程中是逐帧进行的,因此原视频中帧之间的连续性就有可能遭到破坏,从而导致深度伪造视频在连续帧上产生时空差异。最终表现在生成视频的人物运动不一致、色彩与纹理的不正常抖动等等。通过机器学习或神经网络等分类算法,捕捉此类不一致信息的手段被归类为基于时间序列不一致性的深度伪造识别算法。
Güera和Delp(2018)提出了一种时间感知的管道。使用CNN提取帧级特征以后,用LSTM做帧的图像处理,将得到的特征用以训练一个RNN,并将该RNN用以判断图像是否伪造。Sabir等人(2019)基于逐帧的深度伪造由对面部的操作引起的低级伪像预计会进一步表现为跨帧的具有不一致特征的时间伪像,提取待检测视频的帧序列,对其进行训练。
Amerini等人(2020)提出了视觉流动向量场的概念,即从连续帧中提取出变化向量信息,并输入至基于VGG-16的神经网络中进行分类。紧接着,Amerini和Caldelli(2020)又提出了一种利用重编码阶段预测误差引起帧间的不一致性来区分合成图像视频和自然图像视频的新技术。如图12所示,攻击者在生成伪造视频的过程中,势必经历原视频解码、生成、对压缩图像进行重编码,而在最后这个过程中,就引入了帧间预测。作者提取出预测误差图后,输入至LSTM,利用LSTM学习连续帧之间的时间相关性,分析视频是否经过伪造。de Lima等人(2020)基于深度伪造视频在时间序列上的不一致性,文章构建了不同的各种经典时空网络并以特征提取器。

图12 Amerini和Caldeli(2020a)提出的视觉流动向量场Fig.12 Visual flow vector fields by Amerini and Caldelli(2020a)
3)基于与真人行为不一致性的方法。真实视频中的人物在说话时,人物动作与音频能够保持高度地同步,并且特定人物说话时具有特定的面部与头部动作(例如各国领导人)。然而现有的深度伪造技术,都会对这类特征进行破坏。基于上述的原理,研究人员提出了基于与真人行为不一致性的深度伪造检测方法。
Mittal等人(2020)提出了一种方法,即同时从音频和视频中提取感知情感特征,以此来检测输入视频中的篡改。使用了基于暹罗网络的体系结构。Agarwal和Farid(2019)发现不同人在说话时,面部表情和头部运动存在明显的模式差异。而在目前现有的伪造方式中都对这种模式造成了破坏(即视频中的人脸区域发生了篡改,导致人物说话时面部表情和头部运动的模式与人物身份不相符)。论文利用这种方式,建立国家领导人个人的soft-biometric模型,并使用这些模型来区分视频的真假。
Haliassos等人(2021)针对现有的深度伪造技术广泛的口型缺陷问题,提出了一种新方法:LipForensics。通过利用读唇语学习到的丰富表征,来针对语义上高级口部动作的不一致。该方法实现了对未见伪造类型的一定程度上的泛化,同时对目前几种常见的损坏的鲁棒性较高。
表9展示了基于信息不一致的深度伪造检测论文在FF++数据集上展现的性能,其中Haliassos等人(2021)方法的检测准确率最高。基于不一致的伪造检测方法,关键在于如何寻找出能够有效区别真伪视频的特征,并且这类特征难以仅通过提高训练量而被生成模型所克服。例如上述的基于眨眼的检测方法,凭借当今成熟的深度伪造技术已经能够生动模拟出同步的眨眼动作,而不再适用。随着深度伪造技术不断提升,基于信息不一致的深度伪造识别技术显得愈加困难,但相关研究者仍在找寻更多有效的可识别特征。
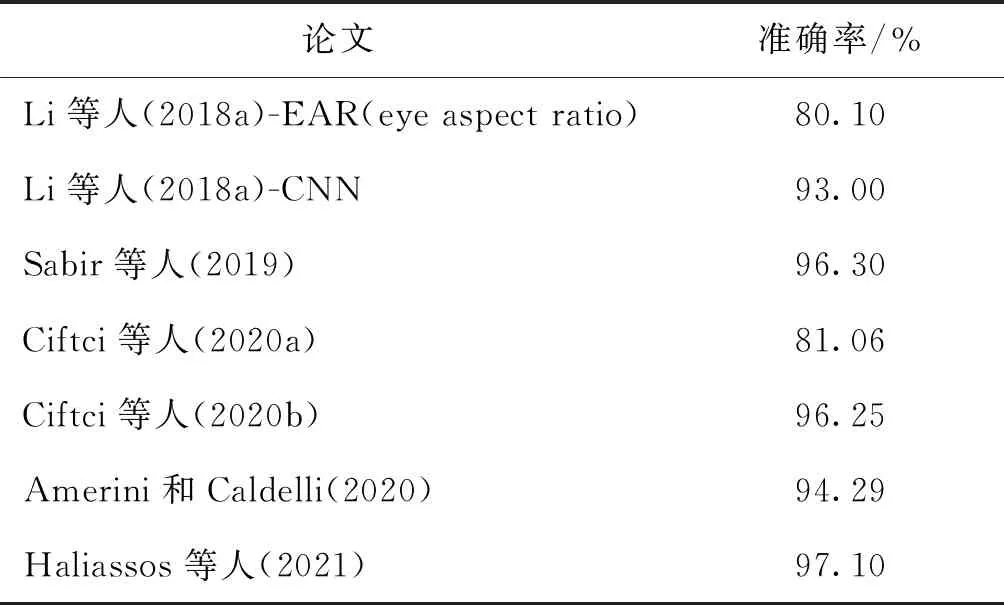
表9 不一致类论文在FaceForensics++上的性能Table 9 Paper of inconformity on FaceForensics++
3.2.4 基于其他方法的深度伪造识别技术
除上述的3个分类以外,研究人员也各自提出了不同的模型,其中包含许多思路新颖、识别率较高的方法,在此将其归于基于其他方法的深度伪造识别技术。此种方法对于视觉深度伪造检测流程各有不同的侧重点。
Agarwal等人(2017)提供了一个脸部图像数据集SWAPPED,并提出了一种基于像素块内像素权重特征。Korshunov和Marcel(2018b)提出了一种基于变分自编码器(VAE)的检测模型。Zhang等人(2019)提出了一种可以模仿GAN模型管道,生成图像伪影的模型autoGAN。从而可以在大量真实图片的数据集中,训练出大量由GAN模型生成的篡改图像。Wang等人(2020a)基于逐层神经元激活模式,提出了一种通过检测深层人脸识别系统中的神经元覆盖行为的方法。并且建立了一个新的数据集对该方法进行评估。
Du等人(2019)提出了一个位置感知自动编码器LAE,在训练过程中,通过像素方向的蒙版来调整局部LAE的解释,以强制模型使用LAE学习伪造区域的内在表示,而非尝试捕捉训练集中的伪影来训练。Fernandes等人(2020)提出一种基于attribution based confidence(ABC)矩阵的检测模型。该方案可以在仅有篡改模型而无训练集时使用,通过将输入图像a,按文章中提供的算法,按相应的概率选择相应的面部特征输入模型,即可得到此模型的ABC矩阵。
Wang和Deng(2021)主要探索如何利用单一的GAN模型来鉴别其他各种GAN生成的图像。研究者希望找到一种用于检测 CNN 生成图像的通用图像伪造检测方法。
基于其他方法的深度伪造识别技术往往是由作者提出一种新的统计特征,接着利用机器学习的手段对特征进行分类。技术的关键就是如何找寻到有效的统计特征,相比于使用神经网络,此项技术不需要大规模的数据集,训练时间也相对较短。
4 结 语
本文搜集了视觉深度伪造检测技术相关领域的论文,并对现今主流的研究方向做出了归纳总结,将其分成4类,现做出如下总结。
1)基于具体伪影的视觉深度伪造检测。此类方法着重于寻找伪造制品与真实图像之间的像素级差异。借助于机器学习的手段,研究人员可以有效地提取出人眼难以察觉到的伪影现象。不需要复杂的网络模型,在真实实验中具有较高的运算效率,检测时也更容易更方便。然而,随着基于各种伪影的深度伪造检测方法被提出,深度伪造生成的技术也在逐渐修复其生成中可能产生的伪影。从2016年至今,视觉深度伪造检测数据集由第一代的FaceForensics、UADFV、DF-TIMIT和 FaceForensics++数据集,发展至包含DFDC、Celeb-DF和Deeperforensics-1.0等数据集的第2代数据集,其中越来越多新的GAN生成的和经过更加严格的手动筛选的数据集的产生,对某些已经被发现的伪影制品起到了很好的修正作用。针对这方面伪造技术的逐渐发展,检测技术今后需要更多着眼于找到还未被发现的、具有泛化性的伪影和不一致,同时也需要针对最新提出的GAN技术进行研究,从伪造生成技术方面着手,找到对应的检测方法。
2)基于数据驱动的视觉深度伪造检测。第2种检测方法从2018年至今经历了技术的更迭,从最开始提出的由最简单的CNN基础架构训练预处理后的伪造数据,逐渐在神经网络结构上加入了胶囊网络、暹罗网络、双流网络等,丰富了模型,使得检测方法的准确率提高,应用的数据集范围增广。然而,基于数据驱动的检测方法也具有一定的缺点:(1)模型的复杂会导致训练的时间长、耗费资源多,在实操方面没有基于伪影的方法那么便捷;(2)由于这类方法着重于研究神经网络的结构,因此可以使用对抗性的机器学习来添加扰动以避免检测,对抗性机器学习的攻击可以跨越多个模型(Papernot等,2016),且这些攻击不仅对深度伪造检测分类器有效,而且在不了解分类器及其数据集的情况下也能工作(Carlini和Farid,2020)。基于数据驱动的检测方法目前仍然处于不断发展中,由于其准确率高、可以面向的数据集类型广,在视觉深度伪造检测方法未来的发展上更被看好,同时也具有广阔的发展空间,如何有效地提高模型训练的效率和如何解决对抗机器学习的攻击将成为日后该类检测方法需要解决的问题。
3)基于信息不一致的视觉深度伪造检测。此类方法着重于寻找伪造制品与真实图像或视频之间的信息级差异。目前主流分为3个方向:生物信号的不一致性、时间序列的不一致性、与真人行为的不一致性。与基于具体伪影的视觉深度伪造检测相似,攻击者在知晓伪造制品的不一致性表现后,可以通过模型优化或者加大模型训练数据集的方式减弱或消除此类表现,如针对伪造制品眨眼频率与真实人像不同的检测方法,在新的GAN被提出后,该不一致已经不在新的视觉深度伪造数据集中出现,则使用该伪造检测方法用于新数据集上的准确率也会大大降低。因此,如何找寻到一种各种篡改模型共性且难以消弭的不一致性特征,是此类研究方向未来需要研究的关键。
4)其他类型视觉深度伪造检测。本文将不属于上述3种方法的检测手段归于此类,其中包含了许多思想各异的方案。研究人员从海量的数据集中抽取出特定的统计特征,在无需大量训练计算量的情况下,也能使用统计特征有效区分真假图像与视频。当然,此类方法也往往局限于某种特定的数据集或篡改模型,较强的泛化能力与所提取特征的有效性是其发展的关键点。
针对以上4种分类的深度伪造检测方法的总结与评价,本文认为未来在视觉深度伪造检测上的重难点应该基于以下几个方向:
1)基于最新的生成伪造技术提出检测方法。对基于伪影和不一致性的视觉深度伪造检测方法而言,如何保证其针对的特征的新鲜度是其需要解决的重难点问题,而越来越多新的生成伪造技术在伪造方面修复了原先的伪造技术可能产生的伪影等特征,所以在伪造检测方面需要关注新的伪造生成技术,从生成方面入手,针对新的生成伪造技术进行分析。可以针对最新的生成伪造技术和真实的人脸,采用对比的方式,如孪生网络等,获取更鲁棒的特征提取,从而获得更好的深度伪造检测性能。
2)提出高效的基于数据驱动的方法。由于基于数据驱动的方法往往需要大量的数据集和机器学习训练,基于数据驱动的伪造检测方法在近年才逐渐发展起来,并且在未来也拥有良好的发展前景。但是其提取特征的效率低下、耗费资源广、耗时长也是一个需要解决的问题。因此,对基于数据驱动的伪造检测方法而言,可以采用知识蒸馏的方式进行模型压缩,也可以采用教师—学生网络,通过复杂但性能完好的教师网络训练浅层的学生网络模型,从而达到压缩模型,提高模型工作效率的目的。
3)提出泛化性更强的检测方法。另外一些检测方法在原理上有创新,但是往往在使用上局限于方法特定的生成技术和数据集上,不具有泛化性,则会出现对某个特定数据集检测准确率高、对其他常用的数据集准确率低的情况。如何使一些伪造检测方法具有泛化性,是一些论文需要继续解决的问题。为了增强检测方法的泛化性,一方面可以进行数据扩增,对目标数据集进行数据增强、数字图像处理等工作。另一方面,可以尝试进行单分类鉴别,通过学习训练真实的人脸来鉴别更多未知的伪造。
4)引入对抗学习防御技术。由于深度伪造检测方法往往是基于机器学习的大量工作提取特征,可以尝试在原有的检测方法中引入对抗学习防御的方法解决这一问题。因此可以采用针对对抗样本的方式,一方面是对对抗样本的识别,另一方面可以在训练集当中加入对抗样本的鲁棒的模型训练。
猜你喜欢
快乐学习报·教育周刊(2022年16期)2022-05-01
小天使·三年级语数英综合(2022年4期)2022-04-28
新高考·高三数学(2022年3期)2022-04-28
福建基础教育研究(2019年6期)2019-05-28
初中生世界·九年级(2018年12期)2018-12-22
汽车导报(2017年5期)2017-08-03
求学·理科版(2017年1期)2017-03-02
中学生数理化·高二版(2016年4期)2016-05-14
读者(2015年9期)2015-05-04
初中生世界·八年级(2014年2期)2014-03-15
